数据导入处理方法及数据处理装置与流程
技术特征:
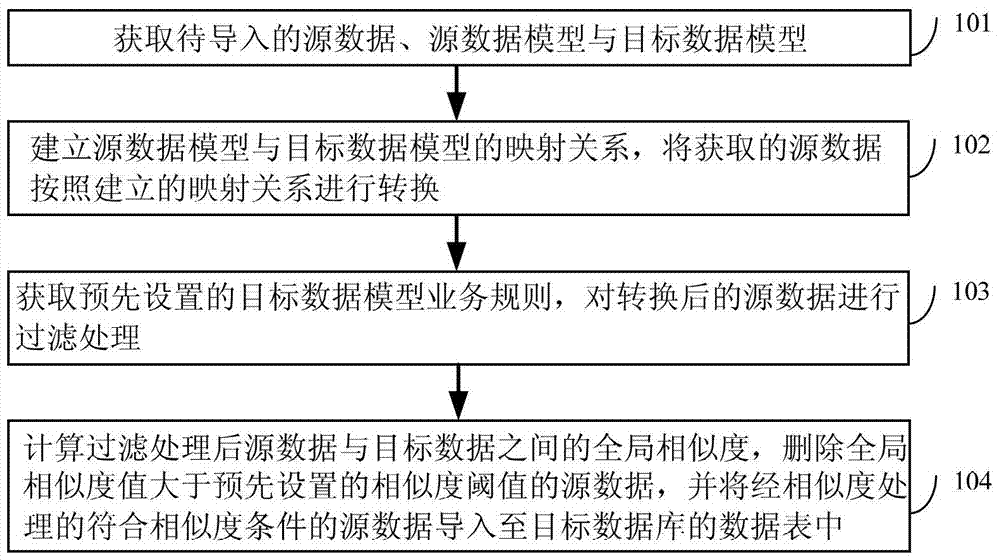
1.一种数据导入处理方法,包括:
获取待导入的源数据、源数据模型与目标数据模型;
建立源数据模型与目标数据模型的映射关系,将获取的源数据按照建立的映射关系进行转换;
获取预先设置的目标数据模型业务规则,对转换后的源数据进行过滤处理;
其中,所述目标数据模型业务规则设置有多条,所述对转换后的源数据进行过滤处理包括:
如果源数据不满足多条业务规则中的任意一条,则将该源数据执行过滤处理;
计算过滤处理后源数据与目标数据之间的全局相似度,删除全局相似度值大于预先设置的相似度阈值的源数据,并将经相似度处理符合相似度条件的源数据导入至目标数据库的数据表中;
所述建立源数据模型与目标数据模型的映射关系包括:
获取源数据模型中属性项的源关键词;
获取目标数据模型中属性项的目标关键词;
将获取的源关键词,依序遍历匹配目标关键词,获取与源关键词匹配的目标关键词;
根据源关键词匹配的目标关键词,建立将源数据模型转换为目标数据模型的映射关系。
2.根据权利要求1所述的方法,其中,所述源数据模型和目标数据模型中的每一个包括:数据表、EXEL表、可扩展标记语言以及文本。
3.根据权利要求2所述的方法,其中,一所述源关键词唯一匹配一目标关键词,或一所述源关键词匹配多个目标关键词,或多个所述源关键词匹配同一目标关键词,或所述源关键词没有与之匹配的目标关键词。
4.根据权利要求3所述的方法,其中,所述根据源关键词匹配的目标关键词,建立将源数据模型转换为目标数据模型的映射关系包括:
根据目标数据模型的属性项,对匹配的源数据模型的属性项进行拆分、合并以及数据归一处理,将源数据模型映射至目标数据模型。
5.根据权利要求1所述的方法,其中,采用最近邻相似度算法中海明距离计算所述全局相似度。
6.根据权利要求5所述的方法,其中,计算所述全局相似度的公式为:
式中,
sim(X,Y)表示数据表中源数据记录X与目标数据记录Y的全局相似度;
xi和yi分别为源数据记录X和目标数据记录Y的第i个属性;
wi表示第i个属性的权重,i=1,2,3,…,n,n为记录中属性的个数;
其中,
dist(xi,yi)=|xi-yi|/|maxi-mini|
式中,
maxi,mini分别表示记录的第i个属性的最大值、最小值。
7.一种数据处理装置,其特征在于,该装置包括:源数据获取模块、映射关系构建模块、过滤模块以及相似度处理模块,其中,
源数据获取模块,用于获取待导入的源数据、源数据模型与目标数据模型,输出至源数据获取模块;
映射关系构建模块,用于根据源数据获取模块的输出,建立源数据模型与目标数据模型的映射关系,将获取的源数据按照建立的映射关系进行转换,输出至过滤模块;
过滤模块,用于获取预先设置的目标数据模型业务规则,对接收的转换后的源数据进行过滤处理,输出至相似度处理模块;
相似度处理模块,用于计算过滤处理后源数据与目标数据之间的全局相似度,删除全局相似度值大于预先设置的相似度阈值的源数据,并将经相似度处理符合相似度条件的源数据导入至目标数据库的数据表中;
其中,所述目标数据模型业务规则设置有多条,所述对转换后的源数据进行过滤处理包括:
如果源数据不满足多条业务规则中的任意一条,则将该源数据执行过滤处理;
所述映射关系构建模块包括:源关键词获取单元、目标关键词获取单元、匹配单元以及映射关系构建单元,其中,
源关键词获取单元,用于获取源数据模型中属性项的源关键词;
目标关键词获取单元,用于获取目标数据模型中属性项的目标关键词;
匹配单元,用于根据源关键词获取单元获取的源关键词,依序遍历匹配目标关键词获取单元获取的目标关键词,获取与源关键词匹配的目标关键词;
映射关系构建单元,用于根据源关键词匹配的目标关键词,建立将源数据模型转换为目标数据模型的映射关系。
8.根据权利要求7所述的装置,其特征在于,所述相似度处理模块包括:相似度数据获取单元、属性权重分配单元、最近邻相似度算法计算单元、全局相似度计算单元以及相似度处理单元,其中,
相似度数据获取单元,用于获取计算全局相似度的源数据以及目标数据;
属性权重分配单元,用于为相似度数据获取单元中的源数据的属性项配置权重系数,输出至全局相似度计算单元;
最近邻相似度算法计算单元,用于计算源数据与目标数据中对应属性项之间的局部相似度,输出至全局相似度计算单元;
全局相似度计算单元,用于根据属性权重分配单元以及最近邻相似度算法计算单元的输出,依据全局相似度计算公式计算源数据与目标数据之间的全局相似度值,输出至相似度处理单元;
相似度处理单元,用于判断接收的全局相似度值是否大于预先设置的相似度阈值,如果是,删除大于预先设置的相似度阈值的源数据,并将经相似度处理符合相似度条件的源数据导入至目标数据库的数据表中;如果否,将符合相似度条件的源数据导入至目标数据库的数据表中。
9.根据权利要求8所述的装置,其特征在于,所述全局相似度计算公式为:
式中,
sim(X,Y)表示数据表中源数据记录X与目标数据记录Y的全局相似度;
xi和yi分别为源数据记录X和目标数据记录Y的第i个属性;
wi表示第i个属性的权重,i=1,2,3,…,n,n为记录中属性的个数。
其中,
dist(xi,yi)=|xi-yi|/|maxi-mini|
式中,
maxi,mini分别表示记录的第i个属性的最大值、最小值。
- 还没有人留言评论。精彩留言会获得点赞!