基于强约束字典和深度神经网络的两阶段单通道语音分离方法
1.本发明属于语音分离技术领域,具体涉及一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法。
背景技术:
2.日常生活中涉及到语音分离技术的产品越来越多,如手机、助听器、智能家居控制系统、军用对讲机等,随着通信技术的快速发展,人们对这些产品的语音质量有了更高的追求。如何从被干扰的语音中最大限度地获取纯净语音信号或将干扰信号的影响最小化是语音分离领域的研究重点内容之一。国内外众多学者对语音分离问题进行研究,提出了许多不同的方法。早期的传统信号处理方法有谱减法和维纳滤波器,这些方法通常适用于连续平稳的高信噪比环境。在此基础上提出的基于模型的方法根据源信号和混合过程构建模型,以数学推导的方式推算得到估计的源信号,如基于隐马尔科夫模型和高斯混合模型的方法都取得不错的效果。另外,nmf方法通过建立混合信号到目标信号的线性映射,也广泛应用于语音分离领域,但是信号结构复杂时并不能很好地表达。
3.基于字典的信号稀疏表示方法也常用来解决语音分离问题,信号稀疏表示就是用尽可能少的过完备字典原子来表示信号,学者们主要在字典构造方法和信号稀疏分解算法方面进行重点研究。aharon等人最早提出了k-svd算法,在该算法基础上一些学者通过增加字典约束条件来优化分离性能。sigg等人利用干净语音信号和干扰信号分别训练得到语音字典和干扰字典,将两个字典拼接成联合字典进行稀疏编码,从混合语音分离纯净语音取得了较好的性能。zhang等人研究了语音信号间的关联和字典间的交叉干扰,提出了一种将语音字典和干扰字典联合学习的语音增强方法,能减少源失真和混淆,提高语音质量,且在输入信噪比较低时增强效果更为明显。tian等人提出了一种基于学习字典的源分离方法,将公共子字典合并到常规的联合字典中,以确保特定源的子字典能捕获对应源的判别信息,并且设计了一种任务驱动学习算法来优化所提出的联合字典和用于分配公共信息的权重,实验结果表明该算法可以获得比传统算法更好的分离性能。
4.近年来,深度学习技术凭借其强大的学习能力在语音分离领域日益突出。基于深度学习的语音分离通过训练学习混合信号与目标信号之间的非线性映射关系,这种方法不需要大量的先验知识,而且在低信噪比或非平稳信号环境下仍然有不错的泛化能力。geoffrey hinton教授对传统的神经网络算法进行了优化,最早提出了深度神经网络的概念。han等人提出了通过训练dnn从受损语音的幅度谱中学习干净语音的幅度谱,达到去混响和去噪的目的。在训练dnn时,不同的训练目标会影响网络模型的分离效果,wang等人分析比较了常用的训练目标包括ibm和irm等的增强效果,整体上掩蔽技术取得了较好的效果。li等人提出了一种频谱变化感知损失函数的dnn语音分离算法,结果表明所提出的损失函数能提高语音清晰度和信噪比增益。我们团队提出的联合约束算法不仅惩罚残差平方和,而且利用输出之间的联合关系来训练双输出dnn,与基本损失函数相比该方法能获得更
好的性能。
技术实现要素:
5.本发明所要解决的技术问题是克服现有技术的不足,提供一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法,第一阶段进行初步估计,利用强约束字典学习实现语音与语音的分离,获取信号的粗略估计。第二阶段进行精细估计,利用映射能力强的dnn对第一阶段分离重构信号进行增强,通过联合约束实现语音与交叉投影残余的分离,使得最终估计的信号与目标信号更接近,从而提高分离语音的质量。
6.本发明提供一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法,包括如下步骤,
7.步骤s1.提取干净语音信号和混合语音信号的幅度谱,利用k-svd算法计算干净语音信号的子字典d1和d2,将子字典拼接成联合字典d=[d1,d2],在强约束的优化函数限制下迭代更新字典;
[0008]
步骤s2.将另一份训练样本在字典d上投影获取混合信号在d上的稀疏编码矩阵c=[c1,c2]
t
,重构获取第一阶段分离出的语音信号幅度谱和
[0009]
步骤s3.和经过dnn获取估计的理想比率掩码m1和m2,将掩码分别与和进行哈达玛积获取第二阶段精细估计的幅度谱和幅度谱和混合信号的相位相乘恢复出语音信号。
[0010]
作为本发明的进一步技术方案,步骤s1的具体步骤为,
[0011]
步骤s11.对每一句输入的时域连续语音信号进行采样,再进行短时傅里叶变换获取预处理后的语音信号;
[0012]
步骤s12.计算预处理后的语音信号的幅度谱s1和s2,基于k-svd算法分别训练获取对应的身份子字典d1和d2,拼接d1和d2获取初始联合字典d=[d1,d2];
[0013]
步骤s13.固定d,通过omp算法在目标函数约束下求得混合信号y在d上的稀疏编码矩阵c;
[0014]
步骤s14.固定c,通过l-bfgs算法求强约束优化函数来更新字典,获取强约束优化后的字典。
[0015]
更进一步的,步骤s14中,通过l-bfgs算法求强约束优化函数来更新字典的具体方法为,
[0016]
步骤s141.定义强约束优化函数为
[0017][0018]
其中,和分别为单个干净信号s1和s2在联合字典d
上投影的稀疏编码矩阵,和为和中在自身子字典上的投影部分;
[0019]
步骤s142.定义矩阵步骤s142.定义矩阵和其中i为单位矩阵,o为全零矩阵;
[0020]
步骤s143.强约束优化函数改写为
[0021][0022]
目标函数的梯度函数为
[0023][0024]
步骤s144.经过多次迭代求解获取更新后的优化字典,使混合信号在该字典上投影时能区分不同的源信号。
[0025]
进一步的,步骤s2的具体步骤为,
[0026]
步骤s21.混合信号在字典d上投影得到估计的稀疏编码矩阵
[0027]
步骤s22.根据重构得到第一阶段分离出的语音信号幅度谱和
[0028]
进一步的,步骤s3的具体步骤为,
[0029]
步骤s31.构建dnn网络框架,包含一个输入层、三个隐藏层和一个输出层;
[0030]
步骤s32.目标语音的理想比率掩码作为dnn网络的训练目标,定义联合约束损失函数对网络进行约束;
[0031]
步骤s33.将第一阶段分离出的语音信号幅度谱和输入dnn网络中,输出估计的理想比率掩码m1和m2;
[0032]
步骤s34.m1和m2分别与和进行哈达玛积获取第二阶段精细估计的幅度谱和
[0033]
步骤s35.和与混合信号的相位相乘恢复出目标语音信号。
[0034]
更进一步的,步骤s32中,定义联合约束损失函数对网络进行约束的具体步骤为,
[0035]
步骤s321.考虑掩码误差的损失函数为其中,和mi分别为第i个源信号的第l层输出层的预测输出矩阵和目标掩码矩阵,||
·
||2为l2范数;
[0036]
步骤s322.利用irm与信号幅度谱的关系,联合约束损失函数定义为
[0037][0038]
其中,和si分别为第一阶段重构得到初步估计信号的幅度矩阵和第i个源信号的幅度矩阵;
[0039]
步骤s323.在前向传播算法中,随机初始化dnn每层神经元节点的权值和偏置,获取随机预测的再通过反向传播算法在联合约束损失函数下微调网络参数,使预测估计值逐渐逼近真实目标值;
[0040]
步骤s324.经过多次迭代更新后得到网络权值和偏置,训练好的dnn模型用于语音与交叉投影残余的分离。
[0041]
进一步的,还包括步骤s4.对所提出的基于强约束字典和深度神经网络的两阶段单通道语音分离方法进行性能评估;
[0042]
其具体方法为,
[0043]
步骤s41.将基于强约束字典学习的单通道语音分离方法与基于传统联合字典的方法进行对比实验,验证强约束优化函数的有效性;
[0044]
步骤s42.将基于强约束字典和深度神经网络的两阶段单通道语音分离方法与基于强约束字典学习的单通道语音分离方法进行对比实验,验证了两阶段语音分离方法的有效性。
[0045]
本发明的优点在于,
[0046]
1.该方法通过抑制重构信号与目标信号的误差、约束单个干净信号在联合字典上表示的重构误差、抑制干净信号在其他字典上的投影并限制字典间的原子相关性,三个部分来减少信号在联合字典上表示时出现的“交叉投影”,提高单通道语音分离系统的性能;
[0047]
2.该方法在第一阶段利用强约束字典实现语音分离,得到初步估计信号后。第二阶段中利用映射能力强的深度神经网络,通过联合约束实现语音与交叉投影残余的分离得到精细估计信号,使得估计信号更接近目标信号,提高单通道语音分离系统的性能。
附图说明
[0048]
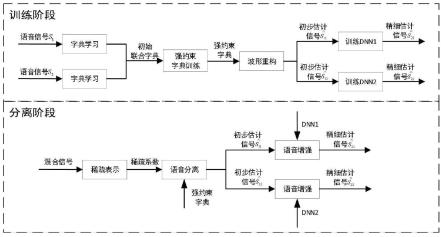
图1为本发明的运行流程示意图;
[0049]
图2为本发明的第二阶段dnn模型结构示意图;
[0050]
图3为本发明的实施例中loss1算法与mse算法比较图;
[0051]
图4为本发明的实施例中loss1-mmse、loss1-loss2与loss1算法比较图。
具体实施方式
[0052]
请参阅图1,本实施例提供一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法,在实际应用中,一般提取语音信号的声学特征,将声学特征输入到分离模型中进行训练,然后用训练得到的分离模型进行语音分离。基于字典的信号稀疏表示方法常用来解决语音分离问题,因此,本实施例将字典学习用于第一阶段的语音分离。近几年,深度学习在数据挖掘,模式识别,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果,其强大的特征提取和建模能力使得模式识别的性能得到极大提升,因此,本实施例将dnn应用于语音分离中,用于第二阶段的语音分离,可构建更高性能的语音分离系统。
[0053]
为了有效的提升语音分离性能,第一阶段,提出了强约束的优化函数,在此函数约束下构建更具有区分性的联合字典,来减少“交叉投影”。该约束分为三部分,第一部分抑制重构信号和目标信号的误差,第二部分约束干净信号在联合字典上的误差,第三部分抑制干净信号在其他字典上的投影并限制字典间的原子相关性。第二阶段,为了提高两个相似信号的分离效果,本实施例提出基于强约束字典和深度神经网络的两阶段单通道语音分离方法。第一阶段利用强约束字典实现语音分离,得到初步估计信号。第二阶段利用映射能力强的深度神经网络,通过联合约束实现语音与交叉投影残余的分离,从而去除交叉投影残余的影响,得到精细估计信号,使得估计信号更接近目标信号。以下是对本实施例体实施方式的详细论述。
[0054]
步骤s1:对输入语音信号进行预处理并更新字典。
[0055]
对语音信号进行预处理并计算语音信号的幅度谱
[0056]
由于语音信号具有短时平稳特性,故在进行特征提取前需要对语音信号进行预处理,这一才能将语音信号的特征信息提取出来。预处理操作主要包含:预加重,分帧加窗。接下来计算语音信号的幅度谱s1和s2[0057]
训练得到身份子字典d1和d2[0058]
k-svd是一种稀疏表示中字典学习的算法,其名字的由来是该算法要经过k此迭代,且每一次迭代都要使用svd分解。k-svd在字典更新的过程中,每次只更新一个原子和对应的稀疏编码向量,在更新该原子时,其它原子是不变的,每次更新完字典的所有原子就同时更新了系数编码系数,这叫做一次迭代。基于k-svd算法分别训练得到对应的身份子字典d1和d2。
[0059]
获取初始联合字典
[0060]
拼接d1和d2得到初始联合字典d=[d1,d2]。
[0061]
进行稀疏编码
[0062]
omp算法是指从字典矩阵d(也称为过完备原子库中),选择一个与信号y最匹配的原子(也就是某列),构建一个稀疏逼近,并求出信号残差,然后继续选择与信号残差最匹配的原子,反复迭代,信号y可以由这些原子的线性和,再加上最后的残差值来表示。每一次迭代过程中对所挑选的全部原子先要执行schmidt正交化操作,来确保每一次循环结果都是
最优解。固定d,使用omp算法在目标函数约束下求得混合信号y在d上的稀疏编码矩阵c。
[0063]
在强约束优化函数指导下更新字典
[0064]
具体步骤如下:
[0065]
a.定义强约束优化函数:
[0066][0067]
其中,和分别为单个干净信号s1和s2在联合字典d上投影的稀疏编码矩阵,和为和中在自身子字典上的投影部分。
[0068]
强约束优化函数可以分为三部分来分析,第一部分包含前三项,第一项是为了减少混合信号由联合字典表示时的误差;第二项和第三项的作用是约束干净语音信号在对应子字典上的投影误差,使语音信号尽可能被自身子字典所表示。第二部分包含第四和第五项,是为了进一步加强约束干净语音信号在联合字典上投影时,尽可能投影在相应的子字典上,而不要投影在其他子字典上。第一部分和第二部分的区别是,第二部分从信号自身出发,更强化约束了单个干净语音信号在联合字典上投影时,尽可能投影在自身子字典上。第三部分包含第六、第七和第八项,第六项和第七项是为了抑制干净语音信号在其他子字典上的稀疏表示,减少语音信号在其他子字典上的交叉投影,尽可能减少字典之间的交叉干扰;第八项通过使子字典间原子内积尽可能小来抑制子字典间的原子相关性,增加两个子字典的区分性,从而进一步减少交叉投影。
[0069]
l-bfgs算法是求解无约束非线性规划问题最常用的拟牛顿方法,即在有限内存中执行近似bfgs算法,它的内存开销小,计算效率高,在特征维度较高时其优势十分明显。固定c,通过l-bfgs算法求强优化约束函数来更新字典,得到强约束优化后的字典。
[0070]
b.定义矩阵b.定义矩阵和其中i表示单位矩阵,o表示全零矩阵。
[0071]
c.强约束优化函数改写为:
[0072][0073]
目标函数的梯度函数为:
[0074][0075]
d.经过多次迭代求解得到更新后的优化字典,该字典相较于初始联合字典更具有差异性,使得混合信号在该字典上投影时能更好地区分不同的源信号。
[0076]
步骤s2:获得第一阶段分离语音幅度谱。
[0077]
混合信号在字典d上投影得到估计的稀疏编码矩阵
[0078]
根据重构得到第一阶段分离出的语音信号幅度谱和
[0079]
步骤s3:经过第二阶段dnn得到分离后的目标语音
[0080]
构建dnn网络框架
[0081]
dnn框架包含一个输入层、三个隐藏层、一个输出层如图2所示。神经元设置如下257-1024-1204-1024-257,输入层和输出层节点数为257,隐藏层为三层,节点数为1024
[0082]
定义联合约束损失函数
[0083]
初步估计信号特征作为输入,目标语音的理想比率掩码作为监督,我们定义本实施例两阶段方法中第二阶段的理想比率掩码为:
[0084][0085][0086]
其中,si(t,f)表示第i个源信号在时间t频率f处的幅度谱,表示该信号在第一阶段分离后的估计幅度谱,其仍含有部分交叉投影残余,mi(t,f)表示第i个源信号在时间t频率f处的掩码。
[0087]
考虑掩码误差的损失函数:
[0088][0089]
其中,和mi分别为第i个源信号的第l层输出层的预测输出矩阵和目标掩码矩阵,||
·
||2表示l2范数。上述损失函数只考虑了估计信号与目标信号之间的关系,为了提高估计信号与目标信号的逼近程度,利用irm与信号幅度谱的关系,联合约束损失函数定义为:
[0090]
[0091]
其中,和si分别为第一阶段重构得到初步估计信号的幅度矩阵和第i个源信号的幅度矩阵。该联合约束损失函数j
loss2
中除irm的约束外增加了irm估值对应的幅度谱误差约束。
[0092]
使用梯度函数求解每一层的w和b,输出层的预测输出满足:
[0093][0094]
此时,损失函数变化为:
[0095][0096]
第l层w和b的梯度为:
[0097][0098][0099]
其中,
⊙
表示哈达玛积,对z
l
求导部分表示的是第l层的残差,记为:
[0100][0101]
再根据前向传播算法,w
l
和b
l
有如下关系:
[0102][0103]
计算出w
l
和b
l
梯度:
[0104][0105][0106]
通过归纳法递推可以得出:
[0107]
δ
l
=(w
l+1
)
t
δ
l+1
⊙
σ'(z
l
)
[0108]
对w
l
和b
l
的更新如下:
[0109]
[0110][0111]
其中,α表示学习速率。
[0112]
训练网络
[0113]
在前向传播算法中,随机初始化dnn每层神经元节点的权值和偏置,得到随机预测的再通过反向传播算法在联合损失函数约束下微调网络参数,使预测估计值逐渐逼近真实目标值。经过多次迭代更新后得到网络权值和偏置,训练好的dnn模型用于语音与交叉投影残余的分离,从而实现对分离语音的增强。
[0114]
分离得到幅度谱
[0115]
将第一阶段分离出的语音信号幅度谱和输入dnn网络中,输出估计的理想比率掩码m1和m2。
[0116]
重构语音
[0117]
m1和m2分别与和进行哈达玛积得到第二阶段精细估计的幅度谱和和与混合信号的相位相乘恢复出目标语音信号。
[0118]
步骤s4:对所提出的一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法进行性能评估。
[0119]
数据库及实验设置。
[0120]
实验硬件处理器是intel(r)core(tm)i5-4210u cpu@1.70ghz 2.40ghz,程序编写是基于python3.7和matlab。本实施例实验中使用的语音样本来自grid语料库,该语料库由高质量的音频和视频录音组成,总共有34位说话者(男性18位,女性16位),每人有1000条记录,每条语句约2秒。此外,所使用的深度学习框架有keras2.3.1和pytorch1.10.0。随着tensorflow2.0的发布,tensorflow包含了keras学习库,本实施例使用tensorflow2.1.0版本。
[0121]
从grid语料库中选择2个男性和2个女性进行实验,对任意两个说话人的混合语音进行分离,每个说话人1000条语句中,400条作为第一阶段字典学习时的训练集1,400条作为第二阶段dnn训练时的训练集2,剩余的200条为测试集,语音信号的采样频率由25khz下采样为16khz。使用的dnn框架是257-1024-1204-1024-257,输入层和输出层节点数为257,隐藏层为三层,节点数为1024。dnn训练过程中,设置迭代次数为50个epochs,初始学习率为0.01,隐层间使用relu激活函数,输出层使用sigmoid激活函数。本实施例采用sdr、sir、sar和pesq以及stoi作为衡量语音质量评价的指标,语音质量与指标数值成正相关。
[0122]
实验性能评估
[0123]
首先,验证强约束字典学习的单通道语音分离方法的有效性。随机选择2位女性说话人f1、f2和2位男性说话人m1、m2,共6种语音混合方式进行实验,图3展示了强约束字典算法和传统联合字典算法的性能比较。如图3所示,与基于传统联合字典算法(mse算法)相比,使用强约束优化函数训练字典的语音分离方法(loss1算法)的sdr、sir、sar、pesq和stoi都有一定程度的提升,说明语音可懂度和准确度增强了,这意味着强约束的优化函数有效限
制了不同信号间的干扰影响。不论哪种衡量指标,异性别组合的混合信号分离时,整体性能要好于同性别混合的情况,原因是同性别的语音相似度较高从而导致分离任务更加困难。女性f1-f2混合语音分离时,与传统联合字典算法相比,sdr、sir、sar、pesq和stoi分别提升了0.692db、1.632db、1.014db、0.046和0.055;男性m1-m2混合时,sdr、sir、sar、pesq和stoi分别提升了1.637db、0.73db、1.565db、0.03和0.028。女性组合比男性组合的分离性能要差的原因是女性的基音频率比较高且相似性高,分离难度就较大。异性别组合的混合信号分离结果好于同性别组合,因为男生和女生语音相似度较低。以f2-m1为例,sdr提升了0.642db,sir提升了0.571db,sar提升了1.178db,pesq提升了0.079,stoi提升了0.057。实验结果验证了本实施例提出的强约束优化函数获取的字典对语音分离是有效的,同时也可以看出混合语音的性别组合对实验结果是有影响的。
[0124]
接下来,验证强约束字典和深度神经网络的两阶段单通道语音分离方法的有效性。图4显示了强约束字典和深度神经网络的两阶段单通道语音分离方法(loss1-mmse算法、loss1-loss2算法)与基于强约束字典学习的单通道语音分离方法(loss1算法)分离性能的比较。从图4中可以看出,首先loss1-mmse和loss1-loss2算法相对loss1算法各评价指标都有一定的增长,这表明字典学习联合dnn的两阶段语音分离方法能够有效提升语音分离性能。其次,loss1-loss2算法的整体分离性能相对loss1-mmse算法有更进一步的提升,尤其是异性别组合的情况。异性别混合以f2-m1为例,loss1-loss2语音分离方法相对loss1语音分离方法,sdr、sir、sar、pesq和stoi分别提升了2.545db、0.77db、2.236db、0.089和0.058。女性f1-f2混合时,对应的sdr、sir、sar、pesq和stoi分别提升了1.776db、0.32db、0.22db、0.042和0.048。男性m1-m2混合时,相应的sdr、sir、sar、pesq和stoi分别提升了0.451db、0.325db、0.317db、0.036和0.036。异性别组合各指标取值大于女性f1-f2组合或男性m1-m2组合情况,而且各指标从loss1算法到loss1-loss2算法的提升值也要大一些,这主要因为同性别组合时两个语音更为相似,分离任务要更难一些。实验结果验证了本实施例提出的字典学习联合dnn的两阶段语音分离方法能有效提升了分离语音的可懂度和清晰度。
[0125]
以上结果表明:本实施例提出的一种基于强约束字典和深度神经网络的两阶段单通道语音分离方法,从字典学习的优化函数和分离模型的构建两个方面提出两种可以提升语音分离系统的性能的方法,实验结果验证了这两个方法的合理性和有效性。与其他方法相比,本实施例的方法在五种测量指标上得到提升,可以一定程度上克服普通方法对语音分离不完全的缺点,在实际应用中具有很好的借鉴意义。
[0126]
以上显示和描述了本实施例的基本原理、主要特征和优点。本领域的技术人员应该了解,本实施例不受上述具体实施例的限制,上述具体实施例和说明书中的描述只是为了进一步说明本实施例的原理,在不脱离本实施例精神范围的前提下,本实施例还会有各种变化和改进,这些变化和改进都落入要求保护的本实施例范围内。本实施例要求保护的范围由权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1