用于结构监测数据异常识别的加权主成分分析方法与流程
本发明属于土木工程结构健康监测领域,提出了用于结构监测数据异常识别的加权主成分分析方法。
背景技术:
土木工程结构在长期荷载、环境侵蚀和疲劳效应等因素的共同作用下,其服役性能的退化不可避免。深入分析结构监测数据,可以及时发现结构的异常状态并提供准确的安全预警,对确保土木工程结构的安全运营具有重要的现实意义。目前,结构监测数据的异常识别主要通过统计方法实现,一般分为两大类:1)单变量控制图,如休哈特控制图、累积和控制图等,该类方法对每个测点的监测数据分别建立控制图,以识别监测数据中的异常;2)多变量统计分析,如主成分分析、独立分量分析等,该类方法利用多测点监测数据之间的相关性建立统计模型,并定义相应的统计量以识别监测数据中的异常。
一般情况下,结构相邻测点的监测数据之间具有一定的相关性。实际工程应用中,能够考虑这种相关性的多变量统计分析方法更具优越性。此外,该类方法仅需定义1~2个统计量,即可判别监测数据是否异常,这对于包含众多传感器的结构健康监测系统而言,非常便捷。然而,主成分分析作为多变量统计分析方法的典型代表,其每个主方向对数据异常的敏感性并不相同。若能量化这种敏感性,并依据敏感性的差异定义一个加权统计量以提升异常识别能力,则多变量统计分析在结构监测数据异常识别中将更具实用价值。
技术实现要素:
本发明旨在提出一种加权主成分分析方法,以有效识别结构监测数据中的异常。其技术方案是:首先,建立结构正常监测数据的多变量统计分析模型;其次,推导敏感因子用于量化每个主方向对某一测量变量中发生异常的敏感性;接着,依据敏感因子的大小为每个主方向赋予不同的权值,并定义相应的加权统计量;最后,将所有测量变量对应的加权统计量融为一个指标用于识别监测数据中的异常。
本发明的技术方案:
一种用于结构监测数据异常识别的加权主成分分析方法,步骤如下:
步骤一:监测数据建模
(1)建立结构正常监测数据的多变量统计分析模型:
Σ=E{y*y*T}=QΞQT
式中:表示结构的某一正常监测数据,包含m个测量变量;Σ表示协方差矩阵;Ξ=diag(ξ1,ξ2,...,ξm)包含所有特征值ξi;Q=[q1,q2,...,qm]包含所有特征向量qi,qi即为第i个主方向;
步骤二:推导敏感因子
(2)对实际监测过程中采集到的某一监测数据y而言,第i个主方向qi对应的统计量定义如下:
对y中某一测量变量发生的异常而言,每个qi的敏感性不同,即每个Hi的异常识别能力不同;
(3)若y中第j个测量变量发生异常,则其表达式为:
y=y*+δjζj
式中:δj表示第j个测量变量中发生异常的幅度;ζj表示m阶单位矩阵的第j列;
(4)此时,qi对应的统计量为:
式中:是正常监测数据定义在qi上的统计量,它不引起Hi超限;是由于监测数据发生异常所导致的Hi的增量,它越大越可能引起Hi超限;
(5)由于且则ΔHi简化为:
式中:qji表示qi的第j个元素;表示y*在qi上的投影;
(6)由于y*具有随机性,则也具有随机性;进一步,推断ΔHi具有随机性,为了量化ΔHi,计算其平均值:
若在预处理阶段将正常监测数据中心化,则有因此,ΔHi的平均值为:
(7)上式表明:在异常幅度不变的情况下,越大,ΔHi的平均值也越大;换言之,定义在qi上的统计量Hi对第j个测量变量中发生异常的识别能力取决于的大小;因此,定义敏感因子如下:
敏感因子βj,i越大,Hi越可能识别出第j个测量变量中发生的异常;
步骤三:定义加权统计量
(8)对第j个测量变量而言,qi对应的权系数计算如下:
(9)进一步,对第j个测量变量定义加权统计量如下:
加权统计量对第j个测量变量发生的异常更敏感;这样,监测数据中的每个测量变量均对应一组权系数和一个加权统计量,可将所有加权统计量组成一个向量
步骤四:融合加权统计量
(10)条件下判断监测数据发生异常的概率为:
式中:P(·)表示某变量的概率;F表示监测数据的异常状态;
(11)的计算公式如下:
式中:N表示监测数据的正常状态;正常和异常状态下统计量出现的条件概率分别为和是的控制限;
(12)给定所有的加权统计量则监测数据中是否存在异常的判断准则为:
式中:α表示显著性水平,一般取0.01;满足上式可判断监测数据中存在异常。
本发明的有益效果:由于加权统计量的权系数是依据每个主方向对数据异常的敏感性的大小确定的,故其异常识别能力得到了有效提升。
附图说明
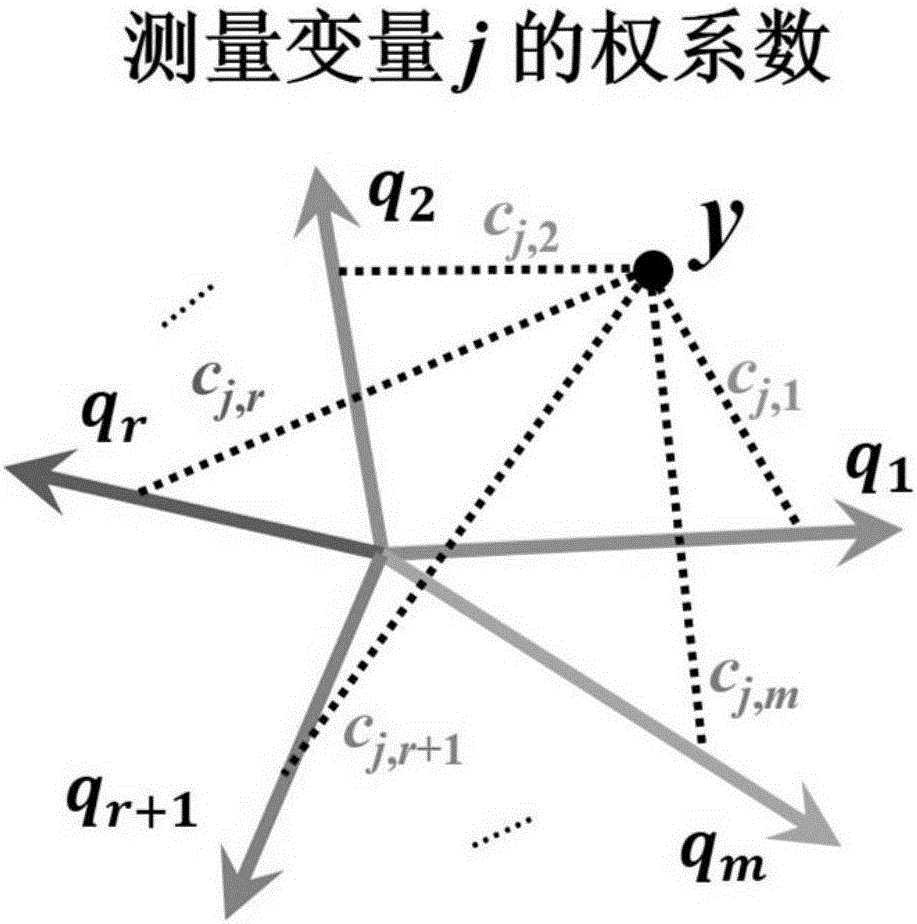
图1是权系数的对应关系。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
采用一个四层钢框架结构模拟监测数据,每层布设4个加速度计,共有16个加速度计采集监测数据。生成两个数据集:训练数据集和测试数据集;训练数据集为正常监测数据集,测试数据集中的一部分用于模拟异常监测数据;两个数据集均持续100s,采样频率为256Hz。具体实施方式如下:
(1)对训练数据集进行建模,得到模型参数参数Q=[q1,q2,...,qm]和Ξ=diag(ξ1,ξ2,...,ξm)。
(2)计算所有的敏感因子βj,i以及权系数cj,i,j=1,2,...,m,i=1,2,...,m;这样,监测数据中每个测量变量均对应一组权系数(见图1)。
(3)在测试数据集中模拟异常监测数据;对模拟异常后的测试数据集中的任一数据点而言,结合上述确定的权系数计算所有加权统计量并组成向量将Γ中的所有加权统计量融为一个指标P(F|Γ),若满足P(F|Θ)>α,则可判断监测数据中存在异常;对比本发明与传统主成分分析方法的异常识别效果可知,本发明的异常识别能力更优。
- 还没有人留言评论。精彩留言会获得点赞!