一种基因碱基编辑器的制作方法
本发明涉及一种基因碱基编辑器。
背景技术:
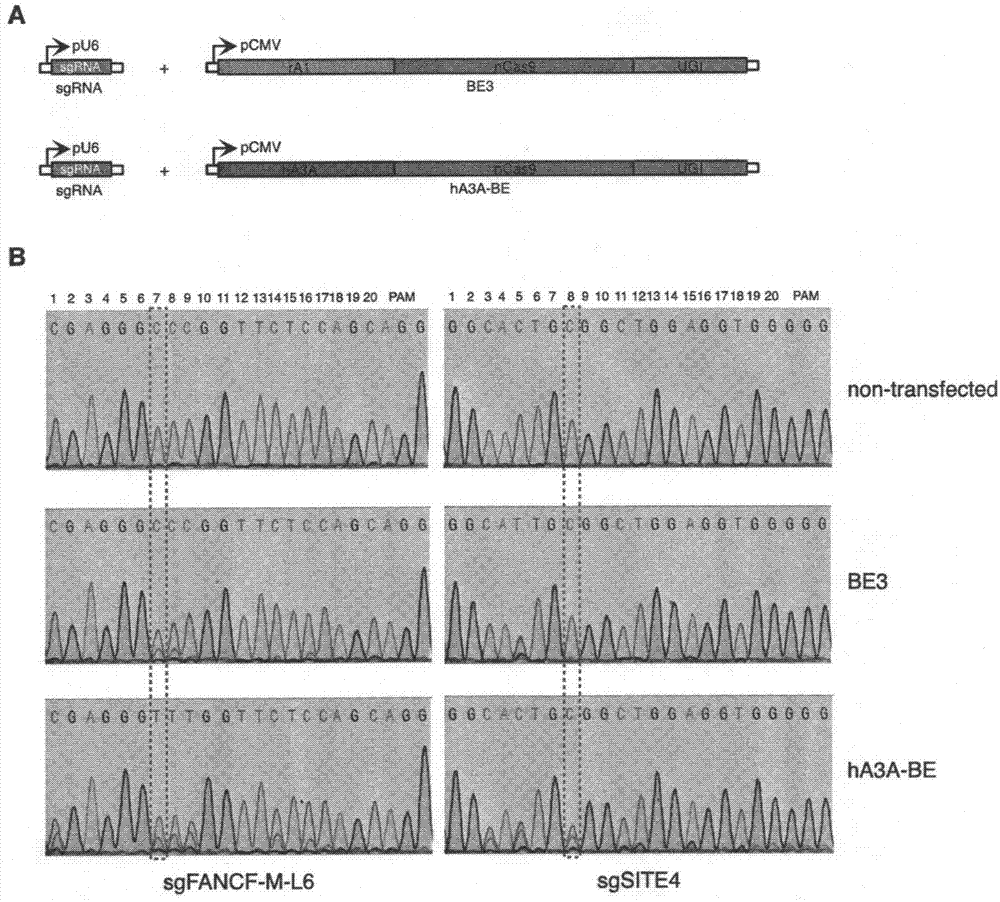
基因组编辑技术指利用可设计的核酸酶(分子剪刀)通过碱基插入、缺失或置换等方式,对生物体基因组dna特定片段进行改造从而达到对目标基因进行编辑的一种基因工程技术。利用基因组编辑技术对细胞进行遗传学操纵,可广泛的应用于生命科学基础研究、生物技术开发、农业技术开发以及医药研发领域。例如:直接在体内校正引起遗传疾病的基因突变,将能够从根本上治疗遗传疾病;对农作物进行精确的基因工程改造,使其产量提高或能够抵抗环境污染或病原体的感染;对微生物基因组进行精准改造,从而促进可再生生物能源的开发等。crispr/cas(clusteredregularlyinterspacedshortpalindromicrepeats/crispr-associatedprotein)基因组编辑系统自问世以来,就有着其它基因组编辑技术无可比拟的优势,被认为能够在活细胞中广泛使用,并且是迄今为止最有效、最便捷的基因组编辑系统。cas核酸酶利用引导rna(guiderna,grna)可在多种细胞的基因组特定靶点定位,对其进行切割从而产生dna双链断裂(doublestrandbreaks,dsbs),然后利用细胞内源的dna修复机制来实现编辑。根据不同dna修复通路的激活,基因组编辑将会导致基因的失活或者突变的校正。通常来说,有两种主要的修复机制会被dsb所激活,一种是非同源末端连接(non-homologousendjoining,nhej),另一种是同源性介导修复(homology-directedrepair,hdr)。作为dna双链断裂最主要的修复通路,nhej在修复过程中能在dsb附近的基因组位点引入随机性碱基插入或缺失,从而导致基因的失活。与nhej相反,当hdr被激活时能够以外源性供体dna作为模版,利用同源重组机制将外源性供体dna的序列替换靶点基因组dna的序列,从而完成基因突变的校正。但实际上,由于同源重组机制本身的局限性,hdr介导的基因校正效率一直很低(通常小于5%)。因此,极大限制了crispr/cas基因组编辑工具从科研向应用的转化,尤其是在精准基因治疗方面的应用,这也是基因编辑领域的一大难题。为了提高基因突变的校正效率,碱基编辑器(baseeditor,be)在近期内应运而生。现有的碱基编辑器将crispr/cas系统和大鼠胞嘧啶脱氨酶1(ratapobec1,ra1)整合在一起,可执行将胞嘧啶(cytosine,c)编辑为胸腺嘧啶(thymine,t)的功能。然而,基于ra1的碱基编辑器无法有效编辑gpc位点中的碱基c,从而限制了现有碱基编辑器的有效编辑位点。例如,gpt至gpc的突变可导致rna剪接位点的缺失,从而引发多种人类疾病;而现有的基于ra1的碱基编辑器则无法有效的矫正gpt至gpc的突变。因此,创造能够在gpc位点进行高效碱基编辑的新型碱基编辑器,有助于在各物种基因组更为广泛的位点实现高效的碱基编辑,并极大地扩充我们对于碱基编辑器的应用,特别是在医疗领域对相关疾病进行精准基因治疗方面。技术实现要素:本发明公开了一系列新型碱基编辑器(融合蛋白)和相应的新的基因碱基编辑方法。该发明显示,通过将人胞嘧啶脱氨酶3a(humanapobec3a,ha3a)与crispr/cas系统融合,能够在crispr/cas系统的靶标位点高效地将胞嘧啶(c)脱氨基成尿嘧啶(u),从而导致基因组中特定位点上c到t的突变。当融合蛋白中同时融合了尿嘧啶糖基化酶抑制剂(ugi)时,该系列碱基编辑器的编辑效率能够进一步提高。惊喜的是,即使是在gpc二核苷酸的背景下,该系列编辑器仍然能够实现高精度、高效率的定向碱基编辑。特别值得注意的是,该系列编辑器也能够在甲基化的胞嘧啶(methylatedc)上进行高效率的编辑,由于胞嘧啶甲基化在活细胞中普遍而常见,所以该系列编辑器在甲基化胞嘧啶上的高编辑效率无疑具有显著的临床意义。相应地,在本发明公开的实施例中,本发明公开了一种碱基编辑器,其包含有两个片段,第一片段包含载脂蛋白b人胞嘧啶脱氨酶3a(humanapobec3a,ha3a),第二片段包含crispr/cas系统相关蛋白。在其他的一些实施例中,融合蛋白还将进一步包含尿嘧啶糖基化酶抑制剂(ugi)。该系列基因碱基编辑器的大小分别不超过3000,2500,2200,2100,2000,1900,1800,1700,1600,或1500个氨基酸。在一些实施例中,该系列基因碱基编辑器的apobec3a部分包含来自于seqidno:1的氨基酸序列,或者与seqidno:1的氨基酸残基的29-199位具有至少90%的序列同一性并保留胞苷脱氨酶活性。在一些实施例中,该系列基因碱基编辑器的apobec3a部分包含选自seqidno:1-10的氨基酸序列。在一些实施例中,该系列基因碱基编辑器的cas蛋白部分来自于以下组群spcas9,fncas9,st1cas9,st3cas9,nmcas9,sacas9,ascpff1,lbcpff1,fncpff1,vqrspcas9,eqrspcas9,vrerspcas9,rhafncas9,以及kkhsacas9;在一些实施例中,该系列基因碱基编辑器的cas蛋白部分是上述cas蛋白组群(spcas9,fncas9,st1cas9,st3cas9,nmcas9,sacas9,ascpff1,lbcpf1,fncpf1,vqrspcas9,eqrspcas9,vrerspcas9,rhafncas9,以及kkhsacas9)中某些蛋白的突变体,其保留了这些cas蛋白的dna结合活性,但完全丧失了dna剪切活性;在一些实施例中,该系列基因碱基编辑器的cas蛋白部分是上述cas蛋白组群(spcas9,fncas9,st1cas9,st3cas9,nmcas9,sacas9,ascpff1,lbcpff1,fncpff1,vqrspcas9,eqrspcas9,vrerspcas9,rhafncas9,以及kkhsacas9)中某些蛋白的突变体,其保留了这些cas蛋白的dna结合活性,但丧失了部分dna剪切活性(即只能切割基因组双链dna中的一条链);在一些实施例中,该系列基因碱基编辑器的cas蛋白部分包含如seqidno:11所示的氨基酸序列。在一些实施例中,该系列基因碱基编辑器的ugi部分包含如seqidno:12所示的氨基酸序列,或者与seqidno:12列出的氨基酸序列具有至少90%的序列抑制同一性并保留尿嘧啶糖基化酶活性的功能。在一些实施例中,第一片段位于第二片段的n端侧;在一些实施例中,第一片段位于第二片段的n端侧,第二片段位于ugi片段的n端侧。在一些实施例中,该系列基因碱基编辑器(融合蛋白)在第一片段与第二片段之间进一步包含长短不一的连接肽;在一些实施例中,该连接肽具有1至100个氨基酸残基;在一些实施例中,该连接肽的氨基酸残基序列中至少有10%,20%,30%,40%,50%,60%,70%,80%或90%是选自以下的氨基酸残基:丙氨酸,甘氨酸,半胱氨酸和丝氨酸;在一些实施例中,该连接肽具有如seqidno:13或14所示的氨基酸序列;在一些实施例中,该系列基因碱基编辑器(融合蛋白)还进一步包含核定位序列。该系列碱基编辑器(融合蛋白)的实施实例包括但不限于如seqidno:16-20所示的那些氨基酸序列。该发明同时提供了现公开实施例中所用碱基编辑器的编码核苷酸序列;在另一个实施例中,其提供的组合序列除包含了现公开实施例中所用碱基编辑器的编码核苷酸序列外,还包含了一个在药学意义上已被广泛承认和接受的承载载体;在某些实施例中,该组合还进一步包含一个引导rna(guiderna)的序列。该发明还同时提供了使用该系列碱基编辑器(融合蛋白)和其相关组合物的方法。在该发明揭示的一个实施例中,其通过利用一种包含在该申请书中的碱基编辑器(融合蛋白)以及相应的引导rna(guiderna)将该碱基编辑器靶向定位到与guiderna至少有部分序列互补性的基因组序列上,从而在目标位点有效地催化进行了胞嘧啶(c)脱氨基反应;在一些实施例中,胞嘧啶(c)处于gpc二核苷酸背景中;在一些实施例中,胞嘧啶(c)被甲基化;在一些实施方案中,该碱基编辑器的靶向定位接触是体外,离体或体内的。附图说明图1:ha3a-be在gpc的碱基c位点实现高效碱基编辑图1a:共表达sgrna与ha3a-be的方法示意图;图1b:相对于共表达sgrna与be3,共表达sgrna与ha3a-be的方法在实施例1(sgfancf-m-l6)、2(sgsite4)的sgrna靶点序列中gpc位点处实现了高效的c-to-t碱基编辑。数字1-20代表sgrna靶点序列中碱基的位置,non-transfected代表未转染样品。图2:ha3a-be-y130f与ha3a-be-y132d缩小了碱基编辑窗口图2a:共表达sgrna/ha3a-be-y130f或sgrna/ha3a-be-y132d的方法示意图;图2b:相对于共表达sgrna/ha3a-be,共表达sgrna/ha3a-be-y130f或sgrna/ha3a-be-y132d的方法在实施例3(sgsite3)、4(sgemx1)中缩小了碱基编辑窗口,从而实现了更为精确的碱基编辑。数字1-20代表sgrna靶点序列中碱基的位置,non-transfected代表未转染样品。图3:ha3a-be-w104a与ha3a-be-d131y增强了碱基编辑效率图3a:共表达sgrna/ha3a-be-w104a或sgrna/ha3a-be-d131y的方法示意图;图3b:相对于共表达sgrna/ha3a-be,共表达sgrna/ha3a-be-w104a或sgrna/ha3a-be-d131y的方法在实施例5(sgfancf)、6(sgsite2)中增强了碱基编辑效率,从而实现了更为高效的碱基编辑。数字1-20代表sgrna靶点序列中碱基的位置,non-transfected代表未转染样品。具体实施方式下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。需要注意的是,该发明中的术语“一”或“一个”实体是指一个或多个该实体;例如“一种抗体”应被理解为表示一种或多种抗体。因此,术语“一”(或“一个”),“一个或多个”和“至少一个”在本文中可互换使用。本文中所用术语“多肽”旨在涵盖单数“多肽”以及复数“多肽”,并且是指由通过酰胺键线性连接的单体(氨基酸)组成的分子(也称为肽键)。术语“多肽”是指两个或更多个氨基酸组成的的任何链或多个链,并且不涉及产物的特定长度。因此,“多肽”的定义中包括肽,二肽,三肽,寡肽,“蛋白质”,“氨基酸链”或用于表示两个或更多个氨基酸的链的任何其他术语,并且术语“多肽”可以用来代替这些术语中的任何一个,术语“多肽”还意指多肽的表达后修饰的产物,包括但不限于糖基化,乙酰化,磷酸化,酰胺化,通过已知的保护/封闭基团衍生化,蛋白水解切割或非天然修饰发生的氨基酸。多肽可以来自天然生物来源或通过重组技术产生,但不一定从指定的核酸序列翻译而来。它可能以任何方式产生,包括通过化学合成。本文中关于细胞、多肽或核酸(例如dna或rna)所使用的术语“分离的”是指分别与存在于大分子的天然来源中的其他dna或rna分离的分子。本文所用的术语“分离的”还指当相应核酸或多肽分子通过重组技术产生时,其基本上不含来源于细胞、病毒或培养基的物质;还指当相应核酸或多肽分子通过化学合成技术产生时,其基本上不含来源于化学前体的物质或其他化学物质。此外,“分离的核酸”还意欲包括那些在天然状态下不以片段形式存在的核酸分子,这些“分离的核酸”在天然状态下不会单独存在。术语“分离的”在本文中也以于指被从其他细胞、蛋白质或组织分离的细胞或多肽,同时分离的多肽也意味着包括纯化的和重组的多肽。本文中涉及多肽或多核苷酸时所用术语“重组”意指相关多肽或多核苷酸的形式在天然状态下不存在,其实施实例包括但不限于可通过组合相关多核苷酸或多肽得到的多核苷酸或多肽,而这些组合方式在天然状态下通常不会自动发生。“同源性”或“同一性”或“相似性”是指两个肽之间或两个核酸分子之间的序列相似性。同源性可以通过比对不同多肽或核酸分子中的相对应位置来确定,当被比较分子序列中的同一位置在不同序列中被相同的碱基或氨基酸占据时,那么该分子在该位置是同源的。序列之间的同源程度由序列共有的匹配或同源位置的数目的函数决定。“不相关的”或“非同源的”序列与本发明所公开的序列之一的同源性应小于40%,但在优选条件下,该同源性应小于25%。多核苷酸或多核苷酸区域(或多肽或多肽区域)与另一多核苷酸酸或多核苷酸区域(或多肽或多肽区域)具有一定百分比的序列同源性(例如,60%,65%,70%,75%,80%,85%,90%,95%,98%或99%)是指比对时,被比对的两个序列中有该百分比的碱基(或氨基酸)是相同的。该比对和百分比同源性或序列同一性可以使用本领域已知的软件程序和方法来确定,例如像ausubeletal.eds.(2007)currentprotocolsinmolecularbiology中描述的那样。优选地,序列比对时应使用默认参数。其中一个备选的对齐程序是blast,使用默认参数。特别地,当使用程序blastn和blastp进行比对时,使用以下默认参数:geneticcode=standard;filter=none;strand=both;cutoff=60;expect=10;matrix=blosum62;descriptions=50sequences;sortby=highscore;databases=non-redundant.genbank+embl+ddbj+pdb+genbankcdstranslations+swissprotein+spupdate+pir。在生物学意义上被认为是等价的多核苷酸是指具有上述限定百分比同源性并编码具有相同或相似生物学活性的多肽的那些多核苷酸。本文中所用术语“等价核酸或多核苷酸”是指具有与该发明公开的多核苷酸或与其互补的核苷酸序列具有一定程度同源性或序列同一性的多核苷酸。双链核酸的同源物意图同时包括与编码链或互补非编码链具有一定同源性的多核苷酸。在一个方面,核酸的同系物能够与核酸或其互补物杂交。类似地,“等价多肽”是指与该发明中公开的参考多肽的氨基酸序列有至少约70%,75%,80%,85%,90%,95%,98%或99%同源性或序列同一性的多肽。在某些情况下,与该发明中公开的参考多肽或多核苷酸相比,等价多肽或多核苷酸具有1,2,3,4或5个添加、缺失、取代或它们的组合;在某些情况下,等价序列保留与该发明中公开的参考序列相同或相似的活性(例如,表位结合)或结构(例如盐桥)。杂交反应可以在不同的“严格性”条件下进行。通常,在约40℃下、约10×ssc或具有等同离子强度/温度的溶液中进行低严格杂交反应;在约50℃下、约6×ssc中进行中度严格杂交;在约60℃、约1×ssc中进行高度严格杂交反应。杂交反应也可以在本领域技术人员所熟知的“生理条件”下进行。“生理条件”包括但不限于通常在细胞或生物体内中存在的温度、离子强度、ph和mg2+浓度。当多核苷酸为dna时,该多核苷酸的序列由以下四个核苷酸碱基的代表字母组成:腺嘌呤(a);胞嘧啶(c);鸟嘌呤(g);胸腺嘧啶(t)。当多核苷酸为rna时,该多核苷酸的序列由以下四个核苷酸碱基的代表字母组成:腺嘌呤(a);胞嘧啶(c);鸟嘌呤(g);尿嘧啶(u)。因此,术语“多核苷酸序列”是多核苷酸分子的字母表示。该字母表示可以输入到具有中央处理单元的计算机中的数据库中,并用于生物信息学应用,例如功能基因组学和同源性搜索。术语“多态性”是指多于一种形式的基因或其部分的共存,“基因的多态性区域”是指基因在同一位置有不同的核苷酸表现形式(即不同的核苷酸序列)。基因多态性区域可以是单核苷酸,其在不同的等位基因中是不同的。在本发明中,术语“多核苷酸”和“寡核苷酸”可互换使用,并且它们是指任何长度的核苷酸的聚合形式,无论是脱氧核糖核苷酸还是核糖核苷酸或其类似物。多核苷酸可以具有任何三维结构并且可以执行已知或未知的任何功能。多核苷酸的实例包括但不限于如下这些:基因或基因片段(包括探针,引物,est或sage标签),外显子,内含子,信使rna(mrna),转运rna,核糖体rna,核酶,cdna,dsrna,sirna,mirna,重组多核苷酸,分支多核苷酸,质粒,载体,任何序列的分离的dna,任何序列的分离的rna,核酸探针和引物。多核苷酸也包含经过修饰的核苷酸,例如甲基化的核苷酸和核苷酸类似物。如果多核苷酸上存在修饰,该修饰可以在组装多核苷酸之前或之后赋予。核苷酸序列可以被非核苷酸组分打断。多核苷酸可以在聚合后被进一步修饰,例如通过偶联被标记组分所标记。该术语同时指双链和单链多核苷酸分子。除非另有说明或要求,否则本发明公开的多核苷酸的任何实施方案包括其双链形式和已知或预测能构成双链形式的两条互补单链形式中的任一种。当将其应用于多核苷酸时,术语“编码”是指多核苷酸“编码”多肽,意即在其天然状态下或当通过本领域技术人员公知的方法操作时,其可以通过转录和/或翻译以产生目的多肽和/或其片段,或产生能够编码该目的多肽和/或其片段的mrna。反义链是指与该多核苷酸互补的序列,并且可以从中推导出编码序列。融合蛋白当前基于ra1的be(碱基编辑器)无法有效编辑在gpc背景中的c,这限制了该碱基编辑器的使用。本发明公开了一系列新型碱基编辑器(融合蛋白)和相应的新的基因碱基编辑方法。该发明显示,通过将人胞嘧啶脱氨酶3a(humanapobec3a,ha3a)与crispr/cas系统融合,能够在crispr/cas系统的靶标位点高效地将胞嘧啶(c)脱氨基成尿嘧啶(u),从而导致基因组中特定位点上c到t的突变。当融合蛋白中同时融合了尿嘧啶糖基化酶抑制剂(ugi)时,该系列碱基编辑器的编辑效率能够进一步提高。惊喜的是,即使是在gpc二核苷酸的背景下,该系列编辑器仍然能够实现高精度、高效率的定向碱基编辑。特别值得注意的是,该系列编辑器也能够在甲基化的胞嘧啶(methylatedc)上进行高效率的编辑,由于胞嘧啶甲基化在活细胞中普遍而常见,所以该系列编辑器在甲基化胞嘧啶上的高编辑效率无疑具有显著的临床意义。相应地,在本发明公开的实施例中,本发明公开了一种碱基编辑器,其包含有两个片段,第一片段包含载脂蛋白b人胞嘧啶脱氨酶3a(humanapobec3a,ha3a),第二片段包含crispr/cas系统相关蛋白。在其他的一些实施例中,融合蛋白还将进一步包含尿嘧啶糖基化酶抑制剂(ugi)。apobec3a,也被称为载脂蛋白bmrna编辑酶催化亚基3a或a3a,是在人,非人灵长类动物和一些其他哺乳动物中都存在的apobec3家族成员中的一种。apobec3a蛋白缺乏其他家族成员的锌结合活性。人的apobec3a有两种isoform,isoforma(np_663745.1;seqidno:1)和isoformb(np_001257335.1;seqidno:6)都具有脱氨基活性;相比于isoformb,isoforma在靠近n-末端处包含更多的残基。术语“apobec3a”还包括与野生型哺乳动物apobec3a具有一定水平(例如70%,75%,80%,85%,90%,95%,98%,99%)序列同一性的变体和突变体,这些变体和突变体都具有胞苷脱氨活性。如实施例1所示,某些突变体(例如y130f(seqidno:2),y132d(seqidno:3),w104a(seqidno:4)和d131y(seqidno:5))甚至优于野生型人apobec3a。下表1中提供了这些变体和突变体的实例序列。表1.apobec3a及其变体、突变体的序列apobec3a蛋白也可以在其他氨基酸位置进行进一步的修饰,例如添加,缺失和/或取代。这样的修饰可以是在一个,两个或三个或更多个氨基酸位置上进行的取代替换。在一个实施例中,修饰是在一个位置处的替换。在一些实施例中,这样的替换是保守氨基酸取代。“保守氨基酸取代”是指氨基酸残基被其他具有相似侧链的氨基酸残基取代的情况。具有相似侧链的氨基酸残基家族在本领域内已有公认的定义,包括碱性侧链(例如赖氨酸,精氨酸,组氨酸),酸性侧链(例如天冬氨酸,谷氨酸),不带电荷的极性侧链(例如,甘氨酸,天冬酰胺,谷氨酰胺,丝氨酸,苏氨酸,酪氨酸,半胱氨酸),非极性侧链(例如丙氨酸,缬氨酸,亮氨酸,异亮氨酸,脯氨酸,苯丙氨酸,甲硫氨酸,色氨酸)异亮氨酸)和芳族侧链(例如酪氨酸,苯丙氨酸,色氨酸,组氨酸)家族。因此,该发明公开的融合蛋白中的非关键氨基酸残基可以被来自相同侧链家族的另一氨基酸残基取代置换。在另一个实施例中,一串氨基酸可以通过保守氨基酸取代的方法被另外一串结构相似的氨基酸代替,后者的侧链家族成员的顺序和/或组成和前者不同。保守型氨基酸取代包括但不限于下表中所列,下表中的数字表示两个氨基酸之间的相似度,当数字大于等于0时认为是保守氨基酸取代。表a.氨基酸相似度矩阵cgpsatdenqhkrvmilfyww-8-7-6-2-6-5-7-7-4-5-3-32-6-4-5-20017y0-5-5-3-3-3-4-4-2-40-4-5-2-2-1-1710f-4-5-5-3-4-3-6-5-4-5-2-5-4-10129l-6-4-3-3-2-2-4-3-3-2-2-3-32426i-2-3-2-1-10-2-2-2-2-2-2-2425m-5-3-2-2-1-1-3-20-1-20026v-2-1-1-100-2-2-2-2-2-2-24r-4-300-2-1-1-101236k-5-2-10-10001105h-3-20-1-1-111236q-5-10-10-12214n-40-1100212e-50-100034d-51-10004t-200113a-21112s0111p-3-16g-35c12表b.保守氨基酸替代品术语“crispr/cas9”或简称“cas”是指在化脓链球菌streptococcuspyogenes中,或其他细菌中发现的与其基于crispr(成簇规则间隔短回文重复序列)的获得性免疫系统相关的一系列rna引导的dna内切核酸酶。cas蛋白包括但不限于化脓性链球菌cas9(spcas9),金黄色葡萄球菌cas9(sacas9),酸性氨基酸球菌cas12a(cpf1),lachnospiraceae细菌cas12a(cpf1),新凶手弗朗西斯氏菌cas12a(cpf1)。在komor等人2017年1月12日发表于cell杂志168(1-2):20-36的文章“用于真核基因组操作的基于crispr的技术”中还提供了关于cas蛋白另外实例。在一些实施例中,该系列基因碱基编辑器的cas蛋白部分来自于以下组群spcas9,fncas9,st1cas9,st3cas9,nmcas9,sacas9,ascpf1,lbcpf1,fncpf1,vqrspcas9,eqrspcas9,vrerspcas9,rhafncas9,以及kkhsacas9;在一些实施例中,该系列基因碱基编辑器的cas蛋白部分是上述cas蛋白组群(spcas9,fncas9,st1cas9,st3cas9,nmcas9,sacas9,ascpf1,lbcpf1,fncpf1,vqrspcas9,eqrspcas9,vrerspcas9,rhafncas9,以及kkhsacas9)中某些蛋白的突变体,其保留了这些cas蛋白的dna结合活性,但没有dna剪切活性,或不能够同时切割双链dna的两条链。例如,以往的研究已经发现,spcas9蛋白中的asp10和his840氨基酸对于其dna剪切活性十分关键。当两个氨基酸均被突变为丙氨酸时,突变体蛋白完全丧失dna剪切活性;当asp10被突变为丙氨酸时,突变体蛋白丧失部分dna剪切活性,不能够同时切割双链dna的两条链从而引入dna双链断裂,而只能切割其中一条链从而引入dna缺刻。这样的cas蛋白突变体又被称为casnickase。cas9nickase的序列包括但不限于seqidno:11中所列。在一些实施例中,该系列基因碱基编辑器(融合蛋白)还进一步包含尿嘧啶糖基化酶抑制剂(ugi),其序列包括但不限于bacillusphagear9(yp_009283008.1)中所示。在一些实施例中,其ugi部分包含如seqidno:12所示的氨基酸序列,或者其序列与seqidno:12列出的氨基酸序列具有至少90%的序列同一性并保有尿嘧啶糖基化酶的活性。在一些实施例中,该系列基因碱基编辑器(融合蛋白)在第一片段与第二片段之间进一步包含长短不一的连接肽;在一些实施例中,该连接肽具有1至100个氨基酸残基;在一些实施例中,该连接肽的氨基酸残基序列中至少有10%,20%,30%,40%,50%,60%,70%,80%或90%是选自以下的氨基酸残基:丙氨酸,甘氨酸,半胱氨酸和丝氨酸;在一些实施例中,该连接肽具有如seqidno:13或14所示的氨基酸序列。在一些实施例中,apobec3a,cas蛋白和ugi可以以任何方式排列。然而,在一个优选的实施方案中,apobec3a被置于cas蛋白的n端侧,当融合蛋白包含ugi时,cas蛋白优选被置于ugi的n端侧。在一些实施例中,该系列基因碱基编辑器(融合蛋白)还进一步包含核定位序列。表2.其他序列本发明还提供了在本发明中公开的碱基编辑器(融合蛋白)或其突变体或衍生物的分离的多核苷酸或核酸分子(例如,seqidno:21)。制备融合蛋白的方法在本领域中是公知的并在此描述。组成与方法本发明同时提供了碱基编辑器组合物的组成与使用方法。这种组合物包或有效量的融合蛋白和可接受的载体。在一些实施例中,组合物还包含与目标dna具有互补性的指导rna。这样的组合可以用于样本中靶标序列的碱基编辑。融合蛋白及其组合物可以用于碱基编辑。在一个实施例中,提供了用于编辑靶标多核苷酸的方法:利用与靶标多核苷酸具有至少部分序列互补性的指导rna来将本发明公开的碱基编辑器(融合蛋白)和与靶多核苷酸接触,其中所述编辑包括胞嘧啶脱氨基(c)在靶多核苷酸中。目前数据表明融合蛋白可以对任意位置,任意环境的胞嘧啶发生编辑,例如cpc,apc,gpc,tpc,cpa,cpg,cpc,cpt等等。意外之喜的是我们发现融合蛋白可以编辑gpc二核苷酸位点的胞嘧啶和甲基化位点的胞嘧啶。融合蛋白(包括引导rna)与其所靶向的多核苷酸的接触可以是体外的,在细胞中尤其如此。本发明中的融合蛋白在临床治疗中可以发挥重要作用,无论是在间接体外治疗或者体内治疗。实施例实施例1:碱基编辑器构建pcmv-ha3a-be的表达质粒。人源载脂蛋白b信使rna脱氨酶催化亚基3a(apobec3a,ha3a;seqidno:1)与cas9切口酶以及一个尿嘧啶dna糖苷酶抑制剂[芽孢杆菌噬菌体](seqidno:12)融合在一个表达载体上。cas9切口酶的第10位天冬氨酸突变为丙氨酸,由此失去切割双链的活性并保证在一条链上产生一个切口。融合表达载体ha3a-ncas9-ugi(ha3a-be,seqidno:21)与单链引导rna的表达载体共转入真核细胞中(图1,图例a),在基因组的引导rna靶向的位点发生c-t的碱基编辑。pcr扩增基因组dna靶位置的序列,并通过sangerdna测序来检测靶位点c-t的碱基编辑效率。相对于共表达sgrna与be3,共表达sgrna与ha3a-be的方法在实施例1(sgfancf-m-l6)、2(sgsite4)的sgrna靶点序列中gpc位点处实现了高效的c-to-t碱基编辑(图1,图例b,虚线框)。然后,y130f(seqidno:2)和y132d(seqidno:3)突变分别引入到原始的ha3a序列中,构建得到ha3a-be-y130f和ha3a-be-y132d碱基编辑器(图2,图例a)。相对于共表达sgrna/ha3a-be,共表达sgrna/ha3a-be-y130f或sgrna/ha3a-be-y132d的方法在实施例3(sgsite3)、4(sgemx1)中缩小了碱基编辑窗口,从而实现了更为精确的碱基编辑(图2,图例b)。此外,w104a和d131y两种突变分别引入到原始ha3a序列中,构建得到ha3a-be-w104a和ha3a-be-d131y碱基编辑器(图3,图例a)。相对于共表达sgrna/ha3a-be,共表达sgrna/ha3a-be-w104a或sgrna/ha3a-be-d131y的方法在实施例5(sgfancf)、6(sgsite2)中增强了碱基编辑效率,从而实现了更为高效的碱基编辑(图3,图例b)。***目前的信息公开并不局限于所描述的用于说明本发明单一方面特性的特定的实施例中,任何功能相同的组分和方法都在这一公开范围之内。对于技术娴熟的人来说,他们可以在目前的组成成分和方法上做任意的修饰和改变,但不能背离所公开信息的精神和范围。因此现在的公开包含修饰和改变,但前提是这些修饰和改变要在附加权利要求及其等价物范围之内。本规范中所提到的所有出版物和专利申请都是在此基础上进行合并的,每一个单独的出版物或专利申请都是具体的并且个别地指明要被引用的。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1