基于评判辨识结构的可重构机器人分散神经最优控制方法与流程
本发明涉及一种可重构机器人系统的分散神经最优控制方法,属于机器人控制算法领域。
背景技术:
可重构机器人由电源装置、减速设备、执行器、传感器和计算系统组成。这些模块可以被组装成具有标准机械接口的预定参数,以满足各种任务的需求。从这一优势出发,可重构机器人经常被用于复杂而危险的工作环境,如救灾、空间探索、高温/低温作业等。因此,可重构机器人需要适当的控制系统来保证机器人系统的稳定性,同时考虑到控制性能和功耗组合的优化实现。
可重构机器人的重要特性是机器人模块可以添加、删除和替换,而不需要调整其他模块的控制参数。换句话说,对于可重构机器人系统,在子系统和本地控制器之间存在着物理上的信息交换限制,对于这些子系统和本地控制器来说,它们拥有集中控制器的能力是不可靠的。
对于复杂的相互关联的非线性系统,尤其是可重构机器人系统,交联项的性质和规模与内部动力学有很大的不同。分散神经最优控制策略是在非线性系统的动态信息是完全未知的前提下进行研究的,因此这些方法的应用局限于求解机器人系统特定类的最优控制问题,而没有实现最优的动态补偿。事实上,在设计机器人分散最优控制器时,尤其是在可重构机器人系统中,需要充分利用现有的动态模型信息。
赵博等人在internationaljournalofcontrol,automationandsystems上发表的”model-freeadaptivedynamicprogrammingbasednear-optimaldecentralizedtrackingcontrolofreconfigurablemanipulators”,该文中分散最优控制没有考虑复杂的互联非线性系统,特别是对于可重构机器人系统,交联项的性质和大小与内部动力学完全不同,所以该方法存在控制精度低的问题。
技术实现要素:
本发明为了解决现有技术中存在分散最优控制精度低的问题,提出了一种基于评判辨识结构的可重构机器人分散神经最优控制方法。
本发明解决技术问题的方案是:
基于评判辨识结构的可重构机器人分散神经最优控制方法,其特征是,该方法首先建立可重构机器人系统动力学模型,其次构建代价函数与hjb方程,通过基于策略迭代的学习算法,来求hjb方程的解,然后通过对可重构机器人关节子系统间的耦合力矩交联项的辨识,接下来采用神经网络对代价函数进行近似,最后通过仿真验证所提出控制方法的有效性。
基于评判辨识结构的可重构机器人分散神经最优控制方法,包括如下步骤:
步骤一,建立可重构机器人系统动力学模型如下:
上式中,i代表第i个模块,imi是转动轴的转动惯量,γi是齿轮传动比,qi,
定义系统的状态向量
则子系统的状态空间的形式可以表示为:
其中,
步骤二,构建代价函数如下:
其中,si(ei)定义为
构建哈密顿方程如下:
其中,
根据式(15)、(16),基于非线性系统最优控制设计理论,易知
最优控制律
其中,ui1为基于局部动力学信息的模型补偿控制律,ui2为辨识策略的神经网络控制律,
将式(17)的hjb方程改写成:
接下来,定义ui1为
ui1是根据第i个关节模块的局部动态信息来设计的;
步骤三,交联项动力学的辨识;
交联项hi可以用一个单层神经网络来进行逼近:
σih(xih,xd)表示神经网络激活函数,wih表示未知理想权重,xih表示确定的神经网络状态,xd=[x1d,x2d,…,xmd]t,m<i代表已知有界参考状态向量,εih(xih)表示神经网络逼近误差;在(23)的基础上,考虑如下有界控制输入uih非线性动力学系统:
用神经网络辨识逼近(24),得到:
其中,
rih=kiheih+vih(27)
其中,
其中,kih,αih,γih,δi1代表正控制常参数,sgn(·)表示符号函数,结合(24),(25),辨识动态误差为:
其中,
根据式(28)、(29)对时间t的导数,有如下定义:
神经网络权重更新设计如下:
其中,proj表示光滑投影运算,γih表示正常数增益矩阵;
结合式(21),(25),(26),(27),得到交联项辨识策略的神经网络控制律ui2为:
权值
步骤四,通过神经网络来近似代价函数ji(si),定义如下:
其中,wci是理想的权值向量,σci(si)是激活函数,εci是神经网络的逼近误差,ji(si)的梯度通过神经网络近似为:
其中:
由于理想权值wci是未知的,所以用近似权值wci建立一个评价神经网络来估计代价函数:
根据哈密顿方程(15)和代价函数(36)以及它的梯度(37),哈密顿方程可以进一步改写为:
其中,echi是由评判网络逼近误差而得到的残差,它可以定义为:
以同样的方式近似哈密顿方程,可得:
定义误差方程为
训练和调整评价网络的权值信息,采用目标函数
其中,αci>0表示评价神经网络的学习速率;推导出神经网络权值的动态误差,引入下式:
通过式(43),(44)和(45),得到评价神经网络的动态误差如下所示:
结合(18)和(36),理想基于自适应动态规划的神经最优控制律为:
在实现在线策略迭代算法来完成策略改进时,得到了近似最优控制律
结合式(22),(35)与(48),可得到基于评判辨识结构的可重构机器人分散神经最优控制律
本发明的有益效果如下:
在位置跟踪方面,本发明改善了系统的跟踪性能,并且降低了评判神经网络对未知非线性项的计算负担,关节位置的稳态误差减小。
在控制力矩方面,本发明的控制力矩更加连续和平滑,不仅可以保持系统渐进稳定,而且可以降低每个关节的能量损耗。
在训练神经网络方面,本发明通过在线策略迭代的方法可以更快的训练神经网络。
因此,本发明解决了现有技术中存在分散最优控制精度低的问题,为可重构机器人提供稳定性和精确性,并且可以满足各种任务的需求。
附图说明
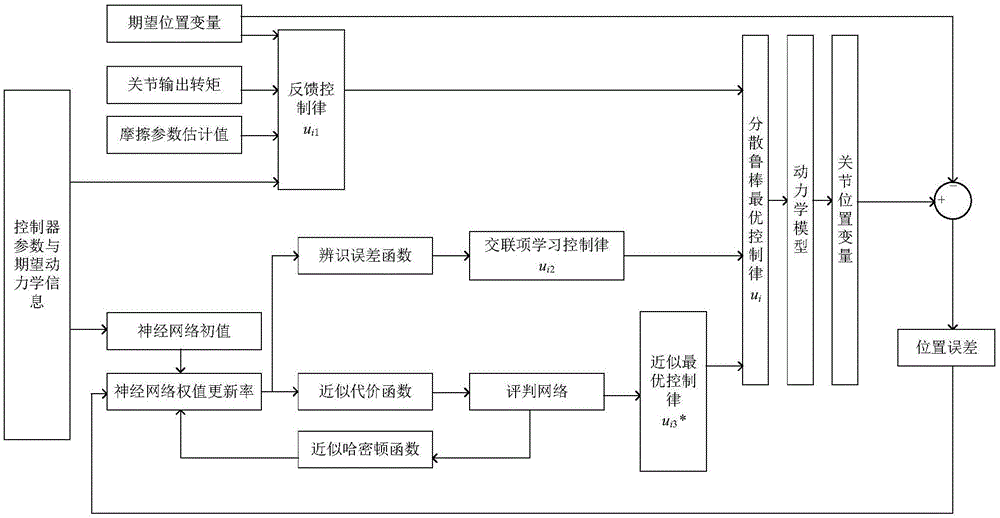
图1为本发明基于评判辨识结构的可重构机器人分散神经最优控制原理图。
图2为本发明基于评判辨识结构的可重构机器人分散神经最优控制方法流程图。
图3为本发明仿真验证中的可重构机器人构型a关节1(图3-(a))和关节2(图3-(b))的提出方法的关节位置跟踪曲线。
图4为本发明仿真验证中的可重构机器人构形a的提出方法的关节位置跟踪误差曲线。
图5为本发明仿真验证中的可重构机器人构型a关节1(图5-(a))和关节2(图5-(b))的提出方法的关节位置跟踪曲线。
图6为本发明仿真验证中的可重构机器人构形a关节1的提出方法的评判神经网络权重调节曲线。
图7为本发明仿真验证中的可重构机器人构形a关节2的提出方法的评判神经网络权重调节曲线。
图8为本发明仿真验证中的可重构机器人构型b关节1(图8-(a))和关节2(图8-(b))的提出方法的关节位置跟踪曲线。
图9为本发明仿真验证中的可重构机器人构形b的提出方法的关节位置跟踪误差曲线。
图10为本发明仿真验证中的可重构机器人构型b关节1(图10-(a))和关节2(图10-(b))的提出方法的控制力矩曲线。
图11为本发明仿真验证中的可重构机器人构形b关节1的提出方法的评判神经网络权重调节曲线。
图12为本发明仿真验证中的可重构机器人构形b关节2的提出方法的评判神经网络权重调节曲线。
具体实施方式
下面结合附图对本发明做进一步详细说明。
如图1所示,根据控制器参数与期望动力学信息,与期望位置变量、关节输出转矩与摩擦参数估计值相结合得到基于局部动力学信息的模型补偿控制律ui1。确定神经网络初值,得到神经网络权值更新率,得到辨识误差函数,获得辨识策略的神经网络控制律ui2。通过近似代价函数,通过评判网络,得到基于自适应动态规划的神经最优控制律
如图2所示,基于评判辨识结构的可重构机器人分散神经最优控制方法,该方法首先建立可重构机器人系统动力学模型,其次构建代价函数与hjb方程,通过基于策略迭代的学习算法,来求hjb方程的解,然后通过对可重构机器人关节子系统间的耦合力矩交联项的辨识,接下来采用神经网络对代价函数进行近似,最后通过仿真验证所提出控制方法的有效性。
1、动力学模型的建立
建立可重构机器人系统的动力学模型如下:
上式中,i代表第i个模块,imi是转动轴的转动惯量,γi是齿轮传动比,qi,
(1)式中,关节摩擦项
其中,bfi是粘性摩擦系数,fci是库伦摩擦相关系数,fsi是静态相关系数,fτi是关于stribeck效应的位置参数,
结合式(2)和式(3),关节摩擦项
其中,
此外,(1)式子中的关节子系统间的耦合力矩交联项
其中,zmi是第i个转子旋转轴上的单位矢量,zlj是第j个关节旋转轴上的单位矢量,zlk是第k个关节旋转轴上的单位矢量。
便于分析关节子系统间的耦合力矩交联项,将
其中,
(1)中di(qi)项定义为:
di(qi)=dih(qi)+dis(qi)(9)
其中,dih(qi)表示力矩传输波纹,dis(qi)表示力矩传感干扰。
重新改写式(1)中第i个子系统的动力学模型可以得到:
其中,
第i个子系统的状态空间的形式可以表示为:
其中
性质1:根据摩擦力模型(4),如果参数bfi,fci,fsi和fτi都是有界的,可以得出
性质2:摩擦力项
性质3:zmi,zlk与zlj是沿着相应关节旋转方向的单位矢量,
性质4:dih(qi)主要受到波形发生器和谐波传动器中柔轮最大变形量影响,因此dih(qi)≤ρdhi。
性质5:dis(qi)的上界|dis(qi)|≤ρdsi是由力矩传感偏离决定的。
2、代价函数与哈密顿函数的构建
首先,构建代价函数为:
其中,si(ei)定义为
耦合力矩交联项hi和模型不确定项
定义哈密顿方程如下:
其中,
基于非线性系统最优控制设计理论下,易知
若
hjb方程可以改写成:
接下来,把最优控制
分别解决项φi,hi,
定义控制律ui1为:
由于ui1是根据第i个关节模块的局部动态信息来设计的。
接下来,通过基于策略迭代的学习算法,来求hjb方程的解。选择一个很小的正常数εip,让
3、交联项动力学的辨识
要辨识交联项动力学,首先要给出以下假设:
假设1:神经网络逼近误差是有上界的,上界是一个未知常数。
假设2:激活函数σ(·)和它的导数σ′(·)是有界的。
利用假设1和2,交联项hi可以用一个单层神经网络来进行逼近:
σih(xih,xd)表示神经网络激活函数,wih表示未知理想权重,xih表示确定的神经网络状态,xd=[x1d,x2d,…,xmd]t,m<i代表已知有界参考状态向量,εih(xih)表示神经网络逼近误差。在(23)的基础上,考虑如下有界控制输入uih非线性动力学系统:
用神经网络辨识逼近(24),得到:
其中,
rih=kiheih+vih(26)
其中,
其中,kih,αih,γih,δi1代表正控制常参数,sgn(·)表示符号函数,结合(24),(25),辨识动态误差为:
其中,
根据(28),(29)对时间t的导数,有如下定义:
神经网络权重更新设计如下:
其中,proj表示光滑投影运算,γih表示正常数增益矩阵,(30)可以重新改写为:
其中,
其中
其中
结合式(21),(25),(26),(27),得到交联项辨识策略的神经网络控制律ui2为:
权重
4、基于评判神经网络的代价函数近似实现
利用单层神经网络来近似代价函数ji(si),定义如下:
其中,wci是理想的权值向量,σci(si)是激活函数,εci是神经网络的逼近误差,ji(si)的梯度通过神经网络近似为:
其中:
由于理想权值wci是未知的,所以用近似权值wci建立一个评价神经网络来估计代价函数:
根据哈密顿方程(15)和代价函数(36)以及它的梯度(37),哈密顿方程可以进一步改写为:
其中,echi是由评判网络逼近误差而得到的残差,它可以定义为:
以同样的方式近似哈密顿方程,可得:
定义误差方程为
训练和调整评价网络的权值信息,采用目标函数
其中,αci>0表示评价神经网络的学习速率。推导出神经网络权值的动态误差,引入下式:
通过式(43),(44)和(45),得到评价神经网络的动态误差如下所示:
结合(18)和(36),得到基于自适应动态规划的神经最优控制律为:
在实现在线策略迭代算法来完成策略改进时,得到了基于自适应动态规划的近似神经最优控制律
结合式(22),(35)与(48),可得到基于评判-辨识结构的可重构机器人分散神经最优控制律
5、仿真验证
验证所提出的分散神经最优控制方法的有效性,对二自由度可重构机器人模型的两种不同构形进行仿真验证,其中,控制器参数由表1给出:
表1控制器参数
两种构形的理想轨迹如下所示:
构形a:
x1d=0.4sin(0.3t)-0.1cos(0.5t)
x2d=0.3cos(0.6t)+0.6sin(0.2t)
构形b:
x1d=0.2cos(0.5t)+0.2sin(0.4t)
x2d=0.3cos(0.2t)-0.4sin(0.6t)
选取权值向量
辨识的激活函数选择为有5个隐含层的对称s型函数,辨识参数选择为kih=800,αih=350,γih=5,δi1=0.5,γih=0.1i,其中i是单位矩阵。其余的设计参数、控制参数和不确定性界限由表1给出。摩擦模型参数选取为:
fci=0.35+0.7sin(10θi)n·m
fsi=0.5+sin(10θi)n·m
fτi=0.1+0.2sin(10θi)s2/rad2
bfi=0.5+0.3sin(10θi)n·m·s/rad
图3给出了系统的关节位置跟踪曲线。跟踪性能的提高在于基于模型的动态补偿的实现和交联项的识别,这可降低系统中未知非线性动力学的规模和评判神经网络的计算负担。
图4是构型a的提出方法的位置跟踪误差曲线。图中关节位置的稳态误差减小,由于动态补偿是通过模型补偿控制器和基于交联项辨识的学习控制器来实现的,并且在基于自适应动态规划的神经最优控制律下也对模型的不确定性进行了补偿。
图5是构型a的控制力矩曲线,在曲线中,控制力矩是连续、平滑的电机输出力矩,可以在实际的可重构机器人系统上实施的。提出的神经最优控制不仅可以保证系统闭环渐进稳定,而且优化保持在适当范围内的功率消耗,以匹配每个连接模块中电机的输出功率。
图6和图7是构型a的各独立关节子系统的神经网络权值调整曲线。实施在线策略迭代和评判神经网络的训练,可以看到权值在10秒以前可以收敛,评判神经网络收敛到wc1=[21.5714,43.4167,39.2565],wc2=[26.4409,30.5433,26.4850]。
图8-12给出了构型b的关节位置跟踪曲线、位置跟踪误差曲线、控制力矩曲线和关节1、关节2权值收敛结果曲线。它与构型a相比较,有相似的结果。这意味着所提出的分散最优控制律不需要对控制参数进行调整,适用于可重构机器人的不同控制。可以看到,构型b关节1的位置跟踪误差明显小于构型a。因为构型b关节1不受重力的影响,减小了关节动力学和不确定性的大小。构型b中评判神经网络收敛到wc1=[22.8395,33.1094,37.5858],wc2=[32.2989,7.0446,16.0892]
仿真结果表明,所提出的分散最优控制方法能为可重构机器人提供稳定性和精确性,以满足各种任务的要求。
- 还没有人留言评论。精彩留言会获得点赞!