配准对象形状的精度评估方法和设备、配准的方法和设备与流程
本发明涉及图像处理、计算机视觉和模式识别。更具体地,本发明涉及用于评估图像中的由多个标定点表示的配准的对象形状的精度的方法和设备以及用于配准图像中的对象形状的方法和设备。
背景技术:
在诸如面部识别、表情分析、3D面部建模和面部动画制作的许多计算机视觉领域中,自动并且精确地配准由标定点的集合描述的对象(例如,面部)的形状是重要的任务。对于面部配准,已经提出了许多不同类型的方法。在这些方法之中,由Cootes等人提出的主动形状模型(ASM)和主动表观模型(AAM)被证明是有效的方案。与AAM相比,ASM在速度、精度和普遍化性质方面具有更好的性能。因此,近年来对于ASM已经提出很多改进和变化。主动表观模型(ASM)是由TimCootes和ChrisTaylor于1995年开发的对象形状的统计模型,其进行迭代变型以与新图像中的对象的示例拟合。对象的形状由(通过形状模型控制的)点的集合表示。ASM算法旨在将该模型与新图像匹配。其通过交替执行以下步骤来工作:·在每个点周围的图像中寻找对于该点的更好位置;·更新模型参数以与这些新发现的位置进行最佳匹配。根据ASM,实际中已经存在许多用于正面部配准的算法。进来,面部配准已经扩展到多视角配准。已经进行了许多工作来扩展这些算法以处理多视角面部。总体而言,常规多视角面部配准方法的状态是基于视角的方法,其中,视角被分布诸如正面、半侧面和全侧面等的若干子视角。图2示出多视角面部配准的示例,其中视角被分为七个子视角,并且对于每个子视角,训练形状模型、以及局部纹理模型的集合。该方法通过选择正确的基于视角的模型来应对对视角面部的非线性形状变形。多视角配准的通用方法是面部视角估计。可以存储每个视角的形状模型。如图1A中所示,对于输入图像,首先通过视角估计方法估计面部视角,然后通过与估计的视角对应的模型执行面部配准。图1A示出用于通过ASM方法进行多视角面部配准的通用方法的处理序列。但是,该通用方法的视角估计通常不是令人满意的。现在,为了更好的视角估计,一些目前的多视角配准方法已经引起关注。方法1:基于形状和视角参数估计的方法在L.Zhang,H.Ai,Multi-ViewActiveShapeModelwithRobustParameterEstimation,ICPR,2006中,提出了用于多视角主动形状估计的参数估计方法。首先,分别对于每个视角训练形状模型以及局部纹理模型的集合。其次,估计给定图像的初始视角,并且执行使用局部纹理模型的局部搜索。然后,通过非线性优化方法进行参数估计。使用优化方法,在该优化方法中,对每个特征点进行动态加权以使得只有与形状模型一致的特征点将具有大的权重,而异常值(outlier)的影响将被消除。最后,可以获得新的形状直到该形状收敛为止。图1B示出利用参数估计的多视角面部配准方法的流程图。方法2:以基于混合视角的ASM和3D面部模型为基础的方法在YanchaoSu,HaizhouAi,ShihongLao,Multi-ViewFaceAlignmentUsing3DShapeModelforViewEstimation.The3rdIAPRInternationalConferenceonBiometrics,2009中,对基于视角的ASM和在500个3D扫描面部上建立的简单3D面部形状模型进行组合,以建立完全自动多视角面部配准系统。由多视角面部检测器发起,首先使用基于视角的局部纹理模型来局部搜索初始形状周围的特征点,然后使用3D面部形状模型从这些点重构3D面部形状。根据重构的3D形状,可以获得其面部信息,根据该面部信息可以指示自封闭(self-occluded)的点,然后采用该视角的2D形状模型来通过非线性参数估计精细化观察的非封闭形状。方法1和方法2的整个配准过程基本相同。主要不同是在方法1中使用3D面部形状模型来进行参数估计。图1C示出流程图。图1C示出方法1和2两者的主流程图(方法2具有虚线框图而方法1没有)。对于方法2在图1D中示出整个配准过程。图1D是配准过程的例示。在(a)中,通过当前视角的平均形状对算法进行初始化。在(b)中,使用局部纹理信息通过局部搜索得到观察的形状。在(c)中,利用观察的形状,使用3D形状模型重构3D形状,并且估计姿态。在(d)中,从观察的形状重构2D形状。在(e)中,当迭代收敛时获得最终形状。方法1和方法2的问题:上述方法的一个共同问题是它们需要估计每个迭代中的对象的子视图。然而,视角估计本身是非常难的并且易于出错。虽然这些视角估计方法不是完全取决于由面部检测器获得的初始视角,但是视角估计可能导致最终配准的不精确。方法3:基于贝叶斯混合模型的方法在Y.Zhou,W.Zhang,X.Tang,andH.Shum.Abayesianmixturemodelformulti-viewfacealignment.CVPR,2005中,提出了用于多视角面部配准的多模式贝叶斯架构。首先,通过多视角面部检测器初始化视角。其次,根据初始视角,使用混合模型来描述形状分布和点可视性,然后导出在给定未知有效特征点的观察值时的模型参数的后验概率。具体地,将多模式和可变特征点的问题表达为统一的贝叶斯框架。最后,给出EM算法来估计模型参数、正则化的形状以及该形状的点的可视性。图1E示出该局部更新处理。方法3的问题:一方面,在方法3中,在每个标记点的局部搜索中使用的纹理模型取决于初始视角,并且通过面部检测器获得初始视角。然而,其通常对于隐藏视角参数的估计非常敏感。当没有正确预测初始视角时,局部搜索的结果变得不可靠。如果形状参数的估计没有处理潜在的异常值,那么该方法将失败。另一方面,在局部更新步骤中,以不同的权重使用两个模型来进行局部更新。一个问题是线性混合模型不能充分地描述面部的3D形状,这可能导致最终结果不准确。这些方法通过选择正确的基于视角的模型来处理多视角面部的非线性形状变型。由于在特定形状模型的每个标定点的局部匹配中使用的纹理取决于其视角类别,所以这些方法对于初始视角类别的估计非常敏感。然而,面部视角本身的精确估计是没有很好解决的问题并且仍然在发展中。虽然视角范围的重叠定义能够在一定程度上减轻由于视角的不适当初始化而引起的错误,但是如果初始视角没有被正确预测,那么局部匹配的结果将变得不可靠。由此,如何有效地选择正确模型是基于视角的多视角面部配准中的关键步骤。从上述可知,在模型拟合之前选择最佳的视角是非常困难的。因此,在拟合之后执行模型选择可以是对于该问题的有效方案。根据拟合结果选择最佳模型的问题实质上是如何评估来自不同模型的拟合结果的精度的问题。已经存在用于评估面部配准的精度的几个方法。在这些方法之一中,在FaceAlignmentviaComponent-basedDiscriminativeSearch,ECCV,2008,L.Liang,R.Xiao,F.Wen,J.Sun中,使用Boosted表观模型(BAM)计算每个访问形状{S0,...,Sk}的分数f(Sk),并且挑出最大的分数作为最终输出。用于形状参数优化的后验概率P(S|I)也可被视为形状配准的良好度的评估。在给定具有真实值标定的面部数据集的情况下,训练基于boosting的分类器以学习基于真实值标定的变形图像(图3A,来自XiaomingLiu.Genericfacealignmentusingboostedappearancemodel.CVPR,2007)(正类)与基于随机扰动(perturb)的标定点的变形图像(负类)之间的判决边界。基于Haar-like的矩形特征的一组经训练的弱分类器确定boosted表观模型。来自最后一个强的分类器的分类置信分数被视为配准形状的良好度的测量。图3A示出用于BAM训练的扰动的变形图像。训练中的负样本的扰动对BAM的性能的影响更大。图3B(来自XiaomingLiu.Genericfacealignmentusingboostedappearancemodel.CVPR,2007)示出用于面部配准的boosted表观模型。使用正确配准和不正确配准两种来训练BAM中的表观模型。面部被视为整体并且正和负样本被变形成30×30像素。这很好地工作,但是扔掉可能有用的信息。另外,BAM中的表观模型不能被应用于多个模型的评估。该方法将面部配准视为分类问题。通过形状参数的随机扰动来合成用于BAM训练的负形状。负形状的选择极大地依赖于用户的经验。如果负形状没有被适当扰动,则这将导致非常差地性能。如果用大量的扰动来扰动负形状,则这将导致良好的分类性能,而两个类别(即,正类别和负类别)的余量将是大的。可以看出,训练中的负样本的扰动对于BAM的性能有更多的影响,并且存在样本被视为含糊的的一些余量区域。
技术实现要素:
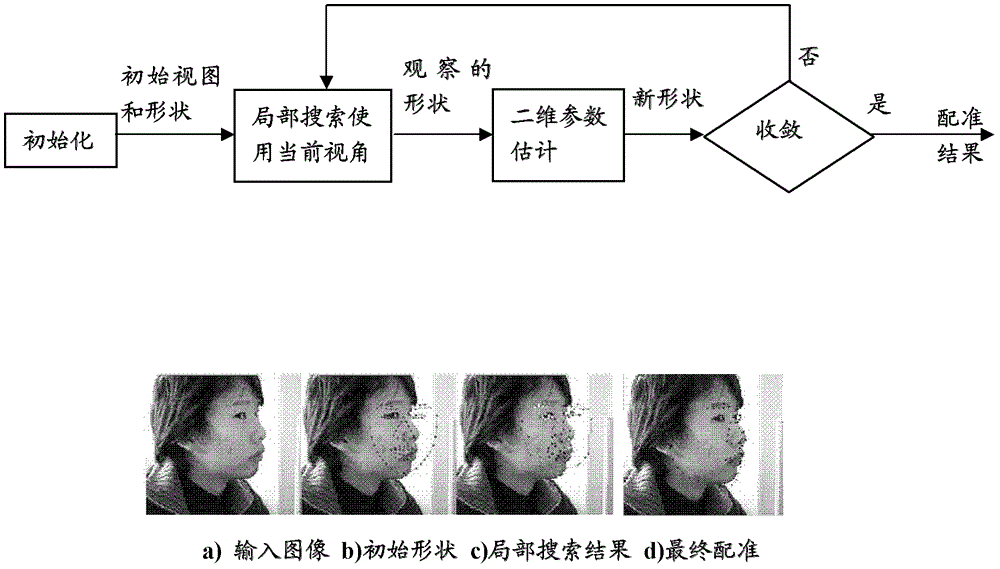
由上述方法的问题所激发的,本发明集中于用于不同视角类别的模型的拟合结果选择。在本发明的一个方面,提供了一种用于评估图像中的由多个标定点表示的配准的对象形状的精度的方法。该方法包括:第一分数计算步骤,使用第一模型按照对象形状计算第一分数;第二分数计算步骤,使用第二模型按照所述多个标定点中的每一个计算第二分数;以及评估步骤,根据第一分数和第二分数计算配准的精度。在本发明的另一方面,提供一种用于配准图像中的对象形状的方法。该方法包括:形状配准步骤,根据用于对象的多个形状模型拟合对象形状,所述多个形状模型中的每一个对应于来自对象的一个视角的图像;选择步骤,基于拟合结果通过根据本发明的方面的评估方法计算每个形状模型的拟合结果的分数,并且选择与最高分数对应的拟合结果作为对象形状的配准结果。在本发明的又一方面,提供一种评估图像中的由多个标定点表示的配准的对象形状的精度的设备。该设备包括:第一分数计算装置,用于使用第一模型按照对象形状计算第一分数;第二分数计算装置,用于使用第二模型按照所述多个标定点中的每一个计算第二分数;以及评估装置,用于根据第一分数和第二分数计算配准的精度。在本发明的又一方面,提供一种用于配准图像中的对象形状的设备。该设备包括:形状配准装置,用于根据用于对象的多个形状模型拟合对象形状,所述多个形状模型中的每一个对应于来自对象的一个视角的图像;以及选择装置,用于基于拟合结果通过根据本发明的方面的设备计算每个形状模型的拟合结果的分数,并且选择与最高分数对应的拟合结果作为对象形状的配准结果。根据本发明,找到执行所有形状模型的配准之后的最佳匹配结果。在本发明中,无需迭代估计子视角并且拟合不依赖于初始视角。本发明对于选择正确视角的形状模型并且去除不正确视角的形状模型是特别有用的。利用用于评估图像中的由多个标定点表示的配准的对象形状的精度的方法和设备以及用于配准图像中的对象图像的方法和设备,可以提高图像中的对象配准的精度,并且可以以低计算成本选择最佳拟合形状模型。从以下参考附图对示例性实施例的说明,本发明的进一步特征将变得明显。附图说明图1A示出通过ASM方法进行多视角面部配准的通用方法的处理序列。图1B到1E分别示出利用参数估计进行多视角面部配准的常规方法的流程图。图2示出多视角面部配准的示例。图3A示出用于BAM训练的扰动的变形图像。图3B示出用于面部配准的boosted表观模型。图4示出表示可以实现本发明的信息输出设备的计算机系统的硬件配置的框图。图5示出根据本发明的多视角对象配准的设备的框图。图6示出根据本发明的对象配准的流程图。图7示出候选形状模型的选择的图。图8示出用于评估图像中的配准的对象形状的精度的评估设备。图9示出用于配准由标定点的集合表示的对象形状的精度评估方法的流程图。具体实施方式现在将按照附图详细描述本发明的优选实施例。注意,实施例中的组件的相对布置和器件的形状仅被描述为例子,并且并不旨在将本发明的范围限制于这些例子。此外,相似的附图标记和字母在图中指代类似的项,由此,只要在一个图中定义一项,则无需对于后续的图讨论该项。图4是示出能够实现本发明的实施例的计算机系统1000的硬件配置的框图。如图4所示,计算机系统包括计算机1110。计算机1110包括经由系统总线1121连接的处理单元1120、系统存储器1130、不可移动非易失性存储器接口1140、可移动非易失性存储器接口1150、用户输入接口1160、网络接口1170、视频接口1190和输出外围接口1195。系统存储器1130包括ROM(只读存储器)1131和RAM(随机存取存储器)1132。BIOS(基本输入输出系统)1133驻留在ROM1131中。操作系统1134、应用程序1135、其它程序单元1136和某些程序数据1137驻留在RAM1132中。诸如硬盘之类的不可移动非易失性存储器1141连接到不可移动非易失性存储器接口1140。不可移动非易失性存储器1141例如能够存储操作系统1144、应用程序1145、其它程序单元1146和某些程序数据1147。诸如软盘驱动器1151和CD-ROM驱动器1155之类的可移动非易失性存储器连接到可移动非易失性存储器接口1150。例如,软盘1152可以被插入到软盘驱动器1151中,以及CD(光盘)1156可以被插入到CD-ROM驱动器1155中。诸如鼠标1161和键盘1162之类的输入设备被连接到用户输入接口1160。计算机1110能够通过网络接口1170连接到远程计算机1180。例如,网络接口1170能够通过局域网1171连接到远程计算机1180。另选地,网络接口1170能够连接到调制解调器(调制器-解调器)1172,以及调制解调器1172经由广域网1173连接到远程计算机1180。远程计算机1180可以包括诸如硬盘之类的存储器1181,其存储远程应用程序1185。视频接口1190连接到监视器1191。输出外围接口1195连接到打印机1196和扬声器1197。图4所示的计算机系统仅仅是说明性的并且决不意图对本发明、其应用或用途进行任何限制。图4所示的计算机系统能够被实现于任何实施例,能够作为独立计算机,也能够作为设备中的处理系统,能够移除一个或多个不必要的组件,或者向其添加一个或多个附加的组件。现在将描述根据本发明的用于对象配准的设备和方法。图5是根据本发明的用于多视角对象配准的设备的框图。如图5所示,用于对象配准的设备包括:模型存储装置501,用于存储要配准的对象的多个形状模型,每个形状模型对应于对象的子视图;形状配准装置502,用于单独地根据多个形状模型拟合对象形状,并且输出每个模型的拟合结果;以及配准结果选择装置503,用于基于拟合结果通过根据稍后将描述的本发明的评估装置计算每个形状模型的拟合结果的分数,并且从作为对象形状的拟合结果的所有结果中选择最佳结果。利用该用于对象配准的设备,一旦输入面部图像,在面部图像上放置对于每个子视图的对应平均形状,所述子视图包括正子视图、左半子视图、左全子视图、右半子视图、右全子视图等。从存储在模型存储装置中的对应形状模型获得平均形状。作为示例,从用于前子视图的形状模型获得用于前子视图的平均形状。当然,根据图像处理的要求,子视图的数量n是可变的。相应地,形状模型的数量n也是可变的。对于每个子视图,在形状配准装置502中执行形状模型拟合。更具体地,在图像上放置对于对应模型的每个子视图的初始平均形状,并且选择形状参数的集合。检查来自平均形状的每个点周围的图像的区域以找到对于该点的最佳邻近匹配。更新形状参数以最佳拟合新找到的点。也就是说,从对应的形状模型执行形状变形以获得对于对象图像拟合的形状。之后,拟合结果,即,拟合的形状被输入拟合结果选择装置503以选择最佳拟合结果,这将在随后描述。最佳拟合结果被输出作为对象图像的最后配准。想在,将参照图6讨论通过用于对象配准的设备执行的方法的过程。图6是根据本发明的用于对象配准的流程图。在步骤610,对于输入图像,可以使用面部检测器检测面部或对象。然后,可以从面部的限制框估计初始形状和大小。根据本发明,采用基于boosting嵌套级联检测器的多视角面部检测器。多视角面部检测器可以提供对于面部配准的初始面部视角。另选地,多视角面部检测器可以不提供初始面部视角。在步骤620,根据初始视角和由面部检测器获得的形状,从训练的模型中选择适当形状模型的集合。这些选择的模型对应于初始视角本身并且是相邻的视角。例如,面部视角被分为五个视角类别,即,正(F)、左半侧(LHP)、左侧(LP)、右半侧(RHP)、右侧(RP)。每个视角类别被视为通道,并且训练的模型具有五个模型,包括LP、LHP、F、RHP和RP形状模型。图7中示出选择形状模型的示例的主要过程。图7是用于选择候选形状模型的示图。如图7所示,选择对应于与初始视角相邻的视角的形状模型集合作为候选模型。具体地,对于通道F,所选择的形状模型可以包括F、LHP和RHP模型;对于通道LP,所选择的形状模型可以包括LP和LHP模型;对于通道RP,所选择形状模型可以包括RP和RHP模型;对于通道LHP,所选择的形状模型可以包括F、LHP和LP模型;对于通道RHP,所选择的形状模型可以包括F、RHP和RP模型。如图7所示,选择多个形状模型,而不是单个模型,这使得对于初始视角的依赖性减少,并且还实现比单个模型更好的配准性能。也可以根据需求以任何其它方式执行选择。例如,可以选择与初始视角的模型相邻的四个模型。另选地,如果在步骤610中没有提供初始视角,则可以选择所有训练的形状模型。在步骤S630,一旦确定形状模型的集合,则可以使用这些模型来相对于初始形状配准面部。在该步骤中,采用标准ASM方案来执行拟合。该方案主要由以下步骤构成:1)得到所监测面部的初始视角、位置和大小;2)局部搜索以找到每个特征点的最佳匹配位置;以及3)选出要点并且通过形状模型更新形状参数。在模型拟合步骤中可以使用许多面部配准方法,所述模型拟合步骤诸如使用统计模型和小波特征的面部配准、基于局部纹理分类器的面部配准和经由基于成分的区别搜索的面部配准。在步骤640中,在通过分别使用对于面部的这些选择的形状模型执行拟合之后,建立找到最佳拟合结果的评估方法。以下将描述评估方法的细节。以下表示出本发明和现有技术之间的不同。表1.本发明与现有技术中的方法的比较在表1中,√表示是,×表示否。从表1可以看出,与常规方法相比,根据本发明的对象配准设备和方法不需要视角估计或更新、任何混合形状模型和3D形状模型。此外,本发明可产生多个拟合结果,而常规方法只产生一个拟合结果。根据本发明的对象配准方案与使用对应于子视角的单个模型的方案进行比较。当对于通用方法中的面部配准采用由面部检测器获得的仅一个子视角时,仅选择与子视角对应的形状模型来执行拟合。如果没有正确地预测初始视角,则配准结果变得不可靠。在根据本发明的对象配准设备和方法中,从训练的形状模型中选择形状模型的集合;使用所选择的模型中的每一个来局部搜索对应的平均形状周围的特征点;并且选择最佳拟合结果。这不仅避免初始视角对于整个配准过程的影响,而且实现面部配准的高精度和鲁棒性。现在,将描述用于评估配准形状的精度的方法和设备。如何评估配准形状的精度的问题被分为计算与不同信息对应的两个分数:第一分数用于根据空间先验(spatialprior)评估配准的面部形状的良好度,所述空间先验代表对象形状的所有可能变形;第二分数用于使用由对象图像提供的图像证据(evidence)来评估配准形状的良好度。通过两个离线训练的模型,即空间先验模型和标准似然模型,来对这两种信息进行建模。本发明所集中与的形状配准精度评估问题还被表述为贝叶斯架构并且被表示为后验概率p(V|I)。p(V|I)表示在图像纹理I的条件下的V的概率。V=(x1,x2,…xn,y1,y2,…,yn)描述泛用普式分析(GPA,GeneralizedProcrustesAnalysis,一种统计形状分析)之后的面部形状,该泛用普式分析去除相似度变换姿态并且通过零质心和大小归一化(unitnorm)来进行归一化以去除偏移和大小变化。i表示标定点的号。(xi,yi)表示第i个标定点的坐标。基于贝叶斯函数通过以下表达式(1)表示以上后验概率p(V|I)。p(V|I)=p(V)p(I|V)p(I)∝p(V)p(I|V)---(1)]]>p(V)是面部形状V的先验概率。p(I|V)是在给定形状V时图像中的该位置处的面部表观的似然概率。这里,图像内容是任意的,即,任何图像的表观的概率p(I)是相等的。由此,面部表观的概率p(I)被认为是恒定值。因此,与p(V)p(I|V)成正比。现在,将描述获得面部形状V的先验概率p(V)的方式。通过对手动标记的形状样本进行主成分分析(PCA),将总的形状变小分为许多独立的成分,并且这些独立的成分中的每一个被对应的主成分编码。PCA是使用正交变换将可能相关的变量的观察值的集合转换为称为主成分的不相关变量的值的集合的数学过程。主成分的数目小于或等于源变量的数目,以降低经转换的数据的维。由每个主成分编码的形状变形被建模为均值为零并且主成分分析模型的对应本真值为方差的高斯分布。这些分布可以从手动标记的正面部形状计算。通过将当前面部形状V映射到主成分轴上,如下计算先验概率。在给定面部形状V时,将面部形状V映射为K个主成分的线性组合V=V0+p1V1+…+pkVk+…+pKVK。Vk是第k个主成分,并且是从手动标记的样本统计导出的向量。pk是与V对应的映射系数,并且是标量。V由p1,…,pk,…,pK唯一地确定。因此,p(V)可以被表示为映射系数p1,…,pk,…,pK的结合概率分布p(p1,…,pk,…,pK)。p(V)=p(p1,…,pk,…,pK)(2)根据PCA的分布,主成分Vk彼此正交,即彼此独立。因此,由每个主成分表示的数据是高斯分布。由此,通过以下表达式(3)计算面部形状V的先验概率。p(V)=p(p1,···,pk,···,pK)]]>=Πk=1K(pk)]]>=Πk=1K[12πλkexp(-pk22λk)]---(3)]]>∝exp(-Σk=1Kpk2λk)Πk=1K1λk]]>其中,λk是PCA系数pk的统计方差。现在,将描述获得面部形状V的似然概率p(I|V)的方式。p(I|V)是在给定形状V时在图像I中的位置处的面部表观的似然概率。位置vi处看到第i个标定点的图像证据被假定为独立于在给定其它标定点的空间位置时的其它标定点的图像证据。因此,局部似然概率被建模为高斯分布。也就是说,似然概率p(I|vn)被建模为高斯分布。总之,可以使用以下表达式(4)计算总体似然概率:(I|V)(I|v1,v2,···,vN)]]>∝Πn=1Np(I|vn)]]>∝Πn=1N12πσn2exp(-(vn,current-vn,true)22σn2)---(4)]]>∝exp(-Σn=1N||Δvn||2σn2)Πn=1N1σn]]>其中,是在给定位置vn时的图像I的局部似然概率的统计方差。Δvn代表第n个标定点的当前位置vn,current和真值位置vn,true之间的位移。当进行形状配准时第n个标定点的真值位置vn,true是未知的。然而,表观似然模型被设计为使用基于梯度树Boost的增量回归模型直接估计位移Δvn,这将在下文讨论。通过以上两个近似,后验概率可以被重写为:p(V|I)∝p(V)p(I|V)]]>∝exp(-Σk=1Kpk2λk)Πk=1K1λk·exp(-Σn=1N||Δvn||2σn2)Πn=1N1σn]]]>∝exp(α·Σk=1Kpk2λk+β·Σn=1N||Δvn||2σn2)Πk=1K1λkΠn=1N1σn---(5)]]>∝c1c2·exp(α·s1+β·s2)]]>∝exp(α·s1+β·s2)]]>s1=ΣkKpk2λk---(6)]]>s2=Σn=1N||Δvn||2σn2---(7)]]>其中,s1是代表先验概率的第一分数,s2是代表似然概率的第二分数。参数α和β分别是s1和s2的权重。引入这两个参数的目的是使得s1和s2的范围大致相同,以对于后验概率平衡s1和s2的分布。这两个参数的值可以根据需求来调整。作为示例,并且仅与预定模型相关,并且独立于当前的图像表观。在实验中,本发明人发现用常量代替c1c2对于本发明的模型选择的影响是可以忽略的。然后,c1c2·exp(α·s1+β·s2)被进一步近似为exp(α·s1+β·s2)以简化计算。给定配准形状和对象图像时,可以容易地以小的计算成本计算s=α·s1+β·s2。该分数用于评估形状配准的良好度。然后,与多个形状模型对应的配准形状的分数被彼此比较。具有最高分数的配准形状被选择作为最终结果。表2根据本发明的多视角面部配准的实验结果如表2所示,第一列代表实验的号码,第一行代表要使用的形状模型。对应的形状模型之下的列代表对应实验中的模型的分数。例如,第2行第2列中的分数“-0.472332”意指用于实验1的模型“LP”的分数为-0.472332。在表2的实验1中,具有最高分数-0.183356的形状被选择作为最终结果。在表2的实验2中,具有最高分数-0.164278的形状被选择作为最终结果。在表2的实验3中,具有最高分数-0.187144的形状被选择作为最终结果。在表2的实验4中,具有最高分数-0.193906的形状被选择作为最终结果。实验表明由本发明计算的分数可以以高鲁棒性区别配准形状的良好度。无论如何,以上表达式s=α·s1+β·s2仅是计算最终分数的一种方法。另选地,可以通过将s3、s4和系数相乘来计算s。s3是s4是实际上,可以基于上述推导过程中的任何步骤计算s。总之,本发明的原理如下。对于每个配准的面部形状,独立地根据不同地信息计算两个分数,并且将两个分数线性组合来产生最终分数以评估配准的面部形状的良好度。根据当前面部形状的变形计算第一分数,并且根据由对象图像提供的面部表观信息计算第二分数。现在将描述用于实现面部配准(对象配准)的精度的上述评估的方法和设备。图8示出根据本发明的用于评估图像中的由多个标定点表示的配准的对象形状的精度的评估设备。该评估设备包括:存储装置1201,用于存储预先从手动标记样本学习的空间先验模型和对象表观模型;第一分数计算装置1202,用于根据当前形状相对于空间先验模型的变形计算第一分数;第二分数计算装置1203,用于使用对象表观模型根据由所有配准的标定点确定的对象图像中的位置处的图像证据,计算第二分数;以及评估装置1204,用于通过这两个分数的加权相加来计算配准的对象形状的最终分数。在存储装置1201中,通过利用泛用普式分析(GPA)配准训练形状向量来构造空间先验模型,以去除相似度变换姿态并且通过零质心和大小归一化来进行归一化以去除偏移和大小变化,并且对配准的形状矢量执行主成分分析(PCA)以将整个形状变形分割为许多独立的成分并通过主成分对这些成分进行编码。通过根据标定点将总对象表观分割为若干独立的局部表观,对于每个标定点学习一个位移预测器以估计当前位置和接地真是位置之间的位移,并将局部表观似然度中的每一个建模为以标定点的真实位置为中心的、均值为零并且预先学习的位移预测器的残量为方差的高斯分布,来构造对象表观模型。在第一分数计算装置1202中,通过将配准形状映射到主成分轴上以获得形状变形参数,使用与每个成分轴对应的高斯分布模型计算每个参数的分数,并且对所有分数求和以形成第一分数,来计算第一分数。在第二分数计算装置1203中,通过对于每个标定点估计当前位置和真实位置之间的位移,使用高斯分布局部表观模型的位移来计算每个标定点的分数,并且对所有分数求和以形成第二分数,来计算第二分数。现在,将描述用于评估通过标定点的集合表示的配准面部形状的精度的方法。图9示出用于配准通过标定点的集合表示的对象形状的精度评估方法的流程图。在步骤1310中,输入通过标定点的集合表示的配准形状。通过向量V=(x1,x2,…xn,y1,y2,…,yn)表示形状,该向量包含图像中的标定点的坐标。vi=(xi,yi)表示图像中的第i个标定点的坐标。在步骤1320中,该方法创建离线空间先验模型来表示对象形状的所有可能变形。为了学习形状的所有可能变形的分布,选择N(诸如300或1000)个手动标记的形状作为训练样本。优选地,N尽可能大以创建更精确的模型。然而,所需要的训练样本的数量依赖于形状的复杂度和可能变形的程度。在选择所有训练样本之后,使用泛用普式分析将形状矢量与参考形状矢量对齐,以去除相似度变换姿态并且通过零质心和大小归一化来进行归一化以去除偏移和大小变化。以下过程用于对形状变形进行建模。通过称为k-fan的图形模型的类别、通过允许形状根据多元高斯分布进行变形的高斯马尔可夫随机场模型、或者通过高斯分布,对空间形状先验性进行建模。对于诸如面部、手和人体的要建模的特定对象,形状变形的程度是不同的,并且可以使用具有不同复杂性的模型进行建模。要使用的模型依赖于形状的复杂度和可能形状变形的程度。对于面部形状配准,在实验中证明将通过每个主成分编码的形状变形建模为高斯分布是足够的。在步骤1330,根据空间先验模型计算一个形状的第一分数V=(x1,x2,…xn,y1,y2,…,yn)。使用高斯分布对与PCA形状模型的每个主成分对应的形状变形进行建模。该分数被计算如下:s1=ΣkKpk2λk---(6).]]>其中,pk是与PCA形状模型的第k个主成分对应的映射系数。λk是PCA系数pk的统计方差。K是保留的主成分的数量。可以使用k-fans或者高斯马尔可夫随机场模型或者更为简单地使用对象的当前形状和平均形状之间的距离,来计算第一分数。在步骤1340中,该方法创建形状的表观似然模型来表示在给定当前形状时的图像证据。对象表观被分为与标定点对应的若干局部部分。在位置vi看到第i个标定点的图像证据被假定为独立于在给定其它点的空间位置时的其它点的图像证据。对于每个局部部分,将表观似然度建模为高斯分布,该高斯分布以标定点的真实位置为中心并具有特定方差。p(I|vn)∝exp(-(vn,current-vn,true)22σn2)---(4a)]]>为了计算局部似然概率,建立模型来使用基于梯度树Boost的增量回归模型直接预测位移Δvn=vn,current-vn,true,并且使用训练残量作为方差这里还可以使用许多其它方法。例如,可以使用与haar-like特征组合的GentleBoost逻辑回归方法来学习图像证据。使用Haar-like特征作为弱回归函数的基础来将局部纹理映射为大小特征值h(I)。并且通过弱回归函数来从特征值h(I)计算位移。在步骤1350,根据局部表观似然模型计算第二分数。s2=Σn=1N||Δvn||2σn2---(7).]]>其中Δvn表示对象图像中的与第n个标定点对应的由第n个局部表观似然模型预测的当前位置和真实位置之间的位移。N是标定点的数目。在步骤1360,通过两个计算的分数的加权和来计算当前形状的精确测量。Score=α·ΣkKpk2λk+β·Σi=1N||Δvi||2σi2---(5a)]]>=α·s1+β·s2]]>参数α和β是对应项的权重,它们在(0,1]的范围内并且需要根据实验进行选择。这里,且无论如何,上述表达式Score=αs1+βs2仅是计算最终分数的一种方式。另选地,通过将s3,s4和系数相乘来计算Score。s3是s4是实际上,可以基于上述推导过程中的任何步骤计算Score。与L.Liang等人的方法相比,在本发明中,面部被根据面部点分为若干局部区域。在30×30像素的局部图像片处对于每个面部点独立地学习一个表观模型。与对于30×30像素的整个面部图像学习一个表观模型相比,可以通过表观模型表示更多信息,并且这将比L.Liang等人的方法更为鲁棒。此外,在本发明中,使用增量回归方法构造表观模型。通过从真实位置的随机位移创建样本,并且用位移标记样本。回归训练可以使用可获得的整个训练数据。所以比BAM更为精确。此外,在本发明的评估方法中,Δvn=vi,current-vi,groundtruth是当前点位置和真实位置之间的位移。表观似然模型被设计为对于第n个标定点直接估计位移Δvn。由此,可以用小的计算成本计算似然概率。可以在许多应用中使用根据本发明的上述评估方法。这些示例之一是如图5和6中所示的多视角面部形状配准中的模型选择。可以按各种方式执行本发明的方法和系统。例如,可以通过软件、硬件、固件或者它们的组合执行本发明的方法和设备。所述方法的步骤的上述顺序仅旨在例示,并且本发明的方法的步骤不限于以上特别描述的顺序,除非另外特别陈述。此外,在一些实施例中,本发明还可以实施为记录在记录介质中的程序,包括用于实现根据本发明的方法的机器可读指令。由此,本发明还覆盖存储用于实现根据本发明的方法的程序的记录介质。虽然通过例子具体例示了本发明的一些特定实施例,但是本领域技术人员应当理解以上例子仅旨在例示而不是限制本发明的范围。本领域技术人员应当理解可以在不脱离本发明的范围和精神的情况下修改以上实施例。本发明的范围由所附权利要求限定。虽然参照示例性实施例描述了本发明,但应理解本发明不限于公开的示例性实施例。以下权利要求的范围应当被给予最宽的解释以包含所有修改以及等同的结构和功能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1