一种基于强化学习的浓密机在线控制方法与流程
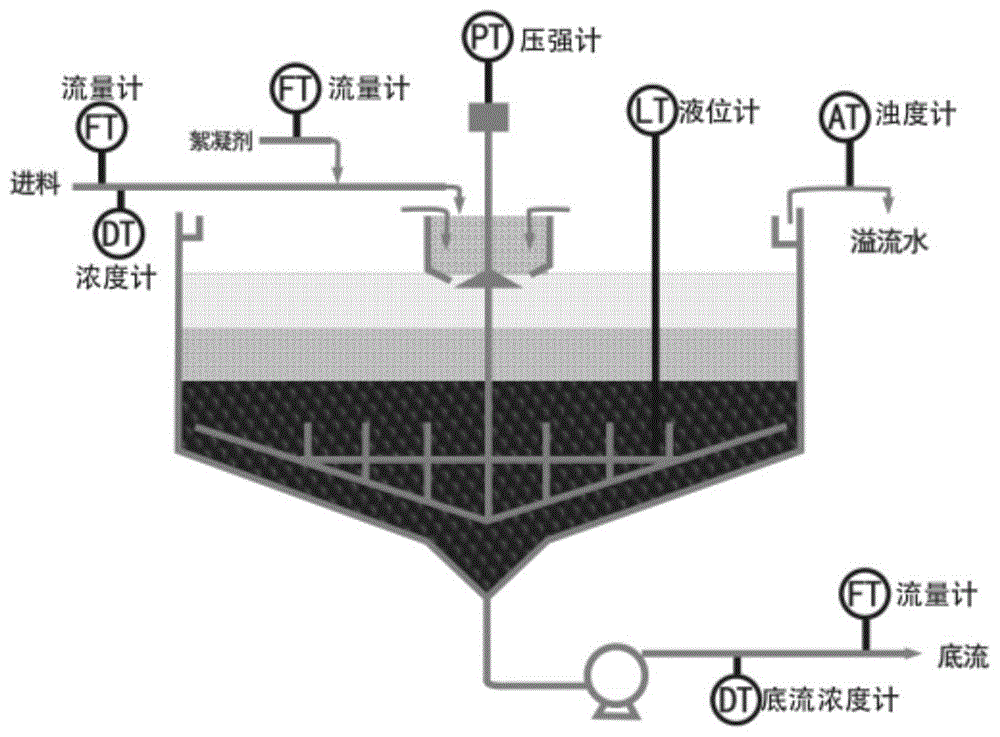
本发明涉及采矿领域,特别是指一种基于强化学习的浓密机在线控制方法。
背景技术:
:在冶金领域等复杂过程工业场景下,浓密机是一个被广泛应用的大型沉降工具,它通过重力沉降作用可以将低浓度的固液混合物进行浓缩形成高浓度的混合物,起到减水、浓缩的作用。在实际生产过程中,由于浓密机运行机理复杂,难以建立数学模型,大部分的控制算法都是基于人工设计的专家系统或手工制定模糊控制器中的规则库,并辅助以传统的比例积分控制手段实现对底流泵速、絮凝剂泵速的控制。此类方法过度依赖人工经验、缺乏自适应性。技术实现要素:本发明要解决的技术问题是提供一种基于强化学习的浓密机在线控制方法,以解决现有技术所存在的难以建立数学模型,浓密机控制方法过度依赖人工经验、缺乏自适应性的问题。为解决上述技术问题,本发明实施例提供一种基于强化学习的浓密机在线控制方法,包括:获取生产过程中所监测到的历史记录数据,所述历史记录数据包括:底流浓度、泥层高度、进料流量、进料浓度、底流泵速以及絮凝剂泵速;建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练;通过训练好的模型网络预测下一时刻的底流浓度和泥层高度,且训练好的评价网络根据预测到的所述下一时刻的底流浓度、泥层高度,估计所述下一时刻的累计代价值,根据估计得到的下一时刻的累计代价值,计算当前时刻的累计代价值,根据得到的当前时刻的累计代价值,利用梯度下降迭代算法确定当前时刻最优控制动作:底流泵速、絮凝剂泵速。进一步地,在建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练之前,所述方法还包括:对获取到的底流浓度、泥层高度、进料流量、进料浓度、底流泵速以及絮凝剂泵速进行归一化放缩,其中,归一化放缩的公式为:其中,z表示获取到的原始参量值,参量为底流浓度、泥层高度、进料流量、进料浓度、底流泵速或絮凝剂泵速;表示归一化放缩后的参量值;zmin表示参量z的最小值;zmax表示参量z的最大值。进一步地,模型网络表示为:其中,k为采样时间;分别表示模型网络预测的k+1时刻的底流浓度、泥层高度;wm1和wm2都表示模型网络的权重;tanh为激活函数;分别表示归一化放缩后的底流浓度、泥层高度、进料流量、进料浓度、底流泵速、絮凝剂泵速;表示归一化放缩后的控制动作;上标t表示矩阵转置。进一步地,在训练模型网络的过程中调整权重wm1和wm2,当模型网络的损失函数的值收敛到第一预设值,则表明模型网络训练完成,其中,模型网络的损失函数表示为:其中,em(k)表示模型网络的损失函数;em(k)为简写形式,分别表示实际的k+1时刻的底流浓度、泥层高度。进一步地,在训练模型网络的过程中,采用梯度下降法来调节权值,表示为:其中,lm表示学习率,i表示第i个权重。进一步地,评价网络表示为:其中,表示累计代价函数值;wc1和wc2都表示评价网络的权重。进一步地,在训练评价网络的过程中,使用基于经验回放技术的损失函数训练评价网络,当评价网络的损失函数的值收敛到第二预设值,则表明评价网络训练完成,其中,评价网络的损失函数表示为:其中,ec(k)表示评价网络的损失函数;l表示回放点数;u()表示效用函数;γ表示折扣因子。进一步地,在训练评价网络的过程中,采用梯度下降法来调节权值,表示为:其中,lc表示学习率,i表示第i个权重。进一步地,所述通过训练好的模型网络预测下一时刻的底流浓度和泥层高度,且训练好的评价网络根据预测到的所述下一时刻的底流浓度、泥层高度,估计所述下一时刻的累计代价值,根据估计得到的下一时刻的累计代价值,计算当前时刻的累计代价值,根据得到的当前时刻的累计代价值,利用梯度下降迭代算法确定当前时刻最优控制动作:底流泵速、絮凝剂泵速包括:a1,随机选取控制动作初始化j=0;a2,通过训练好的模型网络,预测下一时刻的底流浓度、泥层高度:其中,k为采样时间,即:当前时刻;k+1为下一时刻;a3,已训练好的评价网络,根据预测到的下一时刻的底流浓度、泥层高度,估计下一时刻的累计代价值:其中,a4,根据估计得到的下一时刻的累计代价值,计算当前k时刻的累计代价值:其中,表示第j次迭代得到的控制动作a5,根据得到的当前k时刻的累计代价值,利用梯度下降算法对进行更新:其中,lu为学习率;a6,j=j+1;a7,返回执行步骤a1-a6,直到的变化值小于预设的第三阈值,或者当前的迭代次数大于预设的最大迭代次数,此时的为最优控制动作:底流泵速、絮凝剂泵速。a8,对进行反归一化,得到最终的最优控制动作u:其中,⊙表示按位乘,umax、umin、umid分别表示控制动作的上限、下限、上限与下限的均值。进一步地,在建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练之后,所述方法还包括:获取实际充填过程中所监测到的实时监测数据;利用所述实时监测数据对评价网络进行学习训练;或,在建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练之后,所述方法还包括:建立浓密机仿真模型;使用建立好的浓密机仿真模型验证所述控制模型的有效性。本发明的上述技术方案的有益效果如下:上述方案中,获取生产过程中所监测到的历史记录数据,所述历史记录数据包括:底流浓度、泥层高度、进料流量、进料浓度、底流泵速以及絮凝剂泵速;建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练;通过训练好的模型网络预测下一时刻的底流浓度和泥层高度,且训练好的评价网络根据预测到的所述下一时刻的底流浓度、泥层高度,估计所述下一时刻的累计代价值,根据估计得到的下一时刻的累计代价值,计算当前时刻的累计代价值,根据得到的当前时刻的累计代价值,利用梯度下降迭代算法确定当前时刻最优控制动作:底流泵速、絮凝剂泵速。这样的控制模型不仅具有自适应、不依赖于精确数学模型的特点,同时相比较已有的自适应动态规划算法,该控制模型在双网结构中去掉了动作网络,直接采用梯度下降迭代算法求解控制动作,有着更少的时间消耗和更高的控制精度,且结构简单。附图说明图1为本发明实施例提供的浓密机系统的结构示意图;图2为本发明实施例提供的基于强化学习的浓密机在线控制方法的流程示意图;图3为本发明实施例提供的基于强化学习的浓密机在线控制方法的详细流程示意图;图4为本发明实施例提供的模型网络的结构示意图;图5为本发明实施例提供的噪音量变化曲线示意图一;图6(a)、(b)分别为本发明实施例提供的hcnvi与其他adp算法的底流浓度、效用值对比示意图;图7(a)、(b)分别为本发明实施例提供的在hdp算法、hcnvi算法中引入经验回放对效用值的影响示意图;图8为本发明实施例提供的hdp与hcnvi在时间消耗上的对比示意图一;图9为本发明实施例提供的噪音量变化曲线示意图二;图10(a)、(b)分别为本发明实施例提供的hcnvi与其他adp算法在波动噪声输入下的底流浓度、效用值对比示意图;图11(a)、(b)为本发明实施例提供的噪音持续变化下经验回放对hcnvi的底流浓度、效用值影响示意图;图12为本发明实施例提供的hdp与hcnvi在时间消耗上的对比示意图二。具体实施方式为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。本发明针对现有的难以建立数学模型,浓密机控制方法过度依赖人工经验、缺乏自适应性的问题,提供一种基于强化学习的浓密机在线控制方法。为了更好地理解本发明实施例所述的基于强化学习的浓密机在线控制方法,参考图1,先对浓密机系统运行过程进行简要说明:浓密机在采矿领域是重要的沉降分离设备,上游工段会产生浓度、流量不断波动的低浓度料浆。利用泥沙颗粒的密度大于水的特性以及絮凝剂的絮凝作用,砂粒会不断沉降并在浓密机底部形成高浓度的底流,在底流泵的压力作用下被吸入输送管道。对于浓密沉降过程的性能进行评价,其核心控制指标为底流浓度y(k)。该因素受控制输入、系统状态参量、及其他外部噪音影响,其中,控制输入u(k)为底流泵速u1(k)以及絮凝剂泵速u2(k),其中,k为采样时间,系统状态参量为底流浓度y(k)和泥层高度h(k),进料流量c1(k)、进料浓度c2(k)为外部噪音输入c(k),这是由于在部分工业场景中,上游工序产生的物料浓度、物料流量是不可控的,为了使本发明提出的浓密机控制模型具有通用性,因此将进料状态(进料流量c1(k)、进料浓度c2(k))作为噪音输入量。根据上述定义,其中为可控制输入量,为实数,为不可控但是可观测的噪音量,为系统状态量,该参量是表征当前浓密机状态的重要参量,它可被间接控制但不作为控制目标。在工业领域中,浓密机进料颗粒大小,进料成分都会对浓密机底流浓度产生影响。不过由于此类变量无法观测且波动较小,为了简化问题,假定其保持恒定的。浓密机系统可表述为一个未知非线性系统:[y(k+1),h(k+1)]t=f(y(k),u(k),c(k),h(k))(1)其中,y(k)表示底流浓度,f(·)为非线性未知函数,k为采样时间。对于式(1),智能控制的首要目标是使底流浓度y(k),追踪其设定的理想值y*。另外,为了保证浓密机系统运行安全与仪器寿命,控制输入必须满足一定的限制条件。综合上述指标因素,可以将浓密机控制问题转化为有约束的最优化问题:其中,j(k)表示累计代价值函数,是一种评价值函数;u(k)表示效用函数;j(k)代表在当前状态y(k)下,执行控制输入u(k)需要承受的代价;γ∈(0,1]是折扣因子,代表系统短期控制过程中产生的惩罚值在累计惩罚项所占比重;q>0,是一个实验参数,用于平衡(y(k)-y*)2和的比重;r是对称正定矩阵,uimin,uimax分别表示ui(k)的下限和上限,u1(k)以及絮凝剂泵速u2(k)的下限统称为:umin,上限统称为:式(2)可以表示为式(4)贝尔曼方程的形式:根据贝尔曼最优原则,第k时刻的最优评价值函数j*(k)满足离散哈密顿-雅可比-贝尔曼方程:第k时刻,最优的控制输入u*(k)可以表示为:基于式(5)、公式(6),提出一种启发式评价网络值迭代算法(hcnvi),该算法能根据浓密机系统生产过程中产生的实时监测数据x(k)进行在线学习,并产生满足ωu={u:umin≤u≤umax}约束的控制输入量u(k),且最小化j(k)。实施例一如图2所示,本发明实施例提供的基于强化学习的浓密机在线控制方法s101,获取生产过程中所监测到的历史记录数据,所述历史记录数据包括:底流浓度、泥层高度、进料流量、进料浓度、底流泵速以及絮凝剂泵速;s102,建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练;s103,通过训练好的模型网络预测下一时刻的底流浓度和泥层高度,且训练好的评价网络根据预测到的所述下一时刻的底流浓度、泥层高度,估计所述下一时刻的累计代价值,根据估计得到的下一时刻的累计代价值,计算当前时刻的累计代价值,根据得到的当前时刻的累计代价值,利用梯度下降迭代算法确定当前时刻最优控制动作:底流泵速、絮凝剂泵速。本发明实施例所述的基于强化学习的浓密机在线控制方法,获取生产过程中所监测到的历史记录数据,所述历史记录数据包括:底流浓度、泥层高度、进料流量、进料浓度、底流泵速以及絮凝剂泵速;建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练;通过训练好的模型网络预测下一时刻的底流浓度和泥层高度,且训练好的评价网络根据预测到的所述下一时刻的底流浓度、泥层高度,估计所述下一时刻的累计代价值,根据估计得到的下一时刻的累计代价值,计算当前时刻的累计代价值,根据得到的当前时刻的累计代价值,利用梯度下降迭代算法确定当前时刻最优控制动作:底流泵速、絮凝剂泵速。这样的控制模型不仅具有自适应、不依赖于精确数学模型的特点,同时相比较已有的自适应动态规划算法,该控制模型在双网结构中去掉了动作网络,直接采用梯度下降迭代算法求解控制动作,有着更少的时间消耗和更高的控制精度,且结构简单。本实施例中所述的基于强化学习的浓密机在线控制方法是一种新的自适应动态规划(adp)算法,所述方法是在传统启发式动态规划(hdp)算法的基础上,建立由模型网络和评价网络组成的双网结构的控制模型,可以称为启发式评价网络值迭代算法(hcnvi),所述方法利用评价网络与模型网络分别近似累计代价函数和对浓密机生产过程进行建模与预测,所述方法不依赖于精确的数学模型,并采用梯度下降迭代算法求解式(6),实现对浓密机底流泵速和絮凝剂泵速的稳定控制,因此可以有效实现对浓密机等大型过程工业设备的控制。为了更好地理解本发明实施例所述的一种基于强化学习的浓密机在线控制方法,对其进行详细说明,如图3所示,具体可以包括以下步骤:步骤(1)数据获取及预处理:获取实际生产过程中各种传感器所监测到的历史记录数据,并对其进行预处理,具体可以包括以下步骤:步骤(1-1)数据获取获取实际充填过程中各种传感器所监测到的历史记录数据,其中,历史记录数据用于模型网络和评价网络的最初训练,模型网络的训练全部离线进行,在控制任务开始后,将不再对模型网络进行调整。另需要说明的是:在浓密机系统稳定运行时,还需获取实际充填过程中各种传感器所监测到的实时监测数据,并采用在线学习的方式,用实时监测数据对评价网络进行学习训练。本实施例中,获取数据主要可以包括以下步骤:步骤(1-1-1)获取实际充填过程中各种传感器所监测到的历史记录数据,假设,本实施例中的历史记录数据,由矿山的自动化系统记录并存储于企业数据库中,通过使用opc服务器将企业数据中的数据进行导出,保存在本地。数据记录跨度为1个月,总数据记录约1万余条,记录间隔为1分钟。历史记录数据的属性有底流泵速u1(k)、絮凝剂泵速u2(k)、泥层高度h(k)、进料流量c1(k),进料浓度c2(k)以及底流浓度y(k)。定义x(k)=[y(k),h(k),c(k)]t,上标t表示矩阵转置。步骤(1-1-2):浓密机系统稳定运行后,将浓密机系统产生的实时监测数据通过opc服务器实时传送到控制模型中进行评价网络的在线学习与实时控制。由于本实施例是通过浓密机仿真模型来验证控制模型的有效性,所以在本实施例中,用于在线学习的实时监测数据为仿真模型在运行过程中所产生的数据,也就是说,是将浓密机仿真模型产生的数据实时传送到控制模型中进行评价网络的在线学习与实时控制。步骤(1-2)数据预处理由于不同物理量的取值差异很大,这会导致网络无法有效学习并且造成超参数设定困难。因此需要统计由浓密机产生的数据中各参量的极值,对所有数据利用下式进行归一化放缩。式(7)中,表示归一化放缩后的参量值,z表示获取到的原始参量值,zmin表示参量z的最小值,zmax表示参量z的最大值,参量为底流浓度、泥层高度、进料流量、进料浓度、底流泵速或絮凝剂泵速。例如,对于底流浓度y(k),进行归一化放缩后的底流浓度值为:其它参量同理。则得到预处理后的数据属性为:底流泵速絮凝剂泵速泥层高度进料流量进料浓度以及底流浓度预处理后的x(k)表示为预处理后的u(k)表示为步骤(2)建立控制模型建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练。需要说明的是:图3中的经验数据就是历史记录数据,本实施例将历史记录数据暂存,在训练模型时批量取出用于控制模型更新,其中,模型网络训练过程是离线进行的,不需要使用经验回放,模型网络在图中只起到预测和的作用。本实施例中,所述建立由模型网络和评价网络组成的双网结构的控制模型,并利用获取到的历史记录数据对所述模型网络和评价网络进行训练,具体可以包括以下步骤:步骤(2-1)建立模型网络建立模型网络用来对浓密机生产过程进行建模,即根据当前系统状态、外部噪音量、控制输入、预测下一时刻底流浓度和泥层高度变化。模型网络的训练全部离线进行,在控制任务开始后,将不再对模型网络进行调整。主要包括以下步骤:步骤(2-1-1)模型网络的自变量为因变量为下一时刻的底流浓度和泥层高度初始化模型网络的网络参数,设置网络的学习率为lm=0.01,批训练的数据个数predict_batch_size=32;步骤(2-1-2)构造一个3层神经网络结构的模型网络,其基本结构如图4所示,模型网络可以表示为:其中,分别表示模型网络预测的k+1时刻的底流浓度、泥层高度;wm1和wm2都表示模型网络的权重并且均初始化为0~1之间的随机数;tanh为激活函数;且模型网络的输入层包含6个节点,隐含层包含20个节点,输出层包含2个节点。步骤(2-1-3)确定模型网络的损失函数,训练模型网络;其中,模型网络的损失函数表示为:其中,em(k)表示模型网络的损失函数;em(k)为简写形式,分别表示实际的k+1时刻的底流浓度、泥层高度。步骤(2-1-4)设置训练次数predict_epoch=50,使用adam(adaptivemomentestimation,自适应矩估计)优化器作为神经网络的优化器,并采用梯度下降法来调节权重wm1和wm2,如式(11)所示,当模型网络的损失函数的值收敛到第一预设值,例如,0.08,则表明模型网络已训练完成。其中,lm表示学习率;i表示第i个权重,i的取值为1、2。步骤(2-2)建立评价网络评价网络用于对累积代价函数进行近似。在训练评价网络时,将短期内的监测数据共同用于评价网络的训练,主要包含以下步骤:步骤(2-2-1)评价网络的自变量为因变量为累计代价值。初始化模型网络的网络参数,设置网络的学习率为lc=0.01,批训练的数据个数batch_size=1;步骤(2-2-2)构造一个3层神经网络结构的评价网络,评价网络表示为:其中,表示累计代价函数值;wc1和wc2都表示评价网络的权重且均初始化为0~1之间的随机数;tanh为激活函数,评价网络的输入层包含4个节点,隐含层包含14个节点,输出层为1个节点。步骤(2-2-3)确定损失函数,训练评价网络。本实施例中,使用时序差分误差作为评价网络的损失函数,损失函数表示为:其中,ec(k)表示评价网络的损失函数;u()表示效用函数;γ表示折扣因子。本实施例中,由于浓密机具有运行缓慢、状态迁移滞后的特点,为了维持评价网络的局部梯度差异以增强控制模型的收敛速度,在训练评价网络的过程中,本实施例利用经验回放技术以对短期内的监测数据进行回放训练,以增加评价网络训练的准确性和收敛速度,且增强了收敛稳定性。本实施例中,经验回放方法将式(13)所述的损失函数修改为式(14),得到基于经验回放技术的损失函数:其中,l表示回放点数,一般设置为2。步骤(2-2-4)设置训练次数nc=500,使用adam优化器作为神经网络的优化器,并采用梯度下降法来调节权重wc1和wc2,如式(15)所示,当评价网络的损失函数的值收敛到第二预设值∈c,例如,∈c=0.001,则表明评价网络已训练完成。其中,lc表示学习率;i表示第i个权重,i的取值为1、2;由于浓密机所处环境的外界噪音是不断波动的,lc需设定为固定值以保持学习能力。步骤(3)利用梯度下降算法计算控制动作通过输入第k时刻(当前时刻)的底流浓度、泥层高度、进料流量、进料浓度、底流泵速或絮凝剂泵速,得到第k时刻的最优控制动作输出:底流泵速、絮凝剂泵速;主要包含以下步骤:步骤(3-1)随机选取控制动作初始化j=0;;步骤(3-2)预测下一(k+1)时刻的系统状态:其中,k为采样时间,即:当前时刻;k+1为下一时刻;步骤(3-3)已训练好的评价网络,根据预测到的下一时刻的底流浓度、泥层高度,估计下一时刻的累计代价值:其中,需要说明的是:由于真实工业环境下进料噪音都是连续变化的,很少出现突变,因此本实施例采用当前时刻噪音c(k)来充当下一时刻噪音c(k+1);步骤(3-4)根据估计得到的k+1时刻的累计代价值,计算当前k时刻的累计代价值:其中,表示第j次迭代得到的控制动作步骤(3-5)根据得到的当前k时刻的累计代价值,利用梯度下降算法对进行更新:其中,lu为学习率,设置为0.4,令j=j+1;步骤(3-6)一直循环步骤(3-2)、(3-3)、(3-4)、(3-5),直到u的变化值小于预设的第三阈值∈a,例如,∈a=0.0001,或者当前迭代的次数j大于最大迭代次数na(例如,4000),此时的为最优控制动作;步骤(3-7)对进行反归一化,得到最终的最优控制动作u:其中,⊙表示按位乘,umax、umin、umid分别表示控制动作的上限、下限、上限与下限的均值。步骤(4)建立浓密机仿真模型,并使用建立好的浓密机仿真模型验证本发明提出的控制模型的有效性。由于在真实工业场景下进行浓密机控制实验成本较高,本发明采用浓密机仿真模型验证所提出控制模型的有效性,主要包括以下步骤:步骤(4-1)根据已有的理论知识建立浓密机仿真模型,该浓密机仿真模型建立在四个假设基础上:(a)进料都是球形颗粒;(b)絮凝剂在浓密机的静态混合器中作用完全;(c)流体的扩散以固液混合物形式进行;(d)忽略颗粒间相互作用、浓密机中把机中轴的影响,主要包含以下步骤:步骤(4-1-1)确定仿真模型推导中出现的变量,如表1,表2,表3所示:表1仿真模型常量变量含义量纲参考值ρs干砂密度kg/m34150ρe介质表观密度kg/m31803μe悬浮体系的表观粘度pa·s1d0进料颗粒直径m0.00008p平均浓度系数无0.5a浓密机横截面积m2300.5ks絮凝剂作用系数s/m20.157ki压缩层浓度系数m3/s0.0005*3600ki进料流量与进料泵频的系数m3/r50/3600ku底流流量与底流泵频的系数m3/r2/3600kf絮凝剂流量与絮凝剂泵频的系数m3/r0.75/3600θ压缩时间s2300表2参量定义变量含义量纲初始值补充说明fi(t)进料泵频hz40扰动量fu(t)底流泵频hz85控制量ff(t)絮凝剂泵频hz40控制量ci(t)进料浓度kg/m373扰动量h(t)泥层高度m1.48状态量cu(t)底流浓度kg/m3680目标量表3部分变量计算方法步骤(4-1-2)根据已有的理论知识,进行仿真模型推导。首先可得泥层高度与泥层内平均单位体积含固量之间的关系:根据固体守恒定律,泥层内固体质量变化量等于由进料导致泥层内固体量增加量与底流导致泥层内固体减少量的差,因此可以建立泥层内平均单位体积含固量与粒子沉降速度的关系:对上式做变形得到下式:联立式(19)、式(17),可得泥层高度h(t)与底流浓度cu(t)的一阶变化率:在这个仿真模型中,絮凝剂泵速ff和底流泵速fu是控制输入u=[fu,ff]t,进料泵速fi和进料浓度ci是外部干扰量c=[fi,ci]t,底流浓度cu为系统追踪变量y=cu。理想的控制系统能够在外界干扰量c不断波动下,通过在合理范围内调节u,驱使y追踪其设定值y*。根据真实生产数据对变量取值范围进行限制,umin=[40,30],umax=[120,50],hmin=0.75,hmax=2.8,ymin=280,ymax=1200,cmin=[40,30],cmax=[120,50],y*=680。步骤(4-2)使用建立好的浓密机仿真模型验证本发明提出的控制模型的有效性。主要在两种类型噪音量c(k)输入下,展示本发明提出的控制模型的控制效果,并与其他adp算法,主要包括hdp、双启发式动态规划(dualheuristicprogramming,dhp)、穿插学习策略迭代(interleavedlearningpolicyiteration,ilpl)进行比较。主要包含以下步骤:步骤(4-2-1):恒定-阶跃型噪音输入下浓密机控制仿真实验:第一个实验首先设置干扰量输入c为恒定值,并在某一时刻为其增加阶跃突变,噪音输入量如图5所示。该实验用来验证控制模型能否在浓密机处于非最优态下,快速寻找到u*,使被控模型达到理想收敛稳态。主要包含以下步骤:步骤(4-2-1-1):在这个仿真实验中设置控制器参数如下:迭代轮次t=270,仿真步长td=12min,q=0.004,γ=0.6,na=4000,nc=500,∈c=0.001,∈a=0.0001,lm=0.01,lc=0.01,lu=0.4。控制效果如图6所示,其中hdp、dhp算法也使用经验回放,回放点数为2。实验中hdp、ilpl、hcnvi的评价网络结构相同,且网络参数初始化为相同数值。根据实验结果可以发现,对于不同控制算法,由于网络参数初始值均为随机设定值,训练初期底流浓度有较大幅度的波动,且在设定值两侧持续震荡。随着各个控制模型的学习,系统状态与网络参数不断趋于平稳,直到某一时刻,底流浓度开始稳定并与设定值重合,且不再产生波动,此时控制模型参数也不再发生变化,被控系统和控制模型同时收敛到最优态。从效用值变化曲线也可以看出,早期由于底流浓度与其设定值偏差较大,效用值较高,但是随着模型与系统趋于稳态,u(k)不断缩减直到接近于0的位置。到达270分钟时,系统进料浓度、进料流量发生突变,底流浓度无法维持稳态,开始远离设定值。控制模型根据噪音量改变后的系统所产生的轨迹数据重新训练,将底流浓度拉回设定值位置。由于在第一阶段控制模型已经到达过一次稳态,在第二阶段仅需要较少的迭代次数就可以使系统重归理想收敛稳态。通过观察不同控制算法产生的系统轨迹,可以发现不同控制算法到达最优态所需的时间有较大差别,且在收敛到最优态的过程中,底流浓度的波动也有较大差异。在实验第一阶段,为使系统达到稳态,hcnvi算法所需要的迭代次数更少,训练过程中产生的底流浓度振幅也更小。并且在噪音量改变后,hcnvi算法可以迅速地使模型重归最优态,且底流浓度几乎未发生大幅度波动。步骤(4-2-1-2)为了验证经验回放技术对控制算法性能的影响,本发明分别对比了无经验回放、经验回放数量为2的情况下,hdp、hcnvi的控制性能。对比结果如图7所示。在本实验中,仅比较了两种算法的效用值变化,效用值越快地收敛到0说明算法控制效果越佳。通过观察图7(a)和图7(b)中无经验回放情况下的效用值变化曲线,可以发现曲线波动较大,相比于使用短期经验回放,无经验回放情况下控制模型需要更多的迭代轮次才能够使系统达到收敛。特别是在图7(b)的hcnvi的实验中,270分钟时系统噪音输入量改变,效用值开始剧增,底流浓度开始偏离设定值,被控系统几乎无法收敛,但在增加了经验数据回放后效用函数值可以快速收敛至最低点。该实验结果表明经验回放技术无论对hdp算法还是hcnvi算法都有很好的促进作用。对于在线学习的控制算法,增加对短期历史数据点的经验回放可以通过维护局部梯度准确性,有效地指导评价网络学习正确的评价值,增强模型的收敛能力。步骤(4-2-1-3)本文进行了十组实验来对比hcnvi算法在时间上的优势。选取hdp算法作为参考对象,t=270,结果如图8所示。由于每次实验中网络初始值不同,系统运行轨迹以及模型训练过程也不同,因此每组实验中模型学习以及控制所需的累积时间略有差异。但是从多次实验结果可以看出,由于hcnvi算法中去掉了动作网络,仅需要训练评价网络,所以模型整体训练时间大大缩减,尽管hcnvi算法中计算控制输入所需时间相比于hdp算法直接利用动作网络前向传播求解控制动作所需时间长,但是hcnvi算法总消耗时间明显少于hdp算法。步骤(4-2-2)高斯噪音波动输入下浓密机控制仿真实验。真实工业场景下,浓密机的进料浓度和流量是实时波动的。步骤(4-2-1)中仿真模型的进料状态是基本恒定的,只在某一时刻产生突变,其目的是为了更好地观察不同控制算法的收敛速度。在步骤(4-2-2)实验中,进料流量和进料浓度两个噪音量存在持续波动,用来模仿真实工业场景。噪音输入的单步变化量服从高斯分布:c(k+1)=c(k)+δcδc~n(μ=0,∑=diag(0.6,0.6))(26)本实施例中,进料波动变化如图9所示。步骤(4-2-2-1)hcnvi控制器参数与步骤(4-2-1-1)相同,迭代轮次t=270,仿真步长td=120s。利用该仿真模型再次对比hcnvi与其他算法控制性能的差异,结果如图10(a)、(b)所示。通过观察实验结果发现在环境噪音连续变化条件下,浓密机底流浓度会发生持续震荡。随着对模型参数的不断训练,各个算法的控制性能趋于平稳,由于进料噪音导致的底流浓度波动稍有减弱。对比不同控制算法的控制性能,可以发现hcnvi相比于其他adp算法,能够更快地将底流浓度锁定在设定值临域范围内,且浓度振幅小于其他adp算法。从效用值变化曲线也可以看出,相比于其他算法,hcnvi算法的效用值整体较小,且在训练后期几乎0。步骤(4-2-2-2)进一步分析不同控制算法之间的性能。表4给出了不同算法在恒定-阶跃型噪音输入下步骤(4-2-1-1)实验(称为:实验一)和高斯噪音波动输入下步骤(4-2-2-1)实验(称为:实验二)中底流浓度控制性能指标对比结果。相比其他算法,hcnvi算法可以更好地控制底流浓度稳定在其设定值附近,其控制总体稳定性(由mse、iae体现)、控制鲁棒性(由mae体现)更佳。在过程工业控制场景中,控制系统的mae指标尤为重要,某一工序的物料性质发生剧烈波动会使下游物料加工工序出现连带波动,严重影响生产的稳定性和最终产品的质量。hcnvi算法在mae指标上的优势证实了其在过程工业控制问题中的适用性。表4不同控制算法之间性能分析步骤(4-2-2-3)在噪音持续变化下,算法中引入经验回放技术对于控制性能的改善也是很明显的。图11(a)、(b)对比了在hcnvi算法中,不使用经验回放和设置经验回放数量为2两种情况下的模型控制模型性能。实验结果表明,经验回放技术在环境噪音持续变化下仍对模型收敛速度有重要促进作用。步骤(4-2-2-4)再次对比了在噪音持续变化下,两个算法在时间消耗上的差异性。本发明中仍然重复十次实验,每次实验的迭代轮次为270轮。实验结果如图12所示,在噪音持续变化环境下,hcnvi算法在时间消耗上的优势稍有削减,这是由于当环境存在持续外部扰动时,评价网络的参数也伴随着持续波动,每轮迭代中评价网络训练的时间增加,而这一部分的时间损耗在hcnvi和hdp中是共有的,因此使得hcnvi算法在整体时间消耗的优势减少,但总时间消耗仍少于hdp算法。以上所述是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1