基于自适应遗传算法的混合流水车间可持续调度控制方法与流程
本发明涉及制造行业生产节能控制
技术领域:
,尤其是涉及一种基于自适应遗传算法的混合流水车间可持续调度控制方法。
背景技术:
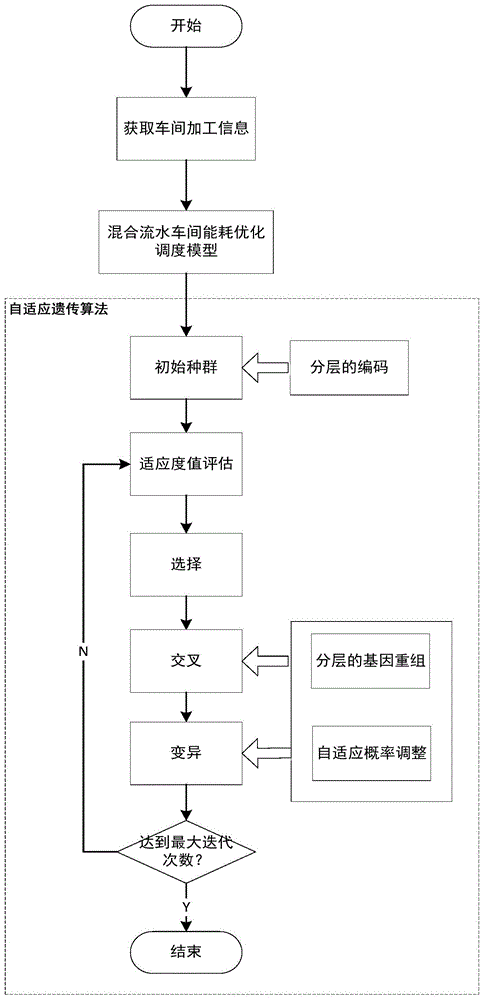
:尽管混合流水车间调度(hybridflowshopscheduling,hfs)问题已经有较多的研究成果,但是大多数的研究对实际问题做了简化,缺少对实际生产环境中复杂调度情况的考虑。体现在,一方面当前研究成果往往以优化生产性能为目标,例如,最小化最大完工时间、总的加工时间以及总的延迟时间等。然而,随着环境问题的凸显和能源成本的上升,生产制造的可持续发展越来越受到重视,尤其以如何优化生产过程中的能源消耗问题最为紧迫。因此,本发明将降低能耗作为生产调度的优化目标。另一方面,当前研究成果对实际生产调度中的约束条件考虑不足,而本发明考虑了来源于钢铁企业炼钢-连铸生产过程的末道工序批加工约束。因此,本发明研究末道工序批加工的混合流水车间可持续调度问题,具有重要的理论和应用价值。混合流水车间调度问题求解难度高,目前的求解方法主要有运筹学方法、启发式方法和元启发式方法。运筹学方法往往难以在有效时间内获得精确解,尤其难以应用于考虑了复杂约束的调度问题。启发式方法简单易行,然而对调度问题特点较为敏感,不具有一般性。元启发式方法不依赖于具体的调度问题,其由于较好的求解性能越来越受到青睐。其中,遗传算法在求解混合流水车间调度问题上得到了广泛的应用,然而其仍存在着易陷入局部最优解等缺点。鉴于此,本发明设计一种自适应遗传算法以获得高效的求解性能。经过对现有技术的文献检索,发现混合流水车间调度研究较多。在中国专利“一种用于混合流水车间调度问题的改进候鸟优化方法”(公开号cn108287531a),任彩乐等提出了改进的候鸟优化方法以求解经典的混合流水车间调度问题。在中国专利“一种混合流水车间调度方法”(公开号cn102929263a),李冬妮等提出了一种包含并行批处理、串行批处理和装配的混合流水车间调度方法。但这些技术方法都是以传统生产性能为优化目标。而在考虑能耗方面,在中国专利“一种混合流水车间调度节能控制方法”(公开号cn108153268a),孟磊磊等考虑了机床能耗和公共能耗,提出一种基于候鸟优化算法的求解方法。针对以能耗为优化目标的混合流水车间调度的技术方法还十分有限,并且这些技术对于来源于实际生产的约束考虑不足。因此,目前仍缺少以降低能耗为优化目标,同时考虑复杂实际约束的混合流水车间调度技术方法的研究。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于自适应遗传算法的混合流水车间可持续调度控制方法。本发明的目的可以通过以下技术方案来实现:一种基于自适应遗传算法的混合流水车间可持续调度控制方法,包括以下步骤:1)获取车间加工信息,包括工件数、加工工序、各道工序上的机器数、工件在机器上的加工时间、工件的单位驻留能耗、机器的单位等待能耗以及末道工序批加工信息;2)建立以最小化能耗为目标的末道工序批加工的混合流水车间调度模型;3)采用自适应遗传算法求解所述调度模型获得优化的调度方案,在所述自适应遗传算法中,以分层的方式进行编码和基因重组,并采取自适应的交叉和变异概率更新种群。进一步地,所述步骤2)中,最小化能耗的目标函数表示为:mine=ei+er式中,e为总能耗,ei为机器等待能耗,er为工件驻留能耗;i代表工件号,j代表机器号,k代表工序号;h为混合流水车间中总的工序数量,l为混合流水车间中总的工件数量,nk为在工序k上的机器数量;ak,ij为加工状态参数,若工件i在工序k的机器j上加工,则ak,ij=1,否则为工件i在工序k上的结束时间,nk,ij为工序k上的机器j加工工件i结束后所要加工的工件,为工件nk,ij在工序k上的开工时间,为工件i在工序k+1上的开工时间;ipk,j为工序k上的机器j的单位等待能耗,rpk,i为工件i在工序k和k+1之间的单位驻留能耗。进一步地,所述步骤2)中的调度模型满足的约束条件包括:a)同一个工件在每道工序上只能被加工一次;b)工件的开始加工时间不小于零;c)工件的上下工序约束;d)工件在加工过程中不能被打断;e)末道工序上同一个批次内的工件连续加工;f)末道工序上同一个机器在加工前后两个批次之间需要准备时间;g)末道工序上同一个工件只能被安排到一个批次中。进一步地,所述步骤3)中,分层的编码方式表示为:其中,矩阵b是一个h×l的矩阵,bk,i是工件i在第k道工序上选择的加工机器号,其一行即一层,一层上的基因代表了每个工件在一道工序上的机器选择,且最后一层的工件机器号基于所述末道工序批加工信息获得。进一步地,所述自适应遗传算法中,采用分层交叉方式实现交叉操作,且交叉概率自适应调整,所述分层交叉具体为:除最后一层外,在两个待交叉个个体上逐层选择待交叉的基因,在每一层中以部分映射交叉的方式进行交叉。进一步地,所述交叉概率的自适应调整公式为:其中,pcmin和pcmax分别是最小和最大交叉概率,fit(n)是个体n的适应度值,fitmax是当前种群中的最大适应度值,fitavg是当前种群中的平均适应度值,fitjdg=β×fitavg,参数β随机取自区间进一步地,所述自适应遗传算法中,采用分层变异方式实现变异操作,且变异概率自适应调整,所述分层变异具体为:除最后一层外,在待变异的个体上逐层选取变异基因,在每一层中将选取的两个基因以基因交换的形式进行变异。进一步地,所述变异概率的自适应调整公式为:其中,pmmin和pmmax分别是最小和最大变异概率,fit(n)是个体n的适应度值,fitmax是当前种群中的最大适应度值,fitavg是当前种群中的平均适应度值;fitjdg=β×fitavg,参数β随机取自区间与现有技术相比,本发明具有以如下有益效果:(1)本发明面向考虑末道工序批加工约束和能耗优化目标的混合流水车间调度问题,具有重要的实际应用背景,建立了以降低能耗为目标的调度模型,通过应用该模型,能在保证生产性能的情况下,明显降低能源消耗;本发明有利于制造企业节约能源,保证生产效率;(2)本发明设计了自适应遗传算法进行求解,主要技术特点包括分层的编码和基因重组方式,以及自适应的概率调整方法,算法流程简单,并且得到的调度方案优于其他常见的方法;(3)本发明有效提高制造企业的自动化水平、降低成本、提升效率,具有一定的应用价值。附图说明图1为本发明的流程示意图;图2为本发明自适应的交叉概率调整示意图;图3为本发明分层的交叉方式示意图;图4为本发明分层的变异方式示意图;图5为本发明实施例中两种调度模型在最大完工时间上的比较示意图。具体实施方式下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。如图1所示,本发明提供一种基于自适应遗传算法的混合流水车间可持续调度控制方法,通过建立末道工序批加工的混合流水车间调度的可持续性目标和约束条件,以自适应遗传算法求解调度模型得到优化的调度方案,以控制工件加工过程。该方法具体包括以下步骤:步骤1),获取车间加工信息,包括工件数、加工工序、各道工序上的机器数、工件在机器上的加工时间、工件的单位驻留能耗、机器的单位等待能耗以及末道工序批加工信息。步骤2),建立以最小化能耗为目标的末道工序批加工的混合流水车间调度模型。以最小化能耗e为目标,能耗e包括机器等待能耗ei和工件驻留能耗er,目标函数如公式(1)-(3)所示:mine=ei+er(1)式(2)表示机器等待能耗,式(3)表示工件驻留能耗。该调度模型应满足的约束条件如公式(4)-(11)所示:i1∪i2∪…∪iq=i(11)式(4)表示同一个工件在每道工序上只能被加工一次;式(5)表示工件的开始加工时间不小于零;式(6)表示工件的上下工序约束;式(7)表示工件在加工过程中不能被打断;式(8)表示末道工序上同一个批次内的工件连续加工;式(9)表示末道工序上同一个机器在加工前后两个批次之间需要准备时间;式(10)和(11)表示末道工序上同一个工件只能被安排到一个批次中。上述公式中:i:代表工件号;j:代表机器号;k:代表工序号;h:混合流水车间中总的工序数量;l:混合流水车间中总的工件数量;nk:在工序k上的机器数量;tk,ij:工件i在工序k的机器j上的加工时间;nk,ij:工序k上的机器j加工工件i结束后所要加工的工件;nh,ij:末道工序h上的机器j加工工件i结束后所要加工的工件;q:末道工序上的工件组成的批的数量;iq:批次q中包含的工件集合;cq:批次q的下一个批次;批次q的下一个批次cq中包含的工件集合;st:末道工序上同一个机器加工两个批次之间的准备时间;dq:批次q的计划开工时间;i:工件集合;k:工序集合;mk:工序k上的机器集合;mh:末道工序h上的机器集合;ipk,j:工序k上的机器j的单位等待能耗;rpk,i:工件i在工序k和k+1之间的单位驻留能耗;调度模型的决策变量包括:ak,ij:如果工件i在工序k的机器j上加工,那么ak,ij=1,否则,ak,ij=0;工件i在工序k上的开工时间;工件i在工序k上的结束时间。步骤3),采用自适应遗传算法求解所述调度模型,获得优化的调度方案。自适应遗传算法求解调度模型的具体步骤包括:(301)设置算法参数,包括初始种群大小、最大迭代次数、最大的交叉和变异概率以及最小的交叉和变异概率;(302)初始化种群,设计分层的编码方式,此分层的编码方式采用矩阵b表示,其一行即一层,一层上的基因代表了每个工件在一道工序上的机器选择,矩阵b如下所示:矩阵b是一个h×l的矩阵,h是总的工序数,l是总的工件数,bk,i是工件i在第k道工序上选择的加工机器号。这样,由此分层编码方式得到的矩阵b就是自适应遗传算法的一个个体;初始化时,依据此编码方式,依次在各层上(各道工序上),为每个工件随机选取一个当前工序上可用的机器;按照生产工艺要求,最后一层(末道工序上)的工件机器指派确定且已知,因此在最后一层上按照计划设置工件的机器号;(303)适应度值计算,将调度模型中的目标值的倒数作为适应度值。在计算目标值时,需要决策各个工件在每道工序上的机器选择以及加工的开始时间和结束时间。其中,机器选择可依据编码确定;对于加工的开始时间和结束时间,首先在末道工序上依据各个批次q的计划开工时间dq确定每个批次内各个工件的开始时间和结束时间,然后按照工序的反向顺序逆推工件在其他工序上的开始时间和结束时间,最后对各个机器上出现加工时间段冲突的工件进行调整;(304)选择,根据适应度值,采取轮盘赌的方式选取个体,准备进行交叉和变异;(305)交叉,设计了分层的交叉方式和自适应的交叉概率调整方式,个体n的自适应交叉概率的调整方式如下公式(13)所示:其中,pcmin和pcmax分别是最小和最大交叉概率,fit(n)是个体n的适应度值,fitmax是当前种群中的最大适应度值,fitavg是当前种群中的平均适应度值;fitjdg=β×fitavg,β随机取自区间如果(rand是0-1之间的随机数),那么进行分层的交叉,分层交叉在两个待交叉个个体上逐层选择待交叉的基因(除最后一层即末道工序),在每一层中以部分映射交叉(pmx)的方式进行交叉,如图2和图3所示;(306)变异,设计了分层的变异方式和自适应的变异概率调整方式,个体n的自适应变异概率的调整方式如下公式(14)所示:其中,pmmin和pmmax分别是最小和最大变异概率,fit(n)是个体n的适应度值,fitmax是当前种群中的最大适应度值,fitavg是当前种群中的平均适应度值;fitjdg=β×fitavg,β随机取自区间如果(rand是0-1之间的随机数),那么进行分层的变异,分层变异在待变异的个体上逐层选取变异基因(除最后一层即末道工序),在每一层中将选取的两个基因以基因交换的形式进行变异,如图4所示;(307)判断是否达到最大迭代次数,如果是,则结束算法并且输出当前最优的解;否则,返回步骤(303)。以某钢铁联合企业的炼钢-连铸生产环节为例,验证本发明的有效性。炼钢-连铸的生产调度可以抽象为末道工序批加工的混合流水车间调度问题,其有3道加工工序,每道工序上的机器数量分别是3台、5台以及3台,一共有54个工件准备加工。工件在机器上的加工时间、工件的单位驻留能耗以及机器的单位等待能耗,各自在[30,55],[5,10],[3,8]上满足均匀分布。同时,在末道工序上,每6个工件组成1个批次进行批加工,因此一共有9个批次。不同批次之间的准备时间是100。根据上述生产数据,本发明随机产生5组实例进行实验和对比,仿真实验在matlab2016b平台上实现。接下来,依次对考虑能耗优化的调度模型有效性、自适应概率调整方法有效性以及分层方案有效性的验证方式和结果进行说明。为了说明本发明调度模型(we)在降低能耗方面的有效性,这里选取以最小化最大完工时间为目标的传统调度模型(cmax)作为比较对象,分析调度cmax模型与we模型在能耗优化上的差别。首先,使用本发明的自适应遗传算法分别求解we模型和cmax模型的5组实例,每组实例求解10次。然后,统计调度两个模型得到的机器等待能耗、工件驻留能耗以及总能耗,对每类能耗数据取平均值。最后,在各类能耗上,计算出两个模型的5组实例的平均能耗比值,结果如表1所示。5组实例的平均能耗比值显示,在机器等待能耗、工件驻留能耗以及总能耗上,调度cmax模型的结果分别是调度we模型结果的1.86,3.02,2.28倍,充分说明了调度本发明模型可以有效地降低能耗。表1两种模型在能耗值上的比对结果同时,在相同情况下调度we模型与cmax模型的5组实例,比较在最大完工时间上的差距,结果参考图5所示。可以看到,在实例1中,调度we模型与cmax模型得到的最大完工时间是相同的。并且,在其余实例中,调度两种模型得到的最大完工时间同样十分接近。从表1和图5可以得到,调度we模型的平均总额外能耗是11587.2(kw·h),平均最大完工时间是1134.16(s),而调度cmax模型的平均总额外能耗是26282.08(kw·h),平均最大完工时间是1127.2(s)。相比于调度传统的cmax模型,调度本文we模型在延长了0.617%最大完工时间的情况下,降低了55.912%的能耗。因此,调度本文模型可以有效降低能源消耗,同时保证较好的生产性能。为了验证本发明公开的自适应遗传算法的有效性,这里选取的性能指标是相对增长率(rpi),计算方式如公式(15)所示:rpi=(e-e*)/e*×100(15)其中,e表示每种算法求解生产数据的目标值,e*表示参与比较的所有算法中求解出来的最小目标值,即最优目标值。首先验证本发明提出的自适应概率调整方法的有效性,这里比较四种交叉和变异概率选取方式,包括传统的固定概率(nv)、线性的概率调整方式(lv)、非线性的概率调整方式(nlv)以及本文的概率调整方式(ourmethod)。这里,nv的交叉概率是0.9,变异概率是0.1。其他三种调整方式的最大和最小交叉概率是0.9/0.6,最大和最小变异概率是0.5/0.1。另外,四种调整方式对应的四种算法设置相同种群大小和最大迭代次数(nind=100,maxgen=300),并且四种算法的初始种群相同。为了更好地比较算法性能,每组实例求解10次,计算每一次的rpi,统计出5组实例的平均rpi,如表2所示(加粗表示每组最小的rpi值)。表2自适应概率调整方式的比较实例nvlvnlvourmethod15.804.126.310.0028.4715.126.541.2637.326.185.641.80410.8613.946.921.6959.4611.124.342.46mean8.3810.105.951.44从表2中可以看出,本发明的算法求解5组实例得到的rpi都是最小的,平均rpi是1.44%。相比于其他三种算法,本发明的算法可以得到每组实例的最优目标值。另外,具有非线性的概率调整方式的算法的平均rpi是5.95%,优于平均rpi是10.10%的线性概率调整方式,同样优于平均rpi是8.38%的固定概率的算法。然而,具有线性概率调整方式的算法在例子1和3中优于固定概率的算法,在例子2,4,5中差于nv算法,说明了线性概率调整方式的不稳定性。因此,本发明的自适应交叉和变异概率调整方式对于求解调度模型具有最佳的效果。为了验证分层方案的有效性,本发明将具有分层方案的eaga和不具有分层方案的eagane进行对比。相比于eaga,eagane采取一维编码方案进行初始化种群,并且采取与eaga相同的自适应交叉和变异概率调整方式。为了公平地进行比较,给两种算法赋予代表相同机器选择的初始种群,并且设置了相同的算法参数(种群大小100,最大迭代次数300,最大和最小交叉概率0.9/0.6,最大和最小变异概率0.5/0.1)。eaga和eagane分别求解5组实例,每组实例运行10次。5组实例的运行10次的平均rpi如表3所示(加粗表示每组最小的rpi值)。表3分层方案的有效性实例eaganeeaga14.80%1.15%23.91%1.59%35.33%1.01%44.50%1.40%54.00%1.52%mean4.51%1.33%从表3中看出,eaga求解5组实例得到的rpi都小于eagane,并且eaga求解5组实例得到的meanrpi小于eagane的1/3,因此分层方案提高了eagane的求解性能。最后,我们将本发明的自适应遗传算法(eaga)与常用与求解混合流水车间调度问题的模拟退火算法(sa)、粒子群算法(pso)和混合智能局部搜索算法(gls)进行比较。为了将这些算法用于求解本发明的模型,这里修改了相应的计算目标值方法和初始化种群方式。为了公平地进行比较,pso和gls的初始种群与eaga相同,避免初始种群对于解的影响。同时,将终止条件设置为:连续10次寻优的最优解都相同。这里,将四种算法分别求解5组生产数据,每组数据求解10次。5组实例的运行10次的平均rpi如表4所示(加粗表示每组最小的rpi值)。表4eaga与其他算法比较结果从表4中可以清楚的看出,相比于其他三种算法,本发明的eaga求解每组实例的rpi都是最小的。另外,在四种算法求解5组实例得到的rpi的平均值中,eaga的平均值是0.97%,小于排在第二位gls(5.38%)的1/5倍。而其他两种算法的平均rpi都较大,排在第三位的sa的平均值是19.71%,而排在最后的pso的平均值是20.05%。因此,提出的eaga求解本发明的末道工序批加工混合流水车间能耗优化模型是非常有效的。综合上述实施例的详细说明和实验的结果分析,表明本发明公开的基于自适应遗传算法的混合流水车间可持续调度方法可以明显降低能源消耗,同时保证生产性能。相比与其他算法,设计的自适应遗传算法具有较好的求解性能。以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本
技术领域:
中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1