一种以RHBDD1为靶点的抗肿瘤药物筛选模型及其方法与流程
本发明涉及肿瘤药物筛选领域,具体涉及一种以rhbdd1为靶点的抗肿瘤药物筛选模型及方法。
背景技术:
肿瘤极大威胁人类健康,抗肿瘤药物研究是当今生命科学中极富挑战性且具有重大意义的领域。随着对肿瘤致病机制的深入研究,细胞内的信号通路变化过程正被逐步阐明,以信号通路为药物筛选靶点发现高效、低毒、特异性强的新型靶向药物已成为当今抗肿瘤药物研究的有效途径之一。针对不同的疾病以及靶点已报道了许多不同的筛选方案并对肿瘤的研究起到一定的作用:对于肝脏微粒体,报道有一种新型的多层微粒体的装置可以进行药物筛选[1];以二肽酶dpp4为靶点的抑制剂的高通量筛选的药物已进入临床试验期[2];通过电流的刺激对癫痫病人化合物的筛选[3];以及通过表型进行的药物筛选方法等[4],均是在探索肿瘤药物过程中通过不同肿瘤以及特异性靶点进行的药物筛选。
结直肠癌是世界上常见的恶性肿瘤之一,死亡率居恶性肿瘤的第三位,并有逐年增高的趋势[5]。rhomboid家族蛋白质是一类存在于所有物种中高度保守的跨膜丝氨酸蛋白酶,其具有一个保守的rhomboid结构域[6],rhbdd1是本研究组在前期精子发生过程中发现的rhomboid家族新成员,其在睾丸组织中高表达并与精原细胞的凋亡密切相关[7,8]。研究表明rhbdd1的失活可以抑制结直肠癌肿瘤细胞的生长,进一步的研究显示rhbdd1与protgfα相互作用并诱导adam非依赖性剪切并促进protgfα分泌,分泌的protgfα进一步激活下游egfr/raf/mek/erk信号通路,并在结肠炎诱导的结肠癌动物模型中证实;rhbdd1也可通过wnt/β-连环蛋白(β-catenin)信号通路影响结直肠癌的发生发展,暗示rhbdd1在结直肠癌的肿瘤预后中可以作为一个分子标志物,是一个潜在的药物靶点[9,10,11]。另外,rhbdd1可以通过akt途径调控cdk2而影响细胞周期,进一步影响乳腺癌的发生发展。这些研究均表明rhbdd1在肿瘤预后中可以作为一个分子标志物,是一个潜在的药物靶点。探索rhbdd1成为结直肠癌新的分子标志物及药物靶标具有重要的意义,进而对癌症的靶向治疗提供重要线索。
因此我们拟构建以rhbdd1为靶点的药物筛选平台,进行基于rbdd1为靶点的抗肿瘤药物的筛选,为临床治疗癌症提供依据。
技术实现要素:
基于上述目的,在第一方面,本发明提供了一种以rhbdd1为靶点的抗肿瘤药物筛选模型,其包括rhbdd1蛋白或其截短体蛋白、荧光标记的底物短肽、脂质体转染试剂以及模型缓冲液。
在一个具体的实施方案中,rhbdd1的截短体蛋白的序列如seqidno:1、seqidno:2或seqidno:3所示。
在一个具体的实施方案中,荧光标记的底物短肽为荧光标记的keren短肽,所述keren短肽的序列如seqidno:4所示。
在一个具体的实施方案中,脂质体转染试剂为invitrogentmlipofectaminetm3000。
在一个具体的实施方案中,模型缓冲液为含有20mm的hepes和150mm的nacl的水溶液。
在第二方面,本发明提供了一种建立以rhbdd1为靶点的抗肿瘤药物筛选模型的方法,其包括:a)加入rhbdd1蛋白或其截短体蛋白、荧光标记的底物短肽、脂质体转染试剂以及模型缓冲液,并混匀;b)加入待测药物;c)避光反应2~4小时;d)测量荧光值变化。
在一个具体的实施方案中,在步骤a)中,加入0.4-1.2μg的rhbdd1蛋白或其截短体蛋白、0.5-3.5μm的荧光标记的底物短肽以及1-3μl的脂质体转染试剂,补充模型缓冲液中至20-80μl,并混匀。
在一个具体的实施方案中,在步骤b)中,每20-80μl的筛选模型中,加入2~300μm待测药物。
在一个具体的实施方案中,rhbdd1的截短体蛋白的序列如seqidno:1、seqidno:2或seqidno:3所示。
在一个具体的实施方案中,荧光标记的底物短肽为荧光标记的keren短肽,所述keren短肽的序列如seqidno:4所示。
在一个具体的实施方案中,脂质体转染试剂为invitrogentmlipofectaminetm3000。
在一个具体的实施方案中,模型缓冲液为含有20mm的hepes和150mm的nacl的水溶液。
在一个优选的实施方案中,在步骤a)中,加入0.8μg的序列如seqidno:1、seqidno:2或seqidno:3所示的rhbdd1的截短体蛋白、2μm的荧光标记的keren短肽以及2μl的invitrogentmlipofectaminetm3000,补充模型缓冲液中至50μl,并混匀。
在第三方面,本发明提供了一种用于建立以rhbdd1为靶点的抗肿瘤药物筛选模型的rhbdd1截短体蛋白,其序列如seqidno:1、seqidno:2或seqidno:3所示。
在第四方面,本发明提供了一种编码上述的rhbdd1的截短体蛋白的核苷酸序列。
在第五方面,本发明提供了上述rhbdd1截短体蛋白在制备用于筛选以rhbdd1为靶点的抗肿瘤药物的模型中的用途。
在第六方面,本发明提供了通过上述的以rhbdd1为靶点的抗肿瘤药物筛选模型,筛选抗肿瘤药物的方法,其包括:a)待测药物加入到已构建的以rhbdd1为靶点的抗肿瘤药物筛选模型中;b)在37℃避光反应2~4小时;c)测量在485/528nm的荧光值变化。
在具体的实施方案中,与未加入待测药物的对照相比较,加入待测药物荧光值不显著升高,指示该待测药物可能具有抗肿瘤性质。
在第七方面,本发明提供了一种筛选rhbdd1抑制剂的模型,其包括rhbdd1蛋白或其截短体蛋白、荧光标记的底物短肽、脂质体转染试剂以及模型缓冲液。以及提供了一种筛选rhbdd1抑制剂的方法,其包括:a)加入rhbdd1蛋白或其截短体蛋白、荧光标记的底物短肽、脂质体转染试剂以及模型缓冲液,并混匀;b)加入待测试剂;c)避光反应2~4小时;d)测量荧光值变化。
在一个具体的实施方案中,rhbdd1的截短体蛋白的序列如seqidno:1、seqidno:2或seqidno:3所示。
在一个具体的实施方案中,荧光标记的底物短肽为荧光标记的keren短肽,所述keren短肽的序列如seqidno:4所示。
在一个具体的实施方案中,脂质体转染试剂为invitrogentmlipofectaminetm3000。
在一个具体的实施方案中,模型缓冲液为含有20mm的hepes和150mm的nacl的水溶液。
在上述方面中,所述肿瘤是可以以rhbdd1为靶点进行治疗的肿瘤,例如所述肿瘤选自结直肠癌和乳腺癌。
附图说明
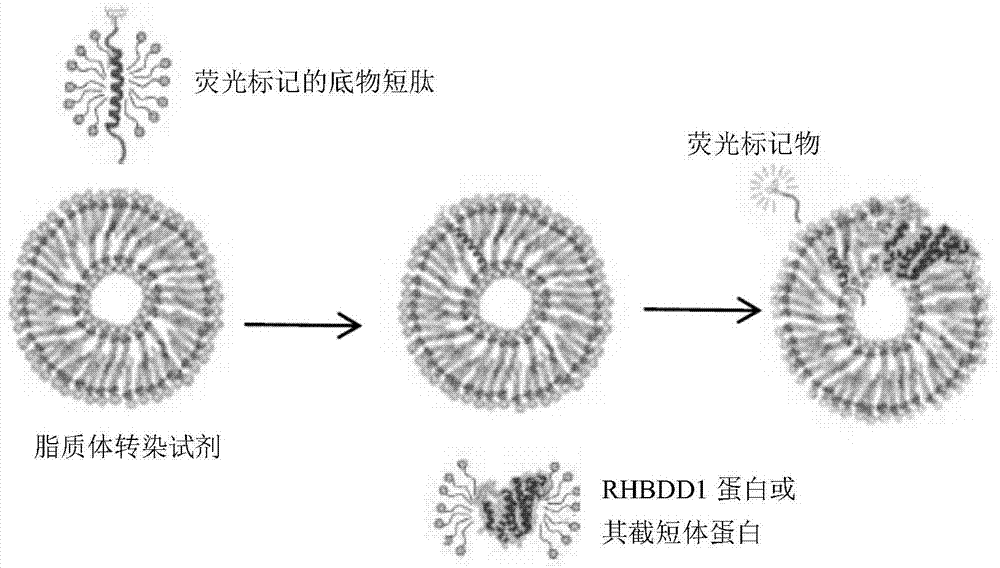
图1:本发明的以rhbdd1为靶点的抗肿瘤药物筛选模型的反应系统示意图。荧光标记的底物短肽本身发光,将荧光标记的底物短肽整合入脂质体后使其荧光淬灭,当加入rhbdd1蛋白或其截短体蛋白后,荧光标记的底物短肽被切割,荧光释放。
图2:不同的rhbdd1截短体蛋白的表达情况。构建于表达质粒pcdna3.1(-)并带有strep标签的rhbdd1-207、rhbdd1-237、rhbdd1-247在293t细胞中可以表达。
图3:底物keren的选择。构建rhomboid家族的四种通用底物(spitz、keren、gurken、tata)的表达质粒并与rhbdd1共转染于293t细胞,检测四种底物被rhbdd1切割情况,其中keren被明显切割,如图中箭头所示,切割条带被鉴定。因此确定keren为rhbdd1切割底物。
图4:不同的rhbdd1截短体蛋白rhbdd1-207、rhbdd1-237、rhbdd1-247可以切割底物,荧光值发生变化(升高),将rhbdd1突变失活后的δrhbdd1不可以切割底物,荧光并未升高。
图5:在本发明的以rhbdd1为靶点的抗肿瘤药物筛选模型中加入丝氨酸蛋白酶抑制剂dci后,rhbdd1截短体蛋白的切割活性被抑制,证明本发明的以rhbdd1为靶点的抗肿瘤药物筛选模型建立了以rhbdd1为靶点的抗肿瘤药物筛选平台。
具体实施方式
通过体外培养hek293f细胞进行表达、纯化膜蛋白rhbdd1蛋白截短体,得到rhbdd1截短体蛋白。进一步发现了rhbdd1在体内、外均可进行切割的底物keren,体内证明rhbdd1截短体蛋白具有切割活性以后,在体外构建了keren短肽,并在其n端加入fitc荧光基团,以此来验证rhbdd1靶向分子的活性。在脂质体存在的情况下,在体系中加入纯化后的rhbdd1截短体蛋白和底物keren短肽,在脂质体存在时,fitc标记的keren短肽被包裹,不发荧光,当加入rhbdd1截短体蛋白时,rhbdd1可以切割底物keren短肽,使得fitc荧光释放,从而验证rhbdd1截短体蛋白对底物keren短肽进行了切割。加入dci(3,4-二氯异香豆素)丝氨酸蛋白酶抑制剂等rhbdd1靶向分子,抑制rhbdd1截短体蛋白的切割活性后,切割底物的效果被抑制。因此,可以通过此模型,进行以rhbdd1为靶点的小分子或者多肽的筛选,从而获得以rhbdd1为靶点的抗肿瘤潜在药物(参见图1)。
实施例1:以rhbdd1为靶点的抗肿瘤药物筛选模型的构建
一、rhbdd1截短体蛋白的制备
1.缓冲液及培养基配制
(1)lb培养基的配制
分别称取酵母粉5g、胰蛋白胨10g和nacl10g,并用蒸馏水补齐至1l,高压灭菌锅灭菌,121℃,30分钟。其中固体培养基配方是在液体培养基配方基础上,加入琼脂粉15g,使用高压灭菌锅灭菌处理,121℃,15分钟,待培养基降温至60-70℃,在超净台中加入一定比例的抗生素,冷却后,倒立放置于4℃冰箱。
(2)抗生素配制
本实施例中主要用到的抗生素为氨苄抗生素和卡那抗生素,其中氨苄是在培养大肠杆菌提质粒过程中使用,氨苄霉素储液浓度为80mg/ml,使用过程中稀释1000倍进行使用。
(3)dna电泳试剂
a.核酸琼脂糖凝胶
使用锥形瓶,在锥形瓶瓶颈缠上隔热材料。称取1g琼脂糖并加入100ml1×tae缓冲液,使用微波炉加热充分,需要沸腾两次,充分摇匀后,使用自来水沿锥形瓶壁降温,约50-70℃左右时,按照1:1000比例加入染色剂goldenview染料,并倒胶和插梳子,一般放置20-30分钟后便可使用,保存时,将凝胶放入dna胶电泳缓冲液中保存。
b.dna胶电泳缓冲液
分别称取tris242g、na2edta·2h2o37.2g和冰醋酸57.1ml,并加入超纯水,补至1l。此为50×的凝胶电泳储液,使用时用水稀释50倍。
(4)蛋白胶相关试剂
a.1×sds电泳缓冲液(runningbuffer)
分别称取3.03gtris、14.4g甘氨酸以及1gsds粉末,加水补到1l体积。
b.蛋白上样缓冲液
以配制10ml蛋白上样缓冲液为例,分别称取sds0.8g,溴酚蓝0.04g,甘油4ml,tris-hcl0.3g,放置于常温保存,建议500μl每管,使用前加入每管加入20μl的β-巯基乙醇。
c.考马斯亮蓝r-250染色液
以配制1l为例,称取考马斯亮蓝r-2501g,无水乙醇300ml,冰醋酸100ml,可以使用自来水定容至1l,使用转子充分混匀后,放置室温保存。
d.考马斯亮蓝脱色液
以配制1l为例,分别加入无水乙醇300ml,冰醋酸100ml,可以使用自来水定容至1l,充分混匀后,放置室温保存。
(5)westernblot(wb)实验相关试剂盒缓冲液
a.转膜液
转膜液一般要提前半个小时左右预冷。分别称取tris3.03g、甲醇150ml、甘氨酸14.1g,并加入蒸馏水定容至1l。
b.洗膜缓冲液1×tbst
分别称取3.03gtris-hcl,8.78gnacl,1ml吐温-20(tween-20),加水定容至1l。
c.封闭液
称取2.5g脱脂奶粉溶于50ml1×tbst缓冲液,终浓度为5%脱脂奶粉。
(6)strep-tagii亲和柱缓冲液
分别称量2.5ghepes、8.7gnacl,加水至950ml,调节ph值到7.4左右,并加入二硫苏糖醇(dl-dithiothreitol,dtt),使dtt终浓度为2mm,加水定容至1l。
(7)蛋白纯化以及筛选缓冲液
在前期纯化的rhbdd1蛋白的缓冲液成分为:溶于水中的20mmhepes、150mmnacl,ph7.4。
2.基因克隆与蛋白纯化方法
2.1.相关基因及载体的获取
在本实施例中使用的编码rhbdd1蛋白的基因模板为本实验室保存,所用的pcdna3.1(-)空载体为清华大学杨茂君实验室馈赠。
rhbdd1蛋白基因序列(geneid:84236,seqidno:5):
atgcaacggagatcaagagggataaatactggacttattctactcctttctcaaatcttccatgttgggatcaacaatattccacctgtcaccctagcaactttggccctcaacatctggttcttcttgaaccctcagaagccactgtatagctcctgccttagtgtggagaagtgttaccagcaaaaagactggcagcgtttactgctctctccccttcaccatgctgatgattggcatttgtatttcaatatggcatccatgctctggaaaggaataaatctagaaagaagactgggaagtagatggtttgcctatgttatcaccgcattttctgtacttactggagtggtatacctgctcttgcaatttgctgttgccgaatttatggatgaacctgacttcaaaaggagctgtgctgtaggtttctcaggagttttgtttgctttgaaagttcttaacaaccattattgccctggaggctttgtcaacattttgggctttcctgtaccgaacagatttgcttgttgggtcgaacttgtggctattcatttattctcaccagggacttccttcgctgggcatctggctgggattcttgttggactaatgtacactcaagggcctctgaagaaaatcatggaagcatgtgcaggcggtttttcctccagtgttggttacccaggacggcaatactactttaatagttcaggcagctctggatatcaggattattatccgcatggcaggccagatcactatgaagaagcacccaggaactatgacacgtacacagcaggactgagtgaagaagaacagctcgagagagcattacaagccagcctctgggaccgaggaaataccagaaatagcccaccaccctacgggtttcatctctcaccagaagaaatgaggagacagcggcttcacagattcgatagccagtga
2.2.相关载体的构建
关于rhbdd1各截短体蛋白的引物设计如下:
rhbdd1-207:
正向引物(seqidno:7):
tggatatctgcagaattcgccaccatgtggagccac
反向引物(seqidno:8):
attcctcgacgcggccgctcattgagtgtacattagtccacc
rhbdd1-237:
正向引物(seqidno:9):
tggatatctgcagaattcgccaccatgtggagccac
反向引物(seqidno:10):
attcctcgacgcggccgctcatgaactattaaagtagtattg
rhbdd1-247:
正向引物(seqidno:11):
tggatatctgcagaattcgccaccatgtggagccac
反向引物(seqidno:12):
attcctcgacgcggccgctcacggataataatcctgatatcc
δrhbdd1蛋白(将rhbdd1蛋白的144位s突变为a)的基因模板由本实验之前构建并保存,其基因序列为(seqidno:6):
atgcaacggagatcaagagggataaatactggacttattctactcctttctcaaatcttccatgttgggatcaacaatattccacctgtcaccctagcaactttggccctcaacatctggttcttcttgaaccctcagaagccactgtatagctcctgccttagtgtggagaagtgttaccagcaaaaagactggcagcgtttactgctctctccccttcaccatgctgatgattggcatttgtatttcaatatggcatccatgctctggaaaggaataaatctagaaagaagactgggaagtagatggtttgcctatgttatcaccgcattttctgtacttactggagtggtatacctgctcttgcaatttgctgttgccgaatttatggatgaacctgacttcaaaaggagctgtgctgtaggtttcgcaggagttttgtttgctttgaaagttcttaacaaccattattgccctggaggctttgtcaacattttgggctttcctgtaccgaacagatttgcttgttgggtcgaacttgtggctattcatttattctcaccagggacttccttcgctgggcatctggctgggattcttgttggactaatgtacactcaagggcctctgaagaaaatcatggaagcatgtgcaggcggtttttcctccagtgttggttacccaggacggcaatactactttaatagttcaggcagctctggatatcaggattattatccgcatggcaggccagatcactatgaagaagcacccaggaactatgacacgtacacagcaggactgagtgaagaagaacagctcgagagagcattacaagccagcctctgggaccgaggaaataccagaaatagcccaccaccctacgggtttcatctctcaccagaagaaatgaggagacagcggcttcacagattcgatagccagtga
本实施例中使用的是全式金公司的pcr聚合酶,50μl配制体系如下:分别加入5×pcr缓冲液10μl、2mmdntp5μl、模板cdna2μl、上游引物2μl、下游引物2μl、酶1μl、无菌水28μl。
pcr反应条件如下:
预变性:98℃5分钟;变性:98℃30秒;退火:58℃30秒;延伸:72℃60秒;之后进行34个循环;之后延伸:72℃5分钟。
pcr完成之后的产物,加入6×dna加样缓冲液10μl,并进行dna胶电泳,分离出正确的dna凝胶条带,并进行切胶回收,使用商业化的快速凝胶回收试剂盒回收。
酶切反应条件如下:
pcr之后的片段酶切:分别加入片段40μl、ecor1酶2μl、kpn1酶2μl、酶切缓冲液5μl,使用37℃酶切3个小时。
载体酶切:分别加入1500ng的未切载体、ecor1酶2μl、kpn1酶2μl、酶切缓冲液5μl,无菌水补至40μl,在37℃下进行酶切3-5个小时。
对酶切之后的片段和载体进行琼脂糖凝胶电泳后分别进行凝胶回收。
后续使用t4连接酶对片段和载体进行回收,分别加入片段15μl、载体2μl、t4连接酶1μl、t4缓冲液2μl。然后置于16℃连接2小时,之后使用dh5α感受态进行转化实验,涂板,并过夜置于37℃培养箱放置。
第二天早上,在超净台中进行挑点,将单菌落置于ep管中培养,加入200μl含有抗生素的培养基,使用37℃摇床,220rpm培养3-5小时,待菌液浑浊时,使用taq酶进行菌液pcr,如果菌液pcr正确,则进行送测序。
2.3.大量提取质粒以及转染试剂pei(聚酰醚亚胺)的配制
由于使用瞬时转染技术,需要大量的质粒和转染试剂pei来满足后续的蛋白纯化工作。
质粒大量提取:将上一步通过基因克隆得到的插入各rhbdd1截短体蛋白及rhbdd1突变体的质粒,转化至dh5α感受态细胞中,并通过37℃恒温培养箱,过夜培养12小时左右,在超净台中挑取单菌落,加入到50mllb小瓶中,并维持氨苄抗生素浓度为80μg/l,过夜培养,220rpm,并转接至4llb大瓶培养基中,继续培养6小时左右,收集菌体,并使用康为世纪质粒大提试剂盒提取质粒。
pei配制:本实施例中使用购自polysciences的pei固体粉末,使用精密天平称取50mgpei,加入到干净的50ml离心管中,加入双蒸水至45ml,密封离心管,并置于85℃水浴锅,加热水浴20分钟,可以发现pei固体粉末溶解,之后,取出离心管,并冷却至室温,使用ph计调节ph至7.2,用双蒸水定容至50ml,在超净台中使用0.22μm滤膜过滤分装,之后冻存于-20℃冰箱。再次使用的时候,如果有pei固体析出,可将pei溶液置于65℃水浴锅,水浴加热5分钟,冷却至常温后,可继续使用。
2.4.hek293f的细胞培养
在本实施例中使用的hek293f细胞来自清华大学杨茂君实验室馈赠。细胞在初期培养过程中,涉及到哺乳动物细胞的冻存和复苏。hek293f细胞是人源胚胎肾脏细胞驯化而来,而且此细胞系极少表达胞外配体所需的内生配体,易转染,易操作,是最常用的外源表达体系。
hek293f细胞复苏:从液氮中取出冻存的hek293f细胞,并置于37℃水浴锅中,大约1-2分钟左右,细胞便可溶解,立即转移至超净台中,溶解的细胞加入10ml左右细胞培养基(293ti培养基,购于义翘神州),重悬细胞,并使用离心机,600g,离心5分钟后,弃去上清,再加入10ml培养基,进行第二次重悬和离心。最后,使用25ml左右培养基重悬后,并加入青链霉素双抗,置于二氧化碳培养箱中培养。
hek293f细胞冻存:在本实施例中,对培养代数较少的细胞,以及生长状态较好的细胞,一般需要对细胞进行冻存操作。收集生长状态好的细胞,密度约为1.5-2.5×106个细胞/毫升,取100ml左右于离心管中,使用离心机600g,离心5分钟后,弃去上清,使用冻存缓冲液(10%dmso、40%fbs和50%培养基)重悬,分装至冻存管中,并置于冻存盒中,放于-80℃冰箱过夜,第二天将冻存的细胞转移至液氮罐中保存。
hek293f细胞传代:哺乳动物细胞在培养过程中,需要加入青链霉素,来抑制革兰氏阳性/阴性菌的污染。刚开始培养的时候,使用细胞小瓶进行培养,对于hek293f悬浮细胞,一般生长周期为24小时,待细胞密度增长至2-3×106个细胞/ml时,将小瓶传代至大瓶中,并稀释至浓度约为0.5×106个细胞/ml,理论上,细胞培养时,浓度不要过高,超过4×106个细胞/ml,细胞生长状态就会变差,产生聚集现象;传代浓度不要太稀,不要低于0.3-0.5×106个细胞/ml。浓度过低细胞不太容易生长起来。
2.5.哺乳动物细胞瞬时转染以及转染条件优化
瞬时转染技术(transienttransfection)是一种简单、快捷、高效的哺乳动物表达方法,是将外源dna导入到真核细胞的一种方式,pei作为阳离子型的脂质体可以包裹住带负电荷的质粒dna,并通过胞吞过程进入细胞体内,从而获得目的基因的短暂但是高水平的表达。操作过程中,待转染的质粒不需要导入宿主染色体,可以在较短时间内获得转染蛋白。具有操作简单、周期短、表达效率高、安全高效、不需要筛选基因以及能在完整细胞株上进行操作等优点。
以转染500mlhek293f细胞为例:待细胞在对数生长期时(1.5-2.5×106个细胞/ml),在超净台中打开两个无菌离心管,分别各加入无抗生素的培养基25ml,其中一个离心管中加入0.5mg的质粒,另一个离心管中加入2mg的pei。并置于37℃烘箱中,静置孵育3-5分钟,之后在超净台中,将pei溶液缓慢逐滴加入到质粒缓冲液中,并充分混匀,之后37℃烘箱孵育20-30分钟,形成pei包裹质粒的脂质体,之后逐滴加入到对数生长期的细胞中。一般培养48小时后,即可完成转染过程。
此外,根据不同蛋白的转染条件不同,对不同的转染条件进行优化。
如转染时间(24小时、36小时、48小时、60小时)优化,分别设置四个时间梯度,到预期时间点时收集细胞,并进行westernblot实验检测。转染比例优化,在本实施例中使用的细胞:质粒:pei比例为1:1:4,在优化条件的过程中,分别设置了不同的混合比例,简单的来说,就是首先固定细胞和质粒的比例为1:1,然后筛选加入的pei最适比例。之后根据筛选出的pei比例,变化质粒的比例,并筛选出合适的质粒比例。最后结合转染时间筛选,最终的优化条件是细胞:质粒:pei=1:1:4,转染48小时后,收集细胞。
2.6.strep-tag标签蛋白纯化rhbdd1截短体蛋白
strep-tagii是一类含有八个氨基酸的亲和纯化蛋白标签,这类标签可以帮助更好的得到纯度较高的蛋白,特别是对于膜蛋白而言。
收集转染完成的细胞,一般以1l为提取单位,使用重悬缓冲液(20mmhepesph8.0,150mmnacl,1mmpmsf,2mmdtt)对hek293f细胞进行重悬,注意,蛋白纯化过程中一般置于4℃或者冰上温度。使用高压破碎仪,对重悬的细胞进行高压破碎两次,将得到的细胞破碎液,使用高速低温离心机,13000rpm,离心5分钟,除去细胞碎片,然后收集上清,并使用贝克曼公司的超高速离心进行离心,离心时使用70ti转子,41000rpm,离心1个小时。然后轻轻的弃去上清,将管子中的沉淀放置于冰上保存。使用胶头滴管以及缓冲液(25mmtrisph8.0,200mmnacl,2mmdtt),将管底沉底重悬起来,重悬后的悬浊液使用组织匀浆破碎仪,进行破碎处理。加入ddm去垢剂,终浓度为1%ddm,放置于四度摇床上,缓慢摇动,抽提2-3个小时。
抽提完成后,将抽提液使用超高速离心机,41000rpm,离心30分钟,留上清,并使用0.45μm滤膜过滤上清。
使用strep柱子缓冲液(20mmhepesph8.0,150mmnacl,2mmdtt)对亲和柱预平衡,一般2个柱体积左右。然后将蛋白上清重复挂柱子两次,之后使用清洗缓冲液(20mmhepesph8.0,150mmnacl)洗去杂蛋白;期间可使用考马斯亮蓝g250检测杂蛋白是否清洗干净,一般清洗体积为10个柱体积左右。最后使用洗脱缓冲液(20mmhepesph8.0,150mmnacl,5mm脱硫生物素,2mmdtt)对目的蛋白进行洗脱。收集蛋白后,使用millipo蛋白浓缩管进行浓缩,方便进行下一步实验操作。浓缩后蛋白浓度为0.2~0.4mg/ml,最终蛋白是溶于洗脱缓冲液(20mmhepesph8.0,150mmnacl,5mm脱硫生物素,2mmdtt)中待用。
值得注意的是,每次在使用完streptag亲和柱之后,都需要对柱子进行处理。步骤如下:
使用重生缓冲液(100mmtrisph8.0,100mmnacl,1mmedta,5mmhaba)冲洗亲合柱,一般冲洗5-10个柱体积;
使用亲和柱缓冲液(25mmtrisph7.8,150mmnacl,2mmdtt)冲洗亲合柱5-10个柱体积;
使用0.5mnaoh溶液,冲洗亲和柱,洗去残留的haba,一般冲洗5个柱体积;
使用双蒸水冲洗亲和柱,洗去naoh,一般冲洗5个柱体积;
使用亲和柱缓冲液(25mmtrisph7.8,150mmnacl,2mmdtt)冲洗亲合柱10-20个柱体积,并将亲和柱放于4℃冰箱保存。
2.7.sds-page和westernblot蛋白检测
sds-page:十二烷基硫酸钠聚丙烯酰胺凝胶电泳。制备的蛋白样品在sds作用下,蛋白质内部的氢键和疏水键全部打开,sds作为一种阴离子表面活性剂,能够结合蛋白表面并使蛋白质带负电,并且这种电荷数量远远超过了蛋白质分子原有的电荷量,进而掩盖了不同蛋白质之间本身的电荷差异,而此时,不同泳道的蛋白质分子迁移率主要决定于分子量大小。如果蛋白质分子量较大,分子迁移率也就较慢,在sds-page上位于泳道的上方。蛋白质样品一般都预先和蛋白加样缓冲液混合,并在100℃加热块中加热使蛋白样品充分变性,离心后,上样到sds-page胶上,使用180v电压大概电泳60-80分钟左右,之后使用染色液染色半个小时,再使用脱色液脱色1个小时,便可观察蛋白条带。
westernblot蛋白检测实验步骤如下:
(1)待检测样品通过sds-page进行电泳,一般使用预染蛋白标志物;
(2)电泳完成后,使用湿转膜仪将蛋白胶样品转移至pvdf膜上,时间大约1.5小时;
(3)转膜完成后,使用封闭液(pbst+5%脱脂牛奶)对pvdf膜进行封闭处理,一般30分钟左右;
(4)一抗:实验中使用的是鼠源strep-tag一抗,按照1:5000比例加入到封闭液中,室温孵育1个小时;
(5)洗膜:使用tbst溶液进行洗膜,分三次,每次5分钟左右;
(6)二抗:按照1:5000的比例加入山羊抗小鼠二抗,室温孵育1个小时;
(7)使用pbst溶液洗膜,分三次,每次5分钟左右;
(8)加入显影液,使用bio-rad机器进行曝光。
本实施例中构建了5种不同的rhbdd1截短体,其中rhbdd1-207、rhbdd1-237和rhbdd1-247在hek293f细胞中表达较好,因此后续实验中确定采用rhbdd1-207、rhbdd1-237和rhbdd1-247纯化后构建筛选模型。其中strep为标签抗体(参见图2)。
通过上述方法最终获得纯化的截短蛋白rhbdd1-207、rhbdd1-237、rhbdd1-247,以及先前构建的突变体δrhbdd1,用于后续实验,其氨基酸序列分别为:
rhbdd1-207(seqidno:1):
rhbdd1-237(seqidno:2):
rhbdd1-247(seqidno:3):
二、底物keren短肽的制备
因为rhomboid家族蛋白蛋白具有高度保守性,本发明人构建了rhomboid家族四个底物keren、spitz、gurken和tata并表达于293t细胞(北京协和医学院细胞资源中心)中,共转染rhbdd1后,wb验证rhbdd1对四个底物的切割效果,发现对keren切割效果最好,因此选择keren作为体外筛选的底物。
结果参见图3,分别在293t细胞中转染不同底物,并同时转染rhbdd1后通过wb检测切割效果,转染keren后切割效果明显,切割条带也显现。因此选择keren作为体外筛选底物。
底物keren短肽:保留keren蛋白跨膜区122~144位氨基酸之间的序列同时保留两端几个氨基酸序列上去合成短肽序列如下(seqidno:4):rnrvmlekasivsgatlallfmamccvvlylrheklq并且,将底物keren与fitc缀合,fitc-ahx合成过程是氨基酸的脱水缩合的过程,合成后由酰胺键连接,ahx为6-氨基己酸(aminocaproicacid),合成后获得:
fitc-ahx-rnrvmlekasivsgatlallfmamccvvlylrheklq-nh2,
其由北京中科亚光生物科技有限公司合成,采用蛋白纯化缓冲液(20mmhepesph8.0,150mmnacl)去溶解为50μm备用。
三、模型缓冲液的制备
模型缓冲液的具体配方:
20mmhepes,ph7.4,150mmnacl,溶于ddh2o。
以配置1l为例,称取4.766ghepes,8.766gnacl,加入约800mlddh2o后调节溶液ph至7.4,之后定容至1l。
四、脂质体
本实施例中使用的脂质体为invitrogentmlipofectaminetm3000。
在本实施例中所使用的实验材料与仪器见下表:
实施例2:不同rhbdd1蛋白对fitc标记的keren切割作用的验证
通过上述实施例1获得的rhbdd1截短体蛋白、fitc标记的keren、以及模型缓冲液,结合市售的脂质体invitrogentmlipofectaminetm3000可用于构建以rhbdd1为靶点的抗肿瘤药物筛选模型。
分别在黑色384孔板中的不同孔中加入对应的试剂(每组设置3个复孔):
在37℃避光反应2~4小时;synergyh1全功能微孔板检测仪测量在485/528nm的荧光值(相对荧光单位,rfu)变化。本实施例中所述数据均以平均值计标准差表示,所有的统计分析均采用prismversion5.0完成。
其中,对照组(null):未加入任何rhbdd1蛋白,但加入等体积的溶解rhbdd1蛋白的溶液。实验组分别加入突变体δrhbdd1蛋白、rhbdd1-207、rhbdd1-237、rhbdd1-247截短体蛋白。
实验结果(参见图4):null为对照,δrhbdd1荧光与对照组无明显差异,而rhbdd1不同截短体rhbdd1-207、rhbdd1-237、rhbdd1-247加入后荧光值显著升高。δrhbdd1荧光与对照组无明显差异,说明δrhbdd1对底物keren(krn)短肽没有切割作用,而rhbdd1不同截短体rhbdd1-207、rhbdd1-237、rhbdd1-247加入后荧光值升高明显,证明rhbdd1截短体对底物keren的有切割作用。
实施例3:以rhbdd1为靶点的抗肿瘤药物筛选模型的验证
本实施例采用的体系基本同实施例2,但额外加入dci,其浓度为20μm。在进行药物筛选时,待测药物加入的量可在2~300μm尝试,直到确定合适的浓读,可以从高浓度向低浓度摸索,一开始药物浓度可尝试200μm。
实验结果(参见图5):null为对照,δrhbdd1荧光与对照组无明显差异,rhbdd1-207+dci与对照组无明显差异,rhbdd1截短体蛋白rhbdd1-207加入后荧光值升高明显。
讨论:dci为丝氨酸蛋白酶抑制剂,rhbdd1属于丝氨酸蛋白酶,δrhbdd1为rhbdd1突变体,突变后rhbdd1失活,不能切割底物keren,导致荧光值未升高,与对照组(null)无明显差异,加入dci抑制剂,dci可以抑制rhbdd1的活性,当rhbdd1被抑制后不对底物发生切割,荧光不升高,只有当rhbdd1未突变有活性,并未有其对应的抑制剂对其抑制,其可发生对底物keren的切割。
参考文献:
1.wu,q.,etal.,developmentofanovelmulti-layermicrofluidicdevicetowardscharacterizationofdrugmetabolismandcytotoxicityfordrugscreening.chemcommun(camb);2014;50(21):2762-2764.
2.upadhyay,j.,etal.,combinedligand-basedandstructure-basedvirtualscreeningapproachforidentificationofnewdipeptidylpeptidase4inhibitors.currdrugdiscovtechnol.2018.doi:10.2174.
3.simonato,m.,etal.,findingabetterdrugforepilepsy:preclinicalscreeningstrategiesandexperimentaltrialdesign.epilepsia.2012.53(11):1860-1867.
4.enna,sj.,etal.,phenotypicdrugscreening.jperiphernervsyst.2014;2:s4-5.
5.mundade,r.,etal.,geneticpathways,prevention,andtreatmentofsporadiccolorectalcancer.oncoscience.2014;1(6):400-4066.
6.waters,c.m.etal.,quorumsensing:cell-to-cellcommunicationinbacteria.annurevcelldevbiol,2005;21:319-346.
7.cohen,s.j.,etal.,isolationandcharacterizationofcirculatingtumorcellsinpatientswithmetastaticcolorectalcancer.clincolorectalcancer,2006;6(2):125-132.
8.ioannidis,i.,etal.,comparativestudyoftheimmunohistochemicalexpressionofmetalloproteinases2,7and9betweenclearlyinvasivecarcinomasand"insitu"trophoblastinvasion.neoplasma.2010;57(1):20-28.
9.song,w.,etal.,rhomboiddomaincontaining1promotescolorectalcancergrowththroughactivationoftheegfrsignallingpathway.natcommun,2015;(6):8022.
10.zhang,m.,etal.,rhbdd1promotescolorectalcancermetastasisthroughthewntsignalingpathwayanditsdownstreamtargetzeb1.jexpclincancres,2018;(37):22.
11.miao,f.,etal.,rhbdd1upregulatesegfrviatheap-1pathwayincolorectalcancer.oncotarget,2017;8(15):25251-25260.
序列表
<110>中国医学科学院基础医学研究所
<120>一种以rhbdd1为靶点的抗肿瘤药物筛选模型及其方法
<130>380206cg
<160>12
<170>patentinversion3.3
<210>1
<211>207
<212>prt
<213>人工序列
<220>
<223>rhbdd1-207截短体
<400>1
metglnargargserargglyileasnthrglyleuileleuleuleu
151015
serglnilephehisvalglyileasnasnileproprovalthrleu
202530
alathrleualaleuasniletrpphepheleuasnproglnlyspro
354045
leutyrsersercysleuservalglulyscystyrglnglnlysasp
505560
trpglnargleuleuleuserproleuhishisalaaspasptrphis
65707580
leutyrpheasnmetalasermetleutrplysglyileasnleuglu
859095
argargleuglyserargtrpphealatyrvalilethralapheser
100105110
valleuthrglyvalvaltyrleuleuleuglnphealavalalaglu
115120125
phemetaspgluproaspphelysargsercysalavalglypheser
130135140
glyvalleuphealaleulysvalleuasnasnhistyrcysprogly
145150155160
glyphevalasnileleuglypheprovalproasnargphealacys
165170175
trpvalgluleuvalalailehisleupheserproglythrserphe
180185190
alaglyhisleualaglyileleuvalglyleumettyrthrgln
195200205
<210>2
<211>237
<212>prt
<213>人工序列
<220>
<223>rhbdd1-237截短体
<400>2
metglnargargserargglyileasnthrglyleuileleuleuleu
151015
serglnilephehisvalglyileasnasnileproprovalthrleu
202530
alathrleualaleuasniletrpphepheleuasnproglnlyspro
354045
leutyrsersercysleuservalglulyscystyrglnglnlysasp
505560
trpglnargleuleuleuserproleuhishisalaaspasptrphis
65707580
leutyrpheasnmetalasermetleutrplysglyileasnleuglu
859095
argargleuglyserargtrpphealatyrvalilethralapheser
100105110
valleuthrglyvalvaltyrleuleuleuglnphealavalalaglu
115120125
phemetaspgluproaspphelysargsercysalavalglypheser
130135140
glyvalleuphealaleulysvalleuasnasnhistyrcysprogly
145150155160
glyphevalasnileleuglypheprovalproasnargphealacys
165170175
trpvalgluleuvalalailehisleupheserproglythrserphe
180185190
alaglyhisleualaglyileleuvalglyleumettyrthrglngly
195200205
proleulyslysilemetglualacysalaglyglypheserserser
210215220
valglytyrproglyargglntyrtyrpheasnserser
225230235
<210>3
<211>247
<212>prt
<213>人工序列
<220>
<223>rhbdd1-247截短体
<400>3
metglnargargserargglyileasnthrglyleuileleuleuleu
151015
serglnilephehisvalglyileasnasnileproprovalthrleu
202530
alathrleualaleuasniletrpphepheleuasnproglnlyspro
354045
leutyrsersercysleuservalglulyscystyrglnglnlysasp
505560
trpglnargleuleuleuserproleuhishisalaaspasptrphis
65707580
leutyrpheasnmetalasermetleutrplysglyileasnleuglu
859095
argargleuglyserargtrpphealatyrvalilethralapheser
100105110
valleuthrglyvalvaltyrleuleuleuglnphealavalalaglu
115120125
phemetaspgluproaspphelysargsercysalavalglypheser
130135140
glyvalleuphealaleulysvalleuasnasnhistyrcysprogly
145150155160
glyphevalasnileleuglypheprovalproasnargphealacys
165170175
trpvalgluleuvalalailehisleupheserproglythrserphe
180185190
alaglyhisleualaglyileleuvalglyleumettyrthrglngly
195200205
proleulyslysilemetglualacysalaglyglypheserserser
210215220
valglytyrproglyargglntyrtyrpheasnserserglyserser
225230235240
glytyrglnasptyrtyrpro
245
<210>4
<211>37
<212>prt
<213>人工序列
<220>
<223>底物keren短肽
<400>4
argasnargvalmetleuglulysalaserilevalserglyalathr
151015
leualaleuleuphemetalametcyscysvalvalleutyrleuarg
202530
hisglulysleugln
35
<210>5
<211>948
<212>dna
<213>人类
<400>5
atgcaacggagatcaagagggataaatactggacttattctactcctttctcaaatcttc60
catgttgggatcaacaatattccacctgtcaccctagcaactttggccctcaacatctgg120
ttcttcttgaaccctcagaagccactgtatagctcctgccttagtgtggagaagtgttac180
cagcaaaaagactggcagcgtttactgctctctccccttcaccatgctgatgattggcat240
ttgtatttcaatatggcatccatgctctggaaaggaataaatctagaaagaagactggga300
agtagatggtttgcctatgttatcaccgcattttctgtacttactggagtggtatacctg360
ctcttgcaatttgctgttgccgaatttatggatgaacctgacttcaaaaggagctgtgct420
gtaggtttctcaggagttttgtttgctttgaaagttcttaacaaccattattgccctgga480
ggctttgtcaacattttgggctttcctgtaccgaacagatttgcttgttgggtcgaactt540
gtggctattcatttattctcaccagggacttccttcgctgggcatctggctgggattctt600
gttggactaatgtacactcaagggcctctgaagaaaatcatggaagcatgtgcaggcggt660
ttttcctccagtgttggttacccaggacggcaatactactttaatagttcaggcagctct720
ggatatcaggattattatccgcatggcaggccagatcactatgaagaagcacccaggaac780
tatgacacgtacacagcaggactgagtgaagaagaacagctcgagagagcattacaagcc840
agcctctgggaccgaggaaataccagaaatagcccaccaccctacgggtttcatctctca900
ccagaagaaatgaggagacagcggcttcacagattcgatagccagtga948
<210>6
<211>948
<212>dna
<213>人工序列
<220>
<223>突变体δrhbdd1蛋白的基因序列
<400>6
atgcaacggagatcaagagggataaatactggacttattctactcctttctcaaatcttc60
catgttgggatcaacaatattccacctgtcaccctagcaactttggccctcaacatctgg120
ttcttcttgaaccctcagaagccactgtatagctcctgccttagtgtggagaagtgttac180
cagcaaaaagactggcagcgtttactgctctctccccttcaccatgctgatgattggcat240
ttgtatttcaatatggcatccatgctctggaaaggaataaatctagaaagaagactggga300
agtagatggtttgcctatgttatcaccgcattttctgtacttactggagtggtatacctg360
ctcttgcaatttgctgttgccgaatttatggatgaacctgacttcaaaaggagctgtgct420
gtaggtttcgcaggagttttgtttgctttgaaagttcttaacaaccattattgccctgga480
ggctttgtcaacattttgggctttcctgtaccgaacagatttgcttgttgggtcgaactt540
gtggctattcatttattctcaccagggacttccttcgctgggcatctggctgggattctt600
gttggactaatgtacactcaagggcctctgaagaaaatcatggaagcatgtgcaggcggt660
ttttcctccagtgttggttacccaggacggcaatactactttaatagttcaggcagctct720
ggatatcaggattattatccgcatggcaggccagatcactatgaagaagcacccaggaac780
tatgacacgtacacagcaggactgagtgaagaagaacagctcgagagagcattacaagcc840
agcctctgggaccgaggaaataccagaaatagcccaccaccctacgggtttcatctctca900
ccagaagaaatgaggagacagcggcttcacagattcgatagccagtga948
<210>7
<211>36
<212>dna
<213>人工序列
<220>
<223>rhbdd1-207:正向引物
<400>7
tggatatctgcagaattcgccaccatgtggagccac36
<210>8
<211>42
<212>dna
<213>人工序列
<220>
<223>rhbdd1-207:反向引物
<400>8
attcctcgacgcggccgctcattgagtgtacattagtccacc42
<210>9
<211>36
<212>dna
<213>人工序列
<220>
<223>rhbdd1-237:正向引物
<400>9
tggatatctgcagaattcgccaccatgtggagccac36
<210>10
<211>42
<212>dna
<213>人工序列
<220>
<223>rhbdd1-237:反向引物
<400>10
attcctcgacgcggccgctcatgaactattaaagtagtattg42
<210>11
<211>36
<212>dna
<213>人工序列
<220>
<223>rhbdd1-247:正向引物
<400>11
tggatatctgcagaattcgccaccatgtggagccac36
<210>12
<211>42
<212>dna
<213>人工序列
<220>
<223>rhbdd1-247:反向引物
<400>12
attcctcgacgcggccgctcacggataataatcctgatatcc42
- 还没有人留言评论。精彩留言会获得点赞!