基于主辅PCA模型的多变量工业过程故障检测方法与流程
本发明属于工业过程故障检测
技术领域:
,涉及一种基于主辅pca模型(英文:primaryassistedprincipalcomponentanalysis,简称:pa-pca)的多变量工业过程故障检测方法。
背景技术:
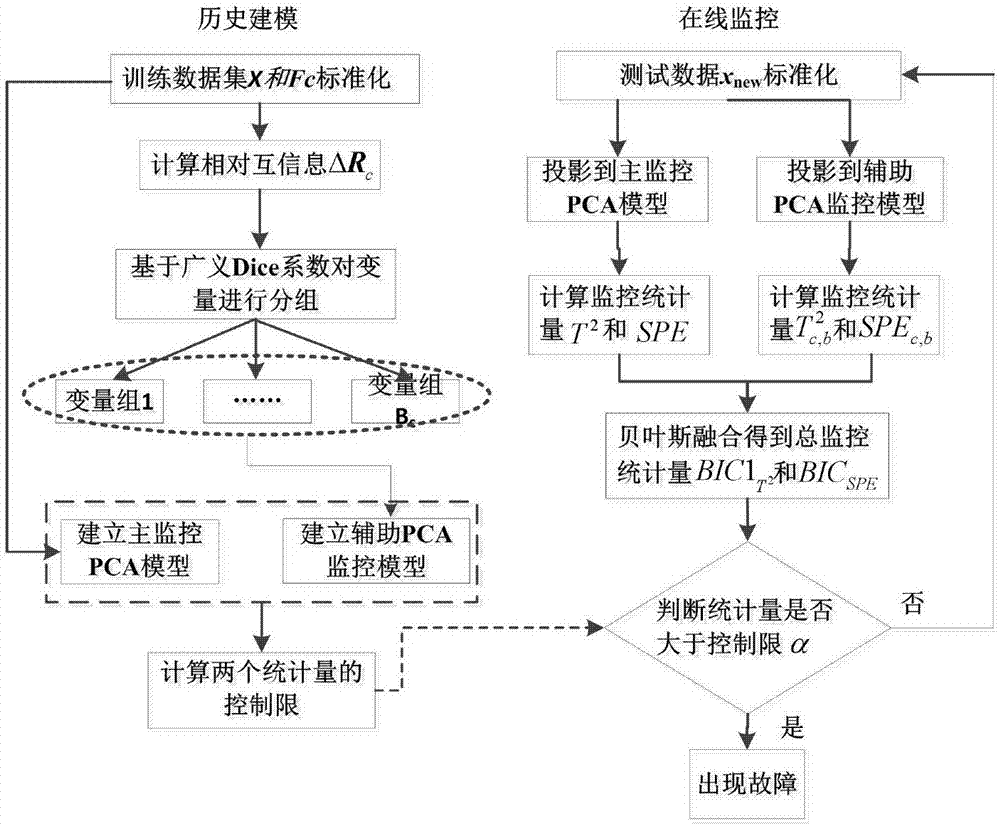
:由于现代工业系统日益复杂化,人们对过程安全和产品质量日益重视,故障诊断在工业生产中的地位越来越重要。随着存储技术的发展,大量生产过程数据被采集并记录。因此,基于数据驱动的故障诊断方法得到了广泛应用。经典的故障检测方法包括主元分析(pca)、独立元分析(ica)和费舍尔判别分析(fda)等方法。其中pca方法近年来成为控制领域研究的热点,并得到了研究者们的广泛应用,但该方法仍然存在一些问题值得进一步研究。传统的pca方法在进行统计建模时仅仅利用正常数据,忽略了部分已知先验故障信息,造成部分重要信息的遗漏和浪费,从而导致故障检测性能降低。因此,如何有效利用已知先验故障数据挖掘有效信息提高pca的故障检测性能,已经成为一种具有挑战性的课题。技术实现要素:本发明针对传统pca方法存在的无法深入挖掘与故障相关的局部信息导致故障检测性能低等问题,提供一种基于主辅pca模型的多变量工业过程故障检测方法。该方法能够利用先验故障信息并能够深入挖掘变量局部信息,提高故障检测率,进而改善故障检测结果。为了达到上述目的,本发明提供了一种基于主辅pca模型的多变量工业过程故障检测方法,含有以下步骤:(一)收集历史数据库中的正常数据集x和c类已知故障数据集fc,c=1,2,...,c作为训练数据集,并使用正常数据集x的均值μ和标准差σ对训练数据集x和fc进行标准化处理,得到标准化后的训练数据集和(二)对正常数据集建立pca模型作为主监控模型;(三)计算故障数据集相对于正常数据集的相对互信息矩阵δrc,c=1,2,...,c;(四)对相对互信息矩阵δrc,基于广义dice系数对过程变量进行变量分组,获得分组后的数据集其中,bc为变量组的个数;(五)对分组后的数据集建立pca模型作为辅助监控模型;(六)采集测试数据集xnew,利用正常数据集x的均值μ和标准差σ对测试数据集xnew进行标准化处理,得到标准化后的测试数据集(七)将测试数据集分别向主监控模型和辅助监控模型投影,并计算测试数据集投影到主监控模型的统计量t2和spe,测试数据集投影到辅助监控模型的统计量和spec,b,统计量t2的控制限统计量spe的控制限spelim、统计量的控制限和统计量spec,b的控制限[spec,b]lim均通过核密度估计计算;(八)整合所有监控结果得到总的监控统计量和bicspe,根据统计量或统计量bicspe是否超出控制限判断测试数据集xnew是否发生故障。进一步的,所述步骤(一)中,利用正常数据集的均值μ和标准差σ通过公式(1)对训练数据集x和fc进行标准化处理,公式(1)的表达式为:训练数据集x和fc经上述公式(1)标准化处理后即可获得标准化后的训练数据集和进一步的,所述步骤(二)中,对训练数据集进行pca分解,通过公式(2)中的主监控模型计算训练数据集的负载矩阵p,公式(2)表示为:式中,t为正常数据集的得分矩阵,e为正常数据集的模型残差矩阵。进一步的,步骤(三)中,相对互信息矩阵δrc的计算步骤为:通过公式(3)计算正常数据集的互信息矩阵r,通过公式(4)计算已知故障数据集的互信息矩阵rc,公式(3)和公式(4)表示为:式中,m表示变量个数,rij表示正常数据集的第i列和第j列的互信息,rc,ij表示已知故障数据集的第i列和第j列的互信息;相对互信息矩阵δrc则表示为:进一步的,步骤(四)中,进行变量分组的具体步骤为:(1)定义相对互信息向量为:ri=[δrc,i1,δrc,i2,…,δrc,im]t(6)用广义dice系数衡量某一变量与其余变量之间相对互信息相关度的相似性,定义为:式中,0≤si,j≤1;选择使||ri||最大的变量作为第一个变量组并初始化变量组的个数bc=1;(2)按照变量顺序选择下一个向量rj(j≠i且j≤m),并通过公式(8)计算向量rj与已知变量组中各向量相似性的均值,公式(8)表示为::式中,b表示第b个变量组,nb表示第b个变量组内变量的个数;(3)确定中最大的值并判断其值是否超过阈值γ,若超过γ,则该向量所对应的变量xj被划分到变量组b中;反之,变量xj构成一个新变量组,即bc=bc+1;(4)重复步骤(2)和步骤(3)直至所有的变量分组完成,即进一步的,步骤(五)中,对变量分组后的数据集进行pca分解,通过公式(9)中的辅助监控模型计算变量分组后数据集的负载矩阵pc,b,公式(9)表示为:式中,tc,b为数据集的得分矩阵,ec,b为数据集的模型残差矩阵。进一步的,步骤(六)中,利用正常数据集x的均值μ和标准差σ通过公式(10)对测试数据集xnew进行标准化处理,进行标准化处理,公式(10)的表达式为:测试数据集xnew经上述公式(10)标准化处理后即可获得标准化后的测试数据集进一步的,步骤(七)中,通过公式(11)和公式(12)计算测试数据集投影到主监控模型的统计量t2和spe,公式(11)和公式(12)表示为:式中,σ表示主监控模型特征值组成的对角阵;通过公式(13)和公式(14)计算测试数据集投影到辅助监控模型的统计量和spec,b,公式(13)和公式(14)表示为:式中,σc,b表示辅监控模型特征值组成的对角阵,表示根据第c类故障信息获得的中第b组变量。进一步的,步骤(八)中,采用贝叶斯推理整合所有监控结果,具体步骤为:定义样本在第b个统计量发生故障的概率为:式中,s表示统计量t2、统计量spe、统计量和统计量spec,b,表示样本故障的后验概率,代表正常情况下的后验概率,通过公式(16)和公式(17)分别求解和公式(16)和公式(17)表示为:式中,slim表示统计量t2、统计量spe、统计量和统计量spec,b相应的控制限,p(f)为置信水平α,则p(n)=1-α,进而融合所有的监控结果所得总监控统计量为:进一步的,步骤(八)中,依据融合后的总监控统计量或总监控统计量bicspe是否超过控制限判断测试数据是否是故障数据;当或bicspe>0.01时,则认为过程出现了故障;否则,认为过程中并无故障发生。与现有技术相比,本发明的有益效果在于:本发明提供的多变量工业过程故障检测方法,计算先验故障和正常数据的相对互信息衡量由于故障的发生所引起变量间相关关系结构变化的差异性,借助广义dice对变量进行分组,不仅能够充分利用已知先验故障信息,尽可能避免有用故障信息的浪费和遗漏,还能够通过变量分组提取变量的局部信息;在此基础上,分别对包含所有变量的正常数据集建立pca模型作为主监控模型和在不同变量组的数据集建立pca子模型作为辅助监控模型,并应用贝叶斯推理整合变量组的信息得到总的监控统计量,根据监控统计量是否超出控制限判断测试数据集是否发生故障,通过融合后的统计量判断是否发生故障,进而改善故障检测结果,提高故障检测率。附图说明图1为本发明基于主辅pca模型的多变量工业过程故障检测方法的流程图;图2为本发明实施例所述cstr控制系统的结构图;图3a为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统中正常测试数据与标准正常数据的互信息对比图;图3b为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统中故障1与标准正常数据的互信息对比图;图3c为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对中故障4与标准正常数据的互信息对比图;图4a为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统利用故障1的先验故障信息变量分组结果示意图;图4b为本发明实施例本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统利用故障4的先验故障信息变量分组结果示意图;图5a为本发明实施例采用现有pca方法对cstr控制系统故障3的监控结果示意图;图5b为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统故障3的监控结果示意图;图6a为本发明实施例采用现有pca方法对cstr控制系统故障6的监控结果示意图;图6b为本发明实施例采用本发明基于主辅pca模型的多变量工业过程故障检测方法对cstr控制系统故障6的监控结果示意图。具体实施方式下面,通过示例性的实施方式对本发明进行具体描述。然而应当理解,在没有进一步叙述的情况下,一个实施方式中的元件、结构和特征也可以有益地结合到其他实施方式中。参见图1,本发明揭示了一种基于主辅pca模型的多变量工业过程故障检测方法,含有以下步骤:(一)收集历史数据库中的正常数据集x和c类已知故障数据集fc,c=1,2,...,c作为训练数据集,利用正常数据集的均值μ和标准差σ通过公式(1)对训练数据集x和fc进行标准化处理,公式(1)的表达式为:训练数据集x和fc经上述公式(1)标准化处理后即可获得标准化后的训练数据集和(二)对正常数据集建立pca模型作为主监控模型;具体为:对训练数据集进行pca分解,通过公式(2)中的主监控模型计算训练数据集的负载矩阵p,公式(2)表示为:式中,t为正常数据集的得分矩阵,e为正常数据集的模型残差矩阵。(三)计算故障数据集相对于正常数据集的相对互信息矩阵δrc,c=1,2,...,c;具体步骤为;通过公式(3)计算正常数据集的互信息矩阵r,通过公式(4)计算已知故障数据集的互信息矩阵rc,公式(3)和公式(4)表示为:式中,m表示变量个数,rij表示正常数据集的第i列和第j列的互信息,rc,ij表示已知故障数据集的第i列和第j列的互信息;相对互信息矩阵δrc则表示为:由于不同的故障引起变量间的互信息是不同的,故以正常数据集的互信息矩阵r为基准,分别衡量故障数据集的互信息与该基准的差异性,以此可以获得不同的变量分组结果。在相对互信息中,每行代表某一变量与所有变量之间互信息变化的差异性,若两个变量的变化差异性相似,说明由于故障的发生造成变量间相关关系结构的变化是相似的,为此可以将两个变量划分为同一变量组。(四)对相对互信息矩阵δrc,基于广义dice系数对过程变量进行变量分组,获得分组后的数据集其中,bc为变量组的个数;进行变量分组的具体步骤为:(1)定义相对互信息向量为:ri=[δrc,i1,δrc,i2,…,δrc,im]t(6)用广义dice系数衡量某一变量与其余变量之间相对互信息相关度的相似性,定义为:式中,0≤si,j≤1;si,j值越接近于1两个向量相似度越强,则故障引起变量间相关关系结构的变化相似,两个变量间具有一定的内部关系,两个变量应划分为同一变量组;选择使||ri||最大的变量作为第一个变量组并初始化变量组的个数bc=1;(2)按照变量顺序选择下一个向量rj(j≠i且j≤m),并通过公式(8)计算向量rj与已知变量组中各向量相似性的均值,公式(8)表示为::式中,b表示第b个变量组,nb表示第b个变量组内变量的个数;(3)确定中最大的值并判断其值是否超过阈值γ,若超过γ,则该向量所对应的变量xj被划分到变量组b中;反之,变量xj构成一个新变量组,即bc=bc+1;(4)重复步骤(2)和步骤(3)直至所有的变量分组完成,即本发明考虑到运算的复杂程度,将变量组内个数小于等于2的变量合成一个变量组。通过上述变量分组方法可以有效利用已知先验故障信息,降低了对已知故障信息的浪费量,更能够进一步挖掘变量的局部信息,更加有利于提高故障的检测性能。该步骤中,利用不同的先验故障信息可以得到不同的变量分组结果。(五)对分组后的数据集建立pca模型作为辅助监控模型;具体为:对变量分组后的数据集进行pca分解,通过公式(9)中的辅助监控模型计算变量分组后数据集的负载矩阵pc,b,公式(9)表示为:式中,tc,b为数据集的得分矩阵,ec,b为数据集的模型残差矩阵。(六)采集测试数据集xnew,利用正常数据集x的均值μ和标准差σ通过公式(10)对测试数据集xnew进行标准化处理,进行标准化处理,公式(10)的表达式为:测试数据集xnew经上述公式(10)标准化处理后即可获得标准化后的测试数据集(七)将测试数据集分别向主监控模型和辅助监控模型投影;通过公式(11)和公式(12)计算测试数据集投影到主监控模型的统计量t2和spe,公式(11)和公式(12)表示为:式中,σ表示主监控模型特征值组成的对角阵;通过公式(13)和公式(14)计算测试数据集投影到辅助监控模型的统计量和spec,b,公式(13)和公式(14)表示为:式中,σc,b表示辅监控模型特征值组成的对角阵,表示根据第c类故障信息获得的中第b组变量;通过核密度估计计算分别统计量t2的控制限统计量spe的控制限spelim、统计量的控制限和统计量spec,b的控制限[spec,b]lim。(八)采用贝叶斯推理整合所有监控结果得到总的监控统计量和bicspe,具体步骤为:定义样本在第b个统计量发生故障的概率为:式中,s表示统计量t2、统计量spe、统计量和统计量spec,b,表示样本故障的后验概率,代表正常情况下的后验概率,通过公式(16)和公式(17)分别求解和公式(16)和公式(17)表示为:式中,slim表示统计量t2、统计量spe、统计量和统计量spec,b相应的控制限,p(f)为置信水平α,则p(n)=1-α,进而融合所有的监控结果所得总监控统计量为:依据融合后的总监控统计量或总监控统计量bicspe是否超过控制限判断测试数据是否是故障数据;当或bicspe>0.01时,则认为过程出现了故障;否则,认为过程中并无故障发生。上述方法中,步骤(一)至(五)为离线建模阶段,步骤(六)至(八)为在线测试阶段。本发明上述故障检测方法,一方面利用正常过程数据建立pca模型,作为主监控模型,另一方面根据正常过程数据与故障数据之间的相对互信息对变量分组,然后针对先验故障信息建立pca模型,作为辅助监控模型,融合主监控模型和辅助监控模型的结果监视过程变化。能够利用先验故障信息并能够深入挖掘变量局部信息,减少有用故障信息的浪费和遗漏,提高故障检测率,进而改善故障检测结果。为了能更清楚地说明本发明上述故障检测方法的有益效果,以下结合实施例对本发明上述故障检测方法做出进一步说明。实施例:连续搅拌反应釜(简称:cstr)控制系统,作为一类化学反应器,具有成本低、热交换能力强和产品质量稳定等优势,在工业过程反应中得到广泛应用。在反应过程中,反应物a在反应器中发生一级不可逆的放热反应,同时生成物质b。该cstr控制系统中测量了10个变量,其中包括4个状态变量和6个输入变量,变量详情见表1。表1变量说明ca反应物a从反应釜流出时的浓度t反应釜的温度tc夹套出口冷却剂的温度h反应釜液位高度q反应釜流出物料的浓度qc夹套内冷却剂的流量qf进料a的流量caf反应釜进料a的浓度tf进料a的温度tcf夹套入口冷却剂温度在上述cstr控制系统仿真中,采集了1000个正常数据作为训练集,另生成表2中的6种故障数据,每种故障均包含1000个样本,每种故障均从第161个采样点加入故障。表2采用本发明上述故障检测方法(以下简称:pa-pca方法)对本实施例所述cstr控制系统进行故障检测。检测到发生故障后,为评价不同故障检测方法的故障检测性能,通过故障检出率fdr指标对不同方法的故障检测结果对比。故障检出率fdr定义为能够检测出的故障数据个数占总故障数据个数的百分比。很显然,fdr的数值越大,意味着工业过程故障检测方法的故障检测效果越好;反之,工业过程故障检测方法的故障检测效果越差。在本实施例的cstr控制系统仿真中,采用pca方法和本发明pa-pca方法两种方法监控过程的变化。选取故障1(阶跃故障)和故障4(斜坡故障)两种不同类型的信息作为先验故障信息。两种方法中主元个数的选取均根据80%的方差贡献率,变量组划分的阈值γ设置为0.65,99%置信度被用来计算各方法的控制限。以故障3和故障6为例说明故障检测效果。图3a给出了正常测试数据与标准正常数据的互信息对比示意图,图3b给出了cstr控制系统中的故障1与标准正常数据的互信息对比示意图,图3c给出了cstr控制系统中的故障4与标准正常数据的互信息对比示意图。图3a-3c中均为变量1与其余变量之间的互信息。从图3a可以看出,两组不同正常数据集的互信息基本是重合的,说明在正常工况下,过程数据中变量间的相关关系结构基本没有发生变化。从图3b和图3c可以看出,两种不同故障的互信息和标准正常数据集之间的互信息存在较大差异,说明在异常工况下,过程数据中变量间的相关关系结构发生了变化,这也验证了本发明从先验故障信息考虑的必要性。故障3是由催化剂的活性以斜坡的形式发生变化而引起。图4a给出了利用故障1的先验信息变量分组结果示意图,图4b给出了利用故障4的先验信息变量分组结果示意图。从图4a、图4b中可以看出,利用不同的先验故障信息可以得到不同的变量分组结果。pca方法和本发明pa-pca方法的故障监控图如图5。根据图5a,pca方法的t2和spe统计量分别在第760和第639个采样时刻给出报警信号,两个统计量的故障检出率分别为32.02%和39.88%,故障检出率较低。而图5b中,pa-pca方法的两个统计量能够比传统pca方法分别提前285和106个时刻报警,且故障检出率分别为46.43%和58.81%,与传统pca方法相比,监控性能得到了提高。故障6是由冷却水温度传感器发生偏差而引起的。两种方法对该故障的监控图如图6a和图6b所示。由图6a可以看出,pca方法的两个统计量虽然能够在第413和239个采样时刻检测出该故障,但是统计量均在控制线的上下波动,这使得大部分统计量位于控制线下方,故障检出率仅为26.07%和40.6%。相比之下,虽然本发明pa-pca方法中spe统计量的监控性能与传统pca方法基本一致,检测时刻提前了1个,故障检出率为43.45%,但是本发明pa-pca方法的t2统计量能够在第161个采样时刻及时给出报警信号,比pca方法的t2统计量提前了252个时刻,且具有较高的故障检出率,故障检出率提到了77.5%,监控性能得到了提升,如图6b。因此,本发明所提的pa-pca方法能够改善对cstr控制系统故障6的故障检测性能。表3给出了pca方法和本发明pa-pca方法对于cstr控制系统6种故障的故障检出率。表3由表3可知,本发明pa-pca方法对6种故障的监控效果最好,具有最高的平均故障检出率,尤其是对故障3和故障6的监控性能改善更为明显。综合以上分析,本发明pa-pca方法的故障检测效果要优于传统pca方法。以上所举实施例仅用为方便举例说明本发明,并非对本发明保护范围的限制,在本发明所述技术方案范畴,所属
技术领域:
的技术人员所作各种简单变形与修饰,均应包含在以上申请专利范围中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1