一种基于粒子群优化核独立元分析模型的故障检测方法与流程
本发明涉及一种工业过程故障检测方法,尤其是涉及一种基于粒子群优化核独立元分析模型的故障检测方法。
背景技术:
近年来,随着计算机技术的飞速发展与广泛应用,现代化的工业过程已逐步走向“大数据时代”。工业过程尤其是流程工业过程拥有了相当丰富的生产数据资源,为数据驱动的故障检测研究提供了充实的数据基础。通常来讲,数据驱动的故障检测方法不需要过程对象精确的机理模型,只需针对过程正常运行的采样数据进行分析,定义出一个描述正常数据波动范围的区域,即可实施在线故障检测。多变量统计分析算法(如主元分析、偏最小二乘、独立元分析算法)在这一领域中受到了广泛的关注与研究,各种改进的新型算法层出不穷。以独立元分析(independentcomponentanalysis,ica)为例,针对采样数据间的相关性,目前有基于动态ica模型的故障检测方法;针对过程数据的非线性特性,可以采用核ica(kernelica,kica)算法建立非线性非高斯的故障检测模型。相比于主元分析法,ica因为在提取独立元的过程中考虑了数据的高阶统计信息,可以处理非高斯分布的数据对象。而现代工业过程因其自身的复杂性,采样数据通常是不满足高斯分布的。因此,ica算法更适合于监测现代工业过程对象。
在目前被广泛使用的ica求解算法中,fastica算法因其迭代求解过程简单快速而得到了使用者们的青睐。然而,已有研究文献指出,fastica算法由于利用了牛顿迭代法的原理,遇到二次凸函数时容易陷入局部最优值。若初始值设置不当,fastica算法还有可能不收敛。另外,fastica算法通常要求先利用主元分析对数据进行白化处理,并且假设白化后的数据是较好的独立元初始值。为了克服这些缺点,国内学者提出利用粒子群优化(particleswarmoptimization,pso)算法取代fastica算法中采用牛顿迭代法,可直接用于分析原始过程数据。它保证了优化算法能够收敛到全局最优点,并在实际应用中取得了满意的效果。这种pso-ica算法虽然克服了牛顿迭代法的缺点,但是却比牛顿法更加耗时。可幸的是,将pso-ica用于故障检测时,因只在离线建模阶段涉及求解独立元,算法的时效性不会限制它应用于故障检测。可是,pso-ica算法依旧是线性变换算法,无法有效地挖掘非线性过程数据的有用信息。传统的kica算法虽然能处理非线性数据,但是从kica建模过程来讲,它其实是先利用核主元分析对数据进行白化处理后,再实施fastica迭代求取独立元。若是简单地将pso-ica算法用于处理核主元分析白化后的数据,一方面导致所提取的独立元并非直接由原始数据而来,另一方面还会增加相应计算耗时。因此,这种非线性扩展的方式是不可取的,还违背了pso-ica算法可直接用于分析原始数据的初衷。
另一种可行的思路是直接将pso-ica算法应用于处理非线性数据,这就需要利用核学习技巧。在处理非线性过程数据的建模方法中,核学习技巧可谓是最常见的,也是最简单实用的。例如,主元分析算法就是借鉴核学习而扩展成能处理非线性数据的核主元分析法。核学习技巧的基本原理是通过构造内积而避免确定非线性映射函数的具体形式。也就是说,利用核学习方法,我们不知道原始数据非线性映射后的结果,只知道他们的内积。若pso-ica算法利用核学习技巧,关键的技术难点在于如何构造原始数据经非线性映射后的内积。可以想象的是,基于核学习的pso-ica算法是一种直接型的非高斯非线性建模方法。它不需要数据的白化预处理,可以直接针对原始数据提取出非线性的独立元并建立相应的模型。这一点对于有效地定义正常数据的活动区域是有直接意义的,相应故障检测模型检测效果也会得到显著的改善。
技术实现要素:
本发明所要解决的主要技术问题是:如何利用核学习技巧将pso-ica算法扩展成能直接处理非线性过程数据的建模方法并基于此建立相应的故障检测模型。本发明解决上述技术问题所采用的技术方案为:一种基于粒子群优化核独立元分析模型的故障检测方法,包括以下步骤:
(1)从生产过程的历史数据库中找出该过程对象在正常运行状态下的采样数据组成训练数据矩阵x∈rn×m,并对x中每个变量进行标准化处理,得到均值为0,标准差为1的新矩阵
(2)设置核函数参数c=5m后,按照下式计算核矩阵k∈rn×n中的第(i,j)个元素:
上式中,下标号i=1,2,…,n与j=1,2,…,n,exp表示以自然常数e(约为2.71828)为底的指数函数,符号||||表示计算向量的长度。
(3)依据如下公式对矩阵k进行中心化处理,即:
上式中,方阵l∈rn×n中各元素都为1。
(4)设置pso算法的参数,一般取最大迭代次数imax=1000,粒子群数n=max(20,2m)(表示取20与2m两数中的最大值),加速常数β1与β2都等于2,惯性权重δ按照如下所示公式从最大值δmax=1.2线性递减到δmm=0.4:
上式中,i表示pso算法的迭代次数,其取值范围是0≤i≤imax。
(5)令下标号k表示提取的第k个非线性独立元,并初始化k=1。
(6)任意初始化n个粒子w1,w2,…,wn后,运行pso算法待迭代次数完成后得到对应于第k个非线性独立元的分离向量ak,那么相应的非线性独立元为
(7)判断k≥3n/4?若否,置k=k+1后返回步骤(6);若是,则执行下一步骤(8)。
(8)将所有得到的分离向量组成矩阵w=[a1,a2,…,ak]∈rn×k,所有的非线性独立元组成矩阵s=[t1,t2,…,tk]∈rn×k。
(9)将矩阵s中的各列按非高斯性大小进行降序排列后,选取前d列非高斯性大的独立元构建非线性的故障检测模型,并保留模型参数集θ。
(10)在线收集最新采样时刻的样本数据xnew∈rl×m,并对其进行同样的标准化处理得到
(11)按照下式计算核向量z∈rl×n中的各个元素zi(i=1,2,…,n),即:
(12)依据下式计算得到中心化的核向量
其中,行向量l=[1,1,…,1]∈rl×n。
(13)调用模型参数集θ实施在线故障检测。
与现有方法相比,本发明方法的优势在于:
首先,本发明方法是直接应用于训练数据,避免了传统kica方法的白化处理过程。由于白化处理过程有可能会扭曲原始数据的部分信息,本发明方法因不涉及白化处理而不会受其影响。其次,本发明方法不仅利用了核学习技巧而且还使用pso算法迭代求取非线性独立元,使原始的pso-ica算法成功扩展成可以处理非线性非高斯数据的建模方法。最后,本发明方法不仅限于建立故障检测模型,该方法还可以应用于其他涉及非线性数据信号源分离上。相比于传统的kica方法,本发明方法可以说是一种更为优选的非线性建模与数据分析方法。
附图说明
图1为本发明方法的实施流程图。
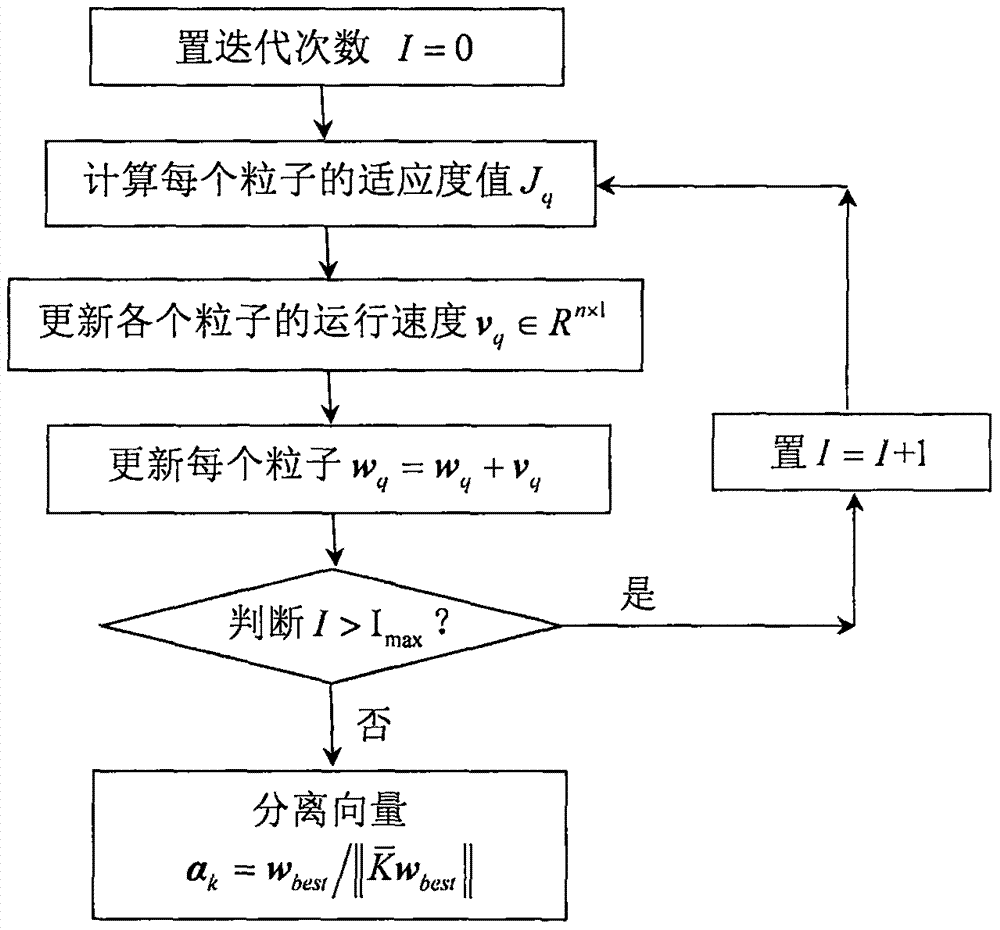
图2为pso算法搜寻分离向量ak的实施流程图。
具体实施方式
下面结合附图对本发明方法进行详细的说明。
如图1所示,本发明提供了一种基于粒子群优化核独立元分析模型的故障检测方法,该方法的具体实施步骤如下所示:
步骤1:从生产过程的历史数据库中找出该过程对象在正常运行状态下的采样数据组成数据矩阵x∈rn×m,并对x中每个变量进行标准化处理,得到均值为0,标准差为1的新矩阵
步骤2:设置核函数参数c=5m后,按照下式计算核矩阵k∈rn×n中的第(i,j)个元素:
上式中,下标号i=1,2,…,n,j=1,2,…,n,exp表示以自然常数e(约为2.71828)为底的指数函数,符号||||表示计算向量的长度。
步骤3:依据如下公式对矩阵k进行中心化处理,即:
上式中,方阵l∈rn×n中各元素都为1。
步骤4:设置pso算法的参数,一般取最大迭代次数imax=1000,粒子群数n=max(20,2m)(表示取20与2m两数中的最大值),加速常数β1与β2都等于2,惯性权重δ按照如下所示公式从最大值δmax=1.2线性递减到δmim=0.4:
上式中,i表示pso算法的迭代次数,其取值范围是0≤i≤imax。
步骤5:令下标号k表示提取的第k个非线性独立元,并初始化k=1。
步骤6:任意初始化n个粒子w1,w2,…,wn后,运行pso算法待迭代次数完成后得到对应于第k个非线性独立元的分离向量ak,那么相应的非线性独立元为
①置i=0,开始执行pso迭代过程;
②按照如下所示公式计算每个粒子wq∈rn×l所对应的适应度值jq:
jq=e[g(sq)](11)
其中,q=1,2,…,n为粒子标号,e表示求取均值,函数g(sq)=log[cosh(sq)],自变量sq的计算方式如下所示:
③将当前迭代次数中取得最大适应度值的粒子记做c∈rn×l,将每个粒子在其整个迭代历史中取得最大适应度值的位置记做bq∈rn×l,并依照如下所示公式更新各个粒子的运行速度vq∈rn×1,即:
vq=δ·vq+β1·rand1·(bq-wq)+β2·rand2·(c-wq)(12)
其中,rand1和rand2是在区间[0,1]内的任意随机数。
值得注意的是,当迭代次数i=0时,pso算法刚开始迭代运行,这时候有b=c。
④按照如下所示公式更新每个粒子,即:
wq=wq+vq(13)
⑤判断i>imax?若否,置i=i+1后返回②进行下一次迭代;若是,执行⑥;
⑥输出当前迭代次数中取得最大适应度值的粒子wbest,该粒子即是对应于第k个非线性独立元的分离向量
步骤7:判断k≥3n/4?若否,置k=k+1后返回步骤6;若是,则执行步骤8。
步骤8:将所有得到的分离向量组成矩阵w=[a1,a2,…,ak]∈rn×k,所有的非线性独立元组成矩阵s=[t1,t2,…,tk]∈rn×k。
步骤9:将矩阵s中的各列按非高斯性大小进行降序排列后,选取前d列非高斯性大的独立元构建非线性的故障检测模型,具体的实施过程如下所示:
①按照如下公式分别计算t1,t2,…,tk的非高斯性大小fg,即:
fg={e[g(tg)]-e[g(u)]}2(15)
其中,下标号g=1,2,…,k,函数g(u)=log[cosh(u)],u表示一任意均值为0,标准差为1的高斯分布的随机变量;
②按f1,f2,…,fk数值大小进行降序排列,并依据前d个较大数值所对应的下标号分别从矩阵s与矩阵w中选出相应的列,对应组成矩阵
③依据如下公式分别计算监测统计量
上式中,算子diag表示取矩阵对角线上的元素组成列向量。
④分别计算向量
⑤保留模型参数集
步骤10:在线收集最新采样时刻的样本数据xnew∈rl×m,并对其进行同样的标准化处理得到
步骤11:按照下式计算核向量z∈rl×n中的各个元素zi(i=1,2,…,n),即:
步骤12:依据下式计算得到中心化的核向量
其中,行向量l=[1,1,…,1]∈rl×n。
步骤13:利用步骤9中保留的模型参数集θ实施在线故障检测,具体的实施过程如下所示:
首先,计算得到该新样本数据所对应的非线性独立元
然后,计算监测统计量
最后,判断是否满足
上述实施例仅是对本发明的优选实施方式,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!