一种音频风格转换方法和系统与流程
[0001]
本发明涉及音频信号处理技术领域,具体涉及一种音频风格转换方法和系统。
背景技术:
[0002]
目前,视觉技术领域中,在卷积神经网络(cnn)的推动下,图像之间的风格转换成为一个非常活跃的研究主题,并迅速成为社交媒体中一种非常流行的技术。而音频技术领域中,例如,专业音频编辑,音乐创作,声音设计和电影后期制作(包括配音),将音频的风格转换已成为迫切的需求。
技术实现要素:
[0003]
本发明的目的在于提供一种音频风格转换方法和系统,以解决上述技术问题。
[0004]
为达此目的,本发明采用以下技术方案:
[0005]
提供一种音频风格转换方法,其改进之处在于,包括如下内容:
[0006]
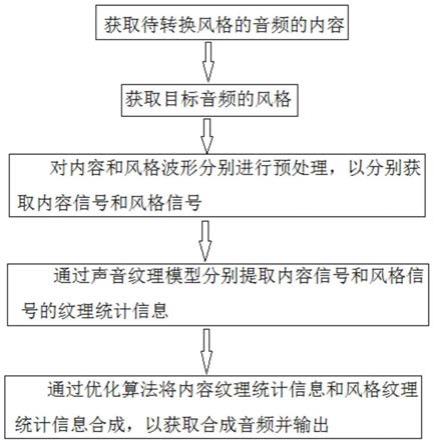
获取待转换风格的音频的内容;
[0007]
获取目标音频的风格;
[0008]
对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号;
[0009]
通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息;
[0010]
通过优化算法将内容纹理统计信息和风格纹理统计信息合成,以获取合成音频并输出。
[0011]
本发明还提供了一种音频风格转换系统,其改进之处,包括:
[0012]
内容获取模块,用于获取待转换风格的音频的内容;
[0013]
风格获取模块,用于获取目标音频的风格;
[0014]
处理模块,用于对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号;
[0015]
提取模块,用于通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息;
[0016]
合成模块,用于通过优化算法将内容纹理统计信息和风格纹理统计信息合成,以获取合成音频并输出。
[0017]
本发明通过声音纹理模型提取表征相关音频风格和内容的纹理统计信息,然后使用优化算法将内容纹理统计信息和风格纹理统计信息合成,是由目标内容而不是随机噪声初始化的,并且优化后的损失仅与纹理有关,而与结构无关,使得合成音频不是风格和内容的混合,而是格式化的内容,因此,使得合成音频的音质更自然、生动。
附图说明
[0018]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图作简单地介绍。显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于
本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0019]
图1是本发明一实施例提供的音频风格转换方法的步骤图;
[0020]
图2是本发明一实施例提供的音频风格转换系统的结构示意图
具体实施方式
[0021]
下面结合附图并通过具体实施方式来进一步说明本发明的技术方案。
[0022]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本专利的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0023]
需要说明的是:在音频中,风格和内容的概念很难定义,其更多地取决任务和数据,但是,本发明为了便于理解,进行如下示例性解释:
[0024]
对于语音,内容可以指代诸如音素和单词之类的语言信息,而风格可以与讲话者的特殊性有关,例如讲话者的身份,语调,口音和/或情感。
[0025]
对于音乐,内容可以是某种全球性的音乐结构,例如演奏的乐谱和节奏,而风格可以指代乐器的音色和音乐体裁。
[0026]
本发明一实施例提供的音频风格转换方法,如图1所示,包括如下内容:
[0027]
获取待转换风格的音频的内容;
[0028]
获取目标音频的风格;
[0029]
对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号;
[0030]
通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息;
[0031]
通过优化算法将内容纹理统计信息和风格纹理统计信息合成,以获取合成音频并输出。
[0032]
本发明通过声音纹理模型提取表征相关音频风格和内容的纹理统计信息,然后使用优化算法将内容纹理统计信息和风格纹理统计信息合成,是由目标内容而不是随机噪声初始化的,并且优化后的损失仅与纹理有关,而与结构无关,使得合成音频不是风格和内容的混合,而是格式化的内容,因此,使得合成音频的音质更自然、生动。
[0033]
在一个实施例中,对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号,其中,对内容和风格波形分别通过stft(短时傅里叶变换)转换处理,以分别获取内容信号和风格信号的2d频谱图信号。
[0034]
在一个实施例中,通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息,其中,声音纹理模型可以为神经网络或工程感知模型。
[0035]
在一个实施例中,声音纹理模型包括:
[0036]
通过30个带通耳蜗滤波器将波形分解为声频带;
[0037]
提取每个频带的包络,并对其施加压缩非线性;
[0038]
通过20个带通调制滤波器分解每个压缩包络。
[0039]
虽然,卷积神经网络(cnn)功能非常强大,但是,其很难对其获取的数据进行解释,而通过设置上述声音纹理模型,能够很好地对所获取的数据进行解释。
[0040]
在一个实施例中,纹理统计信息包括:每个频带的方差,每个包络带的均值、方差、偏度,以及跨带相关性信息。
[0041]
基于同样的发明构思,本发明实施例还提供一种音频风格转换系统,如图2所示,包括:
[0042]
内容获取模块1,用于获取待转换风格的音频的内容;
[0043]
风格获取模块2,用于获取目标音频的风格;
[0044]
处理模块3,用于对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号;
[0045]
提取模块4,用于通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息;
[0046]
合成模块5,用于通过优化算法将内容纹理统计信息和风格纹理统计信息合成,以获取合成音频并输出。
[0047]
本发明通过声音纹理模型提取表征相关音频风格和内容的纹理统计信息,然后使用优化算法将内容纹理统计信息和风格纹理统计信息合成,是由目标内容而不是随机噪声初始化的,并且优化后的损失仅与纹理有关,而与结构无关,使得合成音频不是风格和内容的混合,而是格式化的内容,因此,使得合成音频的音质更自然、生动。
[0048]
在一个实施例中,对内容和风格波形分别进行预处理,以分别获取内容信号和风格信号,其中,对内容和风格波形分别通过stft转换处理,以分别获取内容信号和风格信号2d频谱图信号。
[0049]
在一个实施例中,通过声音纹理模型分别提取内容信号和风格信号的纹理统计信息,其中,声音纹理模型可以为神经网络或工程感知模型。
[0050]
在一个实施例中,声音纹理模型,包括:
[0051]
一层结构模型,用于通过30个带通耳蜗滤波器将波形分解为声频带;
[0052]
二层结构模型,用于提取每个频带的包络,并对其施加压缩非线性;
[0053]
三层结构模型,用于通过20个带通调制滤波器分解每个压缩包络。
[0054]
虽然,卷积神经网络(cnn)功能非常强大,但是,其很难对其获取的数据进行解释,而通过设置上述声音纹理模型,能够很好地对所获取的数据进行解释。
[0055]
在一个实施例中,纹理统计信息包括:每个频带的方差,每个包络带的均值、方差、偏度,以及跨带相关性信息。
[0056]
需要声明的是,上述具体实施方式仅仅为本发明的较佳实施例及所运用技术原理。本领域技术人员应该明白,还可以对本发明做各种修改、等同替换、变化等等。但是,这些变换只要未背离本发明的精神,都应在本发明的保护范围之内。另外,本申请说明书和权利要求书所使用的一些术语并不是限制,仅仅是为了便于描述。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1