一株高效生产苹果酸的黑曲霉菌株、构建方法及应用与流程
本发明属于微生物技术领域,尤其是一株高效生产苹果酸的黑曲霉菌株、构建方法及应用。
背景技术:
黑曲霉作为重要的细胞工厂用于有机酸的发酵生产已有100多年的历史,不仅是gras(generallyregardedsafe)菌株,而且能够利用廉价的碳源。l-苹果酸,又名2-羟基丁二酸,主要用于食品、医药等行业。在食品行业,l-苹果酸主要用作食品酸味剂,与柠檬酸相比,具有味道柔和、酸度大,滞留时间长等特点,且不损害口腔牙齿、不积累脂肪,成为一种低热量的国际食品界公认的安全性食品酸味剂,是目前世界食品行业中用量最大和发展前景较好的有机酸之一。在医药行业,l-苹果酸被用于治疗肝病、贫血、尿毒症等多种疾病。而且由于l-苹果酸在代谢上利于氨基酸的吸收,常被配入复合氨基酸注射液中。由于l-苹果酸酸味刺激效果优于柠檬酸,而且因西方发达国家消费者对化学合成产品持谨慎和怀疑态度,因此发酵生产的天然产品l-苹果酸在食品和医药领域应用范围在扩大,并且美国fda禁止在食品中使用dl-苹果酸,又限制了柠檬酸在儿童、老年食品中的应用,所以近几年来l-苹果酸在食品工业的应用已逐渐取代柠檬酸,因此,国际市场上对l-苹果酸的需求量与日俱增。
当前,应用黑曲霉发酵生产苹果酸存在生产效率低,发酵生产周期长且副产物柠檬酸积累较高等问题,造成生产成本过高且后续复杂的苹果酸分离纯化工艺,因此,构建一种高效生产苹果酸的黑曲霉菌株,以提高苹果酸的生产效率、缩短发酵周期并消除副产物十分必要。
通过检索,尚未发现与本发明专利申请相关的公开专利文献。
技术实现要素:
本发明目的在于克服现有技术中的不足之处,提供一株高效生产苹果酸的黑曲霉菌株、构建方法及应用。
本发明解决其技术问题所采用的技术方案是:
一株高效生产苹果酸的黑曲霉(aspergillusniger)基因工程菌株,所述黑曲霉基因工程菌株是敲除了柠檬酸转运蛋白基因cexa,并过表达了黑曲霉来源的葡萄糖转运蛋白基因mstc、己糖激酶基因hxka、磷酸果糖激酶基因pfka和丙酮酸激酶基因pkia的黑曲霉基因工程菌株。
而且,所述基因cexa序列在ncbi-geneid是4989494,所述基因mstc序列在ncbi-geneid是4978840,所述hxka基因在ncbi-geneid是4979978,所述基因pfka序列在ncbi-geneid是4989727,所述基因pkia序列在ncbi-geneid是4982167。
如上所述的高效生产苹果酸的黑曲霉基因工程菌株的构建方法,步骤如下:
⑴消除副产物柠檬酸的黑曲霉基因工程菌株的构建
步骤1,构建基因cexa敲除质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应分别扩增获得基因cexa的上游和下游同源重组序列片段;将所述基因cexa的上下游同源重组序列片段克隆到载体plh594,构建基因cexa敲除质粒plh623;
步骤2,cexa基因敲除菌株的获得:将所述质粒plh623转化至宿主菌株s575,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除菌株s895;
⑵高效生产l-苹果酸的黑曲霉基因工程菌株的构建
步骤1,构建mstc基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因mstc序列片段;将所述基因mstc序列片段克隆到载体plh509,构建基因mstc过表达质粒plh684;所述基因mstc由黑曲霉丙酮酸激酶基因启动子ppkia控制,所述启动子ppkia序列为seqno.4,长度为1035bp;
步骤2,mstc基因过表达菌株的获得:将所述质粒plh684转化至cexa基因敲除菌株s895,经转化子筛选和潮霉素抗性基因重组获得mstc基因过表达菌株s1006;
步骤3,构建pfka基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因pfka序列片段;将所述基因pfka序列片段克隆到载体plh454,构建基因pfka过表达质粒plh473;所述基因pfka由黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda控制;
步骤4,构建hxka基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因hxka序列片段;将所述基因hxka序列片段克隆到载体plh509,构建基因hxka过表达质粒plh667;所述基因hxka由黑曲霉丙酮酸激酶基因启动子ppkia控制;
步骤5,构建pfka基因及hxka基因组合过表达质粒:分别以pfka基因过表达质粒plh473及hxka基因过表达质粒plh667为模板,通过pcr反应扩增获得pgpda-pfka-ttrpc序列片段和ppkia-hxka-ttrpc序列片段;将所述pgpda-pfka-ttrpc序列片段和ppkia-hxka-ttrpc序列片段克隆到载体plh331,构建pfka基因及hxka基因组合过表达质粒plh727;
步骤6,cexa基因敲除且mstc、hxka和pfka基因过表达菌株的获得:将所述质粒plh727转化至cexa基因敲除且mstc基因过表达菌株s1006,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078;
步骤7,构建pkia基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因pkia序列片段;将所述基因pkia序列片段克隆到载体plh509,构建基因hxka过表达质粒plh683;所述基因pkia由黑曲霉丙酮酸激酶基因启动子ppkia控制;
步骤8,cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株的获得:
将所述质粒plh683转化至cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株s1149,即得高效生产苹果酸的黑曲霉基因工程菌株。
而且,所述载体plh594的构建方法如下:
合成双丙氨膦抗性基因bar基因,然后将bar基因序列同时与经ecorⅰ/bamhⅰ双酶切线性化后的出发载体plh577进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh593;
以质粒plh593为模板,经pcr扩增黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda、双丙氨膦抗性基因bar和构巢曲霉色氨酸合成基因c终止子ttrpc序列;然后将pgpda启动子、bar基因和ttrpc终止子序列同时与经kpni/ecori双酶切线性化后的出发载体plh334进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh594。
而且,所述载体plh509的构建方法如下:
分别以黑曲霉和构巢曲霉基因组为模板,经pcr扩增黑曲霉丙酮酸激酶基因启动子ppkia和构巢曲霉色氨酸合成基因c终止子ttrpc序列,经测序确认无突变后,将ppkia启动子和ttrpc终止子序列同时与经xbai/xhoi双酶切线性化后的出发载体plh419进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh509。
而且,所述菌株s1149的构建方法如下:
⑴cexa基因敲除菌株的获得:
将质粒plh623电转至农杆菌,然后将含有质粒plh623的农杆菌与宿主菌株s575在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取100个转化子转接至含有10μg/ml草铵膦的mm平板中,然后挑取在含有草铵膦的平板上生长缓慢的克隆提取基因组进行pcr筛选验证,挑取其中一个正确的cexa敲除克隆进行hphmarker诱导重组从而获得不具有潮霉素抗性的cexa基因敲除菌株s895;
⑵cexa基因敲除且mstc基因过表达菌株的获得:
将质粒plh684电转至农杆菌,然后将含有质粒plh684的农杆菌与cexa基因敲除菌株s895在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc基因过表达菌株s1006;
⑶cexa基因敲除且mstc、hxka和pfka基因过表达菌株的获得:
将质粒plh727电转至农杆菌,然后将含有plh727的农杆菌与mstc基因过表达且cexa基因敲除菌株s1006在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078;
⑷cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株的获得:
将质粒plh683电转至农杆菌,然后将含有质粒plh683的农杆菌与mstc基因过表达和hxka基因及pfka基因组合过表达且cexa基因敲除菌株s1078在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株s1149;
所述诱导重组方法为:将转化子孢子均匀涂布与含有10μg/ml多西环素的mm平板中至长出单克隆,然后随机挑取100个克隆同时转接至pda平板和含有潮霉素的pda平板中,在含潮霉素的pda平板中不能生长而在pda能正常生长的克隆即为hphmarker诱导重组,表现为潮霉素敏感。
如上所述的高效生产苹果酸的黑曲霉基因工程菌株在苹果酸制备方面中的应用。
利用如上所述的高效生产苹果酸的黑曲霉基因工程菌株于发酵罐发酵产生苹果酸的方法,步骤如下:
首先,将高效生产苹果酸的黑曲霉基因工程菌株接种在pda培养平板上在28℃培养6天直至产生分生孢子;
然后,将孢子粉接种于含有种子培养基的摇瓶中,孢子的终浓度为2×106个/ml,在28℃,220rpm培养20h;
最后,将种子培养液接种至含有发酵培养基的发酵罐进行分批补料发酵,温度维持28℃~32℃,通气量为0.5vvm~1vvm,搅拌速度为250~400rpm。整个发酵过程维持葡萄糖浓度高于15g/l且补加碳酸钙以维持ph在5.8-6.5之间直至发酵结束;其中,所述种子培养液:发酵培养基的体积比ml:l为140:1.26。
而且,40g/l葡萄糖,6g/l细菌蛋白胨,750mg/l无水磷酸二氢钾,750mg/l无水磷酸二氢钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
而且,所述发酵培养基的组成为:100g/l葡萄糖,80g/l碳酸钙,6g/l细菌蛋白胨,150mg/l无水磷酸二氢钾,150mg/l无水磷酸氢二钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
本发明取得的优点和积极效果为:
1、本发明克服了现有技术中的不足,现有黑曲霉发酵生产苹果酸过程中,会伴随主要副产物柠檬酸的生成,造成后续的苹果酸纯化工艺成本提高,本发明提供了一种cexa基因敲除的黑曲霉基因工程菌株及消除黑曲霉发酵生产苹果酸过程中副产物柠檬酸的方法,通过构建cexa基因敲除载体,转化到宿主菌株s575,经筛选可获得消除副产物柠檬酸的工程菌株s895,应用该cexa基因敲除菌株s895发酵生产苹果酸,其副产物柠檬酸几乎被完全消除。
2、本发明基于黑曲霉产生苹果酸的天然特性,通过遗传重组改造黑曲霉的生理代谢特征,加强黑曲霉发酵过程中的糖酵解代谢途径以及葡萄糖转运途径,获得了一种黑曲霉基因工程菌株,经过实验证实,该黑曲霉基因工程菌株生产苹果酸的效率显著提高,经发酵罐分批补料发酵第八天的产量可达到195.72~210g/l,苹果酸对葡萄糖的转化率达到1.59~1.64mol/mol,发酵周期较出发菌株缩短一天,由原来的9天缩短至8天。为微生物发酵法制备苹果酸提供了优良菌种。
3、本发明基因工程菌株的构建方法利用基因敲除技术破坏黑曲霉柠檬酸转运蛋白基因(cexa),并过表达了黑曲霉来源的葡萄糖转运蛋白基因mstc、己糖激酶基因hxka、磷酸果糖激酶基因pfka和丙酮酸激酶基因pkia从而获得了高效生产苹果酸菌株s1149。经过8天发酵罐分批补料发酵,l-苹果酸的含量可达到195.72~210g/l且无柠檬酸副产物产生;与出发菌s575相比发酵周期缩短一天,且转化率由1.27mol/mol提高到1.59~1.64mol/mol,达到理论最高转化率的79.5%。将本发明中的基因工程菌株应用于l-苹果酸的发酵生产,能够显著提高苹果酸的产量并克服了黑曲霉发酵生产苹果酸过程中产生大量副产物柠檬酸的问题,可极大降低下游发酵产物苹果酸的分离纯化成本。该基因工程菌株具有很好的工业化应用前景。
附图说明
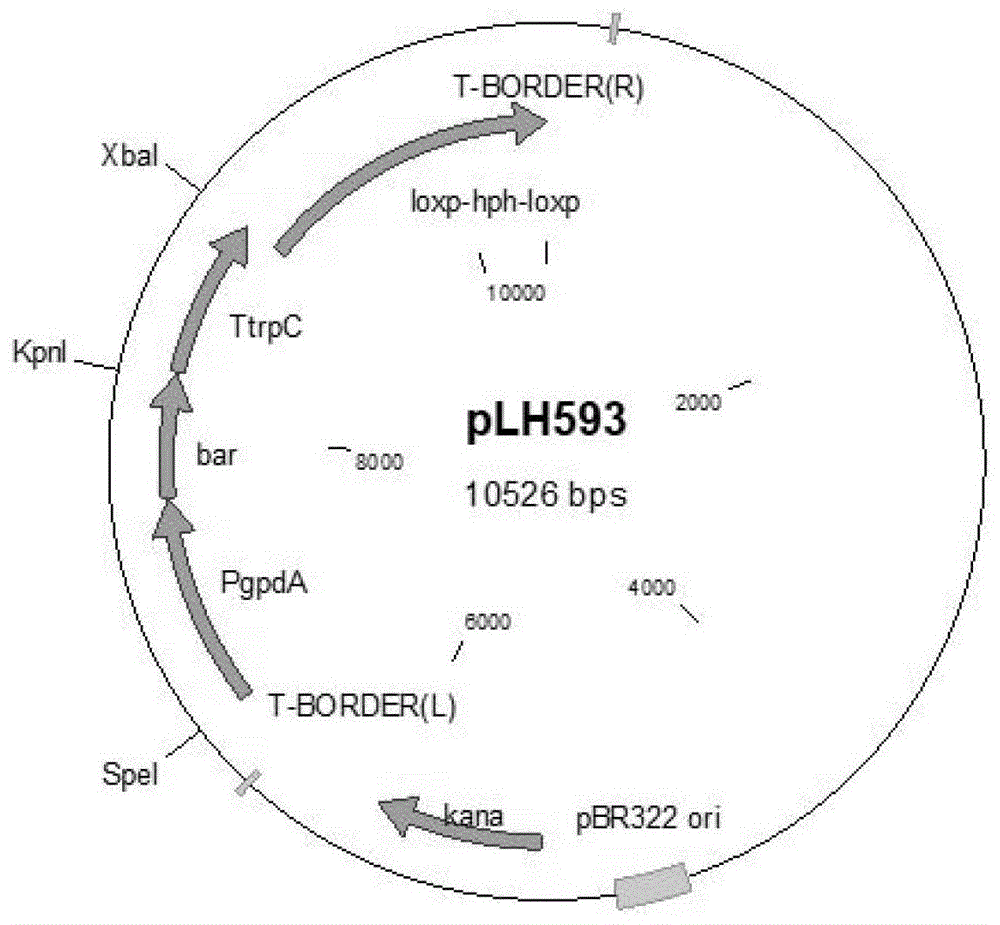
图1为本发明中构建的敲除质粒plh593图谱;
图2为本发明中对敲除质粒plh593双酶切验证图,其中m为dnamarker,1为kpnⅰ和xbaⅰ双酶切验证质粒;
图3为本发明中构建的敲除质粒plh594图谱;
图4为本发明中构建的敲除质粒plh594双酶切验证图,其中m为dnamarker,1、2、3为ecorⅰ和xbaⅰ双酶切验证质粒;
图5为本发明中构建的连接cexa基因下游同源臂质粒plh622图谱;
图6为本发明中对连接cexa基因下游同源臂质粒plh622双酶切验证图,其中m为dnamarker,1为speⅰ和xbaⅰ双酶切验证下游同源臂质粒;
图7为构建的cexa基因敲除质粒plh623图谱;
图8为本发明中构建的cexa基因敲除质粒plh623双酶切验证图,其中m为dnamarker,1、2、3为sacⅰ和speⅰ双酶切验证质粒;
图9为本发明中构建的基因表达质粒plh509图谱;
图10为本发明中构建的基因表达质粒plh509双酶切验证图,其中m为dnamarker,1、2为speⅰ和kpnⅰ双酶切验证质粒;
图11为本发明中构建的mstc基因过表达质粒plh684图谱;
图12为本发明中构建的mstc基因过表达质粒plh684双酶切验证图,其中m为dnamarker,1、2为ecorⅰ和sacⅰ双酶切验证质粒;
图13为本发明中构建的pfka基因过表达质粒plh473图谱;
图14为本发明中构建的pfka基因过表达质粒plh473双酶切验证图,其中m为dnamarker,1、2为sacⅰ和bamhⅰ双酶切验证质粒;
图15为本发明中构建的hxka基因过表达质粒plh667图谱;
图16为本发明中构建的hxka基因过表达质粒plh667双酶切验证图,其中m为dnamarker,1、2为speⅰ和ecorⅰ双酶切验证质粒;
图17为本发明中构建的质粒plh726图谱;
图18为本发明中构建的质粒plh726双酶切验证图,其中m为dnamarker,1、2为pstⅰ单酶切验证质粒;
图19为本发明中构建的pfka基因及hxka基因组合过表达质粒plh727图谱;
图20为本发明中构建的pfka基因及hxka基因组合过表达质粒plh727双酶切验证图,其中m为dnamarker,1、2为ecorⅴ和nheⅰ双酶切验证质粒;
图21为本发明中构建的pkia基因过表达质粒plh683图谱;
图22为本发明中构建的pkia基因过表达质粒plh683双酶切验证图,其中m为dnamarker,1、2为ecorⅰ和kpnⅰ双酶切验证质粒;
图23为本发明中cexa基因敲除左同源臂pcr验证图,即p1949/1950验证左臂及p1949/641验证左臂-php,其中m为dnamarker,方框内3、4为成功敲除cexa基因的黑曲霉转化子;
图24为本发明中cexa基因敲除右同源臂pcr验证图,即p1951/1952验证右臂及p1951/642验证右臂-php,其中m为dnamarker,方框内3、4为成功敲除cexa基因的黑曲霉转化子;
图25为本发明中基因工程菌株发酵液的高效液相色谱分析图,其中,s575为宿主菌株的发酵液高效液相色谱分析图,s895为cexa基因敲除菌株的发酵液高效液相色谱分析图,方框所标注为副产物柠檬酸出峰时间及峰面积;
图26为本发明中基因工程菌株及宿主菌株发酵罐分批补料发酵数据折线图;其中,a为宿主菌株s575发酵罐分批补料发酵数据折线图,b为本发明中基因工程菌株s1149发酵罐分批补料发酵数据折线图;图中■代表苹果酸产量,▼代表葡萄糖残糖量,╳代表ph值,▲代表富马酸产量,●代表柠檬酸产量。
具体实施方式
下面详细叙述本发明的实施例,需要说明的是,本实施例是叙述性的,不是限定性的,不能以此限定本发明的保护范围。
本发明中所使用的原料,如无特殊说明,均为常规的市售产品;本发明中所使用的方法,如无特殊说明,均为本领域的常规方法。
一株高效生产苹果酸的黑曲霉(aspergillusniger)基因工程菌株,所述黑曲霉基因工程菌株是敲除了柠檬酸转运蛋白基因cexa,并过表达了黑曲霉来源的葡萄糖转运蛋白基因mstc、己糖激酶基因hxka、磷酸果糖激酶基因pfka和丙酮酸激酶基因pkia的黑曲霉基因工程菌株。
较优地,所述基因cexa序列在ncbi-geneid是4989494,所述基因mstc序列在ncbi-geneid是4978840,所述hxka基因在ncbi-geneid是4979978,所述基因pfka序列在ncbi-geneid是4989727,所述基因pkia序列在ncbi-geneid是4982167。
如上所述的高效生产苹果酸的黑曲霉基因工程菌株的构建方法,步骤如下:
⑴消除副产物柠檬酸的黑曲霉基因工程菌株的构建
步骤1,构建基因cexa敲除质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应分别扩增获得基因cexa的上游和下游同源重组序列片段;将所述基因cexa的上下游同源重组序列片段克隆到载体plh594,构建基因cexa敲除质粒plh623;
步骤2,cexa基因敲除菌株的获得:将所述质粒plh623转化至宿主菌株s575,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除菌株s895;
⑵高效生产l-苹果酸的黑曲霉基因工程菌株的构建
步骤1,构建mstc基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因mstc序列片段;将所述基因mstc序列片段克隆到载体plh509,构建基因mstc过表达质粒plh684;所述基因mstc由黑曲霉丙酮酸激酶基因启动子ppkia控制,所述启动子ppkia序列为seqno.4,长度为1035bp;
步骤2,mstc基因过表达菌株的获得:将所述质粒plh684转化至cexa基因敲除菌株s895,经转化子筛选和潮霉素抗性基因重组获得mstc基因过表达菌株s1006;
步骤3,构建pfka基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因pfka序列片段;将所述基因pfka序列片段克隆到载体plh454,构建基因pfka过表达质粒plh473;所述基因pfka由黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda控制;
步骤4,构建hxka基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因hxka序列片段;将所述基因hxka序列片段克隆到载体plh509,构建基因hxka过表达质粒plh667;所述基因hxka由黑曲霉丙酮酸激酶基因启动子ppkia控制;
步骤5,构建pfka基因及hxka基因组合过表达质粒:分别以pfka基因过表达质粒plh473及hxka基因过表达质粒plh667为模板,通过pcr反应扩增获得pgpda-pfka-ttrpc序列片段和ppkia-hxka-ttrpc序列片段;将所述pgpda-pfka-ttrpc序列片段和ppkia-hxka-ttrpc序列片段克隆到载体plh331,构建pfka基因及hxka基因组合过表达质粒plh727;
步骤6,cexa基因敲除且mstc、hxka和pfka基因过表达菌株的获得:将所述质粒plh727转化至cexa基因敲除且mstc基因过表达菌株s1006,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078;
步骤7,构建pkia基因过表达质粒:以野生型黑曲霉atcc1015基因组为模板,通过pcr反应扩增获得基因pkia序列片段;将所述基因pkia序列片段克隆到载体plh509,构建基因hxka过表达质粒plh683;所述基因pkia由黑曲霉丙酮酸激酶基因启动子ppkia控制;
步骤8,cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株的获得:
将所述质粒plh683转化至cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078,经转化子筛选和潮霉素抗性基因重组获得cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株s1149,即得高效生产苹果酸的黑曲霉基因工程菌株。
较优地,所述载体plh594的构建方法如下:
合成双丙氨膦抗性基因bar基因,然后将bar基因序列同时与经ecorⅰ/bamhⅰ双酶切线性化后的出发载体plh577进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh593;
以质粒plh593为模板,经pcr扩增黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda、双丙氨膦抗性基因bar和构巢曲霉色氨酸合成基因c终止子ttrpc序列;然后将pgpda启动子、bar基因和ttrpc终止子序列同时与经kpni/ecori双酶切线性化后的出发载体plh334进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh594。
较优地,所述载体plh509的构建方法如下:
分别以黑曲霉和构巢曲霉基因组为模板,经pcr扩增黑曲霉丙酮酸激酶基因启动子ppkia和构巢曲霉色氨酸合成基因c终止子ttrpc序列,经测序确认无突变后,将ppkia启动子和ttrpc终止子序列同时与经xbai/xhoi双酶切线性化后的出发载体plh419进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh509。
较优地,所述菌株s1149的构建方法如下:
⑴cexa基因敲除菌株的获得:
将质粒plh623电转至农杆菌,然后将含有质粒plh623的农杆菌与宿主菌株s575在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取100个转化子转接至含有10μg/ml草铵膦的mm平板中,然后挑取在含有草铵膦的平板上生长缓慢的克隆提取基因组进行pcr筛选验证,挑取其中一个正确的cexa敲除克隆进行hphmarker诱导重组从而获得不具有潮霉素抗性的cexa基因敲除菌株s895;
⑵cexa基因敲除且mstc基因过表达菌株的获得:
将质粒plh684电转至农杆菌,然后将含有质粒plh684的农杆菌与cexa基因敲除菌株s895在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc基因过表达菌株s1006;
⑶cexa基因敲除且mstc、hxka和pfka基因过表达菌株的获得:
将质粒plh727电转至农杆菌,然后将含有plh727的农杆菌与mstc基因过表达且cexa基因敲除菌株s1006在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078;
⑷cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株的获得:
将质粒plh683电转至农杆菌,然后将含有质粒plh683的农杆菌与mstc基因过表达和hxka基因及pfka基因组合过表达且cexa基因敲除菌株s1078在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株s1149;
所述诱导重组方法为:将转化子孢子均匀涂布与含有10μg/ml多西环素的mm平板中至长出单克隆,然后随机挑取100个克隆同时转接至pda平板和含有潮霉素的pda平板中,在含潮霉素的pda平板中不能生长而在pda能正常生长的克隆即为hphmarker诱导重组,表现为潮霉素敏感。
如上所述的高效生产苹果酸的黑曲霉基因工程菌株在苹果酸制备方面中的应用。
利用如上所述的高效生产苹果酸的黑曲霉基因工程菌株于发酵罐发酵产生苹果酸的方法,步骤如下:
首先,将高效生产苹果酸的黑曲霉基因工程菌株接种在pda培养平板上在28℃培养6天直至产生分生孢子;
然后,将孢子粉接种于含有种子培养基的摇瓶中,孢子的终浓度为2×106个/ml,在28℃,220rpm培养20h;
最后,将种子培养液接种至含有发酵培养基的发酵罐进行分批补料发酵,温度维持28℃~32℃,通气量为0.5vvm~1vvm,搅拌速度为250~400rpm。整个发酵过程维持葡萄糖浓度高于15g/l且补加碳酸钙以维持ph在5.8-6.5之间直至发酵结束;其中,所述种子培养液:发酵培养基的体积比ml:l为140:1.26。
较优地,40g/l葡萄糖,6g/l细菌蛋白胨,750mg/l无水磷酸二氢钾,750mg/l无水磷酸二氢钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
较优地,所述发酵培养基的组成为:100g/l葡萄糖,80g/l碳酸钙,6g/l细菌蛋白胨,150mg/l无水磷酸二氢钾,150mg/l无水磷酸氢二钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
具体地,一种高效生产苹果酸的黑曲霉(aspergillusniger)基因工程菌株,所述基因工程菌株的构建步骤如下:
1)构建基因敲除质粒:双丙氨膦抗性基因bar基因序列由北京华大基因公司合成,经pcr扩增双丙氨膦抗性基因bar序列(引物见表1)。然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将bar基因序列同时与经ecorⅰ/bamhⅰ双酶切线性化后的出发载体plh577进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh593,其图谱如图1所示,plh593的双酶切验证如图2所示。为扩增双丙氨膦抗性基因bar基因序列,设计上游引物bar-f和下游引物bar-r(如表1所示),所述基因bar的序列为序列表中的seqno.1,长度为552bp。
以质粒plh593为模板,经pcr扩增黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda、双丙氨膦抗性基因bar和构巢曲霉色氨酸合成基因c终止子ttrpc序列。然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将pgpda启动子、bar基因和ttrpc终止子序列同时与经kpni/ecori双酶切线性化后的出发载体plh334进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh594,其图谱如图3所示,plh594的双酶切验证如图4所示。为扩增黑曲霉3-磷酸甘油脱氢酶基因启动子pgpda、双丙氨膦抗性基因bar和构巢曲霉色氨酸合成基因c终止子ttrpc序列,设计上游引物p951和下游引物p952(如表1所示)。
2)cexa基因敲除质粒的构建:
为扩增cexa下游同源重组序列片段,设计引物p1751/p1752(表1),通过pcr扩增得到cexa下游序列片段,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将cexa下游序列片段同时与经xbaⅰ/speⅰ双酶切线性化后的出发载体plh594进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh622,其图谱如图5所示,plh622的双酶切验证如图6所示。所述基因cexa的下游序列为序列表中的seqno.2,长度为1318bp。
为扩增cexa上游同源重组序列片段,设计引物p1749/p1750(表1),通过pcr扩增得到cexa上游序列片段,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将cexa上游序列片段同时与经ecorⅰ/bamhⅰ双酶切线性化后的出发载体plh622进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh623,其图谱如图7所示,plh623的双酶切验证如图8所示。所述基因cexa的上游序列为序列表中的seqno.3,长度为1303bp。
3)构建基因过表达质粒:分别以黑曲霉和构巢曲霉基因组为模板,经pcr扩增黑曲霉丙酮酸激酶基因启动子ppkia和构巢曲霉色氨酸合成基因c终止子ttrpc序列(引物见表1)送至华大基因公司测序确认无突变。然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将ppkia启动子和ttrpc终止子序列同时与经xbai/xhoi双酶切线性化后的出发载体plh419进行连接,连接产物经转化大肠杆菌jm109感受态细胞获得质粒plh509,其图谱如图9所示,plh509的双酶切验证如图10所示。为扩增黑曲霉丙酮酸激酶基因启动子ppkia和构巢曲霉色氨酸合成基因c终止子ttrpc序列,设计ppkia启动子上游引物p1352和下游引物p1353,及ttrpc终止子上游引物ttrpc-f和下游引物ttrpc-r(如表1所示)。
4)mstc过表达质粒的构建
为扩增mstc基因序列,设计引物p1977/p1978(表1),通过pcr扩增得到mstc基因序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将mstc序列同时与经ecori/saci双酶切线性化后的出发载体plh509进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得mstc过表达质粒plh684。其图谱如图11所示,plh684的双酶切验证如图12所示。
所述基因mstc序列起始于起始密码子atg,包含该基因编码序列和自身终止子,为序列表中的seqno.6,长度为1683bp。
5)pfka过表达质粒的构建
为扩增pfka基因序列,设计引物p1981/p1982(表1),通过pcr扩增得到pfka基因序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将pfk序列同时与经saci/bamhi双酶切线性化后的出发载体plh454进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得pfka过表达质粒plh473。其图谱如图13所示,plh473的双酶切验证如图14所示。
所述基因pfka序列起始于起始密码子atg,包含该基因编码序列和自身终止子,为序列表中的seqno.7,长度为1463bp。
6)hxka过表达质粒的构建
为扩增hxka基因序列,设计引物p1937/p1938(表1),通过pcr扩增得到hxka基因序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将hxka序列同时与经ecori/bamhi双酶切线性化后的出发载体plh509进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得hxka过表达质粒plh667。其图谱如图15所示,plh667的双酶切验证如图16所示。
所述基因hxka序列起始于起始密码子atg,包含该基因编码序列和自身终止子,为序列表中的seqno.8,长度为1479bp。
7)pfka及hxka组合过表达质粒的构建
为扩增pgpda-pfka-ttrpc序列片段,设计引物p2743/p2744(表1),以质粒plh473为模板,通过pcr扩增得到pgpda-pfka-ttrpc序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将pgpda-pfka-ttrpc序列同时与经ecori/saci双酶切线性化后的出发载体plh331进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得质粒plh726。其图谱如图17所示,plh726的双酶切验证如图18所示。
为扩增ppkia-hxka-ttrpc序列片段,设计引物p2745/p2746(表1),以质粒plh667为模板,通过pcr扩增得到ppkia-hxka-ttrpc序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将ppkia-hxka-ttrpc序列同时与经xbai/spei双酶切线性化后的出发载体plh726进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得pfka及hxka组合过表达质粒plh727。其图谱如图19所示,plh727的双酶切验证如图20所示。
8)pkia过表达质粒的构建
为扩增pkia基因序列,设计引物p1979/p1980(表1),通过pcr扩增得到pki基因序列片段,送至华大基因公司测序确认无突变,然后应用诺唯赞c113-clonexpress-multisonestepcloningkit试剂盒将pkia序列同时与经ecori/kpni双酶切线性化后的出发载体plh509进行连接,连接产物经转化大肠杆菌jm109感受态细胞,经菌落pcr验证和双酶切验证,获得pkia过表达质粒plh683。其图谱如图21所示,plh683的双酶切验证如图22所示。
所述基因pkia序列起始于起始密码子atg,包含该基因编码序列和自身终止子,为序列表中的seqno.9,长度为1581bp。
表1.所用引物序列
9)以上所述lb培养基组分:
胰蛋白胨10.0g/l,酵母浸出物5.0g/l,nacl10.0g/l,ph调至7.0-7.2,固体培养基加1.5%(w/t)的琼脂粉。121℃灭菌20min。灭菌完毕冷却至60℃左右时加入卡那霉素至终浓度100μg/ml。
10)农杆菌介导黑曲霉转化及克隆筛选:
本发明所述过表达,是将相关基因整合到黑曲霉基因组进行表达。本发明所述表达基因及敲除基因的转化方法为农杆菌介导法。所述农杆菌为agl-1菌株。本发明所述表达基因及敲除基因在农杆菌介导转化黑曲霉之前,需将所述表达质粒和敲除质粒首先电转化至农杆菌。所述电转条件是:capacitnce:25uf,voltage:2.5kv,resistance:200ω,pulse:5msec,即电容:25uf,电压:2.5kv,电阻:200ω,脉冲:5msec。
(1)cexa基因敲除菌株的获得:
将质粒plh623电转至农杆菌,然后将含有质粒plh623的农杆菌与宿主菌株s575在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取100个转化子转接至含有10μg/ml草铵膦的mm平板中,然后挑取在含有草铵膦的平板上生长缓慢的克隆提取基因组进行pcr筛选验证,验证引物为p1949/p1950,p641/p1951,p1952/p642(见表1)。cexa基因敲除左同源臂验证胶图见图23,及cexa基因敲除右同源臂验证胶图见图24,由于敲除是双交换同源重组原理,cexa被loxp-hph-loxp替代。挑取其中一个正确的cexa敲除克隆进行hphmarker诱导重组从而获得不具有潮霉素抗性的cexa基因敲除菌株s895。
所述诱导重组方法为:将约300个转化子孢子均匀涂布与含有10μg/ml多西环素的mm平板中至长出单克隆,然后随机挑取100个克隆同时转接至pda平板和含有潮霉素的pda平板中,在含潮霉素的pda平板中不能生长而在pda能正常生长的克隆即为hphmarker诱导重组,表现为潮霉素敏感,该菌株即为cexa基因敲除菌株s895。
(2)cexa基因敲除且mstc基因过表达菌株的获得:
将质粒plh684电转至农杆菌,然后将含有质粒plh684的农杆菌与cexa基因敲除菌株s895在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc基因过表达菌株s1006。所述诱导重组方法同上。
(3)cexa基因敲除且mstc、hxka和pfka基因过表达菌株的获得:
将质粒plh727电转至农杆菌,然后将含有plh727的农杆菌与mstc基因过表达且cexa基因敲除菌株s1006在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka和pfka基因过表达菌株s1078。所述诱导重组方法同上。
(4)cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株的获得:
将质粒plh683电转至农杆菌,然后将含有质粒plh683的农杆菌与mstc基因过表达和hxka基因及pfka基因组合过表达且cexa基因敲除菌株在im平板共培养进行农杆菌介导转化,共培养两天后将转化子转接于含有200μm头孢噻肟,100μg/ml氨苄青霉素,100μg/ml链霉素,250μg/ml潮霉素b的cm平板中进行筛选直至转化子长出菌丝,然后随机挑取20个转化子进行摇瓶发酵筛选,选取产量最高的转化子进行hphmarker诱导重组,获得潮霉素敏感的cexa基因敲除且mstc、hxka、pfka和pkia基因过表达菌株s1149。所述诱导重组方法同上。
(5)以上所述pda培养基组分:马铃薯200g,切成小块,加1000ml水煮沸30min,用双层纱布滤成清液。然后加入20g葡萄糖完全溶解,加水定容至1l。固体培养基加琼脂20g。121℃,20min高压灭菌。
(3)im培养基组分:
15g琼脂,加水至905.7ml,121℃灭菌20min,微波加热待琼脂完全溶解后,加入:kbuffer0.8ml,mnbuffer20ml,1%cacl2·2h2o1ml,0.01%feso410ml,imtraceelements5ml,20%nh4no32.5ml,50%甘油10ml,1mmes40ml,20%葡萄糖5ml。
所述im培养基中所需试剂的配制:
1)kbuffer:将1.25mk2hpo4加入到1.25mkh2po4使得ph为4.8。
(a):1.25mkh2po4:k2hpo417.01g,加入去离子水定容至100ml,121℃灭菌20min。
(b):1.25mk2hpo4:k2hpo421.77g,加入去离子水定容至100ml,121℃灭菌20min。
2)mnbuffer:mgso4·7h2o3g,nacl1.5g,加入去离子水定容至100ml,121℃灭菌20min。
3)1%cacl2:cacl2·2h2o1g,加入去离子水定容至100ml,121℃灭菌20min。
4)0.01%feso4:feso4·7h2o0.01g,加入去离子水定容至100ml,121℃灭菌20min。
5)imtraceelements:znso4·7h2o10mg,cuso4·5h2o10mg,h3bo310mg,mnso4·h2o10mg,na2moo4·2h2o10mg,加入去离子水定容至100ml,121℃灭菌20min。
6)20%nh4no3:加入nh4no320g,加入去离子水定容至100ml,121℃灭菌20min。
7)50%甘油:甘油50ml,加入去离子水定容至100ml,121℃灭菌20min。
8)1mmes:mes(即2-(n-吗啉)乙磺酸一水合物)19.524g,加入去离子水定容至100ml,加入naoh调节ph为5.5,过滤除菌。黑暗下保存一个月,或分装后与-20℃下保存。
9)20%葡萄糖:葡萄糖20g,加入ddh2o定容至100ml,115℃灭菌20min。
(6)以上所述cm培养基组分:
20g琼脂,加水到897ml,121℃灭菌20min。微波加热待琼脂完全溶解后,加入:asp+n20ml,50%葡萄糖20ml,1mmgso42ml,cmtraceelements1ml,10%酪蛋白水解物10ml,10%酵母浸出物50ml。
所述cm培养基中所需试剂的配制:
1)asp+n:kcl(350mm)2.61g,kh2po4(550mm)7.48g,nano3(3.5m)29.75g,加入去离子水定容至100mlph5.5(5mkoh),121℃灭菌20min。
2)50%葡萄糖:葡萄糖50g,加入ddh2o定容至100ml,115℃灭菌20min。3)1mmgso4:mgso424.648g,加入ddh2o定容至100ml,121℃灭菌20min。
4)cmtraceelements:znso4·7h2o(76mm)2.1g,h3bo3(178mm)1.1g,mncl2·4h2o(25mm)0.5g,feso4·7h2o(18mm)0.5g,cocl2·6h2o(7.1mm)0.17g,cuso4·5h2o(6.4mm)0.16g,na2moo4·2h2o(6.2mm)0.15g,edta(174mm)5.1g,加入去离子水定容至100ml,121℃灭菌20min。
5)10%酪蛋白水解物:酪蛋白水解物10g,加入ddh2o定容至100ml,121℃灭菌20min。
6)10%酵母浸出物:酵母浸出物10g,加入ddh2o定容至100ml,121℃灭菌20min。
(7)以上所述mm培养基组分:vogel'ssalts20ml,葡萄糖15g,琼脂15g,蒸馏水溶解并定容至1000ml。121℃灭菌20min。
所述mm培养基中所需试剂的配制:
1)vogel's50xsalts:柠檬酸钠150g,kh2po4250g,nh4no3100gmgso4·7h2010g,cacl2·2h205g。微量元素5ml,生物素溶液2.5ml,蒸馏水溶解并定容至1000ml,加0.2ml氯仿作为防腐剂,室温下保存。
2)微量元素溶液:柠檬酸·h205.00g,znso4·7h205.00g,fe(nh4)2(so4)2·6h201.00g,cuso4·5h200.25g,mnso4·h200.05g,h3bo30.05g,na2moo4·2h200.05g,蒸馏水溶解并定容至100ml,加1ml氯仿作为防腐剂,室温下保存。
3)生物素5.0mg,蒸馏水溶解并定容至50ml,-20℃保存。
本发明中工程菌株的相关检测及应用:
1、cexa基因敲除菌株摇瓶发酵生产l-苹果酸
利用本发明构建的cexa基因敲除菌株s895于摇瓶发酵产生苹果酸的方法,具体步骤如下:
首先,将菌株接种在pda培养平板上在28℃培养6天直至产生分生孢子;
然后,将孢子粉接种于摇瓶发酵培养基中,孢子的终浓度为2×106孢子/ml,在28℃,220rpm培养3天。经样品制备后,利用hplc法测定发酵液中副产物柠檬酸的含量。结果显示,没有柠檬酸被检出,结果如图25,即柠檬酸副产物被完全消除。
发酵培养基的组成为:100g/lglucose,80g/lcaco3,6g/lbactopeptone,50mg/lkh2po4,150mg/lk2hpo4,100mg/lmgso4·7h2o,100mg/lcacl2·2h2o,5mg/lfeso4·7h2o,5mg/lnacl。
2、cexa基因敲除、mstc、hxka、pfka和pkia基因过表达菌株s1149发酵罐发酵生产l-苹果酸
利用本发明构建的工程菌株s1149于2l发酵罐(上海保兴)进行分批补料发酵,具体步骤如下:
首先,将菌株接种在pda培养平板上在28℃培养6天直至产生分生孢子;
然后,将孢子粉接种于含有50ml种子培养基的摇瓶中,孢子的终浓度为2×106个/ml,在28℃,220rpm培养20h。
最后,将140ml种子培养液接种至含有1.26l发酵培养基的2l发酵罐进行分批补料发酵,温度维持30℃,通气量为1vvm,搅拌速度为300rpm。初始糖浓度为100g/l,整个发酵过程通过补给葡萄糖(70%w/v)维持其浓度高于15g/l且补加碳酸钙以维持ph在5.8-6.5之间直至第8天发酵结束。经样品制备后,利用hplc法测定发酵液中l-苹果酸的含量。结果显示,经过8天发酵l-苹果酸的含量可达到195.72~210g/l,与出发菌s575相比周期缩短一天,结果如图26,且转化率由1.27mol/mol提高到1.59~1.64mol/mol,达到理论最高转化率的79.5%。此外,本发明中的基因工程菌株s1149发酵液未有副产物柠檬酸被检出,而出发菌s575的发酵液中柠檬酸含量达28.00g/l。
本发明的研究成果证实了黑曲霉发酵生产苹果酸的出色能力,为工业化发酵生产l-苹果酸提供了优良的菌株。
种子培养基的组成为:40g/l葡萄糖,6g/l细菌蛋白胨,750mg/l无水磷酸二氢钾,750mg/l无水磷酸二氢钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
发酵培养基的组成为:100g/l葡萄糖,80g/l碳酸钙,6g/l细菌蛋白胨,150mg/l无水磷酸二氢钾,150mg/l无水磷酸氢二钾,100mg/l七水硫酸镁,100mg/l二水氯化钙,5mg/l七水硫酸亚铁,5mg/l无水氯化钠。
其中,l-苹果酸发酵样品制备及检测如下:
样品制备:摇匀发酵悬液,取1ml发酵液加入等体积的2mhcl溶解有机酸钙沉淀及残留的caco3,离心后再稀释50倍,经0.22μm滤膜过滤后滤液用于hplc检测。
苹果酸以及副产物柠檬酸的测定方法:aminexhpx-87h柱(300mm×7.8mm),uv检测器。流动相:5mmh2so4。流速0.6ml/min,柱温65℃,波长210nm,进样体积为20μl。
本发明中使用到的序列:
1.bar基因的核苷酸序列552bp
atgagcccagaacgacgcccggccgacatccgccgtgccaccgaggcggacatgccggcggtctgcaccatcgtcaaccactacatcgagacaagcacggtcaacttccgtaccgagccgcaggaaccgcaggagtggacggacgacctcgtccgtctgcgggagcgctatccctggctcgtcgccgaggtggacggcgaggtcgccggcatcgcctacgcgggcccctggaaggcacgcaacgcctacgactggacggccgagtcaaccgtgtacgtctccccccgccaccagcggacgggactgggctccacgctctacacccacctgctgaagtccctggaggcacagggcttcaagagcgtggtcgctgtcatcgggctgcccaacgacccgagcgtgcgcatgcacgaggcgctcggatatgccccccgcggcatgctgcgggcggccggcttcaagcacgggaactggcatgacgtgggtttctggcagctggacttcagcctgccggtaccgccccgtccggtcctgcccgtcaccgagatgtga
2.cexa基因的下游序列的核苷酸序列1318bp
accgctcatgcactggtaggctttggatgtatgtctggctcttatctggtcggctaccttatggattacaaccaccgtcttaccgaacgcgaatattgcgagaaacacggttatccggcaggcacacgtgtcaatctgaaatcacaccccgacttccccattgaggtcgcccggatgcgcaatacctggtgggtgattgcgatcttcatcgtgacagttgctttgtacggcgtgtctttgcggacacatctggcggtgcctatcattctgcagtacttcattgcgttctgctcaacaggactcttcaccatcaacagcgccctggtcatcgatctttacccaggtgctagcgccagtgcgacagcagtgaacaatctgatgcggtgcctgcttggagctggcggtgtggctatcgtgcaacctatcctggacgccttgaagccggattatactttcctcttgcttgccggcatcacccttgtgatgactccgttgctgtacgtcgaagatcgatggggtcctggctggcgacatgcccgcgaaaggagactcaaggccaaagccaacggcaactagggagagaaaggacttgaaaaaaaaaaggtgaagtgggactggtgaagtaaatgtttgattcttccccacactttcttgatatgggttttattttagcggcatttggcgataccactgttttgcaagcgataccagttagatttatagaagaattgatcagtttcatcggctatctcgctattacttcctcgtagctttttagcttcatatatgggtgagtgggaaaggtttgacatggtggttgagatagtatcatttggatggagatggaagtataaagcaagaagttctgttgtttggtgtttagactagactagacgtggccggtgaagtcacgagcctcagcttagataatctaatgcggctgatgtgactgaccgatggctttgttatatgaagacaggtcggtcaattagaagatgtcgccagcaaaagggtataataatggctattatagagataagaatgtagagtatccctgtttttaaggatcagtacgtagttttactataaaggtacccatatatatatttgcggaacacgaggaggtcgggagtacatacttgtagttactgtttgtttgtgacgaggaatgccagttaggtaagcaccacgtgatgcgtgacccaaacaagcgcccggtcgttgcttgaggaaccaatttctctgtttatcctccttcgaacaccacacttcgaccttctggacactgccgctatgagccttccatagccagcctgtt
3.cexa基因的上游序列的核苷酸序列1303bp
tggtgcctcaaatcctcacggcatcttcgtcatcactttctattattatgcatccctccctgttgaaatccccccatcttgtatttcctttgcttcacttccactgtgatcctgtttgcgcagctactcctttcctccctatccacctcccctgatggcaatttctacttgtctcatatttaagcttaccaactgttacgtagacctcccgcactgaccccaatcaggtgcaccttacctgtggagttgtggtttgcgactcccgtgggagctctctcaggatgtcttggtatagcttcactccacccccaattccgcaatctgcagccacggtggaaccagcccagcgaggctggccagcttgtcaaggatccatcccaagaagtttcgttgtctgggcgtcgcactcgattttttttggtcctcgcctcccatgcaatcatcctcccacaccccccttcttagtgcgtatgggcctgatgtagatccccgagatccatagtaacccactacacctgagcagttcgccaatcaggctgatctcagattgctcatactggtgcgcgtgcgtgctccctgtttcctacaactactcctcctgaagaggggggaatagggaccctggcgccctgagtcgtcaattgatgacctgccttgccgtctcgcgttgcatcgggcctctccgtgttgatcacagcttagcttctgcgtgggagacagccttctccgtcaacacatgtgggagatgttggctgagaagagtcgacggcctatctactccataccatgtagcccaacgctccgccacggcgccactgaatagcctgctcagctcccttatcacgggctccgcttccatctagacccttgcgcatgacaggcgtgcccggtccttcaaacacaccattcgctggaaatctgtatgctaagttgactaaatccgtcagctcttgaggtgcaggcgctagtcgtagtccaggatggcctggaaagcatgcttgttctggaatttcatcaccacgccgggcccacgtcatgtatgcagatcttggtagctccgcccttttgtcccttcaattttattttttttccctctttcttcgtcggctgcccgacggcttggactctctcggatgtgacctagactactagtcgccaagtaagaccggccgaagagaaactcctaaacccacgtctccgttcataccttggcgataacaccggctcttgccacccacatttgcccgctttgggaaggtcattgatgatggatagcccccccgtctgtccaagttgctccgca
4.丙酮酸激酶基因启动子ppkia的核苷酸序列1035bp
atggaagagaaaacctccgagtacttacttagggtccctgtctactgaccagagtctcgtcctcattactatgattaattacccactggacaaaaaaataaaataaaataaaaataaaaagggagacagcttctccataactggcaactgggtccgtccgagcagagcaaaattcagccttatgggttccgatggagtcagggaaatagttcttgcgaagggcattgggcttttttgcgaggagaaaattcagcaccgacaaagcatccaaatccacctcgctaggagagaatggatccgcgacgatgtggggtcaactggacagagtgagagggtatcatgtggtcctgccagatacttcgcagaatgttgtgtgggtgtctgattgtggcttgggcgtgaattgcttttggtcttcccaaccaattattattgcatgcggcgtatgaatgcctgagatgcgcggagggaaggtgcctgaggatgtagtggacaaatgctgctgatcgctgggcggaaacccttggctgaccagtgaaaagagcggacggaggcagcaggtgtatctacgatcaaagaatagtagcaaagcagtgaaaggtggatcacccagcaaataattgagttttgatacccagcgatagtgccgggggggagaaaaagtcattaataatgggaattatgtaggcgatgggaagtgtgattgtaactactccgtagctggaggcacaactaacaagccagctctcaacccgcggggaaccgaccgacagaaaaaagcgtcccaaagcaggaatcccaccaaaaagggccgatccagccaatcaccgccgccaacatttttccttcccgggcacccctcctctagtccaccatctctctcttctctcgctcaccggccccgtcttttccttccctattatctctccctcttctcctcccttctctccctccattctttctcccatcttcatcaatcccttctcttctgtcttcccccccggttcagtagagatcaatcatccgtcaagatgg
5.色氨酸合成基因c终止子ttrpc的核苷酸序列719bp
cttaacgttactgaaatcatcaaacagcttgacgaatctggatataagatcgttggtgtcgatgtcagctccggagttgagacaaatggtgttcaggatctcgataagatacgttcatttgtccaagcagcaaagagtgccttctagtgatttaatagctccatgtcaacaagaataaaacgcgttttcgggtttacctcttccagatacagctcatctgcaatgcattaatgcattgactgcaacctagtaacgccttncaggctccggcgaagagaagaatagcttagcagagctattttcattttcgggagacgagatcaagcagatcaacggtcgtcaagagacctacgagactgaggaatccgctcttggctccacgcgactatatatttgtctctaattgtactttgacatgctcctcttctttactctgatagcttgactatgaaaattccgtcaccagcncctgggttcgcaaagataattgcatgtttcttccttgaactctcaagcctacaggacacacattcatcgtaggtataaacctcgaaatcanttcctactaagatggtatacaatagtaaccatgcatggttgcctagtgaatgctccgtaacacccaatacgccggccgaaacttttttacaactctcctatgagtcgtttacccagaatgcacaggtacacttgtttagaggtaatccttctttctagac
6.mstc基因的核苷酸序列1683bp
atgggtgtctctaatatgatgtcccggttcaagcctcaggcggaccactctgagtcctccactgaggctcctactcctgctcgctccaactccgccgtcgagaaggacaatgtcttgctcgatgacagtcccgtcaagtacttgacctggcgctccttcatcctgggtatcgtcgtgtccatgggtggtttcatcttcggttactctactggtcaaatctctggtttcgagactatggatgacttcctccaacgtttcggtcaggaacaggcggatggatcctatgctttcagcaacgtccgtagtggtctcattgtcggtctgctgtgtatcggtactatgatcggtgccctggttgctgctcctatcgcagaccgcatgggccgcaagctctccatctgtctctggtctgtcatccacatcgtcggtatcatcattcagattgccaccgactccaactgggtccaggtcgctatgggtcgttgggttgccggtctgggtgttggtgccctctccagcattgtccccatgtaccagagtgaatctgctccccgtcaggtccgtggtgccatggtcagtgccttccagctgttcgttgccttcggtatcttcatctcctacatcatcaacttcggtaccgagagaatccagtcgactgcttcctggcgtatcaccatgggcattggcttcgcctggcccttgattctggctgttggctctctcttcctgcccgagtctcctcgtttcgcctaccgtcagggtcgtatcgatgaggcccgtgaggttatgtgcaagctgtacggtgtcagcccgaaccaccgcgtcatcgcccaggagatgaaggacatgaaggacaagctcgacgaggagaaggccgccggtcaggctgcctggcacgagctgttcaccggccctcgcatgctctaccgtaccctgctcggtattgctctgcagtccctccagcagctgaccggtgccaactttatcttctactacggaaacagtatcttcacctccactggtctgagcaacagctacgtcactcagatcattctgggtgctgtcaacttcggtatgaccctgcccggtctgtacgtcgtcgagcacttcggtcgtcgtaacagtctgatggttggtgctgcctggatgttcatttgcttcatgatctgggcttccgttggtcacttcgctctggatcttgccgaccctcaggccactcctgccgctggtaaggccatgatcatcttcacttgcttcttcattgtcggtttcgccaccacctggggtcctatcgtctgggccatctgtggtgagatgtaccccgcccgctaccgtgctctctgcattggtattgccaccgctgccaactggacctggaacttcctcatctccttcttcacccccttcatctctagctccattgacttcgcctacggctacgtctttgctggatgctgtttcgccgccatcttcgttgtcttcttcttcgtcaatgagacccagggtcgcactcttgaggaggttgacaccatgtacgtgctccacgtcaagccctggcagagtgccagctgggttcccccggagggcattgtccaggacatgcaccgccccccttcctcttccaagcaggagggtcaggctgagatggctgagcacaccgagcccactgagctccgcgagtaa
7.pfka基因的核苷酸序列1463bp
atggctcccccccaagctcccgtgcaaccgcccaagagacgccgcatcggtgtcttgacctctggtggcgatgctcccggtatgaacggtgtcgtccgggccgtcgtccggatggctatccactccgactgtgaggctttcgccgtctacgaaggttacgagggtctcgtcaatggcggcgacatgatccgtcagcttcactgggaggatgttcgcggctggttgtcccgtggtggtaccttgatcggttccgcccgctgcatggagttccgtgagcgccccggtcgtctgcgggctgccaagaacatggtcctccgtggcattgacgcccttgtcgtctgtggtggtgatggcagtttgactggtgccgacgtttttcgttccgagtggcccggtctgttgaaggaattggtcgagacgggcgagttgaccgaagagcaggtcaagccataccagattctgaacatcgtcggtttggtgggttcgatcgataacgacatgtccggcaccgacgccaccatcggttgctactcctccctcactcgcatctgtgacgccgtcgacgacgtcttcgatactgccttttcccaccagcgtggattcgtcattgaggtcatgggtcgtcactgcggttggctggccttgatgtctgctatcagtaccggtgccgactggctgttcgtgcccgagatgccgcccaaggacggatgggaggatgacatgtgcgctatcattaccaaggtgggttgatcggaacttggtggagagaactcagaggcatcactaactccccgcagaacagaaaggagcgtggaaagcgtaggacgatcgtcatcgtggccgagggtgcccaggatcgccatctcaacaagatctcgagttcgaagatcaaggatattttgacggagcggttgaacctggatacccgtgtgactgtgttgggtcacactcagagaggtggagccgcctgtgcgtacgaccgctggctgtccacactgcagggtgtcgaggctgtccgcgcggtgctggacatgaagcccgaagccccgtccccggtcatcaccatccgtgagaacaagatcttgcgcatgccgttgatggacgccgtgcagcacaccaagactgtcaccaagcacattcagaacaaggagttcgccgaagccatggccctccgcgactcggaattcaaagagtaccacttttcctacatcaacacttccacgcccgaccacccgaagctgctcctcccagagaacaaggtttgtcgccacagtagctgcttcggtgctgagctaacaaaaggcagagaatgcgcatcggtattattcacgttggcgcccccgctggtggtatgaaccaggctacccgcgcggccgttgcctactgcctgactcgtggccacacccccctggccattcacaacggtttccccggtctgtgccggcactatgatgggccctaag
8.hxka基因的核苷酸序列1479bp
atggttggaatcggtcctaagcgtcccccctcccgcaagggttccatggccgatgttccccagaacctcttgcagcagatcaaggacttcgaggaccaattcaccgtcgatcgctccaagctcaagcagattgtcaaccactttgtcaaggaattggaaaagggtctctctgtcgagggtggaaacatccctatgaacgtcacctgggttctgggattccccgatggcgacgaacagggtactttcctcgccctcgacatgggtggcaccaacctgcgtgtttgtgagatcaccctgacccaggagaagggtgccttcgacatcacccagtccaagtaccgcatgcccgaggaattgaagaccggtaccgccgaggagctgtgggaatacatcgccgactgcctgcagcaattcatcgagtcccaccacgagaacgagaagatctccaagctgcccctgggtttcaccttctcctaccccgccacccaggattacatcgaccacggtgtcctgcagcgctggaccaagggtttcgacattgatggtgtcgagggccacgacgtcgtcccgccgttggaggccatcctgcagaagcgcggcctgcccatcaaggtggctgcactgatcaacgacaccaccggaaccctcatcgcctcttcttacaccgactccgacatgaagatcggctgcatcttcggtaccggtgtcaacgccgcctacatggagaacgccggctccatccccaagctggctcacatgaacctgcccgccgacatgcccgtggctatcaactgcgagtacggtgctttcgacaacgagcacatcgtgctgcctctgaccaagtacgaccacatcatcgaccgcgactcgccccgtcccggtcagcaggccttcgagaagatgaccgccggtctgtacctgggtgagatcttccgtctggccctgatggacctggtggagaaccgccccggcctcatcttcaacggccaggacaccaccaagctgcgcaagccctacatcctggatgcctccttcctggcagccatcgaggaggacccctacgagaacctggaggagaccgaggagctcatggagcgcgagctcaacatcaaggccaccccggcggagctggagatgatccgccgcctggccgagctgatcggtacgcgtgccgctcgcctgtcggcctgcggtgttgccgccatttgcacgaagaagaagatcgactcgtgccacgttggtgccgacggctccgtcttcaccaagtaccctcacttcaaggcgcgcggagccaaggctctgcgcgagatcctggactgggctccggaggagcaggacaaggtgaccatcatggcggccgaggatggatctggtgtgggagctgcgctgattgcggcgctgaccctgaagcgggtcaaggccggcaacctggccggtatccgaaacatggctgacatgaagaccctgctataagagctc
9.pkia基因的核苷酸序列1581bp
atggccgccagctcttccctcgaccacctgagcaaccgcatgaagttggagtggcactccaagctcaacactgagatggtgccctccaagaacttccgccgcacctccatcatcggaaccatcggccccaagaccaactccgtggagaagatcaactctctccgcactgccggtcttaacgttgttcgcatgaacttctcccacggttcttatgagtaccaccaatctgttatcgacaacgcccgcgaggccgccaagacccaggtcggacgtcctctcgccattgctcttgataccaaaggacccgagatccgtaccggaaacacccccgatgataaggatatccctatcaagcagggccacgagctcaacatcaccaccgacgagcaatatgccaccgcctccgacgacaagaacatgtacctcgactacaagaacatcaccaaggtgatctctcctggcaagctcatctatgttgatgacggtatcctttccttcgaggtcctcgaagtcgtagatgacaagaccatccgcgtccggtgcttgaacaacggcaacatctcttcccgcaagggtgttaacttgcccggcactgacgttgacctccccgccctttccgagaaggacattgccgatctcaagttcggtgttaggaacaaggtcgacatggtcttcgcttctttcatccgccgcggtagcgacattcgccacatccgtgaggttctgggtgaggagggcaaggagatccagatcattgccaagattgagaaccagcagggtgtcaacaacttcgacgagatcctcgaagagactgacggtgtcatggttgcccgtggtgaccttggtatcgagatccccgcccccaaggtcttcatcgcccagaagatgatgatcgccaagtgtaacatcaagggtaagcccgtcatctgtgccactcagatgctcgagtccatgacatacaaccctcgtcctactcgtgccgaggtgtccgatgttgccaacgccgtccttgacggtgccgactgtgtcatgctgtcgggagagaccgccaagggtaactaccccaacgaggccgtcaagatgatgtccgagacctgcctgctcgccgaggttgccatcccccacttcaatgtgttcgatgagctccgcaaccttgctcctcgccccaccgacactgtcgagtccatcgccatggctgccgttagcgccagtctggaactcaacgctggtgccattgtcgtcttgactaccagcggtaaaactgctcgctacctttccaagtaccgccccgtctgccccattgtcatggttacccgtaaccccgctgcctcccggtactctcacctgtaccgtggtgtctggcccttcctcttccccgagaagaagcccgacttcaacgtcaaggtctggcaggaggatgttgaccgccgtctcaagtggggtatcaaccacgctcttaagctcggcatcatcaacaagggtgacaacatcgtctgtgtccagggatggcgcggcggtatgggccacaccaacaccgtccgtgtggtccctgctgaggagaaccttggcctggctgagtaa
尽管为说明目的公开了本发明的实施例,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换、变化和修改都是可能的,因此,本发明的范围不局限于实施例所公开的内容。
序列表
<110>天津科技大学,南京师范大学
<120>一株高效生产苹果酸的黑曲霉菌株、构建方法及应用
<160>39
<170>siposequencelisting1.0
<210>1
<211>552
<212>dna/rna
<213>基因bar的序列(unknown)
<400>1
atgagcccagaacgacgcccggccgacatccgccgtgccaccgaggcggacatgccggcg60
gtctgcaccatcgtcaaccactacatcgagacaagcacggtcaacttccgtaccgagccg120
caggaaccgcaggagtggacggacgacctcgtccgtctgcgggagcgctatccctggctc180
gtcgccgaggtggacggcgaggtcgccggcatcgcctacgcgggcccctggaaggcacgc240
aacgcctacgactggacggccgagtcaaccgtgtacgtctccccccgccaccagcggacg300
ggactgggctccacgctctacacccacctgctgaagtccctggaggcacagggcttcaag360
agcgtggtcgctgtcatcgggctgcccaacgacccgagcgtgcgcatgcacgaggcgctc420
ggatatgccccccgcggcatgctgcgggcggccggcttcaagcacgggaactggcatgac480
gtgggtttctggcagctggacttcagcctgccggtaccgccccgtccggtcctgcccgtc540
accgagatgtga552
<210>2
<211>1318
<212>dna/rna
<213>基因cexa的下游序列(unknown)
<400>2
accgctcatgcactggtaggctttggatgtatgtctggctcttatctggtcggctacctt60
atggattacaaccaccgtcttaccgaacgcgaatattgcgagaaacacggttatccggca120
ggcacacgtgtcaatctgaaatcacaccccgacttccccattgaggtcgcccggatgcgc180
aatacctggtgggtgattgcgatcttcatcgtgacagttgctttgtacggcgtgtctttg240
cggacacatctggcggtgcctatcattctgcagtacttcattgcgttctgctcaacagga300
ctcttcaccatcaacagcgccctggtcatcgatctttacccaggtgctagcgccagtgcg360
acagcagtgaacaatctgatgcggtgcctgcttggagctggcggtgtggctatcgtgcaa420
cctatcctggacgccttgaagccggattatactttcctcttgcttgccggcatcaccctt480
gtgatgactccgttgctgtacgtcgaagatcgatggggtcctggctggcgacatgcccgc540
gaaaggagactcaaggccaaagccaacggcaactagggagagaaaggacttgaaaaaaaa600
aaggtgaagtgggactggtgaagtaaatgtttgattcttccccacactttcttgatatgg660
gttttattttagcggcatttggcgataccactgttttgcaagcgataccagttagattta720
tagaagaattgatcagtttcatcggctatctcgctattacttcctcgtagctttttagct780
tcatatatgggtgagtgggaaaggtttgacatggtggttgagatagtatcatttggatgg840
agatggaagtataaagcaagaagttctgttgtttggtgtttagactagactagacgtggc900
cggtgaagtcacgagcctcagcttagataatctaatgcggctgatgtgactgaccgatgg960
ctttgttatatgaagacaggtcggtcaattagaagatgtcgccagcaaaagggtataata1020
atggctattatagagataagaatgtagagtatccctgtttttaaggatcagtacgtagtt1080
ttactataaaggtacccatatatatatttgcggaacacgaggaggtcgggagtacatact1140
tgtagttactgtttgtttgtgacgaggaatgccagttaggtaagcaccacgtgatgcgtg1200
acccaaacaagcgcccggtcgttgcttgaggaaccaatttctctgtttatcctccttcga1260
acaccacacttcgaccttctggacactgccgctatgagccttccatagccagcctgtt1318
<210>3
<211>1303
<212>dna/rna
<213>基因cexa的上游序列(unknown)
<400>3
tggtgcctcaaatcctcacggcatcttcgtcatcactttctattattatgcatccctccc60
tgttgaaatccccccatcttgtatttcctttgcttcacttccactgtgatcctgtttgcg120
cagctactcctttcctccctatccacctcccctgatggcaatttctacttgtctcatatt180
taagcttaccaactgttacgtagacctcccgcactgaccccaatcaggtgcaccttacct240
gtggagttgtggtttgcgactcccgtgggagctctctcaggatgtcttggtatagcttca300
ctccacccccaattccgcaatctgcagccacggtggaaccagcccagcgaggctggccag360
cttgtcaaggatccatcccaagaagtttcgttgtctgggcgtcgcactcgattttttttg420
gtcctcgcctcccatgcaatcatcctcccacaccccccttcttagtgcgtatgggcctga480
tgtagatccccgagatccatagtaacccactacacctgagcagttcgccaatcaggctga540
tctcagattgctcatactggtgcgcgtgcgtgctccctgtttcctacaactactcctcct600
gaagaggggggaatagggaccctggcgccctgagtcgtcaattgatgacctgccttgccg660
tctcgcgttgcatcgggcctctccgtgttgatcacagcttagcttctgcgtgggagacag720
ccttctccgtcaacacatgtgggagatgttggctgagaagagtcgacggcctatctactc780
cataccatgtagcccaacgctccgccacggcgccactgaatagcctgctcagctccctta840
tcacgggctccgcttccatctagacccttgcgcatgacaggcgtgcccggtccttcaaac900
acaccattcgctggaaatctgtatgctaagttgactaaatccgtcagctcttgaggtgca960
ggcgctagtcgtagtccaggatggcctggaaagcatgcttgttctggaatttcatcacca1020
cgccgggcccacgtcatgtatgcagatcttggtagctccgcccttttgtcccttcaattt1080
tattttttttccctctttcttcgtcggctgcccgacggcttggactctctcggatgtgac1140
ctagactactagtcgccaagtaagaccggccgaagagaaactcctaaacccacgtctccg1200
ttcataccttggcgataacaccggctcttgccacccacatttgcccgctttgggaaggtc1260
attgatgatggatagcccccccgtctgtccaagttgctccgca1303
<210>4
<211>1035
<212>dna/rna
<213>黑曲霉丙酮酸激酶基因启动子ppkia序列(unknown)
<400>4
atggaagagaaaacctccgagtacttacttagggtccctgtctactgaccagagtctcgt60
cctcattactatgattaattacccactggacaaaaaaataaaataaaataaaaataaaaa120
gggagacagcttctccataactggcaactgggtccgtccgagcagagcaaaattcagcct180
tatgggttccgatggagtcagggaaatagttcttgcgaagggcattgggcttttttgcga240
ggagaaaattcagcaccgacaaagcatccaaatccacctcgctaggagagaatggatccg300
cgacgatgtggggtcaactggacagagtgagagggtatcatgtggtcctgccagatactt360
cgcagaatgttgtgtgggtgtctgattgtggcttgggcgtgaattgcttttggtcttccc420
aaccaattattattgcatgcggcgtatgaatgcctgagatgcgcggagggaaggtgcctg480
aggatgtagtggacaaatgctgctgatcgctgggcggaaacccttggctgaccagtgaaa540
agagcggacggaggcagcaggtgtatctacgatcaaagaatagtagcaaagcagtgaaag600
gtggatcacccagcaaataattgagttttgatacccagcgatagtgccgggggggagaaa660
aagtcattaataatgggaattatgtaggcgatgggaagtgtgattgtaactactccgtag720
ctggaggcacaactaacaagccagctctcaacccgcggggaaccgaccgacagaaaaaag780
cgtcccaaagcaggaatcccaccaaaaagggccgatccagccaatcaccgccgccaacat840
ttttccttcccgggcacccctcctctagtccaccatctctctcttctctcgctcaccggc900
cccgtcttttccttccctattatctctccctcttctcctcccttctctccctccattctt960
tctcccatcttcatcaatcccttctcttctgtcttcccccccggttcagtagagatcaat1020
catccgtcaagatgg1035
<210>5
<211>719
<212>dna/rna
<213>色氨酸合成基因c终止子ttrpc的核苷酸序列(unknown)
<400>5
cttaacgttactgaaatcatcaaacagcttgacgaatctggatataagatcgttggtgtc60
gatgtcagctccggagttgagacaaatggtgttcaggatctcgataagatacgttcattt120
gtccaagcagcaaagagtgccttctagtgatttaatagctccatgtcaacaagaataaaa180
cgcgttttcgggtttacctcttccagatacagctcatctgcaatgcattaatgcattgac240
tgcaacctagtaacgccttncaggctccggcgaagagaagaatagcttagcagagctatt300
ttcattttcgggagacgagatcaagcagatcaacggtcgtcaagagacctacgagactga360
ggaatccgctcttggctccacgcgactatatatttgtctctaattgtactttgacatgct420
cctcttctttactctgatagcttgactatgaaaattccgtcaccagcncctgggttcgca480
aagataattgcatgtttcttccttgaactctcaagcctacaggacacacattcatcgtag540
gtataaacctcgaaatcanttcctactaagatggtatacaatagtaaccatgcatggttg600
cctagtgaatgctccgtaacacccaatacgccggccgaaacttttttacaactctcctat660
gagtcgtttacccagaatgcacaggtacacttgtttagaggtaatccttctttctagac719
<210>6
<211>1683
<212>dna/rna
<213>mstc基因的核苷酸序列(unknown)
<400>6
atgggtgtctctaatatgatgtcccggttcaagcctcaggcggaccactctgagtcctcc60
actgaggctcctactcctgctcgctccaactccgccgtcgagaaggacaatgtcttgctc120
gatgacagtcccgtcaagtacttgacctggcgctccttcatcctgggtatcgtcgtgtcc180
atgggtggtttcatcttcggttactctactggtcaaatctctggtttcgagactatggat240
gacttcctccaacgtttcggtcaggaacaggcggatggatcctatgctttcagcaacgtc300
cgtagtggtctcattgtcggtctgctgtgtatcggtactatgatcggtgccctggttgct360
gctcctatcgcagaccgcatgggccgcaagctctccatctgtctctggtctgtcatccac420
atcgtcggtatcatcattcagattgccaccgactccaactgggtccaggtcgctatgggt480
cgttgggttgccggtctgggtgttggtgccctctccagcattgtccccatgtaccagagt540
gaatctgctccccgtcaggtccgtggtgccatggtcagtgccttccagctgttcgttgcc600
ttcggtatcttcatctcctacatcatcaacttcggtaccgagagaatccagtcgactgct660
tcctggcgtatcaccatgggcattggcttcgcctggcccttgattctggctgttggctct720
ctcttcctgcccgagtctcctcgtttcgcctaccgtcagggtcgtatcgatgaggcccgt780
gaggttatgtgcaagctgtacggtgtcagcccgaaccaccgcgtcatcgcccaggagatg840
aaggacatgaaggacaagctcgacgaggagaaggccgccggtcaggctgcctggcacgag900
ctgttcaccggccctcgcatgctctaccgtaccctgctcggtattgctctgcagtccctc960
cagcagctgaccggtgccaactttatcttctactacggaaacagtatcttcacctccact1020
ggtctgagcaacagctacgtcactcagatcattctgggtgctgtcaacttcggtatgacc1080
ctgcccggtctgtacgtcgtcgagcacttcggtcgtcgtaacagtctgatggttggtgct1140
gcctggatgttcatttgcttcatgatctgggcttccgttggtcacttcgctctggatctt1200
gccgaccctcaggccactcctgccgctggtaaggccatgatcatcttcacttgcttcttc1260
attgtcggtttcgccaccacctggggtcctatcgtctgggccatctgtggtgagatgtac1320
cccgcccgctaccgtgctctctgcattggtattgccaccgctgccaactggacctggaac1380
ttcctcatctccttcttcacccccttcatctctagctccattgacttcgcctacggctac1440
gtctttgctggatgctgtttcgccgccatcttcgttgtcttcttcttcgtcaatgagacc1500
cagggtcgcactcttgaggaggttgacaccatgtacgtgctccacgtcaagccctggcag1560
agtgccagctgggttcccccggagggcattgtccaggacatgcaccgccccccttcctct1620
tccaagcaggagggtcaggctgagatggctgagcacaccgagcccactgagctccgcgag1680
taa1683
<210>7
<211>1463
<212>dna/rna
<213>pfka基因的核苷酸序列(unknown)
<400>7
atggctcccccccaagctcccgtgcaaccgcccaagagacgccgcatcggtgtcttgacc60
tctggtggcgatgctcccggtatgaacggtgtcgtccgggccgtcgtccggatggctatc120
cactccgactgtgaggctttcgccgtctacgaaggttacgagggtctcgtcaatggcggc180
gacatgatccgtcagcttcactgggaggatgttcgcggctggttgtcccgtggtggtacc240
ttgatcggttccgcccgctgcatggagttccgtgagcgccccggtcgtctgcgggctgcc300
aagaacatggtcctccgtggcattgacgcccttgtcgtctgtggtggtgatggcagtttg360
actggtgccgacgtttttcgttccgagtggcccggtctgttgaaggaattggtcgagacg420
ggcgagttgaccgaagagcaggtcaagccataccagattctgaacatcgtcggtttggtg480
ggttcgatcgataacgacatgtccggcaccgacgccaccatcggttgctactcctccctc540
actcgcatctgtgacgccgtcgacgacgtcttcgatactgccttttcccaccagcgtgga600
ttcgtcattgaggtcatgggtcgtcactgcggttggctggccttgatgtctgctatcagt660
accggtgccgactggctgttcgtgcccgagatgccgcccaaggacggatgggaggatgac720
atgtgcgctatcattaccaaggtgggttgatcggaacttggtggagagaactcagaggca780
tcactaactccccgcagaacagaaaggagcgtggaaagcgtaggacgatcgtcatcgtgg840
ccgagggtgcccaggatcgccatctcaacaagatctcgagttcgaagatcaaggatattt900
tgacggagcggttgaacctggatacccgtgtgactgtgttgggtcacactcagagaggtg960
gagccgcctgtgcgtacgaccgctggctgtccacactgcagggtgtcgaggctgtccgcg1020
cggtgctggacatgaagcccgaagccccgtccccggtcatcaccatccgtgagaacaaga1080
tcttgcgcatgccgttgatggacgccgtgcagcacaccaagactgtcaccaagcacattc1140
agaacaaggagttcgccgaagccatggccctccgcgactcggaattcaaagagtaccact1200
tttcctacatcaacacttccacgcccgaccacccgaagctgctcctcccagagaacaagg1260
tttgtcgccacagtagctgcttcggtgctgagctaacaaaaggcagagaatgcgcatcgg1320
tattattcacgttggcgcccccgctggtggtatgaaccaggctacccgcgcggccgttgc1380
ctactgcctgactcgtggccacacccccctggccattcacaacggtttccccggtctgtg1440
ccggcactatgatgggccctaag1463
<210>8
<211>1479
<212>dna/rna
<213>hxka基因的核苷酸序列(unknown)
<400>8
atggttggaatcggtcctaagcgtcccccctcccgcaagggttccatggccgatgttccc60
cagaacctcttgcagcagatcaaggacttcgaggaccaattcaccgtcgatcgctccaag120
ctcaagcagattgtcaaccactttgtcaaggaattggaaaagggtctctctgtcgagggt180
ggaaacatccctatgaacgtcacctgggttctgggattccccgatggcgacgaacagggt240
actttcctcgccctcgacatgggtggcaccaacctgcgtgtttgtgagatcaccctgacc300
caggagaagggtgccttcgacatcacccagtccaagtaccgcatgcccgaggaattgaag360
accggtaccgccgaggagctgtgggaatacatcgccgactgcctgcagcaattcatcgag420
tcccaccacgagaacgagaagatctccaagctgcccctgggtttcaccttctcctacccc480
gccacccaggattacatcgaccacggtgtcctgcagcgctggaccaagggtttcgacatt540
gatggtgtcgagggccacgacgtcgtcccgccgttggaggccatcctgcagaagcgcggc600
ctgcccatcaaggtggctgcactgatcaacgacaccaccggaaccctcatcgcctcttct660
tacaccgactccgacatgaagatcggctgcatcttcggtaccggtgtcaacgccgcctac720
atggagaacgccggctccatccccaagctggctcacatgaacctgcccgccgacatgccc780
gtggctatcaactgcgagtacggtgctttcgacaacgagcacatcgtgctgcctctgacc840
aagtacgaccacatcatcgaccgcgactcgccccgtcccggtcagcaggccttcgagaag900
atgaccgccggtctgtacctgggtgagatcttccgtctggccctgatggacctggtggag960
aaccgccccggcctcatcttcaacggccaggacaccaccaagctgcgcaagccctacatc1020
ctggatgcctccttcctggcagccatcgaggaggacccctacgagaacctggaggagacc1080
gaggagctcatggagcgcgagctcaacatcaaggccaccccggcggagctggagatgatc1140
cgccgcctggccgagctgatcggtacgcgtgccgctcgcctgtcggcctgcggtgttgcc1200
gccatttgcacgaagaagaagatcgactcgtgccacgttggtgccgacggctccgtcttc1260
accaagtaccctcacttcaaggcgcgcggagccaaggctctgcgcgagatcctggactgg1320
gctccggaggagcaggacaaggtgaccatcatggcggccgaggatggatctggtgtggga1380
gctgcgctgattgcggcgctgaccctgaagcgggtcaaggccggcaacctggccggtatc1440
cgaaacatggctgacatgaagaccctgctataagagctc1479
<210>9
<211>1581
<212>dna/rna
<213>pkia基因的核苷酸序列(unknown)
<400>9
atggccgccagctcttccctcgaccacctgagcaaccgcatgaagttggagtggcactcc60
aagctcaacactgagatggtgccctccaagaacttccgccgcacctccatcatcggaacc120
atcggccccaagaccaactccgtggagaagatcaactctctccgcactgccggtcttaac180
gttgttcgcatgaacttctcccacggttcttatgagtaccaccaatctgttatcgacaac240
gcccgcgaggccgccaagacccaggtcggacgtcctctcgccattgctcttgataccaaa300
ggacccgagatccgtaccggaaacacccccgatgataaggatatccctatcaagcagggc360
cacgagctcaacatcaccaccgacgagcaatatgccaccgcctccgacgacaagaacatg420
tacctcgactacaagaacatcaccaaggtgatctctcctggcaagctcatctatgttgat480
gacggtatcctttccttcgaggtcctcgaagtcgtagatgacaagaccatccgcgtccgg540
tgcttgaacaacggcaacatctcttcccgcaagggtgttaacttgcccggcactgacgtt600
gacctccccgccctttccgagaaggacattgccgatctcaagttcggtgttaggaacaag660
gtcgacatggtcttcgcttctttcatccgccgcggtagcgacattcgccacatccgtgag720
gttctgggtgaggagggcaaggagatccagatcattgccaagattgagaaccagcagggt780
gtcaacaacttcgacgagatcctcgaagagactgacggtgtcatggttgcccgtggtgac840
cttggtatcgagatccccgcccccaaggtcttcatcgcccagaagatgatgatcgccaag900
tgtaacatcaagggtaagcccgtcatctgtgccactcagatgctcgagtccatgacatac960
aaccctcgtcctactcgtgccgaggtgtccgatgttgccaacgccgtccttgacggtgcc1020
gactgtgtcatgctgtcgggagagaccgccaagggtaactaccccaacgaggccgtcaag1080
atgatgtccgagacctgcctgctcgccgaggttgccatcccccacttcaatgtgttcgat1140
gagctccgcaaccttgctcctcgccccaccgacactgtcgagtccatcgccatggctgcc1200
gttagcgccagtctggaactcaacgctggtgccattgtcgtcttgactaccagcggtaaa1260
actgctcgctacctttccaagtaccgccccgtctgccccattgtcatggttacccgtaac1320
cccgctgcctcccggtactctcacctgtaccgtggtgtctggcccttcctcttccccgag1380
aagaagcccgacttcaacgtcaaggtctggcaggaggatgttgaccgccgtctcaagtgg1440
ggtatcaaccacgctcttaagctcggcatcatcaacaagggtgacaacatcgtctgtgtc1500
cagggatggcgcggcggtatgggccacaccaacaccgtccgtgtggtccctgctgaggag1560
aaccttggcctggctgagtaa1581
<210>10
<211>34
<212>dna/rna
<213>bar-f(unknown)
<400>10
cacatctaaacaatgatgagcccagaacgacgcc34
<210>11
<211>34
<212>dna/rna
<213>bar-r(unknown)
<400>11
tcagtaacgttaagttaacatctcggtgacgggc34
<210>12
<211>43
<212>dna/rna
<213>p951(unknown)
<400>12
cattattatggagaaactcgagggactaacattattccagcac43
<210>13
<211>40
<212>dna/rna
<213>p952(unknown)
<400>13
ttatggatccgagctcgaattctgggtgttacggagcatt40
<210>14
<211>46
<212>dna/rna
<213>p1751(unknown)
<400>14
tgtatgctatacgaagttattctagaaccgctcatgcactggtagg46
<210>15
<211>46
<212>dna/rna
<213>p1752(unknown)
<400>15
ttgcatgcctgcaggggcccactagtaacaggctggctatggaagg46
<210>16
<211>40
<212>dna/rna
<213>p1749(unknown)
<400>16
tgaatgctccgtaacacccatggtgcctcaaatcctcacg40
<210>17
<211>40
<212>dna/rna
<213>p1750(unknown)
<400>17
catacattatacgaagttattgcggagcaacttggacaga40
<210>18
<211>47
<212>dna/rna
<213>p1352(unknown)
<400>18
atggagaaactcgagactagtaaatggaagagaaaacctccgagtac47
<210>19
<211>42
<212>dna/rna
<213>p1353(unknown)
<400>19
tcagtaacgttaagtggatccagatctctgcagggtaccgag42
<210>20
<211>58
<212>dna/rna
<213>ttrpc-f(unknown)
<400>20
acaatggaattcgagctcggtaccctgcagggatccacttaacgttactgaaatcatc58
<210>21
<211>50
<212>dna/rna
<213>ttrpc-r(unknown)
<400>21
gtagggccccccgggtctagaaagaaggattacctctaaacaagtgtacc50
<210>22
<211>20
<212>dna/rna
<213>p1949(unknown)
<400>22
ccgacactccatacacctcc20
<210>23
<211>19
<212>dna/rna
<213>p1950(unknown)
<400>23
ccagaagtgcgaggccaat19
<210>24
<211>22
<212>dna/rna
<213>p1951(unknown)
<400>24
ccagtaccaccgacctcttcag22
<210>25
<211>18
<212>dna/rna
<213>p1952(unknown)
<400>25
tcggtaaccacgggcaat18
<210>26
<211>20
<212>dna/rna
<213>p641(unknown)
<400>26
caatatcagttaacgtcgac20
<210>27
<211>20
<212>dna/rna
<213>p642(unknown)
<400>27
ggaaccagttaacgtcgaat20
<210>28
<211>50
<212>dna/rna
<213>p1977(unknown)
<400>28
tcatccgtcaagatggaattcatgggtgtctctaatatgatgtcccggtt50
<210>29
<211>43
<212>dna/rna
<213>p1978(unknown)
<400>29
tctctgcagggtaccgagctcttactcgcggagctcagtgggc43
<210>30
<211>42
<212>dna/rna
<213>p1981(unknown)
<400>30
taaacaatggaattcgagctcatggataccctactaaccgcg42
<210>31
<211>43
<212>dna/rna
<213>p1982(unknown)
<400>31
tcagtaacgttaagtggatccctagacaacatcttccacatgc43
<210>32
<211>43
<212>dna/rna
<213>p1937(unknown)
<400>32
tcatccgtcaagatggaattcatggttggaatcggtcctaagc43
<210>33
<211>48
<212>dna/rna
<213>p1938(unknown)
<400>33
tctctgcagggtaccgagctcttatagcagggtcttcatgtcagccat48
<210>34
<211>42
<212>dna/rna
<213>p2743(unknown)
<400>34
ttattatggagaaactcgagggactaacattattccagcacc42
<210>35
<211>42
<212>dna/rna
<213>p2744(unknown)
<400>35
ttatacgaagttatggatccaagaaggattacctctaaacaa42
<210>36
<211>42
<212>dna/rna
<213>p2745(unknown)
<400>36
tgtatgctatacgaagttatatggaagagaaaacctccgagt42
<210>37
<211>44
<212>dna/rna
<213>p2746(unknown)
<400>37
ttgcatgcctgcaggggcccggattacctctaaacaagtgtacc44
<210>38
<211>39
<212>dna/rna
<213>p1979(unknown)
<400>38
tcatccgtcaagatggaattcatggccgccagctcttcc39
<210>39
<211>40
<212>dna/rna
<213>p1980(unknown)
<400>39
tccagatctctgcagggtaccttactcagccaggccaagg40
- 还没有人留言评论。精彩留言会获得点赞!