基于主动学习的轴承故障检测与诊断的制作方法
本发明涉及故障诊断领域,具体涉及滚动轴承故障检测的方法。
背景技术:
调查研究表明,机器设备故障中有约30%是由于滚动轴承的故障造成的。滚动轴承发生故障,会使机器产生剧烈振动和噪声,轻则机器停止工作,重则会引起飞机失事、列车出轨等灾难性事故。振动法具有采集和处理信号简单、效果好、适用范围广等优势而被广泛应用。
p.konar等人利用svm支持向量算法在美国西储大学故障集上识别故障;何晓霞等采用连续小波分析的方法对滚动轴承振动加速度信号进行处理,提取了滚动轴承在正常、内圈剥落、外圈剥落及滚动体剥落的故障特征;万书亭采用小波包变换进行提取,在提取所得的特征向量采用支持向量机进行诊断,结果表明小波包变换相对小波变换更加细致准确。统计发现,传统诊断方法多采用正确:损坏=1:1的比例,这与实际情况相差甚远(实际情况远大于1)。因此在实际情况中,传统方法识别率极低。
技术实现要素:
本发明的目的是为了研究并提供一种滚动轴承故障检测的新方法,提高滚动轴承故障识别率。
本发明所采用的方法是:
利用振动法原理,根据实验设备采集的滚动轴承的振动信息,计算时域特征参数,然后结合小波包变换得到频域参数,再通过基于密度聚类的主动学习模型进行故障分类,形成一个比较完整的系统的滚动轴承故障分析检测模型和方法。
为实现上述的滚动轴承检测方法,方法如下:
1、用qpz-ⅱ型轴承故障分析仪对运行状态下的滚动轴承进行数据采集;
2、对采集到的数据进行时域分析,计算五个时域因子,相关公式如下:
均方根值:
峰值因子:c=xpeak/rrms
裕度因子:
脉冲因子:
波形因子:s=xrms/xav
峭度因子:
3、统一采样频率,对滚动轴承进行重采样,将采样得到的数据转换为频域,进行频域分析,得到三个频域特征参量;
4、用基于密度聚类的主动学习算法对得到的八个特征参量进行分类,步骤如下:
(1)通过密度聚类得到“直属上司-下级”关系树,给每组数据贴标签,首先定义两个核心参数:密度(ρi)和距离(δi)。数据i的密度为:
参数dc>0需要手动设定,一般选择最大距离10%。dij表示数据i和数据j之间的距离,δi计算式为:
对于密度最高的点,我们取
从上式可知,“直属上司-下级”关系树有n个节点,每个节点的“直属上司”是距离其最近,且比自己密度大的数据.密度最大的数据没有“直属上司”.每块的中心具有两个特点:第一,比相邻数据密度更大;第二,距离密度较大的数据尽可能的远。因此将密度和距离的乘积降序排列,选取前k个数据作为块中心.基于选取的k个中心,采用递归的方式进行聚类.每个示例获得与“直属上司”相同的类标签。
(2)选择较高密度和较大距离的一组数据,选择依据如下:
γi=δi×ρi.
(3)根据聚类结果和选择的标签给数据分类。
本发明的优点是:
有更加全面评价故障数据分类效果的指标,并且在降低训练样本个数的同时,能够提高滚动轴承的故障识别率。
附图说明
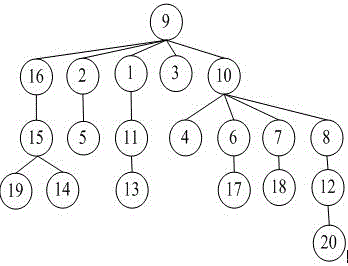
图1为聚类所得“直属上司-下级”关系树的概念图;
图2为基于密度聚类的主动学习算法的原理框图。
具体实施方式
下面通过具体实施方式并结合附图对本发明作进一步详细说明,在以下的具体描述中,很多细节描述是为了本发明能更好的被理解,本领域技术人员可以很清楚的明白和了解。下面描述的内容是说明性的而不是非限制性的,不应以此限制本发明的保护范围。
1、利用采集设备进行数据采集,试验设备有4个安装在滚动轴承不同部位的传感器来记录轴承运行时刻的振动信号,传感器的采样频率f=10khz,采样时间t=1s,记录不同时刻信号的幅值,得到采样数据。
2、对采样得到的数据进行时域分析,即计算得到五个时域因子,得到时域内的五个特征值,相关公式如下:
均方根值:
信号xi中找到j个峰值xpj(j=1~m),则xi的峰值指标为,
峰值因子:c=xpeak/rrms
裕度因子:
脉冲因子:
波形因子:s=xrms/xav
峭度因子:
3、统一采样频率进行采样,进行频域分析,步骤如下:
(1)选取振动信号分解层数,取l=3;
(2)小波分解后的的细节信号进行hilbert变换,再进行频谱变换得到小波包络谱,在l层中的细节信号特征值为:
(其中小波包络函数为w(f),f1为外圈包络谱值,f2为内圈包络谱值,f3为滚珠包络谱值);
(3)选取最大能量的频带作为特征分量,从而得到频域内的3个特征值。
4、将得到的五个时域特征参量和三个频域特征参量通过基于密度聚类的主动学习算法进行故障分类,如图2所示,具体分类方法如下:
(1)聚类
通过基于密度聚类的方法很容易检测具有任意形状的簇,每个簇中的数据收敛到密度分布函数的局部最大值处。在这里,我们提出了一种仅基于数据点之间的距离,它能够检测非球形簇并自动找到正确的簇数量,该算法有其基础假设,即聚类中心被局部密度较低的邻居包围,并且它们与任何具有较高局部密度的点相距较远。因此我们使用密度和距离两个参数来衡量每一个数据。首先定义两个核心参数:密度(ρi)和距离(δi)。数据i的密度为:
参数dc>0需要手动设定,一般选择最大距离10%。dij表示数据i和数据j之间的距离,δi计算式为:
对于密度最高的点,我们取
从上式可知,“直属上司-下级”关系树(如图1所示)有n个节点,每个节点的“直属上司”是距离其最近,且比自己密度大的数据.密度最大的数据没有“直属上司”.每块的中心具有两个特点:第一,比相邻数据密度更大;第二,距离密度较大的数据尽可能的远。因此将密度和距离的乘积降序排列,选取前k个数据作为块中心.基于选取的k个中心,采用递归的方式进行聚类.每个示例获得与“直属上司”相同的类标签。
(2)选择代表数据
一个数据如果有较高密度和较大距离,则代表其周围有较多的数据,更有可能作为簇的中心,更具有代表性。因此选取同时具有更高密度和较大距离的数据作为本簇的代表数据。本文提出采用乘积的方法来表示数据i具有更高密度和较大距离。计算式为:
γi=δi×ρi.
设置预算标签总数,以及每次每块可以获取的标签数目m。在每一块中密度和距离乘积比较大的数据更具有代表性。如果该块数目大于m,则将该块数据的γi值降序排列,取前m个数据标记,否则标记该块全部数据。
(3)分类
经过聚类以及选择代表数据之后,某一块数据没有被完全标记则需要分类。如果获取该块实例的标签一致,此标签直接作为块所有数据的类标签,不一致则重新聚类,选择代表数据。直到总标签预算用完之后,停止迭代。
- 还没有人留言评论。精彩留言会获得点赞!