核酸构建体和其制造方法与流程
1.本发明涉及可以用于许多应用中的新型人工合成的单链核酸分子以及用于制备所述单链核酸分子的模板和方法。单链核酸分子有许多用途,包含但不限于用于递送序列(例如,基因序列,或用于基因编辑、基因敲入或敲低的模板)的载体或用于生物工程中,例如用于从纳米颗粒结构单元构建高度有序的材料。单链核酸可以具有各种几何形状,并且可以提供功能,例如适配体和核酸酶。如果单链核酸用作载体,则这些可以用于将核酸序列/片段直接转移到靶细胞或被另外的组分包封。
背景技术:
2.人们越来越认识到核酸在细胞内承担的功能,所述功能不仅仅是编码蛋白质的生产。双链结构就其本质而言已经被广泛研究,但应当理解,由于互补核苷酸之间的碱基配对,所述双链结构可以在细胞中形成刚性组装。核酸的最柔性区域通常是非碱基配对的,并且包含参与细胞内的重要过程的单链脱氧核糖核酸(ssdna)和核糖核酸(ssrna)区域。例如,双链dna(dsdna)被如dna聚合酶等酶解旋,从而暴露ssdna部分。然后这些部分可用于转录成ssrna,如信使rna(mrna),或用于与识别ssdna的其它蛋白质相互作用。
3.单链核酸分子是将核酸递送到细胞的领域的技术人员特别感兴趣,因为核酸在经转染的细胞内是立即可获得的,并且不需要通过合适的酶“解旋”以暴露相关的基因信息(例如,用于转录和翻译或插入到基因组中)。单链核酸分子被认为是用于若干种应用的最佳递送载体,尤其是基因转移、基因编辑和生物传感。另一个潜在应用是提供dna疫苗。可替代地,单链dna可以具有与其构象相关的功能,即作为适配体。然而,较长的单链核酸(例如长度在数千个核苷酸的范围内的单链核酸)目前生产效率低下或不准确,从而限制了所述单链核酸的效用,如下文进一步讨论的。产生长寡核苷酸的最常见的方法是将序列克隆到质粒中以在细菌中培养,随后是限制性消化和纯化dsdna序列,然后将其进行链剥离以产生ssdna。尽管存在细菌繁殖问题,但仍存在许多效率低下和纯化问题。整个质粒主链序列被扩增,并且然后必须与细菌基因组一起被分离和丢弃。剥离二级链以揭示单链核酸分子又进一步降低了另外百分之五十的效率。
4.为了利用单链核酸的治疗潜力,需要一种高效且可扩展的制造方法,以制备商业规模的大量材料。目前的技术在以具有成本效益、准确、快速且安全的方式扩大规模生产材料的能力方面受到限制。还期望准确地产生长度为200个个核苷酸或更长的单链分子。
5.ssdna和dsdna供体序列两者均可以充当有效的基因编辑模板,但是供体构建体的选择通常由待引入的序列的长度决定。ssdna供体主要用于需要小编辑的应用,主要是因为已经发现产生较长的ssdna是有问题的,如以上所讨论的。已经发现ssdna模板在用于基因编辑时在修复特异性方面具有唯一优势(长ssdna供体对基于crispr的敲入的设计和特异性(design and specificity of long ssdna donors for crispr
‑
based knock
‑
in),han li、kyle a.beckman、veronica pessino、bo huang、jonathan s.weissman、manuel d.leonetti biorxiv 178905),并且因此其用途是令人期望的。
6.就其本质而言,线性单链核酸在细胞内会迅速降解,因为游离的3'和5'末端可用于如单链核酸酶等酶,其“咀嚼”末端并破坏核酸。因此,需要为此目的提供稳定的单链核酸构建体,其中保护游离的3'和5'末端免于立即降解。
7.用于将基因物质递送到细胞的许多病毒载体具有单链基因组,无论是rna还是dna,并且因此在基因递送中使用单链核酸是有先例的。
8.例如,腺相关病毒(aav)是一种有趣的基因疗法媒剂并且属于细小病毒家族,并且本质上依赖于与其它病毒(如腺病毒)的共感染,以便进行复制。aav基本上是围绕约4.7千碱基(kb)的单链dna基因组的蛋白质外壳。存在数百种唯一的aav菌株。其单链基因组尤其含有rep(复制)和cap(衣壳)基因。这些编码序列在两端侧接有长度通常为145个核苷酸的反向末端重复序列(itr)。
9.缺乏病毒dna的重组aav(raav)基本上是在基于蛋白质的纳米颗粒中保护的itr侧接的转基因,所述纳米颗粒被工程化以用于dna货物递送到细胞的细胞核中。设计这种raav载体的主要考虑因素是转基因的包装大小和两个itr之间的相关序列。5kb(包含病毒itr)似乎是目前的限制,以确保itr侧接的转基因被包装。可替代地,可以将itr侧接的转基因(或其它所关注序列)直接引入到细胞中而不进行包装,这意味着“人工基因组”确实可以更长。
10.本领域中通常使用的核酸分子,如源自病毒基因组的基因递送载体可能是有问题的,因为所述核酸分子可以在基因递送载体的受体中诱导免疫应答,因为免疫系统可以识别循环的“外来”dna。如果dna是在细菌细胞中产生的,则其将具有dna甲基化的原核模式,其在真核生物中可能被认为是外来的,并且类似地被拒绝。例如,质粒(pdna)是环状dsdna分子,其是天然存在的可以稳定地代代相传的额外染色体dna片段。质粒和其衍生物已经用作基因递送载体,并取得了不同程度的成功。
11.产生核酸载体的方法也可能是有问题的。在细菌细胞内制造核酸结构有终产物被脂多糖(lps)、内毒素和其它原核特异性分子污染的风险。这些具有在真核生物体中产生免疫应答的能力,因为其是微生物病原体的有效指标。实际上,在任何基于细胞的系统内制造核酸载体都会导致来自细胞培养物的污染物存在于终产物中的风险,包含来自宿主细胞的基因组材料。在细胞内产生核酸是低效的,因为需要供应比合成方法更多的材料来产生核酸。除了成本问题之外,在许多情况下,细胞培养物的使用可能会给扩增过程的再现性带来困难。在细胞的复杂生物化学环境中,难以控制期望的核酸产物的质量和产率。也难以处理可能对在其中扩增核酸的细胞有毒的序列。重组事件也可能导致所关注核酸的忠实产生出现问题。
12.dna可以在不使用细胞的情况下合成产生。寡核苷酸可以通过使用经修饰的核苷酸延伸链来化学合成。制备这些结构单元是有成本的。每个核苷酸的逐步添加都是不完善的过程(每个链被延伸的机会被称为“偶联效率”),并且对于较长序列,大部分起始链将不会变成全长正确的产物。这排除了大规模生产长序列的可能—对于这些过程,在长度、准确性与规模之间始终必须有所牺牲。此类寡核苷酸的主要用途仍然在低至数百个核苷酸的范围内(例如,引物和探针),并且最大准确长度被认为是长度为约300个核苷酸。通常,合成的寡核苷酸是长度约为15
‑
25个碱基的单链核酸分子。
13.合成过程的优选替代方案是依赖于模板的核酸酶促生产。用于合成核酸的无细胞
体外酶促过程避免了使用任何宿主细胞的需要,并且因此是有利的,特别是当生产需要符合良好制造规范(gmp)标准时。因此,可以更有效地制备酶促产生的核酸,并且没有细胞源性污染物的风险。
14.因此,需要酶促产生和改进的构建体,所述构建体更安全且受体耐受,理想的是还能抵抗细胞内的立即降解。
15.酶促制备单链脱氧核糖核酸(dna)载体可能是有问题的,因为如果聚合酶和引物与双链模板一起使用,则固有地会产生两条互补链。虽然这些链可以被分离并且不需要的链被丢弃,但是这仍然可以被视为加工资源的浪费。当扩大生产规模时,终产物中超过50%的起始材料的损失是不可持续的。
16.本发明具体地涉及一种高效且有效地制备单链核酸构建体的新型无细胞和体外方法,并且还涉及能够产生单链核酸构建体的模板。模板能够产生用于各种用途的任何期望长度的单链核酸多联体,包含单链核酸构建体的产生。由于核酸末端的隔离,这些构建体比简单的线性单链核酸更稳定。
17.现有技术没有公开制造具有多价螯合末端的单链核酸的方法或用于如本文所述的这种方法的模板。
18.各种文件描述了具有“加帽”末端的闭合线性双链dna的产生。touchlight ip的wo2018/033730涉及双链闭合线性dna分子,其将不适合用作本发明的模板,因为没有相邻的加工和构象基序。generation bio的wo2019/051255和wo2019/143885描述了由具有共价闭合末端(线性、连续且非衣壳化结构)的互补dna的连续链形成的线性双链体dna分子,其包括5'反向末端重复(itr)序列和3'itr序列。同样,这不适合用作根据本发明的模板分子。
19.若干rna结构是已知的,特别是在cripsr
‑
cas 9基因编辑领域中。在gorter de vries等人(《微生物细胞工厂(microb cell fact)》16,222(2017).https://doi.org/10.1186/s12934
‑
017
‑
0835
‑
1)中公开了两种可以自我加工的核酶侧接的grna。在ng等人(《分子生物学和生理学(molecular biology and physiology)》,2017年3月/4月,第2卷第2期,e00385
‑
16)中详述了类似结构。由侧接内部反式作用核酶的两种顺式作用核酶组成的三核酶(trz)构建体公开于benedict等人,《癌变(carcinogenesis)》1998年7月;19(7):1223
‑
30中。这种结构在所关注序列的两个末端缺乏相邻的构象和加工基序,从而使末端残基能够多价螯合在线性单链产物中。
20.附图简要说明
21.图1是本发明的模板的示例性图示;
22.图2是不同示例性模板的图示,并且示出了通过聚合酶作用于模板而产生的单链核酸的展开视图;
23.图3是对扩增本发明的模板的一种方法的描绘,通过所述扩增方法产生初生核酸链,对所述初生核酸链进行加工,从而产生具有多价螯合末端的单链核酸构建体;
24.图4提供了对图3的初生链的部分的两种描绘,其中示出了导致产生具有多价螯合末端的单链核酸构建体的加工步骤;
25.图5示出了模板连同扩增和加工步骤的替代性图示;
26.图6是描绘了实例2的结果的测定结果的凝胶照片,其中测试了核酸构建体对核酸外切酶降解的抗性;
27.图7是描绘了实例3的结果的测定结果的凝胶照片,其中测试了核酸构建体对细胞组分降解的抗性;
28.图8是aav2 itr的序列的图示连同本发明的具有itr样式结构的单链核酸的可能构象的图示;
29.图9是在实例1中使用的模板的图示;以及
30.图10是示出了实例1的结果的凝胶照片。
技术实现要素:
31.本发明的单链核酸分子具有多价螯合末端。本发明的单链核酸分子是线性单链核酸,因此在每个末端具有末端核苷酸。末端核酸残基不是游离的,即不像在未呈现任何进一步构象的纯线性单链核酸分子中那样暴露。因此,核酸的末端被固定或隐藏在构建体内并且不能立即被如单链核酸酶等酶接近。单链核酸的末端可以通过将末端核苷酸包含在用于保护末端的构象内而被多价螯合。因此,线性ssdna的每个末端处的末端核苷酸与可能作用于其以便开始降解核酸分子的任何药剂保持分开或远离。通常,酶定位末端核苷酸,并且从此残基开始咀嚼单链核酸。
32.单链核酸分子可以由模板核酸制备。这种模板核酸的设计是唯一的。
33.因此,本发明提供:
34.一种用于无细胞体外制造具有多价螯合末端的单链核酸分子的核酸模板,所述核酸模板包括编码以下元件的序列:
35.i)第一加工基序,所述第一加工基序与第一构象基序相邻;
36.ii)所述第一构象基序;
37.iii)所关注序列;
38.iv)第二构象基序,所述第二构象基序与第二加工基序相邻;
39.v)所述第二加工基序,
40.其中加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,并且其中所述构象基序包含能够形成分子内氢键的至少一个序列。
41.因此,本发明的模板编码如本文所述的单链核酸。所述单链核酸是线性的。线性单链核苷酸具有多价螯合末端。
42.可替代地描述的,可以使用在正向取向(加工基序然后是构象基序)或反向取向(构象基序然后是加工基序)上彼此相邻的加工基序和构象基序的组合。这些是格式化元件。
43.因此,模板可以包括以所描述的顺序编码以下元件的以下序列:
44.i)正向格式化元件;
45.ii)所关注序列;
46.iii)反向格式化元件。
47.本发明的模板可以使用任何合适的聚合酶进行扩增,以制造单链核酸产物。
48.所述单链核酸产物是线性的并且具有多价螯合末端。
49.模板可以是双链或单链的。模板的一条链与具有多价螯合末端的期望线性单链核
酸产物互补,并且因此指导其生产。模板在与聚合酶接触时指导产物的构建,并且因此模板被复制或扩增。术语扩增或复制在本领域中可以互换使用。
50.本发明的模板可以与能够进行滚环扩增(rca)的聚合酶接触。可以使用能够催化滚环扩增(rca)的聚合酶来扩增本发明的模板。rca是等温酶促过程,其中使用环状dna模板和特殊的dna或rna聚合酶合成长单链dna或rna。rca产物是含有与环状模板互补的数十到数百或数千个串联重复序列的串联体。因此,模板与聚合酶的接触可能导致模板的“扩增”,从而产生核酸的互补单链。
51.因此,可以使用能够进行滚环扩增或复制的聚合酶来扩增本文所述的任何模板。这导致产生长的单链多联体核酸分子。由于格式化元件(包括与构象基序相邻的加工基序,无论是正向取向还是反向取向)的存在,可以通过添加必需的核酸内切酶来简单地加工多联体。核酸内切酶在加工基序内的切割释放所关注序列,所述所关注序列在任一侧上侧接有构象基序。在释放时,这些构象基序通过形成固定末端核苷酸的氢键部分来多价螯合单链核酸的末端。因此,单链核酸分子中的构象基序确实呈现出使用氢键的构象,所述氢键多价螯合末端核苷酸。末端核苷酸可以通过包含在或涵盖在假定具有或不具有分子内碱基配对或氢键的构象内而被固定。可替代地,末端核苷酸可以通过分子内碱基配对或氢键固定,使得构象基序增加这些分子内相互作用的稳定性。
52.因此,线性单链核酸产物的末端残基是通过核酸内切酶对加工基序的作用形成的,一旦核酸内切酶切割较长的中间产物,末端残基就是分子末端处的残基。因此,格式化元件可以被描述为包括与构象基序相邻的加工基序,其中切割位点产生被构象基序多价螯合的末端残基。加工基序和构象基序可以被描述为相邻、邻接或连续的。可替代地描述的,在加工基序与构象基序之间没有外来的或间插的核酸序列。核酸内切酶的作用产生末端残基,所述末端残基随后被多价螯合。
53.因此,本发明提供:
54.一种制造具有多价螯合末端的单链核酸分子的方法,所述方法包括:
55.(a)使用能够进行滚环扩增的聚合酶扩增环状模板,其中所述模板包括编码以下元件的序列:
56.i)第一加工基序,所述第一加工基序与第一构象基序相邻;
57.ii)所述第一构象基序;
58.iii)所关注序列;
59.iv)第二构象基序,所述第二构象基序与第二加工基序相邻;
60.v)所述第二加工基序,
61.其中加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,并且其中所述构象基序包含能够形成分子内氢键的至少一个序列,
62.所述扩增产生核酸多联体,以及
63.(b)使用识别所述加工基序中的一个或多个加工基序中的所述切割位点的一种或多种核酸内切酶加工所述核酸多联体。
64.所产生的单链核酸是线性的,具有多价螯合末端。
65.可替代地,本发明包括:
66.一种制造具有多价螯合末端的单链核酸分子的方法,所述方法包括:
67.(a)使用能够进行滚环扩增的聚合酶扩增环状模板,其中所述模板包括编码以下元件的序列:
68.i)正向格式化元件;
69.iii)所关注序列;
70.iv)反向格式化元件,
71.其中正向格式化元件包括与构象基序相邻的加工基序,并且反向格式化元件包括与加工基序相邻的构象基序;加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,其中所述构象基序包含能够形成分子内氢键的至少一个序列,
72.所述扩增产生核酸多联体,以及
73.(b)使用识别所述加工基序中的一个或多个加工基序中的所述切割位点的一种或多种核酸内切酶加工所述核酸多联体。
74.本发明的单链核酸分子是线性的,具有多价螯合末端。
75.加工步骤产生具有多价螯合末端的单链核酸构建体。末端被多价螯合,因为在加工形式中,构象基序能够形成或呈现其期望的构象,所述期望的构象通过分子内氢键稳定。单链核酸分子的末端被构象基序呈现的构象多价螯合。末端核苷酸可以通过被包含在构象内而被固定,使得末端核苷酸在空间上难以被核酸外切酶接近,或被包含在构象基序内的分子内键中,其整体使得末端核苷酸对核酸外切酶更稳定。由于分子具有两个末端和两个构象基序,因此所述两个末端和两个构象基各自起作用以呈现涵盖相关末端或末端核苷酸的构象。由于核酸是线性的,因此分子具有两个末端,具有两个末端残基。
76.多联体是制造本发明的单链核酸分子期间的中间产物,但由于多联体作为所关注序列的多聚体连接链的组成,多联体可以具有其自身的一些效用,这可以用于增加所述序列在可能具有优势的应用中,例如在生物传感等中的局部浓度或效力。亲和力结合是一种可能的应用。
77.因此,本发明提供:
78.一种具有序列单元的两个或更多个重复序列的单链寡核苷酸多联体,所述序列单元包含以下元件:
79.i)第一加工基序,所述第一加工基序与第一构象基序相邻;
80.ii)所述第一构象基序;
81.iii)所关注序列;
82.iv)第二构象基序,所述第二构象基序与第二加工基序相邻;
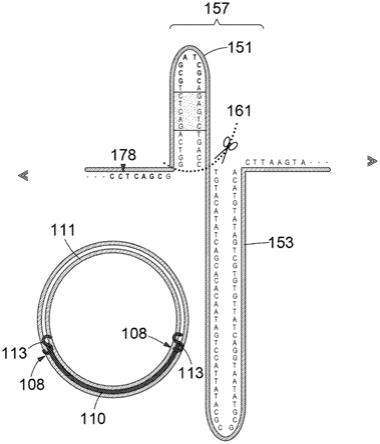
83.v)所述第二加工基序,
84.其中加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,并且其中所述构象基序包含能够形成分子内氢键的至少一个序列。
85.可替代地,本发明提供:
86.一种具有序列单元的两个或更多个重复序列的单链核酸多联体,所述序列单元包括以下元件:
87.i)第一加工基序,所述第一加工基序与第一构象基序相邻;
88.ii)所述第一构象基序;
89.iii)所关注序列;
90.iv)第二构象基序,所述第二构象基序与第二加工基序相邻;
91.v)所述第二加工基序,
92.其中加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,并且其中所述构象基序包含能够形成分子内氢键的至少一个序列。
93.本发明的单链核酸分子是线性的,具有多价螯合末端。
94.可替代地,如果加工基序和构象基序一起作为加工元件,本发明提供:
95.一种具有序列单元的两个或更多个重复序列的单链寡核苷酸多联体,所述序列单元包含以下元件:
96.i)正向格式化元件;
97.iii)所关注序列;
98.iv)反向格式化元件,
99.其中正向格式化元件包括与构象基序相邻的加工基序,并且反向格式化元件包括与加工基序相邻的构象基序;加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶的识别位点和相关切割位点,其中所述构象基序包含能够形成分子内氢键的至少一个序列。
100.本发明的单链核酸分子是线性的,具有多价螯合末端。
101.构象基序的末端核苷酸,或者实际上单链核酸构建体的末端核苷酸通常是与加工基序相邻并通过核酸内切酶的作用从多联体核酸“释放”的核苷酸。正是这种末端核苷酸形成单链核酸构建体的末端,并且被适当地多价螯合以延迟降解。
102.正向格式化元件包括与构象基序相邻的加工基序,并且反向格式化元件包括与加工基序相邻的构象基序。这种排列确保了所关注序列在加工后在每个末端均侧接有构象基序。因此,所关注序列在构建体中侧接有两个构象,所述两个构象各自多价螯合核酸的末端。
103.附图详细说明
104.图1是本发明的模板(100)的示例性图示。示出了编码第一加工基序和第二加工基序(101和102)、第一构象基序和第二构象基序(103和104)、所关注序列(105)、含有切割位点的核酸内切酶的识别位点(106和107)和模板中的切口位点(108)的序列。
105.图2是不同示例性模板(100)的图示,其中模板被描绘为双链环状核酸构建体,其中示出了切口位点(108),连同主链序列(110)和用于产生单链核酸构建体的序列(111),在每个末端以编码格式化元件(113)的序列终止。示出了在格式化元件(113)处通过模板链的聚合酶扩增产生的单链核酸的展开视图。这描绘了切口位点(178)、第一加工基序(151)、第一构象基序(153)和含有切割位点的核酸内切酶的识别位点(161)。第一加工基序和第一构象基序相邻,仅由切割位点分开,所述第一加工基序和第一构象基序一起形成格式化元件(157)。
106.图3是对扩增本发明的模板(100)的一种方法的描绘,使用模板的滚环扩增产生初
生核酸链(150)。在初生链上,示出了第一加工基序(151)、第二加工基序(152)、第一构象基序(153)、第二构象基序(154),其与所关注序列一起形成核酸构建体(156)和主链序列(155)的基础。描绘了包含切割位点(未示出)的格式化元件(157)。使用识别切割位点的必需酶(未示出)加工初生链,从而产生具有多价螯合末端(160)的单链核酸构建体,以及由模板主链(158)和加工基序(159)产生的副产物。
107.图4提供了对图3的初生链的部分的两种描绘,其中示出了导致产生具有多价螯合末端(160)的单链核酸构建体与副产物的加工步骤。根据所利用的构象基序的类型,构建体的3'和5'末端的构象或结构可能发生变化。
108.图5示出了模板(200)的替代性图示。示出了编码第一加工基序和第二加工基序(201和202)、第一构象基序和第二构象基序(203和204)、所关注序列(205)、含有切割位点的核酸内切酶的识别位点(206和207)和模板中的切口位点(208)的序列。还示出了由模板产生的初生核酸链(250)。在初生链上,示出了第一加工基序(251)、第二加工基序(252)、第一构象基序(253)和第二构象基序(254),其与所关注序列(255)一起形成核酸构建体。切割位点(256和257)在格式化元件(281和282)内形成。使用识别切割位点的必需酶加工初生链,从而产生具有多价螯合末端(260)的单链核酸构建体与副产物(未示出)。
109.图6是描绘了实例2的结果的测定结果的凝胶照片(0.8%tae琼脂糖凝胶,1x gelred染色剂)。凝胶上的通道如下:
[0110][0111]
核酸构建体按照实例2进行标记。
[0112]
图7是描绘了实例3的结果的测定结果的凝胶照片(0.8%tae琼脂糖凝胶,1x gelred染色剂)。凝胶上的通道如下:
[0113][0114]
核酸构建体按照实例2进行标记。
[0115]
图8a是aav2 itr的构象的图示。aav2 itr由嵌入较大茎回文(a
‑
a')中的两个臂回文(b
‑
b'和c
‑
c')构成。itr可以获得两种构型(正和反(flip and flop))。正构型(所描绘的)和反构型分别具有最靠近3'末端的b
‑
b'和c
‑
c'回文体。d序列在基因组的每个末端仅存在一次,因此保持单链。加框基序与rep结合元件(rbe)相对应。图8b和8c是本发明的线性单链核酸的模板(i),随后是(ii)切割之前和(iii)切割之后的模板的单链产物的图示。图8b包含如野生型aav itr中的单链d区。图8c通过将d区与d'区配对而包含构象基序内的d区,并且因此所述d区位于双链部分中。
[0116]
图9是实例1中使用的模板(质粒图谱)的图示。示出了:所关注序列、构象基序、加工基序、主链和加工酶(mlyi)的位点。还描绘了切口核酸内切酶(bsrdi,其可以例如被nb.bsrdi的变体切口)的位点;以及
[0117]
图10是示出了两个通道的凝胶照片(0.8%tae琼脂糖凝胶,1x safeview染色剂),第一通道是标志物通道,并且第二通道示出了根据实例1使用图9的模板制备的核酸构建体。
具体实施方式
[0118]
本发明满足了体外制备大量单链核酸分子的高效、无细胞、酶、成本有效、准确和
清洁的方法的需要。为了增加用于基于细胞的用途的单链核酸分子的寿命,本发明人已经设计了通过多价螯合这些末端来保护单链核酸分子的末端免于立即降解的巧妙方式。
[0119]
多价螯合末端
[0120]
所有线性核酸分子的关键特征在于其是包括核苷酸残基的聚合物并且具有两个独特的末端。末端的性质是由核酸主链的性质决定的。对于天然(非合成)核酸分子,这两个末端是5'(5
‑
prime)和3'(3
‑
prime)末端。在天然核酸(即,dna或rna)中,5'末端是分子的终止于5'磷酸基团的末端。按照惯例,核酸序列的书写顺序是5'末端在左边并且3'末端在右边,并且本文中所叙述的顺序与所述惯例一致。3'末端是分子的终止于3'磷酸基团的末端。通常在天然核酸中,在一个核苷酸的磷酸基团与另一个核苷酸的糖之间形成磷酸二酯键以形成主链。使用核苷酸中碳编号的化学惯例,磷酸基团是核苷酸的5'末端,因为其与糖的5'碳键合。在一个核苷酸的5'末端与另一个核苷酸的3'羟基之间形成磷酸二酯键,从而形成具有一个开放的5'末端和一个开放的3'末端的聚合物。因此,5'末端可以被认为是具有5'磷酸基团的末端残基。因此,3'末端可以被认为是具有3'羟基的末端残基。对于dna和rna,这些末端残基是核苷酸残基。
[0121]
在本发明中,线性单链核苷酸的末端是通过核酸内切酶对本发明的方法的中间产物的作用形成的。因此,构象基序的末端残基变成单链核酸产物的末端残基。在切割之前,此残基有效地将构象基序与加工基序连接起来。
[0122]
核酸仅可以在5'
‑
至
‑
3'方向上体内合成,因为组装新链的聚合酶通常依赖于通过断裂核苷三磷酸键以通过磷酸二酯键将新的核苷单磷酸连接到3'
‑
羟基(
‑
oh)基团而产生的能量。实体的沿着核酸链的相对位置,包含基因和各种蛋白结合位点,通常被认为是上游(朝向5'末端)或下游(朝向3'末端)。本质上,由于dna的反平行性质,这意味着模板链的3'末端在基因的上游并且5'末端在下游。
[0123]
对于完全合成的非天然(合成)核酸,可以根据主链结构标记末端。例如,如果检查肽核酸(pna),则糖磷酸主链已经被n
‑
(2
‑
氨乙基)甘氨酸的单元取代。然后,4个天然碱基中的每个天然碱基都通过亚甲基羰基连接子连接到主链。pna具有n末端和c末端,而不是5'和3'末端。
[0124]
在本发明中,线性核酸分子的末端是多价螯合的,无论这些末端的命名如何。因此,这些末端的处的末端残基或末端核苷酸不是游离的或暴露的。对于天然核酸,如dna和rna,这些末端残基是末端核苷酸,并且是3'和5'末端。对于合成核酸,这些末端可以具有其适当的命名。
[0125]
每个多价螯合的末端是稳定的,因此所述末端不再可用于与如单链核酸酶等酶的立即反应。如果核酸用于细胞环境,则将末端与可能导致单链核酸立即降解的细胞组分远离、屏蔽或隔离。因此,在没有多价螯合的情况下,单链核酸分子的末端不会像其通常那样起作用。与没有多价螯合末端的类似分子相比,末端的多价螯合赋予分子增强的稳定性。诸位发明人在实例1中证明了这一点,其中没有多价螯合末端的类似分子被降解,而本发明的分子保持完整。
[0126]
优选的是末端通过构象基序的存在而被多价螯合。构象基序具有特定序列。构象基序的序列被设计成使得能够形成分子内氢键,以形成或呈现特定构象。当在单链核酸构建体中呈现构象时,末端核苷酸被基序多价螯合,这意味着其已被固定。
[0127]
分子内氢键可以在构象基序序列本身内,或者可以在构象基序的一部分或部分与整个单链核酸分子中的至少一个如所关注序列等其它序列之间。分子内氢键可以包含或可以不包含末端核苷酸。
[0128]
氢键是分子之间或分子内、分子间或分子内的非共价类型的键。这些键由电负性原子(氢受体)和与同一分子或不同分子的另一个电负性原子(氢供体
‑
仅氮、氧和氟原子起作用)共价连接的氢原子形成。这些键是最强种类的偶极
‑
偶极相互作用。氢键负责dna双螺旋中的特定碱基对形成,并且是dna双螺旋结构稳定性的因素。
[0129]
通常,在沃森
‑
克里克碱基配对中,在核苷酸(核碱基)的含氮碱基之间形成氢键。在标准碱基配对(所述标准碱基配对是dna中的腺嘌呤
‑
胸腺嘧啶(a
‑
t)、rna中的腺嘌呤
‑
尿嘧啶(a
‑
u)以及dna和rna两者中的胞嘧啶
‑
鸟嘌呤(c
‑
g))中,氢键形成。a
‑
t/u和c
‑
g配对的作用是在互补碱基上的胺与羰基之间形成双或三氢键。
[0130]
摆动碱基对是核酸分子中的两个核苷酸之间的不遵循标准的沃森
‑
克里克碱基对规则的配对,最显著地在rna中。四个主要摆动碱基对是鸟嘌呤
‑
尿嘧啶(g
‑
u)、次黄嘌呤
‑
尿嘧啶(i
‑
u)、次黄嘌呤
‑
腺嘌呤(i
‑
a)和次黄嘌呤
‑
胞嘧啶(i
‑
c)。摆动碱基对的热力学稳定性与沃森
‑
克里克碱基对的热力学稳定性相当。摆动碱基对是rna结构中的基础。
[0131]
替代性或非规范碱基配对在核酸结构中也是可能的,再次通过氢键结合在一起。这些通常在rna中更常见,但在dna和其它核酸中也是可能的。非规范碱基配对的一个实例是胡斯坦碱基配对和反向胡斯坦碱基配对。在这些相互作用中,嘌呤碱基、腺嘌呤和鸟嘌呤翻转了其正常取向,并且与其配偶体形成一组新的氢键。胡斯坦氢键已经显示存在于四链体中,如本文更详细地讨论的i
‑
基序和g
‑
四链体。
[0132]
还可以设想各种碱基配对机制的组合。例如,当形成规范b型dna中的a
‑
t和g
‑
c碱基对中的氢键时,核碱基中的若干个氢键供体和受体基团保持未使用。每个嘌呤碱基在暴露于大沟中的边缘上均具有两个这种基团。三链体dna可以在双链体与第三寡核苷酸链之间分子间形成。第三链碱基可以与b型双链体中的嘌呤形成胡斯坦型氢键。
[0133]
碱基对也可以在天然碱基与非天然碱基之间形成,并且也可以在非天然碱基对之间形成。
[0134]
因此,碱基配对是使构象基序能够呈现相关构象的分子内氢键的实例。如果构象基序依赖于碱基配对来多价螯合末端核苷酸,则在所述基序内可能存在与单链核酸构建体中的其它地方(即,所关注序列内)的序列碱基配对的序列。可替代地,构象基序内的序列可以被设计成与构象基序内的至少一个其它序列碱基配对,使得在基序本身内形成氢键。设想了任何类型的碱基对,包含根据标准沃森
‑
克里克配对在“非互补”核苷酸之间形成的碱基对。
[0135]
分子内氢键也可以是未被定义为经典碱基配对的相互作用,例如鸟嘌呤残基在g
‑
四链体的g
‑
四分体中的平面排列,其通过胡斯坦氢键稳定。这些结构将在下面进一步讨论。
[0136]
另外,核酸分子的稳定化也可以依赖于碱基堆叠相互作用。pi
‑
pi堆叠(也称为π
–
π堆叠)是指芳香环之间具有吸引力的非共价相互作用,因为其含有pi键。这些相互作用在已经通过氢键结合在一起的核酸分子内的核碱基堆叠中非常重要。因此,单链核酸构建体很可能通过碱基堆叠相互作用进一步稳定。稳定核酸的其它相互作用也是可能的,这些相互作用包含pi
‑
阳离子相互作用、范德华相互作用(van der waals interaction)和疏水相互
作用。
[0137]
一方面,构象基序被设计成包含能够形成碱基配对部分的序列。碱基配对部分可以在碱基配对部分中包含适当数量的核苷酸。在一些方面,碱基配对部分可以由核苷酸序列形成。由于需要保持构象,因此碱基配对部分的长度可能为至少5个碱基对。碱基配对部分可以包含至少2个核苷酸或2
‑
5个核苷酸或5个核苷酸,或可以包含5个或更多个核苷酸,即,5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个或更多个核苷酸。在一些情况下,碱基配对部分可以包含更多的核苷酸,以便牢固地多价螯合末端核苷酸。因此,碱基配对部分的长度可以为1
‑
50个或1
‑
100个核苷酸,或实际上为1
‑
250个核苷酸或更多。
[0138]
末端核苷酸残基可以与包含构象基序的单链核酸构建体的另一部分分子内氢键合。一方面,末端核苷酸与构建体中的另一个核苷酸形成碱基对。
[0139]
然而,末端残基可以不含氢键或更具体地碱基配对。在这种情况下,构象基序通过涵盖、环绕或包围末端核苷酸来固定或多价螯合末端核苷酸,使得构象基序对于单链核酸酶而言不游离以将其从构建体中的相邻核苷酸切割下来(并且然后切割相邻的核苷酸等)。换句话说,末端在空间上被保护而不会降解,因为较大的实体不可能到达末端。举例来说,末端核苷酸可以固定在四链体基序内。
[0140]
可能简单的是,多价螯合的是单链核酸分子的每个末端的末端残基。可替代地,相邻的一个或多个残基也可以被多价螯合。至少5个或更多个、10个或更多个、15个或更多个、20个或更多个、25个或更多个、50个或更多个残基也可以与末端残基一起被多价螯合。
[0141]
在另外的方面,每个末端可以通过形成至少包含分子末端处的末端残基的双链体而被多价螯合。双链体是通过核苷酸序列之间的碱基配对形成的。这些序列可以是相邻的(发夹)或分离的(茎环等)。
[0142]
残基是指构成如核苷酸等核酸聚合物的单个单元。
[0143]
在另外的方面,优选的是,用于多价螯合单链核酸构建体的末端或末端核苷酸的碱基配对或双链体部分形成在构象基序内。因此,构象基序包含能够形成碱基配对或双链体部分的自我互补序列。这些可以是相邻的或被非互补序列隔开。
[0144]
在其它方面,用于多价螯合单链核酸构建体的末端或末端核苷酸的碱基配对或双链体部分形成在构象基序的外部。因此,其可以涉及所关注序列的一部分,或者实际上是可以引入到核酸构建体内的间隔子序列(即“所关注序列”中的2个编码区之间)。因此,所获得的构象可以是套索,所述套索是单链核酸的环,其包括退火的互补序列或包括末端残基的双链体的一部分。
[0145]
在本文进一步讨论的一些令人感兴趣的方面中,末端可以被多价螯合在如四链体等构象内。这些是四链(四链的(four stranded))结构,其可以涉及染色体的端粒末端的结构。底层模式是四分体,4个残基的平面排列,通过胡斯坦氢键和与中心阳离子的配位而稳定。四链体通过堆叠多个四分体而形成。根据序列最初如何折叠成这些排列,可以形成许多不同的拓扑结构。可以通过存在阳离子,尤其是钾,进一步稳定四链体结构,所述阳离子位于每对四分体之间的中心通道中。已经显示四链体在dna、rna、lna和pna中是可能的,并且可以是分子内的。
[0146]
示例性四链体包含g
‑
四链体,其由富含g的序列和由富含胞嘧啶的序列形成的i
‑
基序(嵌入基序)形成。
[0147]
因此,一方面,末端核苷酸被多价螯合在四链体,任选地是g
‑
四链体或i
‑
基序内。
[0148]
构象基序
[0149]
期望产物之一是单链核酸分子或构建体,其由任何合适的核酸,但优选地dna或rna构成,其含有在两侧上侧接有多价螯合单链的末端的构象基序的所关注序列。因此,单链核酸构建体具有第一(通常在5'末端处)构象基序和第二(通常在3'末端处)构象基序。每个构象基序都可以是唯一的,但其都具有能够多价螯合单链的末端的性质。
[0150]
单链核酸分子或构建体可以包含任何合适的构象基序,如关于多价螯合末端所讨论的。
[0151]
构象基序包括能够形成分子内氢键的序列。这些氢键可以是任何种类的碱基对,或在如四链体(tetraplex)/四链体等结构中看到的胡斯坦型氢键。
[0152]
值得注意的是,构象基序可以是包含一个或多个序列部分的序列,所述一个或多个序列部分能够与另一序列部分在构象基序本身内或单链核酸内的其它地方形成碱基对。
[0153]
因此,构象基序可以仅仅包含“互补”的两个序列部分和所述碱基对,以形成反平行或实际上平行的双链体。此双链体可以包含或可以不包含单链核酸的末端残基(即,3'或5'末端)。在这种情况下,构象基序可以形成发夹(两个部分是连续的)或茎环(如果两个部分被间隔子序列隔开,从而留下单链核酸)。应当理解,这种结构可以通过在构象基序中包含反向重复序列来实现。回文序列是双链核酸序列的一部分,其中在一个部分上的5'到3'正向阅读的序列与其形成双链体的互补部分上的5'到3'正向阅读的序列相匹配。
[0154]
因此,构象基序可以包含形成以下中的一个或多个所必需的序列:发夹、茎环或假结。所有这些构象均具有共同的可以形成双链体的两个序列部分。替代性结构包含套索或套索(lasso),其还包含可以形成双链体的序列部分。
[0155]
构象基序可以是不同构象的杂合体,如具有被设计成形成双链体的另外序列的g四链体,以便通过直接碱基配对来多价螯合末端。所需要的是构象基序可以固定末端核苷酸。
[0156]
具有单链dna或rna基因组的生物体或基因物质可以在生命周期的一部分中以单链形式存在的生物体,已经进化为通过使用特定结构或通过其它方式(包含蛋白质的定位)来保护核酸的游离末端。实际上,哺乳动物基因组已经进化出使用端粒来保护可能存在单链突出端的染色体末端。
[0157]
例如,aav使用itr保护单链dna基因组的末端。腺相关病毒(aav)是细小病毒家族的非致病成员。野生型aav基因组含有通常在两个末端处由145个核苷酸组成的反向末端重复序列(itr)。每个itr的末端125个核苷酸可以自退火,以形成回文双链t形发夹结构,其中小回文b
‑
b'和c
‑
c'区形成横臂并且大回文a
‑
a'区形成茎。每个结构之后是唯一大约20个核苷酸的d(或d')区。重组aav(raav)的产生可以不受itr内的截短的影响,从而导致长度为137个核苷酸或更少。在自然界中,itr用作复制起点并且由嵌入到较大茎回文体(a
‑
a')中的两个臂回文体(图8a
‑
b
‑
b'和c
‑
c')构成。itr可以获得两种构型(正和反)。正构型(在图8a
–
aav2中描绘的)和反构型分别具有最靠近3'末端的b
‑
b'和c
‑
c'回文体。加框基序与aav rep蛋白结合的rep结合元件(rbe)相对应。rbe可以由具有共有序列5'
‑
gngc
‑
3'的四核苷酸重复序列组成。
[0158]
先前已经显示(ping等人,《分子生物技术(mol biotechnol)》doi 10.1007/
s12033
‑
014
‑
9832
‑
3),单链dna中的d区的存在(如图8b所示)可能对由重组aav载体携带的转基因的表达有害。据认为,d区提供了人蛋白的结合位点,所述人蛋白优先地与此区域结合并且防止第二链合成(qing等人,《美国国家科学院院刊(proc.natl.acad.sci.usa)》,第94卷,第10879
‑
10884页,1997年9月,《医学科学(medical sciences)》以及kwon等人,《人基因疗法(human gene therapy)》,doi:10.1089/hum.2020.018)。因此,如果意图在细胞内表达转基因,则可能不期望在本发明的单链dna中包含d区,并且这可以通过去除序列或在构象基序内提供序列来完成,使得d区与如图8c所示的d'区配对。因此,不仅存在d区,而且还存在配对的d'区。这种配对可以提供itr样式结构的另外的稳定化。另外,双链d区的存在可以允许转录因子(如rfx)结合,并且还潜在地增强核转运(julien等人,《科学报告(sci rep.)》,2018年1月9日;8(1):210.doi:10.1038/s41598
‑
017
‑
18604
‑
3)。d区的存在的另外的优点可能是此区域的存在抑制宿主体液免疫应答的潜力。kwon等人已经证明,d序列可以抑制mhc
‑
ii基因的表达。因此,如果d区存在,但呈双链形式,则其具有以下优点:抑制宿主免疫应答并且避免当d区呈单链形式时观察到的第二链合成的抑制,同时潜在地提供用于核转运的机制。因此,期望在核酸构建体内,特别是在构象基序中存在双链d区。
[0159]
因此,本发明延伸到具有多价螯合末端的线性单链核酸分子,其中至少一个末端包括包含双链d区的itr结构。所述d区可以与d'区呈双链体。如本文所使用的,d'区与d区充分互补以允许在两个序列之间形成双链体。d区可以是天然的d区序列(在图8a中
–
aggaacccctagtgatggag,seq id no.2,如seq id no.3到6所呈现的各种血清型变体)或与其具有足够同源性,如至少80%、85%、90%、95%或99%同源性的序列。本发明的线性单链dna可以包含如本文所述的一个或两个itr末端。这些末端可以相同或不同。这种结构的优点是可以表达任何转基因,同时可以暂时抑制宿主免疫系统。
[0160]
因此,单链核酸构建体的构象基序可以是取自任何aav血清型的itr序列。构象基序可以是基于来自任何aav血清型的itr的衍生序列,例如一个或多个元件可以被修改、改变或替代。可以去除rbe,或者可以修改任一回文体的长度,这取决于单链核酸构建体将应用的用途。构象基序可以是与天然aav itr序列完全不同的序列,但仍维持类似的结构。本领域的技术人员将理解如何使用适当的自互补序列来设计将形成双臂回文体的序列。
[0161]
其它病毒基因组也依赖于其线性基因组末端处的多价螯合末端。hiv至少具有5'多价螯合末端。
[0162]
可替代地,可以考虑使用折叠结构,如g
‑
四链体和嵌入基序(i
‑
基序)。i
‑
基序和g
‑
四链体是由dna形成的四链四链体结构;i
‑
基序由富含胞嘧啶的dna区域形成,并且g
‑
四链体通过富含鸟嘌呤的dna形式形成。由于在低于生理学的ph值下特别稳定,因此i
‑
基序在纳米技术和纳米医学方面具有潜在应用,并且已经用作生物传感器、纳米机器和分子开关。
[0163]
g
‑
四链体的序列是变化的,并且可以由推定的化学式定义:(g
3+
n1‑
n
g
3+
n1‑
n
g
3+
n1‑
n
g
3+
),其中n是任何核苷酸,包含鸟嘌呤。鸟嘌呤之间的残基数量限定了环的长度。已经观察到大于7个核苷酸的环。
[0164]
因此,构象基序呈现由氢键保持的构象,所述氢键可以通过相互作用(如碱基堆叠)进一步稳定。这些构象实际上可以通过小分子或离子的存在而进一步稳定,下面给出了构象的实例。
[0165]
例如,四链体(可替代地称为四链体)可以围绕中心离子络合。许多配体(小分子和
蛋白质两者)均可以与四链体结合。这些配体可以是天然存在的或合成的。已经发现,所有表征的g
‑
四链体结合蛋白共享被称为niqi(新的有趣的四链体相互作用基序)的20个氨基酸长的基序/结构域(rgrgr grggg sggsg grgrg
–
seq id no.7),其类似于先前描述的fmr1 g
‑
四链体结合蛋白的富含rg的结构域(rrgdg rrrgg ggrgq ggrgr gggfkg
–
seq id no.8)。已经显示,阳离子卟啉与g
‑
四链体嵌入结合。匹配具有堆叠四重体的四链体和将其保持在一起的核酸环可能很重要。π
‑
π相互作用可以是用于配体结合的重要决定因素。配体应该对平行折叠的四链体具有更高的亲和力。还考虑了与其它构象基序结合以稳定其的配体。
[0166]
构象基序多价螯合单链核酸分子的末端,并且通常形成特定结构。构象基序可以被设计成使得这种结构具有其自身的功能,进一步多价螯合末端。例如,构象基序可以被设计成使得由构象基序或核酶、脱氧核酶和核糖开关形成适配体。适配体由于静电相互作用、疏水相互作用及其互补形状而与特定靶标结合。可以通过重复轮次的体外选择或selex(配体指数增强系统进化技术)工程化适配体序列,以与如小分子、蛋白质、核酸等各种分子靶标结合并且甚至与如细胞、组织和生物体等较大实体结合。可替代地,构象基序可以被设计成包含促进穿过细胞膜或核膜的序列。另外或可替代地,构象基序可以被设计成允许使用核酸构建体形成寡聚复合物,其可以用于纳米技术等。
[0167]
核酸构象可能会受到条件变化的影响。应选择构象基序的序列,使得在待使用核酸构建体的条件(即,ph、温度、盐浓度、压力、蛋白质浓度、糖浓度、渗透压等)下采用构象。
[0168]
核酸构建体可以在许多不同的条件,如生理条件或有利于在例如电子学中使用这项技术的条件下使用。
[0169]
生理条件是生物体或细胞系统在自然界中可能发生的外部或内部环境的条件,并且可以是构象基序呈现相关构象的适当条件。
[0170]
如果核酸构建体用于非细胞目的,即在纳米技术中,则可以根据需要在相关缓冲溶液中或实际上在纯水中实现构象。
[0171]
因此,构象基序在多联体前体分子中可以呈单链形式,这些可以是假定没有构象或者实际上没有构象是可能的条件。在多联体前体中,应当理解,末端残基与加工基序邻接。基序的相邻性质允许产生具有多价螯合末端的线性单链核酸分子。
[0172]
所关注序列
[0173]
单链核酸构建体还包括所关注序列。应当理解,所关注序列可以含有多于一个序列,并且实际上可以含有许多序列,例如若干个基因序列可以包含在“所关注序列”内,如果需要,所述基因序列中的每个基因序列可以具有相关启动子和增强子元件。
[0174]
所关注序列还可以包含间隔子序列,所述间隔子序列包含与构象基序的序列具有互补性的序列,以使碱基配对部分能够形成以多价螯合末端或末端核苷酸。
[0175]
这种所关注序列可以是任何合适的序列,或包含任何数量的序列。序列本身可以具有功能,如形成适配体、核酸酶、核酶、脱氧核酶、核糖开关、小干扰rna等。所关注序列可以编码产物,所述产物可以是适配体、蛋白质、肽或如小干扰rna等rna。所关注序列可以包含包括一个或多个启动子或增强子元件和编码所关注mrna或蛋白质的基因或其它编码序列的表达盒。表达盒可以包括与编码所关注蛋白质的序列可操作地连接的真核启动子,以及任选地增强子和/或真核转录终止序列。
[0176]
可替代地,所关注序列可以被设计成是载体序列。因此,所关注序列可以与可以与
其退火的另一个单独序列充分互补,使得整个单链核酸载体通过与单链部分形成双链体而有效地用作另一个分子的递送机制。单独的寡核苷酸可以是完全合成的。在这种情况下,单链产物充当“载体”分子。
[0177]
所关注序列可以用于产生用于在宿主细胞中表达的dna,特别是用于产生dna疫苗。dna疫苗通常编码感染性生物体的dna的修饰形式。将dna疫苗施用于受试者,然后在所述受试者中所述疫苗表达感染性生物体的所选蛋白质,从而引发针对通常具有保护性的蛋白质的免疫应答。dna疫苗还可以在癌症免疫疗法方法中编码肿瘤抗原。
[0178]
所关注序列可以产生其它类型的治疗性dna分子,例如用于基因疗法的分子。例如,在受试者患有由功能性基因的功能失调形式引起的遗传疾病的情况下,此类dna分子可以用于表达所述基因。此类疾病的实例是本领域众所周知的。
[0179]
所关注序列可能能够在动物和植物中充当用于基因编辑目的的供体核酸。基因编辑的示例性方法包含基于crispr基因编辑和转录激活因子样效应物核酸酶(talen)的方法。
[0180]
本发明的新型结构还可以具有非医学用途,包含在材料科学、纳米技术、数据存储等中,并且可以相应地选择所关注序列。核酸可以用于生物电池、物体的安全标记或作为生物分子电子组件。
[0181]
对于治疗用途而言,特别优选的是,具有多价螯合末端的单链核酸构建体缺乏细菌复制起点、缺乏抗性基因(即,对于抗生素)、缺乏cpg岛(除了同样可能有帮助的dna疫苗之外)、缺乏胞嘧啶和腺嘌呤的甲基化并且缺乏将核酸鉴定为对于宿主细胞是外来的序列(如果构建体用于细胞用途)。
[0182]
单链核酸构建体可以是天然核酸分子,如dna或rna。优选的是,单链核酸构建体是dna。单链核酸构建体也可以是非天然核酸分子。非天然核酸分子或异种核酸(xna)的实例包含1,5
‑
脱水己糖醇核酸(hna)、环己烯核酸(cena)、苏糖核酸(tna)、乙二醇核酸(gna)、锁核酸(lna)、肽核酸(pna)和fana。hachimoji dna是一种合成核酸类似物,其除了天然核酸dna和rna中存在的四/五个核苷酸之外还使用四个合成核苷酸。酶已经被工程化、突变或开发以便识别合成核酸分子,并且因此本发明的方法和产物同样适用于这些类似物或合成和天然核酸的杂交体及其嵌合体。
[0183]
制备单链核酸分子/构建体
[0184]
单链核酸构建体可以使用唯一方法通过滚环扩增独特的模板,并且然后对由这种扩增产生的单链核酸多联体进行加工来制备。
[0185]
制造具有多价螯合末端的单链核酸构建体的方法依赖于通过用相关聚合酶滚环扩增来扩增模板核酸(“序列单元”),从而导致产生具有由模板编码的序列单元的多个重复序列的长的单链核酸。然后可以将此多联体单链核酸加工成具有多价螯合末端的产物,单链核酸。
[0186]
扩增过程将需要添加底物(即,用于核酸生成的适当核苷)和任何辅因子(如盐、离子等)。适当条件包含缓冲液的存在和酶可以运行的温度。用于滚环扩增的适当条件可以是等温的。
[0187]
扩增是核酸模板的多个拷贝的产生,或与核酸模板互补的多个核酸序列拷贝的产生。在本发明的方法中,优选的是,扩增是指与核酸模板互补的多个核酸序列拷贝的产生。
[0188]
优选的是,在模板是双链的情况下,使用技术来确保与期望产物互补的链用作模板。这可以通过下面进一步讨论的若干种方法来实现。
[0189]
当使用时,核苷是其中核酸碱基(核碱基)与糖部分连接的化合物。核酸碱基可以是天然的或经修饰的/合成的核碱基。核酸碱基可以包含嘌呤碱基(例如,腺嘌呤或鸟嘌呤)、嘧啶(例如,胞嘧啶、尿嘧啶或胸腺嘧啶)或脱氮杂嘌呤碱基等。核酸碱基可以是核糖或脱氧核糖糖部分。糖部分可以包含天然糖、糖替代物、经取代的糖或经修饰糖。核苷可以含有糖部分的2'
‑
羟基、2'
‑
脱氧或2',3'
‑
双脱氧形式。
[0190]
核苷酸或核苷酸碱基是指核苷磷酸。这包含天然的、合成的或经修饰的核苷酸,或替代的取代部分(例如,肌苷)。核苷磷酸可以是核苷单磷酸(nmp)、核苷二磷酸(ndp)或核苷三磷酸(ntp)。核苷磷酸中的糖部分可以是戊糖,如核糖。核苷酸可以是但不限于脱氧核糖核苷三磷酸(dntp)或核糖核苷三磷酸(rntp)。
[0191]
核苷酸类似物是结构上与天然存在的核苷酸相似的化合物。核苷酸类似物可以具有改变的磷酸主链、糖部分、核碱基或其组合。应当理解,使用此类类似物会产生可能具有不同的碱基配对性质的核酸,并且当此类碱基堆叠时发生的相互作用可能与在天然核酸中看到的相互作用不同。
[0192]
与如pcr等需要温度循环的扩增不同,扩增反应优选地是等温的(在恒定温度下)。所述方法可以用于扩增任何适当的模板,优选地环状核酸模板。核酸模板可以以任何适当的量提供给反应,包含最小量。
[0193]
优选的是,使用rca扩增核酸模板。
[0194]
用于扩增的一种或多种聚合酶可以是校对或非校对核酸聚合酶。所使用的核酸聚合酶可以是链置换核酸聚合酶。核酸聚合酶可以是嗜热或嗜温核酸聚合酶。
[0195]
所述方法可能需要高度持续的链置换聚合酶,以在高保真扩增条件下扩增核酸模板。聚合酶的保真度是模板准确复制的结果。除了有效区分正确与不正确核苷酸掺入之外,一些聚合酶还具有3'到5'核酸外切酶活性。这种校对活性用于切除不正确掺入的碱基,所述不正确掺入的碱基然后用正确的碱基替代。高保真度扩增利用将低错误掺入率与校对活性偶联的聚合酶,以提供模板的忠实复制。
[0196]
扩增反应可以采用在扩增后产生单链的经扩增核酸的聚合酶。因此,聚合酶能够进行链置换合成。
[0197]
在一些实施例中,可以使用phi29 dna聚合酶或phi29样聚合酶来扩增模板。可替代地,可以使用phi29 dna聚合酶和另一种聚合酶的组合。
[0198]
在所述方法的一个版本中,扩增反应可以采用低浓度的引物。本发明人已经发现,低浓度的引物是有利的,因为低浓度的引物使得扩增反应能够仅生成单链核酸。引物是与模板内的序列杂交以引发核酸合成反应的短的线性寡核苷酸。引物可以是任何核酸,如rna、dna、非天然核酸或其混合物。引物可以含有天然的、合成的或经修饰的核苷酸。
[0199]
可替代地,假定模板是双链环状模板,可以采用切口酶在双链模板的一条链上产生切口。这为聚合酶留下了入口点,然后聚合酶利用模板本身的切口链来引发核酸合成反应。
[0200]
因此,通过使模板与至少一种聚合酶和核苷酸接触并且在适于核酸扩增的条件下温育反应混合物来扩增核酸模板。核酸模板的扩增可以在等温条件下进行。另外的组分可
以包含以下中的一种或多种:切口酶(nicking enzyme/nickase)、辅因子(例如,镁离子)、引物和/或缓冲剂。
[0201]
环状模板的滚环扩增生成具有由模板编码的相邻多个重复序列(本文中每个重复序列称为序列单元)的线性单链多联体。由于模板的性质,这意味着每个序列单元包含侧接有格式化元件的所关注序列。这意味着所关注序列在每个末端处均具有格式化元件。每个序列单元还可以包含主链序列。
[0202]
这种方法依赖于编码模板内的格式化元件的序列,在编码所关注序列的序列的每个末端处均具有一个序列。这种格式化元件是编码加工基序和构象基序的两个相邻序列。正向格式化元件包括与构象基序相邻的加工基序,并且反向格式化元件包括与加工基序相邻的构象基序。加工基序包含核酸内切酶的识别位点和相关切割位点。
[0203]
可以使用核酸内切酶将多联体加工成核酸构建体。切割位点释放构象基序的末端残基。
[0204]
当多联体核酸中的切割位点被必需的核酸内切酶切割时,这将构象基序从加工基序中释放出来,从而使得能够在适当条件下多价螯合单链核酸分子的末端。
[0205]
扩增反应和加工反应可以同时发生,即,核酸内切酶可以存在以在多联体一形成时就对多联体进行加工,或者在添加核酸内切酶时可以存在延迟,直至扩增进一步进行或实际上完成。
[0206]
因此,用于制备单链核酸构建体的方法是巧妙且有效的,并且不受所关注序列长度的限制。
[0207]
模板
[0208]
在模板中,编码所关注序列的序列在两侧上侧接有编码格式化元件的序列。一个呈正向取向,并且另一个呈反向取向。经编码序列是嵌套的,使得所关注序列侧接有构象基序,所述构象基序进而与加工基序直接相邻,构象基序和加工基序一起形成格式化元件。这种嵌套可以表示为如图1所示。加工基序和构象基序的序列因此是连续的。可替代地,所关注序列的每个末端处的格式化元件呈相反取向或镜像取向,从而确保构象基序最接近所关注序列,而加工基序是格式化元件的最外部分。
[0209]
格式化元件在单链核酸分子的产生中是唯一的,但在终产物中并不以完整形式存在,因为加工基序是从构象基序上切割下来的。核酸内切酶在加工期间的作用确保加工基序的切割位点被切割,因此丢弃加工基序。因此,其是一种机制,通过所述机制产生被部分去除的有用产物,确保终产物含有最小量的不必要序列,从而为所关注序列提供更多的空间。因此,加工基序和相邻的构象基序被有效连接,直到切割位点被切割,从而释放产物的末端残基。被核酸内切酶的切割位点有效分离的与构象基序相邻的加工基序的组合使得能够使用核酸内切酶在单步过程中从较长的单链核酸分子中直接产生具有多价螯合末端的单链核酸。加工基序通过用限制酶加工从单链核酸中去除,并且不存在于具有多价螯合末端的单链核酸中。
[0210]
格式化元件被核酸内切酶的作用有效切割,并且因此从终产物中部分去除格式化元件。
[0211]
加工基序
[0212]
加工基序包含能够形成碱基配对部分的序列,所述碱基配对部分包含核酸内切酶
的识别位点和相关切割位点。应当理解,切割位点可以远离识别位点,但是通常需要两者都处于双链体结构中。
[0213]
在一种形式中,由于包含能够与加工基序中的另一个序列结合的至少一个序列区域,加工基序可以能够形成碱基配对部分,这些部分可以被视为在序列上是自互补的。这些序列可以是连续的或可以被间隔子元件隔开。此类基序可以通过在单链核酸中包含互补序列段来设计。应当理解,尽管两个序列都存在于同一条核酸链上,但分子的设计确保一个序列在分子内以正确取向与另一个序列结合。例如,在dna中,为了形成碱基对,序列需要反平行运行。例如,这种基序在病毒单链基因组中很常见。
[0214]
加工基序的碱基配对部分可以是连续的,使得所述部分形成发夹等。核酸可以形成反平行双链发夹样结构。发夹结构由被称为茎的双链碱基配对区域组成。可替代地,加工基序的碱基配对部分可以包含在能够进行碱基配对的两个序列段之间的间隔子序列,从而形成如茎环等结构。间隔子可以是任何合适的长度。发夹可以由如本文定义的回文的核酸序列形成。
[0215]
核酸分子的碱基配对或双链部分也可以具有互补序列。本文中进一步定义了碱基配对和双链体。
[0216]
在加工基序的碱基配对部分中,包含核酸内切酶的识别位点和相关切割位点。优选的是,在碱基配对部分的基脚处形成切割位点,使得可以使用必需的核酸内切酶从单链上切割整个加工基序。
[0217]
碱基配对发生在单链内的至少两个序列部分之间。这种碱基配对可以是标准的(即,沃森和克里克经典碱基对,其是dna中的腺嘌呤(a)
‑
胸腺嘧啶(t)、rna中的腺嘌呤(a)
‑
尿嘧啶(u)以及dna和rna两者中的胞嘧啶(c)
‑
鸟嘌呤(g))或非规范的(即,胡斯坦碱基对或碳
‑
氢和氧/氮基团之间的相互作用等)。这些在其它地方有描述。
[0218]
模板包含编码具有任何这些特性的加工基序的一个或多个序列。加工基序可以是不同的序列。
[0219]
模板可以含有编码第一加工基序的序列和编码第二加工基序的序列。由模板编码的第一加工基序和第二加工基序位于构象基序的外边缘(和格式化元件内),使得所关注序列的每个末端都以相反取向(正向和反向)的格式化元件结束。
[0220]
考虑到对单链核酸多联体中的加工基序的要求的性质(加工前),第一加工基序和第二加工基序的序列可以相同或不同。如果第一加工基序和第二加工基序的序列相同,则在碱基配对部分的基脚处形成限制性位点,使得可以使用必需的核酸内切酶从单链上切割整个加工基序。因此,无论加工基序相对于所关注序列的取向如何(之前或之后),整个加工基序都可以从核酸上切割下来,因为切割位点位于碱基配对部分的基脚处,其也可以被描述为配对部分的最终碱基对或其碱基。
[0221]
可替代地,单链核酸多联体中的第一加工基序和第二加工基序(加工前)可以不同,使得含有切割位点的核酸内切酶的每个识别位点也不同,从而使得在加工本发明的单链多联体时能够使用不同的核酸内切酶。
[0222]
因此,模板可以包含编码相同或不同的第一加工基序和第二加工基序的序列。
[0223]
核酸内切酶是一种切割多核苷酸链内的磷酸二酯键的酶,无论是蛋白质的还是由如dna等核酸构成的。在本发明中,为了产生具有多价螯合末端的核酸分子,需要切割双链
核酸(cut through double
‑
stranded nucleic acid)。因此,可能需要两种核酸内切酶的组合,每种核酸内切酶切割一条单链。或者,可以采用切割两条链的单一酶。例如,核酸内切酶可以是切口核酸内切酶、归巢核酸内切酶、如cas9等引导性核酸内切酶或限制性核酸内切酶。切口核酸内切酶可以是已经被修饰以仅切割一条链的经修饰的限制性核酸内切酶。
[0224]
一方面,核酸内切酶是限制性核酸内切酶。
[0225]
限制性核酸内切酶是在特异性识别位点内或附近的切割位点处切割双链核酸的酶。为了切割,所有限制性核酸内切酶均切开两个切口,一次穿过双链体的每个主链(即,每条链)。由于限制性核酸内切酶需要双链核酸的存在以便识别识别位点,因此需要这种结构以便允许核酸内切酶切割核酸。因此,本发明人提出在单链核酸内构建碱基配对部分,优选地使用自互补序列,使得单链分子形成包含识别位点和切割位点的双链结构。
[0226]
限制性核酸内切酶识别特异性核苷酸序列并且在双链体中产生双链切割。识别位点也可以按碱基数进行分类,通常在4个与8个碱基之间。许多但不是所有的识别位点都是回文的,并且这一性质在设计加工基序时非常有用,因为所述性质有助于序列的设计,从而使其能够更容易地放置在碱基配对部分中。在单链形式中,当彼此碱基配对时能够形成回文体的每个部分被称为反向重复序列。这两个序列可以被单链核酸中的间隔子序列隔开。
[0227]
限制性核酸内切酶可以是钝切割器(即,直接切割穿过碱基配对部分)或以偏置方式切割(即,交错切割穿过碱基配对部分)。切割位点可以在识别位点内或附近,并且因此切割位点不需要是识别位点的一部分。因此,切割位点与识别位点缔合,但不一定形成识别位点的一部分。
[0228]
已知成千上万种天然的和工程化的限制性核酸内切酶,连同其识别位点和切割位点。任何合适的识别位点和切割位点都可以包含在加工基序中。通常用于克隆等的示例性限制性核酸内切酶是hhai、hindiii、noti、ecori、clai、bamhi、bglii、drai、ecorv、pst1、sali、smai、schi和xmai。许多限制性核酸内切酶均可从如新英格兰生物实验室(new england biolabs)和赛默飞世尔科技公司(thermofisher scientific)等供应商商购获得。
[0229]
为了使用核酸内切酶进行切割以从单链核酸多联体中的格式化元件中释放构象基序,优选的是,切割位点与模板中的构象基序相邻,使得构象基序的末端核苷酸形成单链核酸分子产物的末端和多价螯合末端。
[0230]
在模板内,编码的是格式化元件,所述格式化元件的一部分是编码构象基序的序列,所述构象基序被设计成折叠在具有多价螯合末端的最终单链核酸分子中。构象基序多价螯合单链核酸分子的末端(即,dna和rna的5'和3'末端)。
[0231]
构象基序包含能够在单链核酸分子内或与加帽寡核苷酸形成碱基配对部分或双链体的序列。这种碱基配对部分或双链体可以在用核酸内切酶进行加工之前在多联体中形成,或者一旦加工基序从多联体中去除,这种碱基配对部分或双链体就可以在用核酸内切酶进行加工之后形成。参考附图,为了便于参考,这些已经通过在多联体核酸中形成碱基配对部分的构象基序进行了描述(参见图2、3、4和5)。这些结构可以不形成,直到加工基序已经被核酸内切酶切割。如果需要加帽寡核苷酸,当添加加帽寡核苷酸时,构象基序将适当地折叠,因为与此实体进行碱基配对可能会引起必需的折叠。
[0232]
双链体可以通过单链内的至少两个序列部分之间的碱基配对来形成。这种碱基配
对可以是标准的(即,沃森和克里克经典碱基对,其是dna中的腺嘌呤(a)
‑
胸腺嘧啶(t)、rna中的腺嘌呤(a)
‑
尿嘧啶(u)以及dna和rna两者中的胞嘧啶(c)
‑
鸟嘌呤(g))或非规范的(即,胡斯坦碱基对(hoogsteen base pairs)、碳
‑
氢和氧/氮基团之间的相互作用等)。胡斯坦对允许单链核酸富含g的区段(称为g
‑
四链体)或富含c的区段(称为i
‑
基序)的特定结构的形成。g四链体通常需要由短间隔子隔开的四个g的三联体。这允许组装由胡斯坦键合的鸟嘌呤分子的堆叠缔合构成的平面四重体。
[0233]
因此,构象基序可以包含与单链核酸分子内的另一个序列,即与所关注序列或所关注序列内的间隔子序列自互补或互补的序列部分。
[0234]
构象基序可以包含用于形成多于一个碱基配对部分或双链体的序列,所述碱基配对部分或双链体中的每个碱基配对部分或双链体被单链核酸的间隔子序列隔开,或碱基配对部分或双链体可以形成较大结构的一部分,所述较大结构可以包含以下中的任何一种或多种:发夹;单链区域;凸环;内部环;多分支环或连接。
[0235]
一旦构象基序已经形成至少一个碱基配对部分或双链体,单链核酸分子的末端残基就被多价螯合。单链dna的任一端处的末端核苷酸(或残基)被隐藏/保护。这使得末端残基不易于被单链核酸外切酶等获得。
[0236]
单链核酸分子的末端核苷酸通过包含在构象基序的碱基配对部分或双链体内并且因此缺乏游离的单链末端或者折叠于构象基序的拓扑结构内使得末端对于进一步的相互作用不是游离的而被多价螯合并且被固定。
[0237]
优选的是,末端(末端核苷酸)在单链核酸产物中不呈单链形式。这些末端通过每个末端残基与单链核酸的另一个部分之间存在碱基配对来稳定。
[0238]
来自多联体核酸分子的构象基序一旦被加工,就形成单链核酸构建体的一个末端。末端残基被构象基序多价螯合。
[0239]
在单链核酸构建体中,每个末端都被构象基序多价螯合。
[0240]
根据本发明的优选的构象基序包含可以折叠成发夹、茎环、连接、假结、itr、经修饰的itr、合成itr、i
‑
基序和g
‑
四链体的序列。
[0241]
由于核酸单链的相邻互补序列之间的碱基配对,发夹是如dna或rna等核酸中的结构。相邻的互补序列可以被几个核苷酸,例如1
‑
10个或1
‑
5个核苷酸隔开。图2中描绘了这种情况的实例。如果在两个互补序列部分之间包含非互补序列的环,则所述环形成发夹环或茎环。环可以具有任何合适的长度,如茎或双链部分也可以具有任何合适的长度。其它类似的结构包含套索。
[0242]
每个末端处的构象基序可以折叠成相同的特定结构(即,发夹、茎环、itr等)或者所述构象基序可以各自被独立地设计成折叠成不同的结构(即,第一末端是发夹,并且第二末端是是itr)。
[0243]
如先前所述,构象基序可以具有另外的功能。构象基序可以形成功能性结构,如适配体等。可替代地,构象基序可以被设计成提供将单链核酸构建体以寡聚构象结合在一起的机制。
[0244]
模板还编码所关注序列。在具有多价螯合末端的多联体和单链核酸构建体中,所关注序列可以是任何合适长度的任何期望核酸序列。所关注序列可以是功能性序列(即,直接充当适配体等而无需进一步转录或翻译)。可替代地,所关注序列可以编码功能性序列。
功能性序列包含适配体、作为包含核酶的核酸酶的催化实体、包含微rna(mirna)的非编码rna(ncrna)、短干扰rna(sirna)和piwi相互作用rna(pirna)。
[0245]
所关注序列可能能够在动物和植物中充当用于基因编辑目的的供体核酸。基因编辑的示例性方法包含基于crispr基因编辑和转录激活因子样效应物核酸酶(talen)的方法。如果所关注序列是供体核酸,则可能需要包含能够通过必要的机器切除供体核酸的序列或元件。
[0246]
所关注序列可以是用于在细胞中表达的转基因,如基因或基因材料。转基因与表达盒内的启动子序列可操作地连接。
[0247]
所关注序列可以包含编码治疗性产物的序列。治疗性产物可以是dna适配体、蛋白质、肽或rna分子,如小干扰rna。为了提供治疗效用,这种所关注序列可以包括包含一个或多个启动子或增强子元件和编码所关注mrna或蛋白质的基因或其它编码序列的表达盒。表达盒可以包括与编码所关注蛋白质的序列可操作地连接的真核启动子,以及任选地增强子和/或真核转录终止序列。
[0248]
所关注序列可以用于产生用于在宿主细胞中表达的dna,特别是用于产生dna疫苗。dna疫苗通常编码感染性生物体的dna的修饰形式。将dna疫苗施用于受试者,然后在所述受试者中所述疫苗表达感染性生物体的所选蛋白质,从而引发针对通常具有保护性的蛋白质的免疫应答。dna疫苗还可以在癌症免疫疗法方法中编码肿瘤抗原。任何dna疫苗都可以用作所关注序列。
[0249]
此外,本发明的方法可以产生其它类型的治疗性dna分子,例如用于基因疗法的分子。例如,在受试者患有由功能性基因的功能失调形式引起的遗传疾病的情况下,此类dna分子可以用于表达所述基因。此类疾病的实例是本领域众所周知的。
[0250]
优选的是,编码所关注序列或构象基序的模板的部分缺乏细菌复制起点、缺乏抗性基因(即,对于抗生素)、缺乏cpg岛(除了同样可能有帮助的dna疫苗之外)、缺乏胞嘧啶和腺嘌呤或外来dna的任何其它标志物的甲基化。然而,这些实体可以存在于所关注序列和构象基序的外部,因为模板的其余部分被加工并且从产物中去除。
[0251]
模板优选地是环状或能够环化。模板可以是双链或单链的。
[0252]
如果模板是双链的,则优选的是,所述模板在第一个加工基序之前包含切口酶的序列。可替代地被称为切口核酸内切酶,这些酶仅水解双链体的一条链,以产生被“切口”而不是切割的核酸分子。这为滚环扩增提供了起始点而无需另外的引物,并且可以确保在扩增反应中仅产生一条核酸多联体链。此类酶可例如从新英格兰生物实验室和赛默飞世尔科技公司商购获得。这些酶具有足够特异性,使得可以在模板的相关链上设计识别位点和切割位点,以确保正确的链直接用作模板。
[0253]
模板可以是任何合适的核酸,如dna或rna等天然核酸或如先前讨论的人工核酸。优选的是,模板是dna。
[0254]
模板的扩增
[0255]
为了产生单链核酸构建体,模板必须被酶促扩增。
[0256]
模板可以用一种或多种聚合酶扩增。如果提供足够的原材料或底物(如核苷酸)和辅因子(如金属离子等)来扩增核酸,则聚合酶可以使用模板合成互补核酸拷贝。
[0257]
任何合适的聚合酶都可以用于此扩增步骤,并且可以使用一种酶或多种酶的组
合。
[0258]
根据模板的性质,酶可以是dna聚合酶或rna聚合酶,或者是人工的、经修饰的、工程化的或经突变的聚合酶,以便使用合成模板或制造合成单链核酸。
[0259]
扩增优选通过链置换方法来进行。这是一种不需要重复加热和冷却循环(如pcr那样)的等温方法,但聚合酶能够置换与模板退火的任何链。链置换型聚合酶是已知的,包含phi29、deepbst dna聚合酶i和其变体。这意味着多种聚合酶可以同时作用于同一个模板,每种聚合酶置换由早期聚合酶产生的初生链。
[0260]
最优选的链置换扩增技术是滚环扩增(rca)。在这种扩增方法中,链置换聚合酶围绕环状模板连续进行,同时延伸初生寡核苷酸。这导致生成核酸的长多联体链。
[0261]
优选的是,通过用切口核酸内切酶切割模板,允许扩增反应在双链环状模板上启动。上文讨论了此类酶。通过切割双链模板的单链,这打开了聚合酶结合的模板,并且其可以利用产生的游离3'末端通过围绕环状模板进行多次加工来将这条链延伸到多联体核酸中。
[0262]
在模板中使用切口位点和切口核酸内切酶还允许所述方法仅从rca制备单链多联体,并且防止相反链的扩增,因为使用酶仅切割一个主链。
[0263]
因此,在模板中使用切口位点是优选的,因为其允许产生期望产物,并且防止双链模板的互补链的不需要的扩增。
[0264]
可替代地,本发明人已经发现,使用非常少量的被设计成与期望模板链(而不是其互补链)退火的特异性引物,可以迫使进行扩增,从而仅产生大量双链模板的一条链。在此方面,仅需要微微摩尔量的引物。因此,引物可以以1pm到100nm的量提供。
[0265]
如果模板是单链的,则可以使用引物来启动滚环扩增。优选地,引物被设计成仅与模板退火而不与多联体核酸分子退火,从而确保仅制备一种多联体物种。
[0266]
因此,本发明人设计了确保rca继续扩增模板并且仅产生期望多联体、用于产生单链核酸构建体的正确物种而不是互补链的方式。制备互补链将导致50%的废物扩增反应并且还使得单链构建体的合成更加困难,因为互补多联体的存在将固有地导致双链核酸的形成。
[0267]
模板与至少一种聚合酶接触。可以使用一种、两种、三种、四种或五种不同的聚合酶。聚合酶可以是任何合适的聚合酶,以使聚合酶合成核酸的聚合物。聚合酶可以是dna或rna聚合酶。可以使用任何聚合酶,包含任何可商购获得的聚合酶。可以使用两种、三种、四种、五种或更多种不同的聚合酶,例如提供校对功能的聚合酶以及不提供校对功能的一种或多种其它聚合酶。可以使用具有不同机制的聚合酶,例如链置换型聚合酶和通过其它方法复制核酸的聚合酶。不具有链置换活性的dna聚合酶的合适实例是t4 dna聚合酶。
[0268]
聚合酶可以是高度稳定的,因此聚合酶的活性不会因在工艺条件下延长温育而显著降低。因此,酶优选地在包含但不限于温度和ph的一系列工艺条件下具有长半衰期。还优选的是,聚合酶具有适于制造过程的一个或多个特性。聚合酶优选地具有高保真度,例如通过具有校对活性。此外,优选的是,聚合酶对核苷酸和核酸表现出高持续合成能力、高链置换活性和低km。聚合酶可能能够使用环状和/或线性dna作为模板。聚合酶可能能够使用双链或单链核酸作为模板。优选的是,聚合酶未表现出与其校对活性无关的核酸外切酶活性。
[0269]
技术人员可以通过与可商购获得的聚合酶所表现出的性质进行比较来确定给定
聚合酶是否表现出如上所定义的特性,所述可商购获得的聚合酶例如phi29(美国马萨诸塞州伊普斯威奇的新英格兰生物实验室公司(new england biolabs,inc.,ipswich,ma,us))、deep(新英格兰生物实验室公司)、嗜热脂肪芽孢杆菌(bst)dna聚合酶i(新英格兰生物实验室公司)、dna聚合酶i的克列诺片段(新英格兰生物实验室公司)、m
‑
mulv逆转录酶(新英格兰生物实验室公司)、(核酸外切酶
‑
减号(exo
‑
minus))dna聚合酶(新英格兰生物实验室公司)、dna聚合酶(新英格兰生物实验室公司)、deep(核酸外切酶
‑
)dna聚合酶(新英格兰生物实验室公司)、bst dna聚合酶大片段(新英格兰生物实验室公司)、高保真度融合dna聚合酶(例如,火球菌属(pyrococcus)
‑
yke,马萨诸塞州的新英格兰生物实验室)、来自强烈火球菌(加利福尼亚州拉霍亚的strategene公司(strategene,lajolla,ca))的pfu dna聚合酶、t7 dna聚合酶的sequenase
tm
变体、t7 dna聚合酶、t4 dna聚合酶、来自火球菌属物种gb
‑
d(马萨诸塞州的新英格兰生物实验室)的dna聚合酶或来自嗜热高温球菌(thermococcus litoralis)(马萨诸塞州的新英格兰生物实验室)的dna聚合酶。
[0270]
可替代地,聚合酶可以是dna依赖性rna聚合酶。示例性酶包含t3 rna聚合酶、t7 rna聚合酶、hi
‑
t7
tm
rna聚合酶、sp6 rna聚合酶、大肠杆菌poly(a)聚合酶、大肠杆菌rna聚合酶和大肠杆菌rna聚合酶、全酶(全部均可从neb获得)。
[0271]
当提到高持续合成能力时,这通常表示聚合酶每次与模板缔合/解离所添加的核苷酸的平均数,即从单个缔合事件获得的引物延伸的长度。
[0272]
链置换型聚合酶是优选的。优选的链置换型聚合酶是phi 29、deep vent和bst dna聚合酶i或其任何变体。“链置换”描述了聚合酶在合成期间遇到双链dna区域时置换互补链的能力。因此通过置换互补链并合成新的互补链来扩增模板。因此,在链置换复制期间,新复制的链将被置换以使聚合酶复制另外的互补链。当引物或单链模板的自由端与模板上的互补序列退火(两者都是引发事件)时,扩增反应开始。当核酸合成进行时并且如果核酸合成遇到与模板退火的另外的引物或其它链,则聚合酶会置换其并且继续其链延伸。应当理解,链置换扩增方法与基于pcr的方法的不同之处在于,变性循环对于有效扩增不是必需的,因为双链模板不是继续合成新链的障碍。链置换扩增可以仅需要一个初始轮的加热,如果初始模板是双链的,则使初始模板变性,如果使用引物,则允许引物与引物结合位点退火。在此之后,扩增可以被描述为等温的,因为不需要进一步加热或冷却。相比之下,pcr方法要求在扩增过程期间进行变性的循环(即,升温至94摄氏度或更高)以熔融双链dna并提供新的单链模板。在链置换期间,聚合酶将置换已合成的核酸的链。
[0273]
在本发明的方法中使用的链置换聚合酶的持续合成能力优选地为至少20kb、更优选地至少30kb、至少50kb或至少70kb或更高。在一个实施例中,链置换dna聚合酶具有与phi29dna聚合酶相当或更高的持续合成能力。
[0274]
模板与聚合酶和切口酶或引物的接触可以在促进引物与模板退火的条件下进行。所述条件包含允许引物杂交的单链dna的存在。所述条件还包含允许引物与模板退火的温度和缓冲液。可以根据引物的性质选择适当的退火/杂交条件。在本发明中使用的优选的退火条件的实例包含ph为7.5的缓冲液30mm tris
‑
hcl、20mm kcl、8mm mgcl2。退火可以在通过逐渐冷却到期望反应温度使用热进行变性之后进行。
[0275]
模板和聚合酶也与核苷酸接触。模板、聚合酶和核苷酸的组合形成反应混合物。反
应混合物还可以包括一种或多种引物或可替代地切口酶(切口酶)。反应混合物还可以独立地包含一种或多种金属阳离子或用于核酸合成的任何其它所需辅因子。
[0276]
核苷酸是核酸的单体或单个单元,并且核苷酸由含氮碱基、五碳糖(核糖或脱氧核糖)和至少一个磷酸基团构成。可以使用任何合适的核苷酸。
[0277]
核苷酸可以以游离酸、其盐或螯合物、或游离酸和/或盐或螯合物的混合物的形式存在。
[0278]
核苷酸可以以单价金属离子核苷酸盐或二价金属离子核苷酸盐的形式存在。
[0279]
含氮碱基可以是腺嘌呤(a)、鸟嘌呤(g)、胸腺嘧啶(t)、胞嘧啶(c)和/或尿嘧啶(u)。含氮碱基还可以是经修饰的碱基,如5
‑
甲基胞嘧啶(m5c)、假尿苷(ψ)、二氢尿苷(d)、肌苷(i)和/或7
‑
甲基鸟苷(m7g)。
[0280]
优选的是,五碳糖是脱氧核糖,使得核苷酸是脱氧核苷酸。
[0281]
核苷酸可以呈脱氧核苷三磷酸的形式,表示为dntp。这是本发明的优选实施例。合适的dntp可以包含datp(脱氧腺苷三磷酸)、dgtp(脱氧鸟苷三磷酸)、dttp(脱氧胸苷三磷酸)、dutp(脱氧尿苷三磷酸)、dctp(脱氧胞苷三磷酸)、ditp(脱氧肌苷三磷酸)、dxtp(脱氧黄嘌呤核苷三磷酸)及其衍生物和修饰形式。优选的是,dntp包括datp、dgtp、dttp或dctp中的一种或多种、或其修饰形式或衍生物。优选的是,使用datp、dgtp、dttp和dctp的混合物或其修饰形式。
[0282]
核苷酸可以呈溶液形式或以冻干形式提供。核苷酸的溶液是优选的。
[0283]
核苷酸可以以一种或多种合适碱基的混合物的形式提供,包含任何新设计的人工碱基,优选地腺嘌呤(a)、鸟嘌呤(g)、胸腺嘧啶(t)、胞嘧啶(c)中的一种或多种。在合成核酸的过程中使用两个、三个或优选地所有四个核苷酸(a、g、t和c)。
[0284]
多联体
[0285]
所产生的单链多联体也是新的,并且能够被加工成具有多价螯合末端的单链核酸,其可以含有所关注序列。
[0286]
多联体是具有存在于模板中的序列单元的重复单元的核酸分子。每个序列单元包含在两侧上侧接有如先前所述的格式化元件的所关注序列。序列单元还可以包含由模板编码的主链序列,所述主链序列最终不存在于本发明的核酸构建体中。
[0287]
多联体核酸分子可以包括多个序列单元,例如连续系列中的10个、50个、100个、200个、500个或甚至1000个或更多个序列单元。多联体分子的大小可以为至少5kb、至少50kb、至少100kb或甚至长度高达200kb。
[0288]
加工多联体核酸分子
[0289]
一旦模板被扩增,或者甚至在扩增期间,可以使用将切割一个或多个加工位点的必需核酸内切酶将多联体核酸加工成单链核酸构建体。
[0290]
因此优选的是,加工基序能够形成碱基配对部分,同时呈多联体核酸的形式。因此,加工基序可以被设计成使得碱基对在适于等温扩增的条件下形成。一旦这些碱基配对部分在多联体核酸内形成,核酸内切酶的识别位点连同必要的切割位点一起形成。这个巧妙的系统允许对多联体进行加工,尽管其仅是核酸的单链。模板的设计允许在多联体核酸内形成加工位点,从而允许单个步骤通过添加一种或多种核酸内切酶对此多联体进行加工。
[0291]
一旦扩增反应完成,可以在扩增反应正在进行中或在扩增反应开始时添加核酸内切酶。优选的是,在添加核酸内切酶之前进行扩增反应,以确保多联体核酸被快速加工。可替代地,可以允许扩增过程在添加核酸内切酶之前完成(即,模板耗尽、核苷酸耗尽、反应混合物太粘)。
[0292]
一旦被核酸内切酶切割,由于构象基序的作用,多联体被切割成具有多价螯合末端的单链核酸构建体。还产生了由加工基序加上任何相关模板主链组成的副产物。由于副产物的末端没有被多价螯合,因此可以使用单链核酸外切酶去除这些末端。
[0293]
现在将参考以下非限制性实例描述本发明。
[0294]
实例
[0295]
实例1:核酸构建体的产生:
[0296]
模板:模板a(图9,seq id no.1)。
[0297]
模板包含切口位点、与构象基序相邻的加工基序、所关注序列、与第二加工基序相邻的第二构象基序和与所关注序列大小类似的主链。在主链中存在另外的核酸内切酶靶位点,所述位点将仅在dsdna中切割。
[0298]
模板a的序列在相关序列表中表示为seq id no.1。
[0299]
20μl中的切口反应
[0300]
·
4μl模板(原液浓度为1μg/μl)
[0301]
·
13μl水
[0302]
·
2μl cutsmart缓冲液(neb)
[0303]
·
1μl切口酶(nb.bsrdi,neb)
[0304]
在37℃下温育180分钟,随后在80℃下温育20分钟
[0305]
1000μl中的扩增反应
[0306]
·
4μl模板(原液浓度0.2μg/μl)
[0307]
·
100μl缓冲液
‑
10x原液:
[0308]
‑
ph为7.9的300mm tris
[0309]
‑
300mm kcl
[0310]
‑
50mm(nh4)2so4[0311]
‑
100mm mgcl2[0312]
·
837μl ddh2o
[0313]
·
20μl dntp(原液100mm(比奥立公司(bioline)))
[0314]
·
35μl ssb(原液5μg/μl(大肠杆菌ssb,内部制备))
[0315]
·
2μl无机焦磷酸酶(原液2u/μl(enzymatics公司(enzymatics)))
[0316]
·
2μl phi29 dna聚合酶(原液100u/μl(enzymatics公司))
[0317]
在30℃下温育16小时
[0318]
加工反应
[0319]
·
1000μl扩增反应
[0320]
·
20μl mlyi(原液10u/μl)
[0321]
在37℃下温育180分钟
[0322]
结果:
[0323]
如图10所示的凝胶照片。
[0324]
此凝胶示出了rca反应的消化产物。左手孔:thermo scientific gene ruler 1kb plus dna ladder(左侧大小以bp单位)。右手孔:mlyi加工的rca(右侧预期大小以nt(核苷酸)为单位)。具有类似大小的主链和产物条带由于其主要的单链性质而不能明亮地染色。未看到“特征(signature)”下带,这将指示产物的双链化(mlyi位点存在于主链中,并且将在dsdna中切割以将主链条带降至1597和407个碱基对)。
[0325]
实例2:用核酸外切酶测试核酸构建体的末端核苷酸的稳定性
[0326]
本实例测试了与其末端不形成限定结构的核酸(标准单链dna)相比,具有多价螯合末端的新型核酸构建体是否提供显著的核酸外切酶抗性。
[0327]
核酸外切酶稳定性测试:
[0328]
针对这项测试生成了具有不同构象基序的五个产物分子:
[0329]
i.不具有构象基序(并且因此无固定的末端核苷酸)的ssdna;
[0330]
ii.具有三核苷酸环(gaa)构象基序的ssdna,所述构象基序将3'和5'末端处的末端核苷酸固定在碱基配对双链体段中;
[0331]
iii.具有g
‑
四链体构象基序(ttaggg)4(seq id no.11)连同另外的序列的ssdna,所述另外的序列形成与所关注序列的分子内碱基配对的一部分并且包含双链体核酸的一部分内的末端核苷酸;
[0332]
iv.具有g
‑
四链体构象基序而在3'和5'末端处均没有另外的碱基配对部分,因此依赖于通过将每个末端核苷酸包含在四链体(ttaggg)4内来固定每个末端核苷酸的ssdna;
[0333]
v.具有假结构象基序而在3'和5'末端处均没有另外的碱基配对部分,因此依赖于通过将每个末端核苷酸掺入假结内来固定每个末端核苷酸的ssdna。
[0334]
将核酸分子在100 mm kcl中稀释到100 ng/μl,并且热变性(95℃,并冷却到室温)以使构象基序适当地形成构象。将10μl的每种构建体用于随后在50μl终体积的1x核酸外切酶vii反应缓冲液(neb;50 mm tris
‑
hcl、50 mm磷酸钠、8 mm edta、10 mm 2
‑
巯基乙醇,ph 8.0)中进行核酸外切酶测试。在存在或不存在100 u/ml核酸外切酶vii(neb)的情况下,将反应在37℃下温育30分钟。将产物用gelred染料在琼脂糖凝胶上进行解析(图6)。
[0335]
表1:试剂
[0336][0337]
表2材料:
[0338]
1kb序列梯nebn0468s04715116x凝胶加载染料nebb7024s0361604琼脂糖le利斧科学(cleaver scientific)csl
‑
ag50014150916凝胶提取试剂盒普洛麦格(promega)a92820000232671
gelredbiotum4100316g1010tae缓冲液ih不适用不适用
[0339]
结果:
[0340]
在实验的短窗口内,在存在核酸外切酶vii的情况下,将不具有固定3'和5'末端的构象基序的ssdna几乎完全消化(图6,通道1
‑
2)。
[0341]
包含用于固定3'和5'末端核苷酸的构象基序的所有ssdna(如上文(ii)到(v)中描述的),即具有多价螯合末端的单链核酸构建体,比ssdna对核酸外切酶消化更具抗性。
[0342]
被描述为(ii)(通道3
‑
4)的构建体通过将末端包含在碱基配对双链体序列段内来多价螯合末端。这显示出对核酸外切酶的抗性。
[0343]
使用g
‑
四链体构象基序制备两种不同的核酸构建体。在(iv)(通道7
‑
8)中描述的构建体通过将末端包含在g
‑
四链体内来多价螯合末端。在(iii)(通道5
‑
6)中描述的构建体包含双链体核酸的另外的部分,其中末端核苷酸参与碱基配对。对于这项实验,似乎添加额外的双链体序列有助于对核酸外切酶的抗性。这表明,基于多价螯合末端的期望特性,构象可以被工程化以适应可以使用核酸构建体的特定条件。
[0344]
被描述为(v)(通道9
‑
10)的构建体通过将末端包含在假结内来多价螯合末端。这似乎在测试条件下显示出对核酸外切酶的中等抗性。
[0345]
这些数据表明,多价螯合末端可以用于延迟由核酸外切酶和通过改变构象基序的序列引起的降解,构建体的结构可以被工程化以增加核酸构建体的稳定性。
[0346]
实例3:在存在细胞提取物的情况下测试核酸构建体的末端核苷酸的稳定性
[0347]
设计这项实验以测试与其末端不形成限定构象的核酸(这些实例中的标准单链dna)相比,具有多价螯合末端的新型核酸构建体在存在细胞提取物的情况下是否提供显著抗性。
[0348]
细胞提取物的制备:
[0349]
hek293t细胞(clontech z2180n)在37℃和5%co2下生长于伊格尔氏基本必需培养基(eagle's minimal essential medium)(补充有10%fbs、谷氨酰胺、非必需氨基酸和抗生素)中。将具有完全汇合的三个10cm板用pbs洗涤。收获细胞,并且使用10ml的1x细胞裂解缓冲液(普洛麦格e397a)进行裂解。获得大约每毫升2,000,000个细胞的悬浮液。在室温下温育5分钟后,通过离心(4000rpm,持续5分钟)使悬浮液澄清。将甘油添加到20%,并且将细胞提取物等分并且在
‑
80℃下冷冻。
[0350]
细胞提取物稳定性测试:
[0351]
将所有5种核酸构建体(如实例2中制备的)在100mm kcl中稀释到100ng/μl,并且热变性(95℃,并冷却到室温)以使构象基序适当地形成构象。稀释液补充有2mm mgcl2和ph为7.5的10mm tris以及5%的解冻的细胞提取物。将样品温育24小时或72小时,并且将产物用gelred染料在琼脂糖凝胶上进行解析(图7)。
[0352]
表3:试剂
[0353][0354]
表4:材料
[0355]
1kb序列梯nebn0468s04715116x凝胶加载染料nebb7024s0361604琼脂糖le利斧科学csl
‑
ag50014150916凝胶提取试剂盒普洛麦格a92820000232671gelredbiotum4100316g1010tae缓冲液ih不适用不适用l
‑
谷氨酰胺gibco公司(gibco)25030
‑
0811817540mem非必需氨基酸溶液西格玛(sigma)m7145
‑
100mlrnbg2199伊格尔基本必需培养基西格玛m2279
‑
500mlrnbg4545pbs西格玛d1408
‑
100mlrnbf3311甘油费舍尔公司(fisher)bp229
‑
1144356报告基因裂解缓冲液5x普洛麦格e397a0000264994
[0356]
结果:
[0357]
在存在5%细胞提取物的情况下,将缺乏构象基序以多价螯合3'和5'末端的ssdna逐渐消化到接近完成(通道1、6和11),并且在温育72小时后可检测到少量。
[0358]
在存在提取物的情况下,具有多价螯合末端的所有其它核酸构建体提供显著更高的稳定性。
[0359]
在所测试的条件下,似乎通过包含在由碱基配对形成的双链体核酸的一部分或一段内来多价螯合3'和5'末端提供了对降解的最大量抗性。通道2、7、12和通道3、8、13中的构建体(ii)和(iii)的结果分别显示出最大稳定性。
[0360]
然而,剩余的构建体显示出一定程度的抗性,表明有可能在末端残基不直接参与碱基对的情况下固定末端残基。表示为(iv)的g
‑
四链体版本表现出相对较强的稳定性(通道4、9、14),而其构象基序呈现假结结构(v)(通道5、10、15)的分子对降解的抗性水平是多价螯合末端的构建体中最低的。
[0361]
为了消除某些条带作为假象从细胞提取物中出现的可能性,将含有5%提取物而未添加dna的对照温育72小时(通道16)。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1