使用CRISPR/Cas9技术靶向敲除水稻矮杆基因SD1的方法与流程
本发明属于植物分子生物学与生物技术领域,具体涉及一种基于cripsr/cas9基因组编辑技术靶向敲除水稻矮杆基因sd1的方法。
背景技术:
水稻原产于中国,是世界主要粮食作物之一。中国水稻播种面占全国粮食作物的1/4,而产量则占一半以上,为我国重要粮食作物。
人类在大约一万年前开始驯化水稻时,就选择出了一个与高产有关的重要基因。这个基因叫做半矮秆基因sd1,它使水稻长得较矮,从而能结出更多谷粒,并且抗倒伏的能力更强。围绕这个基因进行的水稻矮化育种,是20世纪中期全球第一次绿色革命的关键内容。
sd1参与赤霉素的生物合成,编码由389个氨基酸组成的ga20氧化酶(ga20ox)。ga20ox是赤霉素合成途径中的关键酶,催化ga53转换为ga20。sd1基因的突变引起的ga20ox活性的下降,会使水稻植株矮化。
crispr/cas9系统是近年来发展起来的一种基因组dna编辑技术,它的原理是利用一段靶基因序列特异的sgrna,引导cas9核酸内切酶,对靶基因的dna进行切割、编辑。crispr/cas9技术已经被证明可以非常有效的在第一代转基因水稻中编辑靶基因序列,并且编辑后的序列可以稳定的遗传。crispr/cas9系统与zfns(锌指核酸酶)和talens(转录激活因子样效应物核酸酶)等基因编辑技术相比,具有设计和构建简单、突变效率高、多靶点同时编辑等优点。
过去,水稻矮化育种主要通过诱变获得矮化水稻品种,或者通过杂交的方法将矮杆基因导入到其它的水稻品种中,这两个方法获得矮杆水稻株系的周期较长、工作量大、成本高。通过crispr/cas9基因编辑系统直接对水稻的sd1基因进行定点突变,创制水稻矮杆株系,可以大大的缩短矮杆育种的周期。
技术实现要素:
本发明针对现有技术的不足,提供一种基于crispr/cas9系统的水稻sd1基因定点敲除的方法,及利用该方法在不同水稻品种中创制矮杆水稻株系的应用。本发明利用sd1基因编码的ga20氧化酶是赤霉素合成途径中的关键酶的特点及crispr/cas9系统基因组定点编辑功能,定点突变sd1基因的核苷酸序列,改变sd1基因编码的ga20氧化酶活性,从而得到矮杆的水稻株系。
使用crispr/cas9技术靶向敲除水稻矮杆基因sd1的方法,其特征在于,包括如下步骤:
a)选择sd1基因编码区第108至127核酸序列作为crispr/cas9系统的靶序列(seqidno.1):aggatggagcccaagatcc;
根据靶序列设计两条单核苷酸引物:
sd1-f1(seqidno.2):tgtgtgaggatggagcccaagatcc
sd1-r1(seqidno.3):aaacggatcttgggctccatcctca;
b)将单核苷酸引物sd1-f1和sd1-r1混合,通过退火反应形成二聚体结构,然后与载体片段bgk03进行连接,构建得到含有水稻sd1基因靶序列的质粒bgk03-sd1;
c)用含有bgk03-sd1质粒的根癌农杆菌eha105侵染水稻的愈伤组织,通过潮霉素筛选,再生获得转基因水稻植株;
d)利用如seqidno.4和seqidno.5所示的水稻sd1基因的特异引物,扩增基因组片段进行测序,筛选突变植株;
seqidno.4:gggtcattgattcgaccatc
seqidno.5:gtgctcggacacctggaagaac。
进一步地,所述水稻品种为申繁17、申繁24、申9b或申武1b。
crispr/cas9系统采用的靶序列为sd1编码序列中包括5’-gn(19)ngg-3’的核酸序列,其中n为a、t、g、c中的任意一个碱基。靶序列(seqidno.1):aggatggagcccaagatcc在水稻的基因组中是唯一的。
本发明根据crispr/cas9的设计原则,在水稻sd1基因编码区确定crispr/cas9系统编辑的靶位点,根据靶位点的序列设计引物,构建crispr/cas9载体,用农杆菌介导的方法转化水稻愈伤组织,通过筛选鉴定,最后获得sd1突变的不含转基因dna片段的矮杆水稻品系。该方法应用于矮杆水稻品种的选育,可以免去杂交选育的工作,大大缩短矮杆品种选育的周期。
附图说明
图1是突变植株sd1测序图。
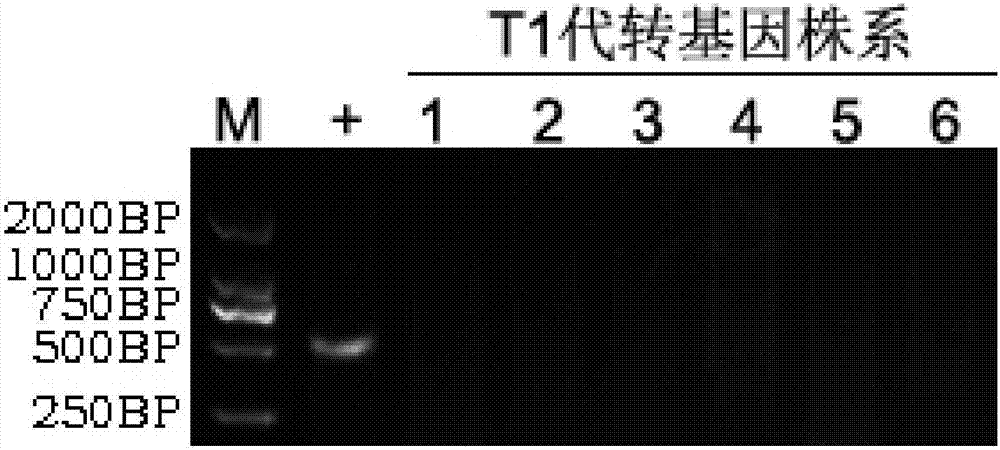
图2是潮霉素基因pcr检测电泳图。其中“m”是dl2000分子标记,“+”是质粒阳性对照,1-6是选取的部分t1代转基因株系。
图3是水稻野生型与sd1基因敲除突变植株的主茎高度对比图。
具体实施方式
下面结合具体实施例对本发明的技术方案做进一步详细说明。
实施例1
水稻sd1基因的编码区序列如seqidno.6所示。
本实施例crispr/cas9编辑靶序列长度为20bp,位于sd1编码区的第108至127碱基位,编辑的靶序列为seqidno.1:aggatggagcccaagatcc。
根据靶序列合成两条单核苷酸引物:
sd1-f1(seqidno.2):tgtgtgaggatggagcccaagatcc
sd1-r1(seqidno.3):aaacggatcttgggctccatcctca;
通过退火反应使得引物sd1-f1和sd1-r1形成二聚体结构,然后与bgk03载体片段进行连接,构建成含有水稻sd1基因靶序列的质粒bgk03-sd1。
用电激法将bgk03-sd1质粒转化如农杆菌eha105,将含有bgk03-sd1质粒的农杆菌eha105在含有kan(50μg/μl)的lb平板上划线,获得单菌落。挑单菌落接种到3ml含利福平(25mg/l)和kan(50mg/l)的lb液体培养基中28℃摇菌培养过夜;第二天将菌液按1:20的比例接种于含利福平(25mg/l)、kan(50mg/l)和乙酰丁香酮(20mg/l)的ab液体培养基中,28℃,200rpm摇菌培养大约4h。离心收集农杆菌,加等体积含乙酰丁香酮(20mg/l)的aam液体培养基重悬,即可用于转化水稻的受体材料。
本实施例以粳稻3系杂交稻的恢复系申繁17和申繁24,保持系申9b和申武1b为受体材料进行农杆菌转化。每个品种去成熟的种子1000粒左右,去壳后用75%的乙醇浸泡1分钟,倒掉75%乙醇后用30%安替福民溶液消毒30分钟,用无菌水洗6次,用灭菌纱布吸干水分后将种子种到含2,4d(2mg/l)的nb培养基上26℃避光培养2周。将诱导出的愈伤组织切下,放入新的含2,4d(2mg/l)的nb培养基上,26℃培养7天。挑取状态较好的愈伤组织,于备好的农杆菌菌液中浸泡8min,期间不时摇晃。吸出或倒掉菌液,将愈伤组织用无菌滤纸吸干,接种于共培养中(含100μm乙酰丁香酮)28℃暗培养72h。取出愈伤组织,转入含有25mg/l潮霉素的筛选培养基上培养,2周后转入含有50mg/l潮霉素的筛选培养基上继续筛选。2周后将愈伤转入预分化培养基上培养1周后,再转入分化培养基光照培养,分化成苗后将小苗用1/2ms培养基生根壮苗获得t0代植株,移入田间种植。
取t0代植株叶片提取dna,根据sd1基因的序列设计引物扩增,对pcr产物进行测序,确定靶序列发生突变的植株,所用引物序列为:
sd1-f5(seqidno.4):gggtcattgattcgaccatc
sd1-r3(seqidno.5):gtgctcggacacctggaagaac。
突变植株sd1测序图如图1所示。
将t0代检测到有突变的植株收种,然后种植t1代。采集t1代植株的叶片提取dna,用引物sd1-f5和sd1-r3扩增测序,确定靶序列突变类型为纯合突变或杂合突变;同时根据潮霉素基因序列设计引物,检测潮霉素基因序列的存在,以此确定外源t-dna片段是否存在。选择靶序列突变为纯合突变同时潮霉素检测为阴性的植株进行收种。所用的潮霉素基因检测引物序列为:
hptf(seqidno.11):cgttatgtttatcggcactttg
hptr(seqidno.12):ttggcgacctcgtattgg。
图2是潮霉素基因pcr检测电泳图。其中“m”是dl2000分子标记,“+”是质粒阳性对照,1-6是选取的部分t1代转基因株系。
表1是水稻野生型与sd1基因敲除突变植株的主茎高度记录表,图3是水稻野生型与sd1基因敲除突变植株的主茎高度对比图。
从表1和附图3可以看出,水稻突变体主茎明显缩短。
本发明通过本发明根据crispr/cas9的设计原则,在水稻sd1基因编码区确定crispr/cas9系统编辑的靶位点,根据靶位点的序列设计引物,构建crispr/cas9载体,用农杆菌介导的方法转化水稻愈伤组织,通过筛选鉴定,最后获得sd1突变的不含转基因dna片段的矮杆水稻品系。该方法应用于矮杆水稻品种的选育,可以免去杂交选育的工作,大大缩短矮杆品种选育的周期。
sequencelisting
<110>上海市农业科学院
<120>使用crispr/cas9技术靶向敲除水稻矮杆基因sd1的方法
<130>
<160>12
<170>patentinversion3.3
<210>1
<211>19
<212>dna
<213>sd1基因编码区108-127核酸序列
<400>1
aggatggagcccaagatcc19
<210>2
<211>25
<212>dna
<213>人工序列
<400>2
tgtgtgaggatggagcccaagatcc25
<210>3
<211>25
<212>dna
<213>人工序列
<400>3
aaacggatcttgggctccatcctca25
<210>4
<211>20
<212>dna
<213>人工序列
<400>4
gggtcattgattcgaccatc20
<210>5
<211>22
<212>dna
<213>人工序列
<400>5
gtgctcggacacctggaagaac22
<210>6
<211>1170
<212>dna
<213>水稻sd1基因编码区
<400>6
atggtggccgagcaccccacgccaccacagccgcaccaaccaccgcccatggactccacc60
gccggctctggcattgccgccccggcggcggcggcggtgtgcgacctgaggatggagccc120
aagatcccggagccattcgtgtggccgaacggcgacgcgaggccggcgtcggcggcggag180
ctggacatgcccgtggtcgacgtgggcgtgctccgcgacggcgacgccgaggggctgcgc240
cgcgccgcggcgcaggtggccgccgcgtgcgccacgcacgggttcttccaggtgtccgag300
cacggcgtcgacgccgctctggcgcgcgccgcgctcgacggcgccagcgacttcttccgc360
ctcccgctcgccgagaagcgccgcgcgcgccgcgtcccgggcaccgtgtccggctacacc420
agcgcccacgccgaccgcttcgcctccaagctcccatggaaggagaccctctccttcggc480
ttccacgaccgcgccgccgcccccgtcgtcgccgactacttctccagcaccctcggcccc540
gacttcgcgccaatggggagggtgtaccagaagtactgcgaggagatgaaggagctgtcg600
ctgacgatcatggaactcctggagctgagcctgggcgtggagcgaggctactacagggag660
ttcttcgcggacagcagctcaatcatgcggtgcaactactacccgccatgcccggagccg720
gagcggacgctcggcacgggcccgcactgcgaccccaccgccctcaccatcctcctccag780
gacgacgtcggcggcctcgaggtcctcgtcgacggcgaatggcgccccgtcagccccgtc840
cccggcgccatggtcatcaacatcggcgacaccttcatggcgctgtcgaacgggaggtat900
aagagctgcctgcacagggcggtggtgaaccagcggcgggagcggcggtcgctggcgttc960
ttcctgtgcccgcgggaggacagggtggtgcggccgccgccgagcgccgccacgccgcag1020
cactacccggacttcacctgggccgacctcatgcgcttcacgcagcgccactaccgcgcc1080
gacacccgcacgctcgacgccttcacgcgctggctcgcgccgccggccgccgacgccgcc1140
gcgacggcgcaggtcgaggcggccagctga1170
<210>7
<211>1145
<212>dna
<213>申繁17突变植株sd1基因突变序列
<400>7
atggtggccgagcaccccacgccaccacagccgcaccaaccaccgcccatggactccacc60
gccggctctggcattgccgccccggcggcggcggcggtgtgcgacctgaggatggatggc120
cgaacggcgacgcgaggccggcgtcggcggcggagctggacatgcccgtggtcgacgtgg180
gcgtgctccgcgacggcgacgccgaggggctgcgccgcgccgcggcgcaggtggccgccg240
cgtgcgccacgcacgggttcttccaggtgtccgagcacggcgtcgacgccgctctggcgc300
gcgccgcgctcgacggcgccagcgacttcttccgcctcccgctcgccgagaagcgccgcg360
cgcgccgcgtcccgggcaccgtgtccggctacaccagcgcccacgccgaccgcttcgcct420
ccaagctcccatggaaggagaccctctccttcggcttccacgaccgcgccgccgcccccg480
tcgtcgccgactacttctccagcaccctcggccccgacttcgcgccaatggggagggtgt540
accagaagtactgcgaggagatgaaggagctgtcgctgacgatcatggaactcctggagc600
tgagcctgggcgtggagcgaggctactacagggagttcttcgcggacagcagctcaatca660
tgcggtgcaactactacccgccatgcccggagccggagcggacgctcggcacgggcccgc720
actgcgaccccaccgccctcaccatcctcctccaggacgacgtcggcggcctcgaggtcc780
tcgtcgacggcgaatggcgccccgtcagccccgtccccggcgccatggtcatcaacatcg840
gcgacaccttcatggcgctgtcgaacgggaggtataagagctgcctgcacagggcggtgg900
tgaaccagcggcgggagcggcggtcgctggcgttcttcctgtgcccgcgggaggacaggg960
tggtgcggccgccgccgagcgccgccacgccgcagcactacccggacttcacctgggccg1020
acctcatgcgcttcacgcagcgccactaccgcgccgacacccgcacgctcgacgccttca1080
cgcgctggctcgcgccgccggccgccgacgccgccgcgacggcgcaggtcgaggcggcca1140
gctga1145
<210>8
<211>1171
<212>dna
<213>申繁24突变植株sd1基因突变序列
<400>8
atggtggccgagcaccccacgccaccacagccgcaccaaccaccgcccatggactccacc60
gccggctctggcattgccgccccggcggcggcggcggtgtgcgacctgaggatggagccc120
aagaatcccggagccattcgtgtggccgaacggcgacgcgaggccggcgtcggcggcgga180
gctggacatgcccgtggtcgacgtgggcgtgctccgcgacggcgacgccgaggggctgcg240
ccgcgccgcggcgcaggtggccgccgcgtgcgccacgcacgggttcttccaggtgtccga300
gcacggcgtcgacgccgctctggcgcgcgccgcgctcgacggcgccagcgacttcttccg360
cctcccgctcgccgagaagcgccgcgcgcgccgcgtcccgggcaccgtgtccggctacac420
cagcgcccacgccgaccgcttcgcctccaagctcccatggaaggagaccctctccttcgg480
cttccacgaccgcgccgccgcccccgtcgtcgccgactacttctccagcaccctcggccc540
cgacttcgcgccaatggggagggtgtaccagaagtactgcgaggagatgaaggagctgtc600
gctgacgatcatggaactcctggagctgagcctgggcgtggagcgaggctactacaggga660
gttcttcgcggacagcagctcaatcatgcggtgcaactactacccgccatgcccggagcc720
ggagcggacgctcggcacgggcccgcactgcgaccccaccgccctcaccatcctcctcca780
ggacgacgtcggcggcctcgaggtcctcgtcgacggcgaatggcgccccgtcagccccgt840
ccccggcgccatggtcatcaacatcggcgacaccttcatggcgctgtcgaacgggaggta900
taagagctgcctgcacagggcggtggtgaaccagcggcgggagcggcggtcgctggcgtt960
cttcctgtgcccgcgggaggacagggtggtgcggccgccgccgagcgccgccacgccgca1020
gcactacccggacttcacctgggccgacctcatgcgcttcacgcagcgccactaccgcgc1080
cgacacccgcacgctcgacgccttcacgcgctggctcgcgccgccggccgccgacgccgc1140
cgcgacggcgcaggtcgaggcggccagctga1171
<210>9
<211>1171
<212>dna
<213>申9b突变植株sd1基因突变序列
<400>9
atggtggccgagcaccccacgccaccacagccgcaccaaccaccgcccatggactccacc60
gccggctctggcattgccgccccggcggcggcggcggtgtgcgacctgaggatggagccc120
aagaatcccggagccattcgtgtggccgaacggcgacgcgaggccggcgtcggcggcgga180
gctggacatgcccgtggtcgacgtgggcgtgctccgcgacggcgacgccgaggggctgcg240
ccgcgccgcggcgcaggtggccgccgcgtgcgccacgcacgggttcttccaggtgtccga300
gcacggcgtcgacgccgctctggcgcgcgccgcgctcgacggcgccagcgacttcttccg360
cctcccgctcgccgagaagcgccgcgcgcgccgcgtcccgggcaccgtgtccggctacac420
cagcgcccacgccgaccgcttcgcctccaagctcccatggaaggagaccctctccttcgg480
cttccacgaccgcgccgccgcccccgtcgtcgccgactacttctccagcaccctcggccc540
cgacttcgcgccaatggggagggtgtaccagaagtactgcgaggagatgaaggagctgtc600
gctgacgatcatggaactcctggagctgagcctgggcgtggagcgaggctactacaggga660
gttcttcgcggacagcagctcaatcatgcggtgcaactactacccgccatgcccggagcc720
ggagcggacgctcggcacgggcccgcactgcgaccccaccgccctcaccatcctcctcca780
ggacgacgtcggcggcctcgaggtcctcgtcgacggcgaatggcgccccgtcagccccgt840
ccccggcgccatggtcatcaacatcggcgacaccttcatggcgctgtcgaacgggaggta900
taagagctgcctgcacagggcggtggtgaaccagcggcgggagcggcggtcgctggcgtt960
cttcctgtgcccgcgggaggacagggtggtgcggccgccgccgagcgccgccacgccgca1020
gcactacccggacttcacctgggccgacctcatgcgcttcacgcagcgccactaccgcgc1080
cgacacccgcacgctcgacgccttcacgcgctggctcgcgccgccggccgccgacgccgc1140
cgcgacggcgcaggtcgaggcggccagctga1171
<210>10
<211>1168
<212>dna
<213>申武1b突变植株sd1基因突变序列
<400>10
atggtggccgagcaccccacgccaccacagccgcaccaaccaccgcccatggactccacc60
gccggctctggcattgccgccccggcggcggcggcggtgtgcgacctgaggatggagccc120
aatcccggagccattcgtgtggccgaacggcgacgcgaggccggcgtcggcggcggagct180
ggacatgcccgtggtcgacgtgggcgtgctccgcgacggcgacgccgaggggctgcgccg240
cgccgcggcgcaggtggccgccgcgtgcgccacgcacgggttcttccaggtgtccgagca300
cggcgtcgacgccgctctggcgcgcgccgcgctcgacggcgccagcgacttcttccgcct360
cccgctcgccgagaagcgccgcgcgcgccgcgtcccgggcaccgtgtccggctacaccag420
cgcccacgccgaccgcttcgcctccaagctcccatggaaggagaccctctccttcggctt480
ccacgaccgcgccgccgcccccgtcgtcgccgactacttctccagcaccctcggccccga540
cttcgcgccaatggggagggtgtaccagaagtactgcgaggagatgaaggagctgtcgct600
gacgatcatggaactcctggagctgagcctgggcgtggagcgaggctactacagggagtt660
cttcgcggacagcagctcaatcatgcggtgcaactactacccgccatgcccggagccgga720
gcggacgctcggcacgggcccgcactgcgaccccaccgccctcaccatcctcctccagga780
cgacgtcggcggcctcgaggtcctcgtcgacggcgaatggcgccccgtcagccccgtccc840
cggcgccatggtcatcaacatcggcgacaccttcatggcgctgtcgaacgggaggtataa900
gagctgcctgcacagggcggtggtgaaccagcggcgggagcggcggtcgctggcgttctt960
cctgtgcccgcgggaggacagggtggtgcggccgccgccgagcgccgccacgccgcagca1020
ctacccggacttcacctgggccgacctcatgcgcttcacgcagcgccactaccgcgccga1080
cacccgcacgctcgacgccttcacgcgctggctcgcgccgccggccgccgacgccgccgc1140
gacggcgcaggtcgaggcggccagctga1168
<210>11
<211>22
<212>dna
<213>人工序列
<400>11
cgttatgtttatcggcactttg22
<210>12
<211>18
<212>dna
<213>人工序列
<400>12
ttggcgacctcgtattgg18
- 还没有人留言评论。精彩留言会获得点赞!
- 靶向B细胞受体复合物膜结合IgM的抗体及其用途的制作方法与工艺
- 一种肿瘤靶向细胞药物载体及其应用的制作方法与工艺
- 具有肿瘤细胞靶向性的超细磁性核壳纳米材料及其制备和应用的制作方法与工艺
- 具有肿瘤细胞靶向性的超细磁性核壳纳米材料及其制备和应用的制作方法与工艺
- 一种检测癌细胞内铜离子的癌细胞靶向荧光探针的制作方法与工艺
- 一种利用细胞通透性差异治疗皮肤癌的靶向药物的制作方法与工艺
- 一种基于细胞源性微囊泡的肿瘤靶向递送载体及制备方法和应用与流程
- 靶向CLDN6的免疫效应细胞及其制备方法和应用与流程
- 一种检测靶向CD33的CART细胞中CAR表达的荧光定量试剂盒的制作方法与工艺
- 靶向HBV核心启动子的抗HBV药物筛选细胞模型及其构建和应用的制作方法与工艺
- 具有肿瘤细胞靶向性的超细磁性核壳纳米材料及其制备和应用的制作方法与工艺
- 具有肿瘤细胞靶向性的超细磁性核壳纳米材料及其制备和应用的制作方法与工艺
- 一种利用细胞通透性差异治疗皮肤癌的靶向药物的制作方法与工艺
- 一种基于细胞源性微囊泡的肿瘤靶向递送载体及制备方法和应用与流程
- 靶向CLDN6的免疫效应细胞及其制备方法和应用与流程
- 一种检测靶向CD33的CART细胞中CAR表达的荧光定量试剂盒的制作方法与工艺
- 靶向HBV核心启动子的抗HBV药物筛选细胞模型及其构建和应用的制作方法与工艺
- 一种响应过氧化氢杀灭肿瘤细胞的光敏感靶向抗肿瘤前药及其制备方法与应用与流程
- 靶向循环肿瘤细胞的长循环纳米粒及其制备和应用的制作方法与工艺
- 使用CRISPR/Cas9技术靶向敲除水稻矮杆基因SD1的方法与流程