一种具有角色扮演的智能服务型机器人的制作方法
本发明涉及智能机器人领域,尤其涉及一种具有角色扮演的智能服务型机器人。
背景技术:
机器人以及智能音响等智能语音系统,语音模块目前都只是智能单一语音系统以及一个特定的角色。目前只能机器人在只能语音方面取得很大进展,但在只能语音系统只能做到一种语音模式,用户在长期使用对一种特定的声音外观产生反感,久而久之会逐渐不会使用。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种具有角色扮演的智能服务型机器人,具有多种语音识别系统,语音音色设定或语音模仿;角色的唤醒;以及机器人与角色本人的交互等相关功能。
本发明采用的技术方案是:
一种具有角色扮演的智能服务型机器人,其包括soc主板、传感器、麦克风阵列、语音模拟仿真组件、语音角色存储组件、智能语音控制器、音频放大器、语音播放器、显示终端、无线通信组件;
麦克风阵列分别连接语音模拟仿真组件和智能语音控制器,语音模拟仿真组件、语音角色存储组件分别连接智能语音控制器,传感器、智能语音控制器、音频放大器、无线通信组件和显示终端分别连接soc主板,音频放大器的输出端与语音播放器连接;
麦克风阵列用于语音的多向输入,语音模拟仿真组件基于输入语音创建模拟不同角色原音,智能语音控制器用于语言信息的识别以及角色唤醒,soc主板用于智能服务型机器人的逻辑控制、语音信号处理以及通讯管理,音频放大器用于放大角色的语音信号,并驱动语音播放器输出,无线通信组件用于soc主板与角色本人对应的远端设备的通信,角色本人通过摄像头和显示终端进行可视语音交互,传感器用于主动感应获取外部信息,语音角色存储组件存储有多个角色配置,每个角色绑定一个角色本人,每个角色具有对应的外观和语音。
进一步地,传感器包括亮度传感器、温湿度传感器和红外人体传感器,在硬件支持下角色本人可对机器的手臂/脚步等进行操作。
进一步地,语言信息的识别包括语音、语调、语义的识别。
进一步地,无线通信组件包括wifi模块、蓝牙模块、4g/5g模块。
进一步地,显示终端为液晶触摸屏。
进一步地,语音播放器为喇叭。
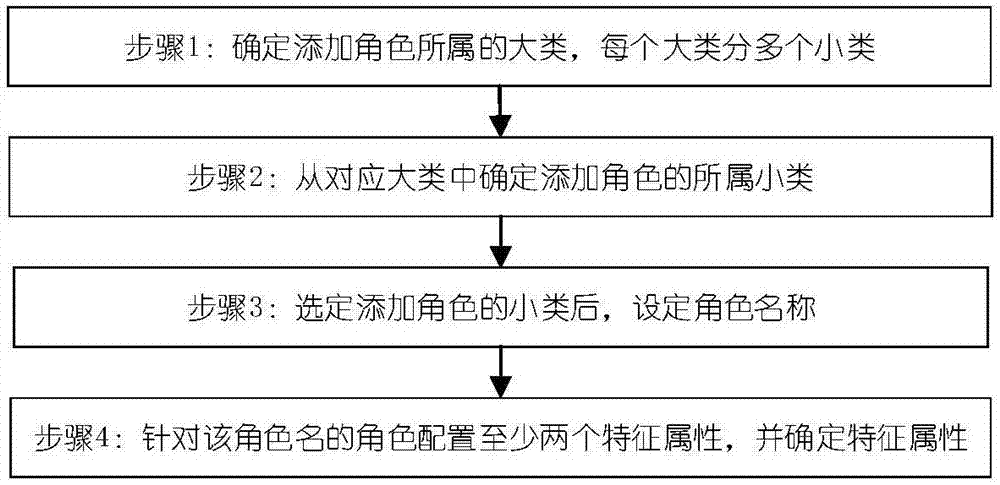
进一步地,语音角色存储组件的角色定义的具体方法包括以下步骤:
步骤1:确定添加角色所属的大类,每个大类分多个小类;
步骤2:从对应大类中确定添加角色的所属小类;
步骤3:选定添加角色的小类后,设定角色名称;
步骤4:针对该角色名的角色配置至少两个特征属性,并确定特征属性;
进一步地,步骤4的特征属性为三个,特征属性包括角色头像、角色语音和角色外观。
进一步地,智能语音控制器的角色唤醒的方法包括以下步骤:
步骤s1:通过麦克风阵列获取语音信息,并识别语音唤醒口令;
步骤s2:通过语音唤醒口令查询该语音唤醒口令对应的角色;
步骤s3:将机器人状态更新为该语音唤醒口令对应的角色;
步骤s4:机器人将当前状态更新为对应的角色,并与该角色本人建立远端语音通信连接;
步骤s5:机器人根据当前信号状态与角色本人进行视频或语音连续;
步骤s6:呼叫方通过机器人与角色本人进行连续对话,角色本人对机器人进行相应的肢体控制。
本发明采用以上技术方案,具有如下优点:1.内置有麦克风这列,可以多向的进行语音输入;内置语音模拟仿真系统,用户可以通过输入固定几句话,系统可创建模拟出不同角色者的原音。2.内置智能语音系统,具有识别语音、语调、语义等信息,具备有不同角色的唤醒。3.内置控制soc主板,能通过将智能语音处理的角色者语音信号通过音频放大器放大后驱动喇叭输出;soc通过wifi/4g/5g等信号与角色本人的手机/电脑等终端设备通信,当机器人遇到无法回答的问题可以直接连接角色本人。4.内置各传感器,角色本人可通过摄像头和液晶屏进行可视语音交互,在硬件支持下角色本人可对机器的手臂/脚步等进行操作。本发明的机器人具有多种语音识别系统,语音音色设定或语音模仿;能设定不同角色对象和外观。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为本发明一种具有角色扮演的智能服务型机器人的结构示意图;
图2为本发明一种具有角色扮演的智能服务型机器人的语音角色存储组件的角色定义示意图;
图3为本发明一种具有角色扮演的智能服务型机器人的智能语音控制器的角色唤醒示意图。
具体实施方式
如图1-3之一所示,本发明公开了一种具有角色扮演的智能服务型机器人,其包括soc主板、传感器、麦克风阵列、语音模拟仿真组件、语音角色存储组件、智能语音控制器、音频放大器、语音播放器、显示终端、无线通信组件;
麦克风阵列分别连接语音模拟仿真组件和智能语音控制器,语音模拟仿真组件、语音角色存储组件分别连接智能语音控制器,传感器、智能语音控制器、音频放大器、无线通信组件和显示终端分别连接soc主板,音频放大器的输出端与语音播放器连接;
麦克风阵列用于语音的多向输入,语音模拟仿真组件基于输入语音创建模拟不同角色原音,智能语音控制器用于语言信息的识别以及角色唤醒,soc主板用于智能服务型机器人的逻辑控制、语音信号处理以及通讯管理,音频放大器用于放大角色的语音信号,并驱动语音播放器输出,无线通信组件用于soc主板与角色本人对应的远端设备的通信,角色本人通过摄像头和显示终端进行可视语音交互,传感器用于主动感应获取外部信息,语音角色存储组件存储有多个角色配置,每个角色绑定一个角色本人,每个角色具有对应的外观和语音。
进一步地,传感器包括亮度传感器、温湿度传感器和红外人体传感器,在硬件支持下角色本人可对机器的手臂/脚步等进行操作。
进一步地,语言信息的识别包括语音、语调、语义的识别。
进一步地,无线通信组件包括wifi模块、蓝牙模块、4g/5g模块。
进一步地,显示终端为液晶触摸屏。
进一步地,语音播放器为喇叭。
进一步地,如图2所示,语音角色存储组件的角色定义的具体方法包括以下步骤:
步骤1:确定添加角色所属的大类,每个大类分多个小类;
步骤2:从对应大类中确定添加角色的所属小类;
步骤3:选定添加角色的小类后,设定角色名称;
步骤4:针对该角色名的角色配置至少两个特征属性,并确定特征属性;
进一步地,步骤4的特征属性为三个,特征属性包括角色头像、角色语音和角色外观。
进一步地,如图3所示,智能语音控制器的角色唤醒的方法包括以下步骤:
步骤s1:通过麦克风阵列获取语音信息,并识别语音唤醒口令;
步骤s2:通过语音唤醒口令查询该语音唤醒口令对应的角色;
步骤s3:将机器人状态更新为该语音唤醒口令对应的角色;
步骤s4:机器人将当前状态更新为对应的角色,并与该角色本人建立远端语音通信连接;
步骤s5:机器人根据当前信号状态与角色本人进行视频或语音连续;
步骤s6:呼叫方通过机器人与角色本人进行连续对话,角色本人对机器人进行相应的肢体控制。
本发明采用以上技术方案,具有如下优点:1.内置有麦克风这列,可以多向的进行语音输入;内置语音模拟仿真系统,用户可以通过输入固定几句话,系统可创建模拟出不同角色者的原音。2.内置智能语音系统,具有识别语音、语调、语义等信息,具备有不同角色的唤醒。3.内置控制soc主板,能通过将智能语音处理的角色者语音信号通过音频放大器放大后驱动喇叭输出;soc通过wifi/4g/5g等信号与角色本人的手机/电脑等终端设备通信,当机器人遇到无法回答的问题可以直接连接角色本人。4.内置各传感器,角色本人可通过摄像头和液晶屏进行可视语音交互,在硬件支持下角色本人可对机器的手臂/脚步等进行操作。本发明的机器人具有多种语音识别系统,语音音色设定或语音模仿;能设定不同角色对象和外观。
- 还没有人留言评论。精彩留言会获得点赞!