一种基于深度学习的燃机涡轮叶片故障检测方法与流程
本发明属于燃气轮机故障检测领域,具体涉及一种基于深度学习的燃机涡轮叶片故障检测方法。
背景技术:
燃气涡轮发动机,作为热机的一种形式,又被称之为燃气轮机,它产生于上世纪30年代,自发明以来,就被应用于航空和船舰等大型军用民用领域,被视为国家综合实力的一种重要体现。自1960年燃气轮机全面代替了活塞式发动机之后,更是得到了突飞猛进的应用,在发电机、各国主战坦克的推进系统中也变得无可替代。由于它拥有着体积不大、质量较轻、污染较小、可靠性高、性价比突出以及效率极高等优良特点,步入21世纪以来,在改善环境和调整能源产业机构的大前提环境下,再一次体现出了它的利用价值,迄今为止,其产业规模变得愈发宏大,产品应用也变得越来越广泛。
燃气轮机的主体结构主要是由燃烧室、压气机、涡轮、尾喷管以及其他部件构成的,按照分类来讲,又可以分为:涡轮喷气式发动机、涡轮风扇式发动机、涡轮螺旋桨发动机和涡轮轴承发动机等,其中涡轮风扇式发动机应用最为广泛,航空领域,船舶领域和发电机系统大部分都采用它作为提供动力的首选方案。我国燃气轮机产业起步较晚,但是发展迅猛,经过多年的科研发展,我国在燃气轮机自主创新,产品研制和消化吸收国外先进技术方面取得了长足进步。同时,由于能源产业结构的调整,天然气产量持续增加,这也给了以天然气为燃料的燃气轮机发展提供了良好的条件以及环境。根据国家发改委的规划,截至2020年,我国的燃气轮机装机总量将达到5500万千瓦,与此同时成为全球最为庞大的燃气轮机发展市场,具有无限值得期待的前景。
深度学习是由Hinton等人在2006年提出来的一种人工智能模式,它可以将低层次的特征抽象成更接近特征本质的高层次特征,已经被成功实现于手写体识别,语音识别以及人脸识别等方面,是当今研究的热点。传统的机器学习方法诸如隐型马尔科夫模型,支持向量机,最大熵模型等在处理特征向量时的原理是将原输入特征映射到特征区间内,这样的结果就是造成特征结构变得较为简单,有其一定的局限性。然而当样本容量和计算能力有限时,这些方法面对复杂问题的分类时,往往显得力不存心。相较之下,深度学习模式可以处理从大容量样本中提取数据集本质特征的问题,有效地逼近复杂式函数,对输入数据处理之后进行分类。
技术实现要素:
本发明的目的在于提供一种提高故障检测故障率的基于深度学习的燃机涡轮叶片故障检测方法。
本发明的目的是这样实现的:
(1)涡轮叶片的温度数据预处理,包括:
(1.1)周期信号提取
所分析的涡轮发动机由86个叶片构成,辐射测温的数据是所有叶片经多个周期旋转之后得到的数据,
根据周期性质的判别公式:f(x)=f(x+T)
其中T是函数的周期,通过上式来判断温度数据是否是周期数据;以极小值和极大值为判别标准,进行周期判断,
以某一极大值点为起始点,统计某段区间内所有的极大值点,称这些点为测试点,获得相邻的两个同温度测试点后,分别向后采样对比采样点温度,如果相同,认定为这是一个周期;
(1.2)变工况温度数据分布
将工况分为以下三种工况:0.6工况、0.8工况以及1.0工况,三种工况下的涡轮叶片转速分别为:8635/rpm,8920/rpm,9138/rpm;
(1.3)单个叶片温度数据分布
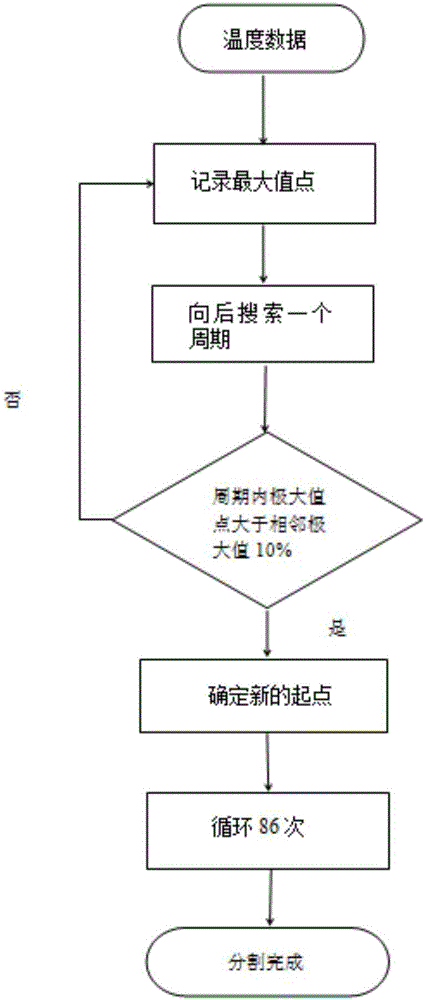
对单个叶片温度数据的分割算法建立在极值寻找上,统计数据中的极大值点,对比各个极值点的温度数据后,选取温度数据最大的一点,即最大值点,记为a0,以a0为起点,向后搜索一个周期,即40个采样点,并记录下该周期内的极大值点;对这些极大值点做一个判定,当这些极大值点不能大于其相邻极大值点的10%,如果大于相邻点的10%,那么就将这个极大值点变为起始点a0,循环上述过程86次,得到了86个叶片的周期,并对叶片进行01到86序列编号,对其提取特征用于状态分类检测;
(2)提取涡轮叶片温度特征向量
采用基于全体经验模态分解的方法来进行叶片温度特征向量的提取;通过每次在信号中加入给定幅值的不同高斯噪声来改变信号或是数据的极值点个数和极值点的分布间隔,之后对多次分解得到的IMF分量进行总体平均抵消加入到信号中的噪声;
(2.1)对加入到信号中的噪声幅度值进行初始化;
(2.2)对于第i次加入的噪声信号进行分解;
(2.2.1)信号x(t)中加入一定幅值的高斯信号ni(t),xi(t)=ni(t)+x(t),其中等式左边代表了第i次加入噪声信号后形成的信号;等式右边第一项代表了高斯噪声信号;x(t)表示原始信号;
(2.2.2)对xi(t)进行EMD分解,得到一组IMF分量ci(i=1,2,3,...,I),其中ci表示第i次分解得到的IMF分量;I代表分解次数;
(2.2.3)如果i<I,则返回到步骤(2.2.1),且使得i=i+1,重复步骤(2.2.1)和步骤(2.2.2),直到i=I;
(2.3)计算通过I次分解的总体平均值,用符号y表示;
(2.4)保存所有IMF分量的总体平均值作为最终的IMF分量;
(3)基于深度学习网络的故障诊断
选取受限制玻尔兹曼机模型作为深度网络设计模型,通过层与层之间的递进来调节受限制玻尔兹曼机模型,使用1层隐含层搭配1层可视输出层来构成整个深度模型的传递层,并对整个网络的权值进行初始化;
受限制玻尔兹曼机模型表示为RBM(W,b,c,v0),其中,W是第一个隐藏层与第二个隐藏层之间的权值连接矩阵,b是隐藏层的偏置,c是输入层的偏置,v0代表在训练中使用的样本集合;
(3.1)对于所有隐藏层的节点i,计算隐藏层之间的映射运算即P(h0i=1|v0),根据P(h0i=1|v0)进行抽样,得到h0i,sigm()是映射函数;
(3.2)对于所有可视层的节点j,计算可视层之间的映射运算即P(v1j=1|h0),根据P(v1j=1|h0)进行抽样,得到v1j;
(3.3)对于使用到的隐藏层节点i,计算隐藏层与隐藏层之间的映射运算即P(h1i=1|v1),根据P(h1i=1|v1),更新连接权值的偏置参数;更新公式如下所示:
W=W-ε(h0v0'-Q(h1=1|v1)v1')
b=b-ε(h0-Q(h1=1|v1))
c=c-ε(v0-v1)
(4)燃机涡轮叶片故障检测:构建了一个用于算法实验的燃机涡轮叶片故障检测系统,模拟故障数据各6类,每类10组样本,共60组数据,对模拟的涡轮叶片故障信号进行EEMD分解,然后求其IMF的能量,因此选用前8个分量,残余项的能力为零,然后求得特征向量;数据分为两部分,随机取48组作为训练样本,其余12组作为测试样本;利用训练样本对深度学习网络进行训练;用训练好的深度学习网络对待测试样本进行分类,并输出分类结果。
本发明的有益效果在于:本发明针对涡轮叶片温度采集数据样本较大的问题,首次将深度学习方法引入到燃气轮机涡轮叶片故障诊断中,推动了燃气轮机涡轮叶片故障诊断的多样性发展,提高了故障检测的正确率。
附图说明
图1基于深度学习的涡轮叶片故障检测框图;
图2涡轮叶片分割流程图。
具体实施方式
下面结合附图对本发明做进一步描述。
本发明提供的是一种基于深度学习的燃机涡轮叶片故障检测方法,该方法首先进行涡轮叶片温度数据的预处理,包括周期信号提取与分割,不同工况温度数据分析,单个叶片温度数据分布研究,然后进行涡轮叶片的特征提取,采用基于全体经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)的方法来进行叶片温度特征向量的提取。最后基于深度学习网络进行涡轮叶片故障诊断。本发明相比于BP神经网络和支持向量机,故障诊断的正确率更高。
本发明是燃气轮机涡轮叶片故障检测的一种方法,通过对涡轮叶片的温度数据进行分析和预处理,并进行周期信号提取,及不同工况数据分析,对单个涡轮叶片温度数据进行分割后提取涡轮叶片温度特征向量,然后基于深度学习理论进行燃机涡轮叶片故障检测。
本发明是燃气轮机涡轮叶片故障检测的一种方法,首先对涡轮叶片的温度数据进行预处理,得到不同工况下,单个涡轮叶片一个周期内数据,对单个涡轮叶片温度数据进行分割后提取涡轮叶片温度特征向量,然后基于采用深度模型的BP人工网络进行燃机涡轮叶片的故障检测。
本发明的具体实现步骤如下:
(1)涡轮叶片的温度数据预处理,包括:
①周期信号提取
所分析的涡轮发动机有86个叶片构成,辐射测温的数据是所有叶片经多个周期旋转之后得到的数据。
根据周期性质的判别公式:f(x)=f(x+T)
其中T是函数的周期,通过上式来判断这些温度数据是否是周期数据。以极小值和极大值为判别标准,进行周期判断,结果发现,相隔一段采样间距,会出现几乎一样的波形,因此判断采集到的温度数据是周期数据。
以某一极大值点为起始点,统计某段区间内所有的极大值点,称这些点为“测试点”,获得相邻的两个同温度测试点后,分别向后采样对比采样点温度,如果相同,认定为这是一个周期。
②变工况温度数据分布
由于涡轮运转时转速很快,因此无法确定到发生故障的具体时刻,只能确定到发生故障的某一段时间内,涡轮发动机工作中在一定温度下的转速情况,常用工况这个词汇来描述。工况分为以下三种工况:0.6工况、0.8工况以及1.0工况,三种工况下的涡轮叶片转速分别为:8635/rpm,8920/rpm,9138/rpm。
③单个叶片温度数据分布
涡轮发动机中,叶片与叶片之间存在着重叠,因此需要将温度数据进一步进行分析,辨别出具体的叶片位置。对单个叶片温度数据的分割算法建立在极值寻找上,以极大值为例,统计数据中的极值点,对比各个极值点的温度数据后,选取温度数据最大的一点,即最大值点,记为a0,以a0为起点,向后搜索一个周期,即40个采样点,并记录下该周期内的极大值点。对这些极大值点做一个判定,当这些极大值点不能大于其相邻极大值点的10%,如果大于相邻点的10%,那么就将这个极大值点变为起始点a0,循环该方法86次,得到了86个叶片的周期,并对叶片进行01到86序列编号,可以对其提取特征用于状态分类检测。
(2)涡轮叶片温度特征向量提取
采用基于全体经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)的方法来进行叶片温度特征向量的提取。EEMD是一种通过噪声来辅助分析的信号分析方法,该方法利用了高斯白噪声具有频率均匀分布的特点来解决经验模态分解(Empirical Mode Decomposition,EMD)方法分解带来的模态混叠现象,通过每次在信号中加入给定幅值的不同高斯噪声来改变信号或是数据的极值点个数和极值点的分布间隔,之后对多次分解得到的IMF分量进行总体平均以达到抵消加入到信号中的噪声的目的,从而有效的避免了模态混叠显现的出现。
①对加入到信号中的噪声幅度值进行初始化。
②对于第i次加入的噪声信号进行分解:
a.信号x(t)中加入一定幅值的高斯信号ni(t),xi(t)=ni(t)+x(t),其中等式左边代表了第i次加入噪声信号后形成的信号;等式右边第一项代表了高斯噪声信号;x(t)表示原始信号。
b.对xi(t)进行EMD分解,得到一组IMF分量ci(i=1,2,3,...,I),其中ci表示第i次分解得到的IMF分量;I代表分解次数。
c.如果i<I,则返回到步骤a,且使得i=i+1,重复步骤a和步骤b,直到i=I。
③计算通过I次分解的总体平均值,用符号y表示。
④保存所有IMF分量的总体平均值作为最终的IMF分量。
(3)基于深度学习网络的故障诊断
选取受限制玻尔兹曼机模型(Restricted Boltzmann Machine,RBM)作为深度网络设计模型。其中最主要的工作是对RBM的调节。RBM调节通过层与层之间的递进来调节的,使用1层隐含层搭配1层可视输出层来构成整个深度模型的传递层,并对整个网络的权值进行初始化。
RBM模型表示为RBM(W,b,c,v0),其中,W是第一个隐藏层与第二个隐藏层之间的权值连接矩阵,b是隐藏层的偏置,而c是输入层的偏置,v0代表在训练中使用的样本集合。
①对于所有隐藏层的节点i,计算隐藏层之间的映射运算即P(h0i=1|v0),根据P(h0i=1|v0)进行抽样,得到h0i,sigm()是映射函数。
②对于所有可视层的节点j,计算可视层之间的映射运算即P(v1j=1|h0),根据P(v1j=1|h0)进行抽样,得到v1j。
③对于使用到的隐藏层节点i,计算隐藏层与隐藏层之间的映射运算即P(h1i=1|v1),根据P(h1i=1|v1),更新连接权值的偏置参数。更新公式如下所示:
W=W-ε(h0v0'-Q(h1=1|v1)v1')
b=b-ε(h0-Q(h1=1|v1))
c=c-ε(v0-v1)
(4)燃机涡轮叶片故障检测:构建了一个用于算法实验的燃机涡轮叶片故障检测系统,以该系统为平台进行一系列针对性实验,系统配置如下:
①硬件:处理器Intel(R)Pentium(R)Dual CPU 1.60GHz;内存2GB;显卡256M;硬盘80G。
②软件:Windows XP操作系统;Matlab2012a开发环境。
模拟故障数据各6类,每类10组样本,共60组数据,对模拟的涡轮叶片故障信号进行EEMD分解,然后求其IMF的能量,由于故障信息主要集中在前几个分量中,因此选用前8个分量,残余项的能力几乎为零,然后求得特征向量。数据分为两部分,随机取48组作为训练样本,其余12组作为测试样本。利用训练样本对深度学习网络进行训练。用训练好的深度学习网络对待测试样本进行分类,并输出分类结果,正确率为91.6%。
模拟故障数据6类,每类10组样本,共60组数据,对模拟的涡轮叶片故障信号进行EEMD分解,然后求其IMF的能量,由于故障信息主要集中在前几个分量中,因此选用前8个分量,残余项的能力几乎为零,然后求得特征向量。数据分为两部分,随机取48组作为训练样本,其余12组作为测试样本。利用训练样本对深度学习网络进行训练。用训练好的深度学习网络对待测试样本进行分类,并输出分类结果,并与BP神经网络,支持向量机(SVM)进行试验比较,结果如表1所示。
表1诊断结果比较
- 还没有人留言评论。精彩留言会获得点赞!