三维模型的切片方法及三维打印装置与流程
本发明涉及三维模型打印领域,特别是涉及一种三维模型的切片方法及三维打印装置。
背景技术:
随着社会计算能力的不断提高,让用户参与的“社会制造”成为必然,“社会制造”的概念是让用户参与到产品的想法、设计和制造过程中,而这种制造方式主要就是3d(3dimensions,三维)打印。与传统的车铣、切削、冲压、模具等制造工艺不同,加式制造始于三维模型,通过将材料逐层堆叠来生产物品。
3d打印的本质在于分层制造,而切片计算是获得三维物体分层信息的过程,因此该过程在3d打印中显得尤为重要,切片计算的效率直接影响3d打印的效率。但是现有方案中的对复杂模型的切片计算需要几个小时甚至几天,切片计算的时间效率难以令人满意,不能满足高效率制造的要求。
技术实现要素:
基于此,有必要提供一种可以提高三维模型的切片计算效率,满足高效率制造需求的三维模型的切片方法及三维打印装置。
一种三维模型的切片方法,应用于三维打印装置,所述三维打印装置包括中央处理器和图形处理器,所述方法包括:
所述中央处理器将所述三维模型转化为stl文件并进行存储,所述stl文件包括三角面片;
所述中央处理器利用多个切割平面将所述三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中;
所述图形处理器将分组的所述三角面片进行并行化处理得到切片截面数据,所述切片截面数据是所述切割平面与所述三角面片的交点数据;
所述中央处理器根据所述切片截面数据生成切片截面图像并进行存储。
在其中一个实施例中,所述图形处理器将分组的所述三角面片进行并行化处理得到切片截面数据的步骤包括:
所述图形处理器将分组的所述三角面片通过双层循环来进行并行化处理得到所述切片截面数据。
在其中一个实施例中,所述图形处理器将分组的所述三角面片通过双层循环来进行并行化处理得到所述切片截面数据的步骤具体为:
外层循环并行计算不同的切割平面与所述三角面片的交点;
内层循环并行计算同一个切割平面和与所述同一个切割平面相交的不同的三角面片的交点。
在其中一个实施例中,所述图形处理器将分组的所述三角面片通过双层循环来进行并行化处理得到所述切片截面数据的步骤,包括:
使用一个线程计算一个切割平面和一个三角面片的交点。
在其中一个实施例中,所述图形处理器将分组的所述三角面片进行并行化处理得到切片截面数据的步骤之前,还包括:
合理分配所述图形处理器的内存。
在其中一个实施例中,所述图形处理器将分组的所述三角面片进行并行化处理得到切片截面数据的步骤之后,还包括:
对所述切片截面数据进行栅格化处理得到位图数据。
另一方面,本发明还提出一种三维打印装置,包括中央处理器和图形处理器:
所述中央处理器用于将待打印的三维模型转化为stl文件并进行存储,所述stl文件包括三角面片,利用多个切割平面将所述三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中,并将分组完成的三角面片传送给所述图形处理器;所述中央处理器还用于接收切片截面数据,并根据所述切片截面数据生成切片截面图像并进行存储。
所述图形处理器用于接收所述分组完成的三角面片,将所述分组完成的所述三角面片进行并行化处理得到切片截面数据,并将所述切片截面数据传送给所述中央处理器,所述切片截面数据是所述切割平面与所述三角面片的交点数据。
在其中一个实施例中,所述图形处理器还用于将分组的所述三角面片通过双层循环来进行并行化处理得到所述切片截面数据。
在其中一个实施例中,所述图形处理器还用于通过外层循环并行计算不同的切割平面与所述三角面片的交点,通过内层循环并行计算同一个切割平面和与所述同一个切割平面相交的不同的三角面片的交点。
在其中一个实施例中,所述图形处理器还用于将每一个切割平面和一个三角面片的交点各分配一个线程进行计算。
上述三维模型的切片方法,应用于三维打印装置,三维打印装置包括中央处理器和图形处理器,该方法包括:中央处理器将三维模型转化为stl文件并进行存储,所述stl文件包括三角面片;中央处理器利用多个切割平面将三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中;图形处理器将分组的三角面片进行并行化处理得到切片截面数据,切片截面数据是切割平面与所述三角面片的交点数据;中央处理器根据所述切片截面数据生成切片截面图像并进行存储。通过中央处理器利用多个切割平面将三角面片进行分组,再利用图形处理器将分组的三角面片进行并行化处理得到切片截面数据,就可以有效提高三维模型的切片计算效率,进而提高3d打印效率,满足高效率制造需求。
附图说明
图1是一实施例中三维模型的切片方法的流程图;
图2是另一实施例中三维模型的切片方法的流程图;
图3是一实施例中一组无序的三角面片组成的stl模型结构示意图;
图4是一实施例中利用切割平面将三角面片进行分组的结果示意图;
图5是一实施例中利用奇偶规则进行像素点判断的示意图;
图6是一实施例中采用扫描线填充算法基本原理示意图;
图7是一实施例中需要进行切片的三维模型的结构示意图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对发明进行更全面的描述。附图中给出了本发明的首选实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
图1是一实施例中三维模型的切片方法的流程图。
在本实施例中,该三维模型的切片方法应用于三维打印装置,三维打印装置包括中央处理器和图形处理器,该三维模型的切片方法包括:
s100,中央处理器将三维模型转化为stl文件并进行存储。
中央处理器(centralprocessingunit,cpu)将待打印的三维模型转化为stl(stereolithography)文件并进行存储。stl(stereolithography)文件是一种3d模型(例如三维cad模型)文件格式,是3d打印中应用最广泛的文件格式。stl文件采用三角形作为基本多边形来近似三维物体表面。一个stl文件实际上是一组某三维物体的无序的三角面片的集合,其中每个三角面片包含三角形面片的三个顶点的空间坐标以及三角面片的法向量,其中法向量方向由模型内部指向模型外部,并且三角形面片的三个顶点的顺序与法向量的方向满足右手法则。
在一个实施例中,请参阅图3,由于一个stl文件实际上是一组某三维物体的无序的三角面片的集合,对于图3中所示的三维模型,可以使用集合t来表示stl文件中的模型数据:
t={ti,i=1,...n}
其中,ti表示一个三角面片,n为自然数,v1,v2,v3是三角形面片ti三个顶点在三维笛卡尔坐标系中的坐标表示,
在3d打印中,z轴为默认打印方向,设zmax、zmin分别为stl模型在z轴的最高点与最低点。
s200,中央处理器利用多个切割平面将三角面片进行分组。
中央处理器利用多个切割平面将三角面片进行分组,使得与同一个切割平面相交的三角面片都在同一组中。若一个三角面片与多个切割平面相交,则应将其划分到与切割平面对应的多个组中。
在一个实施例中,请结合图3,设zmax、zmin分别为stl模型在z轴的最高点与最低点。则总的切片层数m可以通过以下公式得到:
其中,函数
则每个切割平面z可表示如下:
其中,u为切片厚度,m为总的切片层数。
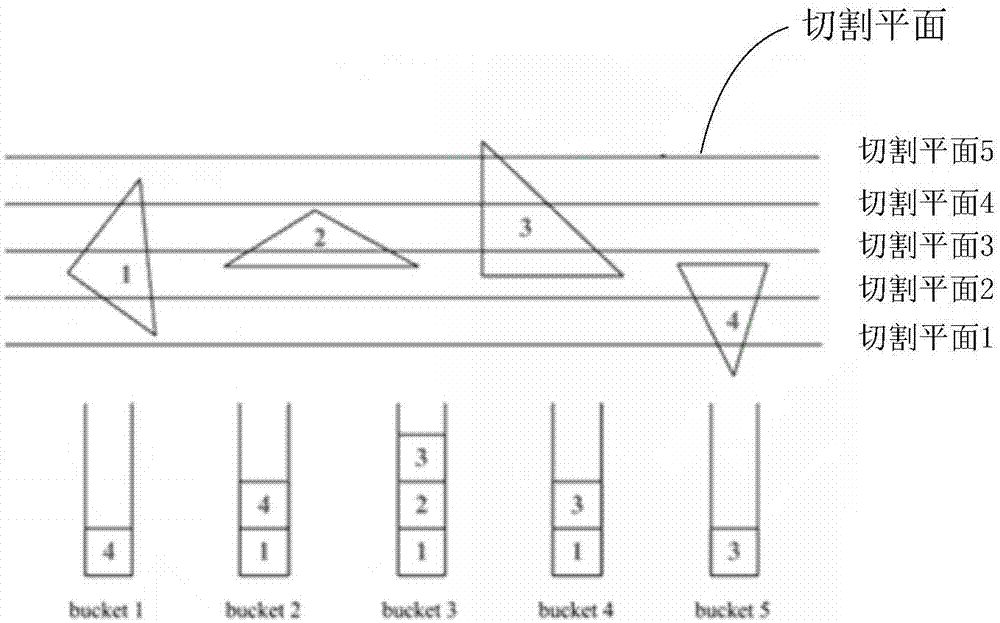
在一个实施例中,请参阅图4,假设有5个切割平面(切割平面1,切割平面2,切割平面3,切割平面4,切割平面5)和4个无序的三角面片(三角面片的编号分别为1,2,3,4),与同一个切割平面相交的三角面片均放在一个集合中,一个集合称为一个桶(bucket)。一般来说,桶的个数等于切割平面的个数。如图4中所示,与切割平面1相交的三角面片编号放在桶1(bucket1)里面,桶1里面有编号为4的三角面片。与切割平面2相交的三角面片编号放在桶2(bucket2)里面,桶2里面有编号为1和4的三角面片,以此类推,此处不再赘述。
s300,图形处理器将分组的三角面片进行并行化处理得到切片截面数据。
图形处理器(graphicsprocessingunit,gpu)将步骤s200中中央处理器分好组的三角面片进行并行化处理得到切片截面数据。切片截面数据是步骤s200中所有的切割平面与三角面片的交点数据。
s400,中央处理器根据切片截面数据生成切片截面图像并进行存储。
中央处理器根据步骤s300中图形处理器得到的切片截面数据生成切片截面图像并进行存储。在一个实施例中,中央处理器根据切片截面数据进行像素填充和切片图片生成。
上述三维模型的切片方法,应用于三维打印装置,三维打印装置包括中央处理器和图形处理器,该方法包括:中央处理器将三维模型转化为stl文件并进行存储,所述stl文件包括三角面片;中央处理器利用多个切割平面将三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中;图形处理器将分组的三角面片进行并行化处理得到切片截面数据,切片截面数据是切割平面与所述三角面片的交点数据;中央处理器根据所述切片截面数据生成切片截面图像并进行存储。通过中央处理器利用多个切割平面将三角面片进行分组,再利用图形处理器将分组的三角面片进行并行化处理得到切片截面数据,就可以有效提高三维模型的切片计算效率,进而提高3d打印效率,满足高效率制造需求。
图2是另一实施例中三维模型的切片方法的流程图。
在本实施例中,该三维模型的切片方法应用于三维打印装置,三维打印装置包括中央处理器和图形处理器,该三维模型的切片方法包括:
在本实施例中,该三维模型的切片方法应用于三维打印装置,该三维模型的切片方法包括:
s101,中央处理器将三维模型转化为stl文件并进行存储。
中央处理器(centralprocessingunit,cpu)将待打印的三维模型转化为stl文件并进行存储。stl(stereolithography)文件是一种3d模型(例如三维cad模型)文件格式,是3d打印中应用最广泛的文件格式。stl文件采用三角形作为基本多边形来近似三维物体表面。一个stl文件实际上是一组某三维物体的无序的三角面片的集合,其中每个三角面片包含三角形面片的三个顶点的空间坐标以及三角面片的法向量,其中法向量方向由模型内部指向模型外部,并且三角形面片的三个顶点的顺序与法向量的方向满足右手法则。
在一个实施例中,请参阅图3,由于一个stl文件实际上是一组某三维物体的无序的三角面片的集合,对于图3中所示的三维模型,可以使用集合t来表示stl文件中的模型数据:
t={ti,i=1,...n}
其中,ti表示一个三角面片,n为自然数,v1,v2,v3是三角形面片ti三个顶点在三维笛卡尔坐标系中的坐标表示,
在3d打印中,z轴为默认打印方向,设zmax、zmin分别为stl模型在z轴的最高点与最低点。
在一个实施例中,中央处理器设计了vertex类和facet类,用来分别存储stl模型的三角面片数据(包括三角面片顶点和法向量):
classvertex{
public:
floatx,y,z;//顶点的三维坐标
};
classfacet{
public:
inta,b,c;//三角面片的顶点索引
floatnormal[3];//三角法向量的方向
};
其中,vertex数组用来存储stl模型中所有不同的顶点,顶点在数组中的索引值由其在stl文件中出现顺序决定;facet数组用来存储模型中所有三角面片,三角面片的顶点由其在vertex数组中的索引表示,三角面片的索引值也由其在stl文件中出现顺序决定。通过这种方式,stl文件的所有数据都存储在vertex数组和facet数组,既节省了存储空间,又能快速获取后续算法实现所需数据。在一个实施例中,通过vertex数组和facet数组可以恢复原来的stl文件数据。
s102,中央处理器利用多个切割平面将三角面片进行分组。
中央处理器利用多个切割平面将三角面片进行分组,使得与同一个切割平面相交的三角面片都在同一组中。若一个三角面片与多个切割平面相交,则应将其划分到与切割平面对应的多个组中。
在一个实施例中,请结合图3,设zmax、zmin分别为stl模型在z轴的最高点与最低点。则总的切片层数m可以通过以下公式得到:
其中,函数
则每个切割平面z可表示如下:
其中,u为切片厚度,m为总的切片层数。
在一个实施例中,与同一个切割平面相交的三角面片均放在一个集合中,一个集合称为一个桶(bucket),所有的桶(bucket)形成桶列表b。一般来说,桶的个数等于切割平面的个数。请参阅图4,假设有5个切割平面(切割平面1,切割平面2,切割平面3,切割平面4,切割平面5)和4个无序的三角面片(三角面片的编号分别为1,2,3,4),与同一个切割平面相交的三角面片均放在一个集合中,一个集合称为一个桶(bucket)。如图4中所示,与切割平面1相交的三角面片编号放在桶1(bucket1)里面,桶1里面有编号为4的三角面片,与切割平面2相交的三角面片编号放在桶2(bucket2)里面,桶2里面有编号为1和4的三角面片,以此类推,此处不再赘述。
在一个实施例中,若一个三角面片与切割平面平行,则该三角面片不会被纳入桶列表b中。
s103,合理分配图形处理器的内存。
合理分配图形处理器的内存,从而使得占据图形处理器内存空间较大的分配至图形处理器的全局内存中,占据所述图形处理器内存空间较小的分配至所述图形处理器的常量内存中。
在一个实施例中,对于桶列表b使用固定大小的数组来实现。桶列表b的大小可由依次查询与每个三角面片相交的切割平面个数并累加得到。由于避免了频繁的内存申请操作,桶列表b使用固定大小的数组b实现相比于动态数据结构实现在中央处理器端也有略微的性能提升。在一个实施例中,包括数组b,stl模型数据(vertex数组和facet数组)在内的占据内存空间较大的变量将被拷贝至图形处理器(gpu)的全局内存中,而切片厚度u、切片层数m和模型z轴最高点(zmax)和最低点(zmin)等小字节变量将被拷贝至图形处理器(gpu)的常量内存中,以便后续步骤中的各线程快速读取。在其他实施例中,也可以使用动态的数组来实现桶列表b。
s104,图形处理器将分组的三角面片通过双层循环来进行并行化处理得到切片截面数据。
图形处理器将步骤s102分组的三角面片通过双层循环来进行并行化处理得到切片截面数据。切片截面数据是步骤102中所有的切割平面与三角面片的交点数据。
在一个实施例中,步骤s104具体为以下步骤:
外层循环并行计算不同的切割平面与三角面片的交点;
内层循环并行计算同一个切割平面和与所述同一个切割平面相交的不同的三角面片的交点。
也就是说,外层循环是不同切割平面与三角面片的交点计算并行执行,内层循环是同一切割平面与该切割平面相交的不同三角面片的交点计算并行执行。
在一个实施例中,步骤s104中图形处理器进行并行化处理时是通过使用一个线程计算一个切割平面和一个三角面片的交点来进行并行化处理的,这样可以最大化切片步骤的并行度。
在一个实施例中,为了给每个切割平面保留足够的线程数,切片过程中所需的总的线程数(totallinenum)可以表示为:
totalthreadnum=m×maxbucketsize
其中,maxbucketsize为桶列表b中所有桶|b[k]|(k=0,1,..m-1)中的最大值,即与切割平面相交的最多的三角面片数量,m为总的切片层数。
在一个实施例中,步骤s104中图形处理器进行并行化处理时使用的线程配置如下:
多个线程同时执行在一个gpu上,并且多个线程组成一个线程块(block),多个线程块又组织成网格(grid),线程块和网格的维度一般都是三维的。需要说明的是,由于切片任务的需求和方便起见,在本实施例中将线程块设置为一维,网格设置为二维,即把所有线程(totalthreadnum)分为一个二维的网格(griddim.x,griddim.y),其中每个网格中有一个一维的线程块(blockdim.x)。由于blockdim.x的取值不能超过gpu所允许的最大block大小,且变量blockdim.x的值通常是32的整数倍,因此性能最优的blockdim.x值可由几次性能测试实验或者通过cuda(computeunifieddevicearchitecture)占有率计算器(cudaoccupancycalculator)得到。cuda占有率计算器是一个excel表格,能够计算特定核函数(在gpu上运行的函数)在gpu上的占有率。一般情况下,占有率越高,gpu利用越充分。
在一个实施例中,考虑到maxbucketsize通常要比blockdim.x大,因此需要许多个线程块(block)才能处理与一个切割平面相交的三角面片的交点计算。因此griddim的第一维大小(griddim.x)可以表示为:
其中,函数
网格(grid)的每一行线程块(block)处理一个桶中的三角面片的交点计算,因此griddim的第二维(griddim.y)大小为桶的个数(即切割平面个数)可以表示为:
griddim.y=m
其中,m为总的切片层数(总的切片层数等于切割平面个数)。
s105,对切片截面数据进行栅格化处理得到位图数据。
对于使用dlp(digitallightprocessing,数字光处理)技术进行3d打印,需使用步骤s105对步骤s104中得到的切片截面数据进行栅格化处理得到切片的位图形式数据。对于使用其他的技术(例如fdm(fuseddepositionmodeling,熔融沉积成型)技术)进行3d打印,步骤s104中得到的切片截面数据已经是位图形式的数据,因此不需要此步骤s105,直接进入步骤s106。
dlp技术采用紫外光或发光二极管作为光源,使用数字微镜设备(digitalmicromirrordevice,dmd)来进行光源投射,可以一次性地将模型截面图像投影到液体光敏树脂上,液体树脂遇光硬化后,形成物体的一层。dmd是一个二维的微镜片阵列,每个镜片都可以独立地旋转,根据三维物体的截面图像数据来控制光线的通过与屏蔽,进而形成三维物体一层的图像。当三维物体的一层成型后,工作平台上移,待液体树脂重新填满容器与三维物体的间隙后,dmd将投射下一层的轮廓,如此反复直至三维物体完全成型。由于dlp技术采用动态投影的模型构建方式,dmd芯片要求的输入是高精度的位图,因此在获得截面图形数据后,还需经过栅格化步骤获得截面的栅格图像。因此,通过dlp技术进行3d打印需要额外的栅格化的步骤。
在一个实施例中,步骤s105中的栅格化处理过程是通过扫描线填充算法(scan-linefillalgorithm)进行栅格化。扫描线填充算法是采用奇偶规则(odd-evenrule)进行内外点判断的一种栅格化算法。奇偶规则(odd-evenrule)由于可以处理真实场景中带有自环或自相交等复杂多边形,因此是栅格化过程中应用最广泛的内外点判定规则。应用奇偶规则进行内外点检测的过程是:从像素点p1朝任意方向作一条射线,若该射线与几何图形有奇数个交点,则p1为图形内部点,否则p1为外部点。图5示出了利用奇偶规则进行像素点判断的过程,图中起始于点p1射线与图形有2个交点,因此p1为外部点(在图5所示图形外部),起始于点p2的射线与图形有3个交点,因此p2为内部点(在图5所示图形内部)。
请结合图6,采用扫描线填充算法进行栅格化的步骤包括:
s1,获取截面图形的最高点和最低点的y轴坐标y_max和y_min。
对于切割平面z=zk,(k=0,1,…,m-1)对应的截面图形,gpu获取切割平面z=zk对应的截面图形在xy坐标系(二维坐标系)中的最高点和最低点的y轴坐标y_max和y_min,其中m为总的切片层数(总的切片层数等于切割平面个数)。
那么切割平面z=zk对应的截面图形(第k层图形)的扫描线个数(linerangek)可由下列公式得到:
其中,函数
在一个实施例中,在切片过程中,许多个block共同计算与一个切割平面相交的所有三角面片的交点。为了避免把交点数据拷贝至cpu端,然后依次统计每个截面图形的y_max和y_min,切片过程中的核函数将执行一些额外的操作,用来统计当前block中交点数据的最高点与最低点。之后,通过将每个block中交点的最高点与最低点拷贝至cpu端,进而统计得到每个截面图形的y_max和y_min。以这样的方式,通过少量的内存拷贝得到了每层截面图形的y_max和y_min。
s2,对于在y_min≤y≤y_max之间的每一条扫描线y=s,s∈n,计算图形与扫描线的交点。
对于在y_min≤y≤y_max之间的每一条扫描线y=s,s∈n,计算图形(即切割平面z=zk对应的截面图形)与扫描线的交点。
为了确保每层图形有足够的扫描线条数,栅格化过程所需的总的线程数,即扫描线总数的一个上界totallinenum为:
totallinenum=m×maxlinerange
其中,maxlinerange为切割平面z=zk对应的截面图形中最多的扫描线的数量,m为总的切片层数(即总的切割平面的个数)。
在一个实施例中,栅格化过程中的线程配置与步骤s104中图形处理器进行并行化处理时使用的线程配置类似:
同样的,将所有的栅格化线程(totallinenum)分为一个二维的网格(griddim.x,griddim.y),每个网格中有一个一维的线程块(blockdim.x)。在一个实施例的栅格化过程中,最优的线程块变量blockdim.x采用和切片步骤中的线程块变量相同的选取策略。griddim的第一维(griddim.x)用于处理maxlinerange大于blockdim.x的情况,因此griddim.x可用下面公式表示:
其中,函数
网格的维度变量griddim的第二维(griddime.y)可用下面公式表示:
griddim.y=m
其中,m为总的切片层数(即总的切割平面的个数)。
需要说明的是,尽管栅格化过程和切片过程采用类似的线程配置方案,但切片过程中每个线程只需要判断该线程对应的三角面片与切割平面的位置关系,然后执行相关计算,而栅格化过程中每个线程的需要迭代该截面图形的所有线段,并计算与对应扫描线相交的线段交点,该过程的计算量一般会远大于切片过程中每个线程的计算量。这是由栅格化过程和切片过程涉及的不同的计算任务所决定的。
s3,以一定的属性值填充扫描线上成对交点之间像素。
并行过程将输出所有与扫描线相交的交点数组i。在一个实施例中,由于同一扫描线交点的y轴坐标相同,这里将仅保留交点的x轴坐标。由于每一条扫描线的交点个数是未知的,因此需要为每一条扫描线预留足够的交点空间。假设一条扫描线上最多的交点个数为maxpointnum,则交点坐标数组i占用的总空间|i|为:
其中,|p|表示一个交点p所占用空间大小,linerangek为切割平面z=zk对应的截面图形(第k层图形)的扫描线个数,m为总的切片层数。
在一个实施例中,由于交点坐标暂存在gpu的共享内存中,且一个block可用的共享内存大小仅有48kb,在实际应用中需对blockdim.x和maxpointnum的选择加以权衡,以取得较高的gpu利用率。
s106,中央处理器根据位图数据生成切片截面图像并进行存储
中央处理器根据步骤s105中图形处理器得到的位图数据生成切片截面图像并进行存储。在一个实施例中,中央处理器根据位图数据进行像素填充和切片图片生成。
请结合图7,利用上述方法进行对图7中的6个复杂的模型(模型编号分别为(1),(2),(3),(4),(5),(6))进行切片的效率与传统的只使用cpu进行串行方法计算的效率(20次的平均值)对比表格如下(其中数组b为固定数组):
由此可见,上述方法中通过并行化处理对三维模型进行切片的效率要比传统技术中串行方法的效率有了显著的提高。并且采用图形处理器(graphicsprocessingunit,gpu)来进行并行计算,gpu并行计算通过将应用程序中计算量繁重的并行化部分交给gpu处理,程序的剩余部分依然在cpu上运行,从而可以实现更高的应用程序性能。cpu与gpu是一个强大的组合,在cpu中包含的是专为串行处理而优化的核心,而gpu则由数以千计更小更节能的核心组成,这些核心针对并行处理而进行了优化,程序的串行部分在cpu上运行,而并行部分则在gpu上运行。这样不仅使得编程简单,只需要利用c语言的扩展语言cuda(computeunifieddevicearchitecture)就可以对gpu编程,入门和开发进度都比较快,性价比高,但是却可以取得非常高的加速比,这是集群系统所不能比拟的。
另一方面,本发明还提出一种三维打印装置,包括中央处理器(centralprocessingunit,cpu)和图形处理器(graphicsprocessingunit,gpu),中央处理器用于将待打印的三维模型转化为stl文件并进行存储,stl文件包括三角面片,利用多个切割平面将所述三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中,并将分组完成的三角面片传送给图形处理器;中央处理器还用于接收切片截面数据,并根据切片截面数据生成切片截面图像并进行存储。
图形处理器用于接收中央处理器传送过来的分组完成的三角面片,将分组完成的三角面片进行并行化处理得到切片截面数据,并将切片截面数据传送给中央处理器,切片截面数据是所述切割平面与所述三角面片的交点数据。
上述三维打印装置,三维打印装置包括中央处理器和图形处理器。中央处理器用于将三维模型转化为stl文件并进行存储,所述stl文件包括三角面片;中央处理器用于利用多个切割平面将三角面片进行分组,以使得与同一个切割平面相交的三角面片都在同一组中。图形处理器用于将分组的三角面片进行并行化处理得到切片截面数据,切片截面数据是切割平面与所述三角面片的交点数据。中央处理器用于根据所述切片截面数据生成切片截面图像并进行存储。通过中央处理器利用多个切割平面将三角面片进行分组,再利用图形处理器将分组的三角面片进行并行化处理得到切片截面数据,就可以有效提高三维模型的切片计算效率,进而提高3d打印效率,满足高效率制造需求。
在一个实施例中,图形处理器还用于将分组的三角面片通过双层循环来进行并行化处理得到切片截面数据。
在一个实施例中,图形处理器还用于通过外层循环并行计算不同的切割平面与三角面片的交点,通过内层循环并行计算同一个切割平面和与该同一个切割平面相交的不同的三角面片的交点。
在一个实施例中,所述图形处理器还用于将每一个切割平面和一个三角面片的交点各分配一个线程进行计算。也就是说将每一个切割平面和一个三角面片的交点都分别分配一个线程进行计算。
在一个实施例中,图形处理器还用于对切片截面数据进行栅格化处理得到位图数据,并将所述位图数据传送给中央处理器。
在一个实施例中,中央处理器可以是x86架构,也可以是arm等嵌入式智能终端设备。即上述三维打印装置可以在具备gpu的普通pc机(personalcomputer,个人计算机)上应用,也可以运行在arm等嵌入版和嵌入式gpu组合设备上。
在一个实施例中,采用塔式高性能gpu桌面服务器作为dlp技术stl模型切片过程并行化计算的实验平台。该服务器包含一个主频为2.0ghz的六核intelxeone5-2620处理器,128gddr3ecc内存,并通过pcie16x总线连接一个型号为nvidiatitanxp的gpu。在软件方面,该服务器装有linux核心版本为4.4.0的gnu/linux操作系统以及版本号为375.66的nvidia(英伟达)显卡驱动。该服务器使用gcc4.8.2用于cpu代码编译以及nvidiacuda(cuda,computeunifieddevicearchitecture)8.0用于gpu代码编译。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!