一种基于果蝇优化和LSSVM的污水过程优化控制方法与流程
本发明属于污水处理领域,更具体地说,涉及一种污水处理优化控制方法。
背景技术:
随着人口数量的持续增长和现代工业的高速发展,对用水需求增加的同时伴随着水环境的严重污染,面对这一矛盾,污水处理成为了我国近年来基本建设投资的重点。现有的污水未经深度处理远远不能满足达标排放的标准,未达标的排放会对地下水资源产生巨大的污染并对环境产生深远的影响。基于环境保护和节约用水,节水的最重要环节就是污水的再利用,尽管全国648个城市已建设较为完备的污水处理厂,占全国城市的98.5%,但是根据最近的统计数据,全国各城市的平均污水处理率仅82.13%,某些城市的污水处理率连70%都无法达到。不难看出,这距离理想指标差距甚远。而运行负荷不足,使得近一半的污水处理厂出水水质超标或运行异常。可以看出,全国各大城市的污水处理厂的运行现状不容乐观。
污水处理过程是一个工艺复杂,具有强耦合、不确定、非线性和大滞后等特点的复杂系统。经过多年的建设,我国污水处理行业取得了一定的成绩,但落后的生产技术和粗放的管理使得大部分污水厂处理成本高、效率低。最突出的表现在相对较小的污水处理厂,因为仪表的准确性不好,设备运行调整迟缓导致出水水质会有些差异,可靠性和抗干扰能力不是很高。因此,如何保证污水处理厂出水水质合格,并在此前提下尽可能的降低能耗物耗并改善生产管理方式是现阶段需要迫切解决的问题。
技术实现要素:
本发明的目的是针对现有技术中所存在的不足,发明一种污水处理过程溶解氧和硝态氮基于果蝇优化和最小二乘支持向量机(LSSVM)模型控制方法和系统,通过采集污水过程数据,建立包含污水过程溶解氧和硝态氮系统模型,准确描述系统实时状态,采用果蝇算法进行滚动优化,将控制目标及各种约束体现在优化性能指标中,并根据实时数据在线更新模型。实现了污水处理过程的流程优化控制,能根据控制情况及时调整控制量,保证控制过程的稳定,而且能够根据过程的变化情况进行优化控制,使污水处理过程能耗降低。
设系统第k步柔化给定yr(k+j)和模型预测输出ym(k+j/k)的偏差为:
e(k+j)=yr(k+j)-ym(k+j/k) (1)
j=1,2,...,M为预测步长,优化控制器的任务是使用优化算法获得如式(2)所示的目标函数的最小值:
并且需要满足系统的控制约束和输出约束:
式(2)中,中下标min,max分别表示最小和最大值;Mp为最大预测长度;Nu为控制长度;λ为控制加权系数,当不满足约束时,γ=1,目标函数加上一个大的惩罚值C,满足约束时γ=0;yr(k+j)为经过柔化的参考给定:
式(4)中,Tr为参考轨迹时间常数;TS为采样时间;yd为设定值向量,yd,NO为硝态氮SNO,2的给定,yd,O为溶解氧SO,5的给定,α为滤波常数矩,k=1,2,…,np。
对应式(2)最小值的未来控制量为:
u(k+j)=(u1(k+j),u2(k+j),…,ul(k+j))T (5)
式(5)中,j=1,2,...,Nu,l为控制量的维数。
优化控制方法包括以下步骤:
步骤一、采集污水过程实时数据,通过标准的LSSVM学习算法离线获得包含污水过程溶解氧和硝态氮系统模型,并在过程控制器中编程实现
步骤二、采集过程实时数据,根据上一时刻的硝态氮浓度SNO,2(k-1)、上一时刻的溶解氧浓度SO,5(k-1)和给定yd计算k时刻的参考值yr(k),计算公式如式(4)所示,将实时采集过程数据送给模型输入。
步骤三、调用果蝇优化控制算法,代入步骤二中的参数,不断调用基于LSSVM的预测模型,计算目标函数适应值,得出目标函数最优控制量。
步骤四、果蝇优化控制器输出最优解。令k=k+1,进入下一采样时刻。如果更新间隔时间到,将最新采集的数据加入到训练集中,将相同时间长度的最老数据从训练集删除,根据模型误差情况通过新采集的滚动窗口数据通过LSSVM训练算法更新模型。
果蝇优化控制算法在每一采样时刻的具体工作步骤如下:
Step1:初始化。确定种群数量sizepop,最大迭代次数maxgen等算法参数,并对果蝇种群的初始位置(X1axis,Y1axis),(X2axis,Y2axis)在可行区间初始化。
Step2:嗅觉随机搜索。令初始代数g=0;设定迭代过程中果蝇个体在嗅觉觅食阶段的随机飞行方向的区间和搜索步长的区间,搜索步长RandomValue在搜索步长区间内随机产生,则有:
Step3:初步计算。在无法得知食物的具体坐标的情况下,只能通过计算个体与坐标原点的距离来求味道浓度的判定Si。具体公式如下:
其中如果其中a1,a2为范围系数。
Step4:计算个体的气味浓度值。令Qa(k)=S1i,kLa(k)=S2i将k时刻状态量(SNO,2(k),SO,5(k))、五号池的爆气量(氧转移系数kLa,5(k))和回流量Qa(k)代入预测模型(11)和味道浓度判断函数(2),计算每个果蝇个体的气味浓度值:
smelli=fitness(Qa(k),kLa,5(k)) (8)
Step5:根据气味浓度值,找出当前种群中气味浓度值最小的个体:
[bestSmell,bestindex]=min(smell) (9)
Step6:视觉定位。记录并保留最佳味道浓度值bestSmell和此时的最优果蝇个体的坐标,同时所有个体依赖视觉飞往最优个体的位置:
Smellbest=bestSmell
X1axis=X1(bestindex)
Y1axis=Y1(bestindex) (10)
X2axis=X2(bestindex)
Y2axis=Y2(bestindex)
Step7:迭代寻优。首先判断是否达到终止条件g=maxgen。当g<maxgen,则重复Step2到Step5。并判断此时最佳味道浓度值是否优于上一次迭代的最佳浓度值,若是则执行Step6,若否则进入下一轮迭代,直至g=maxgen,输出Qa(k)和kLa,5(k)。
采用支持向量机建立污水处理过程模型,采用两个控制量内回流流量(Qa),x1,曝气流量(kLa,5)x2以及进水化学需氧量(COD)x3、进水生化需氧量(BOD5)x4、进水悬浮固体浓度(SS)x5、进水总磷(TP)x6、进水氨氮(NH3-N)x7、进水总氮(TP)x8、进水水温x9、进水pH值x10、进水水量x11、悬浮物MLSSx12、氧化还原电位(ORP)x13作为输入变量,以上x3-x13过程变量如不能实时采集,则不纳入输入变量。对原始数据进行预处理,利用主元分析方法对样本属性进行降维,重构出新的训练样本集;构造输入变量Xk=[x1,k,x1,k-1,x2,k,x2,k-1,…,x13,k,x13,k-1],其中xi,k表示xi变量k时刻值,xi,k-1为前一时刻值。出水硝态氮浓度SNO,2和溶解氧SO,5以及出水COD、BOD5、SS、TN作为模型输出。
根据历史和实验数据,取时间窗口宽度k=1,2,…,N构成训练数据,通过支持向量学习得到输入输出模型,一步预测输出:
式中K(xi,x)核函数取径向基函数;b为偏置;θi=αi-αi*,αi和αi*为拉格朗日乘子,xi为支持向量,La为支持向量个数。多步预测输出可由一步预测输出往后递推得到。
在线运行到达更新周期后,将新采集的时间序列数据XN+j,j=1,2,…,p,p为更新时间周期数时,加入训练数据,舍弃老数据Xj,当时间窗口宽度误差和η为一预先确定的正数,启动更新后窗口数据对支持向量机训练,从而完成模型的在线更新和校正。
有益效果:本发明实现了污水处理过程的流程优化控制,能根据过程变化情况及时调整控制量,保证控制过程的稳定,而且能够根据过程的变化情况在线更新模型,进行优化控制,使污水处理过程能耗降低。
附图说明
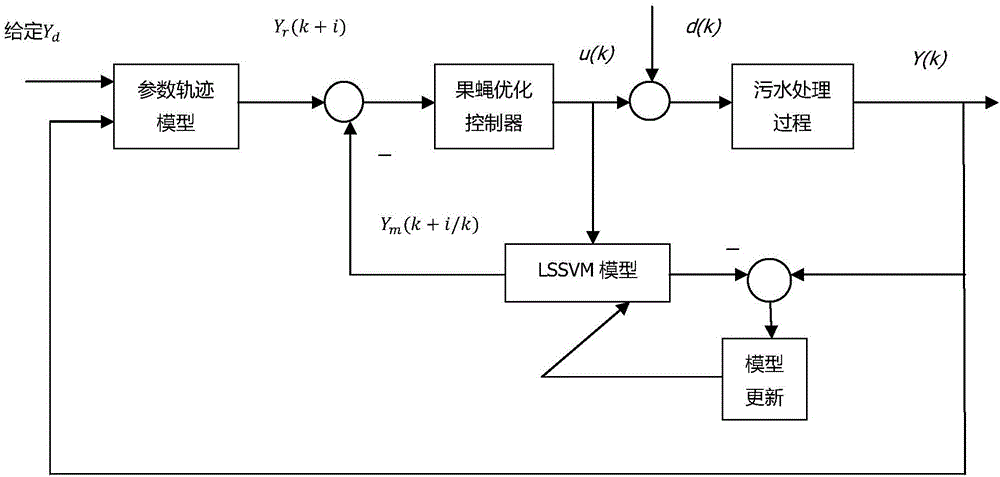
图1为本发明具体实施方式的污水处理系统结构方框示意图;图2为本发明具体实施方式的优化控制系统结构图。
具体实施方式
下面将结合具体的实施例来对本发明内容作进一步的说明。
如图1所示污水处理工艺,根据污水处理脱氮原理,污水中的有机物先在缺氧反应池水解为氨氮,然后在好氧反应池中转化为硝态氮,最后在缺氧反应池中反硝化成氮气。所以,为了衡量缺氧反应池中反硝化反应的情况,2号池中的硝态氮浓度成了一个重要的变量;另外,5号池出水的一部分需要回流至缺氧反应池,如果5号池中的溶解氧浓度过高会破坏缺氧反应池的环境,而过低会导致硝化反应不足,从机理的角度来看该变量的稳定是除氮过程稳定的前提,因此5号池溶解氧浓度成了另一个比较重要的变量。
为了达到良好的除氮效果,可以通过控制5号反应池中的氧转移系数使得5号池出水中的溶解氧含量达到需要值;另外,由于缺氧反应区中的硝态氮主要来自5号池的回流液,所以需要控制内回流液的流量从而稳定2号反应池出水中的硝态氮浓度。
果蝇算法是模拟果蝇觅食行为的仿生算法。它的结构比粒子群算法更加简单,参数更少,并具有记忆功能。虽然其稳定较差并且存在一定可能陷入局部最优解,但是其求解精度比粒子群算法更高,计算量比粒子群更少。预测控制中的优化算法应使用耗时短,参数选取简单的算法,而果蝇算法可以满足此要求。
基于果蝇优化的预测控制是通过最小二乘支持向量机(LSSVM)来获取污水过程的预测模型,并在每个采样时刻通过优化算法获取最优控制序列Uk。
设系统第k步柔化给定yr(k+j)和模型预测输出ym(k+j/k)的偏差为:
e(k+j)=yr(k+j)-ym(k+j/k) (12)
j=1,2,...,M为预测步长,优化控制器的任务是使用优化算法获得如式(2)所示的目标函数的最小值:
并且需要满足系统的控制约束和输出约束:
式(2)中,中下标min,max分别表示最小和最大值;Mp为最大预测长度;Nu为控制长度;λ为控制加权系数,当不满足约束时,γ=1,目标函数加上一个大的惩罚值C,满足约束时γ=0;在这里Mp=5,Nu=3,C=100000,yr(k+j)为经过柔化的参考给定:
式(4)中,Tr为参考轨迹时间常数,取值100;TS为采样时间,取值10;yd为设定值向量,yd,NO为硝态氮SNO,2的给定,yd,O为溶解氧SO,5的给定,α为滤波常数矩,k=1,2,…,np,这里np取为5。
对应式(13)最小值的未来控制量为:
u(k+j)=(u1(k+j),u2(k+j),…,ul(k+j))T (16)
式(15)中,j=1,2,...,Nu,l为控制量的维数,这里为2。
优化控制方法包括以下步骤:
步骤一、采集污水过程实时数据,通过标准的LSSVM学习算法离线获得包含污水过程溶解氧和硝态氮系统模型,并在过程控制器中编程实现
步骤二、采集过程实时数据,根据上一时刻的硝态氮浓度SNO,2(k-1)、上一时刻的溶解氧浓度SO,5(k-1)和给定yd计算k时刻的参考值yr(k),计算公式如式(15)所示,将实时采集过程数据送给模型输入。
步骤三、调用果蝇优化控制算法,代入步骤二中的参数,不断调用基于LSSVM的预测模型,计算目标函数适应值,得出目标函数最优控制量。
步骤四、果蝇优化控制器输出最优解。令k=k+1,进入下一采样时刻。如果更新间隔时间到,将最新采集的数据加入到训练集中,将相同时间长度的最老数据从训练集删除,根据模型误差情况通过新采集的滚动窗口数据通过LSSVM训练算法更新模型。
果蝇优化控制算法在每一采样时刻的具体工作步骤如下:
Step1:初始化。确定种群数量sizepop,取值为30,最大迭代次数maxgen为80等算法参数,并对果蝇种群的初始位置(X1axis,Y1axis),(X2axis,Y2axis)在变量范围[1,100]内随机初始化。
Step2:嗅觉随机搜索。令初始代数g=0;设定迭代过程中果蝇个体在嗅觉觅食阶段的随机飞行方向的区间和搜索步长的区间,搜索步长RandomValue在搜索步长区间内随机产生,这里区间取[0,10],则有:
Step3:初步计算。在无法得知食物的具体坐标的情况下,只能通过计算个体与坐标原点的距离来求味道浓度的判定Si。具体公式如下:
其中a1,a2为范围系数,取值为
Step4:计算个体的气味浓度值。令Qa(k)=S1i,kLa(k)=S2i将k时刻状态量(SNO,2(k),SO,5(k))、五号池的爆气量(氧转移系数kLa,5(k))和回流量Qa(k)代入味道浓度判断函数(13),根据模型计算预测输出,然后计算每个果蝇个体的气味浓度值:
smelli=fitness(Qa(k),kLa,5(k)) (19)
Step5:根据气味浓度值,找出当前种群中气味浓度值最小的个体:
[bestSmell,bestindex]=min(smell) (20)
Step6:视觉定位。记录并保留最佳味道浓度值bestSmell和此时的最优果蝇个体的坐标,同时所有个体依赖视觉飞往最优个体的位置:
Step7:迭代寻优。首先判断是否达到终止条件g=maxgen。当g<maxgen,则重复Step2到Step5。并判断此时最佳味道浓度值是否优于上一次迭代的最佳浓度值,若是则执行Step6,若否则进入下一轮迭代,直至g=maxgen,输出Qa(k)和kLa,5(k)。
采用支持向量机建立污水处理过程模型,采用两个控制量内回流流量(Qa),x1,曝气流量(kLa,5)x2以及进水化学需氧量(COD)x3、进水生化需氧量(BOD5)x4、进水悬浮固体浓度(SS)x5、进水总磷(TP)x6、进水氨氮(NH3-N)x7、进水总氮(TP)x8、进水水温x9、进水pH值x10、进水水量x11、悬浮物MLSSx12、氧化还原电位(ORP)x13作为输入变量,以上x3-x13过程变量如不能实时采集,则不纳入输入变量。对原始数据进行预处理,利用主元分析方法对样本属性进行降维,重构出新的训练样本集;构造输入变量Xk=[x1,k,x1,k-1,x2,k,x2,k-1,…,x13,k,x13,k-1],其中xi,k表示xi变量k时刻值,xi,k-1为前一时刻值。出水硝态氮浓度SNO,2和溶解氧SO,5以及出水COD、BOD5、SS、TN作为模型输出。
根据历史和实验数据,取时间窗口宽度k=1,2,…,N构成训练数据,通过支持向量学习得到输入输出模型,一步预测输出:
式中K(xi,x)核函数取径向基函数;b为偏置;θi=αi-αi*,αi和αi*为拉格朗日乘子,xi为支持向量,La为支持向量个数。多步预测输出可由一步预测输出往后递推得到。
在线运行到达更新周期后,将新采集的时间序列数据XN+j,j=1,2,…,p,p为更新时间周期数时,加入训练数据,舍弃老数据Xj,当时间窗口宽度误差和η为一预先确定的正数,根据符合要求的模型产生的平均误差进行选取,启动更新后窗口数据对支持向量机训练,从而完成模型的在线更新和校正。
上述具体实现只是本发明的较佳实现而已,当然,本发明还可有其他多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!