机床、模拟装置以及机械学习器的制作方法
本发明涉及一种机床,特别是涉及具有使工件加工过程中的移动路径最佳化的功能的机床。
背景技术:
以往,制作加工程序,根据该加工程序来控制机床从而对工件进行加工。对工件进行加工时的加工速度在加工程序内作为轴的移动速度而进行指令,但这是基于该指令的工具与加工物的相对移动(工具移动)的最大速度,作为实际的机床运动,在加工开始时和角部、曲线部分等处,轴的移动速度按照各轴的加减速时间常数而发生变动。
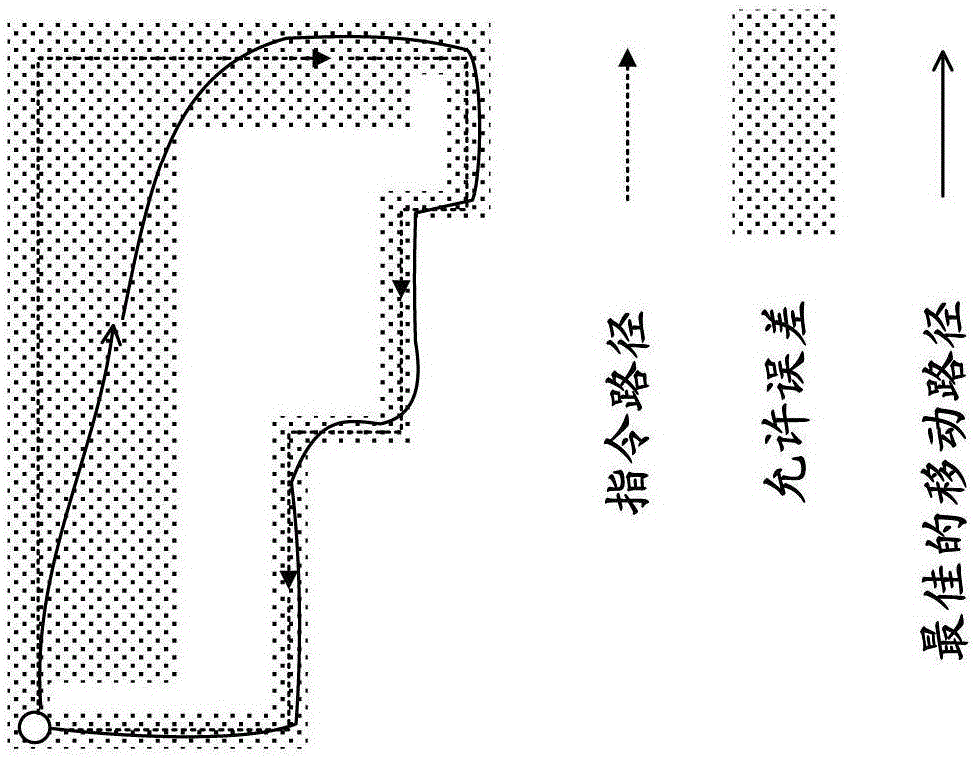
此外,在工件的加工过程中,如图8A以及图8B所示,从作为目标的工具的移动路径来看有允许的允许误差,为了将工件的加工程度维持在预定水平需要调整成工具从由加工程序指令的指令路径在允许误差的范围内进行移动。因此,以往机床的操作者一边确认加工物的加工面精度,一边通过变更加减速时间常数或者变更程序内指令的速度等方法来进行调整。
作为与这样的工件加工相关联的现有技术,在日本特开2006-043836号公报中公开了如下加工条件设定方法:使用加工模式,一边考虑加工精度一边进行缩短加工时间的加工路径信息的生成与加工条件的设定。
在控制机床来加工工件时,当工具路径脱离了对由加工程序指令的指令路径加上允许误差而得的范围时,可能引起加工物的不良,以及加工物、工具、机床的损坏。图9A以及图9B展示了以下示例:在工件加工时工具路径脱离后的结果,在加工物产生了不良(图9A)、或产生了加工物和工具的损坏(图9B)。
一般地,通过来自数值控制装置的被称为指令脉冲的数据来表示从某个时间的机床的轴位置到下一瞬间的轴位置为止的变化量。该指令脉冲根据加工程序指令的指令,作为进行了插补处理、加减速控制等的结果而被输出至机床侧。从这样的数值控制装置输出的指令脉冲受到设定给机床各轴的加减速时间常数的影响,而各轴的加减速时间常数在机床出厂时由机床制造商的技术员来进行设定。此外,在机床的设置时根据主要加工物的特性由机床制造商的技术员来进行调整。因此,是否能获得最佳的变化量取决于机床制造商的技术员的经验和能力、加工状况等,总是存在未必能获得最佳变化量这样的问题。
此外,上述的日本特开2006-043836号公报所公开的技术只能够应用于符合加工模式的状况,而不能灵活地对应于各种状况。
技术实现要素:
因此,本发明的目的在于提供一种机床,能够对将由直线和曲线形成的预定的加工物轮廓作为工具路径的工具动作进行机械学习。
本发明涉及一种机床,其根据程序驱动至少一个轴来进行工件加工,其中,所述机床具有:动作评价部,其评价所述机床的动作并输出评价数据;以及机械学习器,其对所述轴的移动量进行机械学习,所述机械学习器具有:状态观测部,其获取物理量数据以及从所述动作评价部输出的评价数据,其中,该物理量数据包含所述机床的至少所述轴的轴位置;回报计算部,其根据所述状态观测部获取到的所述物理量数据和所述评价数据来计算回报;移动量调整学习部,其根据所述轴的移动量的调整的机械学习结果、以及所述状态观测部获取到的所述物理量数据,来进行所述轴的移动量的调整;以及移动量输出部,其将所述移动量调整学习部调整后的所述轴的移动量进行输出,所述移动量调整学习部构成为:根据调整后的所述轴的移动量、基于所输出的所述轴的移动量而在所述机床的动作后由所述状态观测部获取到的所述物理量数据、以及所述回报计算部计算出的所述回报,来对所述轴的移动量的调整进行机械学习。
也可以是,所述回报计算部构成为在所述轴的合成速度增加时计算正回报,此外,在脱离由所述程序指令的指令路径的范围时计算负回报。
也可以是,所述机床与至少一个其他机床相连接,所述机床在与所述其他机床之间彼此交换或者共享机械学习的结果。
也可以是,所述移动量调整学习部构成为:使用调整后的所述轴的移动量以及评价函数来进行机械学习以使所述回报最大,其中,该评价函数是用自变量来表现由所述状态观测部获取到的所述物理量数据而得的函数。
本发明涉及一种模拟装置,其模拟根据程序驱动至少一个轴来进行工件加工的机床,其中,所述模拟装置具有:动作评价部,其评价所述机床的模拟动作并输出评价数据;以及机械学习器,其对所述轴的移动量进行机械学习,所述机械学习器具有:状态观测部,其获取模拟后的物理量数据以及从所述动作评价部输出的评价数据,其中,该模拟后的物理量数据包含所述机床的至少所述轴的轴位置;回报计算部,其根据所述状态观测部获取到的所述物理量数据和所述评价数据来计算回报;移动量调整学习部,其根据所述轴的移动量的调整的机械学习结果、以及所述状态观测部获取到的所述物理量数据,来进行所述轴的移动量的调整;以及移动量输出部,其将所述移动量调整学习部调整后的所述轴的移动量进行输出,所述移动量调整学习部构成为:根据调整后的所述轴的移动量、基于所输出的所述轴的移动量而在所述机床的模拟动作后由所述状态观测部获取到的所述物理量数据、以及所述回报计算部计算出的所述回报,来对所述轴的移动量的调整进行机械学习。
本发明涉及一种机械学习器,其对机床具有的至少一个轴的移动量的调整进行机械学习,其中,所述机械学习器具有:学习结果存储部,其存储所述轴的移动量的调整的机械学习结果;状态观测部,其获取包含所述机床的至少所述轴的轴位置在内的物理量数据;移动量调整学习部,其根据所述轴的移动量的调整的机械学习结果以及所述状态观测部获取到的所述物理量数据,来进行所述轴的移动量的调整;以及移动量输出部,其将所述移动量调整学习部调整后的所述轴的移动量进行输出。
根据本发明,通过将机械学习用于决定最佳的各轴移动量之中,能够以更短的时间实现维持了加工精度的工件加工。
附图说明
从参照附图的以下的实施例的说明中可以明确本发明的上述以及其他目的和特征。这些图中,
图1A以及图1B是表示通过本发明来使机床的加工路径最佳化的示例1以及示例2的图。
图2是说明强化学习算法的基本概念的图。
图3是与本发明的一实施方式涉及的机床的机械学习相关的图像视图。
图4是对在本发明的实施方式中处理的各数据进行说明的图。
图5是本发明的一实施方式涉及的机床的功能框图。
图6是对图5的机械学习器中的移动量调整学习部进行的机械学习的流程进行说明的流程图。
图7是本发明的一实施方式涉及的模拟装置的功能框图。
图8A以及图8B是对工件的加工过程中的允许误差进行说明的图。
图9A以及图9B是对脱离工具路径导致的问题进行说明的图。
具体实施方式
在本发明中,针对加工工件的机床导入作为人工智能的机械学习器,进行基于加工程序的工件加工中的与机床的各轴的移动量相关的机械学习,由此,如图1A以及图1B所示,调整成:使工件加工中的机床的各轴的移动量为最佳。在各轴的移动量的调整中,以更快的工具移动和不脱离对工具路径加上允许误差而得的范围为目的,由此,实现以更短的时间维持了加工精度的工件加工。
[1.机械学习]
一般地,机械学习根据有教师学习和无教师学习等其目的和条件而分类为各种各样的算法。在本发明中,以基于加工程序的工件加工中机床的各轴的移动量的学习为目的,考虑到明确地表示出针对基于输出的各轴的移动量的工具的移动路径进行怎样的行为(各轴的移动量的调整)是否正确是比较困难的,而采用只给予回报来由机械学习器自动学习用于达到目标的行为的强化学习算法。
图2是说明强化学习算法的基本概念的图。
在强化学习中,通过作为要进行学习的主体的智能体(机械学习器)与作为控制对象的环境(控制对象系统)之间的交换,而能够促进智能体学习和行为。更具体来说,
(1)智能体对某个时间点的环境状态st进行观测,
(2)根据观测结果和过去的学习来选择自己能获取的行为at并执行行为at,
(3)通过执行行为at环境状态st变化为下一状态st+1,
(4)根据作为行为at的结果的状态变化,智能体接受回报rt+1,
(5)在智能体与环境之间进行智能体根据状态st、行为at、回报rt+1、以及过去的学习结果来促进学习这样的交换。
在上述(5)的学习中,获得观测到的状态st、行为at、回报rt+1的映射(mapping),来作为智能体用于判断将来能获取的回报量的基准的信息。例如,设在各时刻能够获取的状态的个数为m、能够获取的行为的个数为n,则通过重复行为而获得存储针对状态st与行为at的组的回报rt+1的m×n的二维阵列。
然后,使用价值函数(评价函数)在重复行为过程中对价值函数(评价函数)进行更新由此学习针对状态的最佳行为,其中,上述价值函数是根据上述获得的映射来表示当前状态和行为有多好的函数。
“状态价值函数”是表示某个状态st是多好的状态的价值函数,表现为将状态作为自变量的函数,在重复行为的过程中的学习中,根据针对某个状态下的行为获得的回报、根据该行为而变化的未来的状态价值等来更新状态价值函数。根据强化学习的算法来定义状态价值函数的更新式,例如,在作为强化学习算法之一的TD学习中,用数学式(1)来定义状态价值函数。另外,在数学式(1)中,α是学习系数,γ是折扣率,其分别是0<α≤1、0<γ≤1的范围。
V(st)←V(st)+α[rt+1+γV(st+1)-V(st)]……(1)
此外,“行为价值函数”是表示在某个状态st下行为at是多好的行为的价值函数,表现为将状态和行为作为自变量的函数,在重复行为的过程中的学习中,根据针对某个状态下的行为而获得的回报、根据该行为而变化的未来状态的行为价值等来更新行为价值函数。根据强化学习的算法来定义行为价值函数的更新式,例如,在作为代表性的强化学习算法之一的Q学习中,用下述数学式(2)来定义行为价值函数。另外,在数学式(2)中,α是学习系数,γ是折扣率,其分别是0<α≤1、0<γ≤1的范围。
另外,在存储作为学习结果的价值函数(评价函数)的方法中,除了使用近似函数的方法和使用阵列的方法以外,例如还存在如下方法:在状态s获取较多状态的情况下,使用将状态st、行为at作为输入来输出价值(评价)的多值输出的SVM或神经元网络等有教师学习器的方法。
然后,在上述(2)中的行为选择中,使用根据过去的学习而制作出的价值函数(评价函数)来选择当前状态st下到将来的回报(rt+1+rt+2+…)最大的行为at(在使用状态价值函数的情况下,在使用了用于向价值最高的状态移动的行为、行为价值函数的情况下,在该状态下价值最高的行为)。另外,在智能体的学习中,以学习推进为目的,在上述(2)的行为选择中以一定概率来选择随机的行为(ε贪婪算法)。
这样,通过重复上述(1)~(5),学习得以推进。在某个环境下学习结束之后,即使置于新的环境下也能通过进行追加学习来推进学习以适应该环境。因此,像本发明这样将该学习应用于基于加工程序的工件加工中机床的各轴的移动量的决定中,由此,即使在制作新的加工程序时,通过对过去的工件加工中机床的各轴的移动量的学习进行将新加工程序作为新环境的追加学习,就能以短时间进行各轴的移动量的学习。
此外,在强化学习中,设为经由网络等连接多个智能体而成的系统,在这些智能体间共享状态s、行为a、回报r等信息来用于各学习,由此,各智能体能进行还考虑了其他智能体的环境来进行学习的分散强化学习,由此,能够进行高效的学习。本发明也通过在控制多个环境(成为控制对象的机床)的多个智能体(机械学习器)经由网络等连接的状态下进行分散机械学习,而能够高效地进行机床基于加工程序的工件加工中各轴的移动量的学习。
另外,作为强化学习的算法,公知有Q学习、SARSA法、TD学习、AC法等各种各样的方法,但也可以采用任意的强化学习算法来作为应用于本发明的方法。由于上述的各强化学习算法是众所周知的,因此本说明书中省略各算法的详细说明。
以下,根据具体的实施方式来对导入了机械学习器的本发明的机床进行说明。
[2.实施方式]
图3是表示与导入了本发明的一实施方式涉及的成为人工智能的机械学习器的机床的各轴的移动量的机械学习相关的图像示意图。另外,图3只示出了本实施方式涉及的机床中的机械学习的说明所必需的结构。
在本实施方式中,作为机械学习器20用于确定环境(“[1.机械学习]”所说明的状态st)的信息,将工具的行进方向、到脱离工具路径为止的距离、当前的各轴速度、当前的各轴加速度作为输入数据。这些各值是从机床的各部获取的数据、以及根据这些数据通过动作评价部3计算出的数据。
图4是对在本实施方式涉及的机床1的各数据进行说明的图。
在本实施方式涉及的机床1中,解析图4所示的加工程序而得的指令路径、以及与由操作员预先定义的指令路径相差的允许误差被存储于未图示的存储器中。在上述的输入数据中包含:从机床1获得的时刻t的各轴的轴位置(xt、zt)、各轴的移动速度(δxt-1、δzt-1)、各轴的加速度(δxt-1-δxt-2、δzt-1-δzt-2)等,除此之外,还包含各轴位置脱离对指令路径加上允许误差而得的范围为止的距离等那样,由动作评价部3根据上述各数据计算出的数据。
另外,在图4中示出了X-Z的二维坐标系的各输入数据的示例,但是在机床的各轴的数量是3轴以上时,通过与轴数量相符地适当增加输入数据的维数由此能够进行对应。
在本实施方式中,作为机械学习器20针对环境输出的行为(“[1.机械学习]”所说明的行为at),将下一瞬间(控制装置的控制周期中的本周期)的各轴的移动量作为输出数据。另外,在本实施方式中,设为将某个周期下输出的各轴的移动量由驱动各轴的伺服电动机在该周期内无延迟地消耗(移动)。因此,在以下将该移动量直接作为工具的移动速度来进行处理。
此外,在本实施方式中,作为对机械学习器20给予的‘回报’(“[1.机械学习]”所说明的回报rt),采用各轴的合成速度的提升(正回报)、向与指令相反方向的移动(负回报)、脱离工具路径(负回报)、超过最高速度(负回报)等。动作评价部3根据输入数据、输出数据等并根据各回报的达成程度来计算‘回报’。另外,关于根据某一数据来决定回报,可以是操作员根据机床1中加工程序涉及的加工内容来适当进行设定,例如,也可以是在钻孔加工中将未到孔底定义为负回报。
并且,在本实施方式中,机械学习器20根据上述的输入数据、输出数据以及回报进行机械学习。在机械学习中,在某个时刻t,根据输入数据的组合来定义状态st,针对该定义的状态st进行的移动量的输出为行为at,然后,作为通过该行为at进行了移动量输出的结果而新获得输入数据,根据该新获得的输入数据而评价计算出的值为回报rt+1,如在“[1.机械学习]”对这些状态st、行为at、回报rt+1进行说明那样,通过使用与机械学习算法对应的价值函数(评价函数)的更新式来推进学习。
这里,使用图5的功能框图来说明本发明的一实施方式涉及的机床。
本实施方式的机床1具有:在工件的加工过程中用于驱动各轴的伺服电动机等驱动部(未图示)、控制这些伺服电动机的伺服控制部(未图示)、周边设备(未图示)、对这些驱动部和周边设备进行控制的数值控制部2、根据从所述驱动部或该周边设备的动作或数值控制部2获取的各数据来评价机床的动作的动作评价部3、以及进行机械学习的作为人工智能的机械学习器20。
在将图5所示的机床的结构与图2所示的强化学习算法中的要素进行对比,包括图5的机床1标准具备的伺服电动机等驱动部、伺服控制部(未图示)、周边设备(未图示)以及控制部2等在内的整体对应于图2的强化学习算法中的“环境”,此外,图5的机床1具有的机械学习器20对应于图2的强化学习算法中的“智能体”。
数值控制部2对从未图示的存储器读出的、或者经由未图示的输入设备输入的加工程序进行解析,根据作为该解析结果而获得的控制数据来控制机床1的各部。数值控制部2通常进行基于加工程序的解析结果的控制,但是在本实施方式中,按照从机械学习器20输出的各轴的移动量,来进行驱动机床1的工具的各轴的控制。
数值控制部2构成为设定‘允许误差’,其中,该‘允许误差’表示允许工具相对于由加工程序指令的指令路径脱离的范围。‘允许误差’定义为相对于各指令路径的向各轴方向的距离、指令路径周围的区域。该‘允许误差’定义为以下(1)~(3)中的某一个或者由这些(1)~(3)的多个组合来定义:(1)作为常数值而存储于数值控制部内的非易失性存储器内,或者在加工开始前由机床操作员预先设定该常数值,(2)在加工程序内指令为加工指令的一部分,(3)预先设定给机床的可动范围、由用于固定工件的夹具的干涉等限制的可动范围。
动作评价部3根据从数值控制部2获取的机床1的各轴的轴位置、数值控制部2解析而得的加工程序指令的工具路径、由加工程序指令的工具的最高速度等,在各控制周期中对从机械学习器20输出的机床1的各轴的移动量进行评价,将该评价结果通知给机械学习器20。动作评价部3进行的行为的评价用于计算机械学习器20的学习中的回报。
作为评价行为的示例,列举有:基于机床1的各轴的移动量的移动方向,与从机床1的各轴的轴位置掌握的、工具当前位置附近的由加工程序指令的指令路径的移动方向之间的角度;工具当前位置脱离对指令路径加上允许误差而得的范围的程度;基于各轴的移动量的移动速度与工具当前位置附近的由加工程序指令的最高速度之间的差分等。但是只要能够对从机械学习器20输出的行为评价来评价优劣,也可以将任何指标用于评价。
进行机械学习的机械学习器20具有:状态观测部21、物理量数据存储部22、回报条件设定部23、回报计算部24、移动量调整学习部25、学习结果存储部26、以及移动量输出部27。机械学习器20可以设置于机床1内,也可以设置于机床1外的个人电脑等中。
状态观测部21经由数值控制部2对与机床1相关的物理量数据进行观测并获取到机械学习器20内,并且将动作评价部3进行的动作的评价结果获取到机械学习器20内。观测并获取的物理量数据中除了上述的各轴的轴位置、速度和加速度之外,还包含温度、电流、电压、压力、时间、转矩、力、消耗功率,还包括对各物理量进行运算处理而计算出的计算值等。此外,动作评价部3进行的动作的评价结果如上所述包括:指令路径与工具的移动方向之间的角度、工具当前位置脱离对工具路径加上允许误差而得的范围的程度、工具的移动速度与指令的最高速度之间的差分等。
物理量数据存储部22输入并存储物理量数据,将该存储的物理量数据输出到回报计算部24、移动量调整学习部25。输入到移动量调整学习部25的物理量数据可以是通过最新的加工运转而获取的数据、可以是通过过去的加工运转而获取的数据。此外,也可以将存储于其他机床40或集中管理系统30的物理量数据输入并存储于物理量数据存储部22,或者将物理量数据存储部22存储的物理量数据输出到其他的机床40或集中管理系统30。
回报条件设定部23在机械学习中设定给予回报的条件。在给予的回报中存在正回报和负回报,可以适当设定。并且,可以从集中管理系统所使用的个人电脑和平板终端等进行对回报条件设定部23的输入,但是通过设定为能够经由机床1所具有的MD I设备(未图示)进行输入,由此能够更简便地设定给予回报的条件。
回报计算部24根据回报条件设定部23设定的条件对从状态观测部21或者物理量数据存储部22输入的物理量数据进行解析,将计算出的回报输出至移动量调整学习部25。
以下,表示图5的机械学习器20中的由回报条件设定部23设定的回报条件的示例。
·[回报1:各轴的合成速度的提升(正回报、负回报)]
在各轴的合成速度比过去的各轴的合成速度提升时,导致加工的周期时间的提升,因此,对应于该速度提升的程度而给予正回报。
另一方面,在各轴的合成速度为通过指令而给予的最高速度或各轴的速度超过设定给机床1的各轴的最高速度时,由于导致机床1的故障等,因此对应于该速度超过的程度而给予负回报。
·[回报2:向与指令不同方向的移动]
鉴于基于机床1的各轴的移动量的工具的移动方向,与从机床1的各轴的轴位置掌握的、工具当前位置附近的由加工程序指令的指令路径的移动方向而构成的角度,在工具移动方向与由加工程序指令的指令路径有较大不同时,对应于其程度而给予负回报。作为负回报的示例,在工具移动方向与指令路径的移动方向而构成的角度比预定角度(例如±45度以内)大时,可以将预定系数乘以该差分而得的值作为负回报来进行给予,也可以设为在单纯地超过180度时(与指令路径的移动方向相反方向)给予负回报。
·[回报3:脱离工具路径]
对应于工具当前位置脱离对由加工程序指令的指令路径加上允许误差而得的范围的程度来给予负回报。该脱离的程度可以设定为工具当前位置与对指令路径加上允许误差而得的范围之间的距离量。
·[回报4:超过最高速度]
在工具移动速度超过了加工程序所指令的最高速度时,对应于其超过量而给予负回报。
返回到图5,移动量调整学习部25根据该移动量调整学习部25自身进行的机床1的各轴的移动量的调整结果、物理量数据存储部22存储的包含输入数据等的物理量数据、以及由回报计算部24计算出的回报,来进行机械学习(强化学习),并且,根据过去的学习结果,根据当前的物理量数据来进行各轴的移动量的调整。这里,所谓的各轴的移动量的调整相当于图2的强化学习算法中的、用于机械学习的“行为a”。
作为移动量的调整方法,例如也可以构成为:预先准备组合了各轴的正负方向的移动量的行为(行为1:(X轴移动量、Z轴移动量)=(1、0),行为2:(X轴移动量、Z轴移动量)=(2、0),…,行为n:(X轴移动量、Z轴移动量)=(δxmax、δzmax))作为能够选择的行为,根据过去的学习结果选择出将来获得的回报最大的行为。此外,还可以设为采用上述的ε贪婪算法,以预定的概率选择出随机行为来实现学习的推进。
在这里,在移动量调整学习部25进行的机械学习中,行为at为:通过某个时刻t的物理量数据的组合来定义状态st,对应于该定义的状态st来调整各轴的移动量通过后述的移动量输出部27输出该调整结果。然后,根据调整结果进行了机床1的各轴的移动,根据作为其结果而获取的数据,由回报计算部24计算出的值为回报rt+1。
对应于应用的学习算法来决定用于学习的价值函数。例如,在使用了Q学习时,设为按照上述的数学式(2)来更新行为价值函数Q(st、at),来推进学习即可。
使用图6的流程图来对图5的机械学习器20中的移动量调整学习部25进行的机械学习的流程进行说明。以下,对于各步骤进行说明。
[步骤SA01]在开始机械学习时,状态观测部21获取表示机床1的状态的物理量数据。
[步骤SA02]移动量调整学习部25根据状态观测部21获取的物理量数据确定当前的状态St。
[步骤SA03]移动量调整学习部25根据过去的学习结果和步骤SA02确定出的状态St来选择行为at(各轴的移动量的调整)。
[步骤SA04]执行由步骤SA03选择出的行为at。
[步骤SA05]状态观测部21获取表示机床1的状态的物理量数据,获取动作评价部3评价了机床1的状态而得的评价结果的数据。在该阶段,机床1的状态根据步骤SA04执行的行为at随着从时刻t向时刻t+1的时间推移而发生变化。
[步骤SA06]回报计算部24根据由步骤SA05获取的评价结果的数据来计算回报rt+1。
[步骤SA07]移动量调整学习部25根据步骤SA02确定出的状态St、步骤SA03选择出的行为at、步骤SA06计算出的回报rt+1、来推进机械学习,返回到步骤SA02。
学习结果存储部26对移动量调整学习部25学习而得的结果进行存储。此外,学习结果存储部26在移动量调整学习部25再次使用学习结果时,将存储的学习结果输出到移动量调整学习部25。在学习结果的存储中,如上所述,设定为通过近似函数、阵列、或者多值输出的SVM或神经元网络等有教师学习器等来存储对应于要利用的机械学习算法的价值函数即可。
另外,可以使学习结果存储部26输入并存储其他的机床40或集中管理系统30存储的学习结果,或者对其他的机床40或集中管理系统30输出在学习结果存储部26中存储的学习结果。
移动量输出部27将移动量调整学习部25进行的移动量的调整结果输出给数值控制部2。数值控制部2根据从移动量输出部27收到的各轴的移动量来驱动机床1的各轴。
然后,再次进行由动作评价部3进行的各轴的驱动结果的评价,通过机械学习器20来进行该评价结果和当前机床1的状况的获取,使用输入的物理量数据来重复学习,由此,能够获取更为优秀的学习结果。
像这样机械学习器20进行了学习的结果,在确认了图1A以及图1B所示的最佳的移动路径的阶段,机械学习器20进行的学习结束。遍布工具路径1圈收集由学习结束的机械学习器20输出的各轴的移动量(指令脉冲)而得的数据为工具的移动数据。
在使用上述学习结束的学习数据而实际在机床进行加工时,机械学习器20可以不进行新学习而是直接使用学习结束时的学习数据来重复进行运转。
此外,也可以将学习结束的机械学习器20(或者,将未图示的其他机械学习器结束的学习数据拷贝到学习结果存储部26的机械学习器20)安装于其他的机床40,直接重复使用学习结束时的学习数据来进行运转。
并且,在保持使该学习功能有效的状态下,将学习结束的机械学习器20安装于其他的机床40,继续工件的加工,由此,也可以进一步学习按机床而不同的个体差异或经年变化等,一边探索对于该机床来说更好的工具路径一边进行运转。
另外,如上所述在使用机床的数值控制部2进行学习动作时,该数值控制部2也可以实际上不使机床1动作而根据虚拟的工件加工处理来进行学习。此外,如图7所示,也可以设为对模拟装置4装入机械学习器20,由此根据该模拟部5进行的模拟结果来进行机械学习器20的学习动作,其中,该模拟装置4具有模拟其他机床动作的模拟部5。优选的是,在任何一情况下,在学习初期的阶段都不伴随实际的工件加工。
此外,也可以设定为机床1单独进行机械学习,但是在多个机床1还分别具有与外部之间的通信手段时,能够收发并共享各所述物理量数据存储部22存储的物理量数据和学习结果存储部26存储的学习结果,能够更高效地进行机械学习。例如,当使移动量在预定范围内变化来进行学习时,使在多个机床1中不同的操作条件在预定范围内分别变动来形成工件,并且在各机床1之间交换物理量数据和学习数据,由此并行地推进学习,从而能够高效地学习。
像这样在多个机床1之间进行交换时,可以经由集中管理系统30等主计算机进行通信,也可以直接与机床1进行通信,还可以使用云端,但是由于有时要处理大量数据,因此尽量优选通信速度快的通信手段。
以上,对本发明的实施方式进行了说明,但是本发明并不局限于上述实施方式的示例,通过追加适当的变更还能够以各种方式来进行实施。
- 还没有人留言评论。精彩留言会获得点赞!