遍历多点归原的路径规划方法
本发明涉及涉及计算机智能路径规划
技术领域:
,尤其涉及一种围绕最小生成树方法的遍历多点归原的遍历多点归原的路径规划方法。
背景技术:
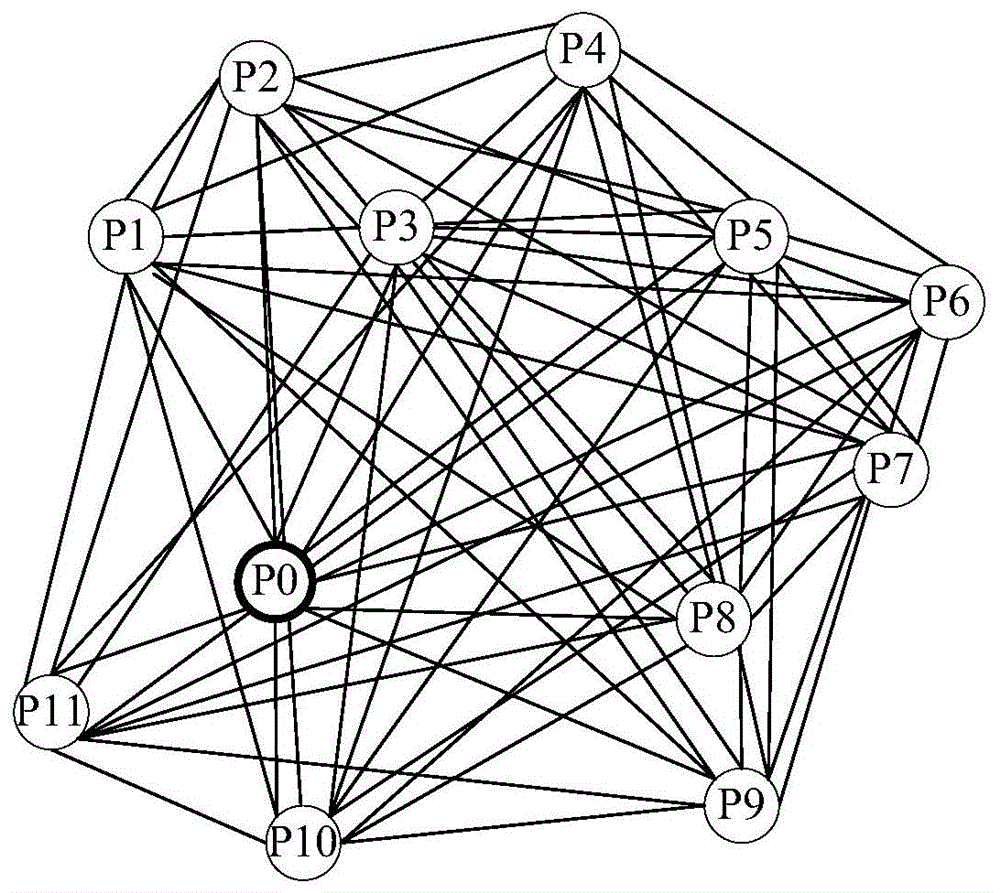
:在现实应用领域,现流行的导航软件有百度、高德、腾讯等导航app,它们的主要功能就是根据用户的需要和根据现实的交通情况,实现一辆车到一个目的地的不考虑回程的合理的路径规划。而现实中需要更复杂的路径规划,比如要合理规划出货车从物流中心出发,到多个目的地进行收货,收货完毕后返回物流中心的路径规划,即遍历多点归原的路径规划,而这种路径规划在现在的导航app中是没有的。在已有的软件服务平台中,滴滴快车的顺风车服务、美团外买骑手app、公交线路规划等,都被误认为是我们的路径规划算法的程序实现,其实它们都不是我们前面所说的遍历多点归原的路径规划,它们只是两点路线规划在现实应用中的升级改进,或是多次两点路线规划的结果。在路径规划领域,遍历多点归原的最短路径规划算法属于tsp(travelingsalesmanproblem)问题(可百度搜索tsp问题),它是一个组合优化问题。该问题已经被证明具有npc计算复杂性,也就是说,针对大型实例,不存在高效稳定且最佳算法这一猜想。所以,高效稳定且接近最佳路径规划方案是众多人的研究方向。现在常见的算法有全排列算法及其提速法、近似算法和各种模拟算法,但这三种算法都不能做到高效稳定且近似最佳,现分析如下:全排列算法,它是唯一能解决遍历多点归原的路径规划的算法,但它是一种低效的计算方法,在目的地较多的情况下,计算效率极低,无法在可接受的时间内得到结果,比如在20个点的情况下,它的计算次数为2432902008176640000次,对于一般计算机来说,实在太多了,用户等待计算时间过长。所以全排列算法不是高效的算法。全排列算法的提速法,比如:分界截支算法,它们在一定程序上提高了组合排列算法的效率,但提高后的效率仍然不理想。各种近似算法,这些算法有最近点算法、节省路程算法、最小生成树算法(不是多点归原算法)、随机算法等,它们可以做到高效,但不稳定,存在多种可能的近似方案,并且经常得不到近似结果。各种模拟算法:这些算法包括有:人工智能的神经网络算法、蚁群算法、鱼群算法、退火算法、遗传算法等等,这些算法都站不住脚,现具体分析如下:1)首先人工智能的神经网络算法,它的特点是需要人的大量训练后,计算机才能拥有相关的功能,但对于多点路径规划来说,本来凭借人的智力也难在一时三刻找到最佳路径,更不用说要人对机器做大量训练了。所以这种命题是伪命题。2)其次是蚁群算法、鱼群算法、退火算法,这类低级智商动物算法更不用与人工智能算法比了。并且在平时观察可了解蚁群和鱼群并不走最短路径,它们一般走安全路径,最明显的是蚁群。其次,这些算法是局部最优算法,不稳定,每次计算,结果可能不一样,并且一但路径规划失败,将重新规划,耗时绝对不低。3)遗传算法,与上面的算法也有相同的缺点,首先它是局部最优算法,没有宏观调控,并且这种算法有随机性(不稳定),失败后又要重新计算,消耗时间变长。总的来说,现在还没有一种符合现实应用的高效且稳定的接近最佳的算法。技术实现要素:本发明所要解决的技术问题是如何提供一种计算量小,计算速度快,稳定性强的遍历多点归原的路径规划方法。为解决上述技术问题,本发明所采取的技术方案是:一种遍历多点归原的路径规划方法,其特征在于包括如下步骤:1)先知条件:已知原点及其它地点的经纬度,并且所有的点的数目超过10个;已知所有点之间的最短路程,并且形成最短路程矩阵;两点间的路程不分方向,路径的正反向路程值相等;通过上述条件,得到这些点的网络图ga和最短路程矩阵pt;2)求最小生成树:基于第1步的条件,求最小生成树;通过上述步骤得最小生成树邻接矩阵tm并得到最小生成树图;3)取最小生成树中的各子树:根据得到的最小生成树邻接矩阵tm以及最小生成树图,并根据取子树的组合公式,进行计算;得各子树的根结点集合b0、各子树的点的集合、各子树图;4)求最密子树:根据前面步骤的条件,结合子树密度组合公式,得各子树密度值;把各子树密度值作为条件,用取最密子树公式,筛选出最密子树集;5)在最密子树中找到最边沿叶子1;使用数据结构技术中的后序遍历方法,对最密子树进行遍历,得到各节点的遍历顺序集合;在集合中的第一个节点为最边沿叶子1;6)针对最密子树找最边沿叶子端点2:根据第5步的遍历顺序集合,以集合作为条件,通过取叶子公式,可得后序遍历顺序的叶子端点集合;叶子端点集合的最后一个节点为最边沿叶子端点2;7)在两个最边沿叶子端点中,确定一个是最密子树始点,另外一个是最密子树终点:根据综合路程值公式,求两个最边沿叶子端点的综合路程值;综合路程值小者为最密子树始点,另外一个是最密子树终点;8)以最密子树根节点和最密子树始点和最密子树终点组成的回路为主线,把最密子树中的叶子端点合并到主线中:以最密子树根节点和最密子树始点和最密子树终点组成的回路为主线;把最密子树中,不在主线上叶子端点合并到主线中,形成新的主线;删除最密子树中叶子的分支;判断最密子树中是否有叶子端点,如果有关步骤,一直到最密子树中没有叶子端点为止;在进行上述步骤的同时,tm矩阵作相应的设置;9)原点与主线合并,形成回路:使用jsprit的rebuild方法,把原点合并到主线中;根据删除公式,删除原点与最密子树根结点间的路径;经过上面的步骤,从而形成一个:以原点为始点,经过原来的最密子树上的点,回到根结点的回路;10)对剩下的子树进行判断,点数超过1的子树重复步骤4)到步骤9),让子树形成回路,过程如下:除了原点,排除现有的回路上的点和路径。把剩下的点所组成的各个子树,逐个经过步骤4)到步骤9),都各自形成回路;重复上面操作,一直进行到没有点数超过1的子树为止;点数为1的子树就当成一个回路,它们都是从原点出发,经过叶子,回到原点的回路;第1颗最密子树形成的回路,用h1代表,按顺时针方式,在h1旁的回路,用h2代表;11)求各回路的回路始点与回路终点:针对只有2点的回路,其叶子端点就是回路始点,也是回路终点;针对超过2点的回路,从原点开始,顺时针遍历回路;除了根结点,第一个遍历的节点是回路始点,用as代表,最后一个是回路终点,用ae代表;所有超过2点的回路用同样的方法,都得到它们各自的回路始点与回路终点;12)使用回路间节约里程公式,求节约里程值:根据我们的回路间节约里程公式,求上一回路终点与下一回路始点间的节约里程数值;13)根据节约里程数值,使用节约里程方法,对回路进行合并:根据节约里程数值,使用节约里程方法,对节约里程值大的两个回路先进行合并;重复步骤11)至步骤13)的过程,一直合并到回路数量为1时停止;14)所有的回路合并后,最终的回路就是我们的最终的路径规划结果。采用上述技术方案所产生的有益效果在于:本申请所述方法在目的地的点数超过10个的情况下,它的计算机次数要比全排列算法至少快100倍,并且方法稳定且唯一,规划后的路程与最短路程相比,相差不超10%,因此,具有计算量小,速度快,稳定性强等优点。附图说明下面结合附图和具体实施方式对本发明作进一步详细的说明。图1是本发明实施例中网络图ga;图2是本发明实施例中最小生成树mtree图;图3是本发明实施例中各子树图;图4是本发明实施例中最密子树图;图5是本发明实施例中主线图;图6是本发明实施例中第一次合并图;图7是本发明实施例中多次合并流程图;图8是本发明实施例中合并p0过程图;图9是本发明实施例中删除根节点分支图;图10是本发明实施例中三条回路图;图11是本发明实施例中合并流程图;图12是本发明实施例中最终最短路径图。具体实施方式下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。本发明实施例公开了一种遍历多点归原的路径规划方法,所述方法包括如下步骤:1)先知条件:1-1)已知原点及其它地点(目的地)的经纬度,并且所有的点的数目超过10个。现设定点数为m,m>10,原点(即出发点和终点同为一点,即为原点)为1个,所有的点都已知经纬度,所有点我们用集合kp表示:kp={pi(xi,yi)|p0(x0,y0),p1(x1,y1),…,pn(xn,yn)}(0≤n<m);其中pi代表第i个点,它的经度为xi,表示为pi.xi,纬度为yi,表示为pi.yi,并且设定p0为原点。现举例,有如下点的集合:kp={pi(xi,yi)|p0(78,59),p1(62,96),p2(76,113),p3(91,97),p4(111,116),p5(129,96),p6(150,89),p7(144,71),p8(125,55),p9(128,35),p10(81,31),p11(54,45)}1-2)已知所有点之间的最短路程,并且形成最短路程矩阵。1-3)两点间的路程不分方向,路径的正反向的路程值相等。1-4)通过上述条件,可得这些点的网络图ga(如图1所示)和最短路程矩阵ptp。pi到pj的最短路程我们用表达式ptp(pi,pj)表示,比如p0到p2的最短路程表达式是ptp(p0,p2),路程值是46公里。还有,由于路径不分方向,因此ptp(pi,pj)=ptp(pj,pi)。2)求最小生成树2-1)基于第1步的条件,使用kruskal算法求最小生成树。2-2)通过2-1)步得最小生成树邻接矩阵。2-3)通过2-1)步得最小生成树图。最小生成树的图命名为mtree(如图2所示),同时用最小生成树邻接矩阵tm表示图中的关系,实例如下:从tm中可知tm(p0,p2)=46表示最小生成树中p0到p2的分支长度为46(和tm中其它非φ值的意义类似),另外,如tm(p3,p1)=φ表示最小生成树中p3和p1之间没有关系,也没有路程值(和tm中所有φ值的意义类似);3)取最小生成树中的各子树3-1)根据前面两步的条件,根据取子树的组合公式,得各子树。其中取子树的组合公式如下:设b0为所有子树的根节点的集合,它的定义为:b0={pi|tm(p0,pi)≠φ∧(i∈n+)∧(0<i<m)}设b1为b0中某根结点px下的第一代子节点的集合,它的定义为:b1={pi|tm(px,pi)≠φ∧(i∈n+)∧(0<i<m)∧(px∈b0)}与b1的定义类似,设b2为b1中某根结点px下的第一代子节点的集合,它的定义为:b2={pi|tm(px,pi)≠φ∧(i∈n+)∧(0<i<m)∧(px∈b1)}按此类推,设bj为bj-1中某根结点px下的第一代子节点的集合,它的定义为:bj={pi|tm(px,pi)≠φ∧(i∈n+)∧(0<i<m)∧(px∈bj-1)}取某一子树所有点的公式为:sontri代表第i子树所有点的集合3-2)通过3-1)步得b0集合、各子树的点的集合、各子树图(如图3所示),如下:b0={p3,p10,p11};sontr1={p1,p2,p3,p4,p5,p6,p7,p8,p9};sontr2={p10};sontr3={p11}。4)求最密子树4-1)根据前面步骤的条件,结合下面的求子树密度值组合公式,得各子树密度值。nc(sontri)=card(sontri),1≤i≤card(b0),i∈n+de(sontri)=(nc(sontri)×lf(sontri))/(nc(sontri)-lf(sontri)),1≤i≤card(b0),i∈n+其中px是第i颗子树的点,pk是kp中的点,nc(sontri)为第i颗子树的点的数量,stlf(sontri)代表第i颗子树的叶子端点的集合,lf(sontri)代表第i颗子树的叶子端点的数量,de(sontri)代表第i颗子树密度值。把各子树集合相关值代入公式得:nc(sontr1)=9,nc(sontr2)=1,nc(sontr3)=1lf(sontr1)=2,lf(sontr2)=0,lf(sontr3)=0de(sontr1)=9*2/(9-2),de(sontr2)=0,de(sontr3)=04-2)把各子树密度值作为条件,用取最密子树公式,筛选出最密子树集取最密子树公式:sontrmxde={sontrx|de(sontrx)=max{de(sontr1),de(sontr2),......de(sontrj)}},1≤j≤card(b0),j∈n+公式中,sontrmxde为最密子树集,sontrx为某一颗子树。根据4-1)步中的结果,通过上述公式可知:sontrmxde={sontr1}sontrmxde只有sontr1一个元素,而它就是最密子树,我们用sontre代表sontr1。sontre如图4所示:5)在最密子树中找到最边沿叶子15-1)使用数据结构技术中的后序遍历方法,对最密子树进行遍历,得到各点的遍历顺序集合,现设该集合用teamnde代表,它的表达式如下:teamnde={q1,q2,q3......qn-1,qn}其中q1,q2,q3,……qn为sontre中的点。现针对sontre进行后序遍历,结果如下:teamnde={p1,p2,p9,p8,p7,p6,p5,p4,p3}5-2)在集合中的第一个节点为最边沿叶子1。因此,从teamnde中可知,最边沿叶子为p1。我们用qs代表最边沿叶子端点16)针对最密子树找到最边沿叶子端点26-1)根据第5步的遍历顺序集合teamnde,以集合作为条件,通过取叶子公式,可得后序遍历顺序的叶子端点集合。下面是集合中取叶子公式:psdteamnde=stlf(sontre)∩teamnde公式中,psdteamnde代表后序遍历顺序的叶子端点集合。使用公式psdteamnde={p1,p9}∩{p1,p2,p9,p8,p7,p6,p5,p4,p3}={p1,p9}6-2)叶子端点集合psdteamnde中,最后一个点为最边沿叶子端点2。即p9是最边沿叶子端点2,同时,我们用qe代表最边沿叶子端点27)在两个最边沿叶子端点中,确定一个是最密子树始点,另外一个是最密子树终点7-1)根据综合路程值的组合公式,求两个最边沿叶子端点的综合路程值。m=card(stlf(sontre))其中,lfditsums为qs的综合路程值,lfditsume为qe的综合路程值,ai是最密子树sontre中的一个点。从6-1)和6-2)可知qs代表p1,qe代表p9,代入公式可得lfditsums=452lfditsume=4647-2)综合路值小者为最密子树始点,另外一个是最密子树终点。根据7.1可知lfditsums小于lfditsume,因此qs代表的p1是最密子树始点,qe代表的p9是最密子树终点。8)以最密子树根节点和最密子树始点和最密子树终点组成的回路为主线,把最密子树中的叶子端点合并到主线中。8-1)以最密子树根节点和最密子树始点和最密子树终点组成的回路为主线,如图5所示:图5中,p3-p1-p9-p3是主线,该主线以较粗的线显示,较细的线是原来最密子树的分支。8-2)使用jsprit的rebuild方法把最密子树中,不在主线上叶子合并到主线中,形成新的主线。由于,sontre最密子树中只有两个叶子,并且已经在主线上,所以不用再处理,直接下一步8-3)删除sontre最密子树中叶子的分支。图6是删除了分支后的结果:8-4)判断sontre最密子树中是否有叶子端点,如果有重复8-2)至8-4)步,一直到最密子树中没有叶子端点为止,图7是重复8.2至8.4步过程。8-5)在进行8-1)至8-4)的同时,tm矩阵作相应的设置,设置结果如下:9)原点与主线合并,形成回路。9-1)使用jsprit的rebuild方法,把原点合并到主线中。图8是原点合并在主线中;9-2)根据删除组合公式,删除原点与最密子树根结点间的路径。删除组合公式:tm(p0,ar)=φ,ar∈b0,ar∈sontre,即tm(p0,p3)=φ,效果如图9所示。对应tm矩阵设置如下:9-3)经过上面的步骤,从而形成一个:以原点为始点,经过原来的最密子树上的点,回到根结点的回路10)现对剩下的子树进行判断,点数超过1的子树重复步骤4)到步骤9),让子树形成回路,过程如下:10-1)除了原点,排除现有的回路上的点和路径。10-2)把剩下的点所组成的各个子树,逐个经过步骤4)到步骤9),都各自形成回路。10-3)上面操作,一直进行到没有点数超过1的子树为止。10-4)点数为1的子树就当成一个回路,它们都是从原点出发,经过叶子,回到原点的回路。10-5)第1颗最密子树形成的回路,用h1代表,按顺时针方式,在h1旁的回路,用h2代表,后面类似命名。现设回路的集合hn={h1,h2……hi},i=card(b0)。经过第10步处理后,如图10所示,tm矩阵的结果如下:11)求各回路的回路始点与回路终点。11-1)针对只有2点的回路,其叶子就是回路始点,也是回路终点。11-2)针对超过2点的回路,从原点开始,顺时针遍历回路。11-3)除了根结点,第一个遍历的节点是回路始点,用as代表,最后一个是回路终点,用ae代表。11-4)所有超过2点的回路用同样的方法,都得到它们各自的回路始点与回路终点。其中回路h1其中回路h1的回路始点与回路终点为as1和ae1,h2的回路始点与回路终点为as2和ae2,因此,我们就有一个始点与终点的集合,我们设这个集合为:se={as1,ae1,as2,ae2,as3,ae3……asi,asi},i=card(b0)。而这里的集合为se={as1,ae1,as2,ae2,as3,ae3}12)使用回路间节约里程公式,求节约里程值:12-1)根据我们的回路间节约里程公式,求上一回路终点与下一回路始点间的节约里程数值;按顺时针方向,第i个回路hi和第j个回路hj的回路间节约里程数为△cij,它的求值公式如下:δcij=tm(p0,aei)+tm(p0,asj)-tm(asj,aei),j=i+1,i∈n+,1≤i<n,n=card(b0)最后一个回路和第1个回路的节约里程数值△cn1为:δcn1=tm(p0,aen)+tm(p0,as1)-tm(as1,aen),n=card(b0)套用公式:△c12=48+21-39=30;△c23=21+22-25=18;△c31=33+22-45=10;13)根据节约里程数值,使用节约里程方法,对回路进行合并。13-1)根据节约里程数值,使用节约里程方法,对节约里程值大的两个回路先进行合并。13-2)重复步骤11)至步骤13),一直合并到回路数量为1时停止,合并流程如图11所示,对应的tm矩阵设置为:14)所有的回路合并后,最终的回路就是我们的最终的路径规划结果,结果图如图12所示,与矩阵如下:总路程值为:250公里最短路径序列为:p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11,p0。全排列算法的计算复杂度:1-1:本实例总共有12个点,但由于原点p0在排列中的位置是不变的,所以,实质上在排列的过程中,只有11个点在进行排列。1-2:11个点的全排列的序列数为11!=11*10*9*8*7*6*5*4*3*2*1=39916800。1-3:每个序列都要计算10次加法才知道路程,因此计算量为11!*10=399168000次约为4亿次。1-4:所有路程计算完毕后,再选出最小值,最小值对应的路径序列就是最短路径,这个步骤需要比较39916800-1次所以总的计算次数为39916800+399168000+39916800-1=479001599≈4.8亿。本方法的计算复杂度:最小生成树计算的复杂度在于比较的次数,而它的比较的次数为:969+290=1259次取最小生成树中的各子树,它的计算复杂度取决于比较的次数,144次求最密子树时,它的计算复杂度取决于统计次数和比较次数和运算次数,首先是统计点的数量时,统计次数为11;在统计叶子数量时,比较次数为144;计算各子树密度值时,运算次数为5。因此总的次数为11+144+5=160。在最密子树中找到最边沿叶子1和2中,后序遍历需要比较19次,最边沿叶子1在这19次中就产生,最边沿叶子2需要再比较2次后产生,因此本过程需要比较21次。确定最密子树始点和终点,在这过程中对上述两点都要进行加法计算,分别都进行8次加法,共16次,之后再进行了1次比较,回次计算的次数为16+p1=17次。在形成回路主线和合并叶子到主线过程中,形成回路主线需要连接路径3次,这3次相当于赋值6次。在合并叶子到主线过程中,需要删除路径,连接路径,路径相加,比较操作,它们的次数如下表:删除连接加法比较p12000p20232p30000p42287p54476p64465p74454p84443p92000根据上述所有次数相加,计算次数为6+102=108次原点与主线合并形成回路,这一过程上面过程基本相似,删除操作为2,连接操作为2,加法运算为9,比较次数为8,因此总的计算次数为2+2+9+8=21次。求各回路的回路始点与回路终点,这个过程主要是比较操作,次数为10使用回路间节约里程公式求节约里程值,进行3次加法和3次减法运算,共6次。使用节约里程方法对回路进行合并,这个过程首先要进行3次比较决定合并的先后顺序,再进行4次删除操作,4次连接操作,从而得到结果,总共为11次。到此为止,本申请所述方法计算次数为1259+144+160+21+17+6+108+21+10+6+11=1763次。综上,本申请所述方法在目的地的点数超过10个的情况下,它的计算机次数要比全排列算法至少快100倍,并且方法稳定且唯一,规划后的路程与最短路程相比,相差不超10%,因此,具有计算量小,速度快等优点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1