一种混合质谱筛除方法与流程
本发明涉及一种气相色谱-质谱联用技术,特别涉及一种色谱共流出峰解析及混合质谱解析技术,属于检测分析
技术领域:
。
背景技术:
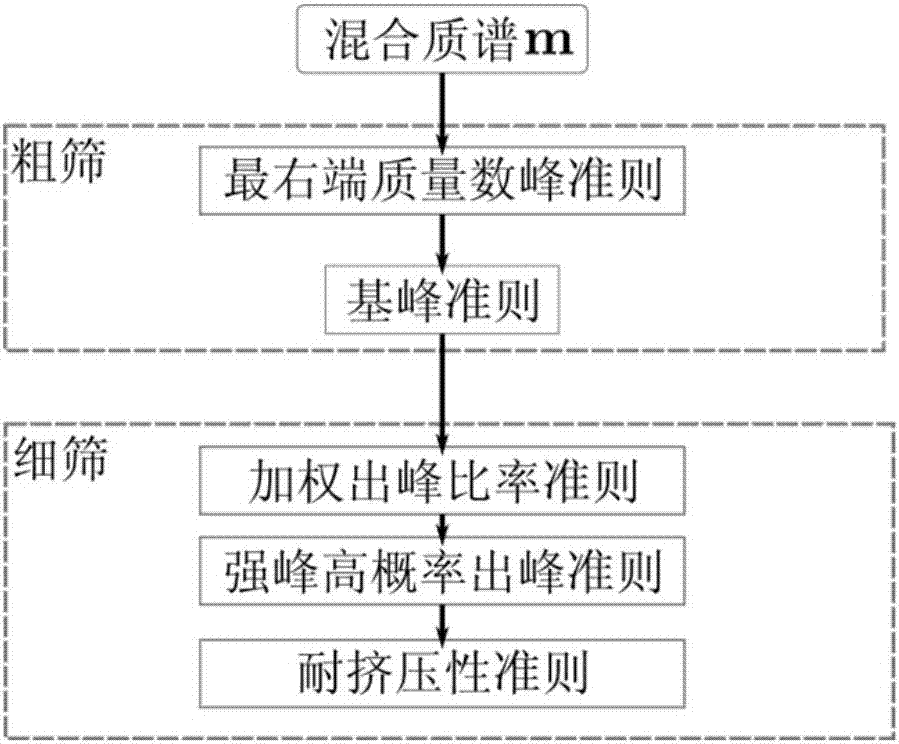
:气相色谱-质谱(gc-ms)联用技术是复杂样品定性定量分析中应用最广泛的技术之一,随着美国国家标准局推出的nist质谱库容量的不断增大,gc-ms已经成为复杂样品的挥发性和半挥发性小分子有机化合物的首选分析技术。然而,实际的色谱指纹图谱往往难以将色谱峰完全分离开来,色谱共流出峰非常普遍,主要是受限于气相色谱硬件本身分离能力的限制,其次是实验条件的限制。当前技术,如渐进因子分析法,固定尺寸移动窗口因子分析法,局部正交投影方法等(参见《复杂体系仪器分析--白、灰、黑分析体系及其多变量解析方法》,梁逸曾、许青松等著)对部分色谱共流出峰有一定的分离效果,但对色谱峰形有较强依赖,且对完全重叠峰尚无一般性的分离方案,无法满足某些特殊领域的应用需求。基于标准质谱数据库对色谱图中任意保留时间点的混合质谱进行分析是解析色谱共流出峰的一个重要思路。但是,基于标准质谱数据库对混合质谱直接进行拟合计算的运算量巨大,且容易导致过拟合现象。因此,首先排除质谱数据库中与待测混合质谱无关或相关性较小的质谱,即开展质谱筛除,是显著降低混合质谱拟合计算的运算量、避免过拟合现象,提高混合质谱解析效果的必要技术。技术实现要素:针对现有的质谱解析方法存在的缺陷,本发明的目的是在于提供一种能快速、高效筛除无关质谱,以降低候选质谱列表规模,排除无关质谱对计算结果干扰的方法,该方法为质谱定性分析提供技术基础。为了实现上述技术目的,本发明提供了一种混合质谱筛除方法,该方法是将混合质谱先采用最右端质量数符合准则和基峰符合准则进行粗选,剔除不合格纯质谱,再通过加权出峰比率准则、强峰高概率出峰准则和耐挤压性准则进行细选,剔除不合格纯质谱,得到候选质谱列表。优选的方案,所述最右端质量数准则为:若在质谱数据库中任意物质的纯质谱中的最右端峰或最右端峰簇中丰度最大峰所对应的质量数在混合质谱中出峰,则相应质谱保留在候选质谱列表中,否则剔除。优选的方案,所述基峰准则为:若在质谱数据库中任意物质的纯质谱中的基峰所对应的质量数在混合质谱中出峰,则相应质谱保留在候选质谱列表中,否则剔除。优选的方案,所述粗选过程中先用最右端质量数准则剔除不合格纯质谱,再用基峰准则剔除不合格纯质谱。优选的方案,所述最右端质量数准则在运用过程中预先建立最右端质量数索引结构。较优选的方案,所述索引结构用于查询纯质谱最右端质量数,判断所述纯质谱最右端质量数与混合质谱中某一峰对应的质量数是否一致,如果一致则相应的纯质谱列入候选质谱列表中,否则剔除。优选的方案,所述基峰准则在运行过程中预先建立基峰索引结构。较优选的方案,所述索引结构用于查询纯质谱基峰,判断所述纯质谱基峰在混合质谱中是否出峰,且混合质谱中相应峰相对丰度大于阈值t,则所述纯质谱列入候选质谱中,否则剔除。所述阈值t优选为20%~30%。阈值t的确定是根据具体实验数据试算所得的最佳取值范围,在该范围内,绝大部分算例工作良好,超出该范围,很多算例会出现效率或精度上偏差的问题。优选的方案,所述加权出峰比率准则为:确定质谱数据库中任意物质的纯质谱碎片在混合质谱中的所有出峰,依据所述出峰在所述物质的纯质谱图中的丰度求和得s1,对所述物质的纯质谱图中的所有碎片出峰的丰度求和得s2,若s1/s2大于或等于阈值,则所述纯质谱列入候选质谱中,否则剔除。所述阈值优选为0.99±0.005。阈值的确定是根据具体实验数据试算所得的最佳取值范围,在该范围内,绝大部分算例工作良好,超出该范围,很多算例会出现效率或精度上偏差的问题。优选的方案,所述强峰高概率出峰准则为:在质谱数据库中任意物质的纯质谱中的相对丰度不小于10%的碎片峰定义为强峰,若所述强峰在混合质谱中的相对丰度与纯质谱图中所述碎片峰的相对丰度之比大于阈值t,则所述纯质谱列入候选质谱中,否则剔除。所述阈值t优选为20%~30%。优选的方案,所述耐挤压性准则为:若混合质谱中每个相对丰度大于5%的碎片峰,在其相应纯质谱中的相对强度与其在混合质谱中相对强度的比值的最大值小于阈值1/t,则所述纯质谱列入候选质谱列表中,否则剔除。所述阈值t优选为20%~30%。本发明混合质谱筛除方法包括如下具体步骤(参见图1):1.粗筛:基于混合质谱中的质谱碎片规律,对质谱数据库中的质谱进行初步筛除,排除不可能存在于混合质谱中的纯质谱;主要包含如下两步:1)质谱最右端质量数准则(参见图2):给定质谱数据库(nist质谱数据库或其他质谱数据库)中任一纯质谱,考察其质谱图中最右端峰所对应的质量数,若待测混合质谱在该质量数处出峰,则初步认为所考察纯质谱可能是待测混合质谱中的某一组分,将其加入初筛列表a;为加速搜索,可以预先基于最右端质量数对质谱数据库建立索引结构,索引结构用于更快速查询纯质谱最右端质量数,判断所述纯质谱最右端质量数与混合质谱中某一峰对应的质量数是否一致;2)基峰准则:考察列表a中所有纯质谱中相对丰度最大的峰所对应的质量数,若待测混合质谱在对应质量数处出峰且其相对丰度大于某一阈值t(例如t=30%),则将该纯质谱保留,将不满足该条件的质谱从列表a中删除;为加速对基峰的搜索,可以预先建立关于基峰的索引结构,对每张纯质谱,标明并存储其基峰位置,由此,对基峰的线性搜索被改进为直接查询;2.细筛:基于初筛后得到的质谱列表a,进行进一步精细筛除,该筛除步骤涉及到质谱出峰强度和一些概率准则,主要分为如下三个小步骤:1)加权出峰比率准则(参见图3):进一步考察列表a中的质谱,计算其加权出峰比率,若该比率大于某一阈值k(例如k=0.99),则将所考察质谱保留在列表a中,不满足该条件则将其删除;此处所考察质谱的加权出峰比率为该质谱在待测混合质谱中出峰的所有质量数处的相对丰度总和与全部出峰的相对丰度总和之比;2)强峰高概率出峰准则(参见图4),亦即在纯质谱中相对丰度较大的峰在待测混合质谱中也应出峰,且其相对丰度不宜太小;一种实现方法为,对列表a中的每一张质谱,若存在某个质量数处的相对丰度i>10%,但在待测混合质谱中出峰的相对丰度m<it,则将所考察的质谱从列表a中删除,此处的t与前述t相同;3)考察纯质谱在待测混合质谱中的耐挤压性;对列表a中的任一质谱,若其在待测混合质谱中出峰的相对丰度m>1%的每个峰均满足m<it(此处i为纯质谱中相应出峰的相对丰度)则将所考察的质谱从列表a中删除,此处的t与前述t相同。相对现有技术,本发明的技术方案带来的有益效果:本发明的技术方案主要是针对现有技术中利用标准质谱数据库对混合质谱解析过程中存在运算量大,且容易导致过拟合现象等问题而提出的改进方法。本发明的技术方案利用质谱的主要特征(碎片规律)和细节特征(丰度细节),首次提出利用最右端质量数符合准则和基峰符合准则进行粗选,再利用加权出峰比率准则、强峰高概率出峰准则和耐挤压性准则进行细选的方案,能够快速、有效筛除与混合质谱无关或相关性较小的质谱,经粗筛后,候选质谱列表中的质谱数目平均意义上可由20余万减少至1万以内,问题规模可达20倍以上的缩减;进一步经过细筛后将质谱数目显著降低,平均可降至10左右,且遗漏真实质谱的概率极低。该方法可极大地降低混合质谱解析的问题规模,为后续分析和处理提供了可靠的数据准备,为进一步开发高效的质谱定性或定量技术提供有力的技术支撑。附图说明【图1】为混合质谱筛除方法的总体流程示意图。【图2】为最右端质量数准则解说示意图;假设混合质谱中只出现了质量数为50,60,70的峰,则在最右端质量数峰索引迅速检索得到对应候选质谱,然后合并而得到候选质谱列表a,另外,实际计算可能忽略一定比例的低质量数。【图3】为加权出峰比率解说示意图;上图为混合质谱,下图为纯质谱,加权出峰比率为:r=s1/s2,当该比率低于事先设定的阈值时,剔除相应纯质谱。【图4】为强峰高概率出峰准则解说示意图;上图为纯质谱,下两图为混合质谱,考虑质量数为60的峰,当纯质谱出峰强度低于某阈值时,则剔除该纯质谱。【图5】为苯甲醇与3-甲基环戊烯醇酮混合物的色谱图(重叠峰局部放大图)。具体实施方式以下实施例旨在进一步说明本
发明内容,而不是限制本发明权利要求的保护范围。本发明以标准质谱数据库为工作基础。为方便阐述本发明专利的实施效果,以nist11版本的质谱数据库(含质谱212,961张)为基础来进行阐述。本发明使用python编程语言实现了所提算法,数据处理(清洗、重塑、合并和转换等操作)使用了pandas库,数值计算部分选用了numpy和scipy数值计算库。本发明将从理论质谱筛除、实验质谱筛除两个方面介绍算法的实施效果。对于实验质谱,应用本发明所提筛除方法前,首先进行适当的预处理,如基线扣除。此处先给出算法的参数设置。默认情况下,设定基峰阈值t=30%,加权出峰比率的阈值为k=0.99。实验中,如无特殊说明,均使用以上默认参数设置。首先考察算法对理论质谱(数据库中的质谱)混合谱筛除的正确性。实施例1理论质谱筛除:本实施例从数据库中选取苯乙醇(索引:55038,nistid:118543)和麦芽酚(索引:98292,nistid:233673)的质谱,将其按1:1混合。上述混合质谱利用数据库进行筛除的结果如下表所示:表1.苯乙醇与麦芽酚混合质谱筛除结果经历筛选步骤所剩质谱数目最右端质量数峰准则55715基峰准则1424加权出峰比率准则589强峰高概率出峰准则16耐挤压性准则11经验证,最终所剩11张质谱中包含苯乙醇和麦芽酚的质谱。利用这11张质谱,对待测混合质谱进行最小二乘分解,剔除微小权重,可得苯乙醇与麦芽酚的比例大致为1∶1,与实际混合比例一致。实施例2理论质谱筛除:本实施例从数据库中选取彼此相似度非常高的邻-二甲苯(索引:55556,nistid:291483),间-二甲苯(索引:55552,nistid:291455)和对-二甲苯(索引:55553,nistid:228010)的质谱,将其按4∶3∶3混合。上述混合质谱利用数据库进行筛除的结果如下表:表2.邻、间、对-二甲苯理论混合质谱筛除结果经历筛选步骤所剩质谱数目最右端质量数峰准则42546基峰准则736加权出峰比率准则54强峰高概率出峰准则6耐挤压性准则4经验证,最终所剩4张质谱中包含邻、间、对-二甲苯的质谱。利用最终所剩4种质谱,对待测混合质谱进行最小二乘分解,忽略微小权重,可得到邻、间、对-二甲苯的比例大约为4∶3∶3,与原始混合比例相符。以上两实施例说明,本发明所提筛除算法对理论质谱筛除效果良好,所生成计算结果为后续处理(例如,实施例中基于最小二乘分解的定性定量分析)提供了可靠的数据基础。但是,实际仪器产生的数据相比理论质谱具有更多的随机性,如噪声和实验操作带来的影响。有必要进一步验证分析实验中的混合质谱的筛除效果。本发明通过实施例3、4、5来阐述本发明算法针对实际混合质谱的测试效果。实施例3实际质谱筛除:本实施例考察某一香精香料gc-ms色谱数据,该数据已通过其他技术手段(安捷伦工作站定性分析、化学检测)完成分析。其中苯乙醇和麦芽酚两峰未完全分离,有部分重叠。本实施例选取两峰之间的谷底,获取其质谱进行筛除和分析。筛除结果如下:表3.苯甲醇与3-甲基环戊烯醇酮混合质谱筛除结果经历筛选步骤所剩质谱数目最右端质量数峰准则52676基峰准则1704加权出峰比率准则1121强峰高概率出峰准则11耐挤压性准则6经验证,最终所剩6张质谱中包含苯乙醇(索引:55038,nistid:118543)和麦芽酚(索引:98292,nistid:233673)的质谱。利用所剩6张质谱,对待测混合质谱进行最小二乘分解,忽略微小权重,可得苯乙醇与麦芽酚的比例大致为5∶3。实施例4实际质谱筛除:苯甲醇和3-甲基环戊烯醇酮是烟草中常用的香料成分。本实施例将这两种物质的纯样品进行混合,利用cg-ms仪器分析处理所得色谱图。仪器条件为:hp-5ms色谱柱(60m*0.25mm*0.25μm),炉温(60℃保持2min,然后6℃/min升温到180℃,保持2min,再8℃/min升温到280℃保持20min;进样口温度:250℃),分流比:20∶1,离子源温度为230℃,四级杆温度150℃,进样量1ul。将获得的色谱图放大,聚焦于图5所示的保留时间为13.7min附近的色谱峰。取该色谱峰的顶点(13.71min)处的质谱数据,对该混合质谱进行筛除,筛除结果如下:表4.苯乙醇与麦芽酚混合质谱筛除结果经历筛选步骤所剩质谱数目最右端质量数峰准则51663基峰准则552加权出峰比率准则412强峰高概率出峰准则19耐挤压性准则13经验证,最终所剩13张质谱中包含苯甲醇(索引:44807,nistid:151560)和3-甲基环戊烯醇酮(索引:80534,nistid:1673)的质谱。利用所剩13张质谱,对待测混合质谱进行最小二乘分解,忽略微小权重,解析得知该色谱峰为苯甲醇与3-甲基环戊烯醇酮的共流出峰,比例大致为9∶5。观察图5可知,该色谱峰的共流出现象非常严重,苯甲醇与3-甲基环戊烯醇酮几乎完全重叠出峰,传统方法是难以解析的。本实施例是通过混合质谱筛除与分解的办法成功解决完全重叠峰解析的典型实例。实施例5实际质谱筛除:本实施例将香精香料中常见的38种化合物配置为混合物,经gc-ms仪器分析,获取其色谱数据。然后使用本发明算法对色谱图中的每一个目标色谱峰对应的混合质谱进行质谱筛除。各色谱峰质谱筛除情况的统计分析结果如下:表5.混合质谱筛除衰减数目平均值统计经历筛选步骤所剩质谱数目(平均值)最右端质量数峰准则78066基峰准则5752加权出峰比率准则217强峰高概率出峰准则13耐挤压性准则8经验证,本实施例没有出现遗漏真实质谱的情况,38种化合物全部出现在相应色谱峰的混合质谱筛除候选列表中。上述实施例充分说明,本发明的混合质谱筛除方法可显著降低混合质谱解析的运算规模,且遗漏真实质谱的概率非常低。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1