一种基于行为的多水下机器人路径规划方法与流程
本发明涉及一种基于行为的多水下机器人路径规划方法,是一种基于行为的多水下机器人协同信息采集的路径规划方法。
背景技术:
多水下机器人(multipleautonomousunderwatervehicles,简称mauv)是指由多个相对比较简单的同构或异构的auv通过某种形式的协同合作,最终可以共同完成特定的比较复杂的作业任务的系统。多水下机器人的并行性可以显著提高auv工作性能,缩短任务时间,并且通过系统中不同个体的协调来增加成功完成任务的可能性。此外,多水下机器人系统相比于单水下机器人具有效率更高、成本更低、灵活性高、鲁棒性强等优点。
发挥多水下机器人协作优势的关键是在系统中每个auv都被分配明确任务的前提下,通过既定的规划和控制策略,组成一个使不同auv自身进行作业任务的同时还能够兼顾与其他auv合作和协调的团队,通过发挥团队意识和协作精神最终完成复杂的任务。对于数据收集任务,auv需要安全地靠近分布在海洋中的节点进而通讯获得数据。在水下海洋环境中,为了自主完成数据收集任务,对于多水下机器人系统来说,有效的路径规划策略是非常有必要的。传统的多水下机器人路径规划方法大多只考虑auv执行任务时,不与其它auv发生碰撞,并未考虑auv与其他成员可能失去联系,从而不能完成协同任务。
本发明提出了一种适用于动态未知环境下基于行为的多水下机器人路径规划策略,通过定义基本行为来对auv的航行路径添加约束,之后建立行为目标函数和全局目标函数来解决协同信息采集过程中的安全和协作问题。本发明采用一种带有惯性权重的粒子群优化算法来求解全局目标函数,通过输出的最优解可以生成一条免于碰撞并且是最短的路径。
技术实现要素:
本发明的目的是为了提供一种在保证多个水下机器人协同完成数据收集任务的同时,使用最少的能耗的安全的路径规划算法。
本发明的目的是这样实现的:(1)定义3个基本行为用来约束auv的运动,保证在安全的前提下,auv的航行距离最短,并且实现与其它auv的协同;
(2)行为目标函数与基本行为对应,是基本行为的具体数学化,定义在auv的决策空间中,并要保证函数的收敛性;
(3)全局目标函数考虑到了3个基本行为的综合影响,利用带有惯性权重的粒子群优化算法来求解不同时刻全局目标函数的最优解,不同时刻全局目标函数的最优解组成auv的路径轨迹。
本发明还包括这样一些结构特征:
1.所述3个基本行为的目标函数具体为:
路径规划的环境设置为二维平面,u为t时刻auv的速度大小,θ为当前的艏向角,(xt,yt)为该时刻的位置坐标,δt为时间间隔,auv的决策输出包括速度和艏向角,假设(fx,fy)为下一时刻auv的位置坐标,得到:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
a、节能目标函数f1(θ,u,t)为:
其中:(xs,ys)为目标点的位置坐标,d1为下一时刻auv与目标点间的欧氏距离,s1和s2是放缩系数;
b、协同目标函数f2(θ,u,t)为:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
其中:(fbx,fby)为与该auv距离最近的auv下一时刻的位置,d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围,s1和s2是放缩系数,m2为设定的常值;
c、安全行为目标函数f3(θ,u,t)为:
其中:(xo,yo)为障碍物点的位置坐标,d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值,m3为设定的常值。
2.所述建立并求解全局目标函数的过程如下:
全局目标函数具体的形式为:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中:ω1,ω2,ω3是可变化的权重系数,将3种行为按照相对重要程度排序为安全行为、协同行为和节能行为,并设置3个权重系数,全局目标函数中具有2个空间变量θ和u、1个时间变量t;
在t时刻,利用带有惯性权重的粒子群优化算法,得到全局目标函数的最优解的具体步骤如下:
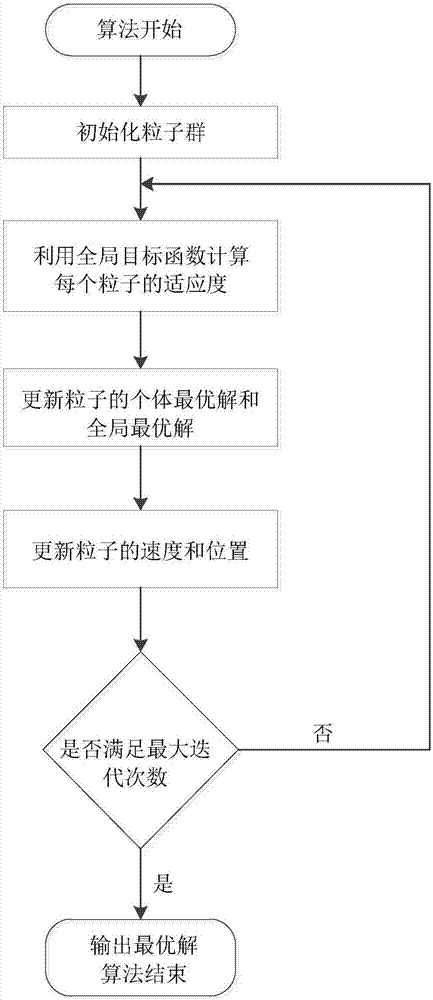
步骤1:利用带有惯性权重的粒子群优化算法求解生成的全局目标函数,算法开始;
步骤2:初始化带有惯性权重的粒子群优化算法参数,包括设置搜索空间为二维空间,其中姿态角空间取值范围为[θ0-θmax,θ0+θmax],速度空间取值范围为[0,umax],其中:θ0为auv当前时刻姿态角,θmax为auv最大转角能力,umax为auv的最大航行速度;群体规模为n,设置各个粒子的初始位置和速度;
步骤3:利用全局目标函数作为适应度函数,计算每个粒子的适应度;
步骤4:更新粒子的个体最优解和全局最优解:
每个粒子所处的位置都表示二维解空间中的一个解,解的质量由适应值决定,某一粒子i在二维空间的位置表示为矢量xi=(θi,ui),粒子通过不断调整自己的位置来搜索新解,每个粒子都能记住自己搜索到的最优解,记作pid;以及整个粒子群经历过的最好的位置,即目前搜索到的最优解,记作pgd;
步骤5:更新粒子的位置和速度:
粒子具有飞行速度,飞行速度可以表示为矢量
其中,vik+1表示第i个粒子在k+1次迭代中的速度,c0为惯性权重,c1和c2为加速常数,rand()为0到1之间的随机数;
对于惯性权重c0,利用先增后减惯性权重的惯性权重确定方法为:
式中,maxnumber为算法的最大迭代次数。
步骤6:判断是否已经达到最大迭代次数,如果达到最大迭代次数,输出最优解,算法结束;否则,算法的迭代次数加1,返回步骤3。
3.所述计算每个粒子的适应度是指得到每个粒子的适应值,每个粒子都有一个由目标函数决定的适应值,适应值直接设置为全局目标函数f(θ,u,t)。
与现有技术相比,本发明的有益效果是:本发明定义了auv的3种基本行为,包括节能行为、安全行为和协同行为,并建立了基本行为相对应的局部目标函数,从而来约束auv的航行,并可以实现与其它auv协同航行的目的。最后建立全局目标函数,并利用带有惯性权重的粒子群优化算法进行求解,通过利用先增后减惯性权重的惯性权重确定方法,比一般的粒子群优化算法具有更快的收敛能力和更好的局部收敛速度。
附图说明
图1是本发明提出的多水下机器人路径规划方法示意图;
图2是本发明中的粒子群优化算法的流程示意图;
图3是本发明中auv在时间和空间运动示意图;
图4是本发明中粒子位置改变的示意图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述。
一种基于行为的多水下机器人路径规划方法,包括:
1、定义3个基本行为用来约束auv的运动,保证在安全的前提下,auv的航行距离最短,并且实现与其它auv的协同。
2、行为目标函数与基本行为对应,是基本行为的具体数学化,定义在auv的决策空间中,并要保证函数的收敛性。
3、全局目标函数考虑到了3个基本行为的综合影响,利用带有惯性权重的粒子群优化算法来求解不同时刻全局目标函数的最优解,不同时刻全局目标函数的最优解组成auv的路径轨迹,
所述3个行为目标函数具体为:
路径规划的环境设置为二维平面,u为t时刻auv的速度大小,θ为当前的艏向角,(xt,yt)为该时刻的位置坐标,δt为时间间隔,auv的决策输出包括速度和艏向角。假设(fx,fy)为下一时刻auv的位置坐标,可以得到下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1)节能目标函数可以表示为:
(xs,ys)为目标点的位置坐标为,d1为下一时刻auv与目标点间的欧氏距离。其中s1和s2是放缩系数。
2)协同目标函数可以表示为:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)为与该auv距离最近的auv下一时刻的位置,d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围,s1和s2是放缩系数,m2为设定的常值。
3)安全行为目标函数可以表示如下:
(xo,yo)为障碍物点的位置坐标,d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值,m3为设定的常值。
所述建立并求解全局目标函数的过程如下:
全局目标函数具体的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可变化的权重系数。将3种行为按照相对重要程度排序为安全行为、协同行为和节能行为,按照这个原则来设置3个权重系数。全局目标函数中具有2个空间变量θ和u,1个时间变量t。
在t时刻,下面利用带有惯性权重的粒子群优化算法,来求全局目标函数的最优解,具体步骤如下:
步骤1:利用带有惯性权重的粒子群优化算法求解生成的全局目标函数,算法开始;
步骤2:初始化带有惯性权重的粒子群优化算法参数,包括设置搜索空间为二维空间,其中姿态角空间取值范围为[θ0-θmax,θ0+θmax],速度空间取值范围为[0,umax],这里θ0为auv当前时刻姿态角,θmax为auv最大转角能力,umax为auv的最大航行速度;群体规模为n,设置各个粒子的初始位置和速度;
步骤3:利用全局目标函数作为适应度函数,计算每个粒子的适应度。每个粒子都有一个由目标函数决定的适应值(fitnessvalue),这里适应值可以直接设置为全局目标函数f(θ,u,t);
步骤4:更新粒子的个体最优解和全局最优解。每个粒子所处的位置都表示二维解空间中的一个解,解的质量由适应值决定,适应度越大,解的质量越好。某一粒子i在二维空间的位置表示为矢量xi=(θi,ui),粒子通过不断调整自己的位置来搜索新解,每个粒子都能记住自己搜索到的最优解,记作pid;以及整个粒子群经历过的最好的位置,即目前搜索到的最优解,记作pgd;
步骤5:更新粒子的位置和速度。粒子具有飞行速度,从而可以调整自己的位置。飞行速度可以表示为矢量
其中,vik+1表示第i个粒子在k+1次迭代中的速度,c0为惯性权重,c1和c2为加速常数,rand()为0到1之间的随机数;
对于惯性权重c0,利用先增后减惯性权重的惯性权重确定方法,该方法在迭代的初期,具有较快的收敛速度;在迭代的后期,具有较好的局部搜索能力,具体方法如下式所示:
式中,maxnumber为算法的最大迭代次数。
步骤6:判断是否已经达到最大迭代次数,如果达到最大迭代次数,输出最优解,算法结束。否则,算法的迭代次数加1,返回步骤3。
下面结合附图对本发明进行详细描述:
如图1所示,本发明提出的一种基于行为的多水下机器人路径规划方法,主要包含以下部分:3个基本行为,分别是节能行为、协同行为和安全行为;与3个基本行为对应的行为目标函数;通过3个行为目标函数生成的全局目标函数,并对全局目标函数进行求解。3个基本行为用来约束auv的运动,保证在安全的前提下,auv的航行距离最短,并且实现与其它auv的协同。行为目标函数分别是对应3个基本行为的具体数学化,行为目标函数需要定义在auv的决策空间中,并要保证函数的收敛性。全局目标函数考虑到了3个基本行为的综合影响,不同时刻全局目标函数的最优解组成auv的路径轨迹,本发明利用带有惯性权重的粒子群优化算法来求解不同时刻全局目标函数的最优解。
(1)所述的基本行为通过以下方式定义:
路径规划的环境设置为二维平面,建立环境地图的全局坐标系o-xy。如图1所示,当auv获取需要的周围环境信息后,这些信息包括目标点的位置,其它auv的位置速度大小和艏向角,以及障碍物位置信息。在这里,u为t时刻auv的速度大小,θ为当前的艏向角,(xt,yt)为该时刻的位置坐标,δt为时间间隔,auv的决策输出包括速度和艏向角,如图3所示为auv在时间和空间上的运动示意图。
假设(fx,fy)为下一时刻auv的位置坐标,可以表示为下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1.1)节能行为
考虑到auv工作时的能源有限,为了简化问题,本发明只考虑航行距离的影响,并且认为,航行距离越短,节能性越好。为了定义节能行为,可以对auv的航行条件添加一些约束,并把约束条件定为auv与目标点的距离。
d1为下一时刻auv与目标点间的欧氏距离,节能行为在整个任务过程中一直处于激活状态。将auv与目标点的距离对应到具体的决策空间,利用auv的姿态角、速度以及时间变量可以将d1表示如下:
d1=d1(θ,u,t)
1.2)协同行为
考虑到实际水下传感器以及通讯手段的限制,在保证安全的前提下,协同行为要求的数学形式可以表示如下:
dmin<d2<dmax
d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围。以上述公式为协同行为处于激活状态的条件,利用auv的姿态角、速度以及时间变量可以将d2表示如下:
d2=d2(θ,u,t)
1.3)安全行为
安全行为的数学形式可以表示如下式:
d3>dmin
d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值。利用auv的姿态角、速度以及时间变量可以将d3表示如下式:
d3=d3(θ,u,t)
(2)建立局部目标函数:
2.1)节能目标函数
与节能行为相对应,节能目标函数的变量是auv与目标点的距离d1。对于节能目标函数来说,d1的值越小,说明auv越接近目标点。在时间间隔δt确定时,距离d1与auv速度和艏向角有关。对d1进行度量处理,得到节能性的目标函数具体形式如下式:
式中s1和s2是放缩系数。
2.2)协同目标函数
与协同行为对应,协同目标函数的变量值是auv与其他成员的距离,在执行任务的过程中,各个auv之间应该保持协同作业,这里表现为auv与系统中最近的成员距离要处于一个阈值[dmin,dmax]范围内。最终的协同目标函数如下式所示:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)为与该auv距离最近的auv下一时刻的位置,d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围,s1和s2是放缩系数,m2为设定的常值。
2.3)安全目标函数
安全行为的激活需要满足一定的限制条件,具体体现为auv与障碍物的距离阈值ds。最终的安全行为目标函数如下式所示:
(xo,yo)为障碍物点的位置坐标,d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值,m3为设定的常值。
(3)所述的全局目标函数建立方法和求解过程如下:
全局目标函数的作用是实现之前一系列基本行为的协调,全局目标函数具体的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可变化的权重系数。将3种行为按照相对重要程度排序为安全行为、协同行为和节能行为,按照这个原则来设置3个权重系数。全局目标函数中具有2个空间变量θ和u,1个时间变量t。
在t时刻,利用带有惯性权重的粒子群优化算法,来求全局目标函数的最优解,函数输出为空间变量θ和u。如图2所示,具体步骤如下:
步骤1:利用带有惯性权重的粒子群优化算法求解生成的全局目标函数,算法开始;
步骤2:初始化带有惯性权重的粒子群优化算法参数,包括设置搜索空间为二维空间,其中姿态角空间取值范围为[θ0-θmax,θ0+θmax],速度空间取值范围为[0,umax],这里θ0为auv当前时刻姿态角,θmax为auv最大转角能力,umax为auv的最大航行速度;群体规模为n,设置各个粒子的初始位置和速度。
步骤3:利用全局目标函数作为适应度函数,计算每个粒子的适应度。每个粒子都有一个由目标函数决定的适应值(fitnessvalue),这里适应值设置为全局目标函数f(θ,u,t)。
步骤4:更新粒子的个体最优解和全局最优解。每个粒子所处的位置都表示二维解空间中的一个解,解的质量由适应值决定,适应度越大,解的质量越好。某一粒子i在二维空间的位置表示为矢量xi=(θi,ui),粒子通过不断调整自己的位置来搜索新解,每个粒子都能记住自己搜索到的最优解,记作pid;以及整个粒子群经历过的最好的位置,即目前搜索到的最优解,记作pgd。
步骤5:更新粒子的位置和速度。粒子具有飞行速度,从而可以调整自己的位置。飞行速度可以表示为矢量
式中,vik+1表示第i个粒子在k+1次迭代中的速度,c0为惯性权重,c1和c2为加速常数,rand()为0到1之间的随机数。
对于惯性权重c0,利用先增后减惯性权重的惯性权重确定方法,该方法在迭代的初期,具有较快的收敛速度;在迭代的后期,具有较好的局部搜索能力,具体方法如下式所示:
式中,maxnumber为算法的最大迭代次数。
步骤6:判断是否已经达到最大迭代次数,如果达到最大迭代次数,输出最优解,算法结束。否则,算法的迭代次数加1,返回步骤3。
当算法达到最大迭代次数时便会终止;此时输出最优解,即整个粒子群经历过的最好的位置pgd,该位置对应的矢量xi=(θi,ui)代表auv在时刻t应该输出的姿态角和速度。最后,利用不同时刻粒子群优化算法输出的最优解对应的姿态角和速度,可以生成auv最后的路径。
(1)定义基本行为:
路径规划的环境设置为二维平面,建立环境地图的全局坐标系o-xy。当auv获取需要的周围环境信息后,这些信息包括目标点的位置,其它auv的位置速度大小和艏向角,以及障碍物位置信息。在这里,u为auv的速度大小,θ为艏向角,(xt,yt)为t时刻的位置坐标,δt为时间间隔,auv的决策输出包括速度和艏向角。
假设(fx,fy)为下一时刻auv的位置坐标,可以表示为下式:
fx=xt+u·δt·cosθ
fy=yt+u·δt·sinθ
1.1)节能行为
考虑到auv工作时的能源有限,为了简化问题,本发明只考虑航行距离的影响,并且认为,航行距离越短,节能性越好。为了定义节能行为,可以对auv的航行条件添加一些约束,并把约束条件定为auv与目标点的距离。d1为下一时刻auv与目标点间的欧氏距离,节能行为在整个任务过程中一直处于激活状态。将auv与目标点的距离对应到具体的决策空间,利用auv的姿态角、速度以及时间变量可以将d1表示如下:
d1=d1(θ,u,t)
1.2)考虑到实际水下传感器以及通讯手段的限制,在保证安全的前提下,协同行为要求的数学形式可以表示如下:
dmin<d2<dmax
d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围。以上述公式为协同行为处于激活状态的条件,利用auv的姿态角、速度以及时间变量可以将d2表示如下:
d2=d2(θ,u,t)
1.3)安全行为数学形式可以表示如下:
d3>dmin
d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值。利用auv的姿态角、速度以及时间变量可以将d3表示如下:
d3=d3(θ,u,t)
(2)建立局部目标函数:
2.1)节能目标函数
与节能行为相对应,节能目标函数的变量是auv与目标点的距离。假设目标点的位置坐标为(xs,ys),d1可以表示为式:
对于节能目标函数来说,d1的值越小,说明auv越接近目标点。在时间间隔δt确定时,这个距离与auv速度和艏向角有关。对d1进行度量处理,得到节能性的目标函数具体形式如下式:
其中s1和s2是放缩系数。
2.2)协同目标函数
与协同行为对应,协同目标函数的变量值是auv与其他成员的距离,在执行任务的过程中,各个auv之间应该保持协同作业,这里体现为auv与系统中最近的成员距离要处于一个阈值[dmin,dmax]范围内。最终的协同目标函数如下式所示:
fbx=xb+ub·δt·cosθb,fby=yb+ub·δt·cosθb
(fbx,fby)为与该auv距离最近的auv下一时刻的位置,d2为下一时刻的两个auv的欧氏距离,[dmin,dmax]为d2的期望取值范围,s1和s2是放缩系数,m2为设定的常值。
2.3)安全目标函数
安全行为的激活需要满足一定的限制条件,具体体现为auv与障碍物的距离阈值ds。最终的安全行为目标函数如下式所示:
(xo,yo)为障碍物点的位置坐标,d3为auv与障碍物下一时刻的欧氏距离,ds为距离d3的安全阈值,s1和s2是放缩系数,m3为设定的常值。
(3)建立并求解全局目标函数:
全局目标函数的作用是实现之前一系列基本行为的协调,具体的形式如下式所示:
f=f(θ,u,t)=ω1f1+ω2f2+ω3f3
式中,ω1,ω2,ω3是可变化的权重系数。将3种行为按照相对重要程度排序为安全行为、协同行为和节能行为,按照这个原则来设置3个权重系数。全局目标函数中具有2个空间变量θ和u,1个时间变量t。
下面利用带有惯性权重的粒子群优化算法,在t时刻,来求全局目标函数的最优解。
3.1)路径规划参数、带有惯性权重的粒子群优化算法参数初始化
设置搜索空间为二维空间,其中姿态角空间取值范围为[θ0-θmax,θ0+θmax],速度空间取值范围为[0,umax],这里θ0为auv当前时刻姿态角,θmax为auv最大转角能力,umax为auv的最大航行速度。群体规模为n,设置各个粒子的初始位置和速度;
3.2)利用粒子对路径进行优化:
算法初始化之后,进入算法的主体迭代优化过程;粒子群算法是通过个体间的协作和竞争,实现复杂空间中最优解的搜索。某一粒子i在二维空间的位置表示为矢量xi=(θi,ui),每个粒子所处的位置都表示二维解空间中的一个解。粒子通过不断调整自己的位置来搜索新解,每个粒子都能记住自己搜索到的最优解,记作pid;以及整个粒子群经历过的最好的位置,即目前搜索到的最优解,记作pgd。
粒子具有飞行速度,从而可以调整自己的位置。飞行速度可以表示为矢量
式中,vik+1表示第i个粒子在k+1次迭代中的速度,c0为惯性权重,c1和c2为加速常数,rand()为0到1之间的随机数。
之后判断是否已经达到最大迭代次数,如果达到最大迭代次数则进入下一步;否则,算法的迭代次数加1,继续进行下一步优化过程。
3.3)输出最优解
当算法达到最大迭代次数时便会终止;此时输出最优解,即整个粒子群经历过的最好的位置pgd,该位置对应的矢量xi=(θi,ui)代表auv在时刻t应该输出的姿态角和速度。
最后,利用不同时刻粒子群优化算法输出的最优解对应的姿态角和速度,可以形成auv最后的路径。
综上,本发明提出一种基于行为的多水下机器人路径规划方法,属于路径规划技术领域。
本发明提出了一种适用于动态未知环境下的多水下机器人路径规划策略,具体包括:首先,定义基本行为来对auv的航行路径添加约束,基本行为分别为节能行为、协同行为和安全行为;然后,建立与基本行为对应的行为目标函数,将与auv有关的时间变量和空间变量结合起来;最后,建立全局目标函数来实现3种基本行为的行为融合,并采用一种带有惯性权重的粒子群优化算法来求解全局目标函数,通过输出的最优解可以生成一条免于碰撞并且是最短的路径。
- 还没有人留言评论。精彩留言会获得点赞!