一种基于非高斯相似度匹配的故障分类诊断方法与流程
本发明涉及一种故障诊断方法,特别涉及一种基于非高斯相似度匹配的故障分类诊断方法。
背景技术:
在工业自动化理论研究与应用实践的进程中,及时地检测出生产过程中发生的故障并正确的识别故障类型一直都是非常热门的一个话题。随着科学技术的飞速发展,现代大型复杂工业生产系统的精确机理模型难以获取,取而代之的是,可以轻易测量和存储的大量工业数据。近年来,这些海量的采样数据孕育出了各式各样的数据驱动的过程监测方法。虽然,数据驱动的故障检测方法层出不穷,但是,有效而实用的故障诊断方法却少有涉及。在现有的专利与文献中,利用不同故障类型的采样数据建立分类模型是一种常见的技术手段,例如判别分析算法、神经网络、支持向量机等。然而,这类方法只有在每种故障类型的训练数据充分的前提下,才可以建立可靠的分类模型。这在实际应用中是难以满足的,主要因为故障被检测出来后,操作人员通常会在第一时间内消除故障,数据采集系统就只能采集到有限的相关故障数据,而且这些故障数据处于过程运行状态转变的起始阶段,变化轨迹的非高斯特性较强。另一方面,这些分类模型用于在线故障数据分类判别时,每次只针对单个样本进行类型识别,对于重叠部分的数据会容易出现较多的错分类情况。因此,这类方法直接应用于生产实际还存在诸多的限制。
一般来讲,数据样本有限都是针对测量变量的个数而言的。比如,相对于现代工业过程数以百计的测量仪表而言,样本数需要达到几千个才可说数据量充分。考虑到不同故障发生后,会导致不同变量出现非正常变化,但不是所有测量变量都会受到影响。若是有针对性地为每种故障类型挑选出最能体现其故障特征的特征变量,那么不仅训练数据的变量维数就会大幅度减少,使样本数不充分对建立模型的制约性就大大降低,而且还能剔除非特征变量对模型分类的干扰影响。此外,现有文献与专利中提供了很多以独立元分析法(Independent Component Analysis,ICA)为代表的处理非高斯训练数据的方法,为应对参考故障数据的非高斯特性提供了相应技术手段。与此同时,针对不同故障类型数据间可能存在的重叠情况,若是采用多个数据样本组成的窗口数据集进行相似性匹配识别,可以将故障数据的变化轨迹考虑进来,从而降低重叠数据的错分类率。
技术实现要素:
针对上述问题,本发明提供一种基于非高斯相似度匹配的故障分类诊断方法。该发明方法首先利用正常过程数据的ICA模型对各个故障类型的训练数据进行投影变换;其次,对变换后的独立成分进行特征选择,挑选出最能体现各故障非正常变化的独立成分,并得到每种故障类型的特征集;然后,利用特征集实施在线故障窗口数据集与各参考故障窗口数据集 间的相似度匹配;最后,所识别出的故障类型决策为取得最大相似度值的参考故障类型。
本发明方法解决上述问题所采用的技术方案为:一种基于非高斯相似度匹配的故障分类诊断方法,包括以下步骤:
(1)收集生产过程正常运行状态下的采样数据,组成数据矩阵X0∈Rn×m,收集生产过程在不同故障操作状态下的采样数据,组成不同的参考故障数据集其中,n为训练样本数,m为过程测量变量数,下标号c=1,2,…,C表示第c种参考故障类型,Nc为第c种故障的可用样本数,R为实数集,Rn×m表示n×m维的实数矩阵。
(2)对矩阵X0进行标准化处理,得到均值为0,标准差为1的新数据矩阵并利用矩阵X0的均值向量与标准差向量对进行同样的处理,得到矩阵
(3)利用ICA算法对进行分析处理,得到分离矩阵W∈Rd×m与独立成分矩阵 其中d为保留的独立成分个数,上标号T表示矩阵或向量的转置。
(4)利用分离矩阵W将各参考故障数据矩阵转换成独立成分矩阵S1,S2,…,SC,并初始化c=1与i=1。
(5)按下式计算S0中第i个独立成分与Sc中第i个独立成分的变化差异:
上式中,与分别为矩阵S0与Sc中的第i列,符号||||表示计算向量的长度。
(6)令i=i+1,若满足条件i≤d,返回至步骤(5);反之,将得到的d个独立成分间的变化差异值组成向量Jc=[J1,J2,…,Jd]。
(7)再次初始化i=1后,从向量Jc中找出数值大于Q(Jc)的所有元素,将这些元素所对应的独立成分标号组成第c种参考故障类型的特征集Fc,并利用Fc从矩阵Sc中挑选出相应列组成新参考故障独立成分矩阵其中,Q(Jc)表示计算向量Jc的较大四分位数,即Jc中所有数值由小到大排列后第75%的数值。
(8)令c=c+1,若c≤C,返回至步骤(5);反之,保存得到的C个特征集F1,F2,…,FC以及新参考故障独立成分矩阵
(9)当在线检测到的故障数据样本数积累到w时,先利用矩阵X0的均值向量与标准差向量对该在线故障数据窗口矩阵Yw进行标准化处理得到后利用分离矩阵W将变换成独立成分矩阵
(10)先利用特征集F1,F2,…,FC对Zw分别进行特征选择得到矩阵后分别从各参考故障独立成分矩阵中选择前w行样本组成相应的参考故障窗口矩阵
(11)先分别计算两对应窗口矩阵与间的互信息相似度,得到然后将中的最大值所对应的参考故障类型判别为当前故障数据的故障类型,其中c=1,2,…,C。
(12)当在线检测出下一个故障数据样本时,数据窗口长度变为w=w+1,重复(9)~(11)再次识别故障类型。
与现有故障诊断方法相比,本发明方法的优点在于:
1.本发明方法首先利用ICA算法对各个参考故障数据集进行投影变换,利用了ICA算法处理非高斯过程数据的能力,这一步骤充分地考虑了各参考故障数据的非高斯特征。其次,该方法通过对比分析投影变换后故障数据集中每个独立成分的相对于正常数据各独立成分的变化情况,进而找出最能体现出各类参考故障非正常变化的特征集。然后,利用特征集对在线检测出的故障数据进行特征选择,不仅降低了变量维数使参考故障训练样本数较少的限制力大大缩减,而且还剔除了干扰成分对匹配分类的负面影响。
2.本发明方法采用了互信息相似度来匹配识别窗口数据的故障类型,相比于传统基于单个样本进行故障分类识别的方法,本发明所采取的窗口数据集匹配方式能包含多个连续样本的动态变化信息,将故障状态下的变化轨迹考虑进来。即使重叠样本数据存在于不同参考故障类型中,该基于窗口数据匹配的互信息相似度也能最大化地将其区分开来。
附图说明
图1为本发明方法的实施流程示意图。
图2为本发明方法中计算互信息值的实施流程示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
如图1所示,本发明公开了一种基于非高斯相似度匹配的故障分类诊断方法,该方法的具体实施步骤如下所示:
步骤1:收集生产过程正常运行状态下的采样数据,组成数据矩阵X0∈Rn×m,收集生产过程在不同故障操作状态下的采样数据,组成不同的参考故障数据集其中,n为训练样本数,m为过程测量变量数,下标号c=1,2,…,C表示第c种参考故障类型,Nc为第c种故障的可用样本数,R为实数集,Rn×m表示n×m维的实数矩阵。
步骤2:对矩阵X0进行标准化处理,得到均值为0,标准差为1的新数据矩阵并利用矩阵X0的均值向量与标准差向量对进行同样的处理,得到矩阵
步骤3:利用ICA算法对进行分析处理,得到分离矩阵W∈Rd×m与独立成分矩阵 其中d为保留的独立成分个数,上标号T表示矩阵或向量的转置,详细的实施过程如下所示:
①计算的协方差矩阵
②计算矩阵Φ的所有实数特征值和特征向量,并剔除小于0.0001的特征值及其对应的特征向量,得到特征向量组成的矩阵P=[p1,p2,…,pM]∈Rm×d以及相应特征值组成的对角矩阵D=diag(λ1,λ2,…,λd)∈Rd×d;
③对进行白化处理得到并初始化j=1;
④选取单位矩阵I∈Rd×d中的第j列作为向量bj的初始值;
⑤按照下式更新向量bj:
bj←E{Zg(bjTZ0)}-E{g′(bjTZ0)}bj (2)
上式中,g和g′分别是函数G(u)=log cosh(u)的一阶和二阶导数,u代表函数G的自变量,E{}表示求取期望值;
⑥对更新后的向量bj依次按照下式进行正交化处理:
bj←bj/||bj|| (4)
⑦重复步骤⑤~⑥直至向量bj收敛,并保存向量bj;
⑧令j=j+1,若j≤d,则返回至步骤④;反之,则将所有d个向量组成矩阵B=[b1,b2,…,bd];
⑨计算分离矩阵W=BTD-1/2PT与独立成分矩阵
步骤4:根据如下所示公式利用分离矩阵W对各参考故障数据矩阵进行投影变换:
对应可得到独立成分矩阵S1,S2,…,SC,并初始化c=1与i=1。
步骤5:按下式计算S0中第i个独立成分与Sc中第i个独立成分的变化差异:
上式中,与分别为矩阵S0与Sc中的第i列,符号||||表示计算向量的长度。
步骤6:令i=i+1,若满足条件i≤d,返回至步骤5;反之,将得到的d个独立成分间的变化差异值组成向量Jc=[J1,J2,…,Jd],并执行步骤7。
步骤7:再次初始化i=1后,从向量Jc中找出数值大于Q(Jc)的所有元素,将这些元素所对应的独立成分标号组成第c种参考故障类型的特征集Fc,并利用Fc从矩阵Sc中挑选出相应列组成新参考故障独立成分矩阵其中,Q(Jc)表示计算向量Jc的较大四分位数,即Jc中所有数值由小到大排列后第75%的数值,f表示矩阵的列数,也为特征集Fc中 标号的个数。
步骤8:令c=c+1,若c≤C,返回至步骤5;反之,保存得到的C个特征集F1,F2,…,FC以及新参考故障独立成分矩阵并执行步骤9。
步骤9:当在线检测到的故障数据样本数积累到w时,先利用矩阵X0的均值向量与标准差向量对该在线故障数据窗口矩阵Yw进行标准化处理得到后利用分离矩阵W将变换成独立成分矩阵
步骤10:先利用特征集F1,F2,…,FC对Zw分别进行特征选择得到矩阵后分别从各参考故障独立成分矩阵中选择前w行样本组成相应的参考故障窗口矩阵
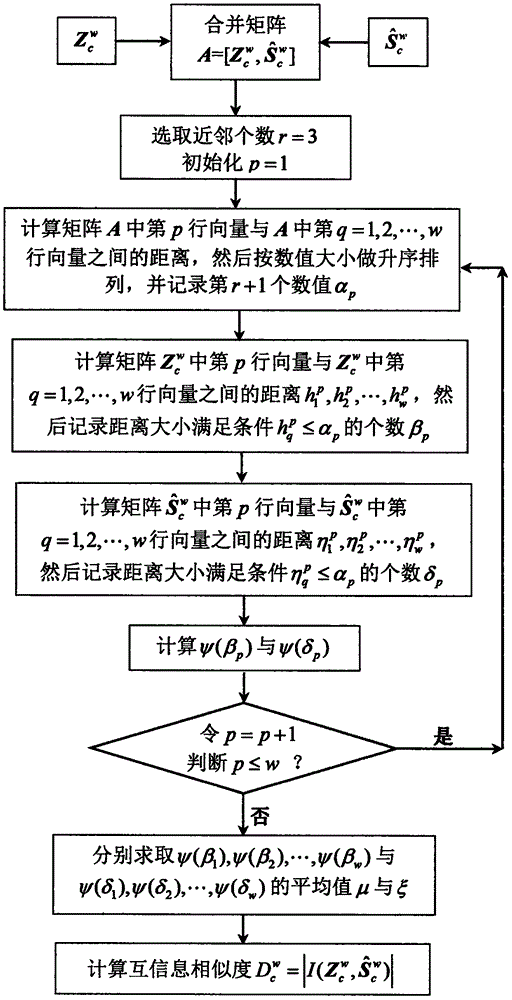
步骤11:先分别计算两对应窗口矩阵与间的互信息相似度,得到然后将中的最大值所对应的参考故障类型判别为当前故障数据的故障类型,其中c=1,2,…,C,计算互信息相似度的实施流程如图2所示,具体的步骤如下所示:
①将窗口矩阵与合并成成一个矩阵选取距离近邻个数r=3并初始化p=1,;
②计算矩阵A中第p行向量与A中第q=1,2,…,w行向量之间的距离,然后按数值大小做升序排列,并记录第r+1个数值αp;
③计算矩阵中第p行向量与中第q=1,2,…,w行向量之间的距离然后记录距离大小满足条件的个数βp;
④计算矩阵中第p行向量与中第q=1,2,…,w行向量之间的距离然后记录距离大小满足条件的个数δp;
⑤利用记录的βp与δp计算其相应的Digamma函数ψ(βp)与ψ(δp),其中Digamma函数满足条件ψ(x+1)=ψ(x)+1/x,x为函数自变量,当x=1时,ψ(1)=-0.57721…;
⑥令p=p+1,若p≤w,则返回至②;反之,则分别求取ψ(β1),ψ(β2),…,ψ(βw)与ψ(δ1),ψ(δ2),…,ψ(δw)的平均值,记为μ与ξ;
⑦按照下式计算窗口矩阵与间的互信息:
那么,窗口矩阵与间的相似度为
步骤12:当在线检测出下一个故障数据样本时,数据窗口长度变为w=w+1,重复步骤9~11再次识别故障类型。
- 还没有人留言评论。精彩留言会获得点赞!