一种基于深度学习技术的土壤近红外光谱分析预测方法与流程
本发明涉及数据分析处理技术领域,具体来说是一种基于深度学习技术的土壤近红外光谱分析预测方法。
背景技术:
我国大部分农田面临成分不足、土壤退化严重的问题,需要改造的中低产田面积大、分布广,了解并掌握农田土壤成分信息有着十分现实和迫切的需求,但想要完全掌握农田成分信息又十分困难,其存在多方面的原因。由于农田成分含量是变化的,从长期看,土壤成分分布是一个动态过程,导致土壤成分的丰缺和分布不均匀。如何利用现代科技手段及时准确获取土壤成分含量信息,制定合理的施肥策略,保证农业正常生产以及保护环境和提高作物产量具有特别重要的现实意义。可见近红外光谱(350-2500nm)检测技术具有检测速度快、多指标同时测定、无污染、成本低和操作简单等优点。可见近红外光谱分析技术能在几分钟内就能获取待测样品中多种成分含量信息,这一点是传统化学方法检测所达不到的,多种组分同时测量,检测过程中也不需要添加任何试剂,不会对环境造成二次污染,是一种检测速度快、无损、无污染和实时的检测分析技术,将近红外光谱分析技术应用于土壤成分检测领域具有十分重要的现实意义。因此利用近红外光谱分析技术实现对土壤成分的综合数据分析已经成为急需解决的技术问题。
技术实现要素:
本发明的目的是为了解决现有技术中无法对土壤成分进行大批量综合分析的缺陷,提供一种基于深度学习技术的土壤近红外光谱分析预测方法来解决上述问题。
为了实现上述目的,本发明的技术方案如下:
一种基于深度学习技术的土壤近红外光谱分析预测方法,包括以下步骤:
训练样本的获取和预处理,使用光谱仪获取训练样本土壤集的光谱数据,对获取的光谱数据进行预处理,得到若干个训练样本;
构造基于深度学习的预测模型;
测试样本的获取和预处理;使用光谱仪获取测试土壤样本的光谱数据,对测试样本土壤扫描40次取平均值;对测试样本土壤采用与训练样本相同的光谱数据预处理方法,得到测试土壤样本;
将预处理过的测试样本的光谱数据输入构造的预测模型,完成对测试样本土壤成分含量的分析预测;将测试土壤样本采用梅尔域的滤波带系数作为参数,变成二维特征输入训练好的卷积神经网络进行土壤成分含量的分析预测。
所述的训练样本的获取和预处理包括以下步骤:
在密封的暗室环境中使用光谱仪获取不同训练土壤样本集的光谱数据,对各训练样本土壤分别扫描40次取平均值;
对光谱数据进行平滑处理;
对光谱数据进行多元散射校正处理;
对光谱数据进行归一化处理;
构成训练土壤样本集。
所述的构造基于深度学习的预测模型包括以下步骤:
将训练土壤样本的光谱信号看作二维特征输入,将波数构成的特征作为第一维特征,将频域构成的特征作为第二维特征;在频域维度上采用梅尔域的滤波带系数作为参数,选择N个滤波频带,按照土壤成分含量设定标签,把预处理好的训练样本土壤集随机排序后输入卷积神经网络;
采用反向传播方法对整个网络进行全局训练,优化网络参数;误差反向传播算法进行反向传播,反向更新权值和卷积核,从而得到训练好的卷积神经网络。
所述的对光谱数据进行平滑处理为Savitzky-Golay卷积平滑法,其包括以下步骤:
通过采用最小二乘拟合系数建立滤波函数,对移动窗口内的波长点数据进行多项式最小二乘拟合,二项式拟合的表达式如下:
式中为Savitzky-Golay卷积平滑算法建立二次拟合曲线后中心点位置得到的拟合值,a0,a1,a2是二项方程式系数;
待定二项方程式系数求解过程采用最小二乘法,如下所示:
令并联立求解方程组可得到二项式系数。
所述的对光谱数据进行多元散射校正处理包括以下步骤:
把整个未知试样的光谱A(λ)变换成假想的基准粒度的光谱A0(λ),根据最小二乘法指定α和β的值,设定两个因子的推定值分别为α'和β',由公式A(λ)=a0A0(λ)+β+e(λ)可得到以下变换式:
A0(λ)=[A(λ)-β']/α';
获取α'和β'的光谱数据,使用所有土壤样本的平均光谱,如下所示:
线性回归方程为:
Ai表示第i个样本的光谱,A为建模集光谱数据,通过最小二乘回归求得α和β。
所述的对光谱数据进行归一化处理为矢量归一化方法,其方法如下:
取一条光谱,其数据表达为x(1*m),其矢量归一化算法公式为:
其中m为波长数,i=1,2,...,n,矢量归一化算法常被用于校正由微小光程差异而引起的光谱变化。
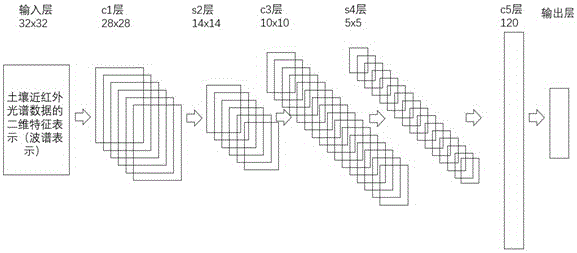
所述的卷积神经网络为采用基于LeNet-5模型改进的卷积神经网络,其向前传播阶段包括以下步骤:
第一个特征提取阶段,输入层-c1层-s2层;输入训练土壤样本的光谱数据的二维波谱表示,经过5*5大小的卷积核运算,再经过子采样处理,缩放为原来的1/2;
第二个特征提取阶段,s2层-s4层;
输入s2层的二维光谱特征数据经过5*5的卷积核运算,再经过子采样处理,缩放为原来的1/2;
第三个特征提取阶段,s4层-c5层;
网络层c5为由120个特征图组成的卷积层,每个神经元与s4网络层的所有特征图的5*5大小的邻域相连接;
分析预测,c5层-输出层;
c5层到输出层采用全连接的方式,使用c5层的120维向量进行预测分类。
有益效果
本发明的一种基于深度学习技术的土壤近红外光谱分析预测方法,与现有技术相比基于卷积神经网络的结构模型来进行土壤近红外光谱分析预测,提高了近红外光谱土壤主要成分预测的精度和模型的鲁棒性。本发明中卷积神经网络拥有更加优异的特征表达能力,其特征提取和模式分类同时进行,并且一个计算层由多个特征图组成,可以学习不同的特征组合,并可通过増加和减少特征图的数量对网络进行优化。
附图说明
图1为本发明的方法流程图;
图2为本发明中LeNet-5模型改进的卷积神经网络的网络结构图。
具体实施方式
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
如图1所示,本发明所述的一种基于深度学习技术的土壤近红外光谱分析预测方法,包括以下步骤:
第一步,训练样本的获取和预处理。使用光谱仪获取训练样本土壤集的光谱数据,对获取的光谱数据进行预处理,得到若干个训练样本。其具体包括以下步骤:
(1)在密封的暗室环境中使用光谱仪获取不同训练土壤样本集的光谱数据,对各训练样本土壤分别扫描40次取平均值。采用ASD公司的FieldSpec Pro FR光谱仪获取不同训练土壤样本集的光谱数据,为了避免在测量过程中由于自然光造成的影响,整个光谱检测是在密封的暗室内进行的,对各训练样本土壤分别扫描40次取平均值。
(2)对光谱数据进行平滑处理,光谱平滑预处理的目标是去除随机高频误差在光谱分析中常用的平滑方法有Savitzky-Golay卷积平滑,Savitzky-Golay卷积平滑算法在对原始光谱进行处理时,不再使用简单的平均,通过采用最小二乘拟合系数建立滤波函数,对移动窗口内的波长点数据进行多项式最小二乘拟合。其包括以下步骤:
A、通过采用最小二乘拟合系数建立滤波函数,对移动窗口内的波长点数据进行多项式最小二乘拟合,二项式拟合的表达式如下:
式中为Savitzky-Golay卷积平滑算法建立二次拟合曲线后中心点位置得到的拟合值,a0,a1,a2是二项方程式系数。
B、待定二项方程式系数求解过程采用最小二乘法,如下所示:
令并联立求解方程组可得到二项式系数。
(3)对光谱数据进行多元散射校正处理,用于校正光谱的分散效果,校正和减弱光在不均匀性样本表面散射引起的光谱变化差异,减少光谱基线漂移情况的发生。其包括以下步骤:
A、把整个未知试样的光谱A(λ)变换成假想的基准粒度的光谱A0(λ),根据最小二乘法指定α和β的值,设定两个因子的推定值分别为α'和β',由公式A(λ)=a0A0(λ)+β+e(λ)可得到以下变换式:
A0(λ)=[A(λ)-β']/α'。
B、获取α'和β'的光谱数据,使用所有土壤样本的平均光谱,如下所示:
线性回归方程为:
Ai表示第i个样本的光谱,A为建模集光谱数据,通过最小二乘回归可求得α和β。
(4)对光谱数据进行归一化处理,归一化算法有最大归一化、平均归一化、面积归一化和矢量归一化法等。在近红外光谱分析中,比较常用的归一化是矢量归一化算法。其方法如下:
取一条光谱,其数据表达为x(1*m),其矢量归一化算法公式为:
其中m为波长数,i=1,2,...,n。矢量归一化算法常被用于校正由微小光程差异而引起的光谱变化。
(5)构成训练土壤样本集。
第二步,构造基于深度学习的预测模型。其包括以下步骤:
(1)将训练土壤样本的光谱信号看作二维特征输入,将波数构成的特征作为第一维特征,将频域构成的特征作为第二维特征;在频域维度上采用梅尔域的滤波带系数作为参数,选择N个滤波频带,按照土壤成分含量设定标签,把预处理好的训练样本土壤集随机排序后输入卷积神经网络。在此卷积神经网络为采用基于LeNet-5模型改进的卷积神经网络,此网络结构相比于LeNet-5去掉了一个全连接神经网络,只使用了一个全连接网络。包括一个输入层、五个隐含层和一个输出层。其中输出层的节点数与待预测土壤成分含量的类别数一致。其向前传播阶段如图2所示,包括以下步骤:
A、第一个特征提取阶段,即输入层-c1层-s2层。输入训练土壤样本的光谱数据的二维波谱表示,经过5*5大小的卷积核运算,再经过子采样处理,缩放为原来的1/2。
B、第二个特征提取阶段,即s2层-s4层。输入s2层的二维光谱特征数据经过5*5的卷积核运算,再经过子采样处理,缩放为原来的1/2。c3层有16个特征图是因为c3层特征图的每个神经元与s2网络层的若干个特征图的5*5的邻域连接,这样组合提取不同的特征,从而提取更为复杂的信息,在训练阶段,可通过改变这种特征图的连接方式来优化网络性能。
C、第三个特征提取阶段,即s4层-c5层。网络层c5为由120个特征图组成的卷积层,每个神经元与s4网络层的所有特征图的5*5大小的邻域相连接。在训练阶段,可通过改变这种特征图的连接方式来优化网络性能。
D、分析预测,即c5层-输出层。c5层到输出层采用全连接的方式,使用c5层的120维向量进行预测分类。由于是全连接,所以此分析预测器参数很多,具有很强的描述能力,神经网络输出判断值既作为反向传播的调整基数,也可用来在测试过程中对土壤成分作预测分类。
(2)采用反向传播方法对整个网络进行全局训练,优化网络参数;误差反向传播算法进行反向传播,反向更新权值和卷积核,从而得到训练好的卷积神经网络。同时可以通过调整卷积核的个数,大小以及特征图的个数和组合方式来优化网络性能。至此可以把需要分析预测的测试土壤样本经过和训练土壤样本相同的预处理后,通过二维波谱表示后输入训练好的网络,只进行网络前向传播过程,根据网络输出层的值对测试土壤样本的成分进行分析预测。
第三步,测试样本的获取和预处理。使用光谱仪获取测试土壤样本的光谱数据,对测试样本土壤扫描40次取平均值;对测试样本土壤采用与训练样本相同的光谱数据预处理方法,得到测试土壤样本。在此测试样本的获取和预处理的步骤与训练样本的获取和预处理步骤完全相同,也同样经过在密封的暗室环境中使用光谱仪获取不同训练土壤样本集的光谱数据,对各测试样本土壤分别扫描40次取平均值;对光谱数据进行平滑处理;对光谱数据进行多元散射校正处理;对光谱数据进行归一化处理;最终构成测试土壤样本集。
第四步,将预处理过的测试样本的光谱数据输入构造的预测模型,完成对测试样本土壤成分含量的分析预测。将测试土壤样本采用梅尔域的滤波带系数作为参数,变成二维特征输入训练好的卷积神经网络进行土壤成分含量的分析预测。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
- 还没有人留言评论。精彩留言会获得点赞!