调控抗铝毒转录因子STOP1蛋白的基因及其应用
调控抗铝毒转录因子stop1蛋白的基因及其应用
1.本技术是申请日为2019年3月25日、申请号为201910228864.1、发明名称为“调控抗铝毒转录因子stop1蛋白的基因及其应用”的发明专利申请的分案申请。
技术领域
2.本发明涉及农学领域,具体地,本发明涉及调控抗铝毒转录因子stop1蛋白稳定性的基因及其应用。
背景技术:
3.全球30%的耕地是酸性土壤,并且随着过度耕作和过度使用氮肥,土壤正在进一步酸化。铝是酸性土壤限制植物生长和农作物产量的主要因素,铝毒主要作用于根尖过渡区,与细胞壁、细胞膜、细胞内靶点结合产生毒害。由于植物不能像动物那样移动,为了生存,许多植物进化出多种应对铝胁迫的解毒机制,充分研究挖掘植物的潜力,并加以利用和改良是解决酸性土壤铝毒害的途径和策略。
4.有机酸分泌是关键的抗铝毒机制,植物分泌少量的有机酸就能明显地减少铝对植物的毒害。拟南芥苹果酸分泌蛋白atalmt1在抗铝毒过程中扮演重要角色,atalmt1的表达受al诱导且还受低ph、aba、h2o2和iaa等多种因素影响,转录因子stop1直接调控atalmt1的表达,但是stop1本身mrna表达是组成型,并不能解释对atalmt1表达的调控,stop1蛋白水平调控机制的研究显得尤为重要。
5.因此,本领域迫切需要开展调控抗铝毒相关基因的功能研究,以便解决酸性土壤铝毒害。
技术实现要素:
6.本发明的目的是提供一种调控抗铝毒转录因子stop1蛋白稳定性的基因及其应用。
7.本发明的第一方面,提供了一种rae1基因或ral1基因,或其编码蛋白、突变蛋白、其促进剂或抑制剂的用途,用于选自下组的一种或多种用途:
8.(1)调控stop1蛋白的表达量;
9.(2)调控选自下组基因的表达:atalmt1、atmate、als3、或其组合;
10.(3)调控植物抗铝毒能力或耐铝性能;和/或
11.(4)制备制剂或农用组合物,且所述的制剂或农用组合物用于调控stop1蛋白的表达量、调控植物抗铝毒能力或耐铝性能、或调控选自下组基因的表达:atalmt1、atmate、als3、或其组合。
12.在另一优选例中,所述调控植物抗铝毒能力包括:调控植物生长期和/或生殖期的抗铝毒能力。
13.在另一优选例中,所述调控植物抗铝毒能力包括:调控植物(如根)有机酸的分泌水平。
14.在另一优选例中,所述调控stop1蛋白的表达量包括介导stop1蛋白的泛素化从而调控stop1蛋白的表达量。
15.在另一优选例中,所述的rae1基因或ral1基因,或其编码蛋白、突变蛋白、或其促进剂或抑制剂还用于调控植物有机酸的分泌水平。
16.在另一优选例中,所述促进剂或抑制剂为rae1或ral1的促进剂或抑制剂,rae1包括rae1基因,或其编码蛋白、突变蛋白;ral1包括ral1基因,或其编码蛋白、突变蛋白。
17.在另一优选例中,所述促进剂或抑制剂包括rae1基因或ral1基因、或其编码蛋白的促进剂或抑制剂。
18.在另一优选例中,所述植物包括农作物、林业植物、蔬菜、瓜果、花卉、牧草(包括草坪草)。
19.在另一优选例中,所述的植物选自下组:禾本科植物、十字花科植物、或其组合。
20.在另一优选例中,所述的植物选自下组:拟南芥、烟草、水稻、小麦、玉米、高粱、大麦、芸薹属、大豆、或其组合。
21.在另一优选例中,所述的植物为拟南芥。
22.在另一优选例中,所述的rae1基因或ral1基因选自下组:cdna序列、基因组序列、或其组合。
23.在另一优选例中,所述rae1基因或ral1基因、或其编码蛋白来源于十字花科植物。
24.在另一优选例中,所述rae1基因或ral1基因、或其编码蛋白来源于拟南芥(如col-0生态型拟南芥)或其变体。
25.在另一优选例中,所述rae1基因、或其编码蛋白来源于单子叶(如水稻、玉米、大麦等)和双子叶植物(如芸薹属白菜、大豆等)。
26.在另一优选例中,所述rae1基因、或其编码蛋白来源于拟南芥、水稻(osrae1.1、osrae1.2)、玉米(xm_008677340.2)、大麦(ak372025.1)、芸薹属(xm_009132381.2)、大豆(xm_003521974.4)、或其组合。
27.在另一优选例中,所述rae1蛋白的氨基酸序列选自下组:
28.(i)具有seq id no.:35、37-42中任一所示氨基酸序列的多肽;
29.(ii)将如seq id no.:35、37-42中任一所示的氨基酸序列经过一个或几个(如1-10个)氨基酸残基的取代、缺失或添加而形成的,具有与seq id no.:35所示多肽相同功能的由(i)衍生的多肽;或
30.(iii)氨基酸序列与seq id no.:35、37-42中任一所示氨基酸序列的同源性≥80%(较佳地≥90%,更佳地≥95%或≥98%),具有与seq id no.:35、37-42中任一所示多肽相同功能的由(i)衍生的多肽。
31.在另一优选例中,所述rae1基因的核苷酸序列选自下组:
32.(a)编码如seq id no.:35、37-42中任一所示多肽的多核苷酸;
33.(b)序列如seq id no.:36、43-49中任一所示的多核苷酸;
34.(c)核苷酸序列与seq id no.:36、43-49中任一所示序列的同源性≥75%(较佳地≥85%,更佳地≥90%或≥95%)的多核苷酸;
35.(d)在seq id no.:36、43-49中任一所示多核苷酸的5’端和/或3’端截短或添加1-60个(较佳地1-30,更佳地1-10个)核苷酸的多核苷酸;或
36.(e)与(a)-(d)任一所述的多核苷酸互补的多核苷酸。
37.在另一优选例中,所述的编码基因编码上述选自(i)、(ii)或(iii)的rae1蛋白。
38.在另一优选例中,所述ral1基因、或其编码蛋白来源于单子叶(如水稻、玉米、大麦等)和双子叶植物(如芸薹属白菜、大豆等)。
39.在另一优选例中,所述ral1基因、或其编码蛋白来源于拟南芥(at5g27920)、水稻(loc_os12g36670)、玉米(xm_008664387.2)、大麦(ak358574.1)、芸薹属(xm_009113489.2)、大豆(xm_003521631.4)、或其组合。
40.在另一优选例中,所述ral1蛋白的氨基酸序列选自下组:
41.(i)具有seq id no.:50-55中任一所示氨基酸序列的多肽;
42.(ii)将如seq id no.:50-55中任一所示的氨基酸序列经过一个或几个(如1-10个)氨基酸残基的取代、缺失或添加而形成的,具有与seq id no.:50-55中任一所示多肽相同功能的由(i)衍生的多肽;或
43.(iii)氨基酸序列与seq id no.:50-55中任一所示氨基酸序列的同源性≥80%(较佳地≥90%,更佳地≥95%或≥98%),具有与seq id no.:50-55中任一所示多肽相同功能的由(i)衍生的多肽。
44.在另一优选例中,所述ral1基因的核苷酸序列选自下组:
45.(a)编码如seq id no.:50-55中任一所示多肽的多核苷酸;
46.(b)序列如seq id no.:56-61中任一所示的多核苷酸;
47.(c)核苷酸序列与seq id no.:56-61中任一所示序列的同源性≥75%(较佳地≥85%,更佳地≥90%或≥95%)的多核苷酸;
48.(d)在seq id no.:56-61中任一所示多核苷酸的5’端和/或3’端截短或添加1-60个(较佳地1-30,更佳地1-10个)核苷酸的多核苷酸;或
49.(e)与(a)-(d)任一所述的多核苷酸互补的多核苷酸。
50.在另一优选例中,所述的编码基因编码上述选自(i)、(ii)或(iii)的ral1蛋白。
51.本发明的第二方面,提供了一种rae1基因或ral1基因,或其编码蛋白、活性增强的突变蛋白、或其促进剂的用途,用于选自下组的一种或多种用途:
52.(1)降低stop1蛋白的表达量;
53.(2)降低或下调选自下组基因的表达:atalmt1、atmate、als3、或其组合;
54.(3)降低植物抗铝毒能力;和/或
55.(4)制备制剂或农用组合物,且所述的制剂或农用组合物用于降低stop1蛋白的表达量、降低植物抗铝毒能力、或下调选自下组基因的表达:atalmt1、atmate、als3、或其组合。
56.在另一优选例中,rae1基因或ral1基因,或其编码蛋白、活性增强的突变蛋白、或其促进剂通过介导stop1蛋白的泛素化修饰使其降解,从而降低stop1蛋白的表达量。
57.在另一优选例中,所述的活性为介导stop1蛋白降解的活性,较佳地为通过泛素化介导stop1蛋白降解的活性。
58.在另一优选例中,所述的活性增强指所述突变蛋白的介导stop1蛋白降解的活性a1与野生型rae1蛋白或野生型ral1蛋白的介导stop1蛋白降解的活性a0之比≥1.2,较佳地≥1.5。
59.在另一优选例中,所述的降低植物抗铝毒能力包括下调选自下组的基因表达:atalmt1、atmate、als3、或其组合。
60.在另一优选例中,所述促进剂为rae1或ral1的促进剂,其中rae1包括rae1基因、或其编码蛋白、或其活性增强的突变蛋白;ral1包括ral1基因、或其编码蛋白、或其活性增强的突变蛋白。
61.在另一优选例中,所述促进剂包括rae1基因或ral1基因、或其编码蛋白、或其活性增强的突变蛋白的促进剂。
62.在另一优选例中,所述促进剂包括促进rae1基因或其编码蛋白表达、或提高rae1蛋白表达量、或增强rae1蛋白活性的化合物或制剂;和/或
63.所述促进剂包括促进ral1基因或其编码蛋白表达、或提高ral1蛋白表达量、或增强ral1蛋白活性的化合物或制剂。
64.在另一优选例中,所述的促进剂选自下组:小分子化合物、核酸分子、多肽、小分子配体、或其组合。
65.在另一优选例中,所述的核酸分子选自下组:mirna、shrna、sirna、或其组合。
66.本发明的第三方面,提供了一种rae1突变蛋白或ral1突变蛋白、或rae1基因或ral1基因或其编码蛋白的抑制剂的用途,所述的rae1突变蛋白为与野生型rae1蛋白相比活性下降的rae1突变蛋白,所述的ral1突变蛋白为与野生型ral1蛋白相比活性下降的ral1突变蛋白,用于选自下组的一种或多种用途:
67.(1)提高stop1蛋白的表达量;
68.(2)提高或上调选自下组基因的表达:atalmt1、atmate、als3、或其组合;
69.(3)增强植物抗铝毒能力;和/或
70.(4)制备制剂或农用组合物,且所述的制剂或农用组合物用于提高stop1蛋白的表达量、增强植物抗铝毒能力、或上调选自下组基因的表达:atalmt1、atmate、als3、或其组合。
71.在另一优选例中,所述的增强植物抗铝毒能力(或对铝的耐受性)包括:提高植物在铝条件下的存活率、或降低铝毒对植物(如根)的毒害。
72.在另一优选例中,所述的增强植物抗铝毒能力包括上调选自下组的基因表达:atalmt1、atmate、als3、或其组合。
73.在另一优选例中,所述rae1突变蛋白、或rae1基因或其编码蛋白的抑制剂还用于提高植物有机酸(如苹果酸)的分泌水平。
74.在另一优选例中,所述ral1突变蛋白、或ral1基因或其编码蛋白的抑制剂还用于提高植物有机酸(如苹果酸)的分泌水平。
75.在另一优选例中,所述抑制剂包括抑制rae1基因或其编码蛋白表达、或降低rae1蛋白表达量、或降低rae1蛋白活性的化合物或制剂;和/或
76.所述抑制剂包括抑制ral1基因或其编码蛋白表达、或降低ral1蛋白表达量、或降低ral1蛋白活性的化合物或制剂。
77.在另一优选例中,所述的抑制剂选自下组:小分子化合物、核酸分子、多肽、小分子配体、或其组合。
78.在另一优选例中,所述的核酸分子选自下组:mirna、shrna、sirna、或其组合。
79.在另一优选例中,所述的抑制剂选自下组:小分子化合物、反义核酸、microrna、sirna、rnai、crispr试剂、或其组合。
80.在另一优选例中,所述rae1突变蛋白为rae1活性下降或丧失的突变蛋白。
81.在另一优选例中,所述ral1突变蛋白为ral1活性下降或丧失的突变蛋白。
82.在另一优选例中,所述的活性为介导stop1蛋白降解的活性。
83.在另一优选例中,所述的活性下降指所述突变蛋白的介导stop1蛋白降解的活性a1与野生型rae1蛋白或野生型ral1蛋白的介导stop1蛋白降解的活性a0之比≤0.8,较佳地≤0.6。
84.在另一优选例中,所述的rae1突变蛋白是活性下降或活性丧失的突变蛋白。
85.在另一优选例中,所述的rae1突变蛋白是缺失f-box结构域的rae1蛋白。
86.在另一优选例中,所述的ral1突变蛋白是活性下降或活性丧失的突变蛋白。
87.在另一优选例中,所述的ral1突变蛋白是缺失f-box结构域的ral1蛋白。
88.在另一优选例中,所述的rae1突变蛋白在对应于野生型的rae1蛋白的选自下组的氨基酸发生突变:第167位(g)、第439位(g)、第466位(r)、第524位(q)、第568位(s)、第116位(g)、第193位(g)、第400位(w)、或其组合。
89.在另一优选例中,所述的rae1突变蛋白在对应于野生型的rae1蛋白具有选自下组的突变:g167r、g439r、r466k、q524stop、s568l、g116r、g193r、w400stop、或其组合。
90.在另一优选例中,所述野生型rae1蛋白的氨基酸序列如seq id no.:35、37-42中任一所示。
91.在另一优选例中,所述野生型ral1蛋白的氨基酸序列如seq id no.:50-55中任一所示。
92.本发明的第四方面,提供了一种调控植物抗铝毒能力的方法,所述方法包括步骤:调节所述植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而调控植物抗铝毒能力。
93.在另一优选例中,适用于所述方法的所述植物包括农作物、林业植物、蔬菜、瓜果、花卉、牧草(包括草坪草)。
94.在另一优选例中,所述调控植物抗铝毒能力为增强植物抗铝毒能力时,下调植物中rae1蛋白或ral1蛋白的表达量和/或活性,或使rae1蛋白或ral1蛋白丧失活性。
95.在另一优选例中,所述调控植物抗铝毒能力为降低植物抗铝毒能力时,上调植物中rae1蛋白或ral1蛋白的表达量和/或活性。
96.在另一优选例中,所述方法还用于调控植物(如根)分泌的有机酸水平。
97.在另一优选例中,所述调控植物抗铝毒能力包括调控植物(如根)分泌的有机酸水平。
98.本发明的第五方面,提供了一种调控基因的表达的方法,所述方法包括步骤:
99.(i)调节所述植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而调控基因的表达;
100.其中,所述基因选自下组:atalmt1、atmate、als3、或其组合。
101.在另一优选例中,步骤(i)包括:上调植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而下调选自下组的基因的表达:atalmt1、atmate、als3、或其组合。
102.在另一优选例中,步骤(i)包括:下调植物中rae1蛋白或ral1蛋白的表达量和/或
活性,从而上调选自下组的基因的表达:atalmt1、atmate、als3、或其组合。
103.在另一优选例中,所述方法还包括步骤:
104.(ii)调控所述植物中stop1蛋白的表达量和/或活性,从而调控rae1基因的表达。
105.本发明的第六方面,提供了一种调控stop1蛋白水平的方法,所述方法包括步骤:
106.(a)调节所述植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而调控stop1蛋白水平。
107.在另一优选例中,步骤(a)包括:上调植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而下调stop1蛋白水平。
108.在另一优选例中,步骤(a)包括:下调植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而上调stop1蛋白水平。
109.在另一优选例中,所述下调stop1蛋白水平包括促进stop1蛋白的降解。
110.在另一优选例中,所述上调stop1蛋白水平包括减少或抑制stop1蛋白的降解。
111.本发明的第七方面,提供了一种分离的突变型rae1蛋白或突变型ral1蛋白,所述突变型rae1蛋白或突变型ral1蛋白为非天然蛋白,且所述突变型rae1蛋白或突变型ral1蛋白用于选自下组的一种或多种用途:
112.(1)调控stop1蛋白的表达或降解;
113.(2)调控植物抗铝毒能力或耐铝性能;和/或
114.(3)调控选自下组基因的表达:atalmt1、atmate、als3、或其组合。
115.在另一优选例中,所述的突变型rae1蛋白或突变型ral1蛋白包括活性增加的突变蛋白、或活性下降的突变蛋白。
116.在另一优选例中,所述突变型rae1蛋白或突变型ral1蛋白是活性下降或丧失的突变蛋白。
117.在另一优选例中,所述的rae1突变蛋白在对应于野生型的rae1蛋白的选自下组的氨基酸发生突变:第167位(g)、第439位(g)、第466位(r)、第524位(q)、第568位(s)、第116位(g)、第193位(g)、第400位(w)、或其组合。
118.在另一优选例中,所述的rae1突变蛋白在对应于野生型的rae1蛋白具有选自下组的突变:g167r、g439r、r466k、q524stop、s568l、g116r、g193r、w400stop、或其组合。
119.在另一优选例中,所述野生型rae1蛋白的氨基酸序列如seq id no.:35、37-42中任一所示。
120.在另一优选例中,所述野生型ral1蛋白的氨基酸序列如seq id no.:50-55中任一所示。
121.在另一优选例中,所述突变型rae1蛋白除所述突变外,其余的氨基酸序列与seq id no.:35、37-42中任一所示的序列相同或基本相同。
122.在另一优选例中,所述的基本相同是至多有50个(较佳地为1-20个,更佳地为1-10个、更佳地1-5个)氨基酸不相同,其中,所述的不相同包括氨基酸的取代、缺失或添加,且所述突变型rae1蛋白不具有介导stop1蛋白降解的活性。
123.在另一优选例中,所述突变型rae1蛋白或突变型ral1蛋白具有选自下组的一种或多种用途:
124.(1)提高stop1蛋白的表达量;
125.(2)增强植物抗铝毒能力;和/或
126.(3)提高或上调选自下组基因的表达:atalmt1、atmate、als3、或其组合。
127.本发明的第八方面,提供了一种多核苷酸,所述多核苷酸编码本发明第七方面所述的突变型rae1蛋白或突变型ral1蛋白。
128.本发明的第九方面,提供了一种rae1蛋白或ral1蛋白,或其编码基因的用途,用于筛选具有调控植物抗铝毒能力的药物。
129.在另一优选例中,所述的药物选自下组:小分子化合物、多肽、核酸、小分子配体、或其组合。
130.本发明的第十方面,提供了一种鉴定植物抗铝毒能力调控剂的方法,所述方法包括步骤:
131.(a)提供待鉴定的调控剂,和rae1基因或ral1基因或其编码蛋白;
132.(b)将所述待鉴定的化合物和所述rae1基因或ral1基因或其编码蛋白接触;
133.(c)测定所述rae1蛋白或ral1蛋白的活性或表达量;
134.(d)基于步骤(c)的结果,鉴定所述化合物为植物抗铝毒能力促进剂或抑制剂。
135.在另一优选例中,步骤(c)的结果为rae1蛋白的活性和/或表达量降低或下调,则所述待鉴定的化合物为植物抗铝毒能力促进剂。
136.在另一优选例中,步骤(c)的结果为rae1蛋白的活性和/或表达量增加或上调,则所述待鉴定的化合物为植物抗铝毒能力抑制剂。
137.在另一优选例中,步骤(c)的结果为ral1蛋白的活性和/或表达量降低或下调,则所述待鉴定的化合物为植物抗铝毒能力促进剂。
138.在另一优选例中,步骤(c)的结果为ral1蛋白的活性和/或表达量增加或上调,则所述待鉴定的化合物为植物抗铝毒能力抑制剂。
139.本发明的第十一方面,提供了调控rae1的表达的方法,所述方法包括步骤:
140.(a)调控所述植物中stop1蛋白的表达量和/或活性,从而调控rae1基因的表达。
141.在另一优选例中,所述方法为上调rae1的表达的方法,所述方法包括步骤:
142.(a)下调所述植物中stop1蛋白的表达量和/或活性。
143.在另一优选例中,所述方法为非治疗和非诊断目的的。
144.本发明还提供了一种rae1基因或rae1蛋白的抑制剂,所述抑制剂中含有stop1蛋白或其编码基因作为活性成分。
145.应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。
附图说明
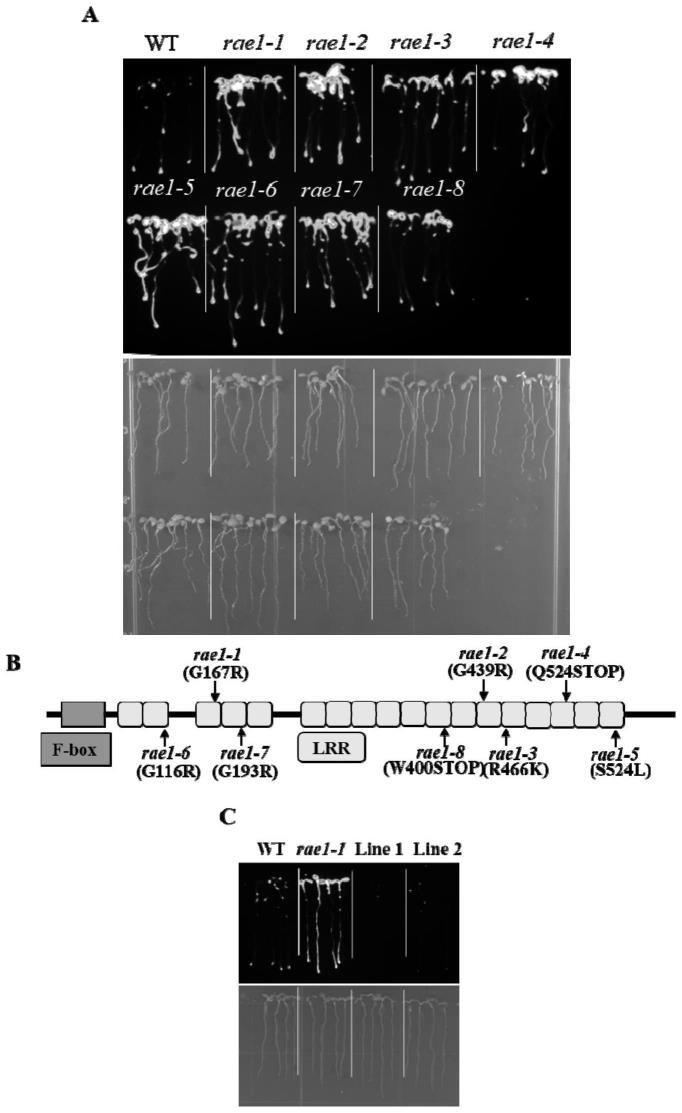
146.图1显示了突变体rae1中patalmt1:luc表达增强。其中,(a)筛选获得8个patalmt1:luc表达增强突变体;(b)突变体rae1在蛋白序列上的突变位点;(c)prae1:rae1转基因株系回补突变体rae1-1的patalmt1:luc表达。
147.图2显示了qpcr分析wt、rae1-1、rae1-2、stop1-3中各基因的表达水平。其中,(a)报告基因luc;(b)atalmt1;(c)atmate;(d)als3;(e)atstar1;(f)als1。
148.图3显示了qpcr分析wt、过量表达rae1株系rae1-ox1和rae1-ox2中各基因的表达水平。其中,(a)rae1;(b)atalmt1;(c)atmate;(d)als3;(e)atstar1;(f)als1。
149.图4显示了rae1的表达调控机制。(a)qpcr分析各组织中rae1的表达(b)rae1表达受到al处理的诱导,并受到stop1的调控,在rae1中表达水平上调(c)gus活性分析prae1:gus的表达(d、e、f、g、h、i)gus染色分析prae1:gus的表达(j)原生质体表达系统显示stop1调控prae1:luc的表达,将结合区域突变则调控减弱(k)emsa验证stop1直接结合rae1的启动子上的结合区域。
150.图5显示了rae1与stop1在体内和体外均互作。(a)pull-down试验体外验证rae1与stop1互作,gst-stop1和rae1-his组合可以拉下rae1蛋白,gst-rae1和his-trx-stop1组合可以拉下stop1蛋白,其他组合为负对照;(b)split-luc试验体内验证rae1与stop1互作,stop1-nluc和cluc-rae1-1/cluc-rae1
△
f产生luc荧光信号,stop1-nluc和cluc-rae1的组合未产生luc荧光信号,其他组合为负对照;(c)co-ip试验体内验证rae1与stop1互作,flag-rae1/flag-rae1-1/flag-rae1
△
f和stop1-ha在原生质体共表达,蛋白粗提液用flag磁珠进行免疫沉淀,stop1-ha蛋白用ha抗体检测。
151.图6显示了stop1蛋白在突变体rae1中积累,,而过量表达rae1促进stop1蛋白降解。western blot分析pstop1:stop1-ha转基因株系在突变体rae1和过量表达rae1株系中stop1蛋白水平。
152.图7显示了蛋白酶体抑制剂mg132稳定stop1蛋白。(a)mg132处理1和3小时stop1蛋白被稳定;(b)在无铝条件和有铝条件stop1蛋白均被mg132稳定;(c)gus染色分析pstop1:stop1-gus转基因株系中stop1蛋白水平;(d)分析pstop1:stop1-gus转基因株系中的gus活性。
153.图8显示了rae1通过介导stop1蛋白的泛素化修饰使其降解。(a)原生质表达系统中stop1蛋白随rae1表达增多而降解,突变体蛋白rae1-1和rae1
△
f不能降解stop1;(b)原生质表达系统中验证stop1蛋白被泛素化修饰;(c)原生质表达系统中突变体蛋白rae1-1和rae1
△
f不能介导stop1的泛素化修饰。
154.图9显示了突变体rae1耐铝能力提高,而过表达rae1株系耐铝能力下降。其中,(a)铝毒处理条件下rae1的苹果酸分泌比野生型增多;(b)铝在rae1根中的积累比野生型减少;(c)铝毒处理条件下rae1和野生型的根长照片;(d)铝毒处理条件下rae1的根相对生长量比野生型更长;(e)铝毒处理条件下过表达rae1株系和野生型的根长照片(f)铝毒处理条件下过表达rae1株系的根相对生长量比野生型更短。
155.图10显示了ral1中atalmt1表达上调且ral1与stop1互作。(a)ral1中atalmt1表达上调;(b)ral1中patalmt1:luc表达上调,rae1与ral1的双突变体中patalmt1:luc的表达大幅上调;(c)ral1表达受到al处理的诱导,并受到stop1的调控,在rae1中表达水平上调;(d)gus染色分析pral1:gus的表达(e)split-luc试验体内验证ral1与stop1互作,stop1-nluc和cluc-ral1
△
f产生luc荧光信号,stop1-nluc和cluc-ral1的组合未产生luc荧光信号,因为ral1介导了stop1蛋白的降解。
156.图11显示osrae1的表达模式且osrae1与art1互作。(a)osrae1.1和osrae1.2在根尖和根基部均表达,而且表达均被al诱导;(b)art1中osrae1.1的表达下降;(c)split-luc试验体内验证osrae1.1与artt1互作,art1-nluc和cluc-osrae1.1
△
f产生luc荧光信号。
具体实施方式
157.本发明人经过广泛而深入的研究,通过大量诱变、筛选和分析,首次意外地发现了一种调控抗铝毒转录因子stop1蛋白稳定性的基因rae1和ral1基因。所述rae1基因或ral1基因或其编码蛋白、或其突变蛋白、或其促进剂或抑制剂可用于(1)调控stop1蛋白的表达或降解;(2)调控植物抗铝毒能力或耐铝性能;和/或(3)调控选自下组基因的表达:atalmt1、atmate、als3、或其组合。实验表明,rae1或ral1介导stop1蛋白的降解。此外,rae1-1突变蛋白和去掉f-box结构域蛋白丧失了介导stop1降解的功能。此外,本发明人还首次意外地发现,下调植物中的rae1蛋白的表达量和/或活性,可显著抑制stop1的降解,上调atalmt1的表达量,增多有机酸(如苹果酸)的分泌和增强植物的抗铝毒能力(或对铝的耐受)。相反,过量表达植物中的rae1蛋白的表达量和/或活性,可显著促进stop1的降解,下调atalmt1的表达量,减少有机酸(如苹果酸)的分泌和增强植物的对铝毒的敏感性。在此基础上,本发明人完成了本发明。
158.构建了atalmt1启动子与荧光素酶基因融合的luc报告基因系(patalmt1:luc),利用该材料进行ems诱变来筛选影响luc报告基因表达的突变体。利用其中一个luc表达增强突变体克隆了一个新的负调控atalmt1表达的基因,命名为rae1(regulation of atalmt1 expression 1),一共筛选获得8个rae1上不同位点突变的突变体(rae1-1到rae1-8)。构建载体prae1:rae1通过侵染rae1-1获得回补转基因株系,2个株系均回补rae1-1荧光表型。
159.除了luc报告基因和atalmt1以外,其他stop1下游调控基因atmate和als3的表达在突变体rae1中无论在无铝条件还是有铝条件下均比野生型(wt)提高。相反,过量表达rae1,可降低ataltm1、atmate和als3的表达。rae1表达受到铝处理的诱导,并受到stop1的调控,在rae1中rae1的表达水平也上调。原生质体表达系统显示stop1调控prae1:luc的表达,将结合区域突变则调控减弱,emsa验证stop1直接结合rae1的启动子上的结合区域。rae1表达在植物各组织中均有表达,且主要在维管组织表达。
160.通过体外pull-down试验、烟草split-luc试验以及体内co-ip试验证明rae1能够与stop1蛋白互作。rae1-1突变蛋白和去掉f-box结构域蛋白并没有丧失与stop1结合的能力,而rae1在体内与stop1互作信号较弱可能是因为rae1介导了stop1蛋白的降解。
161.构建pstop1:stop1-ha转基因株系检测stop1蛋白,铝处理可以使stop1蛋白积累,在rae1-1突变体中stop1蛋白无论在无铝条件还是有铝条件下均比野生型增多。蛋白酶体抑制剂mg132处理可以抑制stop1在无铝条件或有铝条件下的降解,使蛋白增多。进一步通过原生质表达系统证明,rae1介导stop1蛋白泛素化修饰并降解。此外,rae1-1突变蛋白和去掉f-box结构域蛋白丧失了使stop1通过泛素化修饰并降解的功能。相反,过量表达rae1可促进stop1蛋白的降解。
162.分析突变体rae1的耐铝表型,rae1的苹果酸分泌比野生型增多,铝在根上的积累减少,铝毒处理条件下rae1的根长比野生型更长。相反,过量表达rae1在铝毒处理条件下的根长比野生型更短。
163.rae1在拟南芥中有一个同源基因ral1(rae1 like 1),ral1的t-dna敲除突变体ral1中atalmt1、patalmt1:luc的表达上调,但是上调幅度比在rae1-1中更低。patalmt1:luc的表达在rae1-1ral1双突变体中比在各单突变体中表达更高,表明rae1与ral1存在功能冗余。ral1的表达也受铝毒的诱导,但是ral1在根中表达的组织部位与rae1不同。烟草
split-luc试验证明ral1能够与stop1蛋白互作。以上表明,ral1具有与rae1相同的降解stop1蛋白的功能,但由于它不在根尖分生组织和伸长区表达,rae1在植物抗铝毒方面起重要作用。
164.rae1和ral1在大多数单子叶(水稻、玉米、大麦等)和双子叶植物(芸薹属白菜、大豆等)中均有相应的同源基因。水稻中rae1的同源基因是osrae1.1和osrae1.2,两个同源基因氨基酸序列有97.5%相似性,osrae1.1和osrae1.2在根尖和根基部均表达,而且表达均被al诱导,被art1(水稻中与stop1同源的基因)调控。烟草split-luc试验证明osrae1.1能够与art1蛋白互作。因此,我们认为,rae1在调控植物抗铝毒转录因子stop1稳定性机制上是保守的,对作物中的rae1同源基因进行功能缺失突变有可能可以提高作物抗铝毒能力。
165.术语
166.除非另外定义,否则本文中所用的全部技术与科学术语均具有如本发明所属领域的普通技术人员通常理解的相同含义。
167.如本文所用,在提到具体列举的数值中使用时,术语“约”意指该值可以从列举的值变动不多于1%。例如,如本文所用,表述“约100”包括99和101和之间的全部值(例如,99.1、99.2、99.3、99.4等)。
168.如本文所用,术语“含有”或“包括(包含)”可以是开放式、半封闭式和封闭式的。换言之,所述术语也包括“基本上由
…
构成”、或“由
…
构成”。
169.如本文所用,术语“axxb”表示第xx位的氨基酸a变为氨基酸b,例如“g167r”表示第167位的氨基酸g突变为r,以此类推。
170.如本文所用,术语“axxstop”表示第xx位的氨基酸a变为终止密码,例如“q524stop”表示第524位的氨基酸q突变为终止密码,以此类推。
171.如本文所用,术语“抗铝毒能力”、“耐铝能力”、“耐铝表型”、“对铝的耐受性”可互换使用,均指对铝的抵抗能力。
172.如本文所用,术语“植物”没有特别的限制,包括(但不限于):花卉植物、水果植物、林业植物、蔬菜、农作物等,例如水稻、小麦、玉米、大豆、高粱、芸薹属、大麦等。
173.水果植物包括(但不限于):柑橘科、蔷薇科、葫芦科、芭蕉科的植物等。
174.蔬菜植物包括(但不限于):菊科、茄科、唇形科、伞形科、十字花科的植物。
175.农作物例如但不限于:禾本科、石蒜科的植物等。
176.在本发明的一个优选例中,所述植物选自十字花科,更佳地为拟南芥属植物。
177.如本文所用,本发明rae1蛋白包括野生型rae1蛋白和突变型rae1蛋白。
178.如本文所用,本发明ral1蛋白包括野生型ral1蛋白和突变型ral1蛋白。
179.本发明突变蛋白及其编码核酸
180.如本文所用,术语“突变蛋白”、“本发明突变蛋白”包括突变型rae1蛋白和突变型ral1蛋白。
181.如本文所用,术语“突变型rae1蛋白”、“本发明突变型rae1蛋白”可互换使用,均指非天然存在的rae1突变蛋白,且所述突变蛋白为基于seq id no.:35、37-42中任一所示蛋白进行人工改造的蛋白。所述的突变蛋白含有与介导stop1降解活性相关的核心氨基酸。
182.在另一优选例中,所述的突变型rae1蛋白包括活性增加的突变蛋白、或活性下降的突变蛋白。
183.如本文所用,术语“突变型ral1蛋白”、“本发明突变型ral1蛋白”可互换使用,均指非天然存在的ral1突变蛋白,且所述突变蛋白为基于seq id no.:50-55中任一所示蛋白进行人工改造的蛋白。所述的突变蛋白含有与介导stop1降解活性相关的核心氨基酸。
184.在另一优选例中,所述的突变型ral1蛋白包括活性增加的突变蛋白、或活性下降的突变蛋白。
185.在另一优选例中,所述的活性为介导stop1蛋白降解的活性。
186.在另一优选例中,所述突变型rae1蛋白或突变型ral1蛋白是活性下降或丧失的突变蛋白。
187.在另一优选例中,所述突变蛋白的所述核心氨基酸中至少有一个是经过人工改造的,并且具有降低或丧失介导stop1降解的活性。
188.优选地,在本发明中,所述的rae1突变蛋白在对应于野生型的rae1蛋白的选自下组的氨基酸发生突变:第167位(g)、第439位(g)、第466位(r)、第524位(q)、第568位(s)、第116位(g)、第193位(g)、第400位(w)、或其组合。上述突变可导致rae1蛋白的活性大幅下降甚至丧失。
189.应理解,本发明突变蛋白中的氨基酸编号基于seq id no.:35作出,当某一具体突变蛋白与seq id no.:35所示序列的同源性达到80%或以上时,突变蛋白的氨基酸编号可能会有相对于seq id no.:35的氨基酸编号的错位,如向氨基酸的n末端或c末端错位1-5位,而采用本领域常规的序列比对技术,本领域技术人员通常可以理解这样的错位是在合理范围内的,且不应当由于氨基酸编号的错位而使同源性达80%(如90%、95%、98%)的、具有相同或相似的活性的突变蛋白不在本发明突变蛋白的范围内。
190.本发明突变蛋白是合成蛋白或重组蛋白,即可以是化学合成的产物,或使用重组技术从原核或真核宿主(例如,细菌、酵母、植物)中产生。根据重组生产方案所用的宿主,本发明的突变蛋白可以是糖基化的,或可以是非糖基化的。本发明的突变蛋白还可包括或不包括起始的甲硫氨酸残基。
191.本发明还包括所述突变蛋白的片段、衍生物和类似物。如本文所用,术语“片段”、“衍生物”和“类似物”是指基本上保持所述突变蛋白相同的生物学功能或活性的蛋白。
192.本发明的突变蛋白片段、衍生物或类似物可以是(i)有一个或多个保守或非保守性氨基酸残基(优选保守性氨基酸残基)被取代的突变蛋白,而这样的取代的氨基酸残基可以是也可以不是由遗传密码编码的,或(ii)在一个或多个氨基酸残基中具有取代基团的突变蛋白,或(iii)成熟突变蛋白与另一个化合物(比如延长突变蛋白半衰期的化合物,例如聚乙二醇)融合所形成的突变蛋白,或(iv)附加的氨基酸序列融合到此突变蛋白序列而形成的突变蛋白(如前导序列或分泌序列或用来纯化此突变蛋白的序列或蛋白原序列,或与抗原igg片段的形成的融合蛋白)。根据本文的教导,这些片段、衍生物和类似物属于本领域熟练技术人员公知的范围。本发明中,保守性替换的氨基酸最好根据表i进行氨基酸替换而产生。
193.表i
194.最初的残基代表性的取代优选的取代ala(a)val;leu;ilevalarg(r)lys;gln;asnlys
asn(n)gln;his;lys;argglnasp(d)gluglucys(c)sersergln(q)asnasnglu(e)aspaspgly(g)pro;alaalahis(h)asn;gln;lys;argargile(i)leu;val;met;ala;pheleuleu(l)ile;val;met;ala;pheilelys(k)arg;gln;asnargmet(m)leu;phe;ileleuphe(f)leu;val;ile;ala;tyrleupro(p)alaalaser(s)thrthrthr(t)sersertrp(w)tyr;phetyrtyr(y)trp;phe;thr;serpheval(v)ile;leu;met;phe;alaleu
195.本发明的活性下降的突变蛋白不具有介导stop1蛋白降解的活性。
196.此外,还可以对本发明突变蛋白进行修饰。修饰(通常不改变一级结构)形式包括:体内或体外的突变蛋白的化学衍生形式如乙酰化或羧基化。修饰还包括糖基化,如那些在突变蛋白的合成和加工中或进一步加工步骤中进行糖基化修饰而产生的突变蛋白。这种修饰可以通过将突变蛋白暴露于进行糖基化的酶(如哺乳动物的糖基化酶或去糖基化酶)而完成。修饰形式还包括具有磷酸化氨基酸残基(如磷酸酪氨酸,磷酸丝氨酸,磷酸苏氨酸)的序列。还包括被修饰从而提高了其抗蛋白水解性能或优化了溶解性能的突变蛋白。
197.本发明还提供了编码rae1多肽、蛋白或其变体的多核苷酸序列。本发明的多核苷酸可以是dna形式或rna形式。dna形式包括:dna、基因组dna或人工合成的dna,dna可以是单链的或是双链的。dna可以是编码链或非编码链。
198.术语“编码突变蛋白的多核苷酸”可以是包括编码本发明突变蛋白的多核苷酸,也可以是还包括附加编码和/或非编码序列的多核苷酸。
199.本发明还涉及上述多核苷酸的变异体,其编码与本发明有相同的氨基酸序列的多肽或突变蛋白的片段、类似物和衍生物。这些核苷酸变异体包括取代变异体、缺失变异体和插入变异体。如本领域所知的,等位变异体是一个多核苷酸的替换形式,它可能是一个或多个核苷酸的取代、缺失或插入,但不会从实质上改变其编码的突变蛋白的功能。
200.本发明还涉及与上述的序列杂交且两个序列之间具有至少50%,较佳地至少70%,更佳地至少80%相同性的多核苷酸。本发明特别涉及在严格条件(或严紧条件)下与本发明所述多核苷酸可杂交的多核苷酸。在本发明中,“严格条件”是指:(1)在较低离子强度和较高温度下的杂交和洗脱,如0.2
×
ssc,0.1%sds,60℃;或(2)杂交时加有变性剂,如50%(v/v)甲酰胺,0.1%小牛血清/0.1%ficoll,42℃等;或(3)仅在两条序列之间的相同
no.:37所示。
213.maspmptpthrvkrrrldlsppphlndladellflildraaahdpralksfslvsrachaaesrhrrvlrpfrpdllpaalarypalsrldlslcprlpdaalaalpaapsvsavdlsrsrgfgaaglaalvaacpnltdldlsngldlgdaaaaevakarrlqrlslsrckritdmglgciavgcpdlrelslkwcigvthlgldllalkcnklnildlsytmivkkcfpaimklqslqvlllvgcngidddaltsldqecskslqvldmsnyynvthvgvlsivkampnllelnlsycspvtpsmsssfemihklqtlkldgcqfmddglksigkscvslrelslskcsgvtdtdlsfvvprlknllkldvtccrkitdvslaaittscpslislrmescslvsskglqligrrcthleeldltdtdlddeglkalsgcsklsslkigiclritdeglrhvskscpdlrdidlyrsgaisdegvthiaqgcpmlesinlsyctkltdcslrslskciklntleirgcpmvssaglseiatgcrllskldikkcfeindmgmiflsqfshnlrqinlsycsvtdiglislssicglqnmtivhlagvtpngliaalmvcglrkvklheafksmvpshmlkvveargclfqwinkpyqvavepcdvwkqqsqdllvq(seq id no.:37)
214.在另一优选例中,所述rae1蛋白来源于水稻(osrae1.2),氨基酸序列如seq id no.:38所示。
215.maspapthhakrrrlalpppppphlndladellflildraaahdpralksfslvsrachaaesrhrrvlrpfrpdllpaalarypaishldlslcprlpdaalaalpaapfvsavdlsrsrgfgaaglaalvaafpnltdldlsngldlgdaaaaevakarrlqrlslsrckritdmglgciavgcpdlrelslkwcigvthlgldllalkcnklnildlsytmivkkcfpaimklqnlqvlllvgcngidddaltsldqecskslqvldmsnsynvthvgvlsivkampnllelnlsycspvtpsmsssfemihklqklkldgcqfmddglksigkscvslrelslskcsgvtdtdlsfvvprlknllkldvtccrkitdvslaaittscpslislrmescslvsskglqligrrcthleeldltdtdlddeglkalsgcsklsslkigiclritdeglrhvskscpdlrdidlyrsgaisdegvthiaqgcpmlesinmsyctkltdcslrslskciklntleirgcpmvssaglseiatgcrllskldikkcfeindmgmiflsqfshnlrqinlsycsvtdiglislssicglqnmtivhlagvtpngliaalmvcglrkvklheafksmvpshmlkvveargclfqwinkpyqvavepcdvwkqqsqdllvq(seq id no.:38)
216.在另一优选例中,所述rae1蛋白来源于玉米,氨基酸序列如seq id no.:39所示。
217.mamaaqqhrhhkrrrialspspspslapipgaptppldsladellflvldrvaqadpralksfalasrachaaesrhrrtlrplradllpaalarypsatrldltlcarvpdaalasaavsgssalravdlsrsrgfgaagvaalaaacpdladldlsngvhlgdaaaaevararalrrlslvrwkpltdmglgcvavgctelkdlslkwclgltdlgiqllalkcrkltsldlsytmitkdslpsimklpnlqeltlvgcigiddgalvslerecskslqvldmsqcqnitdvgvssilksvpnlleldlsyccpvtpsmvrnfqklpklqalklegckfmanglkaigtscvslrelslskssgvtdtelsfvvsrlknllklditccrsitdvslaaitssctslislrmescshvssgalqligkhcshleeldltdsdlddeglkalarcselsslkigiclkisdeglshigrscpklreidlyrcgvisddgiiqiaqgcpmlesinlsycteitdrslislskcaklntleirgcpsvssiglseiamgcrllskldikkcfgindvgmlylsqfahslrqinlsycsvtdvgllslssisglqnmtivhlagitpngltatlmvcggltkvklheafrsmmpphtiknveargcvfqwidkpfkvevepcdvwkqqsqdvlvr(seq id no.:39)
218.在另一优选例中,所述rae1蛋白来源于大麦,氨基酸序列如seq id no.:40所示。
219.iskdclpaimelpnlevlalvgcvgidddalsglenesskslrvldmstcrnvthtgvssvvkalpnllelnlsyccnvtasmgkcfqmlpklqtlklegckfmadglkhigiscvslrelslskcsgvtdtdlsfvvsrlknllklditcnrnitdvslaaitsschslislriescshfsseglrligkrcchleelditdsdlddeglkalsgcsklsslkigicmrisdqglihigkscpelrdidlyrsggisdegvtqiaqgcpmlesinlsycteitdvslmslskcak
lntleirgcpsissaglseiaigcrllakldvkkcfaindvgmfflsqfshslrqinlsycsvtdigllslssicglqnmtivhlagitpngllaalmvsggltrvklhaafrsmmpphmlkvveargcafqwidkpfkveqercdiwqqqsrdvlvr(seq id no.:40)
220.在另一优选例中,所述rae1蛋白来源于芸薹属,氨基酸序列如seq id no.:41所示。
221.mkkakqiqhmiskpfdllseelvfiildlvaqnpsdlksfsltckwfyqvearhrrslkplraeylpriltryrntadldlsfcprvtdyalsvvgclsgptlrsvdlsrsfsfsaagllrlavkcvslveidlsnatemrdaaaavvaeakslerlklgrckkltdmgigciavgcrklkrvslkwcvgvgdlgvgllavkckdirsldlsylpitgkclhdvlklqhleelllqgcfgvdddslkslthhcnslknldasscqnltqrgltsllsgagclerldlahsssvisldfasslnkvssalqsirldgcavtcdglkaigtlcislrevslskcvtvtdeglsclvmklkdlrklditccrkltgvsitqvasscpllvslkmescslvsrdafwlighkcrlleeldftdneiddeglksisscrslsslklgiclnitdrglsyigmgcsnlreldlyrsvgitdvgissiaqgcchletinisyckditdkslvslskcsmlqtfesrgcphitcqglaaiavrckrlskldlkkcpfindsglltlahfsqglkqisvsetgvtdvglvslanigclqniaavntrglspsgvaaalvgcgglrkvklhaslrsllpsslinhmeargcsflwkdynnhnnsntlqaeldpkywkv(seq id no.:41)
222.在另一优选例中,所述rae1蛋白来源于大豆,氨基酸序列如seq id no.:42所示。
223.msriyssnietkqtnpsllspqlfiinlqndqpnakrrtmkkqklsepqndttnpfevlseelmfvildflqttsldkksfsltcklfysveakhrrllrplraehlpalaarypnvteldlslcprvgdgalglvagayaatlrrmdlsrsrrftatgllslgarcehlveldlsnatelrdagvaavararnlrklwlarckmvtdmgigciavgcrklrllclkwcvgigdlgvdlvaikckelttldlsylpitekclpsifklqhledlvlegcfgidddsldvdllkqgcktlkrldisgcqnishvglskltsisgglekliladgspvtlsladglnklsmlqsivldgcpvtseglraignlcislrelslskclgvtdealsflvskhkdlrklditccrkitdvsiasiansctgltslkmesctlvpseafvligqkchyleeldltdneiddeglmsisscswltslkigiclnitdrglayvgmrcsklkeldlyrstgvddlgisaiaggcpglemintsyctsitdralialskcsnletleirgcllvtsiglaaiamncrqlsrldikkcyniddsgmialahfsqnlrqinlsyssvtdvgllslanisclqsftllhlqglvpgglaaallacggltkvklhlslrsllpellirhveargcvfewrdkefqaeldpkcwklqledvi(seq id no.:42)
224.如本文所用,术语“本发明rae1基因”、“rae1基因”可以互换使用。
225.在本发明中,rae1的基因包括基因组基因、cdna序列、mrna序列。
226.在本发明中,所述rae1基因来源于拟南芥,核酸序列如seq id no.:36(dna序列)或seq id no.:43(mrna序列)所示。
227.gggttttttccaaaatcctcaaagagagactatacttctctcggatccttcctgatttcaaaatttcttcaacccaccagcagcagcagcagatgaagaaggttaaacagattcgtgtcttaaagcctttcgatcttctctcggaagagctcgtctttatcatccttgacctcatctctcccaacccttccgatctcaaatccttctctcttacttgcaaatctttctaccagctcgagtccaagcaccgcggatccttaaaacctctccgctccgactatctccctcgcatcttgactcgttaccggaacaccaccgatctcgatcttaccttctgcccgcgtgtcactgactacgcgcttagcgtcgttggctgtctctccggacctacgcttcgctccctcgacctctcgcgctctggctccttctccgccgcgggactactgcgattggccctcaaatgtgtcaatttagtcgagattgacctgtccaatgcgacggagatgagagacgccgatgctgcggtggtggcggaggcgaggagtctggagaggctgaagctgggcagatgcaagatgctgacggacatgggaatcggatgtatagcagttggatgtaagaagctcaatacggttagcttgaaatggtgtgttggcgtcggagatttaggggttgg
cttgcttgccgtcaaatgcaaggacattcgcaccttagacctctcctacttgccggtaattaacttctctcttcacattttcttaatccgcagagccaaatttcgattaatatggtaagtttgtcgaattggaattatttctaaatttgttcttcctgagacctgttggttgatttttcaagttaacaacaagttttggttgaacttttggtctttcaacatctgtggatcattatctatctgaattcgacactttaagtgccatatgtttggattatatcttcagaggagctggaaattcaaacctattcttttgttccgtattctacagatcacaggaaagtgtttacatgacattctgaaacttcaacaccttgaagaacttcttctagaagggtgctttggagtagatgatgacagtcttaaatcactcagacatgattgcaagtcattgaaggtaacctctattccaagaaatttgtttgattcttatacatgagatcacataatagttttggaatcgacttgacagacaaactttttagttgatattttagaacagaaaacttggtattctcagaatatggcttggagaagatgttacgcttcttcttgctcgctgcatttattctggaaacatttaacttttatgagagaagatgtataaacaggtttcatgttttcttagactcagaaagctatttatcattgaaagtctaatgctggaagactatatagttgattgttttcatcatcatcttatccatagacatttgagattttacttaccaaaacctgtgttctgcagaagcttgatgcatccagctgccagaatttaactcatagaggtttaacctcacttttaagcggggcaggatatcttcagcgacttgatctatcacactgttcttctgtaagttctccgttttctcattatcatcagaacacatgctttccttgctttgttctctggttatggcctgtatgtaagtatttgctaaatggctgagtcaacttagtttggcactaaaactctttagtagtagcaaaaccagtaattgcacataccaccgaatagaccatttgtgtcatggatcgatagcagtacacagacccaccaagttctatgatgccttcttatatgaggtttatttactgatttaggtgatatcattggattttgcgagtagcttaaagaaggtttcagcattacagtcgatcaggttggatggttgttctgttacgcctgatggtttgaaggcgataggcacattgtgcaattccctgaaagaggttagcctaagcaaatgcgtgagcgtaactgatgaaggtctttcttctctagtaatgaaactgaaagacctcagaaaacttgacatcacatgttgccggaaactaagtagagtttcaatcacccaaatcgccaattcgtgtcctttactagtctctttgaagatggagtcttgttctcttgtttccagagaagccttttggttgatcggacaaaagtgtcggctacttgaagagcttgacttaactgacaacgagattgatgatgaaggttctttattttcttcagatcaattcttagaaccgtggtttttggattataccttatcttgttagtctttcctcgtatgatgcaggactgaaatccatatctagttgtctgagtctttcctcgttaaagctgggaatttgtcttaacataacagacaaagggctctcgtacatcgggatgggctgttcaaatctccgtgaacttgatctctataggtatctcgcgtagaaatttatttttcagtcgggtcaataataaaattctccgttctcaatctagtctttatctactccaggtcagtgggaataacagacgtaggcatctccacaattgcccaaggctgcattcatctggaaacaataaacatttcatactgccaagacataacagacaagtccctggtttcattgtccaaatgctcgttgttacaaacattcgagagcaggggatgtcctaacatcacgtcccaaggacttgcagccattgctgttcggtgcaagcgactcgccaaggttgacttgaagaagtgcccatccatcaatgatgcggggttgctcgctctggctcacttctctcagaatctcaaacaggtaataaaccgttgaatccttcactgacagctgaaaaaactacaatatactggttgaatctgttatctgattgcgatccccatgttgcagataaacgtgtcagacacagctgtgactgaagtgggacttctctccctagccaacatagggtgtttacagaacatagcggttgtgaactcgagtggtttaagaccgagcggagtagcagcagcattgctggggtgtggaggattaaggaaagcgaaactacatgcgtccctaagatcactgcttcctctttctctaatccaccacttggaagctcgtggttgtgcgttcctctggaaagacaatacccttcaggtgaatatatatacaagtatatgtagattactacttactacactaaatagccgcaaaaggttggtgtagctttttatgattacaaatgaaaatcttagagcgaaggagtctgacatatggaaatgtaaatgatgtgggaacaggcggagttagatcccaagtactggaagcaacagctggaagagatggcgccttaaattaaaagtgagaagaaacattctgaaatgggaaagaggagttcctatgggagccagcagacaggccctgttttgggcccagtgtggattagctggaacaattttggtctcttttgtgttgttgttgacggcgcgtgttctaacaaccccacacaaccttacattataagtctagtcacatggtgggtgacatggtaccgttgtatatgtagtttttgtttcttttttttttttttttggttggggagccgaaattaacggacgtaacagagtc
acaaggggatgccttctctgtgcctttttgactttttcctcctttcttttttttctgtaatcatatgagttttatgtaatttaatgcctcatcaacttgcctggatagggccggcctttcc(seq id no.:36)
228.gggttttttccaaaatcctcaaagagagactatacttctctcggatccttcctgatttcaaaatttcttcaacccaccagcagcagcagcagatgaagaaggttaaacagattcgtgtcttaaagcctttcgatcttctctcggaagagctcgtctttatcatccttgacctcatctctcccaacccttccgatctcaaatccttctctcttacttgcaaatctttctaccagctcgagtccaagcaccgcggatccttaaaacctctccgctccgactatctccctcgcatcttgactcgttaccggaacaccaccgatctcgatcttaccttctgcccgcgtgtcactgactacgcgcttagcgtcgttggctgtctctccggacctacgcttcgctccctcgacctctcgcgctctggctccttctccgccgcgggactactgcgattggccctcaaatgtgtcaatttagtcgagattgacctgtccaatgcgacggagatgagagacgccgatgctgcggtggtggcggaggcgaggagtctggagaggctgaagctgggcagatgcaagatgctgacggacatgggaatcggatgtatagcagttggatgtaagaagctcaatacggttagcttgaaatggtgtgttggcgtcggagatttaggggttggcttgcttgccgtcaaatgcaaggacattcgcaccttagacctctcctacttgccgatcacaggaaagtgtttacatgacattctgaaacttcaacaccttgaagaacttcttctagaagggtgctttggagtagatgatgacagtcttaaatcactcagacatgattgcaagtcattgaagaagcttgatgcatccagctgccagaatttaactcatagaggtttaacctcacttttaagcggggcaggatatcttcagcgacttgatctatcacactgttcttctgtgatatcattggattttgcgagtagcttaaagaaggtttcagcattacagtcgatcaggttggatggttgttctgttacgcctgatggtttgaaggcgataggcacattgtgcaattccctgaaagaggttagcctaagcaaatgcgtgagcgtaactgatgaaggtctttcttctctagtaatgaaactgaaagacctcagaaaacttgacatcacatgttgccggaaactaagtagagtttcaatcacccaaatcgccaattcgtgtcctttactagtctctttgaagatggagtcttgttctcttgtttccagagaagccttttggttgatcggacaaaagtgtcggctacttgaagagcttgacttaactgacaacgagattgatgatgaaggactgaaatccatatctagttgtctgagtctttcctcgttaaagctgggaatttgtcttaacataacagacaaagggctctcgtacatcgggatgggctgttcaaatctccgtgaacttgatctctataggtcagtgggaataacagacgtaggcatctccacaattgcccaaggctgcattcatctggaaacaataaacatttcatactgccaagacataacagacaagtccctggtttcattgtccaaatgctcgttgttacaaacattcgagagcaggggatgtcctaacatcacgtcccaaggacttgcagccattgctgttcggtgcaagcgactcgccaaggttgacttgaagaagtgcccatccatcaatgatgcggggttgctcgctctggctcacttctctcagaatctcaaacagataaacgtgtcagacacagctgtgactgaagtgggacttctctccctagccaacatagggtgtttacagaacatagcggttgtgaactcgagtggtttaagaccgagcggagtagcagcagcattgctggggtgtggaggattaaggaaagcgaaactacatgcgtccctaagatcactgcttcctctttctctaatccaccacttggaagctcgtggttgtgcgttcctctggaaagacaatacccttcaggcggagttagatcccaagtactggaagcaacagctggaagagatggcgccttaaattaaaagtgagaagaaacattctgaaatgggaaagaggagttcctatgggagccagcagacaggccctgttttgggcccagtgtggattagctggaacaattttggtctcttttgtgttgttgttgacggcgcgtgttctaacaaccccacacaaccttacattataagtctagtcacatggtgggtgacatggtaccgttgtatatgtagtttttgtttcttttttttttttttttggttggggagccgaaattaacggacgtaacagagtcacaaggggatgccttctctgtgcctttttgactttttcctcctttcttttttttctgtaatcatatgagttttatgtaatttaatgcctcatcaacttgcctggatagggccggcctttcc(seq id no.:43)
229.在本发明中,所述rae1基因来源于水稻(osrae1.1,loc_os11g01780),核酸序列如seq id no.:44所示。
230.attattactaccttcccttcccttcttcttgttgcagtcaacctcgccatggcctcgcctatgccaacgcctacccaccgcgtcaagcgccgccgcctcgacctctccccgcccccgcacctcaacgacctcgccgacgagctc
ctcttcctcatcctcgaccgtgccgccgcccatgacccccgcgccctcaagtccttctccctcgtctcccgcgcctgccacgccgccgagtcgcgccaccgccgcgtactccgccccttccgccccgacctcctccccgccgcgctcgcccgctaccccgccctctcccgcctcgatctctccctctgcccgcgcctccccgacgccgccctcgccgcgctccccgccgcgccgtccgtctccgccgtcgacctctcccgctcccgggggttcggcgccgccggcctcgccgcgctcgtcgccgcgtgccccaatctcacggacctcgacctctccaatggcctcgacctcggggatgccgcggcggcggaggtggccaaggcgcgccgcctgcagaggctctcgctgtcgcgatgcaagcgcatcactgacatggggctcggatgcatcgccgtcggatgccccgacctgcgcgagctctcgctcaagtggtgcatcggggtcactcatctcggactagacctcctcgccctcaagtgcaacaagctcaacatcctggatctctcctacaccatgattgtaaaaaaatgctttccagccatcatgaagctacaaagtctacaagtgttactactggtgggatgtaatggaattgatgatgatgcccttactagtcttgatcaagaatgcagcaaatcactacaggttcttgatatgtcaaattattacaatgtcactcatgtcggtgttctgtccattgtgaaggcaatgccgaatctgttggaactcaatctatcatactgctctcctgttactccttctatgtcaagcagcttcgaaatgattcataaattgcagacactgaagctggatggttgccaattcatggatgatggattaaaatccattgggaaatcctgtgtttctttgagggagttaagtctgagcaaatgttctggagtgacagacacagatctttcttttgtcgtgccaagactgaaaaatttgctgaagctggatgttacttgttgtcgcaaaatcactgatgtttcattagctgccatcacaacctcatgcccctccctcatctctctgagaatggagtcctgtagccttgtttccagcaaaggactacagctgattggaaggcgctgcactcacttggaggaattggatcttactgacactgatttggatgatgaaggtttgaaagctctctctggatgcagcaaactttcaagcctaaaaattggcatatgcttgaggataactgatgagggccttagacacgttagcaagtcctgtccagatctccgagatatcgatttgtacaggtctggggcgatcagtgatgaaggggttactcatatagctcaaggatgcccaatgttagagtctatcaatttgtcctactgcacaaaattaacagactgttcactgagatcactttcaaaatgcataaagctgaacacattggagattcgtggctgccccatggtttcatctgctggtctctcggaaattgccacaggatgcaggctactttctaagcttgatatcaagaaatgctttgagatcaatgacatgggaatgattttcctttcccaattctctcacaacctccggcagataaacttgtcatattgttcggtcaccgacattgggcttatatccctttcaagcatatgtggcttgcagaacatgaccattgtgcatttagcgggtgttacgcctaatggactgatagctgctcttatggtctgtggtttgagaaaagtgaagcttcatgaagcattcaaatccatggtgccatcacatatgctcaaagttgttgaagcccgtggttgtcttttccagtggattaataaaccctaccaggttgcggtagaaccgtgtgatgtatggaagcagcagtcgcaggatttgcttgtacagtgaaatgtttcaaagataaacgttgtggaaactggggcgtgttttgtggtgttgaatttatctagagcaatatctccagtcctagagaatgagctccaaaagttttgtgccataactggctgaatagtgtattgaattgctgacggtagtattgtcagaacaacatactagtactggtattttgcttgtatgccagtggaggcgagggaggttatattcttgctgtgttgtatatagcgcaggtaggaatcaacaatcaaagagagatcattggggtaaagcatgttgtaagtagtgcggagtatgtgatatgccttgctgtgcctttttgatgcacaatttgattaatggaatggaacattgcattctcact(seq id no.:44)
231.在本发明中,所述rae1基因来源于水稻(osrae1.2,loc_os12g01760),核酸序列如seq id no.:45所示。
232.gccaaacgcccaccattattactaccttcccttcccttctctcgtttcagtcaacttcgccatggcctcgcctgcgcccacccaccacgccaagcgccgccgcctcgccctgcccccgcccccgcccccgcacctcaacgacctcgccgacgagctcctcttcctcatcctcgaccgtgccgccgcccatgacccacgcgccctcaagtccttctccctcgtctcccgcgcctgccacgccgccgagtcgcgccaccgccgcgtcctccgccccttccgccccgacctcctccccgccgcgctcgcccgctaccccgccatctcccacctcgatctctccctctgcccccgcctccccgacgccgccctcgccgcgctccccgccgcgccgttcgtctccgccgtcgacctctcccgctcccgcgggttcggcgccgccggcctcgcc
gcgctcgtcgccgcgttccccaatctcacggacctcgacctctccaatggcctcgacctcggggatgccgcggcggcggaggtggccaaggcgcgccgcctccagaggctctcgctgtcgcgatgcaagcgcatcactgacatggggctcggatgcatcgccgtcggatgccccgacctgcgcgagctctcgctcaagtggtgcatcggggtcactcatctgggactagacctccttgccctcaagtgcaacaagctcaacatcctggatctctcctacaccatgatagtaaaaaaatgctttccagccatcatgaagctacaaaatctacaagtgttactactggtgggatgtaatggaattgatgatgatgcccttactagtcttgatcaagaatgcagcaaatcactacaggttcttgatatgtcaaactcttacaatgtcactcatgtcggtgttctgtccattgtgaaggcaatgccgaatctgttggaactcaatctatcatactgctctcctgttactccttctatgtcaagcagcttcgaaatgattcataaattgcagaaactgaagctggatggttgccaattcatggatgatggattaaaatccattgggaaatcctgtgtttctttgagggagttaagtctgagcaaatgttctggagtgacagacacagacctttcttttgtcgtgccaagactgaaaaatttgctgaagctggatgttacttgttgtcgcaaaatcactgatgtttcattagctgccatcacaacctcatgcccatccctcatctctctgagaatggagtcctgtagccttgtttccagcaaaggactacagctgattggaaggcgctgcactcacttggaggaattggatcttactgacactgatttggatgatgaaggtttgaaagctctctctggatgcagcaaactttcaagcctaaaaattggcatatgcttgaggataactgatgagggccttagacacgttagcaagtcctgtccagatctccgagatatcgatttgtacaggtctggggcgatcagtgatgaaggggttactcatatagctcaaggatgcccaatgttagagtctatcaatatgtcctactgcacaaaattaacagactgttcactgagatcactttcaaaatgcataaagctgaacacattggagattcgtggctgccccatggtttcatctgctggtctctcggaaattgcaacaggatgcaggctactttctaagcttgatatcaagaaatgctttgagatcaatgacatgggaatgattttcctttcccaattctctcacaacctccggcagataaacttgtcatattgttcggtcaccgacattgggcttatatccctttcaagcatatgtggcttgcagaacatgaccattgtgcatttagcgggtgttacgcctaatggactgatagctgctcttatggtctgtggtttgagaaaagtgaagcttcatgaagcattcaaatccatggtgccatcacatatgctcaaagttgttgaagcccgtggttgtcttttccagtggattaataaaccctaccaggttgcggtagaaccgtgtgacgtatggaagcagcagtcgcaggatttgcttgtacagtgaaatgtttcaaagataaacgttgtggaaactggggcgtgttttgtggtgttgaatttatcttagagcaatatctccagtcctagagaatgagctccaaaagttttgtgccataactggctgaatagtgtattgaattactgacggtagtattgtcagaacaacatactagtactggtattttgcttgtatgccagtggaggcgagggaggttatattcttgatgtgttgtatatagcgcaggtaggaatcaacaatcaaagagagattattggggtaaagcatgtagtaagtgtggagtatgtgatatgccttgttgtgcctttttgatgcacaatttgattaatggaatggaacattgcattcgcact(seq id no.:45)
233.在本发明中,所述rae1基因来源于玉米(xm_008677340.2预测:zea mays f-box/lrr-repeat protein 3(loc103651656)),核酸序列如seq id no.:46所示。
234.ctccatctccatcgccggcctccatttcttgcctcccgtgccagccagtcactctcgtccgccgcagatcgagaagccaccaccaccaccaccaccaccgcatggccatggcagcccagcagcaccggcaccacaagcgccgccgcatcgccctctccccctccccgtccccgtccctcgcgcccatccccggcgcccccacgccgccgctcgactcgctggccgacgagctcctcttcctggtcctggaccgcgtggcccaggccgacccgcgggcgctcaagtccttcgcgctggcctcccgcgcctgccacgccgcggagtcacggcaccgccggacgctccgcccgctccgcgcggacctcctgcccgccgcgctggcgcggtacccgtccgcgacccgcctcgacctcaccctctgcgcgcgcgtccccgacgccgccctcgcctccgccgccgtctccggctcctccgccctccgcgccgtcgacctctcccgctcccgcgggttcggcgccgcgggcgtcgccgcgctcgccgccgcgtgcccggacctcgccgacctcgacctctccaatggggtccacctcggggacgccgcggcggccgaggtagcgcgggccagggcgctgcggaggctctcgctggtccgctggaagccgctcaccgacatgggcctcggatgcgtcgccgtcgggtgcacggagctgaaggacctctcgctcaagtggtgccttggactcacggatctg
gggatccagctcctcgccctcaagtgcaggaagctcaccagcctggatctctcctacaccatgatcacaaaggatagcttgccttctatcatgaagctacccaatcttcaagagctgacactggtggggtgtattggaatcgatgatggtgctcttgttagtcttgagagagaatgcagtaaatcactacaggtgcttgatatgtctcagtgtcagaatatcaccgatgtaggagtttcatccatcctgaagtcggtacccaatctattggaactggatctttcatactgctgtcctgttactccttctatggtgagaaacttccagaagcttcctaaactgcaggccctgaagctggaaggctgcaaattcatggccaatggactaaaagccattgggacctcttgtgtttctttaagggagctaagtcttagcaagtcatctggagtgacagatacagaactctcttttgttgtgtcaaggctaaagaacctgctgaagctggacattacctgttgtcgcagtattactgatgtttcactagcggccataactagttcgtgcacttccctcatctctctgaggatggagtcttgtagccatgtttccagtggagcactccaactgattgggaagcactgttctcacttggaagagttggaccttactgacagtgatttggatgatgaaggattgaaagctcttgccagatgtagcgaactttcgagcctaaaaattggcatttgcttgaagataagtgatgaaggtcttagccacattggaaggtcttgcccaaaactccgcgagattgatttgtacaggtgtggagttattagcgatgatggaattattcaaattgcgcagggttgtccgatgctagagtctatcaacctatcatactgcacagaaataacagaccgttcactgatttcactctcaaaatgcgcaaagctgaatactttggagatccgtggctgccccagtgtttcatcgattgggctctcagaaatagcgatggggtgcaggctgctttccaagcttgatattaagaaatgcttcgggattaatgatgttggaatgctttacctttcccagttcgctcatagcctccgtcagataaacttgtcatactgttcagtcaccgatgttgggctcctttccctttctagcatatccggcctgcagaacatgaccatcgtccatttggcgggtataacacccaatggcttgacagcaactcttatggtttgcggtgggttgacgaaagtgaagcttcatgaagcattcagatccatgatgcctcctcatacgataaaaaatgttgaggcacgtggctgtgttttccagtggatcgataaaccgttcaaggttgaggtggagccttgtgatgtatggaagcaacagtcacaagatgtgcttgtgcgatgagaatacaggagacctcgagcgtagccgctatcgtggaaatcgtggcatgcatcgtatggatggatgagttgttgttggctggcaatggcatccagaagtgaagtctgatggggggagctccaaactcagcgttgtaatcagtgcgattcggcacaaagataccagcatttgagcagaggtgtatgtatgtcttgatgttgttttatactgctatagatgtgtagatcccattgtttggtgaggtgatcatttgcgaggaagttgactattagcatgtattaagataaaaaggaaagagatgagaaaatgtttttgaaatttagtacgatatgccttgcagtgcctgtatctgttgcattcatatttgtgatcagctggaatgaagtggcttgcattcatgtttta(seq id no.:46)
235.在本发明中,所述rae1基因来源于大麦(ak372025.1hordeum vulgare subsp.预测蛋白的vulgare mrna,部分cds,clone:niashv2145b10),核酸序列如seq id no.:47所示。
236.gaggttggccgtggccagccattgctactcctccctcccttcttggtgtcgccgcagcggacaaccaactgccaacttgccttgcccgtcatggccatggcgacccacagccacctccccaagcgccgacgcgtatgccctgccgcgggcgcgccgatcgacgagctgcccgacgagctcctcttcttggtcctggaccgggtggcggccgccgatccgcgcgcgctcaagtccttcgcgctggcctcccgcgcctgccacgccgccgagtcgcgccaccgccgcgtgctccgcccgtaccgcgccgacctactccgcgccgcgcttgcccgctaccccaccgccgcccgcctcgacctcaccctctgcgcgcgcgtgcccggcgcggccctctcctccgcgcccgtgccttccctccgcgccgtcgacctctcccgctcccgcggcttcggggcgcccggcctcgccgcgctcgtcgccgcctgccccgccctggccgacctcgacctctccaatggggtcgacctcggggacgcggcggccgcggagctggcgcgggcgcggggcctgcagaggctctgcctctcgcgctgcaagcccatcacggacatgggcctcggctgcatcgccgtcggctgcccagacctgcgggacctcacgctcaactggtgcctcgggatcacggatttggggatccagctcctcgccctcaagtgcaacaaactcaggaacctgcatctttcctacaccatggttagatctccaaagactgccttccagccatcatggagctacccaatcttgaggtgttggcactggtgggatgtg
ttggaatagatgatgatgcccttagtggtcttgagaatgaaagcagcaaatcactacgggttctcgatatgtctacctgtcgaaatgtcactcatacgggagtttcatcagttgtgaaggcactgccaaatctcttggagttgaatctgtcctactgctgtaatgttactgcatctatgggaaaatgcttccaaatgcttcctaaattgcagaccttgaaattggaaggctgcaagttcatggctgatggactaaaacacattggaatttcttgtgtctctttaagagagttgagcctgagcaagtgctcaggagtgacagatactgatctgtctttcgttgtgtcaagactaaagaatttgctgaagctggacattacttgcaatcgcaatatcactgatgtttcgttagctgccatcactagctcatgccattccctcatctctctaagaatagagtcctgtagccatttttctagtgaagggctccgacttattgggaagcgatgttgccatttggaagagttggatatcaccgacagtgatttggacgatgaaggtttgaaagctttgtctggatgcagcaaactgtcaagcttaaaaattggaatatgcatgaggataagtgaccaaggccttatccacattgggaagtcttgtccagaactccgagatattgatttgtataggtctgggggtattagtgatgagggggttactcaaattgcccaaggttgtccaatgctagagtctatcaacctgtcgtactgtacagaaataacagatgtctcgttgatgtcgctctcaaaatgtgcaaagctaaacacactggagatccgtggttgccccagtatttcatctgctgggctctcagaaatagcaatcggatgcaggctacttgccaagcttgatgtcaagaagtgctttgcgatcaatgatgtggggatgttttttctttcccagttctctcatagcctccgtcagataaacttgtcatactgttcggtcaccgatattgggcttctgtccctctctagcatatgcgggcttcagaacatgacgattgtacacttggcgggtattacgcctaatggcttgctggctgctctgatggtctctggtggtttgacaagggtgaagcttcatgcagcgttcagatctatgatgcccccgcatatgctcaaagtcgttgaggctcgcggctgtgctttccagtggattgataaaccattcaaggtcgagcaagaacgatgcgacatatggcaacaacagtctcgagacgtgcttgtacgatgagaaatgtttgacgtcgtcgtcttggctgtcagcctacaggatatggtgtagaacgaggctttgcaccaaggtggacttgtgtacagaacagacattatcggaacaatgttgtatactcatgtttccttcagtgcactaggaggttcttttgttgtgccgtatcctgtatatagagcagcaggagatggatgaaatcatagaggaattgctggaggtcgacgtgtacttaatagaaactcaccgatcaatgtgagagtgtgcacagttctattacctgtccaatgcgctcttgtttcgaatgagtagtagtttagcctgtgtttctcctggtgtcc(seq id no.:47)
237.在本发明中,所述rae1基因来源于芸薹属(xm_009132381.2预测:brassica rapa f-box/lrr-repeat protein 3(loc103855400)),核酸序列如seq id no.:48所示。
238.ctgtccttttttattctctgtttcccatagaaactgtgaatctgtgggtttttagcaaatcctcatcgaaactgtttctccatttgataaaaaaaaaaatcagtaagtagttgggttcgaatgaagaaggcgaagcagattcaacacatgatctcaaagcctttcgatcttctgtcggaggagctggtcttcataatcctagacctcgtcgctcagaacccttccgatctcaaatccttctctcttacctgcaaatggttctaccaagtggaggccaggcaccggagatccctgaaacctctcagagcggagtatcttcctcgaatcctgacaaggtaccggaataccgccgatctcgatcttagcttctgcccgcgcgtcacggactacgcgcttagcgtggtcgggtgcctctccggaccgacgctgaggtcagtagacttatcgaggtcattctccttctcggcggcggggctgctgagactggccgtgaaatgtgtgagtctggtggagatagacctgtcgaacgcgacggagatgagggacgcggcagcggcggtggtggcggaggcgaagagcctggagaggctgaagctggggagatgcaagaagctgacggacatgggaataggatgcatagcggtgggatgtaggaagctgaagagggtgagcttgaagtggtgtgtaggcgtcggagatttaggagtcggtctgcttgccgtcaaatgcaaggacattcgctccttagacctctcctacttgccgatcacaggcaagtgtttgcatgatgttctcaaacttcaacaccttgaagaacttcttctacaaggttgcttcggagtcgatgatgactctcttaaatcactcactcatcattgcaactccttaaagaacctggatgcatcgagctgccagaatttaactcagagaggtttaacctcacttttaagcggggccggatgtcttgagcgccttgatctagcacactcttcttctgtgatctcattggattttgcaagtagcctgaacaaggtttcttcagcattacagtcgatcaggttggatggttgtgcggtaacttgtgatgggttgaaggcgatagggacactgtgcatttccctcagagaggtta
gcctaagcaaatgtgtcaccgtaactgatgaaggtctctcttgtcttgttatgaaactcaaagaccttagaaaacttgacatcacctgttgccggaaactaactggagtttcaatcacccaagtcgccagttcttgtcccttactagtctccttgaagatggagtcttgttctcttgtttccagagatgccttttggttgatcggacacaagtgtcgcctacttgaagagcttgactttactgacaatgagattgatgatgaaggactaaaatccatatccagttgtcgtagtctttcctcgttgaagttgggaatatgtctgaatataacagacagaggactctcgtacattggtatgggctgctcaaatctccgtgaacttgatctctacaggtcggtgggaataacagacgtaggaatctcatcgatcgctcaaggctgctgtcatctcgaaacaataaacatatcatactgcaaagacatcacagacaagtcgttggtgtcattgtcaaaatgctcaatgttacaaacattcgagagccggggatgtccacacattacttgccaaggacttgccgccattgctgttcgatgtaagcggctcagcaagctcgacttgaaaaagtgtcctttcatcaatgactccggtttgctcactctagctcacttttcacagggcctcaaacagataagcgtgtccgaaacgggggtgacagacgtgggacttgtgtcgctagcaaacatagggtgtttgcagaacatagcggcagtgaacacaaggggtttaagcccgagtggagtagcagcagcgttggttgggtgtggaggtttaaggaaagtgaaactccacgcttccctcagatcactacttccttcgtctcttataaaccacatggaagctcgtggctgctccttcctgtggaaagactataacaaccataataatagtaatacacttcaggcggagttagatcccaagtactggaaggtatagccggaagaagatattgagctttagaagaaagaaacatccacaaggggaaagagacggagccaccatacaggccaaggccccatccattgtttggatttagaaagaggaactaaagcttggtatctatctatgtcgatggcgcgtgttgcctcacacacatacacgtatatccatccttacgtatgtagtatatggttgtgacatggattggtggttagtttgtatgtacccttttgtaatttcatttcctttttttggatgccaaagttaacggacgtcacaagagattgcatttgtgtcctttttttgagtttttcttttctggatggttctatcaa(seq id no.:48)
239.在本发明中,所述rae1基因来源于大豆(xm_003521974.4预测:glycine max f-box/lrr-repeat protein 3(loc100803617)),核酸序列如seq id no.:49所示。
240.actcattcaatattaataaatgtctcgcatttattcctcaaacatagaaaccaaacaaacaaacccttcccttctctccccacagttattcatcattaacctccaaaacgaccaaccaaacgcaaaacgcagaaccatgaagaagcagaagctctccgagcctcaaaacgacaccaccaaccccttcgaggttctctccgaggagctaatgttcgtcatcctcgacttcctccaaacgacgtcgttggacaaaaaatctttctcgctcacgtgtaagttgttttactccgtcgaggccaagcaccgtcgtttgcttcgcccgctacgtgcggaacacctgcccgcgctcgctgcccgctacccgaacgtaacggaattggatctttccttgtgtccgcgcgtgggcgacggcgcgctggggctcgtcgctggcgcgtacgcggcgacgctgcggcgaatggacctgtcgcggtcgcggcggttcacggcgaccgggctgctaagcctcggcgcacggtgcgagcacctggtggagctggacttgtcgaacgcgacggagctgagggacgccggcgtcgccgcggtggcgcgtgcgcggaacttgcggaagctgtggctggcgaggtgcaagatggtgacggatatggggattgggtgtattgcggtggggtgcaggaagctgaggctgctttgcttgaagtggtgtgtgggaattggggatttgggtgtggatttggttgcgattaagtgtaaggagctcacaacattggatctctcttatttgcctatcacggagaaatgtctaccgtcaatcttcaaattgcaacatcttgaagatttggtccttgaaggatgctttggcattgatgacgacagccttgatgttgatctcttaaaacaagggtgcaagacattgaagagacttgatatctcaggttgtcaaaacataagtcatgttgggttatcaaagcttacaagcatttctggaggtttagagaaactcattttagcagatggctctcctgtcaccctttctcttgctgatggtttgaataaactttccatgttgcaatcaattgtattagatggctgccctgttacatctgaaggattacgggccattggaaatttgtgcatttcacttagggagcttagtctaagcaaatgtttgggagtgacagatgaggcactctcatttcttgtgtcaaaacacaaagatttaaggaaacttgacatcacatgctgtcgcaagataactgatgtttccattgccagcattgcaaattcatgcacaggtctaacttctctcaaaatggagtcatgtacactagttccaagtgaagcatttgtcttgattggacagaaatgccattatcttgaggagcttgacctaacagataatgaaattgatgatgaaggtcttatgtccatttctt
cttgttcttggcttaccagcttgaaaataggaatatgcctgaacataactgacagaggacttgcctatgttggcatgcgttgctcaaaattaaaggagctggatctatacaggtctactggagtagatgatttgggcatttcagcaattgctggtggttgccctggccttgagatgataaacacatcctattgtactagcattactgacagggcactaattgccttgtcaaaatgttcaaatttggagacacttgaaattcgaggatgtcttctcgttacatccataggtctggcagctattgcaatgaattgcagacaactaagtcgtctagacataaaaaagtgttacaacattgatgacagtgggatgattgctctggctcatttctcccaaaatctaagacagataaatttgtcatatagctcagttacagatgtggggcttctgtcacttgctaatatcagttgccttcaaagctttaccttgcttcacctgcaaggcttggttccaggaggactggcggcagccttattagcttgtggagggctaacaaaagtgaagctccatctttcactaagatctctgttacctgagctacttatcagacatgtggaagcacgtggctgtgtatttgaatggagagataaagagtttcaggctgaattggaccccaagtgttggaaattacagttggaagatgtgatataataggatttttctcaggttctttgaagttttgataaagacaactctgctgcatggctcatgaaattcaattcggaagtcatcatcttctctctcttctctgttcacctaacctacactacaagaaatgaagaaagcagcatgaaaaatgccagaagtattctgtttagtccattggaggctacacaggcatttggaatggagattgttgatcatccttccttaagtctcgctcgcctaactaggatgagttttgtttattcttttttcttttttttgctgcaaatagcaggattagtgaagtacttaaagtgttacaaaccccatctaacgtctttcatttatttattttgggagtacaattggaaatgttcagagaatggagaagcagtggctatcgaatgtataaaaacactaacttctgttcaatcttttcttttgacagtgaaaagcaagattaagtgtgtaaaacttagaaacctgttttgtttatatatgattagagctgttcatggacatccagaatagaagtttcaaaa(seq id no.:49)
241.野生型ral1蛋白和ral1基因
242.如本文所用,野生型ral1蛋白是指天然存在的、来源于植物(较佳地来自拟南芥、水稻、玉米、大麦、芸薹属、大豆、或类似植物)、未经过人工改造的ral1蛋白,负调控atalmt1表达。其核苷酸可以通过基因工程技术来获得,如基因组测序、聚合酶链式反应(pcr)等,其氨基酸序列可由核苷酸序列推导而得到。
243.在另一优选例中,所述ral1蛋白来源于拟南芥,氨基酸序列如seq id no.:50所示。
244.mstspsilsvlsedllvrvyecldppcrktwrliskdflrvdsltrttirilrveflptllfkypnlssldlsvcpkldddvvlrlaldgaistlgikslnlsrstavrargletlarmchalervdvshcwgfgdreaaalssatglrelkmdkclslsdvglarivvgcsnlnkislkwcmeisdlgidllckickglksldvsylkitndsirsiallvklevldmvscpliddgglqflengspslqevdvtrcdrvslsglisivrghpdiqllkashcvsevsgsflkyikglkhlktiwidgahvsdsslvslssscrslmeiglsrcvdvtdigmislarnclnlktlnlaccgfvtdvaisavaqscrnlgtlkleschlitekglqslgcysmlvqeldltdcygvndrgleyiskcsnlqrlklglctnisdkgifhigskcsklleldlyrcagfgddglaalsrgckslnrlilsycceltdtgveqirqlellshlelrglknitgvglaaiasgckklgyldvklceniddsgfwalayfsknlrqinlcncsvsdtalcmlmsnlsrvqdvdlvhlsrvtvegfefalraccnrlkklkllaplrfllsselletlhargcrirwd(seq id no.:50)
245.在另一优选例中,所述ral1蛋白来源于水稻,氨基酸序列如seq id no.:51所示。
246.mseevqryggggggggggvaalsldllgqvldrvreprdrkacrlvsrafaraeaahrralrvlrreplarllrafralerldlsacaslddaslaaalsgadlagvrrvclarasgvgwrgldalvaacprleavdlshcvgagdreaaalaaatglrelslekclgvtdmglakvvvgcprleklslkwcreisdigidllskkchelrsldisylkvgneslrsisslekleelamvccscidddglellgkgsnslqsvdvsrcdhvtsqglaslidghnflqklnaadslhemrqsflsnlaklkdtltvlrldglevsssvllaiggcnnlveiglskcngvtdegisslvtqcshlrvidltccn
lltnnaldsiaenckmvehlrlescssisekgleqiatscpnlkeidltdcgvndaalqhlakcsellvlklglcssisdkglafissscgklieldlyrcnsitddglaalangckkikmlnlcycnkitdsglghlgsleeltnlelrclvritgigissvaigcknlieidlkrcysvddaglwalaryalnlrqltisycqvtglglchllsslrclqdvkmvhlswvsiegfemalraacgrlkklkmlsglksvlspellqmlqacgcrirwvnkplvykd(seq id no.:51)
247.在另一优选例中,所述ral1蛋白来源于玉米,氨基酸序列如seq id no.:52所示。
248.msreaqkldcaagaggigvlsldllgqvlehlreprdrktcrlvsraferaeaahrralrvlrreplprllrafpalerldlsacaslddaslaaavadaggglaglrsvclarangvgwrglealvaacpklaavdlshcvtagdreaaalaaaselrdlrldkclavtdmglakvavgcpkleklslkwcreisdigidllakkcpelrslnisylkvgngslgsisslerleelamvccsgiddeglellskgsdslqsvdvsrcdhvtseglaslidgrnflqklyaadclheigqrflsklarlketltllkldglevsdsllqaigescnklveiglskcsgvtdggisslvarcsdlrtidltccnlitnnaldsiadnckmleclrlescslinekglerittccpnlkeidltdcgvddaalqhlakcselrilklglcssisdrgiafissncgklveldlyrcnsitddglaalangckrikllnlcycnkitdtglghlgsleeltnlelrclvrvtgigissvaigcknlieldlkrcysvddaglwalaryalnlrqltisycqvtglglchllsslrclqdikmvhlswvsiegfemalraacgrlkklkmlcglktvlspellqmlqacgcrirwvnkplvykd(seq id no.:52)
249.在另一优选例中,所述ral1蛋白来源于大麦,氨基酸序列如seq id no.:53所示。
250.mseeeaqrygggtggggvgalsvdllgqvldrvlerrdrkacrlvsrafaraeaahrralrvlrreplprllrafpalerldlsacaslddaslaaalagadlgtvrqvclarasgvgwrglealvaacprleavdlshcvgagdreaaalaaasglrelnlekclgvtdmglakvavgcprletlsfkwcreisdigvdllvkkcrdlrsldisylkvsneslrsistlekleelamvacsciddeglellsrgsnslqsvdvsrcnhvtsqglaslidghsflqklnaadslheigqnflsklvtlkatltvlrldgfevsssllsaigegctnlveiglskcngvtdegisslvarcsylrkidltccnlvtndsldsiadnckmleclrlescssinekgleriasccpnlkeidltdcgvndealhhlakcsellilklglsssisdkglgfisskcgklieldlyrcssitddglaalangckkikllnlcycnkitdsglshlgaleeltnlelrclvritgigissvvigckslveldlkrcysvndsglwalaryalnlrqltisycqvtglglchllsslrclqdvkmvhlswvsiegfemalraacgrlkklkilgglksvlspdllqllqacgcrirwvnkplvykdai(seq id no.:53)
251.在另一优选例中,所述ral1蛋白来源于芸薹属,氨基酸序列如seq id no.:54所示。
252.mplspsilsvlsedllvrvygfldppcrkkwrlvskefhrvdslsrtsirilrveflpallsnyphlssldlsvcpkldddvvlrlasygavsikslnlsratalrargletlarlcrglervdvshcwgfgdreaaalsvaaglrevrldkclslsdvglarivlgcsnlskislkwcmeisdlgidllckkckdlksldvsylkitndsirsiallpklevlemvncplvdddglqylengcpslqeidvtrcervslsgvvsivrghpdlqhlkashcvsevslsflhnikalkhlktlwidgarvsdsslltlssscrpltdigvskcvgvtdigitglarncinlktlnlaccgfvtdaaisavaqscrnletlkleschmitekglqslgcyskhlqeldltdcygvndrgleyiskcsnllrlklglctnisdkgmfhigskcsklleldlyrcggfgddglaaisrgckslnrliisycgeltdtgveqirqlehlshlelrglknitgaglaavacgckkldyldlkkceniddsgfwalayfarnlrqinlcycsvsdtalcmlmsnlsrvqdvdlvnlnrvtvegsefalraccnrlkklklfaplrfllssellemlhargcrirwd(seq id no.:54)
253.在另一优选例中,所述ral1蛋白来源于大豆,氨基酸序列如seq id no.:55所示。
254.mlsesvfclltedllirvleklgpdrkpwrlvckeflrvesstrkkirilriefllgllekfcnietldlsmcpriedgavsvvlsqgsaswtrglrrlvlsratglghvglemliracpmleavdvshcwgygdreaaalscaarlrelnmdkclgvtdiglakiavgcgklerlslkwcleisdlgidllckkcldlkfldvsylkvtseslrsiasl
lklevfvmvgcslvddvglrflekgcpllkaidvsrcdcvsssglisvisghggleqldagyclselsaplvkclenlkqlriiridgvrvsdfilqtigtnckslvelglskcvgvtnkgivqlvsgcgylkildltccrfisdaaistiadscpdlvclklescdmvtenclyqlglncsllkeldltdcsgvddialrylsrcselvrlklglctnisdiglahiacncpkmteldlyrcvrigddglaaltsgckgltnlnlsycnritdrgleyishlgelsdlelrglsnitsigikavaisckrladldlkhcekiddsgfwalafysqnlrqinmsycivsdmvlcmlmgnlkrlqdaklvclskvsvkglevalraccgrikkvklqrslrfslssemletmhargckirwd(seq id no.:55)
255.如本文所用,术语“本发明ral1基因”、“ral1基因”可以互换使用。
256.在本发明中,ral1的基因包括基因组基因、cdna序列、mrna序列。
257.在本发明中,所述ral1基因来源于拟南芥(at5g27920),核酸序列如seq id no.:56所示。
258.ctttctttattttatttaccttttaccaaagttacacttctacccctatttttcttcaataagagatggaagagcaagggcaattaagtaatttgacaatatccttctccttcaagactctctctctcccacagaaaacaaactgtttgttgttaataactgtgggttttttccaaaatcctcaaagagagactatacttctctcggatccttcctgatttcaaaatttcttcaacccaccagcagcagcagcagatgaagaaggttaaacagattcgtgtcttaaagcctttcgatcttctctcggaagagctcgtctttatcatccttgacctcatctctcccaacccttccgatctcaaatccttctctcttacttgcaaatctttctaccagctcgagtccaagcaccgcggatccttaaaacctctccgctccgactatctccctcgcatcttgactcgttaccggaacaccaccgatctcgatcttaccttctgcccgcgtgtcactgactacgcgcttagcgtcgttggctgtctctccggacctacgcttcgctccctcgacctctcgcgctctggctccttctccgccgcgggactactgcgattggccctcaaatgtgtcaatttagtcgagattgacctgtccaatgcgacggagatgagagacgccgatgctgcggtggtggcggaggcgaggagtctggagaggctgaagctgggcagatgcaagatgctgacggacatgggaatcggatgtatagcagttggatgtaagaagctcaatacggttagcttgaaatggtgtgttggcgtcggagatttaggggttggcttgcttgccgtcaaatgcaaggacattcgcaccttagacctctcctacttgccgatcacaggaaagtgtttacatgacattctgaaacttcaacaccttgaagaacttcttctagaagggtgctttggagtagatgatgacagtcttaaatcactcagacatgattgcaagtcattgaagaagcttgatgcatccagctgccagaatttaactcatagaggtttaacctcacttttaagcggggcaggatatcttcagcgacttgatctatcacactgttcttctgtgatatcattggattttgcgagtagcttaaagaaggtttcagcattacagtcgatcaggttggatggttgttctgttacgcctgatggtttgaaggcgataggcacattgtgcaattccctgaaagaggttagcctaagcaaatgcgtgagcgtaactgatgaaggtctttcttctctagtaatgaaactgaaagacctcagaaaacttgacatcacatgttgccggaaactaagtagagtttcaatcacccaaatcgccaattcgtgtcctttactagtctctttgaagatggagtcttgttctcttgtttccagagaagccttttggttgatcggacaaaagtgtcggctacttgaagagcttgacttaactgacaacgagattgatgatgaaggactgaaatccatatctagttgtctgagtctttcctcgttaaagctgggaatttgtcttaacataacagacaaagggctctcgtacatcgggatgggctgttcaaatctccgtgaacttgatctctataggtcagtgggaataacagacgtaggcatctccacaattgcccaaggctgcattcatctggaaacaataaacatttcatactgccaagacataacagacaagtccctggtttcattgtccaaatgctcgttgttacaaacattcgagagcaggggatgtcctaacatcacgtcccaaggacttgcagccattgctgttcggtgcaagcgactcgccaaggttgacttgaagaagtgcccatccatcaatgatgcggggttgctcgctctggctcacttctctcagaatctcaaacagataaacgtgtcagacacagctgtgactgaagtgggacttctctccctagccaacatagggtgtttacagaacatagcggttgtgaactcgagtggtttaagaccgagcggagtagcagcagcattgctggggtgtggaggattaaggaaagcgaaactacatgcgtccctaagatcactgcttcctctttctctaatccaccacttggaagctcgtggttgtgcgttcctctggaaagacaataccctt
caggcggagttagatcccaagtactggaagcaacagctggaagagatggcgccttaaattaaaagtgagaagaaacattctgaaatgggaaagaggagttcctatgggagccagcagacaggccctgttttgggcccagtgtggattagctggaacaattttggtctcttttgtgttgttgttgacggcgcgtgttctaacaaccccacacaaccttacattataagtctagtcacatggtgggtgacatggtaccgttgtatatgtagtttttgtttcttttttttttttttttggttggggagccgaaattaacggacgtaacagagtcacaaggggatgccttctctgtgcctttttgactttttcctcctttcttttttttctgtaatcatatgagttttatgtaatttaatgcctcatcaacttgcctggatagggccggcctttccacgtcaccttagtcgcgttttgcggtaaaaaaagtaaaaagaaaggccgtgactcagtagggcccattactggtccagtccaggctctcaccgtctgtacaaaaatagcgagtcagcgactcggtgtgacagcaacaaccctctctcgttgaaaaacggctaatgcgcccgacacttccatcctcatattccattacaaaagaaatccagctatgtagtatcaaactaccgaaaacatacacatgtcaatcaagtccaaaaagtatcaccgtcaaatgagtgattcagattttgtttgctcatgaaagataaaccaaatgattacttccttaatcacctgccccttgttttccattttttaattacataatggaaccccccattattaaaacatgatcattttctttcgtaataattaaacttcccaactaaatgcctcttaata(seq id no.:56)
259.在本发明中,所述ral1基因来源于水稻(loc_os12g36670),核酸序列如seq id no.:57所示。
260.atgagcgaggaggtgcagaggtatggaggtggtgggggtgggggaggaggtggggtggcggcgctgtcgctggatttgctcggccaggtgctcgaccgggtgcgggagccgcgggaccgcaaggcgtgcaggctcgtgagccgcgccttcgcccgcgccgaggccgcgcaccgccgcgcgctgcgggtgctccgccgcgagcccctggcgcgcctcctccgcgcgttccgggcgctggagcggctcgacctctccgcctgcgcctccctcgacgacgcctccctcgccgccgcgctctccggcgcggatctcgccggggtgcgccgggtctgcctcgcccgcgccagcggcgtcgggtggcgcggcctcgacgcgctcgtggcggcgtgcccgaggctggaggccgtcgacctgtcgcactgcgtcggcgccggcgaccgcgaggccgccgcgctggccgcggcgacggggctgagggaattgagcctcgagaagtgcctcggcgtcacggacatggggctcgccaaggtggtggtcgggtgcccgaggctggagaagctgagcctcaagtggtgccgcgagatctccgacatcggcatcgatttgctctccaagaagtgccacgagctccggagcctcgacatctcctacctcaaggttggaaatgaatcccttagatcaatatcctcacttgagaaacttgaggagttggcaatggtttgttgctcatgcatagatgatgatggcctggaattactaggcaaggggagcaactcactgcagagcgttgatgtttcaagatgtgatcatgtaacctcccagggattagcttcactcatagatggtcacaattttctccagaagttaaatgctgctgatagtttgcatgagatgagacagtcgtttctgtccaacttggcaaaactgaaggataccttgacagtgcttagacttgatggtcttgaagtctcatcctctgttcttctggccattggtggttgtaataacttggtcgagattggccttagcaaatgcaatggcgttacagatgaaggaatctcttcacttgtaactcaatgcagccacttaagggttattgatctcacatgctgtaacctccttaccaacaatgcccttgattcaatagctgagaactgtaagatggttgaacatctccgtttggaatcctgttcttccataagcgaaaagggactggagcagattgcaacctcctgccccaatctaaaggagatagacctcactgactgtggagtgaatgatgcagcattgcagcacttggccaagtgctctgaactgcttgtactgaaattaggcctgtgctcaagtatttctgacaaaggtcttgcttttatcagttcaagctgtggaaagctgattgagcttgatctctatcgctgcaattctattaccgatgatgggctggcagctttagctaatggctgcaagaagattaagatgctaaacctatgctactgcaacaagattaccgacagtggtttgggccacctaggctctctagaggagctcacaaaccttgaactgaggtgcttggtccgtataacaggtattggaatctcatcagttgccatcggctgcaagaacctgatagagatagacttgaagcgttgctattctgtcgatgatgctggcttgtgggctcttgcccgatatgcactaaaccttagacagcttactatatcatactgccaagtcactggcctgggcctgtgtcacctgttaagctccctgaggtgcctccaggatgttaagatggtacacctctcatgggtctctatagaagggttcgagatggcactgagagcggcttgcgggaggctgaagaaactgaagatgctgagtgggctgaagtc
tgtgctgtctcctgagctgctccagatgctgcaggcctgcggctgccgcatccgttgggtcaacaagcctcttgtctacaaggactaaacctgctctcatatcatcatctgtgcagtgttaatatcctcggatcatacaccatggagcccttaccaagtctagcatgcttacaagccatgttagatacccgcaataatcgtcaattttcatacccaagatgtactgacgatggtgtctctgcattgctgcagtgccatccttatgtttggcaactcctagaccaatgttgtcatcttcagattaaaatccaacatttgcaaacatgaggcatcgaaacagttatgttctgagcaagtgatccttgtaccagactgcaatgaaatgctctacactttcaattggtatatgcaaagaacaatggcatgtttgcctttgtcattgctccaactccaggcttgctgaccgatgcatcttttagagtttaagaacagctttagatcgcagaaaaactcttccttgatgctccaggatctgggctgggacactggtttcatggttgtctgtattgtatgactggtggacccgtccttttttttttaccttgattacaataatctcgatgtactcattcaggcagagatttgaagtaatgtattgaatcagtttttat(seq id no.:57)
261.在本发明中,所述ral1基因来源于玉米(xm_008664387.2预测:zea mays f-box/lrr-repeat protein 3(loc103640946)),核酸序列如seq id no.:58所示。
262.cggcatcacctatccacatctttctccctctctctctctctcctcttccgtccctcctctctccctctctacgccacgcctccacctccacacctgcacgcctctcgctctctctcctcacctgtcgagctgcccacagcccgtacgtacctgcccccagtcccagtccccgccgccccgcctgcccgacccgcggcttatccaccacgtccgccgctgggctggatcgatcgggaccggtatcgcgccgccgccgctgccctcggcactcgcgggatcctgttcctaccatgcagcagcgctgcgcccttgcccgaccgcgccggcccgccgaaccgcgcgttccgctccccgacgatcactccctcgtcgccgtcttctccttcctcttcatccccacctaaatcaacctcctcgccgcgaaattctgctacaatttcttcatcttcccttcccgccgggagcggacggatcgccgcttcctcggccggcgggatgagccgggaggcgcagaaactcgactgcgccgccggcgccggggggatcggggtcctgtcgctggacctactgggccaggtgctggaacacctgcgggagccccgggaccgcaagacgtgccgcctcgtcagccgcgccttcgagcgcgccgaggccgcgcaccgccgcgcgcttcgggtgctccgacgcgagccgctcccgcgcctgctccgcgcgttcccggcgctcgagcggctcgacctctccgcctgcgcctcgctcgacgacgcctccctcgccgcggccgtcgccgacgccggcggagggctcgccggcctccgcagcgtgtgcctcgcgcgggccaatggtgtcggctggcgcggcctcgaggcgctcgtcgcggcctgccccaagctcgcggccgtcgacctgtcgcactgcgtcaccgccggggaccgcgaggccgccgcgttggcggcggcgtccgagctcagggacctgaggctggacaaatgccttgccgtcaccgacatggggctcgccaaggtggctgttgggtgccccaagctggagaagctcagcctcaagtggtgccgtgagatctctgacattggaattgatctgctggccaagaagtgccctgagctccgcagcctcaacatatcctacctcaaggtgggcaatggatcccttggatcaatttcgtcacttgagaggcttgaggaattggcaatggtttgttgttcaggtatagatgacgaaggcttggaattgctgagcaaggggagcgattcgctgcagagtgttgatgtgtcaagatgtgatcatgtgacttccgaggggttagcttcactcatagatggtcgcaattttcttcagaagttatatgctgcagattgtttgcatgagataggacagcgttttctatccaagttggcaagactgaaggaaaccttgacattgctgaaactcgacggtcttgaggtctcggactctcttcttcaagccattggtgaaagctgtaacaaattggttgagattgggcttagcaaatgcagtggtgttactgatggaggaatctcatctcttgtagctcggtgtagtgacctaagaacaattgatctcacatgctgcaatctcattaccaacaatgcgcttgattcaatagctgacaactgtaagatgcttgaatgtttgcggttggaatcatgctctttgataaatgagaagggactagagcgaattacaacttgttgccccaaccttaaggagatagacctcactgactgcggagtagatgatgcagcattgcagcacttggctaaatgctctgaattgcgaatattgaaattaggcctatgctcaagtatttctgacagaggcattgcatttatcagttcgaattgtggaaagctcgtggagcttgatctctaccggtgcaactctattactgatgatgggttggcagctttagcaaatgggtgcaagaggattaagttactgaacttgtgttactgcaacaagatcactgatactggtttgggtcacctaggctccctggaggagc
tcacaaaccttgaactgaggtgcttggtccgcgtaacaggcattgggatctcctcagttgcaatcggatgcaagaacctgatagagctggacttgaaacgatgctattcggttgatgacgctggcctgtgggcccttgctcgttatgctttgaaccttagacagcttacgatatcgtactgccaagtcacggggttgggcctgtgccacctgctgagctccctgcgatgcctccaggacattaagatggtgcacctctcatgggtctcaatagaagggtttgagatggctctgcgagcagcctgcgggaggctgaagaagctgaagatgctctgcgggctgaagaccgtgctctcccctgagctcctccagatgctgcaggcttgtggctgccgaataagatgggtcaacaagcctcttgtctacaaggactagacagactcgtgttcctcattgtgtgtgcagtgtcagcatcagcatgtattgtcaagatcttgcaggtttgccctggctcacgttgtgagtccgcaataatcgttgggggcgtaagctcccgtcccccagatgtggttatggtgcctttggggcacttcttgcgccatttgtcactctctgctccggtgtatctgtgtatgcaaacggaggcaccggtaatgttcatgtgtatatagcgtgcagtagaatgatcccattttatgggattagttagtgtgtaattgttacctcatttcgcatgattcgaatcttgagatgaaagaatcataaggggtatgatcgatgcattgcattcaccggttctta(seq id no.:58)
263.在本发明中,所述ral1基因来源于大麦(ak358574.1hordeum vulgare subsp.预测蛋白的vulgare mrna,全部cds,clone:niashv1079c11),核酸序列如seq id no.:59所示。
264.ggggtgctacctatccacatctttctcctcccatcctccctccctctccccactccccacccatcgacccaccttcctccctccgtaccttcgccaccaccggccgtcgccttgccgctcctccgccgcccggatcaggaacgatcgcaccgtgcggccgcctcccgccctgcgcgcggatcctaccatgctgaggcgctgcgccccataccgaccccgcagggccgccgccgtaccgcgcctcccgatccccggcggccacccctacctcgtcgccctctccttcctcttcatcccgacctaagctccacgcctcgccgacaggccggccctcgccgccggagctgcccggtggaatcgtcagccgcgatgagcgaggaggaggcgcagaggtacggcggcgggaccggcggcggcggcgtcggtgcgctgtccgtggatctgctcggccaggtgctcgatcgcgtgctggagcggcgggaccgcaaggcctgccgcctcgtcagccgcgccttcgcgcgcgctgaggccgcgcaccgccgggccctccgggtgctccgccgggagccgctccctcgcctgctccgcgccttcccggcgctcgagcgcctcgatctctcagcctgtgcctcgctcgacgacgcgtctcttgcagccgctttagccggcgcggacctcggcaccgtccgacaggtctgcctggcgcgggccagcggagtgggctggcgcgggctggaagccctcgtggccgcctgccccaggctcgaggctgtcgacctgtcgcactgcgtcggtgctggggatagggaggctgccgccctggccgccgcctctgggctgagggagctaaatctggaaaagtgccttggggtcactgatatggggctcgccaaggtagccgtgggctgccccagactggagactctgagcttcaagtggtgccgtgaaatctctgacatcggcgtcgatctgcttgtcaaaaagtgccgcgacctccgcagccttgacatctcctacctaaaggtgagcaatgagtcccttagatcaatatcgactcttgagaagctagaggagttggccatggttgcttgctcatgtatagatgatgaaggcctggaattgcttagcagaggaagcaattcattgcagagtgttgatgtctcaagatgcaatcacgtgacttcccaggggttagcttcactgatagatggtcacagttttctccagaagttaaatgccgcagatagtttgcatgagattggacagaattttctatccaagttggtaacactgaaggcaaccttgaccgtgttgagacttgacggctttgaagtgtcatcctctcttctttcagcgattggtgaaggttgtaccaacttggttgagattggactaagcaaatgcaacggtgttacagatgaaggcatctcttcgcttgtagctcgctgtagctacctaaggaaaattgatctcacatgctgcaatctagtcacaaacgattcccttgattcaatagctgacaactgtaagatgcttgaatgcctccggttggagtcctgctcttctataaacgagaaaggactagagagaattgcaagctgttgccccaatctaaaggagatagatctcactgattgtggagtgaacgacgaagcgttgcatcatttggcgaagtgctctgaactgctgatattgaaattaggcctgagctcaagtatttcggacaaaggccttggttttattagttcaaagtgtgggaagctcattgaacttgacctctatcgctgcagttctatcactgatgatgggctggcagccttagccaacggctgcaagaaaattaagctgctgaacctttgttactgcaacaagataactgatagtggtttgag
ccacctgggcgctcttgaggagctcacaaaccttgagctgaggtgcctcgttcgcattacaggcatcggaatttcttccgttgtcattggctgtaagagcctggtagaacttgacttgaagcgctgctattctgtcaatgattctgggctatgggctcttgcccgatatgctctaaaccttagacagctcaccatatcatactgccaagttactggcctaggcttgtgccacctgcttagctccttgaggtgcctccaggacgtgaagatggtgcacctgtcatgggtttccatagaagggttcgagatggctctgcgagccgcttgcgggaggctgaagaagctgaagatactcggcggtttgaagtccgtgctatcccctgacctgctccagcttctgcaagcctgcggctgccgcatcagatgggtcaacaagcctcttgtctacaaggatgccatctgatctgagaagtaccatattgttcatcctttcggcaagtttgtcatcgctgcgtagccctgttagaaaattcacaataactacacgcctcgtcaatgccatgcctaaggtgtggtcaagatcatgtctgtttgagatgtcgagtaaacatggcagctgctgtcgaatatatgtcatgtacagtgaagcctttttttttggacgggatgtacagtgaagcccttttgcatagcagagttgtgcaactggagttctctacttgatgtgaaggaacctgaaaaatatgctgt(seq id no.:59)
265.在本发明中,所述ral1基因来源于芸薹属(xm_009113489.2预测:brassica rapa f-box/lrr-repeat protein 3-l ike(loc103837159)),核酸序列如seq id no.:60所示。
266.gggaaacaattgaagtaaagagagagaggttcggttttgtgtttccaaccggaaaaaaaaccccgaaggtttgacgatgaacccgaatctaataacccgtaacccaattcggatcctggatcaaccggttcaccactctctcctctatctccgagctgtctttctcttcatcccgacttaaaagatccgtacttttttttttttgaaactttccgaccaaactaaaagtaaacacatacttgtctttttttttcttgttctgtcgcgaaatgccgctgtctccatccattctatccgttctgtcggaagatcttctagttcgtgtctacgggttcctagacccgccctgtcggaaaaaatggcgactcgtcagcaaagagtttcaccgagtcgactcactgagccgcacatcgatccgaatcctccgagtcgagttcctccccgcgcttctctccaactaccctcacctctcctccctcgacctctccgtctgccccaaactcgacgacgacgtcgttctgcgcctagcgtcctacggcgccgtttcgataaagtcgctgaacctgagccgcgccaccgcgctccgagcgaggggactggagacgctggctcgcttgtgccgaggcctcgagcgagtcgacgtgtctcactgctgggggttcggagacagggaagcggcggcgctctccgtcgcggcggggctgagggaggtgaggttggacaagtgcttgagcctaagcgacgtcggattggcgaggatcgtcctcgggtgtagtaatctgagcaagattagtttgaagtggtgtatggagatctctgatctagggatcgatcttctctgtaagaaatgcaaagacttgaagtctctcgacgtctcttatcttaagatcacgaatgattcgatccggtccatagctttgttgccaaagctcgaggttttagagatggtgaactgtccgttggtagatgatgatgggttacagtatcttgagaatggttgtccttcgttacaggagattgatgtcacaaggtgtgagcgtgtgagtttgtctggcgttgtctccattgtcagaggccatcctgatcttcaacacctgaaagccagtcactgtgtatcagaagtatctctgagcttcttacataacatcaaagctttgaagcatctcaagactctatggatcgatggagctcgtgtctctgactcctctctcttaaccctaagctccagctgtagacccttaacagatatcggagtgagcaaatgtgtgggtgtgacggatattggcatcacaggactagcacgcaactgcataaacctgaaaaccctaaacctagcgtgctgcgggtttgtgactgatgcagccatctctgcggtagctcagtcttgccgcaatctggagactcttaagttagagtcttgtcatatgataaccgagaaaggtcttcaatcactcggatgttactccaagcatcttcaagaactcgatcttaccgactgttatggcgtcaatgacagagggctagaatatatctcaaagtgttcgaatcttctaaggttgaaacttggcctctgcacaaatatctcagacaaagggatgtttcatatcggttccaaatgttccaagcttctagaacttgatctataccgctgtggtggttttggagatgacggtttagcagctatatcccgaggttgcaagagcttgaaccggctcattatatcgtactgtggtgagctaacagacacaggggttgaacaaatccgccagcttgaacatctaagccatcttgaacttcgagggctaaagaatataaccggtgctggtctagctgcagttgcgtgcggctgcaagaaattggattacttggacctcaagaagtgcgagaatatagatgactcaggcttctgggcgcttgcttactttgcaagaaacctaagacagataaacttgtgctattgctcggttt
ctgatacggctctatgcatgttaatgagcaatctaagtcgggttcaagacgttgacttagtcaacctgaaccgtgtgacagtggaagggtctgagtttgctctaagagcctgttgcaataggctcaagaagcttaaacttttcgctcctctcagattcttgctctcatctgaattgcttgagatgcttcatgctcgtggttgccgcattagatgggactgaaagacgaaactttcttcaatggaactttactagtaacactttaacgtgttcatatgtctacttgttgtatctataaaaaattcgactatgtttttaaattcggtttaccaattatatgtctaccgctttggtattatcttccaacataaacaatagtagttttagaaaacaaaaatattattttggtattctatgcaaaa(seq id no.:60)
267.在本发明中,所述ral1基因来源于大豆(xm_003521631.4预测:glycine max f-box/lrr-repeat protein 3(loc100802904),transcript variant x1),核酸序列如seq id no.:61所示。
268.tttcaacaatttttctctcatgtccaagttttgtcctgagcaggacaacttaattggcggttcccttctcgcccttggatctttaattggttgttccctccgctccaagaaaaaaaagggcatttatggcaaaaaagagcagcagcattcaacaagttgcgagaggaacacaggactcaattcacatggccgtacccgaagaaagcgaaaagtgtgaaacacgcaccctctgaaatctaaaattcaattttcccttccctgaccctgtttcttctattcacattgtattctccttgttttttcgcttttcaattttccattgaactcagacaaaaacagaaagaaaggggaaaaaaatgaacccagagaaatctcgttgcaggttgccacttcgcacgctctctaaacacacgcaccaccctcttctccacctccgcctccttttcctcttcgttcccacctaaactgtttcccttcagttccacgtcacattaacaaacctttttttttcttaaaaaaaaaactttagtaattacgaaatttctgataccttaatgttgtctgaatccgttttctgcctcttgaccgaggacctgctcatccgggtcctcgaaaagctcgggccggatcggaaaccgtggcggctggtgtgcaaggagtttctccgggtcgaatcgtcgacccggaagaagattcggatcctccgaatcgagtttctgcttgggttgttggagaagttctgcaacattgagacgctggacctgtcgatgtgtccgcggatcgaggacggagctgtgtcggttgtgctgagtcagggatcggcgagttggactcggggactgaggagactcgtgctgagtcgcgccaccgggttggggcatgtgggcttggagatgctgattcgggcgtgtcccatgttggaggccgtggatgtgtcccattgttgggggtatggcgacagagaggctgcggcgctatcgtgcgccgcgaggttgagggaactcaacatggataagtgtttgggagttactgatattgggttggccaagattgctgtcgggtgtgggaaattggagaggctgagtttgaagtggtgcttggagatttctgatctggggattgatcttctttgcaaaaagtgcttggatttgaaatttctcgacgtgtcatatctcaaggtaacaagtgaatctttgagatcaatagcttctctgttaaagcttgaggtttttgttatggttggctgctctttagtggatgacgttggattgcggtttcttgaaaaagggtgtccactgcttaaggcaattgatgtatcaaggtgtgattgtgttagctcttccggtttaatatctgtaattagtggacatggaggtcttgagcagttggatgcaggatattgcctctctgagctttcagcacctcttgttaaatgcttggagaatttaaagcagctgagaataattagaattgatggtgttcgagtttctgactttatcctccagacaattggcaccaattgcaagtctttagtggaacttggtttaagcaaatgcgttggagtgaccaacaagggaattgtgcagctagtatctggctgtggctatttgaagatacttgatttgacttgttgtcggttcatatctgatgcagcaatctctactatagcagactcttgtccagaccttgtctgtctgaagctagaatcttgtgatatggtgactgagaattgtctttatcaacttggattaaattgctcgcttctcaaagagcttgatcttactgattgctctggtgttgatgacatagctctaagatatctatcaagatgttcagaacttgtaagattgaaattaggattatgcacaaatatatcagacataggattggcacacattgcttgtaactgcccaaaaatgactgaacttgatctctatcgatgtgtacgtattggagatgatgggctagcggcactaacgagtggatgcaaggggttgacaaacctcaacttgtcatattgcaatagaattacagacagagggttggagtatatcagccatcttggtgaactatctgatctggagttgcgtgggctttctaatatcacaagcattggtataaaagcagttgcaataagttgcaagagattggcagatttagatttgaaacattgcgaaaaaattgatgattcaggtttctgggcccttgctttttattcgcaaaacctgcggcagataaatatgagctactgtatcgtgtcagatatggtgtt
gtgcatgcttatgggtaacctgaaacgcctgcaagatgccaaactggtttgtctttctaaagtgagtgtaaaaggattggaagttgcccttagagcttgctgtggtcggattaaaaaggttaaactgcagaggtccctcaggttctcgctttcctctgaaatgctcgagacaatgcatgcacgagggtgcaagatcagatgggattagccaattgtcacgctattaatctgttatactttcttttcttggaagggtgctgcttcattaagatcttttttattcaaaattttatatttctctagcattttcttttctttaaactctgttaccagatttctacggaaggtatttttttcaccttcttaagttacatcatctccaataaagcatgaggttacttatcttcgaattaaa(seq id no.:61)
269.本发明还提供了一种包括本发明的基因的重组载体。作为一种优选的方式,重组载体的启动子下游包含多克隆位点或至少一个酶切位点。当需要表达本发明目的基因时,将目的基因连接入适合的多克隆位点或酶切位点内,从而将目的基因与启动子可操作地连接。作为另一种优选方式,所述的重组载体包括(从5’到3’方向):启动子,目的基因,和终止子。如果需要,所述的重组载体还可以包括选自下组的元件:3’多聚核苷酸化信号;非翻译核酸序列;转运和靶向核酸序列;抗性选择标记(二氢叶酸还原酶、新霉素抗性、潮霉素抗性以及绿色荧光蛋白等);增强子;或操作子。
270.用于制备重组载体的方法是本领域普通技术人员所熟知的。表达载体可以是细菌质粒、噬菌体、酵母质粒、植物细胞病毒、哺乳动物细胞病毒或其他载体。总之,只要其能够在宿主体内复制和稳定,任何质粒和载体都是可以被采用的。
271.本领域普通技术人员可以使用熟知的方法构建含有本发明所述的基因的表达载体。这些方法包括体外重组dna技术、dna合成技术、体内重组技术等。使用本发明的基因构建重组表达载体时,可在其转录起始核苷酸前加上任何一种增强型、组成型、组织特异型或诱导型启动子,如花椰菜花叶病毒(camv)35s启动子、泛素(ubiquitin)基因启动子(pubi)等,它们可单独使用或与其它的启动子结合使用。
272.包括本发明基因、表达盒或的载体可以用于转化适当的宿主细胞,以使宿主表达蛋白质。宿主细胞可以是原核细胞,如大肠杆菌,链霉菌属、农杆菌:或是低等真核细胞,如酵母细胞;或是高等真核细胞,如植物细胞。本领域一般技术人员都清楚如何选择适当的载体和宿主细胞。用重组dna转化宿主细胞可用本领域技术人员熟知的常规技术进行。当宿主为原核生物(如大肠杆菌)时,可以用cacl2法处理,也可用电穿孔法进行。当宿主是真核生物,可选用如下的dna转染方法:磷酸钙共沉淀法,常规机械方法(如显微注射、电穿孔、脂质体包装等)。转化植物也可使用农杆菌转化或基因枪转化等方法,例如叶盘法、幼胚转化法、花芽浸泡法等。对于转化的植物细胞、组织或器官可以用常规方法再生成植株,从而获得转基因的植物。
273.作为本发明的一种优选方式,制备转基因植物的方法是:将携带启动子和目的基因(两者可操作地连接)的载体转入农杆菌,农杆菌再将含启动子和目的基因的载体片段整合到植物的染色体上。涉及的转基因受体植物例如是拟南芥、烟草、果树等。
274.为了便于对转基因植物细胞或植物进行鉴定及筛选,可对所用植物表达载体进行加工,如加入在植物中表达可产生颜色变化的酶或发光化合物的基因(gus基因、gfp基因、萤光素酶基因等)、具有抗性的抗生素标记物(庆大霉素标记物、卡那霉素标记物等)或是抗化学试剂标记基因(如抗除草剂基因)等。从转基因植物的安全性考虑,可不加任何选择性标记基因,直接以逆境筛选转化植株。
275.rae1蛋白或ral1蛋白及其编码基因有多方面的用途。例如用于筛选具有调控抗铝
毒能力的化合物、多肽或其它配体。用表达的重组rae1蛋白或ral1蛋白的筛选多肽库可用于寻找有价值的能抑制、或促进植物抗铝毒能力的多肽分子。
276.改良植物抗铝毒能力的方法
277.本发明还提供一种调控植物抗铝毒能力的方法,包括步骤:
278.(i)调节所述植物中rae1蛋白或ral1蛋白的表达量和/或活性,从而调控植物抗铝毒能力。
279.在另一优选例中,适用于所述方法的所述植物包括农作物、林业植物、蔬菜、瓜果、花卉、牧草(包括草坪草)。
280.在另一优选例中,所述调控植物抗铝毒能力为增强植物抗铝毒能力时,下调植物中rae1蛋白或ral1蛋白的表达量和/或活性,或使rae1蛋白或ral1蛋白丧失活性。
281.在另一优选例中,所述调控植物抗铝毒能力为降低植物抗铝毒能力时,上调植物中rae1蛋白的表达量和/或活性。
282.在另一优选例中,所述方法还用于调控植物(如根)分泌的有机酸水平。
283.在另一优选例中,下调植物中rae1蛋白或ral1蛋白的表达量和/或活性的方法包括(但不限于):通过rnai技术下调rae1或ral1表达或crispr技术改造rae1或ral1。
284.本发明的主要优点包括:
285.(1)本发明的rae1基因或ral1基因或其编码蛋白、或其突变蛋白、或其促进剂、或其抑制剂可调控stop1蛋白的表达或降解、植物抗铝毒能力或耐铝性能,还可以调控选自下组基因的表达:atalmt1、atmate、als3、或其组合。
286.(2)本发明首次发现,rae1通过泛素化修饰介导stop1蛋白的降解,rae1突变蛋白和去掉f-box结构域蛋白丧失了介导stop1降解的功能,相反,过量表达rae1可促进stop1蛋白的降解。
287.(3)本发明方法可有效、显著提高植物的抗铝毒能力,从而解决酸性土壤铝毒害。
288.(4)本发明rae1基因或ral1基因或其编码蛋白可以用于筛选具有调控抗铝毒能力的化合物、多肽或其它配体,寻找有价值的能抑制、或促进植物抗铝毒能力的多肽分子。
289.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件如sambrook等人,分子克隆:实验室手册(new york:cold spring harbor laboratory press,1989)中所述的条件,或按照制造厂商所建议的条件。除非有特别说明,否则实施例中所用的材料和试剂均为市售产品。
290.通用方法
291.1.实验材料
292.植物材料:拟南芥野生型col-0;从ems诱变库筛选获得的rae1突变体材料rae1-1到rae1-8、stop1突变体材料stop1-3(突变位点是h352y,stop1蛋白失活);从arbc订购ral1的t-dna敲除突变体salk_114341c;转基因材料patalmt1:luc、pstop1:stop1-ha、pstop1:stop1-gus、prae1:gus、pubq10:rae1和pral1:gus。
293.菌种:大肠杆菌dh5α、bl21(de3);农杆菌gv3101。
294.2.实验方法
295.1)ems诱变patalmt1:luc转基因种子库和突变体筛选
296.构建patalmt1:luc载体,将1.76kb atalmt1启动子通过gateway重组试剂盒(thermofisher)连入载体pgwb35。农杆菌转化和拟南芥侵染:通过热激法转化农杆菌gv3101,挑取阳性克隆用lb液体培养,然后用5%蔗糖溶液重悬菌体,再加入silwet-l77使终浓度达到0.05%,完成配置农杆菌的侵染悬浮液。用蘸花法侵染拟南芥,剪去拟南芥的果荚,然后将花浸泡在侵染悬浮液中1min,用保鲜膜保湿并避光24h后去掉保鲜膜重新接受光照,等果荚成熟之后收获t0代种子。将t0代种子种在含潮霉素的1/2ms平板培养基上筛选t1代转基因阳性株系,根据t2代是否显示为3:1分离比,挑选单拷贝插入的转基因株系,继续种植直至得到纯合的t3代用于后续试验。
297.对patalmt1:luc转基因种子库进行ems诱变,将种子用100mm磷酸盐缓冲液在4℃冰箱浸泡过夜,然后用8%的naclo对种子消毒10min,用灭菌水清洗4遍,之后将种子放入40ml新灭菌过的100mm磷酸盐缓冲液中,ems使其终浓度达到0.4%(v/v),在翻转仪室温上下翻转8h,再用灭菌水对m1种子彻底漂洗至少20遍,然后点种在1/2ms平板培养基上生长,再移苗到土里种植。
298.对m2代种子进行突变体筛选,在1/2ms竖板培养基点种并在16h光照/8h黑暗、22℃光照培养箱中培养7-8d,均匀喷洒1mm的荧光素工作液,放于暗处避光反应10min,然后放入luc荧光成像系统的暗箱中间,用预冷到-110℃的cdd相机进行拍照,曝光时间3min,筛选比野生型对照荧光变亮的幼苗。
299.构建patalmt1:luc引物:
300.f:5
’‑
ggggacaagtttgtacaaaaaagcaggctcctggctccttttggttgtcta-3’(seq id no.:1)
301.r:5
’‑
ggggaccactttgtacaagaaagctgggtaacaccttttgatggtcactcagct-3’(seq id no.:2)
302.2)抗铝毒基因的mrna表达分析
303.研究铝处理对野生型和突变体中基因表达的变化,将水培培养4周的拟南芥,用0.5mm cacl2溶液(ph 4.8)预处理6h,之后用0或30μm alcl3的cacl2溶液(ph 4.8)处理12h。剪取整条根系,用rna提取试剂盒(9769;takara,大连,中国)提取rna并进行dna消化,用1μg rna反转录,然后用5μl 1/25cdna进行qrt-pcr(5μl体系)(bio-rad cfx connecttm real-time system;bio-rad,singapore)。atubq10作为内参基因,结果为平均数
±
sd,3个生物学重复。
304.3)回补rae1、检测stop1蛋白和检测rae1/ral1组织表达模式的转基因材料构建
305.为了回补突变体rae1,将一个包含2.43kb rae1启动子、基因组片段和1.44kb基因下游连入载体pcambia3301。为了检测植物体内stop1蛋白,将一个包含2.79kb stop1启动子和基因组片段与3
×
ha或gus融合连入载体pcambia1305或pore-r2,分别得到载体pstop1:stop1-ha和pstop1:stop1-gus。以上载体通过重组试剂盒构建(c112;vazyme biotech co.,ltd,南京,中国)。为了检测rae1的组织表达模式,将包含2.43kb rae1启动子连接gus连入pore-r2载体。为了过量表达rae1,将2.55kb atubq10的启动子连接rae1 cds连入pcambia3301载体。
306.构建prae1:rae1引物:
307.f:5
’‑
gacctgcaggcatgcaagctttgtttcagcatatttgcatgtttgat-3’(seq id no.:3)
308.r:5
’‑
cacctgtaattcacacgtggtgtgctacagaggaaagaaggtttg-3’(seq id no.:4)
309.构建pstop1:stop1-3
×
ha引物:
310.f:5
’‑
ggtacccggggatcctctagatttagggcttcaaactctttaccc-3’(seq id no.:5)
311.r:5
’‑
ggaacatcgtatgggtaaagcttgagactagtatctgaaacagactcac-3’(seq id no.:6)
312.构建pstop1:stop1-gus引物:
313.f:5
’‑
ttggggcccaacgttctcgagtttagggcttcaaactctttaccc-3’(seq id no.:7)
314.r:5
’‑
cggccgcaaagtcgacgaattcgagactagtatctgaaacagactcac-3’(seq id no.:8)
315.构建prae1:gus引物:
316.f:5
’‑
ttggggcccaacgttctcgagtgtttcagcatatttgcatgtttga-3’(seq id no.:62)
317.r:5
’‑
cggccgcaaagtcgacgaattctgctgctgctgctggtgggt-3’(seq id no.:63)
318.构建patubq10:rae1引物:
319.f:5
’‑
cgacctgcaggcatgcaagcttaaagtctgtatatatgacacagaagaaacc-3’(seq id no.:64)
320.f:5
’‑
cacctgtaattcacacgtggtgttaaggcgccatctcttccag(seq id no.:65)
321.构建pral1:gus引物
322.f 5
’‑
ttggggcccaacgttctcgagtgacctgaggctgaaaatcg-3’(seq id no.:66)
323.r 5
’‑
cggccgcaaagtcgacgaattctttgcaacagaaccagaaataaaca-3’(seq id no.:67)
324.4)gus染色方法
325.水培培养1周的pstop1:stop1-gus转基因株系,用0.5mm cacl2溶液(ph 4.8)预处理12h,之后用0或15μm alcl3与50μm mg132组合的cacl2溶液(ph 4.8)处理12h。用gus染液(161031;o’biolab co.,ltd,北京,中国)在37℃染色2h,然后用体视镜拍照(szx7;olympus,japan)。
326.5)luc活性分析检测rae1启动子调控和emsa试验检测stop1与rae1启动子结合
327.luc活性分析:将prae1:luc或mprae1:luc、35s:stop1-2
×
flag或35s:2
×
flag、pzmubq:gus(内参)共同转入拟南芥原生质体中室温孵育表达20h,然后分别检测luc活性(rg006-2;beyot ime biotechnology,中国)和gus活性(a602251;sangon biotech co.,ltd.,中国)。
328.emsa试验:
329.stop1的cds序列连入pet29a(+)载体构建,转入大肠杆菌bl21(de3)表达并纯化蛋白。合成生物素标记的dna探针,使用emsa试剂盒进行化学发光检测(gs009;beyotime biotechnology,中国)。
330.构建prae1:luc引物:
331.f:5
’‑
gcctgcaggctctagaggatcctgtttcagcatatttgcatgtttga-3’(seq id no.:68)
332.r:5
’‑
atgtttttggcgtcttccatggtgctgctgctgctggtgggt-3’(seq id no.:69)
333.构建mprae1:luc引物:
334.1f:5
’‑
gcctgcaggctctagaggatcctgtttcagcatatttgcatgtttga-3’(seq id no.:70)
335.1r:5
’‑
agactatctcggttaaagactgcctcgattaacagattcgagtgcggacagtacgat-3’(seq id no.:71)
336.2f:5
’‑
taatcgaggcagtctttaaccgagatagtcttctactaccaatggcctaac(seq id no.:72)
337.ttgtt-3’338.2r:5
’‑
atgtttttggcgtcttccatggtgctgctgctgctggtgggt-3’(seq id no.:73)
339.合成prae1-emsa序列:
340.f:5
’‑
tcaatctatcgtactgtccgcactcgaatctgtccttcctcgcatgcttactccaccatata cttctactaccaatggcctaacttgttgattgcg-3’(seq id no.:74)
341.r:5
’‑
cgcaatcaacaagttaggccattggtagtagaagtatatggtggagtaagcatgcgaggaag gacagattcgagtgcggacagtacgatagattga-3’(seq id no.:75)
342.合成mprae1-emsa序列:
343.f:5
’‑
tcaatctatcgtactgtccgcactcgaatctgttaatcgaggcagtctttaaccgagatagt cttctactaccaatggcctaacttgttgattgcg-3’(seq id no.:76)
344.r:5
’‑
cgcaatcaacaagttaggccattggtagtagaagactatctcggttaaagactgcctcgatt aacagattcgagtgcggacagtacgatagattga-3’(seq id no.:77)
345.6)pull down试验
346.rae1和stop1的cds序列连入pet29a(+),pgex4t-1或pet-h6trx载体构建rae1-his,gst-rae1,gst-stop1或his-trx-stop1,载体转入大肠杆菌bl21(de3)表达蛋白。bl21(de3)在37℃生长到od
600
达到0.6,然后加入0.1mm iptg在25℃诱导蛋白表达6h。含有gst-stop1或gst-rae1的细菌裂解液和对照gst蛋白与gst琼脂糖珠(c60031;sangon biotech co.,ltd,上海,中国)在4℃摇床上孵育1h。然后用缓冲液清洗4次再用含有rae1-his或his-trx-stop1蛋白的裂解液在在4℃摇床上孵育2h。用缓冲液清洗5次用10%sds-page进行免疫印迹试验。
347.构建rae1-his
348.f:5
’‑
tccatggctgatatcggatccatgaagaaggttaaacagattcgt-3’(seq id no.:9)
349.r:5
’‑
gtggtggtggtggtgctcgagaggcgccatctcttccag-3’(seq id no.:10)
350.构建gst-rae1
351.f:5
’‑
tccgcgtggatccccggaattcatgaagaaggttaaacagattcgt-3’(seq id no.:11)
352.r:5
’‑
gtcacgatgcggccgctcgagttaaggcgccatctcttccag-3’(seq id no.:12)
353.构建gst-stop1
354.f:5
’‑
tccgcgtggatccccggaattcatggaaactgaagacgatttgtg-3’(seq id no.:13)
355.r:5
’‑
gtcacgatgcggccgctcgagttagagactagtatctgaaacagac-3’(seq id no.:14)
356.构建his-trx-stop1
357.f:5
’‑
ggtctggtgccacgcggatccatggaaactgaagacgatttgtg-3’(seq id no.:15)
358.r:5
’‑
acttaagcattatgcggccgcttagagactagtatctgaaacagac-3’(seq id no.:16)
359.7)split-luc试验
360.将rae1,rae1-1,rae1δf和stop1的cds序列连入pcambia1-cluc或pcambia1-nluc载体构建cluc-rae1,cluc-rae1-1,cluc-rae1δf和stop1-nluc。
361.将构建转入农杆菌gv3101,根据不同组合注射入烟草n.benthamiana叶片,在暗处培养24h然后放入光照培养箱培养48d,然后叶片用用luc成像系统拍照。
362.构建cluc-rae1/cluc-rae1-1
363.f:5
’‑
gtacgcgtcccggggcggtaccatgaagaaggttaaacagattcg-3’(seq id no.:17)
364.r:5
’‑
gaacgaaagctctgcaggtcgacttaaggcgccatctcttccag-3’(seq id no.:18)
365.构建cluc-rae1δf
366.f:5
’‑
gtacgcgtcccggggcggtaccctcgatcttaccttctgccc-3’(seq id no.:19)
367.r:5
’‑
gaacgaaagctctgcaggtcgacttaaggcgccatctcttccag-3’(seq id no.:20)
368.构建stop1-nluc
369.f:5
’‑
acgagctcggtacccgggatccatggaaactgaagacgatttgtg-3’(seq id no.:21)
370.r:5
’‑
gacgcgtacgagatctggtcgacgagactagtatctgaaacagact-3’(seq id no.:22)
371.8)蛋白提取,coip试验和蛋白降解试验和泛素化修饰检测试验
372.将水培培养4周的拟南芥,用0.5mm cacl2溶液(ph 4.8)预处理6h,之后用0或30μm alcl3与50μm mg132组合的cacl2溶液(ph 4.8)处理12h。剪取整条根系,用蛋白提取液提取蛋白(20mm tris-hcl ph 7.5,300mm nacl,5mm mgcl2,5mm dtt,50μm mg132,0.5%np-40,和1
×
complete protease inhibitor mixture)。
373.coip试验:2ml拟南芥原生质体用100μg 35s:stop1-3
×
ha和100μg35s:rae1-2
×
flag或50μg 35s:rae1-1-2
×
flag或35s:rae1δf-2
×
flag共转,35s:stop1-3
×
ha和35s:2
×
flag作为对照。然后用100μl蛋白提取液(20mm tris-hcl ph 7.4,150mm nacl,1mm mgcl2,1mm dtt,50μm mg132,0.25%np-40,和1
×
完全蛋白酶抑制剂混合物(complete protease inhibitor mixture))提取蛋白,20μl蛋白提取液作为input。总的蛋白提取液稀释到1ml然后与20μl anti-flag m2磁珠在4℃摇床上孵育3h,用缓冲液洗涤3次后用100mm甘氨酸(ph 2.5)洗脱并用1m tris-hcl(ph 9.0)中和,之后进行免疫印迹试验。
374.蛋白降解试验:用50μg 35s:stop1-2
×
flag和25μg 35s:rae1-3
×
ha或50μg 35s:rae1-3
×
ha(35s:rae1-1-3
×
ha或35s:rae1δf-3
×
ha保持一样).然后用50μl蛋白提取液提取蛋白,20μl蛋白提取液作为input。
375.泛素化修饰检测试验:
376.用35s:myc-ubq10,35s:stop1-2
×
flag,35s:rae1-3
×
ha(35s:rae1-1-3
×
ha或35s:rae1δf-3
×
ha)转入拟南芥原生质体中,室温孵育表达16h,然后50μm mg132处理8h,用蛋白提取液(20mm tris-hcl ph 7.4,150mm nacl,1mm mgcl2,1mm dtt,50μm mg132,0.25%np-40,和1
×
complete protease inhibitor mixture)提取蛋白,20μl蛋白提取液作为input。总的蛋白提取液稀释到1ml然后与20μl anti-flag m2磁珠在4℃摇床上孵育2h,用缓冲液洗涤5次后,用anti-myc抗体检测泛素化修饰情况。
377.构建35s:stop1-3
×
ha
378.f:5
’‑
cttgctccgtggatcctctagaatggaaactgaagacgatttgtg-3’(seq id no.:23)
379.r:5
’‑
gaacatcgtatgggtatctagagagactagtatctgaaacagact-3’(seq id no.:24)
380.构建35s:rae1/rae1-1-3
×
ha
381.f:5
’‑
cttgctccgtggatcctctagaatgaagaaggttaaacagat-3’(seq id no.:25)
382.r:5
’‑
gaacatcgtatgggtatctagaaggcgccatctcttcc-3’(seq id no.:26)
383.构建35s:rae1δf-3
×
ha
384.f:5
’‑
cttgctccgtggatcctctagaatgctcgatcttaccttctgccc-3’(seq id no.:27)
385.r:5
’‑
gaacatcgtatgggtatctagaaggcgccatctcttcc-3’(seq id no.:28)
386.构建35s:stop1-2
×
flag
387.f:5
’‑
cttgctccgtggatcctctagaatggaaactgaagacgatttgtg-3’(seq id no.:29)
388.r:5
’‑
tgtagtcagaaggcctggtaccgagactagtatctgaaacagact-3’(seq id no.:30)
389.构建35s:rae1/rae1-1-2
×
flag
390.f:5
’‑
cttgctccgtggatcctctagaatgaagaaggttaaacagat-3’(seq id no.:31)
391.r:5
’‑
tgtagtcagaaggcctggtaccaggcgccatctcttcc-3’(seq id no.:32)
392.构建35s:rae1δf-2
×
flag
393.f:5
’‑
cttgctccgtggatcctctagaatgctcgatcttaccttctgccc-3’(seq id no.:33)
394.r:5
’‑
tgtagtcagaaggcctggtaccaggcgccatctcttcc-3’(seq id no.:34)
395.9)铝毒耐性能力评测
396.为了测量根际分泌的苹果酸,将水培培养4周的拟南芥,用0.5mm cacl2溶液(ph 4.8)预处理6h,之后用0或30μm alcl3的cacl2溶液(ph 4.8)处理12h,收集根际分泌物,通过nad/nadh酶循环法测定苹果酸(hampp et al.,1984)。
397.根据ligaba-osena等(2017)的方法来测定拟南芥根中铝含量。用0.5mm柠檬酸溶液(ph 4.2)在4℃处理30min来去除根表面的铝,然后用18ω的超纯水清洗三次并吸干,再将样品放于60℃烘箱烘干。用1ml hno3和hclo4的混酸进行消解,并用2%hno3稀释,然后用icp-ms测定铝含量。
398.根据larsen等(2005)的铝浸泡培养基方法来测定拟南芥铝耐性。培养基基质配方如下:1mm kno3,0.2mm kh2po4,2mm mgso4,0.25mm(nh4)2so4,1mm ca(no3)2,1mm caso4,1mm k2so4,1μm mnso4,5μm h3bo3,0.05μm cuso4,0.2μm znso4,0.02μm namoo4,0.1μm cacl2,0.001μm cocl2,1%sucrose和0.3%gellan gum(g1910;sigma-aldrich)。然后将50ml基质用40ml含有0、0.75、1、1.25mm alcl3相同配方(不含gellan gum)的培养液浸泡一天,去除培养液并点上种子在光照培养箱竖直培养七天。植株拍照并用image j测量根长。
399.实施例1突变体诱变筛选和基因回补验证
400.为了研究atalmt1的表达调控和stop1蛋白水平调控机制,将1.76kb atalmt1启动子与荧光素酶基因融合,通过农杆菌侵染拟南芥野生型col-0构建了patalmt1:luc转基因报告基因系,利用该材料进行ems诱变,通过luc荧光检测来筛选影响luc报告基因表达的突变体。
401.通过筛选约10000株m2株系,一共获得17株影响luc报告基因表达的突变体,利用其中一个luc表达增强突变体克隆了目的基因,命名为rae1(regulation of atalmt1 expression 1),通过对其余突变体测序发现,一共筛选到8个rae1上不同位点突变的突变体(rae1-1到rae1-8),突变体rae1-1到rae1-8中根和地上部的luc荧光均比野生型提高(图1a、1b)。
402.为了了解rae1的功能,首先分析rae1的二级结构发现,rae1编码一个含f-box结构
域和18个lrr重复结构的蛋白(图1b)。
403.构建载体prae1:rae1通过农杆菌侵染突变体rae1-1获得回补转基因株系,挑选2个独立株系进行luc荧光检测,它们均能回补rae1-1荧光表型(图1c)。通过以上方法克隆了一个新的负调控atalmt1表达的基因,并对该基因进行了回补验证。
404.实施例2 atalmt1等抗铝毒基因在突变体rae1和过量表达rae1中的表达
405.进一步分析luc报告基因和atalmt1在突变体rae1中的表达,选取wt,rae1-1,rae1-2,stop1-3进行试验,不加al或加al处理12h之后剪取根提取rna进行qpcr分析表达。不加al条件下,rae1中luc报告基因和atalmt1的表达比野生型高5倍多,加al处理luc报告基因和atalmt1的表达比野生型高3-5倍(图2a、2b)。luc报告基因和atalmt1在stop1-3中完全不表达,说明stop1是atalmt1表达必须的转录因子(图2a、2b)。
406.另一方面分析突变体rae1中其他抗铝毒基因的表达发现,另外2个stop1下游调控基因atmate和als3的表达在突变体rae1中无论在无铝条件还是有铝条件下均比野生型(wt)提高(图2c、2d),而不受stop1调控的基因atstar1和als1的表达在突变体rae1中不受影响(图2e、2f)。
407.相反,过量表达rae1,可降低ataltm1、atmate和als3的表达(图3)。rae1表达受到铝处理的诱导,并受到stop1的调控,在rae1中rae1的表达水平也上调。
408.以上结果表明rae1影响stop1调控的基因的表达,进一步推测rae1可能影响stop1的蛋白稳定性。
409.实施例3 rae1的表达受到铝处理诱导并被stop1直接调控
410.rae1表达受到铝处理的诱导,并受到stop1的调控,在rae1中rae1的表达水平也上调。原生质体表达系统显示stop1调控prae1:luc的表达,将结合区域突变则调控减弱,emsa验证stop1直接结合rae1的启动子上的结合区域。rae1表达在植物各组织中均有表达,且主要在维管组织表达(图4)。stop1通过直接结合rae1的启动子调控rae1表达,从而两者形成一个环形的负反馈调控机制。
411.实施例4 rae1与stop1的结合关系
412.为了分析rae1与stop1的结合关系,首先进行了体外pull-down试验。gst-stop1可以特异拉下rae1-his,反过来gst-rae1可以特异拉下his-trx-stop1,说明rae1和stop1在体外可以直接结合(图5a)。
413.为了分析rae1与stop1在植物体内的互作,又进行了烟草split-luc试验,将rae1/rae1-1(突变蛋白)/rae1
△
f(去掉f-box结构域蛋白)的n端与cluc融合,stop1的c端与nluc融合,当cluc-rae1-1与stop1-nluc在烟草叶片中共表达时可以看到荧光,而cluc-rae1与stop1-nluc共表达则没有荧光(图3b)。又将cluc-rae1
△
f与stop1-nluc共表达,发现它们能够互作产生荧光(图5b)。split-luc试验结果表明rae1与stop1在体内能够互作,有功能的rae1与stop1结合促进了stop1的降解,还表明rae1-1突变蛋白没有影响与stop1的互作,而是影响了促进stop1降解的功能。
414.进一步进行体内co-ip试验,将带有flag标签的rae1/rae1-1/rae1
△
f和ha标签的stop1在拟南芥原生质体中共表达,用flag抗体进行免疫沉淀。结果显示flag-rae1,flag-rae1-1和flag-rae1
△
f分别都可以将stop1-ha免疫共沉淀下来(图5c),并且野生型rae1将stop1-ha免疫共沉淀下来较少,这与split-luc试验一致。
415.通过以上体外pull-down试验、烟草split-luc试验以及体内co-ip试验证明了rae1能够与stop1蛋白互作。
416.实施例5研究rae1对stop1蛋白水平的调控
417.为了研究rae1对stop1蛋白水平的调控,构建了pstop1:stop1-ha转基因株系,并将pstop1:stop1-ha杂交到rae1-1突变体中,然后进行不加al或加al处理检测根中的stop1蛋白。铝处理可以使stop1蛋白积累,在rae1-1突变体中stop1蛋白无论在无铝条件还是有铝条件下均比野生型增多,相反,过量表达rae1可促进stop1蛋白的降解(图6)。
418.为了研究stop1是通过26s蛋白酶体途径进行降解,使用蛋白酶体抑制剂mg132对pstop1:stop1-ha转基因株系进行处理,mg132处理1h便可以抑制stop1的降解使stop1蛋白增多(图7a),并且在无铝条件或有铝条件下mg132均抑制stop1的降解使stop1蛋白增多(图7b)。进一步构建了pstop1:stop1-gus转基因株系,进行不加al或加al处理以及mg132处理,结果表明铝处理可以使stop1蛋白积累,并且在无铝条件或有铝条件下mg132均抑制stop1的降解使stop1蛋白增多(图7c、7d)。
419.为了证明rae1介导stop1降解,将不同量的rae1/rae1-1/rae1
△
f和stop1在拟南芥原生质体中共表达,随着提高rae1的表达量,促进了stop1的降解(图8a),相反提高rae1-1/rae1
△
f的表达量,不影响stop1蛋白表达量(图8a)。原生质表达系统中验证stop1蛋白被泛素化修饰,而突变体蛋白rae1-1和rae1
△
f不能介导stop1的泛素化修饰(图8b、8c)。以上表明rae1通过泛素化修饰介导stop1蛋白的降解,而rae1-1突变蛋白和去掉f-box结构域蛋白丧失了介导stop1泛素化并降解的功能。
420.由于突变体rae1中stop1积累,受stop1调控的抗铝毒基因atalmt1等表达上调,比较了野生型和突变体rae1中苹果酸的分泌。在无al条件下,两者的苹果酸分泌都很少,并且没有差异(图9a),当进行al处理之后,两者苹果酸的分泌均增多,并且突变体rae1-1和rae1-2中苹果酸的分泌比野生型显著提高(图9a)。与此一致的是,突变体rae1中苹果酸分泌的提高,导致突变体rae1-1和rae1-2根中比野生型积累更少的al(图9b)。进一步在铝浸泡板培养基上比较了野生型和突变体rae1对al毒的抗性,在1mm al处理条件下,突变体rae1-1和rae1-2的相对根长比野生型明显更长(图9c、9d)。以上表明rae1突变导致的stop1蛋白积累大幅提高了拟南芥对al毒的抗性,而过表达rae1减弱了拟南芥对al毒的抗性。
421.实施例6 rae1同源基因的功能具有保守性
422.rae1在拟南芥中有一个同源基因ral1(rae1 like 1),ral1的t-dna敲除突变体ral1中atalmt1、patalmt1:luc的表达上调,但是上调幅度比在rae1-1中更低(图10a、10b)。patalmt1:luc的表达在rae1-1ral1双突变体中比在各单突变体中表达更高,表明rae1与ral1存在功能冗余(图10b)。ral1的表达也受铝毒的诱导,但是ral1在根中表达的组织部位与rae1不同(图10c、10d)。烟草split-luc试验证明ral1能够与stop1蛋白互作(图10e)。以上表明,ral1具有与rae1相同的降解stop1蛋白的功能,但由于它不在根尖分生组织和伸长区表达,rae1在植物抗铝毒方面起重要作用。
423.rae1和ral1在大多数单子叶(水稻、玉米、大麦等)和双子叶植物(芸薹属白菜、大豆等)中均有相应的同源基因。水稻中rae1的同源基因是osrae1.1和osrae1.2,两个同源基因氨基酸序列有97.5%相似性,osrae1.1和osrae1.2在根尖和根基部均表达,而且表达均被al诱导,被art1(水稻中与stop1同源的基因)调控(图11a、11b)。烟草split-luc试验证明
osrae1.1能够与art1蛋白互作(图11c)。以上表明,rae1在调控植物抗铝毒转录因子stop1稳定性机制上是保守的,对作物中的rae1同源基因进行功能缺失突变有可能可以提高作物抗铝毒能力。
424.在本发明提及的所有文献都在本技术中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1