一种基于汽车雷达的扩展目标跟踪方法与流程
本发明涉及智能驾驶技术领域,具体涉及一种基于汽车雷达的扩展目标跟踪方法。
背景技术:
智能驾驶,是指通过雷达、激光测距器、视频摄像头等装置检测行驶路况,通过地图对前方道路进行导航。在智能驾驶的过程中,智能汽车可为驾驶员提供协助,可在驾驶员收到警告却未能及时采取相应行动时自动进行干预,可在或长或短的时间段内代替驾驶员操控车辆。
智能驾驶领域涉及多目标跟踪系统,多目标跟踪系统在包含杂波、虚警和目标的场景中对目标进行检测、跟踪和识别,其中,目标的数量是可变的。扩展目标是指在同一时刻产生多个量测的目标,即,如果本智能汽车在每一时刻能都能接收到来自同一辆目标汽车的车头、车尾、车轮等不同部位的检测信息,那么该目标汽车则为扩展目标。
现有技术在多目标情形下的扩展目标跟踪方面存在跟踪效率低和跟踪精度差的问题,目前提出的解决该问题的方法有聚类跟踪法和伽马高斯逆威夏特-概率假设密度法(ggiw-phd),聚类跟踪法的优点在于计算时间短,缺点在于无法确定扩展目标的形状,由此带来的位置误差、速度误差较大,尺寸误差、偏航角误差更是难以预计,ggiw-phd的优点在于计算时间略高,位置误差与速度误差相对于聚类跟踪法小,缺点在于尺寸误差和偏航角误差较大。这两种方法都未能实质性解决扩展目标的跟踪效率低和跟踪精度差的问题。
技术实现要素:
本发明提供一种基于汽车雷达的扩展目标跟踪方法,解决现有技术中存在扩展目标跟踪效率低、跟踪精度低的问题。
本发明通过以下技术方案解决技术问题:
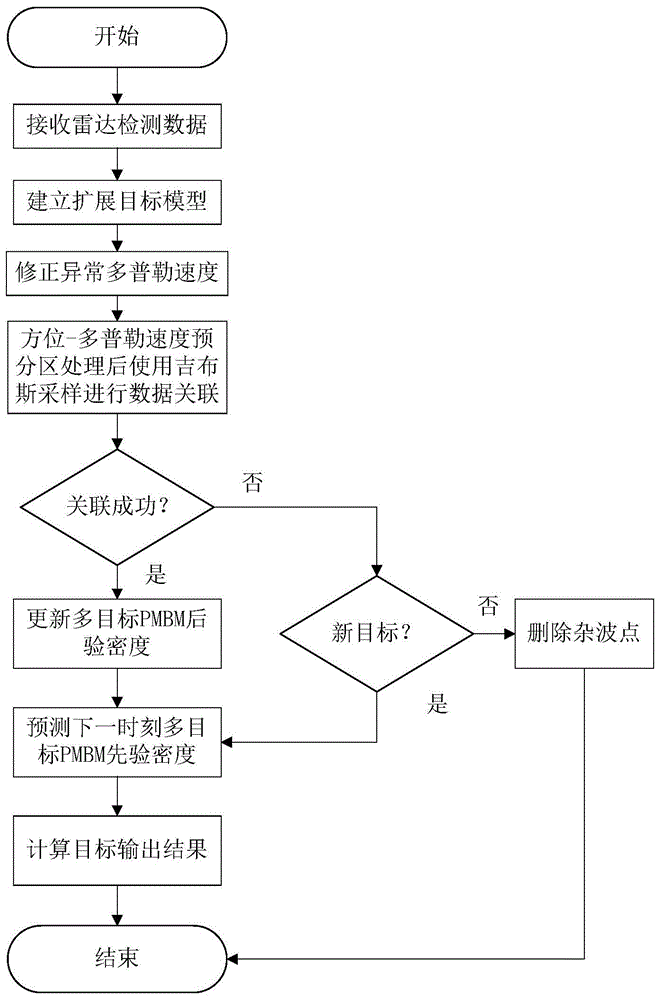
一种基于汽车雷达的扩展目标跟踪方法,包括如下步骤:
(1)获取汽车雷达的检测数据
实时接收各时刻下本智能汽车的雷达检测数据,所述雷达检测数据包括各时刻下本智能汽车相对于各量测目标汽车的径向距离、角度以及多普勒速度,得到各量测目标汽车的测量集;
(2)建立扩展目标模型
根据各时刻下、各实际目标汽车的状态集建立实际目标汽车的随机有限集模型,根据各量测目标汽车的测量集建立量测目标汽车的随机有限集模型;
(3)修正异常多普勒速度
在量测目标汽车的随机有限集模型中,针对每个量测目标汽车,对各时刻下的多普勒速度进行处理,找出车轮位置,修正每个量测目标汽车转弯时产生的异常多普勒速度以及车轮附带的异常多普勒速度,得到量测目标汽车的修正随机有限集模型;
(4)通过吉布斯采样进行数据关联
在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据进行方位-多普勒速度预分区处理,使用吉布斯采样获取关联的多普勒速度;
(5)根据关联结果进行更新或预测
针对各时刻下、各量测目标汽车关联的多普勒速度,如关联成功,根据步骤(2)中的实际目标汽车的随机有限集模型、步骤(3)中量测目标汽车的修正随机有限集模型以及pmbm测量模型更新多目标pmbm后验密度,并预测下一时刻的多目标pmbm先验密度;如关联不成功,则判断是否出现新目标,如是新目标,则根据当前时刻的多目标pmbm后验密度以及贝叶斯滤波器模型预测下一时刻多目标pmbm先验密度,否则删除该多普勒速度;
(6)计算目标输出结果。
进一步地,步骤(2)中,所述实际目标汽车的随机有限集模型包含各时刻下、本智能汽车相对于各个实际目标汽车的径向距离、角度以及多普勒速度信息;所述量测目标汽车的随机有限集模型包含测量集信息。
进一步地,步骤(3)中,在量测目标汽车的随机有限集模型中,针对每个量测目标汽车,通过各时刻下的多普勒速度找出车轮位置以及修正异常多普勒速度的步骤为:
(31)在当前被测单元的前端设置1个保护单元,为前端保护单元,在所述前端保护单元的前端设置
(32)所述前端保护单元和后端保护单元中的各多普勒速度进行求和运算,计算出平均值;
(33)如当前被测单元的多普勒速度大于预设值时,说明当前被测单元是车轮,将该车轮附近的异常多普勒速度用步骤(32)中的平均值替代,否则,执行步骤(34);
(34)以下一个被测单元作为当前被测单元,继续执行步骤(31)、(32)、(33)直至找出所有车轮,完成异常多普勒速度的替代工作。
进一步地,步骤(4)中,在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据,方位-多普勒速度预分区处理的方法为:
(41)在方位上以椭圆形作为窗口;
(42)将修正后的当前时刻下、当前量测目标汽车的、落入椭圆形窗口范围的多普勒速度从小到大排序,如首尾多普勒速度的差值大于预设阈值,则使用k-means算法将所述椭圆形窗口范围内的区域一分为二,得到两个新分区,否则,完成预分区处理;
(43)针对各新分区,分别重新选取椭圆形窗口,执行步骤(42),直至各新分区的首尾多普勒速度的差值小于或等于预设阈值,完成预分区处理。
进一步地,步骤(4)中,在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据采用吉布斯采样法获取关联的多普勒速度时,采样的迭代次数为
进一步地,步骤(5)中,关联成功后,针对各时刻下、各量测目标汽车的多普勒速度,更新多目标pmbm后验密度的方法为:
将步骤(2)中的实际目标汽车的随机有限集模型、步骤(3)中的量测目标汽车的修正随机有限集模型以及pmbm测量模型结合,得到多目标pmbm后验密度
式中,
式中,
式中,
进一步地,步骤(5)中,更新多目标pmbm后验密度之后,或关联失败但确定是新目标后,针对各时刻下、各量测目标汽车的多普勒速度预测下一时刻的多目标pmbm先验密度,下一时刻的多目标pmbm先验密度为
进一步地,步骤(6)中,所述输出结果包括目标位置、目标速度、目标尺寸以及目标偏航角。
与现有技术相比,具有如下特点:
1、本发明将多普勒速度加入量测目标汽车的随机有限集模型,充分考虑动态的多目标参与以及多变的扩展目标状态的情形,对异常多普勒速度进行修正,提高后期环节的计算精度,减少后期环节冗余数据的计算量算,以吉布斯采样法进行数据关联,可大幅度减小计算量,根据关联结果更新多目标pmbm后验密度,再预测下一时刻的多目标pmbm先验密度,或,判断是否有新目标进入,对新目标预测下一个时刻的多目标pmbm先验密度,再结合完全状态向量计算输出结果,可大大提高目标位置、目标速度、目标尺寸、目标偏航角以及目标偏航率的计算精度,本发明既能充分考虑到新目标的加入,又能以尽可能小的计算量精确跟踪扩展目标,实质性提高跟踪效率和跟踪精度;
2、修正异常多普勒速度时,先检测车轮位置,以车轮位置的前后端保护单元的平均多普勒速度替代异常多普勒速度,再进行下一步的数据关联,车轮检测和均值插入,能避免各量测目标汽车转弯时产生的异常多普勒速度以及各量测目标汽车车轮附带的异常多普勒速度的干扰,提高后续环节的关联精度、更新精度、预测精度以及目标结果的计算精度,同时还减少后续关联、更新、预测环节的冗余计算,可实现以尽可能小的计算量获取尽可能大的计算精度,可大大提高跟踪效率和跟踪精度;
3、预分区处理阶段,以椭圆形作为窗口,充分考虑了毫米波雷达在横向测角方面存在些许误差的情形,将误差造成的干扰降到最小,为提高跟踪精度提供支持;
4、更新多目标pmbm后验密度时以实际目标汽车的随机有限集模型、量测目标汽车的修正随机有限集模型和pmbm测量模型为基础,预测下一时刻多目标pmbm先验密度时以上一时刻的多目标pmbm后验密度为基础,并考虑目标存活概率,结合贝叶斯滤波器模型完成预测,本发明以泊松多伯努利混合滤波法完成的更新环节和预测环节相互关联,环环相扣,为计算目标输出结果提供精确的数据基础,以提高跟踪效率和跟踪精度。
附图说明
图1为本发明的方法流程图。
图2为本发明的扩展目标模型参数示意图。
图3为修正异常多普勒速度前后的数据对比图。
图4为修正异常多普勒速度的算法流程图。
图5为车轮多普勒速度示意图。
图6为三种跟踪方法的时间对比图。
图7为三种跟踪方法的属性对比图。
具体实施方式
以下结合实施例对本发明作进一步说明,但本发明并不局限于这些实施例。
一种基于汽车雷达的扩展目标跟踪方法,其流程图如图1所示,包括如下步骤:
(1)获取汽车雷达的检测数据
实时接收各时刻下本智能汽车的雷达检测数据,所述雷达检测数据包括各时刻下本智能汽车相对于各量测目标汽车的径向距离、角度以及多普勒速度,得到各量测目标汽车的测量集;
(2)建立扩展目标模型
根据各时刻下、各实际目标汽车的状态集建立实际目标汽车的随机有限集模型,根据各量测目标汽车的测量集建立量测目标汽车的随机有限集模型;
(3)修正异常多普勒速度
在量测目标汽车的随机有限集模型中,针对每个量测目标汽车,对各时刻下的多普勒速度进行处理,找出车轮位置,修正每个量测目标汽车转弯时产生的异常多普勒速度以及车轮附带的异常多普勒速度,得到量测目标汽车的修正随机有限集模型;
(4)通过吉布斯采样进行数据关联
在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据进行方位-多普勒速度预分区处理,使用吉布斯采样获取关联的多普勒速度;
(5)根据关联结果进行更新或预测
针对各时刻下、各量测目标汽车关联的多普勒速度,如关联成功,根据步骤(2)中的实际目标汽车的随机有限集模型、步骤(3)中量测目标汽车的修正随机有限集模型以及pmbm测量模型更新多目标pmbm后验密度,并预测下一时刻的多目标pmbm先验密度;如关联不成功,则判断是否出现新目标,新目标的判断通常通过一段时间内的m/n准则来实现,如是新目标,则根据当前时刻的多目标pmbm后验密度以及贝叶斯滤波器模型预测下一时刻多目标pmbm先验密度,否则删除该多普勒速度;
(6)计算目标输出结果。
本智能汽车上安装有雷达,驾驶过程中,雷达对车道上的各量测目标汽车发射电磁波,并接收回波,以此各获取量测目标汽车相对于本智能汽车的径向距离、角度和多普勒速度。步骤(1)中,本智能汽车在每个时刻下均接收来自各量测目标汽车的径向距离、角度以及多普勒速度数据,并且,量测目标汽车的数量在量测过程中可能会发生增减。
图2为本发明的扩展目标模型参数示意图,通过图2可知本智能汽车(ego-vehicle)相对于量测目标汽车(target)的径向距离为r、角度为θ、多普勒速度为vd,量测目标汽车车身的长为l、宽为b、后桥行驶速度为v、后桥偏航角为
随机有限集(rfs)中元素的数量是随机变量,元素的顺序实时变化,集合中的势也是随机变量,将多普勒速度加入到随机有限集中进行多目标、扩展目标的建模,适用于多目标、扩展目标跟踪的场景。本发明使用rfs形式,其目的是将实际目标汽车的状态集看作多目标状态,将量测目标汽车的测量集看做多目标观测,进而将多目标跟踪问题转化成多目标状态空间和观测空间上的滤波问题。
在随机有限集框架下,k时刻n(n为正整数)个实际目标汽车的状态
在随机有限集框架下,k时刻雷达接收到的m(m≥n,m为正整数)个量测数据
固定的矩形边界和合理范围的矩形边界关系到后续尺寸计算的性能。本发明中,设置量测目标车辆的长度为1~6m,宽度为1~3m,长宽比为1:1~3:1。进一步地,本发明设置量测目标车辆矩形边界的初始参数长度设置为4.8m,宽度为1.7m。固定的矩形边界和合理范围的矩形边界,还有助于在修正异常多普勒速度环节快速找到车轮位置。
量测目标汽车在线性运动中,车身所有的点都有相同的速度矢量,但是,当量测目标车辆转弯时,车身纵向中心轴(旋转轴)上各点的速度矢量的(不包括旋转中心)纵向速度不同,其他各点的横向速度随时间变化,便产生了异常多普勒速度。另外,量测目标汽车的车轮附带额外的多普勒速度,也会导致出现异常多普勒速度。可以使用常虚警(cafr)方法来检测异常多普勒速度值,并使用异常多普勒速度修正算法对上述两种异常速度进行修正。
现有技术中有学者提出从单帧数据中提取车轮多普勒的方法,给出车轮多普勒速度在智能汽车坐标系下的检测结果,如图5所示,通过图5可知,车轮出速度异常,多普勒速度值相对于其它点的值大许多。因此,修正异常多普勒速度前应当先找出车轮位置。
在图3中,将量测目标汽车的分布在车身边沿的1-15个量测点(measurementindex)以及对应的多普勒速度(dopplervelocity)放入坐标系中,观察可发现车轮处量测点的多普勒速度大于其他量测点的多普勒速度,根据量测点的多普勒速度分布便可找出矩形车身的拐点,从而可确定车轮的位置,并进一步确定量测目标汽车的实际长和宽。
步骤(3)中,在量测目标汽车的随机有限集模型中,针对每个量测目标汽车,通过各时刻下的多普勒速度找出车轮位置以及修正异常多普勒速度的步骤为:
(31)在当前被测单元的前端设置1个保护单元,为前端保护单元,在所述前端保护单元的前端设置
(32)所述前端保护单元和后端保护单元中的各多普勒速度进行求和运算,计算出平均值;
(33)如当前被测单元的多普勒速度大于预设值时,说明当前被测单元是车轮,将该车轮附近的异常多普勒速度用步骤(32)中的平均值替代,否则,执行步骤(34);
(34)以下一个被测单元作为当前被测单元,继续执行步骤(31)、(32)、(33)直至找出所有车轮,完成异常多普勒速度的替代工作。
异常多普勒速度修正算法如图4所示,cut为当前被测单元,guardcells为保护单元,rererencecells为参考单元,输入的多普勒速度数据(input)经求和、求平均后理后,再经比较器(comparator)输出,得到多普勒速度输出结果(output)。在异常多普勒速度修正算法中,通过对前后端参考单元的求和,得到前后端参考单元的局部估计,设置距离当前被测单元最近的两个单元作为保护单元,主要用于防止新的量测目标信号进入参考单元,影响局部估计值。
步骤(32)中,平均值表达式为
步骤(4)中,在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据,方位-多普勒速度预分区处理的方法为:
(41)在方位上以椭圆形作为窗口;
(42)将修正后的当前时刻下、当前量测目标汽车的、落入椭圆形窗口范围的多普勒速度从小到大排序,如首尾多普勒速度的差值大于预设阈值,则使用k-means算法将所述椭圆形窗口范围内的区域一分为二,得到两个新分区,否则,完成预分区处理;
(43)针对各新分区,分别重新选取椭圆形窗口,执行步骤(42),直至各新分区的首尾多普勒速度的差值小于或等于预设阈值,完成预分区处理。
步骤(41)中,从方位维度考虑,毫米波雷达在纵向测距方面具有极高的精度,但是在横向测角方面会有些许误差,基于这一特点,航迹在方位上的开窗不再选用基于欧氏距离的圆形,而是选择椭圆形,且椭圆形窗口的其长宽比为2:1。
步骤(42)中,k-means算法是已知的、用于分类的算法,根据各个维度的参数将一类分成两类,即,认为一个目标可能是两个目标时,便将该目标分为两个目标。
吉布斯采样需要知道样本中一个属性在其他所有属性下的条件概率,然后利用这个条件概率来推导出各个属性的样本值。吉布斯采样可以在给定协方差数据和参数的先验分布条件下获得参数的后验分布样本。每个样本是测量值的一个分区,即,每个样本对应于检测到的目标的分布。使用吉布斯采样获取目标点与各个已有目标轨迹关联的概率,并设置关联概率阈值,选取大于概率阈值、并且概率最高情况的认为该目标点属于该目标轨迹,认为关联成功,如果所有的概率都小于设定的关联阈值,则认为未关联成功。
吉布斯采样是一种迭代的马尔科夫蒙特卡洛(mcmc)方法,可用于从多元分布中直接抽样比较困难的情况。应用于扩展的对象跟踪数据关联,基本思想是给定随机选择的测量集引索指标,在保持所有其他关联不变的情况下,随机改变相应的关联。如,在量测目标汽车的随机有限集模型z中,k时刻下第a的表达式为
为避免吉布斯采样器老化周期,步骤(4)中,在量测目标汽车的修正随机有限集模型中,针对各时刻下、各量测目标汽车的数据采用吉布斯采样法获取关联的多普勒速度时,采样的迭代次数为
在进行更新多目标pmbm后验密度和预测下一时刻多目标pmbm先验密度之前,先阐述与之相关的伯努利随机有限集(mbrfs)的基础信息、泊松点过程随机有限集(ppprfs)的基础信息、泊松多伯努利混合物随机有限集(pmbm)的推广信息以及多贝叶斯滤波器的基础信息。
mbrfs:mbrfs多目标密度表达式为
其中,r∈[0,1],表示量测目标汽车存在的概率,f(x)为概率密度函数,x表示各实际目标汽车的状态集。
mbrfs是由i索引的独立伯努利rfss的不相交并集,参数化为
其中,σ表示的一个排列{1,...,n},
将mb的密度加权得到mbm密度
ppprfs:ppprfs基数服从泊松分布,元素相互独立,但是服从相同的分布,可参数化为d(x)=λf(x),λ>0代表泊松比,f(x)为单一元素x的概率密度函数。ppp多目标密度表达式为
pmbmrfs:pmbmrfs是由具有多目标密度的ppprfs和mbmrfs的不相交集联合而成,表达式为
多贝叶斯滤波器是经典贝叶斯滤波器对rfss的严格扩展,可用于估计多目标状态的后验密度。多目标贝叶斯滤波器使用预测和更新步骤迭代地传播多目标分布。通过使用运动模型来执行预测步骤,在概念上,可以将贝叶斯滤波框架中描述成是一个基于rfs的滤波器。根据chapman-kolmogorov方程推导时间步长多目标后验密度:
fk|k-1(xk|z1:k)=∫fk|k-1(xk|xk-1)fk-1|k-1(xk-1|zk-1)δxk-1
其中,xk是k时刻的状态集,zk是k时刻的测量集,k-1代表上一时刻,fk|k-1(xk|z1:k-1)为k时刻的多目标先验概率。∫·δx代表设定积分。多目标传输密度fk|k-1(xk|xk-1)可以描述传输的变化。更新阶段使用当前时刻的测量集zk,利用贝叶斯理论计算多目标后验概率
步骤(5)中,关联成功后,针对各时刻下、各量测目标汽车的多普勒速度,更新多目标pmbm后验密度的方法为:
将步骤(2)中的实际目标汽车的随机有限集模型、步骤(3)中的量测目标汽车的修正随机有限集模型以及pmbm测量模型结合,得到多目标pmbm后验密度
步骤(5)中,更新多目标pmbm后验密度之后,或关联失败但确定是新目标后,针对各时刻下、各量测目标汽车的多普勒速度预测下一时刻的多目标pmbm先验密度。
当前时刻的多目标pmbm后验密度参数为
步骤(6)中,所述输出结果包括目标位置、目标速度、目标尺寸以及目标偏航角。
根据步骤(5)提供的目标汽车k时刻的空间密度和位置确定矩形框的长宽,量测目标汽车后桥的位置(xr,k,yr,k)在矩形宽bk的中间,至车头0.77lk倍的位置,根据修正后的多普勒速度求平均得到速度vk,对预设时间内后桥位置的变化使用最小二乘法拟合求得偏航角
本发明对聚类跟踪方法、ggiw-phd跟踪方法以及本发明的跟踪方法做仿真和对比。本智能汽车以25m/s的速度行驶在一段500米长的高速公路上,在这20s中有2~4辆汽车出现在测量场景中。聚类跟踪方法、ggiw-phd跟踪方法以及本发明跟踪方法的运算时间对比图如图6所示,通过图6可以看出,在相同的时间步长下,本发明的跟踪时间略高于聚类跟踪方法、ggiw-phd跟踪方法。三种跟踪方法的属性对比图如图7所示,通过图7可知,在位置误差、速度误差较大,尺寸误差、偏航角误差方面,本发明在综合性能远优于聚类跟踪方法和ggiw-phd跟踪方法,在增加少量时间复杂度的情况下,更高效、更精确地完成跟踪。
- 还没有人留言评论。精彩留言会获得点赞!