分布式存储系统中的会话管理的制作方法
许多公司和其他组织运营计算机网络,所述计算机网络使众多计算系统互连以支持它们的操作,诸如其中计算系统位于同一位置(例如,作为本地网络的一部分)或者相反地位于多个不同的地理位置中(例如,通过一个或多个私有或公共中间网络加以连接)。例如,容纳显著数量互连计算系统的数据中心已变得司空见惯,诸如由单一组织运营和代表所述组织运营的私有数据中心,以及由作为企业的实体运营来向客户提供计算资源的公共数据中心。一些公共数据中心运营商为由各种客户所拥有的硬件提供网络访问、电力以及安全安装设施,而其他公共数据中心运营商提供“全方位服务”设施,所述设施也包括可供其客户使用的硬件资源。
一些大型提供商网络实现多种存储服务,诸如实现可被建模为可通过各自URL访问的任意位桶的块级装置(卷)或对象的服务。然而,在提供商网络的数据中心处运行的多个应用可仍然面临关于其使用一些更常见的存储相关的编程接口的限制,诸如各种行业标准文件系统接口。一些行业标准文件系统可能在网络可访问服务的大规模部署之前已经被设计,并且可以因此支持一致性模型和不直截了当地在分布式系统中实现的其他语义,其中异步计算的交互、单独部件的故障和网络分区或网络相关的延迟都是相对常见的。
附图说明
图1提供根据至少一些实施方案的分布式文件存储服务的高级概要图。
图2示出根据至少一些实施方案的使用在提供商网络的多个可用性容器处的资源来实现文件存储服务。
图3示出根据至少一些实施方案的与隔离虚拟网络相关联的网络地址被分配给存储服务的访问子系统节点的配置。
图4示出根据至少一些实施方案的文件存储服务对象、逻辑块以及一个或多个盘区处的物理页面之间的映射。
图5示出根据至少一些实施方案的数据盘区和元数据盘区的复本组的配置。
图6示出根据至少一些实施方案的与在文件存储服务的访问子系统节点处的高速缓存元数据相关联的交互的实例。
图7示出根据至少一些实施方案的与针对文件存储区的数据耐久性、性能和逻辑到物理数据映射有关的策略的不同组合的使用的实例。
图8a是示出根据至少一些实施方案的可被执行来实现可缩放分布式文件系统存储服务的配置和管理相关操作的方面的流程图。
图8b是示出根据至少一些实施方案的可响应于可缩放分布式文件系统存储服务处的客户端请求而执行的操作的方面的流程图。
图9是示出根据至少一些实施方案的可被执行来实现分布式文件系统存储服务处的基于复制的耐久性策略的操作的方面的流程图。
图10是示出根据至少一些实施方案的可被执行来在分布式文件系统存储服务的访问子系统节点处高速缓存元数据的操作的方面的流程图。
图11示出根据至少一些实施方案的可在文件存储服务处实现的读取-修改-写入序列的实例,其中写入偏移和写入大小可能有时候不与原子单位物理存储装置的边界对齐。
图12示出根据至少一些实施方案的用于盘区复本组的基于共识的复制状态机的使用。
图13示出根据至少一些实施方案的可用于一些类型的写入操作的有条件写入协议中涉及的示例性交互。
图14示出根据至少一些实施方案的可被建立来实现有条件写入协议的示例性写入日志缓冲器。
图15是示出根据至少一些实施方案的可被执行来在分布式文件系统存储服务处实现有条件写入协议的操作的方面的流程图。
图16示出根据至少一些实施方案的可导致文件存储服务处的分布式事务的提交的示例性消息流。
图17示出根据至少一些实施方案的可导致文件存储服务处的分布式事务的中止的示例性消息流。
图18示出根据至少一些实施方案的包括被指定为事务协调器的节点的分布式事务参与者节点链的实例。
图19示出根据至少一些实施方案的可被执行来在节点链的节点中的一个处发生故障时促进分布式事务完成的示例性操作。
图20是示出根据至少一些实施方案的可被执行来协调文件系统存储服务处的分布式事务的操作的方面的流程图。
图21是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务准备消息而执行的操作的方面的流程图。
图22是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务提交消息而执行的操作的方面的流程图。
图23是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务中止消息而执行的操作的方面的流程图。
图24示出根据至少一些实施方案的分布式存储服务处的过量预订的存储盘区的实例。
图25示出根据至少一些实施方案的实现按需式物理页面级分配以及盘区过量预订的存储服务的子系统之间的交互。
根据至少一些实施方案,图26a示出自由空间阈值已被指定用于的盘区,而图26b示出由自由空间阈值的违反引起的盘区扩展。
图27是示出根据至少一些实施方案的可被执行来实现支持过量预订的盘区处的按需式物理页面分配的操作的方面的流程图。
图28是示出根据至少一些实施方案的可被执行来动态修改盘区过量预订参数的操作的方面的流程图。
图29示出根据至少一些实施方案的使用可变条带大小条带化的文件存储对象的实例。
图30示出根据至少一些实施方案的可用于文件存储对象的条带定大小序列的实例。
图31示出根据至少一些实施方案的可在元数据子系统处加以考虑以便为文件存储对象做出条带定大小和/或合并决定的因素的实例。
图32是示出根据至少一些实施方案的可被执行来使用可变条带大小实现条带化的操作的方面的流程图。
图33示出根据至少一些实施方案的由指向存储服务对象的逻辑块的多个并行读取请求在调度环境中进行的进程的示例性时间线,其中针对逻辑块的所有读取请求被授予相对于彼此平等的优先级。
图34示出根据至少一些实施方案的由指向存储服务对象的逻辑块的多个并行读取请求在调度环境中进行的进程的示例性时间线,其中使用基于偏移的拥塞控制策略。
根据至少一些实施方案,图35a示出可用于在存储服务处调度I/O请求的基于令牌的拥塞控制机制的实例,而图35b示出可采用的基于偏移的令牌消耗策略的实例。
图36示出根据至少一些实施方案的用于存储服务处的拥塞控制的基于偏移的延迟的使用的实例。
图37示出根据至少一些实施方案的可取决于被访问的存储对象的类型和所请求访问的各种特性的拥塞控制策略的实例。
图38是示出根据至少一些实施方案的可被执行来实现基于偏移的拥塞控制以在存储服务处调度I/O操作的操作的方面的流程图。
图39示出根据至少一些实施方案的可必须在存储服务的多个元数据子系统节点处执行以实现重命名操作的元数据改变的实例。
图40示出根据至少一些实施方案的用于并行重命名操作的死锁避免机制的使用。
图41是示出根据至少一些实施方案的可被执行来在两个可能锁排序中基于第一锁排序实现第一重命名工作流的操作的方面的流程图,所述锁排序可在存储服务处针对重命名操作确定。
图42是示出根据至少一些实施方案的可被执行来在两个可能锁排序中基于第二锁排序实现第二重命名工作流的操作的方面的流程图,所述锁排序可在存储服务处针对重命名操作确定。
图43是示出根据至少一些实施方案的可响应于参与重命名工作流的一对元数据子系统节点的一个元数据子系统节点的故障而执行的恢复操作的方面的流程图。
图44是示出根据至少一些实施方案的可响应于参与重命名工作流的所述对元数据子系统节点的另一个元数据子系统节点的故障而执行的恢复操作的方面的流程图。
图45示出根据至少一些实施方案的可用于文件存储命名空间管理的基于散列的有向无环图(DAG)的实例。
图46示出根据至少一些实施方案的使用针对文件名获得的散列值的连续子序列遍历HDAG的技术。
图47示出根据至少一些实施方案的可由尝试将条目插入命名空间引起的两种类型的HDAG节点分裂中的第一种的实例。
图48示出根据至少一些实施方案的可由尝试将条目插入命名空间引起的两种类型的HDAG节点分裂中的第二种的实例。
图49示出根据至少一些实施方案的两种类型的HDAG节点删除操作中的第一种的实例。
图50示出根据至少一些实施方案的两种类型的HDAG节点删除操作中的第二种的实例。
图51是示出根据至少一些实施方案的可响应于导致第一类型的HDAG节点分裂的将条目插入命名空间而执行的操作的方面的流程图。
图52是示出根据至少一些实施方案的可响应于导致第二类型的HDAG节点分裂的将条目插入命名空间而执行的操作的方面的流程图。
图53是示出根据至少一些实施方案的可响应于将条目从命名空间删除而执行的操作的方面的流程图。
图54示出根据至少一些实施方案的可维持用于分布式存储服务处的面向会话的文件系统协议的元数据的两个维度。
图55示出根据至少一些实施方案的分布式存储服务的子部件之间的客户端会话元数据相关的交互的实例。
图56示出根据至少一些实施方案的分布式存储服务处的客户端会话租用续订的替代方法。
图57a和图57b示出根据至少一些实施方案的分布式存储服务处的面向会话的文件系统协议的锁定状态管理的替代方法。
图58是示出根据至少一些实施方案的可在分布式存储服务处执行的客户端会话元数据管理操作的方面的流程图。
图59是示出根据至少一些实施方案的可在分布式存储服务处执行的客户端会话租用续订操作的方面的流程图。
图60示出根据至少一些实施方案的负载平衡器层被配置用于分布式存储服务的系统。
图61示出根据至少一些实施方案的负载平衡器节点与分布式存储服务的多个访问子系统节点之间的示例性交互。
图62示出根据至少一些实施方案的可随进行的连接尝试的数量变化的连接接受准则的实例。
图63示出根据至少一些实施方案的可取决于与多个资源相关联的工作负载水平以及连接建立尝试计数的连接接受准则的实例。
图64是示出根据至少一些实施方案的可被执行来基于分布式存储服务处的尝试计数实现连接平衡的操作的方面的流程图。
图65示出根据至少一些实施方案的可基于访问节点的对等组的成员的工作负载指示符尝试客户端连接重新平衡所在的分布式存储服务的访问子系统的实例。
图66示出根据至少一些实施方案的可在访问子系统节点处使用的连接接受和重新平衡准则的实例。
图67是示出根据至少一些实施方案的可在分布式存储服务的访问子系统处执行以实现连接重新平衡的操作的方面的流程图。
图68是示出根据至少一些实施方案的可在分布式存储服务处执行以保存跨连接重新平衡事件的客户端会话的操作的方面的流程图。
图69是示出可在至少一些实施方案中使用的示例性计算装置的框图。
虽然在本文中通过列举若干实施方案和说明性附图的方式描述实施方案,但是本领域的技术人员将认识到,实施方案并不限于所描述的实施方案或附图。应理解,附图和对其的详细描述并非意图将实施方案限于所公开的特定形式,而是相反地,其意图在于涵盖落入由所附权利要求书所界定的精神和范围内的所有修改、等同物以及替代方案。本文中使用的标题仅用于组织目的,并且并不意图用于限制说明书或权利要求书的范围。如贯穿本申请所使用的,词语“可”是以允许意义(即,意味着有可能)而不是强制意义(即,意味着必须)使用的。类似地,词语“包括(include/including/includes)”意味着“包括但不限于”。
具体实施方式
描述用于高可用性、高耐久性可缩放文件存储服务的方法和设备的各种实施方案。在至少一些实施方案中,文件存储服务可被设计来支持由几千的客户端共享地访问文件,其中每个单独文件可包括非常大量(例如,拍字节)的数据,旨在独立于文件的大小和/或并行用户的数量的性能、可用性和耐久性水平。一个或多个行业标准文件系统接口或协议可由服务支持,诸如各种版本的NFS(网络文件系统)、SMB(服务器消息块)、CIFS(通用互联网文件系统)等。因此,在至少一些实施方案中,由分布式文件存储服务支持的一致性模型可至少与由行业标准协议支持的模型一样强,例如,服务可支持顺序一致性。在实现顺序一致性模型的分布式系统中,在多个执行实体(例如,分布式系统的节点或服务器)处集体实现的操作执行的结果预期与所有操作以某一顺序次序执行的结果相同。文件存储服务可被设计成由广泛多种应用使用,诸如文件内容服务(例如,网络服务器群、软件开发环境以及内容管理系统)、高性能计算(HPC)和“大数据”应用,诸如需要按需缩放文件存储能力和性能的媒介、财政和科学解决方案等。术语“文件存储”在本文中可用于指示文件系统的逻辑等效物,例如,给定客户端可创建两个不同NFS兼容文件存储区FS1和FS2,其中FS1的文件存储在可安装根目录的一组子目录内,并且FS2的文件存储在不同可安装根目录的一组子目录内。
为了帮助实现高水平的可缩放性,在至少一些实施方案中,模块架构可用于服务。例如,包括某一数量的多租户存储节点的物理存储子系统可用于文件存储内容,而在一个实现方式中,具有其自身一组元数据节点的逻辑上不同的元数据子系统可用于管理文件存储内容。元数据和数据的逻辑分离可由例如以下事实推动:对元数据的性能、耐久性和/或可用性要求可在至少一些情况下与对数据的对应要求不同(例如,更严格)。具有不同于元数据和存储节点的自身一组访问节点的前端访问子系统可负责暴露允许客户端通过行业标准接口提交创建、读取、更新、修改和删除文件存储的请求的网络端点,并且负责处理连接管理、负载平衡、认证、授权以及与客户端交互相关联的其他任务。在一些实施方案中,资源可独立于子系统中的任何一个部署,例如,访问子系统、元数据子系统或存储子系统,而不需要其他子系统处的对应部署变化。例如,如果诸如潜在性能瓶颈的触发条件在访问子系统中识别到,或者如果某一组访问子系统节点经历网络停止运行或其他故障,那么另外的访问子系统节点可上线而不影响存储或元数据子系统并且不暂停客户端请求流。响应于各种类型的触发条件,类似部署改变也可在其他子系统处进行。在一些实施方案中,访问子系统节点具体地可以大致无状态方式实现,使得从访问节点故障恢复可特别有效。
在至少一些实施方案中,文件存储元数据对象的内容(例如,表示目录实体的属性的数据结构、链接等)可自身存储在由存储子系统管理的装置上,但如下所述,在一些情况下,与应用到用于元数据的存储对象的策略不同的策略可应用到用于数据的存储对象。在此类实施方案中,元数据子系统节点可例如包括执行元数据管理逻辑并协调存储子系统处的元数据内容的存储的各种执行过程或线程。在一些实施方案中,给定存储子系统节点可包括若干不同类型的存储介质,诸如某一数量的装置采用旋转磁盘以及某一数量的装置采用固态驱动器(SSD)。在一些实施方案中,给定存储子系统节点可存储元数据和数据两者在各自不同的存储装置处或者在同一存储装置上。术语“文件存储对象”在本文可用于统指数据对象诸如存储服务的客户端通常可见的文件、目录等,以及内部元数据结构(包括例如以下论述的逻辑块、物理页面以及盘区之间的映射),用于管理和存储数据对象。
在至少一些实施方案中,分布式文件存储服务可使用提供商网络的资源构建,并且可被主要设计来履行来自提供商网络内的其他实体的存储请求。实体(诸如公司或公共部门组织)所建立的用于将可通过互联网和/或其他网络访问的一个或多个网络可访问服务(诸如各种类型的基于云的计算或存储服务)提供给一组分布式客户端的网络在本文中可称为提供商网络。服务中的一些可用于构建较高级服务:例如,计算、存储或数据库服务可用作内容分布服务或流数据处理服务的构建块。提供商网络的服务中的至少一些可被封装用于称作“实例”的服务单元中的客户端使用:例如,由虚拟计算服务实例化的虚拟机可表示“计算实例”。实现提供商网络的此类计算实例的计算装置在本文中可称为“实例主机”或本文中更简单地称为“主机”。给定实例主机可包括若干计算实例,并且特定实例主机处的计算实例的集合可用于实现一个或多个客户端的应用。在一些实施方案中,例如,由于将适当网络地址分配给存储服务的访问子系统节点、实现用于虚拟计算服务的授权/认证协议等等,可从提供商网络的计算实例中的一些子集(或所有)访问文件存储服务。在一些实施方案中,提供商网络外面的客户端也可访问文件存储服务。在各种实施方案中,提供商网络服务中的至少一些可实现基于使用的定价策略,例如,客户可至少部分地基于实例被用了多久或者基于从计算实例提交的各种类型的请求的数量来为计算实例付费。在至少一些此类实施方案中,文件存储服务也可针对客户端请求的至少一些分类采用基于使用的定价,例如,服务可把代表给定客户完成的特定文件系统接口请求记录下来,并且可基于那些记录为客户生成付款金额。
在一些实施方案中,文件存储服务可例如使用多种不同复制技术中的任一种来支持高水平的数据耐久性。例如,在一个实施方案中,文件存储数据和元数据可使用称作盘区的存储单元物理存储,并且盘区的内容可在各种物理存储装置处复制。盘区的内容在本文中可称为“逻辑盘区”以将其与不同物理存储装置处的物理副本区分开,所述物理副本可称为“盘区复本”,“复本组成员”或“小盘区”或“复本组”。在一个实现方式中,例如,文件(或元数据对象)可被组织为逻辑块的序列,其中每个逻辑块被映射到一个或多个物理数据页。逻辑块可考虑分条单元,因为至少在一些实现方式中,同一文件(或同一元数据结构)的两个不同逻辑块的内容存储在同一存储装置处的概率可能很小。给定逻辑盘区的每个复本可包括某一数量的物理数据页。在一些实施方案中,可使用基于擦除编码的盘区复本,而在其他实施方案中,可使用诸如完全复制的其他复制技术。在至少一个实施方案中,可使用擦除编码和完全复制的组合。来自客户端的给定修改请求可因此转换成各自存储装置和/或各自存储子系统节点处的多个物理修改,这取决于用于对应文件存储对象或元数据的复制策略的本质。在一些实施方案中,复本组的盘区复本中的一个或多个可被指定为主复本,并且对盘区的更新可由托管当前主复本的存储服务节点例如使用基于共识的复制状态机协调。这种存储服务节点在本文中可关于针对存储主复本的盘区被称为“主节点”或“领导者”。在一个实现方式中,如果给定逻辑盘区的N个盘区复本被维持,那么可需要M(其中M>=N/2)个定额复本,并且这种定额可在特定更新提交之前使用由领导者/主节点发起的更新协议获得。在一个实施方案中,一些盘区可完全用于文件内容或数据,而其他盘区可唯一地用于元数据。在其他实施方案中,给定盘区可存储数据和元数据两者。在一些实现方式中,基于共识的协议可用于复制指示给定文件存储区的状态改变的日志记录,并且状态的内容可使用多个盘区复制(例如,使用完全复制或擦除编码复制)。复制的状态机还可用于确保各种实施方案中的至少一些类型的读取操作的一致性。例如,单个客户端读取请求可实际上需要各种盘区处的多个物理读取操作(例如,对元数据和/或数据),并且复制状态机的使用可确保这种分布式读取的结果不违反目标文件存储的读取一致性要求。
多种不同分配和定大小策略可用于确定如下所述的不同实施方案中用于数据和元数据的逻辑块、物理页面和/或盘区的大小和它们之间的关系。例如,在一个直截了当的实现方式中,文件可包括某一数量的固定大小(例如,4兆字节)的逻辑块,每个逻辑块可包括某一数量的固定大小(例如,32千字节)的物理页面,并且每个盘区可包括足够存储空间(例如,16千兆字节)以存储固定数量的页。在其他实施方案中,不同的逻辑块大小可不同,物理页面大小可不同,或者盘区大小可不同。在一些实施方案中,盘区可动态地调整大小(例如,增长或缩小)。静态分配可用于一些实施方案中的逻辑块(例如,整个逻辑块的所有物理存储可响应于指向块的第一写入而被分配,不管写入有效负载相对于块大小的大小),而动态分配可用在其他实施方案中。以下更详细地描述调节逻辑块配置和对应物理存储空间分配的各种技术和策略。在一些实施方案中,由文件存储服务管理的不同文件存储区可实现不同的块/页/盘区定大小和配置策略。在一些情况下,取决于使用的文件系统接口允许客户端指定的写入大小,来自客户端的给定写入操作可导致仅一部分页而不是整页的修改。在给定实现方式中,如果物理页面是相对于由存储子系统支持的写入的最低水平的原子性,而写入请求可指向任意量的数据(即,写入不必为页对齐的并且不必修改整数页的所有内容),那么一些写入可在存储服务内内部地被视为读取-修改-写入序列。以下提供关于可用于写入的在一些此类实施方案中不跨过页边界的乐观的有条件写入技术的细节。通常,在至少一些实施方案中,每个存储装置和/或存储服务节点可支持多个不同客户的操作和/或存储数据。
通常,针对从客户接收的单个文件存储操作请求可能必须读取或修改的元数据和/或数据可分布在多个存储服务节点之间。例如,删除操作、重命名操作等可需要对位于若干不同存储装置上的元数据结构的多个元素的更新。根据顺序一致性模型,在至少一个实施方案中,包括一组文件系统元数据修改的原子元数据操作可执行以便对单个客户端请求做出响应,包括一个元数据子系统节点处的第一元数据修改和不同元数据子系统节点处的第二元数据修改。支持顺序一致性的各种分布式更新协议可用在不同实施方案中,例如,以下进一步详细描述的分布式事务机制可在至少一些实施方案中用于此类多页面、多节点或多盘区更新。当然,在一些实施方案中,取决于使用的复制策略,元数据修改中的每一个可进而涉及对多个盘区复本的更新。
在一些实施方案中,可采用与文件存储服务的各方面相关联的优化技术,诸如对象重新命名协议、考虑连接寿命的负载平衡技术、命名空间管理技术、客户端会话元数据高速缓存、基于偏移的拥塞控制策略等的使用。以下结合各个附图的描述提供关于存储服务的这些特征的细节。
文件存储服务概要
图1提供根据至少一些实施方案的分布式文件存储服务的高级概要图。如图所示,包括存储服务102的系统100可按逻辑分成至少三个子系统:存储子系统130、元数据子系统120和访问子系统110。每个子系统可包括多个节点,诸如存储子系统130的存储节点(SN)132A和132B,元数据子系统120的元数据节点(MN)122A和122B,以及访问子系统110的访问节点(AN)112A和112B。在一些实施方案中,每个节点可例如实现为在各自物理或虚拟服务器处执行的一组过程或线程。在至少一些实施方案中,任何给定子系统中的节点的数量可独立于其他子系统中的节点的数量修改,因此允许另外资源按需要部署在子系统中的任一个处(以及子系统中的任一个处的资源的类似独立减少)。术语“访问服务器”、“元数据服务器”和“存储服务器”在本文中可分别用作术语“访问节点”、“元数据节点”和“存储节点”的等效物。
在所描绘实施方案中,存储节点132可负责例如使用SSD和转盘的某一组合来存储盘区134(诸如在存储节点132A处的134A和134,并且在存储节点132B处的盘区134K和134L)。可例如在某一组物理存储装置处包括某一数量的千兆字节(通常但不总是)连续存储空间的盘区可在一些实施方案中表示存储复制单元,因此,任何给定逻辑盘区的多个物理复本可被存储。在一些实施方案中,每个盘区复本可被组织为多个物理页面,其中所述页表示在存储子系统内实现读取或写入的最小单元。如以下关于图4论述的,给定文件存储对象(例如,文件或元数据结构)可被组织为一组逻辑块,并且每个逻辑块可映射到数据盘区内的一组页。文件存储对象的元数据可自身包括一组逻辑块(潜在地具有与数据的对应逻辑块不同的大小),并且可存储在不同盘区134的页中。在至少一些实施方案中,复制状态机可用于管理对盘区复本的更新。
访问子系统110可表示到客户端180的一个或多个文件系统接口,诸如所描绘实施方案中的文件系统API(应用编程接口)140。在至少一些实施方案中,如以下更详细描述的,一组负载平衡器(例如,可独立于存储服务自身配置的软件或硬件装置)可充当存储服务的客户端与访问子系统之间的中介。在一些情况下,负载平衡功能的至少一些方面可在访问子系统自身内实现。在至少一些实施方案中,访问子系统节点112可表示在由客户端180并行使用的适当网络结构内建立的服务端点。如以下关于图3描述的,在一些实施方案中,与隔离虚拟网络相关联的特殊网络地址可被分配给AN 112。AN 112可例如基于客户端的网络身份以及用户身份认证传入客户端连接;在一些情况下,AN可与类似于活动目录服务或Kerberos的身份/认证服务交互。可由分布式文件存储服务102支持的一些文件系统协议(诸如NFSv4和SMB2.1)可需要文件服务器来维持状态,例如与锁和打开的文件标识符有关。在一些实施方案中,耐久的服务器状态,包括锁和打开的文件状态,可由元数据子系统120而不是访问子系统处理,并且因此访问子系统可被认为是可按需要放大和缩小的大致无状态服务器集群。在一些实施方案中,如以下关于图6描述的,AN 112可高速缓存与各种文件存储对象有关的元数据状态,并且可使用所高速缓存元数据来直接向存储节点提交至少一些内部I/O请求,而不需要与元数据节点的交互。
元数据子系统120可负责管理所描绘实施方案中的各种类型的文件存储元数据结构,包括例如索引节点的逻辑等效物,文件/目录属性诸如访问控制列表(ACL)、链接数、修改时间、真实文件大小、指向存储子系统页的逻辑块映射等。另外,在一些实施方案中,元数据子系统可记录文件存储对象的打开/关闭状态以及各种文件存储对象上的锁的打开/关闭状态。元数据子系统120可定序并协调操作以便维持期望的文件存储对象一致性语义,诸如NFS客户端预期的关闭到打开语义。元数据子系统还可例如使用以下描述的分布式事务技术来确保可涉及多个元数据元素(诸如,重新命名、删除、截短和附加)的操作中的顺序一致性。尽管元数据子系统120在逻辑上独立于存储子系统130,但在至少一些实施方案中,持久元数据结构可存储在存储子系统处。在此类实施方案中,即使元数据结构可物理存储在存储子系统处,元数据子系统节点也可负责此类任务,如识别将使用的特定存储节点、协调或定序指向元数据的存储操作等。在至少一些实施方案中,元数据子系统可重用在一些实施方案中由存储子系统采用的状态管理技术中的一些,诸如存储子系统的基于共识的状态复制机器。
文件存储服务的提供商网络实现
如前所述,在一些实施方案中,分布式存储服务可使用提供商网络的资源实现,并且可用于由在提供商网络的计算实例处运行的应用或客户端进行的文件相关操作。在一些实施方案中,提供商网络可被组织成多个地理区域,并且每个区域可包括一个或多个可用性容器,所述可用性容器在本文中还可称为“可用性区”。可用性容器进而可包括一个或多个不同位置或数据中心,所述位置或数据中心被构建(例如,利用独立基础结构部件,诸如电力相关设备、冷却设备以及物理安全部件),其方式为使得给定可用性容器中的资源绝缘于其他可用性容器中的故障。一个可用性容器中的故障可不预期导致任何其他可用性容器中的故障;因此,资源的可用性配置文件意图独立于不同可用性容器中的资源的可用性配置文件。可通过在各自的可用性容器中启动多个应用实例来保护各种类型的应用以免在单个位置处出现故障。在一些实施方案中,存储服务的各种子系统的节点也可跨若干不同可用性容器分布,例如根据服务的可用性/正常运行时间目标和/或各种文件存储区的数据冗余要求。同时,在一些实现方式中,可提供驻留在同一地理区域内的资源(诸如用于分布式文件存储服务的主机或存储装置)之间的廉价且低等待时间的网络连接性,并且同一可用性容器的资源之间的网络传输可以甚至更快。一些客户端可能想要指定用于其文件存储区的资源中的至少一些保留和/或实例化的位置(例如,以区域级、可用性容器级或数据中心级),以便维持对其应用的各种部件运行地方的期望精确控制程度。只要资源例如针对性能、高可用性等满足客户端要求,其他客户端可对其资源保留或实例化的精确位置不那么感兴趣。
在至少一些实施方案中,给定数据中心内的资源可基于预期可用性或故障弹性水平的差进一步划分为子组。例如,数据中心处的一个或多个服务器机架可被指定为较低级可用性容器,因为机架内的相关故障的概率可至少在一些情况下高于不同机架上的相关故障的概率。至少在一些实施方案中,当决定在哪里实例化存储服务的各种部件或节点时,可与性能目标和耐久性目标一起考虑各种级的所述可用性容积的任何组合(例如,区域级、数据中心级或机架级)。因此,对于一些类型的存储服务部件,机架级的冗余/复制可被认为是足够的,因此大体不同机架可用于提供相同功能(或存储同一数据/元数据的复本)的不同部件。对于其他部件,还可以或相反以数据中心级或以区域级实现冗余/复制。
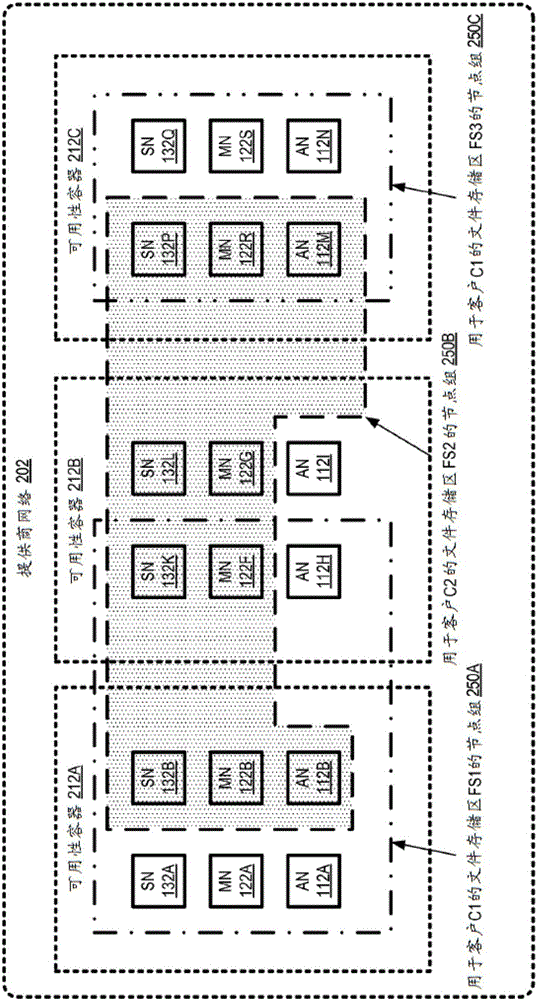
图2示出根据至少一些实施方案的使用在提供商网络202的多个可用性容器212处的资源来实现文件存储服务。在描绘的实施方案中,示出三个可用性容器212A、212B和212C,各自包括存储服务的某一数量的存储节点、元数据节点以及访问节点。由于每个可用性容器通常被建立以便防止跨过可用性容器边界的相关故障事件,故被分配给给定文件存储区的所述组存储服务节点可通常遍布不同可用性容器。应注意,一些文件存储区可具有比其他文件存储区低的可用性或耐久性要求,并且可因此在至少一些实施方案中在单个可用性容器内实现。在一个实施方案中,当文件存储服务建立时,节点池可针对若干可用性容器212中的每一个中的三个子系统中的每一个建立,从所述池特定节点可按需要分配给给定文件存储区。在其他实施方案中,代替建立预配置的存储服务节点池,新的节点可按需要被实例化。
集体实现给定文件存储区或文件系统的文件存储的AN、MN和SN的集合可被称为那个文件存储区的“节点组”250。在图2中示出的实施方案中,存储服务节点是多租户的,因为子系统中的任一个的给定节点可负责处理来自若干不同客户端和/或若干不同客户的请求。应注意,在各种实施方案中,给定客户(例如,已在存储服务处代表其建立付款账户的商业实体或个人)可在所描绘实施方案中建立若干不同文件存储区,并且许多不同客户端装置(可从其调用编程接口的计算装置)可用于通过给定用户或者代表给定用户向单个文件存储区发布文件服务请求。在至少一些实施方案中,多个用户账户(例如,客户业务组织的若干员工中的每一个的一个或多个用户账户)可在单个付费账户的赞助下建立,并且用户账户中的每一个可提交来自多种客户端装置的文件存储请求。
用于客户C1的文件存储区FS1的图2的节点组250A包括分布在两个可用性容器212A和212B中的SN 132A、132B和132K,MN122A、122B和122F,以及AN 112A、112B和112H。用于不同客户C2的文件存储区FS2的节点组250B包括三个可用性容器212A、212B和212C中的节点:SN 132B、132K、132L和132P,MN 122B、122F、122G和122R,以及AN 112B和112M。用于客户C1的文件存储区FS3的节点组250C单独使用可用性容器212C的节点:SN 132P和132Q,MN 122R和122S,以及AN 112M和112N。将用于给定文件存储区的特定节点可基于各种因素例如由存储服务的放置部件按需选择,并且节点组可鉴于改变存储空间需求、性能需求、故障等随时间改变。在至少一些实施方案中,单个存储节点处的给定存储装置可存储属于不同客户端的数据和/或元数据。在至少一些实施方案中,单个盘区可包括多个客户端或客户的数据和/或元数据。
至少关于SN,在一些实施方案中,冗余或复制可针对给定文件存储区沿着若干不同尺寸实现。在给定文件中的数据量增长时,例如,文件的各种逻辑块可大体映射到不同逻辑盘区。因此,文件条带化可在逻辑块级实现,这可帮助改善某些模式的I/O请求的性能并且还可在用于文件的存储节点或装置中的一个出故障的情况下减少恢复大文件所花费的时间。在一些实现方式中,用于文件的元数据还可跨多个元数据逻辑盘区条带化并且由多个MN管理。每个逻辑盘区(不管是数据的还是元数据的)进而可例如使用擦除编码或完全复制在不同的可用性容器212处跨多个SN复制以实现期望的数据耐久性程度。如前所述,在至少一个实施方案中,复制可例如通过针对不同复本选择同一数据中心内的不同机架来跨较低级可用性容器实现。在一些实施方案中,AN和MN也可被组织成冗余组,使得如果一些AN或MN出故障,那么其工作负载可迅速由其冗余组中的不同成员接替。
在一些实施方案中,提供商网络202可支持代表各种客户的“隔离虚拟网络”(IVN)的建立。针对给定客户建立的IVN(在一些实施方案中还可称为虚拟私有云或VPC)可包括提供商网络的逻辑隔离部分中的计算和/或其他资源的集合,通过所述IVN客户被授予对于联网配置的基本控制。在一些实施方案中,例如,客户可选择将用于IVN资源的IP(互联网协议)地址范围,管理IVN内的子网的创建以及用于IVN的路由表、网关等的配置。在一些实施方案中,对于IVN内的装置中的至少一些,网络地址可至少在默认情况下在IVN外侧不可见。为了实现IVN与客户的外部网络(例如,客户的数据中心或办公驻地处的装置)之间的连接,被配置用于与私有地址一起使用的虚拟接口(并且可因此称为私有虚拟接口)和虚拟私有网关可被建立。在一些实施方案中,一个或多个VPN(虚拟私有网络)可被配置在客户的IVN与外部网络(诸如客户的办公室网络或客户的数据中心)之间。在至少一些实施方案中,此类VPN可利用安全联网协议,诸如IPSec(互联网协议安全)、SSL/TLS(安全套接字层/传送层保全)、DTLS(数据报传送层保全)等。
在一些实施方案中,为了安全或其他原因,对由分布式存储服务管理的给定文件存储区的访问可被限制在一个或多个IVN内的特定组客户端装置。图3示出根据至少一些实施方案的与隔离虚拟网络302相关联的网络地址被分配给存储服务的访问子系统节点的配置。此类地址分配的结果是,仅网络地址也位于IVN内的那些客户端可能够通过AN 112访问文件存储区。如图所示,图3中的提供商网络202包括SN 132A-132F,MN 122A-122F,以及AN 112A-112F。两个IVN 302A和302B已在提供商网络202中分别针对客户A和B建立。每个IVN包括虚拟计算服务302的多个计算实例(CI),需要文件存储服务的应用可在所述计算实例处运行。除了在IVN 302A(例如,CI380A和380B)和302B(CI 380K和380L)内示出的CI之外,在所描绘实施方案中,其他CI(例如,380P和380Q)也可在IVN外面的实例主机上运行,因此,不是文件存储服务的所有客户端都需要一定属于IVN 302。
为了能够从IVN 302A内的CI访问文件存储服务,AN 112A和112D已被分配有与IVN 302A相关联的私有IP(互联网协议)地址350A。因此,IVN 302A的客户端CI 380A和380B可使用地址350A调用文件存储服务接口,并且在与文件存储服务交互时可能够依赖已经针对IVN实现的各种网络隔离和安全特征。类似地,AN 112D和112E可被分配有IVM 302B的私有网络地址,实现从IVN 302B的客户端CI 380K和380L的安全访问。应注意,在至少一些实施方案中,给定AN(诸如112D)可被分配由多于一个网络地址,允许单个AN的资源被多个IVN共享。在其他实施方案中,每个AN可被限于不多于一个IVN的网络地址。除了私有地址之外,在一些实施方案中,公共网络地址(例如,可从公共互联网访问的IP地址)也可用于至少一些AN诸如AN 112C,实现从不是IVN的部分的CI诸如380P或380Q访问。在一个实施方案中,位于提供商网络202外面的客户端也可能够使用公共IP地址访问存储服务。在一些实施方案中,单个(私有或公共)网络地址可被分配给多个AN112,使得例如,传入网络请求可跨多个AN平衡,并且AN故障转移可在不影响客户端的情况下实现(例如,即使在特定AN出故障后,客户端仍可继续向同一地址发送文件存储请求,这是因为具有同一网络地址的剩余的AN可继续对客户端请求做出响应)。
逻辑块、页和盘区
图4示出根据至少一些实施方案的文件存储服务对象、逻辑块以及一个或多个盘区处的物理页面之间的映射。三个逻辑块LB 402A、402B和402C已被配置用于文件F1。在本文中逻辑块还可被称为条带,因为诸如文件或元数据结构的给定对象的不同逻辑块的内容可通常存储在不同存储位置处。在一些实施方案中,可强制诸如文件F1的条带A、B和C的条带的物理分离,例如,给定对象中没有两个条带可存储在同一物理存储装置中。在其他实施方案中,例如,由于跨大量物理装置的条带随机或接近随机分布的使用,条带的物理分离可在没有明确强制的情况下以高概率发生。在至少一些实施方案中,逻辑块大小可在给定文件或元数据结构内变化。在其他实施方案中,至少一些存储服务对象的所有逻辑块可具有相同大小。在所描绘实施方案中,每个逻辑块402的内容可存储在给定数据盘区434的一个或多个物理页面(PP)412中。因此,例如,LB 402的内容已被写入到存储节点132D的数据盘区434C处的PP 412J、412K和412L。LB 403的内容存储在存储节点132B的数据盘区434A内的PP 412B中,而LB404的内容存储在存储节点132C处的存储盘区434B的PP 412F中。为了简化块与页之间的映射的论述,图4中未示出盘区复本。至少在所描绘实施方案中,用于复制盘区的技术可独立于用于将块映射到页的技术。
在至少一些实施方案中,如以下更详细描述的,根据在接收到写入请求时可实际上仅分配存储给定写入请求的写入有效负载实际上需要的所述组的页,动态按需分配可用于物理存储。考虑以下示例性情境,其中特定LB的逻辑块大小是8兆字节,64千字节的固定页大小用于LB映射到的盘区,并且指向LB的第一写入包括56千字节的写入有效负载。在这种情境中,在使用按需分配的实施方案中,存储空间的仅一页(64千字节)可响应于请求被分配。在其他实施方案中,可响应于指向LB的第一写入请求而留出用于整个LB的物理存储,不管写入有效负载大小如何。
当客户端第一次写入到特定文件时,所选择元数据子系统节点可为一个或多个逻辑块402生成元数据475(例如,取决于写入有效负载相对于逻辑块大小的大小,在一些情况下可需要多于一个逻辑块)。在所描绘实施方案中,此元数据475自身可存储在一个或多个物理页面中,诸如元数据盘区464的PP 412Q。在至少一些实施方案中,用于元数据结构的块大小和/或页大小可不同于用于对应数据的那些。在至少一个实施方案中,可使用与用于数据的存储装置(例如,转盘)不同的种类或类型的存储装置(例如,SSD)来存储元数据盘区。在一些实现方式中,同一文件存储对象的元数据的至少一部分和元数据的至少一部分可存储在同一盘区中。
在一些实施方案中,如以上论述的,数据盘区434和/或元数据盘区464的内容可被复制例如以便满足各自数据耐久性要求。在此类实施方案中,如以下更详细描述的,逻辑盘区的特定复本可被选择作为主复本,并且可由主复本(或主复本驻留的存储节点)例如通过在指示对应更新请求已成功之前将对盘区的更新从主复本传播到所需数量的复本来发起和/或协调对盘区的更新。
在存储盘区的任何给定复本的存储装置处写入给定逻辑块的内容的次序可变化,即,如果对应于特定1兆字节的逻辑块的两个32千字节的物理页面P1和P2以次序“P2在P1之后”定位在盘或SSD上时,这可能不一定暗示P1中的数据在逻辑块内具有比P2中的数据小的起始偏移。在一些实施方案中,页可在它们被第一次写入之后移动(例如,在它们的存储装置内重新布置),例如以便促进改善的顺序读取或写入性能。在给定盘区或盘区复本内,与若干不同文件相关联的物理页面可存储在例如元数据盘区634中,除了F1的一个或多个文件的块到页的映射(或其他元数据)可存储在PP 412P、412R和412S中。类似地,页412A、412C、412D、412E、412G、412H和412M都可存储除了F1的文件的内容。在一些实施方案中,足够大数量的盘区可建立,同一文件的任何两个逻辑块被映射到同一盘区(例如,盘区的同一复本组)的概率可能很低。在这种情境中,可能并行地响应于指向同一文件的不同逻辑块的并行I/O请求,因为请求可针对(在多数情况下)不同存储节点和不同存储装置。在至少一个实施方案中,存储系统可大体倾向于以明显随机或接近随机的方式在可用盘区之间分布逻辑块,例如通过基于诸如特定块被第一次写入时可用自由空间的量的因素选择将用于特定块的盘区。
图5示出根据至少一些实施方案的数据盘区和元数据盘区的复本组510的配置。示出数据盘区D1和D2的两个复本组510A和510B,并且示出元数据盘区M1和M2的两个复本组510C和510D。示出的每个复本组包括位于存储子系统的各自存储节点132处的各自存储装置532处的两个或更多个复本,但通常可能有时候是这种情况:同一逻辑盘区的两个物理复本存储在同一存储节点处的同一存储装置上或者不同存储装置上。
每个复本组510被示出为包括一个主复本和一个或多个非主复本。主复本可负责例如使用复制状态机和/或基于共识的更新协议协调到复本组的成员的写入。在一些实施方案中,复制状态机和/或基于共识的协议也可用于读取。复制组中的复本的总数量可作为存储在复本中的文件数据和/或元数据的耐久性要求的函数而变。在图5中,复本564A是组510A的主复本,复本565B是组510B的主复本,复本575B是复本组510C的主复本,并且复本576B是复本组510D的主复本。复本组510A和510C各自包括两个非主复本(组510A的复本564B和564C,以及组510B的复本575A和575C)。在各种实施方案中可使用不同类型的复制技术,诸如擦除编码技术、完全复制或者完全复制和擦除编码复制的组合。在一些实施方案中,不同复制技术可用于不同文件存储区。
在至少一些实施方案中,多种不同存储装置可用于存储盘区复本,诸如一种或多种类型的SSD和/或基于旋转磁盘的单个或阵列式装置。在一些实施方案中,给定存储节点132可包括若干不同类型的存储装置,而在其他实施方案中,给定存储节点可仅具有单个类型的可用存储装置。在所描绘实施方案中,存储节点132A、132B和132C各自具有SSD装置(分别在三个节点处的装置532B、532L和532T)以及基于转盘的装置(分别是532A、532K和532S)。在一些实现方式中,只要空间可用,一个特定存储装置技术可优选用于存储数据盘区复本、元数据盘区复本或者用于存储两种类型的盘区。在一个实现方式中,例如,元数据盘区在可能时可存储在SSD上,而数据盘区可存储在较便宜的转盘上。在一些实施方案中,数据和/或元数据盘区或者其部分可例如基于使用水平从一种类型的存储装置迁移到另一种。
元数据高速缓存
图6示出根据至少一些实施方案的与在文件存储服务的访问子系统节点处的高速缓存元数据相关联的交互的实例。如前所述,在一些实施方案中,外部负载平衡器可被配置来在可用访问子系统节点间分布客户端工作负载。在图6描绘的实施方案中,在负载平衡器646处从客户端180接收服务请求644A(诸如指向文件的写入或读取)。负载平衡器646通过与用于初始服务请求644A的网络连接不同的网络连接将对应服务请求644B转发到所选择访问节点112。
访问节点112可维持关于各种文件存储对象的元数据对象的高速缓存器604。如果足以识别存储对应于所转发服务请求644B的适当组的页的存储子系统节点132的元数据恰好处于高速缓存器604中,那么访问节点可向存储节点发布读取/写入请求。然而,如果元数据未高速缓存,那么访问节点112可向所选元数据子系统节点122提交元数据请求650,如箭头693指示的。如前所述,在一些实施方案中,元数据内容可实际上存储在存储子系统节点处。元数据节点122(其可包括例如执行元数据管理节点的过程)可自身维持元数据的存储器内组612,包括另一高速缓存层。如果由访问节点请求的元数据不在存储器内组612中,那么元数据节点可从一个或多个存储节点132A获得含有元数据的页654(如箭头694指示的),并且将元数据存储在其存储器内组612中。在所描绘实施方案中,在一些情况下,来自客户端的请求644A可需要生成新的元数据(例如,如果请求是第一次写入到文件,那么元数据节点可为文件的第一逻辑块创建元数据条目),在这种情况下,元数据节点可确保新的元数据在响应请求650之前安全地存储在存储节点132处。
从存储节点132A获得的元数据的针对响应于客户端的请求需要的至少一部分(称为请求相关元数据652)可被提供给访问节点112,如箭头695指示的。访问节点可读取元数据,将其存储在高速缓存器604中,并且向由元数据识别的适当存储节点132提交读取或写入请求655,如由箭头696指示的。存储节点132B可提供对读取/写入请求的响应(图6中未示出),并且访问节点可在一些实施方案中对客户端180做出响应以指示所请求服务操作成功与否。访问节点112可能够使用高速缓存的元数据来对至少一些随后客户端请求做出响应,而不必从元数据子系统重新获得元数据。
在所描绘实施方案中,代替使用明显的高速缓存失效消息,基于超时的技术可用于管理访问节点处的元数据高速缓存条目的潜在陈旧性。因此,访问节点112可使用高速缓存超时设置608来确定何时将元数据的任何给定元素从高速缓存器604逐出。在一些实现方式中,给定元数据条目可在其超时608期满之后简单地从高速缓存器604移除,而不尝试重新高速缓存它直到在不同客户端请求需要它。在其他实现方式中,或者对于一些选择类型的元数据条目,访问节点112可在其高速缓存超时期满时从元数据节点122重新请求元数据条目,或者检验元数据条目是否保持有效。在后一种情境中,超时可在每次条目重新生效或刷新时重新设置到初始值。在所描绘实施方案中,在元数据节点122处,不同类型的超时设置可相对于元数据的给定逻辑块使用。当元数据节点122为某一文件存储对象初始生成元数据并且将元数据存储在元数据结构的给定逻辑块中时,元数据块重新分配不合格超时时段可开始,这指示在该元数据逻辑块可重新分配之前必须度过的最小时间量。(例如假如元数据存储在块中的对象被删除,那么这种元数据重新分配可最终发生)。块重新分配不合格超时设置614可通常被设置为比对应块元数据的高速缓存超时设置608长的时间段。例如,在一个实现方式中,块重新分配超时值可以是两周,而高速缓存超时设置可以是一天。在这种情境中,访问节点112可每天一次地重新检验元数据的给定块的有效性,而元数据节点122可确保在自块的初始分配以来已度过两周之前为了一些其他目的而不重新使用块。
在一些实施方案中,代替使用基于超时的机制,明确租用或锁定可用于在访问节点处高速缓存的元数据条目。在至少一个实施方案中,明确高速缓存无效机制可使用,其中例如元数据节点122可在元数据的某一元素不再有效时发出无效消息。在一个实施方案中,元数据子系统可响应于元数据改变而将元数据块标记为“无效”或“不可访问”。当访问节点尝试使用无效高速缓存的元数据来访问数据块时,指示元数据无效的错误消息可被元数据子系统或存储子系统返回到访问节点。因此,高速缓存的元数据可由于此类错误消息被隐含地宣告无效。基于超时、基于锁定/租用、基于暗含和明确无效策略的各种组合可在不同实施方案中用于在访问节点处高速缓存的元数据。
在图6中描绘的一些交互中,诸如由标记为693、694和696的箭头指示的那些,存储服务的一些部件可充当其他部件的客户端。例如,访问节点112可将内部请求(即,在存储服务内生成并且使用不可由存储服务的客户直接访问的网络路径的请求)发送到元数据节点(箭头693),充当元数据节点的客户端。类似地,元数据节点和访问节点都可将内部请求发送到存储节点132,充当存储节点的客户端。在一些实施方案中,各种子系统可实现可由存储服务的其他部件调用的内部API来实现此类交互。存储节点132可例如以相同方式来对特定的存储服务API从访问节点112调用还是从元数据节点122调用作出响应。因此,至少在一些实施方案中,存储服务节点可相对于它们乐意从其接收内部请求的资源是不可知的。
文件存储策略
在一些实施方案中,客户端可被授予基本灵活性来控制文件存储服务相对于特定文件存储区的行为的各种方面。例如,一个或多个管理API可实现来允许客户端设置或修改特定文件存储区的耐久性、性能、可用性或其他要求,所述要求可能不同于代表同一客户端或其他客户端创建的其他文件存储区的对应要求。图7示出根据至少一些实施方案的与针对文件存储区的数据耐久性、性能和逻辑到物理数据映射有关的策略的不同组合的使用的实例。
如列704和714所示,分别用于给定文件存储区诸如FS1的数据和元数据的耐久性策略可不同,并且在不同文件存储区诸如FS1和FS2使用的耐久性策略可对于整个数据、元数据或两者不同。对于FS1,10路完全复制用于元数据(元数据的每个页的10个完全副本被维持),而12/6擦除编码用于数据耐久性(每个数据页的12个擦除编码的副本被存储,其中6个需要重构页的内容)。对文件存储区FS1和FS2和元数据和数据的性能目标/要求分别以列706和716指示。性能目标可以各种单位表示,例如,等待时间或响应时间的单位(在列706和716中以标签“resp时间”指示)对比吞吐量的单位(以标签“tput”指示),并且在一些情况下,不同组的要求可指定用于读取(以列706和716中的标签R指示)不同于写入(以标签W指示)。性能目标可用于例如选择应当用于给定文件存储区的元数据或数据的存储装置类型。
在所描绘实施方案中,不同方法可用于针对各自文件存储区为存储对象分配存储空间。例如,如列708中指示的,512千字节的固定逻辑块大小和动态页分配的策略用于FS1元数据,而对于FS2元数据,一兆字节的逻辑块的物理存储可静态地分配。如列718中示出的,对于FS1数据,可使用变化逻辑块大小,其中给定文件的前几个逻辑块被设置为1千字节、1千字节、2千字节、2千字节等,其中逻辑块大小随着文件增长逐渐增加。相反,对于FS2数据,可使用固定大小4兆字节的逻辑块。用于元数据的物理页面大小可被设置为如下(列710):对于FS1是8千字节,并且对于FS2是16千字节。对于数据,如列720中示出的,页大小可被设置为等于FS1的逻辑块大小,而对于FS2,页大小可被设置为32千字节。列712中示出FS1和FS2的各自元数据高速缓存相关的设置,包括以上参考图6论述的元数据高速缓存超时和块重新分配不合格超时。在一些实施方案中,例如为了减小文件存储服务的实现复杂性,仅离散组的选项可支持耐久性策略、块和页面定大小策略等。在一些实施方案中,其他类型的策略诸如可用性相关或正常运行时间要求、文件存储空间限制等也可针对不同文件存储区不同地设置。在至少一个实施方案中,客户端可能够也基于每文件存储区从多个定价策略中选择,例如,一些客户端可选择基于存储空间使用的定价策略,而其他客户端可选择基于文件系统API计数的定价策略。
实现可缩放文件存储服务的方法
图8a是示出根据至少一些实施方案的可被执行来实现可缩放分布式文件系统存储服务的配置和管理相关操作的方面的流程图。如元素801中所示,可例如在服务初始化过程期间在分布式文件存储服务的N个不同存储子系统节点处为数据和/或元数据建立M个空盘区的初始组。在一些实施方案中,存储服务可建立来代表在提供商网络处建立的虚拟计算服务的计算实例上运行的客户端应用实现文件存储操作。在各种实施方案中,每个存储节点可包括多个盘区,例如,M可大于N。在盘区内容针对数据耐久性被复制的实施方案中,M个空盘区中的每一个可能够存储逻辑盘区的内容的各自复本。每个存储节点可包括一个或多个存储装置,包括例如某一数量的基于转盘的装置和/或固态存储装置。给定盘区可在一些实施方案中并入单个存储装置内,或者可在其他实施方案中遍布在多个存储装置中。在一个实施方案中,所有盘区可例如基于与存储服务相关联的可配置参数具有相同大小。在其他实施方案中,不同盘区可具有不同大小,和/或盘区的大小可随时间改变。存储服务的给定例示中的盘区的总数量可随时间变化,例如,在元数据和数据的大小变大时,可部署更多存储装置和/或更多盘区。盘区可表示关于一些实施方案中的存储服务的数据和元数据的恢复单元,例如,每个盘区可基于耐久性策略或设置使用擦除编码、完全复制或者复制技术的某一组合来复制。每个盘区复本组(即,一组同一逻辑数据或元数据盘区的复本)可包括指定为主复本的至少一个复本,所述主复本的存储节点(关于逻辑盘区还可称为主节点或领导者节点)负责协调组成员之间的更新。在一些实施方案中,关于复本组的主选择和/或成员身份的决定可被推迟直到写入文件存储区的第一对象。在至少一些实现方式中,盘区可以是多租户,例如每个盘区可存储多个不同客户端或客户的数据或元数据。
可最初建立某一数量的访问子系统节点来使能够访问所描绘实施方案中的至少特定文件存储区FS1(元素804)。例如,在文件存储客户端包括隔离虚拟网络(IVN)的计算实例的实施方案中,可仅从IVN内访问的私有IP地址可分配给P访问子系统节点。在一些实施方案中,公共IP地址也可或代替分配给访问子系统节点中的一些或全部。在一些实施方案中,可建立部分预配置的访问子系统节点的池,并且可从所述池将特定访问节点分配用于特定文件存储区;在其他实施方案中,可按需要实例化访问节点。在至少一个实施方案中,给定网络地址可分配给多于一个访问子系统节点。
在一些实施方案中,在文件存储区创建后,一组Q元数据节点可分配给文件存储区FS1。在其他实施方案中,例如,在接收到诸如文件或目录的FS1的对象的第一写入请求时,可按需要将元数据节点(还可从预配置的池中选择,或者可动态地实例化)分配给FS1(如以下关于图8b描述的)。在所描绘实施方案中,文件存储服务的管理部件可监视访问子系统、元数据子系统以及存储子系统的各个节点的性能和/或健康状态(元素807)。在所描绘实施方案中,可存储代表任何给定客户端执行的完成的或成功的文件存储操作的记录,并且此类记录可稍后用于为客户端生成基于使用的付款金额。响应于对观察的性能度量和/或健康状态改变的分析,可动态地添加节点或者将所述节点从子系统中的任一个移除,而不影响其他层的填充量,并且不影响传入文件存储请求的流(元素810)。例如,响应于访问子系统处的可能性能瓶颈的检测或者出故障或无反应的访问子系统节点的检测,可实例化更多访问子系统节点而不影响其他子系统节点中的任一个。在一些情况下,如果一个或多个节点处的资源利用(例如,CPU或存储利用)在一定时间段内保持低于阈值,那么此类节点可消除并且其工作负载可分布在其他节点之间。因此,子系统中的每一个可独立地按需要放大或缩小。
图8b是示出根据至少一些实施方案的可响应于可缩放分布式文件系统存储服务处的客户端请求而执行的操作的方面的流程图。响应于指向文件存储区FS1的文件的创建(例如,“打开的”API的调用)或第一写入请求,例如,可在一个或多个选择的元数据盘区和数据盘区处分配空间(元素851)。在所描绘实施方案中,元数据子系统可在存储子系统节点处存储元数据内容,例如,存储子系统的存储能力可重新用于元数据而不是针对元数据严格地实现单独存储层。在其他实施方案中,单独存储子系统可用于元数据而不是用于数据。在使用复制来实现期望数据耐久性的实施方案中,例如,针对适当盘区复本组的所有成员,可在多个元数据和/或数据盘区处分配空间。在不同实施方案中可基于各种因素选择特定盘区来分配一页或多页以对第一写入做出响应,例如,基于盘区当前有多满,基于盘区相对于正创建的对象的性能要求的性能特性,等等。在至少一些实施方案中,在选择盘区时还可考虑文件存储区的对象的当前“伸展”,例如,存储子系统可尝试通过避免在同一盘区或同一存储节点处存储给定文件存储区的数据或元数据的太多块来减小“热点”的概率。
在另外的写入指向FS1内的对象时,可例如基于可应用条带化策略(即,逻辑块到物理页面的映射策略)在其他存储子系统节点处为数据和/或元数据分配另外的空间,并且可按需要配置另外的元数据节点(元素854)。在至少一些实施方案中,三个子系统-存储子系统、访问子系统以及元数据子系统中的每一个的节点可被配置来支持多租户,例如,每个存储服务节点可同时处理来自若干不同客户端的存储请求或者存储所述若干不同客户端的数据/元数据。客户端可能不知道用于其存储请求的相同资源还用于来自其他客户端的请求。在一些实施方案中,每个存储服务节点可包括例如可使用提供商网络的主机或服务器执行的一个或多个过程或线程。
随时间推移,对应于给定文件存储对象诸如目录或文件的元数据可结束跨若干不同存储节点处的若干不同盘区的分布。一些文件存储操作(例如,重新命名操作或删除操作)可需要多于一个盘区处或者多于一个存储节点处的元数据的修改。响应于对这种操作的请求,存储服务可以支持或强制顺序一致性的方式执行包括多于一个元数据页或多于一个元数据盘区处的改变的原子更新操作(元素857)。在不同实施方案中可使用多个不同类型的一致性强制技术中的任一个,诸如分布式事务技术或者一致对象重新命名技术,以下更详细地描述所述两种技术。
图9是示出根据至少一些实施方案的可被执行来实现分布式文件系统存储服务处的基于复制的耐久性策略的操作的方面的流程图。如元素901所示,可例如在创建对象时确定将用于给定文件存储对象F1的数据和/或元数据的一组耐久性相关参数中的每一个的值。在一些实施方案中,参数可包括复本计数,例如,每页的复本并因此每个盘区的数量,所述盘区存储对象的内容或与对象相关的元数据的内容。在一些实施方案中,复制策略(例如,使用完全复制、使用擦除编码复制还是使用此类技术的某一组合)和/或复本在可用数据中心资源之间的放置也可指定为参数。例如,在存储服务包括多个可用性容器的一些实施方案中,至少一个复本可放置在K个可用性容器中的每一个内。可随后根据所述参数识别适当组的盘区复本(元素904)。在一些实施方案中,可基于对以下的分析或者基于其他度量选择特定物理盘区:在各个候选项处可用的自由空间量,在盘区或其包含的存储服务器处的最近工作负载水平,相对于客户端请求的预期资源的地点,如前所述的空间被分配用于的文件存储区的“伸展”。可将复本中的一个指定为主复本,并且可将其存储节点指定为负责协调各种操作诸如指向复本组的成员之间的文件存储对象的写入的领导者(元素907)。在至少一些实施方案中,选为用于协调到给定文件存储对象的数据写入的领导者的特定存储节点还可被选为用于协调针对那个文件存储对象的元数据写入的领导者(即使元数据中的至少一些可存储在与数据不同的存储节点处)。
响应于来自客户端的指向文件存储对象的逻辑块的特定写入请求,内部写入请求可指向逻辑块映射到的逻辑盘区的主盘区复本(元素910)。因此,例如,接收客户端请求的访问节点可首先必须例如使用从适当元数据子系统节点提取的元数据识别用于逻辑块的主盘区复本,并且随后将内部写入请求指向存储主复本的存储节点。响应于接收内部写入请求,领导者节点可发起基于共识的状态管理协议的交互来在复本组成员之间复制写入工作负载(元素913)。在至少一些实现方式中,基于共识的协议可用于复制状态改变的日志记录,并且状态自身的表示可使用擦除编码或者使用完全复制来进行复制。如果由于协议交互提交写入,例如,如果写入在定额的复本组成员处成功,那么在一些实施方案中,请求客户端可最终得到写入请求成功的通知。在其他实施方案中,至少针对一些类型的操作和一些文件系统协议,客户端可不一定被提供关于其请求是否成功的指示。相反,例如,客户端可预期重试看起来没有成功的操作。
图10是示出根据至少一些实施方案的可被执行来在分布式文件系统存储服务的访问子系统节点处高速缓存元数据的操作的方面的流程图。如元素1001所示,可配置允许客户端向分布式文件存储服务的一组访问子系统节点提交文件存储相关请求的服务端点地址。在一些实施方案中,如前所论述的,可为访问节点分配仅可在隔离虚拟网络内访问的私有IP地址。在其他实施方案中,还可使用或代替使用可由非IVN客户端访问的公共IP地址。访问子系统节点可被配置来对符合一个或多个行业标准文件系统协议的各种类型的命令、系统呼叫或API调用(例如,一个或多个版本的NFS、SMB、CIFS等)做出响应。在一些实施方案中,给定访问子系统节点可能够响应于根据多个此类标准或协议格式化的命令。在一个实施方案中,还可支持或代替支持专用文件系统接口。
可在特定访问节点AN1处接收根据API/协议中的一个格式化并且指向特定文件存储对象F1的命令(例如,创建、读取、写入、修改、重新配置或者删除命令)(元素1004)。AN1可例如基于网络身份(例如,源网络地址)、用户身份(例如,用户账户标识符)或者其他因素执行一组认证和/或授权操作(元素1007)以便决定是接收还是拒绝命令。
如果命令通过了认证/授权检查,那么AN1可识别元数据节点MN1,将用于实现所请求操作的关于F1的元数据将从所述MN1获得(元素1010)。访问节点AN1可随后向MN1提交元数据请求(元素1013)。在一些实施方案中,适当元数据节点的识别可自身涉及例如向管理存储对象与其他元数据节点之间的映射的元数据节点提交另一请求。可随后在AN1处获得关于文件存储对象F1的元数据的块。AN1可将元数据存储在本地元数据高速缓存器中(元素1016),具有指示何时元数据的块被丢弃(因为潜在陈旧)或者必须重新生效的高速缓存超时设置。在至少一些实施方案中,高速缓存超时间隔可被设置为小于在元数据节点处使用以便确定其何时可接受重新使用来为了其他目的再循环元数据的块(例如,在F1被删除的情况下存储不同文件存储对象F2的元数据)的元数据块重新分配超时设置的值。
AN1可使用所接收元数据块来识别内部读取/写入请求将指向的特定存储节点SN1,并因此提交内部请求(元素1019)。在高速缓存超时期满之前,AN1可重新使用元数据的高速缓存的块来发布可由API/协议的另外调用引起的另外内部请求(元素1022)。在一些实施方案中,在高速缓存超时时段结束时,可删除元数据的块或者将其标记为无效。在至少一个实施方案中,代替只是丢弃元数据,访问节点可例如通过向元数据从其获得的元数据节点发送另一请求来使所述元数据重新生效。
针对单页面更新的有条件的写入
如前面论述的,在至少一些实施方案中,文件存储服务可被设计来处理来自成百上千客户端的潜在指向几千文件存储对象的大数量的并行操作。确保原子性和一致性的传统基于锁定的机制可能不能在此类高吞吐量高并行性环境中工作,因为锁定系统自身可成为瓶颈。因此,如下所述,在至少一些实施方案中,一个或多个乐观方案可用于并行性控制。首先,描述了用于单页面写入(即,其修改限于单个逻辑盘区的单个页面的写入请求)的并行性控制机制,并且稍后描述可用于将多页面写入实现为原子操作的分布式事务机制。
在至少一些实现方式中,还如上所述,用于存储给定文件存储区的数据和元数据的物理页面的大小可不同于对应对象的逻辑块,而写入操作可通常指向任意偏移并且具有任意大小的写入有效负载。例如,针对至少一些文件系统协议/API,从文件的最终用户的角度来看,对文件的单次写入可修改在文件内以任何期望字节级偏移开始的数据,并且可修改(或者第一次写入)从该字节级偏移开始的任何数量的字节。然而,文件存储服务的存储子系统可在一些实施方案中把物理页面看作原子单位,例如,为降低实现复杂性,页面可表示由存储子系统的内部读取和写入API支持的最小粒度。因此,在暴露于最终用户的文件存储API的灵活性与由存储子系统支持的内部操作的约束之间可存在失配。因此,在此类实施方案中,存储子系统的客户端(例如,访问节点或元数据节点)可被迫来将任意写入请求转换成页面级别的内部写入操作。在至少一些实施方案中,可能不由外部客户端请求直接引起的至少一些内部元数据操作可在一些情况下需要仅修改元数据的给定页面的一小部分。此类元数据写入请求还可必须在页面粒度处实现。
因此,指向物理页面的至少一些写入操作可被实现为读取-修改-写入序列。图11示出根据至少一些实施方案的可在文件存储服务处实现的读取-修改-写入序列的实例,其中写入偏移和写入大小可能有时候不与原子单位物理存储装置的边界对齐。如图所示,文件存储对象(诸如文件或元数据结构)可被组织为一组逻辑块(LB)1102,包括LB 1102A、1102B和1102C。每个逻辑块可映射到存储子系统的盘区(例如,一个逻辑盘区和多个物理盘区复本)内的一组页面,其中页面表示关于存储子系统的API的原子单元。例如,在所描绘实施方案中,逻辑块1102A被映射到盘区1164的物理页面(PP)1112A、1112B、1112C和1112D。
响应于特定写入请求1160,实际上可仅必须改变单个页面的一部分(诸如在写入请求1160A情况下的PP 1112A的阴影部分,以及在写入请求1160B情况下的PP1102D的阴影部分)。然而,因为在所描绘实施方案中存储子系统API可不允许部分页面写入,所以示出的写入请求中的每一个可被转换成指向对应物理页面的读取-修改-写入序列。因此,客户端(例如,发布内部写入请求1160的访问节点或元数据节点)可确定,为了实现预期的部分写入,其必须读取目标页面、应用期望改变并且随后提交整个页面的写入。针对写入请求1160A,可实现读取-修改-写入序列RMW 1177A,包括页面1112A的读取、在客户端处的页面1112A内容的局部修改以及整个页面1112A的写入。针对写入请求1160B,可实现RMW 1177B,涉及页面1112D的读取,之后是修改以及随后整个页面1112D的写入。
给定向同一物理页面请求的并行或接近并行的更新的可能性,存储服务可必须确保给定物理页面的内容在RMW序列的读取与RMW序列的写入之间未修改。在至少一些实施方案中,可针对存储子系统处的复制状态管理实现的逻辑时间戳机制可用于确保如下所述的此类顺序一致性。
如前所述并且如图5所示,在至少一些实施方案中,逻辑盘区的复本组可用于实现期望的数据耐久性水平。图12示出根据至少一些实施方案的用于盘区复本组的基于共识的复制状态机的使用。针对逻辑盘区E1,在所描绘实施方案中示出四个盘区复本:存储节点132处的主复本1264A,以及各自存储节点132B、132C和132D处的非主复本1264B、1264C、1264D。针对不同的逻辑盘区E2,示出存储节点132D处的主盘区复本1265C以及两个非主复本1265A(在存储节点132A处)和1265B(在存储节点132B处)。基于共识的复制状态机1232A可由节点132A(存储主复本的节点)使用来协调E1复本上的各种操作,并且不同的基于共识的复制状态机1232B可由节点132D(主复本1265C驻留的节点)使用来协调E2复本上的操作。
在所描绘实施方案中,状态机1232A可利用逻辑块1222A,并且状态机1232B可利用不同的逻辑块1222B。在至少一些实施方案中,逻辑块可用于指示使用对应状态机管理的各种操作的相对排序,并且可不与挂钟时间或任何特定物理时钟直接相关。因此,例如,特定逻辑时钟值LC1可与使用状态机1232A协调的写入操作的提交相关联,并且不同逻辑时钟值LC2可指示何时从复本组提供对读取操作的响应。如果在这个实例中LC1<LC2,那么这将指示从存储子系统的角度来看,写入操作在读取操作之前完成。逻辑时钟的值在本文还可称为“逻辑时间戳”或“操作序列号”(因为它们可指示使用相关联复制状态机完成的各种读取或写入操作的序列)。在一些实现方式中,在主复本驻留的存储节点处实现的整数计数器可用作逻辑时钟,并且所述存储节点可负责时钟的值的改变(例如,每当使用状态机完成读取或写入操作时计数器可递增)。
在各种实施方案中,存储节点可将从状态机1232获得的逻辑时间戳值与以上描述的RMW序列的读取和写入请求相关联,并且可使用逻辑时间戳来决定是提交还是中止特定单页面写入。图13示出根据至少一些实施方案的可用于一些类型的写入操作的有条件写入协议中涉及的示例性交互。如图所示,作为对应于特定写入操作的读取-修改-写入序列的一部分,存储子系统的客户端1310(诸如,访问节点或元数据节点)可向存储节点132(例如,存储页面所属的盘区的主复本的节点)提交读取页面请求1351。存储节点可提供包括所请求页面的内容以及分配给读取操作的读取逻辑时间戳(RLT)的读取响应1352。RLT可例如从用于盘区的复制状态机获得。
继续RMW序列,存储子系统客户端310可向存储节点132顺序地提交整个页面的写入请求1361,并且可包括在读取响应中包括的RLT。存储节点可确定页面自RLT被生成以来是否已成功更新。如果页面自RLT被生成以来未更新,那么所请求写入可完成并且指示成功的写入响应1362可提供给存储子系统客户端。如果页面自RLT以来由于另一干涉写入请求而更新,那么可拒绝写入请求。接受这种写入请求可能在一些情况下导致数据不一致性,因为例如,将响应于给定写入请求写入的特定数据D1可取决于先前从页面读取的值R1,并且所述值R1可能由干涉写入改写。在一些实现方式中,如果来自客户端1310的写入请求被拒绝,那么指示写入中止的写入响应1362可提供给客户端;在其他实现方式中,没有写入响应可提供。如果写入中止,那么客户端1310可在一些实施方案中针对同一页面发起一个或多个另外RMW序列,例如直到写入最终成功或者直到写入尝试的某一阈值数量失效。
为了检测对同一页面的干涉写入自RLT被生成以来是否成功,在一些实施方案中,可在存储节点132处实现存储写入逻辑时间戳的写入日志缓冲器。图14示出根据至少一些实施方案的可被建立来实现有条件写入协议的示例性写入日志缓冲器。在所描绘实施方案中,例如在存储盘区的主复本的存储节点处针对每个逻辑盘区维持各自的环形写入日志缓冲器1450。环形缓冲器1450A由管理E1的主复本1410A的存储节点1432A维持用于盘区E,并且环形缓冲器1450B由存储E2的主复本1410B的存储节点1432B维持。每个环形缓冲器包括多个写入日志记录1460,诸如缓冲器1450A中的记录1460A、1460B、1460C和1460D以及缓冲器1450B中的记录1460K、1460L、1460M和1460N。在所描绘实施方案中,每个日志条目1460包括提交的(即,成功)页面写入的各自指示,指示被写入的页面标识符、与写入的完成相关联的逻辑时间戳以及代表其执行写入的客户端。因此,在缓冲器1450A中,记录1460A-1460D指示具有标识符1415A-1415D的页面代表具有各自标识符1419A-1419D的客户端以由各自写入逻辑时间戳1417A-1417D指示的次序被分别写入。类似地,缓冲器1450B指示具有标识符1415K-1415N的页面代表具有各自标识符1419K-1419N的客户端以由各自写入逻辑时间戳1417K-1417N指示的次序被分别写入。在至少一些实施方案中,写入日志缓冲器可维持在主存储器中以便快速访问。在至少一个实现方式中,给定记录1460的写入逻辑时间戳可由所述记录在缓冲器内的相对位置隐含地指示。因此,在这种实现方式中,写入逻辑时间戳的明确值不需要存储在缓冲器中。在一些实施方案中,逻辑缓冲器可存储在持久性存储器中,并且可具有通过时间戳值、通过页面标识符和/或通过客户端标识符针对速度检索建立的索引。在各种实施方案中,类似于图14中示出的写入逻辑时间戳信息可维持在不同粒度处,例如,在物理页面粒度处、在盘区粒度处或者在某一其他级别处。
当存储节点1432必须确定是接受还是拒绝读取-修改-写入序列的特定写入,并且写入请求包括所述序列的读取操作的读取逻辑时间戳(RLT)时,其可检查写入日志缓冲器来查看具有比RLT大的逻辑时间戳的任何写入是否已针对同一页面发生。例如,如果对应于用于页面P1的RMW序列的写入请求的RLT值是V1,记录1460之间的最小写入逻辑时间戳是V2<V1,并且在具有值V3>V1的缓冲器中没有记录,那么存储节点1432可得出没有发生对页面P1的干涉写入并且可接受RMW的写入。在所描绘实施方案中,如果对于页面P1存在具有写入逻辑时间戳V3>V1的条目,那么可拒绝或者中止写入。如果环形缓冲器1450中的记录之间的最小写入逻辑时间戳V2大于V1,那么这可指示指向P1的一些写入可自RLT被生成以来已成功但可能已经改写其写入日志记录(例如,由于缓冲器空间限制),因此至少在一些实施方案中,在这种情境中还可拒绝针对P1的写入请求。如果RMW的写入请求被接受,那么新的写入日志记录1460可添加到具有对应于写入的提交的写入逻辑时间戳的环形写入日志缓冲器(潜在地改写先前生成的日志记录)。(应注意,取决于必须更新的复本的数量和使用的复制协议,在修改传播到足够的复本以成功完成或提交写入之前可需要花费一些时间。
在所描绘实施方案中,可使用环形缓冲器,使得用于缓冲器的存储器的总量保持很低,并且旧的写入日志记录逐渐地由更有用的最近写入日志记录改写。因为特定读取-修改-写入序列的写入操作通常预期在读取之后相当快地执行,所以较旧的写入日志记录可通常不太帮助决定是提交还是中止RMW序列的写入。然而,如以上所论述的,在一些情境中,情况可能是对盘区的写入如此频繁使得潜在有用的写入日志记录可在环形缓冲器中得以改写。在一些实施方案中,存储服务可记录由于此类改写被拒绝的写入的数量,即,可监视具体地由读取逻辑时间戳与缓冲器的最早逻辑时间戳的比较(以及读取逻辑时间戳在最早逻辑时间戳之前的随后确定)导致的写入拒绝率。在一些此类实施方案中,环形日志缓冲器的大小可动态地修改,例如,其可响应于确定由缓冲器空间约束引起的写入拒绝率已超过某一阈值而增加,或者其可简单地在重工作负载时段期间增加。类似地,缓冲器大小可在轻工作负载时段期间或者响应于确定可归因于缓冲器大小约束的拒绝率低于某一阈值来减小。在一些实施方案中,可使用其他类型的缓冲器(即,不是环形的缓冲器)。在至少一个实施方案中,客户端标识符可不存储在写入日志缓冲器中。在一些实施方案中,可使用类似于图14中示出的缓冲器来记录读取以及写入。在至少一个实施方案中,缓冲器的长度可基于出色的读取-修改-写入序列的读取的时序动态地调整。例如,如果特定RMW序列的读取在时间T1处发生,并且缓冲器在接收所述序列的对应写入请求之前的某一时间T2处变满,那么缓冲器大小可增加(例如,在某一最大长度阈值和/或某一最大时间阈值内)以尝试做出关于接受对应写入的正确决定。在一些此类情境中,当在时间T3处接收对应写入时,缓冲器大小可再次减小到其先前长度。
在至少一个实施方案中,存储服务可在每页级别维持版本信息,并且使用所述版本信息来决定是否应接受RMW的写入。例如,代替在每盘区级别维持写入操作的日志缓冲器,在一个这种版本化方法中,可在每页级别处维持日志条目,使得可能确定RMW的写入是否指向与对应读取相同的版本。如果自读取以来已创建新的版本,那么可拒接写入。
图15是示出根据至少一些实施方案的可被执行来在分布式文件系统存储服务处实现有条件写入协议的操作的方面的流程图。如元素1501所示,可在存储子系统的客户端C(诸如访问节点或元数据节点)处做出确定:为了实现特定文件存储操作,将实现特定页面P上的读取-修改-写入序列。在一些实施方案中,即使整个页面被修改,所有单页面写入也可在默认情况下转换成读取-修改-写入操作;因此,在此类实施方案中,对任何页面的任何写入可转换成RMW序列,并且可能需要关于是否需要RMW的确定。在其他实施方案中,修改整页的写入可不需要转换成RMW序列,而仅修改一部分页面的写入可转换成RMW序列。
如元素1504所示,作为RMW序列的部分,可在存储节点SN1(例如,存储P所属的盘区的主复本的节点)处从C接收指向P的读取请求。可例如从用于管理P的盘区的复制状态机获得对应于读取请求的读取逻辑时间戳RLT,所述RLT指示读取相对于同一盘区处的其他读取和写入执行的次序(元素1507)。可将RLT提供给提交读取请求的客户端C。
随后,可在SN1处从C接收指向页面P的RMW序列的写入请求WR1(元素1510)。写入请求可包括在元素1507的读取响应中提供给C的RLT值,以及写入有效负载(即,将应用到P的修改)。存储节点SN1可例如通过检查存储与最近成功写入相关联的逻辑时间戳的写入日志缓冲器的内容来确定页面P自RLT被生成以来是否已修改。如果确定P自RLT被生成以来未被修改(元素1513),那么可通过对P进行适当修改并且将所述修改传播到适当数量的复本来实现写入(元素1516)。在所描绘实施方案中,可将对应于写入的完成的写入逻辑时间戳存储在写入日志缓冲器中,并且至少在一些实施方案中,可将写入完成的指示发送到发布RMW序列的客户端。在一些实现方式中,写入逻辑时间戳可提供给客户端作为完成指示的部分。如果确定P自RLT被生成以来已被修改(也在对应于元素1513的操作中),那么可拒绝写入并且在一些实施方案中可向客户端发送“写入中止”的响应。
使用有序的节点链的分布式事务
在各种实施方案中,上述有条件写入技术可用于确保单页面写入操作之间的顺序一致性。然而,针对分布式文件存储服务的一些类型的操作(诸如删除、重新命名等),可必须原子地修改元数据和/或数据的多个页面,即,必须提交涉及的所有页面的所有改变或者必须拒绝所有改变。在至少一些实施方案中,可为此目的采用涉及分布式事务的更高水平的乐观一致性强制机制。为了在这种实施方案中实现分布式事务,可选择协调器节点(例如,所涉及的元数据和/或存储节点中的一个)。协调器可识别将参与改变的存储节点,确定将针对各自存储节点处的接受或拒绝检查单独页面级别改变的序列,并且随后在存储节点之间发起有序序列的操作,其中节点中的每一个可为其页面级别的改变做出各自的提交/中止决定。如果所有参与者决定其局部改变是可提交的,那么事务可作为整体提交,而如果参与者中的任何一个确定不能提交其局部页面级别的改变,那么事务可作为整体中止。以下提供关于协调器和参与者节点的操作的各个方面的细节。
图16示出根据至少一些实施方案的可导致文件存储服务处的分布式事务的提交的示例性消息流。可例如在访问子系统节点或元数据节点处做出特定文件存储操作需要多个页面被写入的确定。可生成对应的多页面写入请求1610。在本文中将被修改的页面组可被称为事务的“目标页面”。存储服务的特定节点(其在各种实施方案中可以是访问节点、元数据节点或存储节点)可被选为用于分布式事务的协调器节点1612来原子性地实现对目标页面的所述组的写入。协调器可识别将被修改的页面组,以及将在其处发起或执行页面级别的改变的存储节点组(在协调器是存储节点的情况下可包括自身)(例如,存储包含目标页面的主复本盘区的存储节点组)。可使用多种技术中的任一种来选择协调器节点,例如,在一些实施方案中,将被修改的页面组中的随机选择的页面驻留的存储节点可被选为协调器,而在其他实施方案中,可考虑候选协调器节点处的工作负载水平,并且可尝试在服务的存储节点之间分布与事务协调相关联的工作。
在至少一些实施方案中,可由协调器1612根据死锁避免技术来确定修改所针对的页面应被锁定的序列。例如,死锁分析模块可提供有在事务中将被修改的页面和盘区的标识符,并且死锁分析模块可基于某一所选择排序次序(例如,基于盘区ID、页面ID的串联和/或其他因素的字典式排序次序)对标识符排序以便确定锁定次序。可跨文件存储区的所有分布式事务一致地使用相同排序次序,并因此,可总是以相同次序请求针对任何一对给定页面P1和P2的锁。例如,如果死锁分析模块指示针对事务Tx1,P1上的锁应在P2上的锁之前获取,那么它将绝不会指示针对任何其他事务Tx2,P2上的锁应在P1上的锁之前获取,因此避免死锁。
在至少一些实施方案中,作为分布式事务的初步阶段的部分,所选择协调器节点1612还可根据先前描述的技术发布指向目标页面的读取请求,并且获得那些读取的对应读取逻辑时间戳(RLT)。如下所述,读取逻辑时间戳可用于在目标页面驻留的存储节点中的每一个处做出页面级别的提交决定。
所选择协调器节点1612可随后编写事务准备(Tx-准备)消息1642A,所述消息1642A包括:将针对各自页面级别提交决定分析目标页面的次序的指示;包括负责以那个次序做出页面级别提交决定的存储节点的节点链;对页面(将被写入的字节)进行的实际改变,以及目标页面中的每一个的RLT。图16中通过实例示出节点链1602。节点链的最后或终端成员(例如,节点链1602中的节点1632C)可被指定为“提交决定者”或“决定者”节点,这是因为它自己的局部页面级别提交决定可导致事务作为整体的提交。
协调器可将Tx-准备消息1642A传输到节点链的第一节点,诸如节点链1602的存储节点1632A,所述第一节点存储目标页面中的至少一个(图16中的逻辑盘区E1的页面P1)。节点1632A可例如使用页面P1的RLT执行局部页面级别提交分析以便决定是否可提交P1的改变。使用类似于先前关于有条件写入和RMW序列描述的技术的技术,如果P1自其RLT被获得以来未被修改,那么对P1的改变可被认为是可提交的。如果P1自RLT被获得以来已被修改,那么可能必须拒绝改变(图17中示出并且以下描述拒绝情境;图16示出所有页面级别提交决定都是肯定的情境)。假设所提议的对P1的改变是可提交的,节点1632A可锁定P1(例如,获取由用于盘区E1的复制状态机管理的锁)并且将“意图记录”存储在持久性存储装置中。在所描绘实施方案中,只要页面P1被锁定,就不能代表任何其他事务处理或者任何其他RMW序列对P1执行任何读取或更新。意图记录可指示节点1632A意图对P1执行所提议的修改,并且将在剩余链成员也能同意执行其各自页面级别修改的情况下进行修改。节点1632A可随后将Tx-准备消息1642B(其内容可与1642A的内容类似或相同)传输到节点链的下一个节点1632B。
可关于逻辑盘区E5的页面P7在节点1632B处执行类似的局部页面级别提交分析。如果节点1632B确定其局部页面级别改变是可提交的(例如,使用包括在Tx-准备消息1642B中的P7的RLT),那么节点1632B可获取P7上的锁、存储其自己的意图记录并且将Tx-准备消息1642C(与1642B类似或相同)传输到决定者节点1632C。
决定节点1632C(链中的终端或最后节点)可关于盘区E8的页面P9执行其自己的页面级别提交分析。如果对页面P8的所提议修改是可提交的(例如,如果自P8的RLT被协调器获得以来没有对P8执行写入),那么决定者可确定事务作为整体将提交,并且可执行或发起对P8的所提议改变。决定者节点可生成指示分布式事务将提交的Tx-提交消息1644A,并且将所述消息1644A传输到链的其他节点。在所描绘实施方案中,Tx-提交可以相对于Tx-准备消息的传播相反的次序顺序地传播。在其他实施方案中,Tx-提交可并行地发送到非决定者节点和/或协调器中的一些或全部,或者可以不同于图16中示出的顺序次序发送。
当链1602的非决定者节点接收Tx-提交消息时,其可执行或发起其局部页面级别修改,释放局部目标页面(例如,节点1632B情况下的P7和节点1632A情况下的P1)上的锁,删除其先前针对页面生成的意图记录,并且(如果需要的话)将Tx-提交消息传输到另一节点(例如,节点1632B可将Tx-提交消息1644B发送到节点1632A,并且节点1632A可将Tx-提交消息1644C发送回到协调器)。当协调器节点1612接收Tx-提交消息时,在一些实施方案中,其可将写入成功响应1650传输到多页面写入1610的请求者。以上描述的用于进行以下各项的技术可全部帮助提高对分布式存储服务中的多个写入要求原子性的操作的效率和可恢复性:以确定来避免死锁的预定次序执行局部页面级别提交分析;仅在Tx-准备消息被接收并且局部提交分析成功时锁定页面;以及将意图记录存储在持久性存储装置中(例如,在负责意图记录的存储节点由于可能在事务完成之前发生的故障被替换的情况下,所述意图记录可从所述持久性存储装置访问)。
在至少一些实施方案中,针对给定分布式事务识别的节点链的存储节点中的任何一个可基于其局部提交分析来决定针对其局部页面的所提议修改是不可接受的,并且可因此发起事务作为整体的中止。图17示出根据至少一些实施方案的可导致文件存储服务处的分布式事务的中止的示例性消息流。如在图16的情况中,节点1612可被选为响应于多页面写入请求1610而尝试的分布式事务的协调器。协调器可执行类似于图16的上下文中描述的事务的初步操作组,诸如确定做出局部页面级别提交决定和获取锁的次序,生成节点链1602以及创建Tx-准备消息1642A。Tx-准备消息可由协调器1612发送到链的第一节点1632A。
节点1632A可执行其局部提交分析,并且决定对盘区E1的页面P1的所提议改变是可接受的。如在图16中示出的情境中,节点1632A可获取P1上的锁、将意图记录存储在持久性存储装置中并且将Tx-准备消息1642B传输到链1602的下一个节点1632B。在图17中示出的情境中,节点1632B可决定对盘区E5的页面P7的所提议改变是不可接受的,例如,这是因为P7自其RLT被协调器1612获得以来已被成功修改。因此,代替存储指示将愿意对P7执行所提议修改的意图记录,节点1632B可相反生成Tx-中止消息1744A,指示事务应中止。在所描绘实施方案中,Tx-中止消息1744A可发送到Tx-准备消息1642B从其接收的节点,但在其他实施方案中,它可并行地发动到在成功局部提交分析之后已存储意图记录的其他节点链成员。在接收Tx-中止消息1744A之后,节点1632A可删除其意图记录、释放页面P1上的锁并且将Tx-提交消息1644C传输回到协调器1612。在一些实施方案中,协调器1612可进而向多页面写入的请求者发送写入失败响应1750。在至少一些实施方案中并且取决于使用的API的语义,写入失败响应1750或写入成功响应1650都不可能在至少一些实施方案中传输,相反,请求实体可使用其他命令(例如,目录列表命令可用于确定删除还是重新命名成功)确定其请求是否成功。应注意,节点链中并非所有节点可参与得以中止的事务中,例如,图17中的决定者节点1632C可甚至不知道其将参与到分布式事务中。因此,中止可能最终不会浪费若干链成员处的任何资源,这可有助于与一些其他技术相比减小与分布式事务相关联的处理的总量。
如上所述,在一些实施方案中,针对事务识别的节点链的参与存储节点中的一个可自身被选为事务的协调器。在至少一些实施方案中,协调器不需要是链的第一节点,协调器也可能不需要是决定者节点。图18示出根据至少一些实施方案的包括被指定为事务协调器的节点的分布式事务参与者节点链1804的实例。如图所示,节点链1804包括存储节点1632A、1632B、1632K和1632C,其中1632A被指定为链的第一节点并且1632C被指定为链中的终端和决定者节点。事务的将被修改的目标页面包括:节点1632A处的盘区E1的页面P1,节点1632B处的盘区E5的页面P7,节点1632K处的盘区E6的页面P4,以及节点1632C处的盘区E8的页面P9。(尽管图16、图17和图18中的实例全都仅示出在每个链成员处被修改的单页面,但通常在各种实施方案中在每个链成员处可修改任何数量的页面。)节点1632K也被指定为事务协调器。
因此,在其作为事务协调器的角色中,节点1632K可将Tx-准备消息1801发送到链的第一节点1632A。如图16中示出的情境,Tx-准备消息可沿着节点链顺序地传播,例如,Tx-准备1802可从节点1632A发送到节点1632B,Tx-准备1803可从节点1632B发送到1632K,并且Tx-准备1804可从节点1632K发送到决定者节点1632C,假设中间节点中的每一个处的各自局部页面级别提交决定是积极的。
决定者节点1632C可发起相反序列的Tx-提交消息的传播,例如,Tx-提交消息1851可从节点1632C发送到节点1632K,Tx-提交消息1852可从节点1632K发送到节点1632B,并且Tx-提交消息1853可从节点1632B发送到1632B。为了完成事务,在所描绘实施方案中,节点1632A可将最终Tx-提交消息1804发送到协调器节点1632K。在至少一些实施方案中,将节点链的参与者节点动态地选择为协调器可帮助比静态地选择协调器的情况下可能的在存储子系统节点之间更平均地分布协调工作负载(例如,在Tx-准备消息所需要的信息被收集并分析期间事务的初步阶段相关的工作负载)。
在至少一些实施方案中,节点链成员中的每一个可甚至在事务之后局部地存储事务状态记录一段时间,如以下参考图19论述的。状态信息可例如用在恢复操作期间,在参与者节点中的一个在事务完成(提交或中止)之前出故障的情况下可能需要所述信息。随时间推移,这种事务状态信息可用光越来越多的存储器和/或存储空间。因此,在图18中描绘的实施方案中,为了空出致力于更旧事务的状态信息的存储器和/或存储装置,在给定事务提交或中止之后的某一点,协调器节点1632K可将Tx-清除消息1871、1872和1873传输到链1804的节点。Tx-清除消息可指示其状态记录应从存储节点删除的事务的标识符。因此,在至少一些实施方案中,存储节点可在接收Tx-清除消息之后移除指定的事务状态记录。在各种实施方案中,Tx-清除消息可并行地从协调器发送到存储节点链成员(如图18中建议的)或者可顺序地传播。在一些实施方案中,协调器可决定在自事务提交或中止以来已流逝了可调谐或可配置时间段之后传输给定事务的Tx-清除消息,并且时间段可基于各种因素调整,诸如各个存储节点处的由旧事务记录用光的存储/存储器空间的量的测量。尽管协调器节点恰好是图18中的节点链1804的成员,但Tx-清除消息可由协调器节点发送,而不管协调器是否是节点链的成员。在一些实施方案中,单个Tx-清除消息可包括其记录应被清除的若干不同事务的指示。在至少一个实施方案中,代替如图18所示的发送Tx-清除消息的协调器,链的某一其他所选择成员可负责传输Tx-清除消息。例如,在一个这种实施方案中,Tx-清除消息可由第一成员(例如,图18中的节点1632A)发送。
在任何分布式计算环境中,尤其是在使用几千商业计算和/或存储装置的大型提供商网络中,在设计实现的服务时必须处理部件的某一子集处的硬件和/或软件故障的可能性。图19示出根据至少一些实施方案的可被执行来在节点链的节点中的一个处发生故障时促进分布式事务完成的示例性操作。示出存储同一逻辑盘区E1的各自复本1902A、1902B和1902C的三个存储节点存储1932A、1932B和1932C。最初,复本1902A被指定为主复本,而1902B和1902C被指定为非主复本。
针对任何给定分布式事务生成的存储节点链可通常包括存储所述事务所涉及的盘区的主复本的存储节点。此类存储节点还可被称为关于其主复本存储在那儿的那些盘区的“主节点”或“领导者节点”。在给定节点链成员处对物理页面进行的改变可在来自主节点的其他复本之间传播。因此,在至少一些实施方案中,先前论述的消息(例如,Tx-准备、Tx-提交和Tx-中止)可通常针对事务中所涉及的盘区发送到主节点。
在所描绘实施方案中,主节点1932A可将意图记录1915、页面锁1910以及事务状态记录1905存储在持久性共享储存库1980处,所述持久性共享储存库1980还可由存储E1的复本组的成员的其他存储节点访问。在至少一些实施方案中,参与分布式事务消息流的每个节点链成员(诸如,图16的节点1632A、1632B和1632C,以及图17的节点1632A和1632B)可存储事务记录1905,所述事务记录1905指示其在Tx-准备、Tx-提交或Tx-中止消息从节点链成员发送时分布式事务的状态的局部视图。例如,如果局部页面修改的提交分析指示修改是可接受的,并且修改局部页面的意图记录被存储,那么从节点链成员的角度看事务状态记录指示(由协调器选择的唯一标识符识别并且包括在Tx-准备消息中)事务处于准备状态。当决定者节点确定事务作为整体将提交,它可保存具有被设置为提交的状态的事务记录。在所描绘实施方案中,当非决定者节点接收Tx-提交消息时,事务的状态(其先前为准备)可变为提交。当链中的任何节点决定中止事务时,具有设置为中止状态的事务状态记录可存储在储存库1980中。当任何节点链成员接收Tx-中止消息时,可修改事务状态记录来将状态设置为中止。如以上在关于Tx-清除消息的论述中提及的,在至少一些实施方案中,在从给定存储节点的角度看来与事务相关联的消息接发已完成之后,事务状态记录1905可保持在那个节点处持续一定时间段。这可在不同实施方案中为了各种目的进行,例如,为了帮助从由丢失的消息引起的故障情境中恢复,为了调试,为了审计目的等等。当针对给定事务接收Tx-清除消息时,在一些实施方案中可删除或存档事务状态记录。
可使用持久性状态储存库1980,使得如果主节点在事务完成之前出故障(例如,在主项负责针对给定事务发送的所有Tx-准备、Tx-提交、Tx-中止或消息在其预定接收者处被成功接收之前),则故障转移节点可接管事务相关操作。例如,如由标记为“1”的箭头指示的,主节点1932A(相对于盘区E1)可在时间T1处将其接收Tx-准备消息所针对的给定事务Tx1的事务状态记录1905、页面锁1910的指示以及意图记录1915写入储存库1980中。在对应Tx-提交或Tx-中止消息被接收之前,节点1932可出故障,如“X”和标记为“2”的文本指示的。根据复制状态管理协议,节点1932B可例如通过将复本1902B指定为新的主项来被选为相对于盘区E1的新的主节点(如由标记“3”指示的)。在一些实施方案中,可使用基于共识的策略来选择新的主项。(在节点1932A出故障之前)将Tx-提交或Tx-中止传输到节点1932A的节点链成员可反而发现相对于盘区E1的主项角色已转移到节点1932B,并且可因此反而将Tx-提交或Tx-中止传输到节点1932B。因为意图记录、锁以及事务状态记录都存储在持久性储存库1980中,节点1932B可能够从储存库1980读取Tx1所需的事务信息并且容易地执行否则将由节点1932A执行的事务相关任务。在至少一些实施方案中,持久性储存库1980可被实现为用于在复本之间传播改变、将逻辑时间戳与读取和写入相关联等等的复制状态管理系统的部件。
图20是示出根据至少一些实施方案的可被执行来协调文件系统存储服务处的分布式事务的操作的方面的流程图。如元素2001中指示的,可例如在元数据节点处从访问节点或者从另一元数据节点接收涉及修改的文件存储操作请求。对请求的分析可揭示例如不同盘区和/或不同存储节点处的多个页面(包含元数据、数据或两者)是否需要履行请求。如果仅单个页面将修改(如元素2004中检测的),那么可发起类似于先前描述的读取-修改-写入序列(元素2007)。
如果多个页面需要被修改或被写入(也如元素2004中检测的),那么可通过选择识别协调器节点来开始分布式事务(元素2010)。在不同实施方案中可使用多种技术来选择协调器。在至少一个实施方案中,可选择事务中涉及的参与者中的一个,例如,存储目标页面中的一个的主复本的存储节点,或者负责生成并管理受到事务影响的元数据的元数据节点中的一个。在一些实施方案中,可预先将一组存储子系统、元数据子系统或访问子系统节点指定为协调器候选者,并且可选择来自候选者之间的特定节点。
协调器可收集完成事务需要的信息的各种元素(元素2013)。在所描绘实施方案中,此类信息可包括例如将修改的所有页面的列表,并且可生成对应写入有效负载(将被写入的字节的内容)的列表。协调器还可例如使用死锁避免机制来确定页面级别提交分析应针对事务执行的次序(并因此锁应被获取的次序)。在一些实施方案中,例如,使用死锁避免机制可包括使用应用到所有分布式事务的一致排序方法来对目标页面的标识符进行排序,使得在任何两个页面上获得锁的次序不会从一个事务到另一个发生改变。在所描绘实施方案中,协调器可例如通过针对其页面被定向的所有盘区识别(当前)主存储节点并且将它们按提交分析应被执行的次序进行布置来为事务构造存储节点链。在至少一个实施方案中,协调器还可负责生成唯一的事务标识符(例如,通用唯一标识符或并入有随机生成的字符串的UUID)。在诸如关于上述有条件写入技术论述的读取逻辑时间戳(RLT)或操作序列号可用于I/O操作的一些实施方案中,协调器还可读取所有目标页面并且确定与读取相关联的RLT(元素2016)。协调器可随后构造指示节点链、写入有效负载以及RLT的Tx-准备消息,并且将所述Tx-准备消息传输到链的第一节点(元素2019)。
至少在一些实施方案中,协调器可随后开始设置为在所选择超时时段之后期满的定时器,并且等待对其Tx-准备消息的响应。如果在超时时段内没有接收响应(如元素2023中检测的),那么在一些实施方案中,可向请求元素2001的文件存储操作的客户端提供指示操作的结果是未知的响应(元素2035)。在至少一个实施方案中,可例如通过将另一Tx-准备消息发送到链的第一节点(如果那个节点仍可访问)或者那个第一节点的替换节点(如果可发现或配置的一个)来发起事务状态恢复操作。
如果在超时时段内在协调器处接收Tx-提交消息(如元素2026中确定的),那么这可指示已成功执行事务的所有单独页面修改。因此,在一些实施方案中,协调器可向请求操作的客户端发送所请求操作已成功的指示(元素2029)。在至少一个实施方案中,可例如相对于Tx-提交的接收异步地将Tx-清除消息发送到链节点,使得可释放在节点链成员处保持提交事务的事务状态的任何资源。如先前论述的,可由协调器或者由某一其他选择的链成员诸如链的第一成员发送Tx-清除消息。
如果在协调器处接收Tx-中止消息(也如元素2026中检测的),那么协调器可在一些实施方案中任选地向客户端发送所请求操作失败的指示(元素2032)。在一些实施方案中,还可由协调器或者链的某一其他成员将Tx-清除消息发送到参与所中止事务的那些链成员。在一些实现方式中,由于事务可由链成员中的任一个中止,仅成员的子集可在中止发生之前已存储事务状态记录,并且因此仅链成员的子集可被发送Tx-清除消息。在其他实现方式中,Tx-清除消息可简单地发送到链的所有节点,并且未存储在Tx-清除消息中识别的事务的任何事务状态的那些节点可忽略Tx-清除消息。
图21是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务准备(Tx-准备)消息而执行的操作的方面的流程图。由协调器构造的节点链的成员CM(例如,存储其页面将作为事务部分被修改的盘区中的一个的主复本的节点)可从某一其他节点(例如,通常从协调器或者从链的某一非决定者成员)接收Tx-准备消息(元素2101)。Tx-准备消息可在针对事务的一列提议页面修改中指示对其母盘区的主复本存储在CM处的页面P的一个或多个提议页面级别修改。CM可例如通过以下方式确定从其角度来看改变是否可接受/可提交:在写入日志缓冲器(类似于图14中示出的缓冲器)中检查页面P自在Tx-准备消息中指示用于P的读取逻辑时间戳被获得以来是否已修改。在一些情况下,可在Tx-准备消息中指示对存储在CM处的同一页面或者不同页面的多页面级别修改,并且可针对可接受性检查所有此类改变。
如果局部页面级别修改是可提交的(如元素2107中确定的),那么可取决于CM是否是决定者(节点链的最后成员)来采取不同行动。在所描绘实施方案中,如果CM是决定者(如元素2110中检测的),那么可发起对一个或多个局部页面的修改,并且可将指示事务处于提交状态的事务记录存储在持久性存储装置中(元素2113)。决定者节点可随后发起将Tx-提交消息传播到节点链的其他成员(元素2116)。在一些实施方案中,Tx-提交消息可例如按相对于Tx-准备消息针对同一事务传输的顺序次序的相反次序顺序地传播。在其他实施方案中,Tx-提交消息可并行地发送。
如果局部页面级别修改是可提交的并且CM不是决定者节点(也如元素2107和2110中确定的),那么在所描绘实施方案中,CM可(a)存储意图记录(指示如果剩余的节点链成员也发现其局部改变是可提交的,则CM意图执行其局部修改),(b)锁定CM的目标局部页面(例如,以便防止对那些页面的任何写入,直到分布式事务作为整体提交/中止),并且(c)存储指示事务处于准备状态的事务状态记录(元素2119)。CM可随后将Tx-准备消息继续发送到链中的下一个节点(元素2122)。
如果局部页面级别修改是不可提交的(也如元素2107中检测的),例如,如果页面P自Tx-准备消息中指示的P的RLT被获得以来已被写入,那么事务作为整体可必须中止以便支持顺序一致性语义。因此,CM(其可以是非决定者节点或决定者节点)可存储事务已中止的指示(元素2125)。在一些实现方式中,可存储指示事务处于中止状态的事务状态记录。在其他实现方式中,可将假的或“无操作”写入记录存储在局部写入日志缓冲器(类似于图14的缓冲器1450)中。这种假的写入将具有与指示中止状态的状态记录相同的效果。即,如果因为某个原因(例如,由于接收错误的或延迟的消息)在CM处尝试重试事务,那么重试将失败。CM可发起将Tx-中止消息传播到链中的已发送Tx-准备消息的其他节点(如果存在任何此类节点的话)和/或协调器(元素2128)。
图22是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务提交(Tx-提交)消息而执行的操作的方面的流程图。如元素2201中所示,事务的Tx-准备消息中的由事务协调器指示的节点链成员CM可接收Tx-提交消息。Tx-提交消息可(至少在正常操作条件下)通常在CM已执行其局部页面级别提交分析并且存储指示事务处于准备状态的事务记录之后的某一时间处接收。响应于接收Tx-提交消息,CM可发起对局部目标页面的实际修改(元素2104),并且修改事务状态记录以便指示事务现在处于提交状态。在一些实施方案中,取决于盘区E的数据耐久性要求,可必须在可认为局部页面写入完成之前修改多个盘区复本。在一些此类情境中,CM可在指示页面修改之后等待,直到在改变事务记录之前已更新足够的复本。
CM可随后释放其在一个或多个目标页面上保持的锁(元素2207)。在至少一些实施方案中,可在此刻删除CM在响应于事务的Tx-准备消息时存储的意图记录(元素2210)。如前所述,在一些实施方案中,Tx-提交消息可按相对于Tx-准备消息相反的次序在链成员之间顺序地传播,而在其他实施方案中,可使用并行传播,或者可使用顺序传播和并行传播的某一组合。如果使用顺序传播,或者如果CM可确定(例如,基于其接收的Tx-提交消息内的指示)链的一些节点还未接收Tx-提交消息,那么CM可将Tx-提交消息继续传输到链中的选择节点或者协调器(元素2213)。在一些实施方案中,可忽略重复的Tx-提交消息,例如如果给定节点或协调器接收事务Tx1的Tx-提交消息并且Tx1已经记录为已提交,那么可无视新的Tx-提交消息。在一些此类实施方案中,非顺序传播机制可用于Tx-提交消息以便缩短完成事务所花费的总时间,其中例如,接收Tx-提交消息的每个节点可将Tx-提交消息转发到链的N个其他节点。
图23是示出根据至少一些实施方案的可响应于在存储服务的节点处接收事务中止(Tx-中止)消息而执行的操作的方面的流程图。如元素2301所示,可在链成员CM处接收Tx-中止消息。如Tx-提交消息一样,Tx-中止消息可(至少在正常操作条件下)通常在CM已执行其局部页面级别提交分析并且存储指示事务处于准备状态的事务记录之后的某一时间处接收。
响应于接收Tx-中止消息,CM可释放其在一个或多个目标页面上保持的锁(元素2304)。在至少一些实施方案中,可在此刻删除CM在响应于事务的Tx-准备消息时存储的意图记录(元素2307)。如在Tx-提交消息的情况中,在不同实现方式中,顺序、并行或混合(即,顺序和并行的某一组合)传播可用于Tx-中止消息。例如,在一些实施方案中,Tx-中止消息可按相对于Tx-准备消息相反的次序在链成员之间顺序地传播。如果使用顺序传播,或者如果CM可确定(例如,基于其接收的Tx-中止消息内的指示)链的先前已发送Tx-准备消息的一些节点还未接收Tx-中止消息,那么CM可将Tx-中止消息继续传输到链中的选择节点或者协调器(元素2310)。在一些实施方案中,如同重复的Tx-提交消息一样,可忽略重复的Tx-中止消息,例如如果给定节点或协调器接收事务Tx1的Tx-中止消息并且Tx1已经记录为已中止,那么可无视新的Tx-中止消息。在一些此类实施方案中,非顺序传播机制可用于Tx-中止消息以便缩短中止事务所花费的总时间,其中例如,接收Tx-中止消息的每个节点可将Tx-中止消息转发到链的N个其他节点。
使用盘区过量预订模型的按需式页面分配
在许多存储系统中,性能目标可能有时候潜在地与空间效率目标冲突。例如,通常,将元数据(诸如包括逻辑块到物理页面的映射的结构)的量保持为相对于管理的数据的量相对较小可帮助加速各种类型的文件存储操作。如果元数据增长地太大,那么访问节点的元数据高速缓存器处的高速缓存命中率可能下降,这可导致访问子系统与元数据子系统之间的更多的交互以便服务相同数量的客户端请求。由于可基于每逻辑块维持至少一些元数据,这将建议从性能角度来看具有大的逻辑块(例如,4兆字节或16兆字节的逻辑块)将比具有小逻辑块更有益。然而,如果在请求对逻辑块的第一写入时为整个逻辑块分配物理页面,那么这可能导致次优的空间使用效率。例如,考虑以下情境:其中逻辑块大小是4MB(因此,如果一次为整个逻辑块分配足够的空间,则将为任何给定文件分配最小4MB的物理空间),并且存储在给定目录或文件系统内的文件中的数据的中间量是32KB。在这种情境中,将浪费大量的物理存储空间。然而,如果逻辑块大小被设置为接近中间文件大小,那么这可导致大文件的非常大量的元数据,因此潜在地不仅减速指向大文件的操作还减速指向作为整体的文件存储服务的操作。
在不同实施方案中,可使用多种技术来处理空间效率与性能之间的权衡。在一种技术中,过量预订模型可用于盘区,并且给定逻辑块内的物理页面可仅按需分配而不是一次全部分配(即,如果逻辑块大小被设置为X千字节,并且对逻辑块的第一写入具有仅(X-Y)千字节的有效负载,那么仅足够存储X-Y千字节的页面可响应于第一写入被分配)。在论述过量预订模型之后描述的另一种技术中,可在给定文件存储对象内采用具有不同大小的逻辑块,使得对象的至少一些条带的大小可不同于其他条带的大小。需注意,虽然在如前所述的各种实施方案中(包括在盘区被过量预订和/或使用可变逻辑块大小的实施方案中)可针对数据耐久性复制盘区,但如本文论述的,盘区复制技术可被认为是正交于逻辑块到页面的映射和盘区过量预订。因此,在本文可不相对于过量预订的盘区或相对于可变大小的条带详细地论述盘区复本。为了简化呈现,相对于盘区过量预订管理技术的多数论述并相对于用于可变大小的条带或可变大小的逻辑块的技术的论述,逻辑盘区可被假设为包括单个物理盘区。
图24示出根据至少一些实施方案的分布式存储服务处的过量预订的存储盘区的实例。在所描绘实施方案中,给定文件存储对象(诸如文件2400A、2400B或2400C)的逻辑块都是相同大小,并且为给定逻辑块分配的所有物理页面是单个盘区的一部分。在所描绘实施方案中,给定盘区内的物理页面可通常也具有与盘区的其他物理页面相同的大小。因此,在一个示例性实现方式中,盘区可包括16千兆字节的32-KB的物理页面,而逻辑块可包括4兆字节。在至少一些实施方案中,可使用各自的配置参数来设置盘区、逻辑块和/或物理页面的大小。
如图所示,至少在一些情况下,同一文件的不同逻辑块可映射到不同盘区,并且因此逻辑块可被视为条带的等效物。文件2400A包括LB(逻辑块)2402A和2402B。LB 2402A按需要映射到盘区E2434A的某一数量的物理页面(PP)2410A。类似地,盘区E2434B处的某一数量的物理页面2410B按需要分配用于LB 2402B。在盘区E2434A处,某一数量的页面2410A按需要分配用于文件2400B的LB 2402L以及文件2400C的LB 2402P。在盘区E2434B处,某一数量的页面2410B按需要分配用于文件2400B的LB 2420K以及文件2400C的LB 2402Q。在所描绘实施方案中,按需式分配技术可按以下实现:每当接收到指向特定逻辑块的写入请求时,文件内的起始偏移以及写入有效负载的大小(例如,将被写入或修改的字节数量)可用于确定是否将分配任何新的物理页面,并且如果是的话,那么需要分配多少新的物理页面。(一些写入请求可能不需要分配任何新的页面,因为它们可能指向先前分配的页面)。例如,代替一次分配可能潜在被写入作为逻辑块的一部分的整组物理页面,可仅分配容纳写入有效负载需要的一些新的物理页面。考虑以下实例:LB 2402A大小是4兆字节,并且PP 2410A大小是32KB。接收对LB 2402A的包括28KB的写入有效负载的第一写入。在此之前,在示例性情境中,没有物理存储装置被分配用于LB 2402A。存储服务做出第一写入需要仅一个PP2410A的确定(由于28KB可容纳在单个32-KB页面内)。因此,在所描绘实施方案中,在盘区E2434A内分配仅一个PP 2410A,即使整个4MB的LB 2402A可最终必须存储在盘区E2434A内,这是由于给定逻辑块的所有页面必须从同一盘区内分配。
通常,在至少一些实施方案中,可能不能直截了当地预测逻辑块的什么部分将最终被写入;例如,一些稀疏文件可在广泛不同的逻辑偏移下包含小区域的数据。为了在所描绘实施方案中改善空间使用效率,盘区E2434A和E2434B可各自被过量预订。盘区如果被配置来接受对比完全物理容纳在其当前大小内多的逻辑块的写入请求则可被认为是过量预订的,例如,如果所有逻辑块内的完整偏移范围将以某种方式同时被写入,那么可能必须扩大盘区(或者可能必须使用不同盘区)。因此,如过量预订参数2455A所示,N个逻辑块可映射到盘区E2434A,并且每个逻辑块可映射到各自具有Y千字节的最大M个物理页面。盘区E2434A的当前大小是X千字节,其中X小于(N*M*Y)。在所描绘实施方案中,过量预订因子OF1应用到盘区E2434A,等于存储装置的潜在溢流量((N*M*Y)-X)对盘区的实际大小(X)的比率。类似的过量预订参数2455B应用到盘区E2434B。E2434B可当前仅存储高达Z千字节,但其被配置来接受指向P个逻辑块的写入请求,所述P个逻辑块中的每一个可各自映射到具有RKB的Q个物理页面。Z小于(P*Q*R),并且E2434B的过量预订因子OF2因此为((P*Q*R)-Z)/Z。在一些实施方案中,不同盘区可被配置有不同过量预订因子。在一个实施方案中,统一过量预订因子可用于所有盘区。如下所述,在一些实施方案中,过量预订因子和/或与过量预订因子相关联的自由空间阈值可例如基于文件系统使用或行为的收集度量针对至少一些盘区随时间推移而修改。在各种实施方案中,类似于本文针对每盘区级别处的过量预订管理描述的技术还可应用到其他级别处的过量预订或者代替应用到其他级别处的过量预订,例如,存储子系统节点可基于其盘区的过量预订被过量预订,单独存储装置可被过量预订,等等。
图25示出根据至少一些实施方案的实现按需式物理页面级别分配以及盘区过量预订的分布式多租户存储服务的子系统之间的交互。如图所示,在所描绘实施方案中,元数据盘区(诸如E2534A)和数据盘区(诸如E2534B)都可过量预订。如箭头2501指示的,可在元数据节点2522处从访问节点2512接收指向特定逻辑块(LB)的第一写入请求。写入请求可包括大小为“WS”的写入有效负载并且可例如响应于指向文件2400的客户端的写入请求而在访问节点2512处生成。
逻辑块自身的元数据可能在写入请求2501被接收时未创建,例如,写入可能只是在文件2400打开之后指向文件的第一写入。在所描绘实施方案中,元数据节点2522可首先生成并写入LB的元数据。请求2554可例如发送到存储节点2532A以存储LB的元数据。存储节点可分配来自过量预订的元数据盘区E2534A的页面,并且存储由元数据节点2522生成的元数据,如块2558指示的。将使用的特定元数据盘区可由元数据节点2522、存储节点2532A或者不同实施方案中的存储服务的不同放置部件选择。选择可例如基于各种因素,诸如被修改的文件的名称、各种盘区中可用的自由空间的量等等。
在所描绘实施方案中,元数据节点2522还可确定将分配多少新的物理数据页面以存储WS字节的写入有效负载。在至少一些实施方案中,针对适当数量的物理页面以容纳WS字节的请求2562可发送到与用于LB元数据的存储节点不同的存储节点2532B。在所描绘实施方案中,存储节点2532B可在过量预订的数据盘区2534B处分配所请求数量的物理页面(其可在至少一些情况下小于将在逻辑块的整个地址范围被一次写入情况下将需要的页面的数量)。在所描绘实施方案中,物理页面的身份可存储在存储于盘区2534A处的LB元数据内,例如,存储节点2534B可将盘区2534B内的数据页面的地址传输到元数据节点2522,并且元数据节点2522可向存储节点2532A提交请求来将地址写入LB元数据内。在一些实施方案中,数据页面可在元数据页面分配之前分配,使得例如元数据页面的分配可与数据页面地址的写入组合而不需要另外的消息。在一个实施方案中,写入有效负载可与针对数据页面的分配请求2562一起由元数据节点2522传输到存储节点2532B,在这种情况下,WS字节的写入可与数据页面的分配组合而不需要另外的消息。在至少一些实施方案中,在一个或多个数据页面已针对第一写入请求2501分配之后,将存储数据的适当存储节点(2532B)的身份可提供给访问节点2512,并且访问节点2512可向存储节点提交写入有效负载。
在至少一些实施方案中,如前所述,使用过量预订模型可导致以下情况:其中给定盘区可能缺乏用于其内容被指定存储的所有逻辑块的足够存储空间。因此,在一些实施方案中,过量预订的盘区可能必须不时地扩展,或者盘区内容可能必须从其原始盘区移动或复制到更大的盘区。在一些实施方案中,为了避免可能否则在盘区级别的数据复制或盘区扩展被支持的情况下导致的同步延迟,可将自由空间阈值分配给过量预订的盘区。在此类实施方案中,如果违反自由空间阈值,那么可实现异步盘区扩展操作或者盘区内容的异步传送。取决于指向不同盘区的存储工作负载的本质,不同盘区可以不同速率增长。可针对至少一些盘区(例如,基于使用的特定存储装置的容量)限定最大盘区大小。因此,当针对特定盘区达到这个最大盘区大小时,盘区可不再被认为是过量预订的,并且存储服务可采用与用于可仍然增长的盘区的逻辑不同的逻辑来处理此类最大大小的盘区。在一些实施方案中,所选择盘区可主动地移动到不同的存储节点或不同的存储装置以便为其他盘区的增长让出空间。在一些实现方式中,此类主动移动可作为后台任务执行,以便最小化正在进行的客户端请求的操作的中断。在不同实施方案中,多种不同规则、策略或试探法可用于选择哪些盘区将主动地移动来为其他盘区让出空间,例如,在一个实施方案中,大多数容量未使用的盘区可优先于大多数容量已被使用的盘区被选择来主动移动。可在其他实施方案中使用相反的方法,例如,已经达到其最大大小(或者接近达到其最大大小)的盘区可优先于仍然具有基本增长可能的盘区移动。类似地,在各种实施方案中,盘区移动到的目标存储装置或存储节点还可基于可配置策略选择。在一个实施方案中,盘区可仅在绝对必要时移动(例如,主动移动可能不能实现)。
根据至少一些实施方案,图26a示出自由空间阈值已被指定用于的盘区,而图26b示出由自由空间阈值的违反引起的盘区扩展。如图26a所示,为过量预订的盘区E2634A设置的自由空间阈值可被设置成使得,M个物理页面的最大限制2650可在扩展触发之前在盘区内分配。只要盘区2634A的分配页面的数量K小于M(即,未分配页面的数量L高于自由阈值限制),就可响应于如图25中示出的写入请求按需要分配新的页面。如果/当第M页被分配时,可发起初始盘区2634A的内容到更大或扩展的盘区2634B的异步复制,如由图26b的箭头2655指示的。如图所示,扩展的盘区2634B的最大分配限制(N个页面)可大于初始盘区2634A的M个页面的分配限制。在一些实施方案中,可能在不复制页面的情况下扩展至少一些盘区,例如,如果给定过量预订的盘区位于具有足够的空间来容纳期望扩展的存储装置上,那么盘区的大小可在存储装置内增加。在其他实施方案中,初始盘区的内容可能必须复制到不同的存储装置,潜在地不同的存储节点。因此,在一个实现方式中,扩展的盘区2634B可占据与初始盘区2634A不同的物理存储装置。在至少一些实现方式中,可在存储服务处创建具有若干不同大小的盘区,例如,可创建10GB的N1盘区,可创建20GB的N2盘区等等。在此类实施方案中,例如,盘区的扩展可涉及将页面从10GB的盘区复制到预先存在的20GB的盘区。如本文所用,术语“盘区扩展”意图大体上指导致在过量预订的盘区处存储另外数据或元数据内容(在其自由空间阈值被违反时)的能力的这些类型的操作中的任一种,例如,不管操作是涉及盘区的原地放大还是盘区内容从一个存储装置传送到另一个。因此,在一些实施方案中,可实际上通过在与初始装置相同的存储节点或者在不同的存储节点处,用不同的存储装置替换用于盘区的存储装置来扩展盘区。在一些实施方案中,如果盘区标识符E1用于指扩展之前的盘区,并且在扩展后使用不同的存储装置,那么可在扩展后使用不同的盘区标识符E2。在其他实施方案中,可在扩展后使用相同的标识符。
图27是示出根据至少一些实施方案的可被执行来实现支持盘区过量预订的存储服务处的按需式物理页面分配的操作的方面的流程图。如元素2701所示,可在分布式多租户文件存储服务的多个存储子系统节点处建立多个物理盘区。在一些实施方案中,例如,可在存储服务于提供商网络的一组资源处启动时预先配置具有一个或多个不同大小的某一数量的盘区。在其他实施方案中,可在新的文件存储区(例如,文件系统)初始化时建立一组盘区。在一些实施方案中,每个盘区可包括足够空间用于某一选择数量的物理页面,其中每个页面包括可用于存储数据或元数据的逻辑块的内容的某一数量的字节。例如,在一个实施方案中,一组盘区中的每一个可在特定SSD或基于转盘的存储装置上包括8千兆字节的存储空间,其内容将存储在盘区处的对象使用的默认逻辑块大小可以是4MB,并且物理页面大小可被设置为32KB。通过此组参数,每个逻辑块可包括多达128个物理页面,并且每个盘区可存储多达大约2000个完全填充的逻辑块(已实际写入至少4MB的数据的块,使得在逻辑块内不存在未写入的偏移范围)。通常,情况可能是由于在至少一些文件系统协议中,写入可指向文件或元数据结构内的随机偏移,逻辑块内并非所有偏移范围可包含数据(或元数据)。在所描绘实施方案中,给定逻辑块的内容可包含在给定盘区内,例如,逻辑块映射到的所有物理页面可必须为同一盘区的部分。
因为逻辑块中的未写入间隙的潜在性,所以可针对至少一些盘区子集确定一组过量预订参数(元素2704),根据可为给定盘区分配比块完全填充情况下可能容纳的多的逻辑块。给定盘区的参数可指示例如,过量预订因子(例如,映射到盘区的逻辑块可能潜在需要多少另外空间的测量),一个或多个阈值(诸如上文论述的自由空间阈值)(在所述阈值下,诸如盘区扩展的各种行动将触发),在达到阈值的情况下当前盘区的内容应复制/移动到的优选的存储装置或盘区,等等。
响应于指向文件存储对象的逻辑块LB1的特定写入请求,诸如对文件或元数据结构的第一写入,可选择可用盘区中的特定盘区E1来存储逻辑块的内容(元素2707)。例如,E1可能够存储总共多达P1个页面(其可以是多租户环境中的若干不同文件存储对象的部分),包括LB1的多达M个页面。在至少一些情境中,E1可在其被选择时过量预订,例如,映射到其的逻辑块(至少一些可能不完全填充有数据或元数据)的组合大小可超过E1的当前大小。可在不同实施方案中基于各种准则选择E1,诸如其为空的存储空间的部分、对于文件存储对象是优选的存储装置的类型(SSD或基于转盘)等。可在E1内针对第一写入分配一个或多个页面,并且可将第一写入请求的有效负载写入到所述页面(元素2710)。虽然分配的页面的组合大小可足够容纳有效负载,但分配页面的组合大小可至少在一些情况下小于逻辑块LB1的大小(例如,如果有效负载大小小于LB1的大小)。在正常操作条件下,在至少一些实施方案中,仅在实现写入不会违反E1的自由空间约束的情况下才针对第一写入选择E1。
可接收指向E1的具有WS大小的写入有效负载的随后写入请求(元素2713)。随后写入请求可指向LB1或者映射到E1的某一其他逻辑块。如果分配足够的物理页面来容纳写入有效负载WS不会违反E1的自由空间阈值设置(如元素2716中检测的),那么可分配所请求数量的物理页面,并且可执行所请求的写入(元素2719)。如果将违反E1的自由空间阈值(也如元素2716中检测的),那么在所描绘实施方案中,可发起一个同步操作和一个异步操作。相对于写入请求同步例如以便在响应于写入请求时避免任何长度延迟,将在E1内分配一个或多个另外页面。可异步地发起以上关于图26b论述的种类的盘区扩展操作。盘区扩展可涉及例如,E1的通过在其初始存储装置处改变E1相关的元数据的原地扩大,或者它可涉及将E1的内容中的至少一些传送到可配置更大盘区的某一其他存储装置(和/或某一其他存储节点)。需注意,在至少一些实施方案中,E1可以是根据与文件存储区相关联的数据耐久性策略配置的复本组中的一个盘区复本(诸如主复本),其中LB1是块并且在E1处执行的写入可根据先前论述的复制技术的种类(例如,擦除编码、完全复制等)传播到一个或多个另外的复本。至少在盘区是过量预订的并且给定块内的页面按需分配的一些实施方案中,给定盘区或逻辑块内的页面的大小可不同,和/或给定文件或元数据结构内的逻辑块的大小可不同。
存储的动态按需式页面级别的分配可具有同一逻辑块的分开部分的副作用,例如,为给定逻辑块分配的页面可至少在一些情况下在使用的存储装置上不是连续的。在一些实施方案中,可能监视文件存储操作随时间推移的各种特性,并且优化实现盘区过量预订的方式,包括例如过量预订的程度,以及给定逻辑块的页面在物理存储装置上布局的方式。图28是示出根据至少一些实施方案的可被执行来动态修改盘区过量预订参数的操作的方面的流程图。如元素2801所示,可根据为某一组盘区E1、E2等设置的初始组的过量预订参数在时间段T1内为数据和/或元数据分配物理页面。
可在T1期间收集关于使用过量预订的盘区执行的文件存储操作的多个不同度量(元素2804)。例如,可分析文件访问模式以便例如确定随机对比顺序的读取和/或写入的比例。可收集关于文件大小(例如,关于平均或中间文件大小,以及关于文件的大小如何随时间推移倾向改变)、关于文件内的间隙(例如,逻辑块填充的程度),和/或关于各种类型的操作的响应时间和吞吐量的统计值。在一些实施方案中并且针对某些类型的操作,从文件名称推断出文件访问的可能模式可能是可行的,例如,用于存储电子邮件的文件可基于文件扩展名识别并且可预期以特定方式访问,用于数据库日志或网络服务器日志的文件可通过名称识别并且可具有特性访问模式,等等。可例如根据机器学习技术在存储服务的优化器部件处分析关于存储使用的此类信息和度量,以便确定修改过量预订参数中的任一个是否可能是明智的,或者一些逻辑块的物理页面是否应合并。如果做出改变过量预订阈值可改善空间利用水平的确定(元素2807),那么可相应地修改阈值(元素2810)并且可收集具有修改的参数的一组新的度量。例如,在一个实施方案中,可最初保守地设置文件系统FS1的过量预订参数设置,例如,可设置仅10%的过量预订因子。稍后,在分析FS1内的对象的存储使用度量和地址范围间隙之后,可将允许的过量预订水平增加到20%。如果确定可通过重新布置某一组逻辑块的物理页面来改善文件存储性能(例如,顺序读取/写入的),那么可重新布置所选择物理页面的内容(元素2813)(例如,通过分配连续空间来保持给定块的内容,并且将块的内容从其初始非连续位置复制到连续位置)。在至少一些实施方案中,此类重新布置可通常相对于传入I/O请求异步地执行,使得发布读取/写入请求的客户端由于优化操作不经历延迟。还可基于各种实施方案中的类似分析发起其他类型的优化,例如像将一些盘区移动到比当前使用的存储装置快的存储装置(诸如SSD)或慢的存储装置。
可变条带大小
在一些实施方案中,可采取另一种方法来进行上文论述的元数据大小与存储空间效率之间的权衡。在采用这种技术的一些实施方案中,盘区不需要过量预订,并且例如在第一写入指向块时候可预先获取给定逻辑快可能潜在需要的所有存储装置。然而,给定存储对象内的逻辑块(如上文论述的,其可表示跨盘区、存储装置或存储节点的条带化文件数据和/或元数据的单元)可能不是全部具有相同大小。在一些此类实施方案中,逻辑块大小并因此每一次分配的空间的量可作为文件内的逻辑偏移的函数增加。以相对小量的存储空间被分配用于第一块开始,越来越多的空间可分配给随后块;因此,可能在不创建随块大小线性地增加的元数据的量的情况下实现小文件和大文件两者。
图29示出根据至少一些实施方案的内容使用可变条带大小存储的文件存储对象的实例。回想一下,如参考图4论述的,文件存储对象的不同逻辑块可通常(但不必须)映射到各自存储节点处的不同存储装置处的不同盘区,并且逻辑块可因此被认为是等同于条带。文件2900被选为存储对象的实例,但在各种实施方案中各种元数据结构也可使用可变条带大小实现。文件2900被示出为包括四个条带或逻辑块LB 2902A、2902B、2902C和2902D。逻辑块2902中的至少一些可与其他中的至少一些大小不同,但逻辑块的一些子集可具有相同大小。
图29中示出两种类型的盘区,具有固定大小页面的盘区和具有可变大小页面的盘区。盘区2934A包括每个大小为S1KB的物理页面2910。盘区2934B的页面2910B每个大小为S2KB,而盘区2934C的页面中的每一个的大小为S3KB。在所描绘实施方案中,S1、S2和S3可彼此不同,例如,S1可小于S2,并且S2可小于S3。如前所述,在一些实施方案中,至少对于具有固定页面大小的盘区,物理页面可表示受支持的I/O的最小单元。因此,在所描绘实施方案中,在盘区2934A处可能支持比在2934B或2934C处的小的读取和写入。盘区2934D支持可变大小的页面,即,在盘区2934D内可一次分配任意量的物理空间(具有某一指定的最小值和最大值)。相反,在盘区2934A、2934B和2934C内,空间可以其各自页面大小的倍数进行分配。在至少一些实施方案中,可仅支持离散组的页面大小或单个页面大小。
在至少一些实施方案中,响应于指向LB 2902的第一写入,可从所选择盘区分配用于整个条带的物理存储空间(其可多于第一写入的写入有效负载需要的物理空间)。因此,例如,盘区2934A的一个或多个页面2910A可用于LB 2902A,并且盘区2934B的一个或多个页面2910B可用于LB 2902B。类似地,针对LB 2902C,一个或多个页面2910C可从盘区2934C分配,并且来自盘区2934D的一个或多个页面可分配给LB 2902D。在一些实施方案中,任何给定逻辑块或条带可映射到物理存储空间的一个连续区域,而在其他实施方案中,为给定逻辑块分配的物理空间可在至少一些情况下在存储装置地址空间内不连续。如果相对小的条带大小例如用于文件的前几个条带,那么即使小的文件也可跨多个盘区条带化,因此获得条带化的性能益处,所述益处可能否则在使用单个大条带大小的情况下不能实现。
通常,在所描绘实施方案中,当接收具有指定偏移和写入有效负载大小的写入请求时,可做出关于写入是否需要另外的存储空间被分配的决定(基于偏移和有效负载大小)。在至少一些实施方案中,可在存储服务的元数据节点处做出这种决定。如果空间确实需要被分配,那么可确定将分配给有效负载的连续物理存储空间的量(通常但不必须)。在至少一些实施方案中,分配的空间的量可取决于写入偏移。(以下更详细地论述文件存在过程中的条带定大小模式的实例以及在决定条带大小时可考虑的一些种类因素的实例)。可识别具有可用于分配期望量的空间的盘区的一个或多个存储节点。例如,如果将为一千字节条带分配空间,那么存储服务可尝试识别具有1KB页面并且具有容纳条带的写入的足够自由空间的盘区。需注意,所选择盘区处的最小页面大小不需要等于条带或逻辑块大小,例如,条带大小可以是3KB,但可使用支持4KB页面的盘区,或者可使用支持2KB页面或1KB页面的另一盘区。在获得用于期望条带大小的物理存储装置之后,可发起写入有效负载中指示的修改。在盘区被复制的一些实施方案中,例如,修改可从存储主复本的存储节点协调,并且可从主节点或者由所述主节点传播到非主复本。
在一些实施方案中,给定文件或元数据结构内的条带大小可作为偏移的函数以可预测方式改变。图30示出根据至少一些实施方案的可用于文件存储对象的条带定大小序列的实例。在条带大小序列3010A中,文件存储对象的前九个逻辑块的大小可分别被设置为例如1KB、1KB、2KB、2KB、4KB、4KB、8KB、16KB和32KB。例如,这种模式可用于预期为小的文件或元数据结构或者用于预期相对缓慢地增长的文件或结构。对于例如大数量的顺序写入预期以某一高概率针对的其他文件,可使用不同的条带大小序列3010B,其中前四块的大小被分别设置为1MB、4MB、16MB和64MB。因此,即使在实现离散组的条带大小的实现方式中,用于一个文件F1的条带大小可不同于用于不同文件F2的条带大小中的任一个。在一些实施方案中,将使用的条带大小序列3010中的至少一些可被指定为存储子系统的配置参数。在一些情况下,在文件增长时,将较小条带合并成较大条带可能是有用的(对于元数据性能和数据访问性能两者)。
图31示出根据至少一些实施方案的可在元数据子系统处加以考虑以便为文件存储对象做出条带定大小决定3170和/或合并决定3172的因素的实例。在所描绘实施方案中,元数据子系统节点122可负责确定包括文件和元数据结构的各种文件存储对象的条带/逻辑块大小,并且负责确定物理页面和/或逻辑块是否以及何时应组合或合并。当确定将用于文件存储对象的下一部分(将为其分配空间)的条带大小时,元数据节点112可考虑对象的当前大小3101和写入请求有效负载大小3103。在一个实现方式中,例如,为文件存储对象分配的第一条带的大小可基于指向对象的第一写入的写入有效负载,例如,如果第一写入的有效负载是3.5兆字节,那么可选择4兆字节的条带大小,而如果第一写入小于或等于2兆字节,那么可选择2兆字节的条带大小。在一些实施方案中,当文件或目录在客户的请求下创建时,提示3105可提供给存储服务,指示例如对象是否将主要用于顺序写入和读取、随机写入和读取或者顺序访问和随机访问的某一混合,并且此类提示可用于选择条带/逻辑块大小。文件系统性能的度量3110诸如针对具有不同大小的写入和/或读取实现的平均响应时间还可在一些实施方案中影响逻辑块大小的选择,和/或影响先前创建的条带的内容组合成较大条带的合并操作的调度。
在一些情景中,如先前论述的,文件或目录的名称(或名称的部分,诸如文件扩展)可对方式提供某一指导,文件或目录的内容预期以所述方式增长或被访问。例如,一些应用诸如电子邮件服务器、网络服务器、数据库管理系统、应用服务器等使用已知的文件扩展和/或其功能的各部分的目录层次结构,并且对于元数据节点112的优化器部件来说可能基于此类文件/目录名称3115更明智地选择条带大小。在至少一个实施方案中,元件数据节点112可确定访问模式(例如,随机对比顺序、百分比读取对比百分比写入、读取大小分布、写入大小分布)并相应地选择条带大小。对象寿命的测量3125(例如,给定文件存储区处的文件的创建与删除之间平均流逝多少时间)可在一些实施方案中帮助做出条带大小的决定,例如,如果给定目录内的多数文件预期在创建之后的X小时之内被删除,那么关于其条带大小的决定可能不具有很多长期影响。在一些实施方案中,盘区空间利用度量3130和/或存储节点资源利用度量3135(诸如使用的存储节点的CPU、存储器或网络利用水平)也可在确定条带大小中起作用。在一个实施方案中,例如,如果/当文件或结构增长超出阈值大小时或者如果/当检测到对文件的频繁顺序访问时,给定文件或元数据结构的小条带可基于一个或多个触发准则组合并成较大条带。取决于使用的盘区的特性(例如,取决于在不同盘区处支持的特定页面大小),此类组合操作可涉及从一个存储装置到另一个存储装置或者从一个盘区到另一个盘区移动或复制数据/元数据。在至少一些实施方案中,可采用机器学习技术来改善随时间在存储服务处做出的条带定大小和/或合并决定。作为此类机器学习方法的一部分,可分析图31中示出的各种因素对整体文件存储性能和/或成本的相对影响。
图32是示出根据至少一些实施方案的可被执行来使用可变条带大小实现条带化的操作的方面的流程图。可例如在分布式多租户存储服务的元数据节点112处接收或生成指示文件存储对象内的写入偏移和写入有效负载的写入请求(元素3201)。在一些情况下,写入请求可在访问节点122处响应于诸如文件写入的客户发布的文件系统API调用而生成,而在其他情况下,元数据节点可自身决定将存储某一新的元数据或者将修改现存元数据。基于对目标对象的写入偏移、写入有效负载以及现存元数据(如果有的话)的分析,可做出将分配另外存储装置以实现写入的确定(元素3204)。(如前所述,整个由预先写入内容的修改组成的一些写入可能不需要另外存储装置)。
可例如基于用于文件存储对象的基于偏移的条带定大小序列(类似于图30中示出的序列)和/或基于图31中示出的因素的某一组合(诸如对象的大小、检测到的访问模式等)确定文件存储对象的下一个新的条带或逻辑块的大小(元素3207)。可随后识别将用于存储具有所选择大小的条带的至少一个复本的特定盘区、存储节点和/或存储装置(元素3210)。如在图29的上下文中论述的,在至少一些实施方案中,给定盘区可被配置来使用特定物理页面大小并且因此并非所有盘区可适合用于为给定逻辑块大小分配空间;因此,可基于盘区页面的大小来选择盘区。在一些情景中,可能仅允许映射到受支持盘区的离散组物理页面大小的离散组逻辑块大小。被配置来支持可变页面大小的盘区(诸如图29的盘区2911)在一些实施方案中可以是可用的,并且此类盘区可被选择用于为具有多种大小的逻辑块/条带分配空间。在一些实施方案中,在为新的逻辑块或条带分配空间时,可针对盘区的复本组识别多个存储节点(例如,分布在若干可用性容器或数据中心之间)。
可将对期望量的物理存储空间的分配请求发送到至少一个选择的存储节点(元素3213)。如果条带被完全填充,那么存储节点可分配所请求的物理存储例如足够的页面以便存储条带的内容(元素3216)。可随后发起或执行写入请求中指示的修改(元素3219)。取决于与文件存储对象相关联的数据耐久性策略,写入有效负载可能必须在可被认为完成写入之前传播到若干不同的复本。需注意,至少在一些实施方案中,按需式页面分配和/或过量预订盘区可组合上述种类的可变条带定大小使用。
基于偏移的拥塞控制技术
以高并行性访问数据组的小部分的客户工作负载可导致分布式文件存储服务中的热点。例如,如果客户大约在同一时间请求使用多个执行线程对文件的多个顺序读取,那么所有线程最终可能首先访问接近文件的开始的单个条带或逻辑块。此外,取决于逻辑块和读取有效负载(在来自客户的每个读取请求中被请求的数据的量)的相对大小,多个读取请求可根据每个线程指向单个条带。在这种情境中,当许多客户端大约在同一时间从同一逻辑块请求多个读取时,拥塞控制技术可在逻辑块的地址范围内实现以便防止单独线程的较差整体吞吐量和/或较差的响应时间。在一些实施方案中,此类拥塞控制技术可将基于偏移的优先级与I/O请求相关联,其中例如赋予读取请求的调度优先级可随着逻辑块内的读取偏移增加。
为了推动取决于偏移的拥塞控制技术的论述,示出可能由未优先化的读取请求调度引起的潜在有问题的情境可以是有用的。图33示出根据至少一些实施方案的由指向存储服务对象的逻辑块的多个并行读取请求在调度环境中进行的进程的示例性时间线,其中针对逻辑块的所有读取请求被授予相对于彼此平等的优先级。已选择实例的各种参数的极值以便更清晰地示出潜在问题;所选择参数并不意图表示常见使用场景。
在图33中,流逝的时间从左到右增加。在大约时间T0处,100个客户端线程各自开始对内容(例如,数据或元数据)存储在盘区E3334的两个物理页面PP1和PP2处的逻辑块3302的顺序读取。逻辑块3302可例如表示还包括其它逻辑块(未示出)的文件的第一逻辑块。假设每次读取一页LB 3302的内容,例如,为了读取整个逻辑块,给定客户端必须首先读取PP1并随后读取PP2。盘区E3334可每秒处理多达25页I/O,如盘区容量3302指示的。在示出的示例性情境中,可假设通过确保在给定秒的时间期间允许不多于25页读取开始来强制此容量限制。如I/O优先化策略3301指示的,所有读取请求被视为具有平等的优先级(其具有与不使用优先化相同的效果)。给定这些参数,考虑客户端请求在沿时间线的以下时间处的状态:T0、T0+1秒、T0+2秒、T0+3秒以及T0+4秒。
在大约T0处,100个请求正在等待开始读取页面PP1。由于盘区容量约束,在T0与T0+1秒之间仅允许25个开始(并结束)读取PP1。因此,在T0+1处,75个客户端尚未读取PP1,而25个客户端已经完成读取PP1。然而,由于所有请求被视为具有相等优先级,很可能是这种情况:已经完成读取PP1的25个客户端可能不能前进到页面PP2直到剩余的75个客户端已读取PP1。因此,由T0+1处的较深色圆角矩形指示的25个客户端可等待其他75个完成读取PP1。在时间T0+2处,又25个客户端可已经完成读取PP1,但它们也必须等待直到剩余的50个客户端读取PP1。在时间T0+3处,25个客户端可能尚未读取PP1,并且已经读取PP0的75个可被迫等待它们。仅在T0+4处(当所有100个客户端已经读取第一页面时),客户端中的任一个被允许在示例性情境中前进到页面PP2,其中,相等的优先级被分配给指向LB 3302的页面处的所有读取请求。
在至少一些实施方案中,可能通过向已经进行更多个进程的那些客户端分配更高(或者,相当地,更低的成本)的优先级来改善针对顺序读取实现的整体性能。图34示出根据至少一些实施方案的由指向存储服务对象的逻辑块的多个并行读取请求在调度环境中进行的进程的示例性时间线,其中使用基于偏移的拥塞控制策略。逻辑块3302再一次包括位于具有每秒25页I/O容量的盘区E3334处的两个页面PP1和PP2。在所描绘实施方案中,LB 3302具有基于偏移的I/O优先化策略3401以便实现拥塞控制。根据策略,指向LB 3302内的更高偏移的读取请求被赋予比指向更低偏移的读取请求高的优先级。
在大约T0处,100个客户端开始其顺序读取操作。在T0+1处,25个客户端已经完成读取页面PP1,并且这25个客户端现在以高于剩余75个的偏移请求读取。根据基于偏移的优先化策略,在时间T0+1处,已经完成读取PP1的25个客户端被授予比剩余75个高的优先级。因此,那25个客户端现在开始读取页面PP2,而75个其他客户端等待。在时间T0+2处,25个客户端已经完成读取LB 3302的全部,并且可继续前进到被顺序读取的文件或元数据结构的下一个逻辑块(如果有的话)。由于下一个逻辑块将(以高概率)存储在不同存储装置处,这意味着,从T0+2开始,100个客户端的工作负载将开始跨两个存储装置分布,而不是仍指向与使用相等优先级的情况中相同的盘区。在T0+3处,又25个客户端已经完成读取PP1,并且被授予比尚未读取PP1的剩余50个客户端高的优先级。在T0+4处,又25个客户端已经完成读取两个页面,并且可前进到下一个逻辑块。同时,50个客户端在图34中的T0+4处尚未读取页面PP1(从那50个客户端的角度来看是比在如图33中示出的相等优先级用于所有客户端的情况下可实现的结果(其中所有100个客户端在T0+4处完成读取页面PP1)差的结果)。因此,在图34中示出的方案中,一些客户端请求可在一定程度上被视为相对于其他“不公平”。作为不公平性的另一示出,考虑以下情境:I/O请求R1和R2在时间Tk和(Tk+delta)处分别从客户端C1和C2接收,其中R1指向逻辑块内的偏移O1,R2指向逻辑块内的偏移O2,并且O2大于O1。即使R2在R1之后接收,R2可基于其更高的偏移被分配更高的优先级,并且因此可在图34的方案下比R1早调度和/或完成。在一些情况下,如果R2是顺序读取模式的部分,那么例如整组的顺序读取可由于基于偏移的优先化在R1被调度之前完成。然而,尽管有这种“不公平性”,图34的方案将通常倾向于更快地导致I/O工作负载并行,这是因为各组客户端的顺序读取将倾向于比相等优先级用于所有请求而不管偏移如何的情况下快地分布在不同存储装置之间。在访问的文件存储对象包括位于不同存储装置处的多个条带的情境中(其预期为多数文件存储对象的情况),使用基于偏移的优先化的工作负载跨存储装置更平均的这种伸展可帮助改善顺序操作的整体平均完成时间和整体吞吐量。从并行支持成百上千客户端的多租户存储服务的部件的角度来看,可能不能总是直截了当(或有效)地记录特定页面读取请求是随机读取还是顺序读取序列的部分,并且因此在一些实施方案中,基于偏移的优先化可通常用于页面级别读取,而不管读取是否是更大顺序扫描的部分。至少在一些实施方案中,逻辑块内的基于偏移的优先化可用于对数据和/或元数据的以下类型操作的任何组合:顺序读取、顺序写入、随机读取或随机写入。
可在不同实施方案中采用如图34中示出的基于类似原理的多个不同基于偏移的拥塞控制技术。根据至少一些实施方案,图35a示出可用于在存储服务处调度I/O请求的基于令牌的拥塞控制机制的实例,而图35b示出可采用的基于偏移的令牌成本策略的实例。总而言之,基于令牌的机制可用于各种类型的实体诸如存储对象、数据库表、数据库分区等的工作负载管理。在分布式文件存储服务的上下文中,可在各种实施方案中针对文件的逻辑块、针对元数据结构的逻辑块、针对整个文件和/或针对整个元数据结构维持此类桶。为了简单陈述,图35a中示出使用令牌3501的单个桶3508的机制;然而,多个桶的组合可用在一些实施方案中,诸如一个桶用于读取操作并且不同的桶用于写入操作。根据机制,为了与特定工作目标诸如文件的逻辑块相关联的拥塞控制目的建立的桶3508(例如,可在至少一些实施方案中实现为软件拥塞控制模块内的数据结构的逻辑容器)可在桶初始化期间填充有初始组的令牌3501,如通过箭头3504A指示的。在各种实施方案中,例如,可基于并行工作负载预期水平、与工作目标相关联的供应的操作限制或者此类因素的某一组合确定初始填充量。在一些实施方案中,针对一些类型的桶,初始填充量可被设置为零。在一些实现方式中,桶的初始填充量可被设置为最大填充量,针对所述最大填充量配置所述桶。
在所描绘实施方案中,当新的I/O请求3522(诸如读取请求或写入请求)例如在存储节点132的拥塞控制子部件处接收时,拥塞控制器可尝试确定某一数量N个令牌(其中取决于实现方式或配置参数,N可大于或等于1)是否存在于桶3508中。如果所述数量的令牌可用在桶中,那么I/O请求3522可立即被接受以用于执行,并且令牌可从桶中消耗或移除(箭头3506)。否则,如果N个令牌不存在,那么所请求存储操作的执行可被延迟直到在所描绘实施方案中足够的令牌变得可用。针对给定I/O请求用光的令牌的数量可被称为接受I/O请求的“成本”。
如标记3504B的箭头示出的,桶3508可随时间推移例如基于配置参数诸如与桶相关联的再填充速率被再填充或重新填充。在一些实现方式中,令牌再填充操作可伴随消耗操作或者时间上紧连所述消耗操作执行,例如,在单个软件例程内,可消耗N个令牌以便接纳请求,并且可基于再填充速率和自桶上次被再填充以来消逝的时间添加M个令牌。在一些实现方式中可修改给定桶的再填充速率或令牌计数,例如以便允许更高的工作请求速率通常在短时间间隔内被处理。在一些实施方案中,可例如使用配置参数对桶可保持的令牌的最大数量和/或令牌的最小数量进行限制。在不同实施方案中,使用配置参数设置的各种组合,相当复杂的准入控制方案可通过使用令牌桶实现。具体地,如下所述,通过针对指向不同偏移的I/O请求需要不同的令牌成本,可实现类似于图34的实例的基于偏移的优先化。
在一个简单的示例性情境中,为了在逻辑块LB1处支持具有相等优先级的每秒25个I/O请求(IOPS)的稳定负载,桶3508可配置有25个令牌的初始填充量、25个令牌的最大可允许填充量以及最小零个令牌。每I/O的成本可被设置为1个令牌,再填充速率可被设置为每秒25个令牌,并且可为了再填充目的每40毫秒添加一个令牌(假设不超过最大填充量限制)。在I/O请求3522到达时,可针对每个请求消耗一个令牌。如果应用每秒期间均匀分布的处于25IOPS的稳定状态工作负载,那么再填充速率和工作负载到达速率可彼此平衡。在一些实施方案中,给定以上列出的桶参数,这种稳定状态工作负载可无限期地持续。然而,如果在给定秒期间接收多于25个I/O请求,那么一些请求可必须等待,并且可导致图33中示出的种类的情境。
代替将成本设置为每I/O请求1个令牌而不管偏移如何,在一个实施方案中,指向较小偏移的I/O请求可能需要比指向文件中的更高偏移的I/O请求所需要的多的令牌。图35b中示出这种令牌成本策略3576的实例。根据策略3575,指向逻辑块内的在0KB与64KB之间的偏移的每个I/O需要10个令牌,指向在64KB与256KB之间的偏移的I/O需要5个令牌,并且指向大于256KB的偏移的每个I/O需要1个令牌。由于更低的偏移需要更多的令牌,指向更低偏移的I/O更可能针对给定令牌桶填充量和再填充速率阻塞或延迟,而指向更高偏移的I/O可通常更快地调度。在不同实施方案中,各种不同数学函数或映射可被选择(例如,基于试探法、存储系统的机器学习部件或者管理员选择的配置设置)来根据偏移计算成本。在一些实施方案中,可使用线性的基于偏移的令牌成本策略3561,而在其他实施方案中可使用非线性成本策略诸如3562。用于各种逻辑块、文件或元数据结构的成本策略、再填充速率以及其他拥塞控制参数可例如响应于对从存储服务获得的性能度量的分析随时间推移而改变。在一些实施方案中,不同参数可用于给定文件存储对象内的不同逻辑块,和/或不同参数可选择用于不同文件存储对象。在至少一些实施方案中,可代替或者除了逻辑块级别之外在文件存储对象级别处应用类似的基于偏移的拥塞控制技术,例如,分配给指向文件内的偏移X的I/O的优先级可高于分配给指向偏移Y的I/O的优先级,其中Y小于X。代替使用基于令牌的技术,在一些实现方式中,其他可变成本分配技术可用在一些实施方案中以便将不同优先级分配给指向逻辑块内或者存储对象内的I/O请求。例如,在一个实施方案中,数字成本可简单地分配给每个I/O请求,并且出色的I/O请求可按分配的成本的相反次序处理。
在至少一个实施方案中,各自的队列可针对指向逻辑块或文件存储对象内的不同偏移范围的I/O请求建立。每个这种队列可在其排队的I/O请求中的任何一个被服务之前具有相关联的延迟间隔,其中更大延迟被分配给更低偏移的I/O请求。图36示出根据至少一些实施方案的用于存储服务处的拥塞控制的基于偏移的延迟的使用的实例。在所描绘实施方案中,示出四个队列3602A、3602B、3602C和3602D,各自指定用于逻辑块的特定偏移范围内的I/O请求(由以“R”开始的标记指示,诸如请求R3631)。队列3602A用于偏移(例如,以字节计)在0与P-1之间的I/O请求;队列3602B用于偏移在P与2P-1之间的I/O请求;队列3602C用于具有2P与4P-1之间的偏移的I/O请求;并且队列3602D用于具有高于4P的偏移的I/O请求。每个队列3602具有相关联的最小延迟,指示在那个队列的任何两个排队I/O请求的实现之间必须消逝的最小时间。队列3602A、3602B、3602C和3602D的最小延迟被示出为分别为4d、2d、d和0。考虑d被设置为一秒的示例性情境,时间T处的各个队列的填充量如图所示,并且没有新的请求在至少几秒内到达。由于序列3602D的请求具有零秒的最小延迟,请求R3634可先进行调度,之后是R3638。随后,队列3602C内的请求可调度,其中每个请求的完成与下一个的开始之间具有一秒的延迟。队列3602B的请求可随后以两秒的间隔进行调度,之后是队列3602A的请求,其中每对请求之间具有四秒的延迟。在所描绘实施方案中,最小延迟可添加到I/O请求的排队延迟。例如,特定请求R1可必须在其队列中等待K秒,简单地因为在同一偏移范围内存在于R1之前到达的其它请求,并且随后在R1到达队列的前面时,R1可仍然必须等待与其队列相关联的最小延迟。在所描绘实施方案中,调度请求之间的延迟可通常允许在那些延迟期间到达的更高偏移(并因此更高优先级)的请求更快地被服务。在不同实施方案中,直截了当的基于偏移的排队技术的多个变型可用于拥塞控制,例如,在一个实施方案中,与给定队列3602相关联的延迟可取决于等待服务的更高优先级请求的数量。在一个实现方式中,将用于给定I/O请求的延迟可通过将其偏移乘以常数来简单地计算。
在一些实施方案中,错误消息可用作用于实现基于偏移的优先化的机制。如果特定I/O请求R1指向较低偏移的一些其他一个或多个请求,代替将R1放置在队列中或者需要更多令牌用于R1,那么错误消息可返回到提交R1的客户端。客户端可随后重试I/O(假设I/O仍然被认为是对客户端是必要的)。由重试引起的延迟可被认为是类似于如上所述的请求在基于偏移的队列中的插入。
在至少一些实施方案中,存储逻辑块的存储装置可必须在强制优先化策略之前实现阈值工作负载水平。在所描绘实施方案中,例如,在图35中,盘区E3334具有每秒25页I/O的限定或基线能力,并且因此优先化策略可仅在工作负载超过(或至少接近)该能力时应用。在至少一些实施方案中,触发优先化的阈值可自身为可修改参数。例如,在各种实施方案中,不同阈值可应用到不同盘区、不同存储节点、不同物理存储装置或者同一盘区内的不同逻辑块。此类阈值可基于各种因素动态地修改。在一个实现方式中,阈值可至少部分地基于盘区、盘区位于的存储装置或存储节点或者甚至阈值应用到的特定逻辑块的整体工作负载水平(例如,如基于在某一时间段内获得的对测量的静态分析计算的)改变。可用于调整阈值的其他因素可包括例如,向逻辑块提交I/O请求的客户端的身份,或者代表其创建包含逻辑块的存储服务对象的客户端的身份(例如,一些客户端可被认为是比其他客户端更重要或者可因此具有分配的更高阈值),时刻(例如,阈值可在通常使用率低的时段期间诸如11PM与6PM之间增加),或者文件系统、目录、文件、卷或者使用盘区实现的其他存储对象的名称。
在一些实施方案中,随机性的元素可添加到拥塞控制技术,例如,代替实现每个偏移范围的固定延迟,可使用包括随机分量(使用某一选择的随机数发生器获得)的延迟。在基于令牌的拥塞控制方案中,随机数量的令牌可添加到I/O请求对给定偏移范围的要求。这种随机化可在一些情况下帮助弄平工作负载分布,并且可帮助减小例如存储装置可最终未被充分利用的不期望的边缘情况的概率。
在至少一些实施方案中,不同拥塞控制策略可用于不同类别的存储操作。图37示出根据至少一些实施方案的可取决于被访问的存储对象的类型和所请求访问的各种特性的拥塞控制策略的实例。如表3780所示,拥塞控制参数设置3710可基于内容类型3702(例如,元数据对比数据)、请求是读取还是写入(I/O类型列3704)和/或请求是顺序的部分还是随机序列(访问模式列3706)变化。还可或者代替基于I/O有效负载大小(列3708)(例如,多少字节的数据/元数据被读取或写入)和/或基于目标对象的当前大小(列3710)使用不同拥塞控制设置。
在所描绘实施方案中,针对元数据结构的顺序读取,在单独读取有效负载大小小于4KB并且元数据结构小于S1MB的情况下,线性基于偏移的优先化可用于拥塞控制。具有任何大小的随机元数据写入操作将被视为具有相等优先级。具有大于64KB的有效负载大小、指向具有>128MB的大小的文件的顺序数据读取将使用具有作为偏移函数的指数衰减的基于偏移的优先级。拥塞控制策略的各种细节(诸如与每个优先级别相关联的成本、不同优先级的偏移边界或者请求之间的最小延迟)已从图36省略以便简化展示。需注意,除了图36中示出的那些之外的其他因素可用于在不同实施方案中分配拥塞控制参数,并且并非所有图36中示出的因素需要在至少一些实施方案中被考虑。例如,在一些实施方案中,拥塞控制技术可仅用于并行顺序读取。
图38是示出根据至少一些实施方案的可被执行来实现基于偏移的拥塞控制以在存储服务处调度I/O操作的操作的方面的流程图。如元素3801所示,可接收指向由多租户文件存储服务管理的存储对象(诸如文件或元数据结构)的逻辑块LB1的至少一些部分的I/O请求(读取或写入)。在不同实施方案中,可在上述各种子系统中的任一个处或者由子系统的组合做出基于偏移的拥塞控制决定。在一些实施方案中,文件读取/写入的拥塞控制决定可在访问子系统节点处做出,而元数据的决定可在元数据子系统处做出。在其他实施方案中,数据和元数据两者的拥塞控制决定可在存储子系统节点处做出。可确定一个或多个存储操作将在其处执行以实现I/O请求的逻辑块LB1内的偏移(元素3804)。
可至少部分地基于偏移确定一个或多个拥塞控制参数的值(例如,分配给IO请求的成本值,诸如将从令牌桶消耗的令牌的数量,或者在存储操作执行之前的延迟)(元素3807)。在至少一些实施方案中,所选择参数可更喜欢或者给予逻辑块LB1内更高偏移下的请求的优先级比给予更低偏移下的请求的优先级高。可随后根据所选择拥塞控制参数调度对应于I/O请求的存储操作(元素3810)。在至少一些实施方案中并且针对某些类型的I/O请求,可向请求者提供响应(元素3813)。需注意,类似于本文描述的那些的基于偏移的拥塞控制技术可在不同实施方案中用在多种存储服务环境中,包括实现文件系统接口/协议的服务、实现存储对象与通用记录标识符(URI)相关联的网络服务接口的服务,或者实现块级装置接口的服务。
一致对象重命名技术
在分布式文件存储服务处,对象重命名操作,例如响应于改变文件或目录的名称的客户请求而执行的操作,可至少在一些情况下涉及对存储在多于一个元数据节点(或者如果元数据子系统将其结构存储在存储子系统处则多于一个存储节点)处的元数据元素的更新。尽管前述分布式事务技术可用于实现此类多节点重命名,但在至少一些实施方案中,可如下所述使用不同的重命名专用机制。图39示出根据至少一些实施方案的可必须在文件存储服务的多个元数据子系统节点处执行以实现重命名操作的元数据改变的实例。通过实例,示出将文件“A.txt”重命名为“B.txt”需要的元数据改变,但可针对目录重命名、链接重命名等做出类似改变。在所描绘实施方案中,示出存储服务的三个元数据子系统节点3922A、3922K和3922P。初始命名为“A.txt”的特定文件存储对象的各种属性3912,包括例如用于对象在一个或多个存储节点处的物理页面的识别、对象拥有者的用户标识符和/或组标识符、对象的当前大小、最后修改时间、访问权限或ACL(访问控制列表)、指示多少硬链接指向对象的链接计数等等可存储在元数据节点3922A处的标记为DFS-索引节点3910的DFS节点条目结构中。DFS-索引节点结构3910可在概念上类似于在许多传统文件系统中实现的索引节点结构,具有由文件存储服务的分布式本质引起的DFS-索引节点的某一组添加或修改特征。
在所描绘实施方案中,文件存储对象的名称“A.txt”(在实现重命名操作工作流之前)可存储在不同元数据节点3922K处的称为DFS-目录条目3930的不同元数据结构中。DFS-目录条目3930可包括对象名称的字段3934和存储对象的属性的到DFS-索引节点3910的指针。在至少一些实施方案中,DFS-目录条目3930还可包括指向对象的母目录的DFS-目录条目的母目录指针DFS-ParentDirPtr 3952。因此,例如,如果“A.txt”在目录“dir 1”中,那么DFS-ParentDirPtr可指向“dir 1的DFS-目录条目。DFS-目录条目元数据结构可在随后论述中被简单地称为目录条目,而DFS-索引节点结构可被简单地称为节点条目。
在不同实施方案中可使用不同技术选择被选择来管理给定对象的目录条目的特定元数据节点3922A,诸如通过在对象创建时散列对象的名称,通过基于元数据节点的当前可用工作负载能力或空间可用性来选择元数据节点等等。因此,不同元数据节点3922P可至少在一些情况下被选择来管理将被创建用于“将A.txt重命名为B.txt”操作的第二操作数(“B.txt”)的目录条目。
实现将“A.txt”重命名为“B.txt”需要的改变在图39中由标记“重命名前状态3945”和“重命名后状态3947”指示。为了实现重命名工作流,应创建具有设置为“B.txt”的对象名称字段3938和指向DFS-索引节点3910的指针字段的新的目录条目3931,并且应移除具有名称字段“A.txt”的原始目录条目3930。在至少一些实施方案中,节点条目3910自身可在重命名期间不修改。为了一致性,图39中示出的元数据改变的组合可必须执行,其方式为使得所有改变(在所涉及的两个元数据节点处)成功或者没有改变成功。在一些实施方案中,如前所述,可实际上使用在服务的存储子系统节点的物理存储装置处实现的盘区存储元数据结构。在后一种情景中,重命名工作流中可涉及四种类型的实体,所述四种类型的实体中的任何一种可独立于其他出故障,或者可独立地丢失传入或传出网络数据包:原始目录条目(“A.txt”的目录条目)的元数据节点和存储节点以及新的目录条目(“B.txt”的目录条目)的元数据节点和存储节点。因此,可使用如下所述的至少两种原子操作的序列来实现被设计来承受参与者节点中的任一个处的可能故障和/或通信延迟的重命名工作流。序列的每种原子操作可能局限于一个元数据节点,并且可因此比多节点原子操作容易实现。需注意,所涉及的每个元数据节点(和/或存储节点)可被配置来管理众多文件存储对象的元数据,潜在地属于多租户环境中的存储服务的众多客户端,并且因此,每个元数据或存储节点可必须并行地处理大数量的重命名请求和其他文件存储操作请求。
在一些实施方案中,为了防止不一致性和/或元数据损坏,可在重命名工作流期间锁定(例如,使用排它锁)诸如目录条目的元数据结构。在至少一些实施方案中,为了防止死锁(如在例如在时间上非常接近地接收两个重命名请求“将A.txt重命名为B.txt”和“将B.txt重命名为A.txt”的情况下可能潜在发生的),可采用锁定排序协议。图40示出根据至少一些实施方案的用于并行重命名操作的这种死锁避免机制的使用。在所描绘实施方案中,死锁避免分析器模块4004(例如,元数据子系统的子部件)可将重命名请求的操作数4001(例如,“将X重命名为Y”请求的操作数“X”和“Y”)看作输入,并且生成特定锁获取次序。
在所描绘实施方案中,相对于“将X重命名为Y”请求示出两个替代锁获取序列4010和4012,其中精确地一个可被死锁避免分析器模块4004生成为输出。根据获取序列4010,将作为重命名工作流的第一原子操作的一部分获得X的目录条目上的锁。根据获取序列4012,将在重命名工作流的第一原子操作中获得Y的目录条目(必要的话在创建目录条目之后)。在所描绘实施方案中,死锁避免模块可使用名称比较器4008来达到锁序列。可例如按字典次序比较两个操作数,并且在至少一些实施方案中,按字典顺次排第一的操作数可被选为将在第一原子操作中被锁定的操作数。(在其他实施方案中,按字典次序排第二的操作数可先被锁定;只要排序逻辑跨不同重命名操作一致地应用,哪一个具体操作数先被锁定可不重要。)因此,在此类实施方案中,相同目录条目可先被锁定,而不管重命名请求是“将X重命名为Y”还是“将Y重命名为X”。以此方式,即使接近并行地接收两个请求“将X重命名为Y”和“将Y重命名为X”,仍可避免死锁,因为X不可能针对第一请求被锁定并且Y不可能针对第二请求被锁定。在一些实施方案中,可使用除了字典式比较之外的技术来确定重命名操作之间的锁次序。由于多个对象(例如,多个文件或目录)可在给定文件存储区内具有相同名称,而分配给DFS-索引节点的标识符可通常预期在文件存储区内为唯一的,在至少一些实施方案中,用作到比较器的输入的“名称”可通过级联或以其他方式将与对象相关联的所选择DFS-索引节点(例如,对象的母DFS-索引节点)的标识符与对象的名称组合起来来获得。可在其他实施方案中使用其他歧义消除技术来克服文件名称(或者目录名称)重新使用的潜在问题,例如,在一个实施方案中,从文件存储区的根部到对象的整个路径可被用作锁序列确定的“名称”,或者与若干路径目录相关联的DFS-索引节点标识符可与对象名称组合。
在至少一些实施方案中,基于死锁避免分析的输出,可针对给定重命名请求实现两个不同重命名工作流中的一个。两个工作流的不同之处可在于哪个目录条目先被锁定。重命名工作流中的每一个可被认为包括至少三阶段:原子性地执行的第一组操作(可集体称为工作流的“第一原子操作”),原子性地执行的第二组操作(可集体称为“第二原子操作”),以及针对其原子性可独立实现的第三组操作。如下所述,在一些情况下还可包括另外(通常异步)的阶段。图41是示出根据至少一些实施方案的可被执行来在两个可能锁排序中基于第一锁排序实现第一重命名工作流的操作的方面的流程图,所述锁排序可在存储服务处针对重命名操作确定。如元素4101所示,可例如在分布式存储服务的元数据子系统处接收将当前名称为“A”的特定文件存储对象诸如文件或目录重命名为“B”的请求。例如,访问子系统节点可从客户接收重命名命令,并且将对应内部重命名请求传输到所选择元数据节点。在服务的存储子系统用于元数据和数据两者的实施方案中,元数据节点可例如包括共同位于作为存储节点的相同硬件服务器处的过程或线程。“A”的目录条目可当前指向节点条目DI1,所述节点条目DI1包括对象的各种属性的值,诸如所有权识别、读取/写入权限等等。“B”的目录条目可能尚未存在。
可例如基于死锁避免分析做出“A”的目录条目上的锁是否将作为重命名工作流的部分先被获取,或者“B”的目录条目上的锁(其可能必须先被创建)是否将先被获取的确定(元素4104)。如果B的目录条目将先被锁定(元素4107),那么可使用图42中示出的工作流步骤,如图41中的标签“转到4201”指示的。如果“A”的条目将先被锁定(也如元素4107中确定的),那么可在存储服务的特定元数据节点MN1处尝试重命名工作流的第一原子操作(元素4110)。在所描绘实施方案中,第一原子操作可包括以下步骤:(a)获取“A”的目录条目上的锁L1;(b)为正尝试的工作流生成唯一的重命名工作流标识符WFID1,以及(c)存储指示当前名称为A的对象将被重命名为B的意图记录IR1。在至少一些实现方式中,意图记录可包括或指示工作流标识符WFID1。在一个实现方式中,可使用存储服务的状态管理子部件(例如,类似于图12中示出的复制状态机)来将三个步骤组合成一个原子操作。第一原子操作的三个步骤相对于彼此执行的次序可在不同实现方式中变化。在一些实施方案中,锁L1、意图记录IR1和/或工作流标识符WFID1的各自表示可各自例如使用如先前所述的存储子系统的盘区复本复制在持久存储装置上。在至少一个实施方案中,选择用于存储锁、意图记录和/或工作流标识符的持久存储位置可在MN1出故障的情况下可从替换元数据节点访问。在所描绘实施方案中,只要锁L1被保持,就没有其他修改可应用到“A”的目录条目。如果锁在第一原子操作被尝试时已经被保持(例如代表某一其他并行或接近并行的修改操作),那么第一原子操作可延迟直到锁变得可用。
如果初始原子操作成功,如元素4113中确定的,那么可尝试重命名工作流的第二原子操作。需注意,关于图41和图42中示出的工作流的原子操作中的每一个,在至少一些实施方案中,在第一次尝试时未能完成操作的情况下可重试一次或多次原子操作(例如,基于一些可配置最大重试计数)。可在指定来管理和/或存储“B”的目录条目的元数据节点(MN2)处执行第二原子操作。在一些实施方案中,在第一原子操作于MN1处完成之后,执行第二原子操作的请求可从MN1发送到MN2。在至少一些实现方式中,请求可包括工作流标识符WFID1。如元素4116中所示,第二原子操作可包括以下步骤:(a)代表某一其他修改操作验证“B”的目录条目当前未被锁定,(b)设置B的目录条目来指向正被重命名的对象的节点条目DI1,以及(c)存储指示对于具有标识符WFID1的工作流“B”的目录条目的指针修改步骤成功的记录。在至少一些情况下,“B”的目录条目可能在尝试第二原子操作时不存在,在这种情况下,可通过为“B”创建新的目录条目来隐含地实现验证“B”的目录条目未锁定的步骤。在至少一些实施方案中,在指针修改之前,在B的目录条目上可需要锁例如以便防止“B”的目录条目的任何并行修改。在一些此类实施方案中,锁可在到DI1的指针被设置之后释放。如写入作为第一原子操作的部分执行的情况下,第二原子操作(例如,指针的设置和成功指示)的写入可在持久存储位置诸如复制盘区处执行,在MN2处出故障的情况下可从所述持久存储位置稍后读取所述写入。可使用存储服务的状态管理子部件来强制写入的组合的原子性。
如果第二原子操作成功(如元素4119中确定的),那么可尝试第三组操作(元素4122)。如同第一原子操作一样,此第三组操作也可在MN1处执行。在至少一些实施方案中,在MN1处接收的第二原子操作成功的指示(例如,对从MN1发送到MN2的针对第二原子操作的请求的响应)可触发第三组操作。在第三组操作中,可删除“A”的目录条目上获取的锁L1,可删除意图记录IR1,并且可删除“A”的目录条目自身。如前所述,在一些实现方式中,此第三组操作还可作为原子单元执行,并且在此类情况下,第三组操作可称为工作流的“第三原子操作”。在其他实现方式中,可不针对第三组操作强制原子性。在第一原子操作期间生成的元数据(例如,意图记录、工作流标识符,以及锁的指示)存储于持久性存储装置中的实施方案中,第三组操作可预期最终成功,即使由于各种种类的故障而需要一个或多个重试亦是如此,而不管第三组是否原子性地执行。如果第三组操作也成功(如元素4125中检测的),那么重命名工作流作为整体可视为成功(元素4128)。在至少一些实施方案中,可发送指示重命名成功的对重命名请求的响应。在一些实施方案中,可不发送响应,和请求者。
在所描绘实施方案中,如果两个原子操作中的没有一个成功,那么工作流作为整体可中止(元素4131),并且可删除在工作流的先前部分中生成的记录中的任一个(诸如,意图记录IR1、锁L1的获取的表示和/或存储在MN2处的成功记录)。如果第三组操作的任何操作失败(如元素4125中检测的),那么在所描绘实施方案中它可简单重试,如指回元素4122的箭头指示的。如前所述,在至少一些实施方案中,可在宣告失败之前针对原子操作中的每一个进行多次尝试。在一些实施方案中,在具有标识符WFID1的工作流的第三组操作完成之后的某一点,可例如相对于第三组操作的完成异步地删除存储在MN2处的成功记录(元素4134)。
如图41的元素4107的负输出中指示的,如果“B”的目录条目将先被锁定,那么可尝试不同的重命名工作流。图42是示出根据至少一些实施方案的可被执行来在两个可能锁排序中基于这种第二锁排序实现第二重命名工作流的操作的方面的流程图,所述锁排序可在存储服务处针对重命名操作确定。在所描绘实施方案中,此第二工作流还可包括将用于将“A”重命名为“B”的两个连续的原子操作,之后是取决于实现方式可原子性地实现或者可不原子性地实现的第三组操作。在元数据节点MN2(节点负责存储对象名称“B”的目录条目)处执行的第一原子操作(图42的元素4201)可包括:验证“B”的目录条目针对某一其他操作未锁定,如果需要的话创建“B”的目录条目,锁定“B”的目录条目,生成并存储重命名工作流的唯一工作流标识符WFID2,以及存储指示当前名称为“A”的对象将被重命名为“B”的意图记录IR2。在一些实现方式中,意图记录IR2可包括或指示工作流标识符WFID2。
如果第一原子操作成功(如元素4204中检测的),那么可尝试工作流WFID2的第二原子操作(元素4207)。此第二原子操作可在“A”的目录条目在其处被管理的元数据节点MN1处执行,并且在一些实施方案中可由来自MN2的指示第一原子操作已成功的请求触发。第二原子操作可包括:验证A的目录条目未锁定,删除“A”的目录条目,以及存储“A”的目录条目已作为工作流WFID2的部分成功删除的持久性记录。如果第二原子操作成功(如元素4210中确定的),那么可在MN2处尝试第三组操作(元素4213)。在一些实施方案中,第二原子操作成功的指示(例如,在MN2处接收的对先前从MN2发送到MN1的针对第二原子操作的请求的响应)可触发执行第三组操作的尝试。第三组操作可包括:设置“B”的目录条目来指向DI1(正重命名的对象的节点条目),释放/删除锁L2,以及删除意图记录IR2。
如果第三组操作成功(如元素4216中检测的),那么工作流作为整体可视为成功(元素4219),并且在一些实施方案中,成功指示符可返回到重命名操作的请求者。如在图41中示出的工作流中,图42的第三组操作可预期最终成功,但在失败情境中可能需要一个或多个重试,如从元素4216指回元素4213的箭头指示的。在至少一些实施方案中,可相对于第三组操作的完成异步地删除由MN1存储的成功记录(指示“A”的目录条目已删除)自身(元素4225)。如果两个原子操作中的任一个失败,那么重命名工作流作为整体可中止(元素4222),并且可清除在中止工作流的先前操作期间存储的记录。如在图41中示出的操作中,存储服务的状态管理机制和/或复制盘区可用于第二工作流的原子操作。
使用图41和图42中示出的死锁避免锁排序序列和操作,可实现文件存储对象的重命名操作来实现正使用的文件系统协议预期的期望一致性水平。将与唯一的工作流标识符相关联的意图记录存储在持久性存储装置中的技术可帮助在不同实施方案中从各种类型的故障恢复。图43是示出根据至少一些实施方案的可响应于参与重命名工作流的一对元数据子系统节点的一个元数据子系统节点的故障而执行的恢复操作的方面的流程图,而图44是示出根据至少一些实施方案的可响应于参与重命名工作流的所述对元数据子系统节点的另一个元数据子系统节点的故障而执行的恢复操作的方面的流程图。为了简化展示,图43和图44各自示出可在图41中示出的工作流序列期间发生单个元数据节点故障的情况下执行的操作,但在至少一些实施方案中即使工作流中所涉及的两个元数据节点都出故障,仍可采用类似恢复策略。
如图43的元素4301所示,可在图41的工作流序列的第一原子操作(其步骤在元素4110中示出)完成之后并且在图41的工作序列的第三组操作(元素4122)开始之前的某一点检测节点MN1的故障。例如,实现管理“A”的目录条目的元数据节点MN1的过程或线程可过早地退出,或者MN1可由于网络相关的故障或者由于导致暂停的软件错误而变得对健康检查无响应。在所描绘实施方案中,在此类环境下,替换元数据节点MN-R可被配置或指定来接管MN1的责任(元素4304)。在一些实施方案中,如前所述,MN1可已被配置为包括多个元数据节点的冗余组的成员,并且预先配置用于故障转移的冗余组的另一成员可快速地被指定为替换。在其他实施方案中,替换元数据节点MN-R可以不是预先配置的冗余组的部分。
在图41的工作流的第一原子操作中,MN-1将意图记录IR1和工作流标识符WFID1与锁L1的表示一起存储在持久性存储装置中。替换元数据节点MN-R可读取在MN-1的故障之前写入的意图记录IR1和工作流标识符WFID1(元素4307)。在所描绘实施方案中,MN-R可随后向MN2(负责“B”的目录条目的元数据节点)发送查询以便确定工作流WFID1的状态(元素4310),例如,以便找出B的目录条目指针是否已经被设置来指向DI1(正重命名的对象的节点条目)作为工作流的第二原子操作的部分。
如前所述,在分布式存储服务为多租户的实施方案中,每个元数据节点可负责管理若干不同文件和/或若干不同客户端的元数据。因此,MN2可已存储对应于众多重命名工作流的第二原子操作的各自成功记录。在接收关于具有标识符WFID1的工作流的状态的查询之后,MN2可查找其成功原子操作的记录。如果MN2找到WFID1的第二原子操作的成功记录(如元素4313中确定的),那么其可通知MN-R第二原子操作完成(即,“B”的目录条目被设置来指向节点条目DI1)。因此,在所描绘实施方案中,MN-R可随后尝试第三组操作企图完成由WFID1识别的重命名工作流(元素4316)。
至少在一些情景中,情况可能是工作流WFID1的第二原子操作未成功。例如,MN1可能在其到MN2的开始第二原子操作的请求成功传输之前已经出故障,或者请求可能已经丢失,或者MN2可能不能成功实现所请求的第二原子操作。在一些实施方案中,如果MN-R得到第二原子操作未成功(也如元素4313中确定的)的通知,那么MN-R可具有放弃或恢复工作流的选项。在所描绘实施方案中,如果满足取消准则(如元素4319中检测的),那么可中止重命名工作流并且可移除与由MN1存储的WFID1相关联的元数据记录(例如,可将意图记录IR1和锁L1的表示从持久性存储装置删除)(元素4322)。在一个实施方案中,如果自从客户端接收原始重命名请求以来消逝的时间超过某一配置阈值,那么可满足取消准则。可例如在这种假设下实现重命名工作流的取决于流逝时间的终止:鉴于长的流逝时间,请求重命名的客户端将认识到原始请求未成功,并且将因此不预期重命名在此刻成功。在一些实施方案中,指示具有标识符WFID1的工作流已中止/取消的取消记录可在某一可配置时间段内存储在例如MN-R、MN2处或者MN-R和MN2两者处。在一个这种实施方案中,在确定工作流将中止之后,MN-R可首先向MN2发送请求以存储取消记录,并且可在其得到MN2已经成功地将取消记录存储到持久性存储装置的通知之后删除意图记录和锁两者。
然而,如果未满足取消准则(也如元素4319中检测的),那么在所描绘实施方案中,MN-R可通过向MN2发送请求以实现第二原子操作来恢复工作流(元素4325)。可在各种实施方案中实现对MN1故障做出响应的其他策略,例如,在一些实施方案中,重命名工作流可总被恢复而不管自接收初始重命名请求以来流逝的时间,并且在至少一个实施方案中,重命名工作流可总被中止,若MN1在第一原子操作完成之后出故障。
图44示出根据至少一些实施方案的可在元数据节点MN2在图41中示出的工作流序列期间出故障的情况下执行的操作。如元素4401所示,可例如在实现工作流的第二原子操作(元素4116)的请求发送到MN2之后检测MN2的故障。以类似于以上论述用于由MN-R替换MN1的方式,在所描绘实施方案中,可针对MN-R指定或配置替换元数据节点MN-R2(元素4404)。MN-R2可能够读取由MN2在其出故障之前写入到持久性存储装置的成功记录。
在MN-R2处,可从MN1接收查询来使MN1能够确定具有标识符WFID1的工作流的第二原子操作是否成功完成(元素4407)。如果第二原子操作已在MN2的故障之前完成(如元素4410中检测的),那么MN-R2可能够找到WFID1的成功记录,并且可因此对MN1做出响应。MN1可随后通过尝试第三组操作来恢复工作流(元素4413)。
如果WFID1的第二原子操作未完成,那么可在图44中描绘的实施方案中实现与图43中实现的程序类似的程序。如果满足重命名操作的取消准则(如元素4416中检测的),例如,如果自请求重命名以来消逝的时间超过某一阈值时间T,那么可中止重命名操作并且可清除与WFID1相关的数据结构(元素4419)。否则,如果未满足取消准则,那么可由MN1通过向MN-R2发送执行第二原子操作的请求来恢复工作流(元素4422)。
虽然图43和图44示出响应于图41的工作流期间任一元数据节点处的故障的恢复技术,但在至少一些实施方案中,类似技术还可在任一元数据节点在图42中示出的工作流期间出故障的情况下实现。只要配置用于故障的元数据节点的替换节点能够从持久性存储装置读取工作流记录(例如,意图记录、锁和/或成功记录),就可能在失败之后恢复工作流。例如,在图42的工作流中,如果MN2在第一原子操作之后失败并且指定替换MNR-2,那么MNR2可读取意图记录IR2和工作流标识符WFID2并且发送关于MN1的状态查询,等等。以类似于图43和图44中示出的方式,取决于检测失败和配置替换节点花费多长时间以及重命名工作流在失败之前进行多少进程,在一些情况下,可在元数据节点出故障之后放弃图42的重命名工作流。在使用与用于数据的基础存储子系统相同的基础存储子系统存储元数据的实施方案中,也可使用类似于图43和图44中示出的那些的恢复技术来对存储节点故障做出响应。在一些实施方案中,可在同一主机或硬件服务器处执行元数据节点和存储节点的功能,并且因此该主机或服务器的故障可影响两种类型的节点。
可缩放命名空间管理
在各种实施方案中,分布式存储服务的目标可包括以可缩放方式处理非常大数量的文件、目录、链接和/或其他对象。例如,对于一些大客户,给定文件系统可包括一百万或更多的目录,并且给定目录可包括一百万或更多的文件。在一些实施方案中,为了支持高吞吐量,和/或为了确保在命名空间中的对象的数量增加到此类水平时在高并行性下各种命名空间操作(诸如目录列表、查询、插入和删除)的响应时间保持相对平坦,称为散列的有向无环图(HDAG)的数据结构可用于管理命名空间条目。术语命名空间在本文中用于指代在给定文件系统或其他数据存储逻辑容器内创建的对象(文件、目录、硬和软链接等等)的名称的集合,并且指代对象之间的关系(例如,母子关系)。在一些实施方案中,例如可由服务的元数据子系统针对文件系统的每个目录生成各自HDAG。以下描述的基于HDAG的命名空间管理技术可利用先前已描述的分布式存储服务的一些特征,诸如元数据结构在可配置粒度下跨多个存储盘区的条带化以及在单个原子操作中在多个存储装置处执行修改的能力。例如,在一个实现方式中,各自逻辑块(可映射到各自盘区的一个或多个页面)可用于特定HDAG的每个节点,因此潜在地在多个存储服务器之间划分命名空间条目。
图45示出根据至少一些实施方案的可用于文件存储命名空间管理的散列有向无环图(HDAG)的实例。在所描绘实施方案中,目录的HDAG可包括至少两种类型的节点:条目列表(EL)节点(其中的每一个包括类似于图39中示出的DFS-目录条目结构的目录条目列表,具有到包含对应对象的其他属性值的各自DFS-索引节点的指针),以及节点标识符阵列(NI阵列)节点(其中的每一个包括到一组子节点的指针阵列)。节点的类型可在报头字段诸如报头字段4504A或4520A中指示。当创建目录D1时,可为目录创建包括单个EL节点(诸如节点4500A,称为HDAG的根节点)的处于初始状态4590A的HDAG。在一些实现方式中,目录的DFS-索引节点可自身用作HDAG的根节点。根节点4500A可包括足够的空间来保持某一组目录属性4502A、指示根节点类型(最初EL)的报头字段4520R以及在D1内创建的前几个文件或子目录的根条目列表4506。给定EL节点可存储多达某一可配置数量(例如,可针对给定文件存储区的所有EL条目选择的值)的命名空间条目,并且给定NI阵列节点可存储多达某一可配置数量的节点标识符(例如,针对给定文件存储区的所有NI阵列条目选择的另一值)。在至少一些实施方案中,HDAG节点的最大可允许大小可确定,使得一个HDAG节点的内容可在单个原子操作中写入到存储装置,例如,在一个实现方式中,如果HDAG参数被选择使得HDAG节点决不占据多于4千字节,那么支持4千字节页面的盘区可用于HDAG,和/或4千字节的逻辑块大小可使用。在其他实现方式中,可使用HDAG、逻辑块大小以及页面大小之间的其他映射。
在更多文件或子目录添加在D1内时(如由箭头4525指示的),根条目列表4506可最终变满,并且根节点4500A可使用散列函数分成某一数量的子节点以便将其条目列表成员分布到子节点。根节点的类型可从EL变成NI阵列,并且到子节点的指针(例如,存储子节点的逻辑或物理存储地址)可写入到根节点处的NI阵列中的各自元素。选择的强散列函数可应用到条目名称中的每一个(例如,文件名称或子目录名称)以便产生具有期望大小的散列值,并且给定条目的散列值的位序列表示的部分可用于将条目映射到新的子节点。在各种实施方案中,可使用条目在新创建的子节点之间类似基于散列的分布在非根节点填满时在所述非根节点上实现若干类型的分裂操作(以下详细描述)。响应于查找请求,相同散列函数还可用于搜索指定对象名称的条目,例如将散列值的位序列表示的连续子序列用作导航HDAG的各自级别直到找到具有目标条目的节点的索引。为了获得目录列表,可递归地遵循从根节点的NI阵列开始的所有指针(假设根节点已分裂)直到已遍历整个HDAG并且已检索其所有条目。以下提供关于各种类型的HDAG操作的另外细节。
条目列表节点的类型可由于在一些条件下的一种或多种类型的HDAG操作改变,例如,根节点4500A已在其条目分布在子节点之间之后变成NI阵列节点(并且如以下更详细描述的,在一些情况下NI阵列节点可在删除之后转换成条目列表节点)。NI阵列4510A包括处于HDAG状态4590B的子节点4550A、4550B和4550C的指针(例如,存储地址)。最初在根条目列表4506中的条目可初始分布在子节点处的各自条目列表之间(例如,节点4550A的条目列表4522A,节点4550C的条目列表4522B,以及在节点4550B处初始创建的另一条目列表)。因此,子节点4550A、4550B和4550C中的每一个可作为EL节点开始。然而,在实现状态4590B时,节点4550B自身已分裂并变成NI阵列节点,其中到其自己的子节点4550K和4550L的指针存储在NI阵列4510B中。节点4550L在状态4590B下也已从EL改变状态为NI阵列,并且其NI阵列4510C包括到其子节点的指针。节点4550K仍然保持为EL节点,其中条目列表4522K表示在D1内创建的文件/目录中的一些。在所描绘实施方案中,在并且如果节点的类型由于节点分裂(或者在一些类型的条目删除之后的节点加入)而改变时,可修改节点中的每一个的报头(例如,报头4520R、4520A、4520B等)。在一些实现方式中,至少在一些时间点处,根节点4500A和/或其他HDAG节点可包括不使用的某一数量的字节。在状态4590B下,HDAG可被认为是包括至少三个“级别”,包括:根级别;HDAG级别1(包括可在单个查找中使用根节点的NI阵列指针访问的节点4550A、4550B和4550C);以及HDAG级别2(包括可在单个查找中使用级别1节点的NI阵列指针访问的节点4550K和4550L)。术语“HDAG级别”在本文中可用作从HDAG的根节点开始到达到某一特定节点已遇到的节点的数量的指示。没有子代的HDAG节点可被称为叶节点。至少在一些实施方案中,对于HDAG的两个叶节点L1和L2情况可能是在从HDAG根朝向叶节点的各自遍历期间,在到达L1之前可遇到与到达L2之前遇到的不同数量的节点。需注意,在图45中示出的实施方案中,用于在节点之间分布条目并且此后查找条目的散列值可能不需要存储在HDAG自身内。
如前所述,命名空间管理技术的一个目标可以是使能够通过名称快速查找。图46示出根据至少一些实施方案的使用针对文件名获得的散列值的连续子序列导航HDAG的技术。(类似技术可用于目录、链接或者其他文件存储对象)文件的名称4602用作到所选择散列函数4604的输入,例如,响应于具有名称作为参数的查找请求。在一些实施方案中,多达K(例如,255)个UTF-8字符的字符串可用作文件名称或目录名称。在其他实施方案中可使用文件存储对象名称的其他长度限制或编码。在一个实施方案中,不同散列函数可用于各自文件存储区,例如,散列函数可指定为配置参数,或者可由存储服务基于文件存储区的命名空间大小的期望值、由代表其创建文件存储区的客户端提供的提示等等选择。在至少一个实施方案中,可随时间跟踪使用的散列函数的有效性的各种度量,诸如给定数量的命名空间条目的HDAG的级别的平均数量,或者HDAG被平衡的程度(例如,一些条目是否通过经过远远小于其他的级别来实现),并且如果测量的有效性不足够则可选择(至少为了未来使用)不同的散列函数。
在所描绘实施方案中,可生成可表示为(至少)N*M位的序列的散列值4610,其中N和M可以是可配置参数。M位的散列值4610的N个子序列(例如,S1、S2……SN)可各自用作到HDAG的对应级别中的索引,例如子序列S1可用于选择将用于导航级别1的NI阵列指针(根节点的),子序列S2可用于选择将用于从级别1节点开始导航级别2的NI阵列指针,等等。给定子序列中并非所有位需要用于给定搜索或导航级别,例如,在一些情况下可仅使用q高阶位(其中q<M)。在一些实施方案中,散列值的一些位4666可不用于任何级别。
当新的条目将添加到文件存储区时,例如,响应于打开文件命令或创建目录命令,可获得新条目的名称的散列值,并且可使用上述基于子序列的导航技术遍历HDAG直到找到名称映射到的候选者EL节点。(在一些情境中,情况可能是命名空间已用光条目的空间,以下论述此类特殊情况)。如果候选者节点在其条目列表中不具有更多自由空间,或者其自由空间将在添加新条目的情况下降至低于阈值水平,那么候选者节点可分裂。分裂的节点的条目中的至少一些可例如使用如下所述的条目的散列值的选择子序列分布在添加到HDAG的一个或多个新的节点之间。在一些实施方案中,可执行至少两种不同类型的HDAG节点分裂操作。
图47示出根据至少一些实施方案的可由尝试将条目插入命名空间引起的两种类型的HDAG节点分裂中的第一种的实例。在第一种类型的分裂中,HDAG节点的类型可如以下详细描述的从条目列表(EL)改变为NI阵列。在一些实施方案中,命名空间条目插入可以是响应于客户端请求创建命名空间对象诸如文件而进行的若干步骤中的一个,例如,其他步骤可包括:为与文件相关联的DFS-索引节点对象分配空间,设置文件的初始属性和/或设置从命名空间条目到DFS-索引节点以及从索引节点到将用于存储文件内容的一个或多个物理页面的指针。进行这些步骤的次序可在不同实施方案中不同。
在图47中示出的实施方案中接收将具有名称(例如,文件名称)“Lima”的条目4701插入命名空间中的请求,并且在为目录创建的HDAG内导航之后找到候选者EL节点4750A,正尝试将具有名称“Lima”的对象插入所述目录。HDAG节点的标识符的初始部分(还可对应于其存储地址,并因此可用作指向存储子系统的读取或写入操作的参数)在图47中被示出为十六进制字符串,例如,节点4750具有ID“0x432d12...”。在所描绘实施方案中可在以下条件下尝试图47中示出的第一类型的节点分裂:(a)候选者节点4750A是根节点,或者(b)节点4750A的母节点中仅一个NI阵列指针条目(图47中未示出)指向节点4750A。在所描绘实施方案中,如果满足这些条件中的任一个,那么可为两个新的HDAG节点4750B和4750C分配空间(例如,在各自元数据盘区处)。(需注意,为了便于展示,图47中示出两个子节点,在其他实施方案中,在分裂期间可创建多于两个新的子节点)。先前位于节点4750A中的条目中的每一个(例如,“Alpha”、“Bravo”、“Charlie”等),以及新的条目“Lima”可基于其各自散列值映射到新节点4750B或4750C中的一个,如标记为“1”的箭头指示的。在一个实现方式中,例如,如果候选者节点在HDAG的第K级中,那么条目的散列值的第(K+1)子序列可基于其最高有效位排序,并且散列值具有“1”作为其最高有效位的条目可映射到节点4750B,而散列值具有“0”作为其最高有效位的条目可映射到节点4750C。在分裂期间创建多于两个子节点的实施方案中,更多位可用于条目的映射,-例如,如果创建四个子节点,那么可使用散列子序列值的两个最高阶位,等等。在所描绘实施方案中,取决于例如对象名称和散列函数,可能不总是分裂的节点(所描绘实例中的4750A)的条目均匀分布在子节点之间的情况,并且至少在一些实施方案中,可能不尝试通过试图实现这种均匀性来“平衡”HDAG。相反,在此类实施方案中可依赖散列函数的强度和质量来实现条目在节点之间的合理平衡的分布。在所描绘实例中,在条目在子节点之间分布之后,子节点4750B具有可用于随后插入的自由空间4710A,而子节点4750C具有可用于随后插入的自由空间4710B。
在分裂之前为EL节点的节点4750A可转换成NI阵列节点,如图47中标记为“2”的箭头指示的。其NI阵列条目的一半可设置来指向节点4750B(例如,通过存储4750B的ID 0x786aa2...)并且另一半可设置来指向节点4750C(例如,通过存储4750C的ID 0xc32176...)。在最高有效位用于分裂条目的实现方式中,NI阵列条目的下半部(例如,具有0至(NI阵列大小/2)-1)的索引的条目可设置来指向节点4750C(散列值以“0”开始的条目),并且NI阵列条目的上半部(例如,具有(NI阵列大小/2)至(NI阵列大小-1)的索引的条目)可设置来指向另一子节点4750C。在n个子节点由于分裂而创建的实施方案中,NI阵列条目的1/n可设置来指向子代中的每一个。三个节点4750A、4750B和4750C的改变可保存到存储子系统处的持久性存储装置。在一些实施方案中,所有三个节点的改变可例如使用前述分布式事务技术在单个原子操作中执行。在其他实施方案中,前述有条件写入可用于使三个节点中的至少一个的改变独立于其他节点持久。
如果未满足以上列出的用于执行第一类型的分列操作的条件(例如,如果候选者节点的母节点具有到候选者节点的多于一个的NI阵列指针),那么可执行第二类型的分裂操作。图48示出根据至少一些实施方案的可由尝试将条目插入命名空间引起的两种类型的HDAG节点分裂中的第二种的实例。在所描绘实例中,节点4750C已被识别为用于新条目“Queen”4801的候选者节点,并且节点4750C在其条目列表中不留自由空间。母节点4750A在尝试“Queen”的插入时包括到节点4750C的众多指针(例如,具有ID值0xc32176...的NI阵列条目)。如具有相同值“0x786aa2...”的多个元素和具有值“0x32176...”的多个元素指示的,在所描绘实施方案中,NI阵列元素各自指向存储节点的内容的块,不指向节点内的单独EL条目。在其他实施方案中,可代替或者除了块级指针之外使用条目级指针。在图48中描绘的情境中,代替图47中示出的两个节点,仅创建一个新的节点(具有ID0x223123...的节点4850A)。可以类似于用于图47中的4750A条目的方式计算节点4750C的条目的散列值。可基于最高有效位排序散列值。4750C中的条目中在分裂时具有“1”作为最高有效位的那些可映射到新的节点4850A,而剩余的(具有“0”作为最高有效位的条目)可保持在节点4750C内,如标记为1的箭头指示的。
在所描绘实施方案中,母节点的NI阵列条目可修改来添加到新添加节点4850A的指针,如箭头2指示的。先前指向4750C的4750ANI阵列条目中的一半(例如,阵列索引范围的上半部)可设置来指向新节点4850A,而另一半可继续指向4750C。因此,在分裂之后,在节点4750A的NI阵列条目之间,一半可包含4750B的ID(其在分裂中不受影响),四分之一可指向4750C,并且四分之一可指向4850A。如以上论述的第一类型的节点分裂的情况下,在一些实施方案中,EL满的候选者节点4750C的条目可重新分布在多于两个节点(包括候选者节点自身)之间,例如,总共4个节点可通过使用条目散列值的2位用于分布。在一些情况下,给定节点的分裂可必须向上朝向HDAG的根传播,例如,节点N1可必须由于插入分裂,因此,N1的母代还可必须分裂等等。在此类情况下可必须从HDAG的根开始重复遍历HDAG到达候选者节点的过程。
图47和图48中示出的分列操作假设在尝试分裂时可将新的级别(例如,新的子指针)添加到HDAG。然而,在至少一些实施方案中,例如基于用于导航HDAG的每个级别的散列值大小和位数量,在某一刻,可达到散列函数允许的级别的最大数量,并且可不添加更多级别。在这种情境中,代替执行图47和图48中示出的基于散列的分裂,可创建不能有基于散列的分裂适应的新条目的链或链接列表(例如,使用第三类型的HDAG节点)。例如,在图48中,如果在进行尝试插入节点“Tom”时节点4850变满并且已达到级别数量的限制,那么可创建新类型的节点“链”来存储“Tom”的条目,并且可在候选者节点中的选择位置处插入到链节点的指针。如果需要的话可修改链节点自身来指向其他链节点。为了定位已包括在链节点中的任何给定条目,那么可代替如其他类型的节点处使用的基于散列的查找使用链的顺序扫描。以此方式,即使HDAG变得“不平衡”可容纳大数量的条目,尽管当然可能失去基于散列的遍历的一些速度优势,因为可必须针对查找顺序地遍历链条目。在各种实施方案中,合理长散列值和强散列函数的选择可减小必须使用链节点的概率来低于可接受阈值。
当将删除命名空间条目E时(例如,当按客户端请求删除对应文件或目录),可使用以上列出的基于散列的遍历技术找到将从其删除条目的EL节点,其中对象的名称的散列值的各自子序列用作HDAG的连续级别处的索引。将从其移除条目的EL节点可被称为删除目标节点。如果删除目标包含多于一个条目,那么E的条目可简单地删除或标记为自由,并且可能不需要另外的操作。然而,如果在删除目标处不存在其他命名空间条目(即,如果移除E的条目将导致空的条目列表),那么删除目标节点自身可能必须被删除。图49示出根据至少一些实施方案的两种类型的HDAG节点删除操作中的第一种的实例。在所描绘实例中,接收从由HDAG表示的命名空间删除“Juliet”的请求。计算“Juliet”的散列值,并且使用散列值的连续子序列来从HDAG的根导航朝向节点4950。节点4950是具有单个条目(将删除的“Juliet”的条目)剩余的EL节点。可删除Juliet条目(如由“X”符号和随附标签“1”指示的)。因为移除Juliet的条目导致节点4950的空条目列表,可能必须删除节点4950自身。删除节点4950对其母节点4948的后果可取决于节点4948的NI阵列列表的状态而不同。
在所描绘实施方案中,删除目标节点的母节点可通常具有指向删除目标节点的一个或多个NI阵列元素(可被称为“删除目标指针”),以及指向除了删除目标节点之外的节点的零个或多个NI阵列元素。指向除了删除目标节点之外的节点并且接下来指向NI阵列内的删除目标指针(例如,紧邻阵列内的下部索引)的那些NI阵列元素可被称为删除目标指针的“邻居”。在所描绘实施方案中,如果在删除删除目标节点的最后一个条目时在4948的NI阵列列表中存在至少一个邻居,那么可简单地将邻居指针值复制到删除目标指针中。在图49中描绘的情境中,例如,在母节点4948中存在指向删除目标节点4950的两个删除目标指针4901和4902(如由4950的ID 0xc44321...存储在4901和4902中的事实指示的)。另外,母节点4948的NI阵列包括存储节点ID 0x32176...的邻居元素4903。因此,如由标记为2的箭头指示的,当Juliet条目的删除导致删除目标节点4950处的空条目列表,并且母节点4948在其NI阵列中包括至少一个邻居时,将那个邻居的内容复制到先前指向删除目标节点4950的NI阵列条目。另外,在所描绘实施方案中,可例如通过向存储子系统发送释放其存储空间的请求使删除目标节点4950自由。箭头4904指示邻居指针的内容替换删除目标指针阵列元素的内容。需注意,在不同实施方案中,不同技术可用于指定删除目标指针的邻居,在一些实施方案中,例如具有NI阵列内的下一较高索引的NI阵列条目可被选为邻居。
如果在删除目标节点的母节点的NI阵列条目中不存在邻居,那么在一些实施方案中可以不同方式识别母节点。图50示出根据至少一些实施方案的两种类型的HDAG节点删除操作中的第二种的实例。如图所示,删除目标节点4950在其条目列表中包括单个条目。删除那个唯一剩余的条目(“Juliet”),如由“X”符号和随附标签“1”指示的。在所描绘示例性情境中,母节点4948的NI阵列不包含任何邻居元素(即,不指向删除目标节点的NI阵列元素)。图49中示出的方法可因此不可行,因为不存在可用的邻居指针值。因此,可采取不同方法,如标记为“2”的箭头示出的:可将母节点4948的类型改变为EL(条目列表)而不是NI阵列,并且可针对节点4948初始化空条目列表。例如,在由于前述类型的分裂操作将新节点添加到HDAG时,可重新使用新近初始化的EL节点。可以类似于以上关于图49论述的方式使删除目标节点4950自由。在各种实施方案中,HDAG的给定级别处进行的修改可在一些情况下需要其他级别处的改变,例如,在一个实施方案中,当如上所述改变节点4848的类型时,可必须修改4848的母节点的NI阵列条目,并且改变的效果可向上朝向HDAG的根传播。如前所述,在各种实施方案中,可使用前述有条件写入技术和/或分布式事务技术来组合由给定插入或删除引起的期望数量的HDAG改变成原子操作。
图51是示出根据至少一些实施方案的可响应于导致第一类型的HDAG节点分裂的将条目插入命名空间而执行的操作的方面的流程图。图47中提供这种分裂操作的简单实例。如元素5101所示,接收向分布式多租户存储服务的命名空间添加条目E的请求。可例如响应于由在服务处实现的文件系统的客户端发布的创建文件“Fname”或打开文件“Fname”的命令而生成所述请求。在一个实施方案中,可在特定元数据子系统节点处的命令解释程序部件处生成请求,并且可在另一元数据子系统节点(或者同一元数据子系统节点)处的命名空间管理器部件处接收所述请求。散列函数可选择用于目标文件系统的命名空间管理(例如,基于散列函数的强度、文件存储区的预期大小和/或性能要求,和/或其他因素)。可使用散列函数来生成对应于“Fname”的散列值Hvalue,其中Hvalue可表示为各自具有M位的N个子序列(元素5104)。在一个实现方式中,例如,Hvalue可包括各自具有8位的8个子序列,因此消耗至少64位。
包括至少两种类型的节点(如前述的节点标识符阵列(NI阵列)节点和条目列表(EL)节点)的HDAG可建立用于命名空间,例如用于新文件Fname添加到的目录。在所描绘实施方案中,条目列表节点可能够容纳多达Max-EL个条目,其中Max-EL可取决于因素诸如受支持的对象名称的最大长度、存储在条目列表中的DFS-索引节点地址或标识符的长度、用于HDAG节点的字节的数量,等等。类似地,在所描绘实施方案中,NI阵列可能够容纳多达Max-NID个元素,其中Max-NID取决于节点ID的大小和HDAG节点的大小。在至少一个实施方案中,可指定条目的阈值填充量EL-阈值,使得如果条目的数量由于插入超过EL-阈值,那么将发起节点分裂。在一些实现方式中,EL-阈值的默认值可设置为Max-EL,例如,可仅在EL变满时实现分裂。类似地,在至少一个实施方案中,可为NI阵列节点限定阈值,例如,在节点处的NI阵列中的元素的数量超过NID-阈值时,NI阵列节点可分裂。在一些实施方案中,在默认情况下,NID-阈值可设置为Max-EL。在一些实现方式中,EL-阈值、NI-阈值中的任一个或El-阈值和NI-阈值两者可实现为可配置参数。
从HDAG的根部(第零级)开始可导航或遍历一个或多个HDAG级别(使用Hvalue的连续M位子序列来识别将在每个级别处检查的特定一个或多个节点)以便识别E应添加到的候选者节点CN(元素5107)。在至少一些实施方案中,HDAG的节点中的每一个可对应于不同逻辑块,并且不同存储子系统节点处的不同盘区用于其而不是其他HDAG节点的概率可以很高。如果未找到候选者节点(如果元数据子系统已用光HDAG的空间,那么其可在一些情况下发生)如元素5110中确定的),那么可返回错误(例如,“目录中允许的文件的最大数量已超过”)(元素5113)。如果找到候选者节点CN(也如元素5110中确定的),并且其条目列表具有足够空间来容纳新的条目E(例如,E的添加将不会导致EL长度超过EL-阈值)(如元素5116中检测的),那么可将新条目E写入到列表中当前未使用的条目中的一个(元素5119)。在所描绘实施方案中,对CN的修改可保存到持久性存储装置,例如,在一个或多个元数据盘区复本处。在至少一些实施方案中,DFS-索引节点结构可分配用于具有名称Fname的对象,并且到那个DFS-索引节点结构的指针可包括在E内。响应于针对“Fname”的随后查找请求,可使用类似于元素5104和5107中示出的基于散列的导航(即,针对“Fname”获得的散列值的各自子序列可用于HDAG导航的各自级别直到找到“Fname”的条目)。
如果CN节点不具有用于E的足够空间(例如,如果E的插入已达到或者将达到EL-阈值)(也如元素5116中检测的),那么可确定CN的母NI阵列列表中指向CN的指针的数量。如果母节点具有到CN的仅一个指针(或者恰好是HDAG的根节点)(如元素5122中检测的),那么可发起第一类型的节点分裂操作(类似于图47中示出的)。除了针对新条目E已经获得的Hvalue之外,可针对CN列表中条目的每一个中的对象名称获得各自散列值(元素5125)。在所描绘实施方案中,可使用散列值来将条目列表成员和E分布到P个组中(例如将散列值的log2P最高有效位用作排序/分布准则)(元素5128)。在一个示例性实现方式中,P可设置为2,因此可仅使用单个最高有效位。可将P个组中的每一个存储作为将添加到HDAG的各自新节点的条目列表(元素5131)。可创建新的NI阵列,其中阵列元素中的大约第1/P指向P个新节点中的每一个(例如,包含其存储地址或标识符)。可修改CN的报头来指示它是NI阵列节点而不是EL节点,并且可将新的NI阵列写入CN(元素5134)。HDAG的P个新节点和修改的CN的内容可保存到持久性存储装置,例如,在一个或多个存储子系统节点处。在一些实施方案中,可使用上述分布式事务技术来将对HDAG的改变的一些子集或全部组合到单个原子操作中。在其他实施方案中,上述类型的有条件写入可用于HDAG节点中的至少一些。
如果从CN的母节点指向CN的NI阵列元素的数量超过一(也如元素5122中检测的),那么可对CN进行第二类型的分裂操作(如图51的“转向5201”元素指示的)。图52是示出根据至少一些实施方案的可响应于导致这种第二类型的HDAG节点分裂的将条目插入命名空间而执行的操作的方面的流程图。在本文中这种类型的分裂可被指定为类型2分裂,并且图51中示出的分裂类型可称为类型1分裂。在类型2分裂中,CN的条目列表的成员中一些可移动到Q个新HDAGEL节点(其中Q不小于一),而一些可保持在CN中,并且母节点的NI阵列指针可相应地改变。在所描绘实施方案中,CN的条目列表的子列表可选择用于重新分布在Q个新HDAG节点NN1、NN2...NNQ之间以及CN自身中。在一个实现方式中,Q可设置为1并且大约(或准确地)一半条目列表可考虑用于重新分布,而在另一实现方式中,可考虑四分之三。可确定子类表的每个成员的各自散列值(元素5204)。可使用散列值来将子列表成员布置到Q+l个组中(例如将散列值的某一数量的最高有效位用作分布准则)(元素5207)。
Q个组可放置在各自的新HDAG EL节点中,而剩余的组可保持在CN内。可将CN的母节点中的NI阵列条目中的指向CN的一些设置来指向新节点NN1...NNQ(元素5210)。在所描绘实施方案中,可在单个原子操作中将由于分裂而修改或创建的HDAG节点(例如,Q个新节点,CN和CN的母节点)写入到持久性存储装置(元素5213)。在一些实施方案中可使用上述分布式事务技术。在其他实施方案中,可不使用单个原子操作;例如,有条件写入技术可用于HDAG节点中的至少一些。
需注意,在一些实施方案中条目列表成员在类型2分裂中重新分布的技术可不同于图52中示出的。例如,在一些实施方案中,可选择子列表成员,其方式为使得它们可完全分布在Q个新节点之间。在一些实施方案中,可随机选择子列表的大小,例如,并非所有在给定HDAG或在给定文件存储区实现的类型2分裂可导致相同数量的新节点。在一些实施方案中,随机元素也可引入类型1分裂中,例如,使用的EL-阈值可在范围内随机变化,或者新节点的数量P可随机从范围选择。
图53是示出根据至少一些实施方案的可响应于将条目从命名空间删除而执行的操作的方面的流程图。如元素5301所示,可接收将具有名称Fname的文件存储对象的条目E从分布式存储服务的命名空间移除的请求。例如,可由于移除文件或目录的客户端请求生成这种请求。使用选择的散列函数,可获得位序列可分成各自具有M个位的N个子序列的散列值Hvalue(元素5304)。
可从为命名空间生成的HDAG的根节点开始导航或遍历HDAG以便识别包含E的删除目标节点N1(元素5307)。在HDAG的每个级别处,可使用N个子序列的连续子序列来识别将读取或检查的节点。如果N1的条目列表包括至少一个或多个条目(如元素5310中检测的),那么可简单地将E在条目列表内的缝隙标记为未使用或自由(元素5313),并且可完成删除操作。在一些实现方式中,例如,为了更快地找到非空条目,可将自由条目移动到列表的一端。因此,例如,如果具有长度N的条目列表包含两个非空条目,那么在一个这种实现方式中,将在列表内的偏移0和偏移1处找到那两个非空条目,而具有偏移2、3...N-1的条目将为空的。在一些实施方案中,可同步地使对N1的改变持久,而在其他实施方案中,可相对于对E的删除请求异步地将N1写入一个或多个盘区处的持久性存储装置。
如果E是N1的条目列表中的最后一个条目(也如元素5310中检测的),那么可检查N1的母节点PN的NI阵列。PN的NI阵列可包括指向N1(例如,存储其地址或标识符)的一个或多个元素NP1、NP2...。如果PN的NI阵列还包括指向除了N1的某个其他节点的至少一个“邻居”元素NX(如元素5316中确定的),那么可将NX的内容复制到NP1、NP2...,使得PN不再包含到N1的指针(元素5319)。在至少一些实施方案中,还可或相反地将阵列元素NP1、NP2...标记为无效。
在所描绘实施方案中,如果PN的NI阵列不包含指向除了N1的节点的此类邻居元素(也如元素5316中检测的),那么可以不同方式修改PN。如元素5322中示出的,可例如通过修改PN的报头来将PN的类型从NI阵列改变为EL。另外,可针对PN初始化新的条目列表,例如,可改写用于NI阵列的字节中的至少一些。在所描绘实施方案中,不管在母节点PN中是否找到邻居元素,可将删除目标节点标记为自由或未使用(元素5325)。可将受到删除影响的节点(例如,PN和N1)的每个的内容保存到存储子系统的一个或多个盘区处的持久性存储装置。在一些实施方案中,可使用前述类型的分布式事务来使至少元素5322和5325中示出的改变成为单个原子操作的部分。在另一实施方案中,在单个原子操作或分布式事务中元素5319中示出的修改还可与元素5322和5325的那些组合。在至少一个实施方案中,有条件写入可用于改变中的每一个。
在各种实施方案中,可使用可配置参数(例如,在文件系统级别处或者针对作为整体的文件存储服务限定的)来确定基于散列的命名空间管理技术的各方面。此类可配置参数可指定用于以下任意组合:(a)将使用的特定散列函数或散列函数族,(b)由散列函数输出的位序列的需要长度,(c)将用于遍历DAG的各自级别的散列值输出的各个子序列的长度,(d)每种类型的分裂的扇出(每种分裂类型中分裂节点的条目将分配给的列表的数量),(e)分裂之后存储每个新节点的标识符的NI阵列元素的数量(或分数),(f)每种类型的分裂的阈值填充水平,或者(g)DAG的级别的最大可允许数量或DAG的总大小。在一些实施方案中,还可通过参数指定另外约束(例如,盘区放置约束),例如,可指定前N个级别的所有HDAG节点存储在同一盘区处的约束,或者可指定没有两个HDAG节点应存储在同一盘区处的约束。在一些实施方案中,可基于收集的性能结果修改这些参数中的一个或多个。例如,如果命名空间相关性能对特定文件系统的给定参数组不满意,那么存储服务可针对同一文件系统(可涉及将在运行中或在重新配置停机时段期间创建的新HDAG)或者针对随后创建的文件系统调整参数。
客户端会话元数据管理
在至少一些实施方案中,分布式存储服务可支持一个或多个有状态或面向会话的文件系统协议诸如NFS。在一些此类协议中,服务的客户端部件(例如,在客户端侧执行平台处运行的守护进程)可通常通过与服务器部件(例如,在服务器侧执行平台处运行的另一守护进程)的一个或多个通信创建会话,其中会话具有相关联的期满时间,在所述期满时间期间服务能够加快对某些种类的客户端请求的响应,并且其中可在一些条件下延伸或更新会话。在会话期间,客户端可例如获得诸如文件的对象上的锁,并且锁可保持有效直到会话结束或者客户端释放锁。会话期间客户端对对象的随后访问可不需要另外锁定。根据一些文件系统协议,来自服务器的对客户端的文件(或另一类型的文件存储对象)状态的控制的这种时限授权可称为“租用”。单个租用可与多个文件存储对象上的锁相关联,并且可由用户端明确地或暗含地更新。在至少一些实施方案中,面向会话的协议可需要会话状态信息(例如,与客户端的租用相关联的锁定文件或目录的列表,租用的期满时间等等)由“文件服务器”维持。在分布式文件存储服务中,文件服务器的协议规定责任可分布在上述各种子系统之间,例如,访问子系统、元数据子系统和/或存储子系统。当决定应在不同实施方案中不同子系统处实现的协议规定会话相关功能的特定部分时,可考虑各种因素诸如可缩放响应时间和吞吐量目标、元数据耐久性要求等等。
图54示出根据至少一些实施方案的可维持用于分布式存储服务处的面向会话的文件系统协议的元数据的两个维度。关于给定客户端会话期间已打开和/或锁定的所有对象的信息可必须由存储服务针对某些类型的操作(例如,针对租用期满,其可需要会话的所有锁被释放)有效地访问。元数据信息的第一维度由示出的概念性元数据表5401中的行表示,诸如可针对客户端会话CS1上租用相关操作访问的元数据组5401的内容。元数据组5401可例如包括锁定状态指示符(LSI)(诸如NFS“状态ID”),所述锁定状态指示符在以下更详细论述中用于多个文件、目录、链接等。在示出的实例中,对于客户端会话CS1,针对目录D1示出写入锁定状态指示符W-锁,并且针对文件F1和FP示出R-锁(读取锁定指示符)。需注意至少在一些实现方式中,锁定可在文件级别处而不在目录级别处实现。
第二维度是必须根据任何给定对象上的文件系统协议维持的会话相关信息组,诸如文件F1上的元数据组5420。例如在接收锁定对象的新请求时或者在接收查看对象的状态或属性的请求时,可必须有效访问此第二元数据集合(也可包括诸如客户端段会话CS1的R-锁的锁定状态指示符)。在可存储几百万个对象(其许多至少潜在地跨多个盘区分布)并且可具有与受支持的许多不同类型的锁定模式和/或租用模式并行的成千上万客户端会话的文件存储区中,将图54中示出类型的所有会话相关信息存储在单个集中位置中可能是不实际或有效的。图54因此提供可必须在各种实施方案中有效访问的至少两种种类的会话相关元数据的概念视图,并且并不意图暗示任何特定实现方法。
需注意,除了特定文件系统协议需要的面向会话的元数据5401之外,还可维持其他内部元数据(诸如包括上述HDAG的命名空间管理元数据、前述逻辑块到物理页面的映射等)。在至少一些实施方案中,不同类型的元数据可由元数据子系统的独立子部件管理,例如,可相对于图54中示出的类型的客户端会话信息的管理正交地实现条带化或逻辑块到物理页面映射的管理。此外,分布式存储服务可至少在一个实施方案中支持多个有状态或面向会话的文件系统协议,其每一个可能限定各自的会话元数据对象类型和语义。例如,NFS可指定其元数据对象组和关系,SMB可指定不同组等等。在此类情景中,单独组的面向会话的元数据5401可维持用于与不同协议中的每一个相关联的文件系统。
在至少一些实施方案中,客户端(诸如,使用提供商网络的计算实例处的一个或多个过程实现的NFS客户端)可通过向分布式存储服务传输根据文件系统协议格式化的消息来请求建立客户端会话。图55示出根据至少一些实施方案的分布式存储服务的子部件之间的客户端会话元数据相关的交互的实例。文件系统客户端5501可向访问子系统节点5512发送会话请求5550,例如,其IP地址已暴露或公布为由客户端使用的文件系统的端点的访问子系统节点。在使用的文件系统协议是NFS的一些实现方式中,例如,会话请求可包括“SetClientID”请求,并且可包括客户端的识别(由客户端生成的)以及称为“验证者”的唯一非重复对象(也由客户端生成)。在一些此类实现方式中,服务可使用验证者来确定客户端自会话被最初实例化以来是否重新启动;因此,具有不同验证者的第二SetClientID请求的提交可允许服务使客户端的先前会话/租用期满。响应于第二请求,使用的文件系统协议可需要(除非遇到错误条件)会话标识符5563(例如,NFS“ClientID”对象)最终由服务提供给请求者。
在至少一些实施方案中,分布式存储服务的元数据子系统可负责管理客户端会话状态信息。例如,元数据子系统可控制客户端会话状态信息映射到逻辑块以及那些逻辑块映射到盘区的方式。在一些实施方案中,盘区自身可存储在存储子系统节点处,并且在其他实施方案中存储在如前述的元数据子系统节点处。虽然在一些实施方案中,访问子系统节点可临时地高速缓存会话相关元数据,但元数据子系统可指定为分布式存储服务内的客户端会话信息的授权源。
在所描绘实施方案中,在接收客户端会话请求之后,访问子系统节点5512可向选择元数据节点5522传输会话初始化请求5553,请求会话标识符由元数据子系统生成。在至少一些实施方案中,由客户端提供的参数(例如,客户端的标识符和/或验证者)可由访问节点传递到元数据节点。元数据节点5522可生成新的逻辑块LB1来存储客户端的会话元数据的至少一部分。在所描绘实施方案中,LB1可包括例如由元数据节点生成的客户端会话的会话标识符5563、会话的租用超时设置5544以及“负责访问节点”(RAN)字段5546。RAN字段可识别特定访问节点5512,通过所述访问节点5512预期在后台子系统(例如,元数据子系统或存储子系统)处接收确保会话期间的客户端的请求。在所描绘实施方案中,元数据节点5522将会话元数据的逻辑块的内容存储在选择盘区5580的一个或多个页面处,如箭头5557指示的。在一些实现方式中,元数据节点5522可向存储子系统提交存储逻辑块内容的请求,而在其他实施方案中,元数据节点5522可将内容写入由元数据子系统自身管理的盘区。
根据至少一些实施方案,针对客户端选择或生成的会话标识符(例如,NFS ClientID)可至少部分地基于逻辑块的存储地址,例如,会话标识符可稍后在读取操作中用作参数来快速查找客户端会话元数据。例如,在一个实现方式中,每个逻辑块可分配有128位的逻辑存储地址,并且用于LB1的128位逻辑地址可提供为客户端的会话标识符5563,或者可被包括或编码在会话标识符5563内。在另一实施方案中,会话标识符可至少部分地基于用于存储会话元数据元素的物理块中的至少一个的物理存储地址。元数据节点5522可向会话初始化请求5553传输响应5560。在所描绘实施方案中,响应5560可包括会话标识符5563,所述会话标识符5563可在高速缓存器5578处的访问节点5512处高速缓存并提供给请求客户端5502。在一些实施方案中,文件系统的会话建立协议可需要一个或多个另外交互,例如,包括会话标识符的确认请求消息可由客户端5502发送到存储服务并且客户端可随后接收确认会话标识符的有效性的响应。在至少一些实施方案中,来自客户端的随后请求诸如文件打开、关闭、锁定请求等可需要包括会话标识符5563。在接收此类稍后请求之后,访问节点5512可使用高速缓存器5578验证客户端的会话标识符。如果会话标识符从高速缓存器缺少,那么访问节点可向元数据子系统提交关于会话的查询,并且可仅在会话仍然打开的情况下(或者在新会话响应于查询由元数据子系统实例化的情况下)仅需所请求的操作。
如先前指示的,在一些实施方案中,文件系统协议诸如NFS可实现租用技术以便有效地管理对文件系统对象的并行访问。在一些此类实施方案中,与客户端会话相关联的租用可表示对客户端的一个或多个文件、目录、链接或文件系统的其他客户端可访问对象状态的控制的时限授权。在至少一个实施方案中,存储服务可使用本文称为锁定状态指示符的另一元数据对象来表示特定文件系统对象的锁定状态。例如,在NFS协议的至少一些实现方式中,锁定状态指示符可称为“StateID”。在至少一些实施方案中,诸如文件F1的对象的锁定状态指示符可在上下文中限定为给定客户端对话CS。因此,例如,当客户端C11将文件F1看作客户端会话CS1的部分时,可创建F1的专用于CS1的锁定状态指示符LSI1;并且稍后,当不同客户端C12将文件F1看作客户端会话CS2的部分时,可由存储服务生成不同锁定状态指示符LSI1。在至少一些实施方案中,LSI可并入或包括到对应客户端会话的会话标识符的指针,例如,在一个实现方式中,兼容NFS StateID可包括到对应ClientID(或其实际值)的指针。在一些实施方案中,每个打开客户端会话可具有相关联租用超时时段,在所述超时时段结束时可使与会话的LSI的全部相关联的锁自由。在一些实施方案中,可使用打开状态指示符(类似于LSI)来指示特定文件存储对象当前打开来由客户端访问。在一些实现方式中,可使用单个元数据结构(例如,打开/锁定状态指示符)表示文件存储对象的打开状态和锁定状态的指示。
根据实现租用的至少一些文件系统协议的语义,可支持用于租用续订的一个或多个机制。例如,可限定一组操作类型,使得由客户端在打开会议期间进行的那组操作类型的操作的请求可自动导致针对一些指定租用续期的租用的更新。在这种实施方案中,如果客户端在例如会话CS1(针对其租用被设置来在时间T1处期满)期间发布读取文件F1的请求,那么租用可延伸到稍后时间T2。在一些实施方案中,还可或代替支持用于明确地更新租用的API。如果在特定时段内不接收导致自动(或明确)租用续订的类型的请求中的任一个,那么租用可期满。在一些实施方案中,在租用期满之后,对应锁(由LSI指示的)可由存储服务释放,在会话期间打开并且在租用期满点之前未关闭的文件系统对象可关闭,并且至少在一些实施方案中,会话元数据可从元数据子系统的持久储存库和/或从访问子系统的高速缓存器删除。
图56示出根据至少一些实施方案的分布式存储服务处的客户端会话租用续订的替代方法。在所描绘实施方案中,可由客户端使用的文件系统协议指定自动续订操作列表5678。自动续订操作列表5678可指示在当前打开会话期间请求时导致与会话相关联的租用的自动续订的操作类型。例如,在一些NFS实现方式中,自动续订操作列表可包括(尤其)读取、写入、锁定、解除锁定以及设置属性操作。在一些实现方式中,租用的明确续订的续订操作也可包括在操作列表5678中。
在所描绘实施方案中,访问子系统节点5512可接收文件存储操作请求5650。在所描绘实施方案中,如果操作请求是在自动续订操作列表中指示的类型(或者是续订客户端租用的明确请求),那么访问节点5612可具有两个选项。访问节点可向元数据节点5522提交即时或非成批租用序列请求5653,或者可推迟租用续订多达某一可配置时间段并且向元数据节点5522提交成批租用续订请求5654。成批租用更新请求可例如包括多个客户端会话的会话标识符,在时间窗口期间针对所述客户端会话接收自动续订操作请求或明确续订请求。在至少一些实施方案中,租用续订请求的成批处理可帮助减少元数据节点5522和/或访问节点5512处的续订相关开销(例如,通信开销、处理开销或两者)。
在一些实施方案中,访问节点可使用可配置即时续订阈值5688来确定给定租用续订是否应响应于客户端的操作请求5650即时传输,或者推迟的成批处理方法是否应用于客户端的租用续订。在所描绘实施方案中,如果例如即时更新阈值设置为X秒,并且客户端的租用设置为在操作请求5650由访问节点接收的时间的X秒内期满,那么可生成非成批或即时租用续订请求5653。或者,如果在租用被设置来期满之前保持多于X秒,那么客户端的续订请求的表示可存储在成批续订缓冲器5679中,并且一些数量的续订可稍后按成批租用续订请求5654发送到元数据节点5522。在所描绘实施方案中,访问节点可已针对各种客户端会话(针对其访问节点在会话元数据高速缓存器5578内负责)高速缓存租用期满时间,并且可使用高速缓存内容来做出关于发送即时续订请求还是成批续订请求的确定。独立于租用续订,访问节点可代表客户端发起所请求操作(例如,使用高速缓存的客户端会话元数据和/或高速缓存的逻辑块到物理页面的映射),并且可将适当文件存储操作响应5663提供给客户端5502。
为了在期望性能级别下执行各种类型的文件存储操作,可采用存储文件存储对象的锁定状态信息的若干方法中的任一种。图57a和图57b示出根据至少一些实施方案的分布式存储服务处的面向会话的文件系统协议的锁定状态管理的替代方法。在图57a中示出的一个方法中,特定文件系统的锁定状态指示符5705可分布在多个盘区之间。在这种方法的一些实现方式中,包含各种文件存储对象的锁定和/或打开状态信息的LSI可与维持用于条目的其他类型的元数据存储在一起,例如,对应命名空间DFS-DirectoryEntries(命名空间条目)、DFS-索引节点和/或文件系统的对象的逻辑块到物理页面的映射。因此,例如根目录的LSI 5705A可与根目录的其他元数据5704A一起存储在特定盘区的一个或多个逻辑块处,目录D1的LSI 5705B可与目录D1的其他元数据5704B一起存储在不同盘区处,等等。类似地,各自打开/锁定状态信息条目5705C、5705D、5705E和5705F可各自存储在目录D2、目录D3、文件F1以及文件F2的各自逻辑块中。在图57b中示出的第二种方法中,给定文件系统的所有对象的打开/锁定状态信息可以合并方式存储,例如在单个元数据盘区5754内。当针对给定客户端会话例如针对会话无效操作查找所有LSI条目时,如果使用图57a中示出的分布式方法那么可必须访问多个条目,而如果使用图57b中示出的合并方法那么可仅需要一个或小数量的盘区。然而,在一些情况下,合并方法可导致比分布式方法更适当的资源利用,例如,因为LSI可在文件存储对象的填充量改变时删除,和/或因为在创建文件系统和获得其LSI的盘区时可能不能容易预测给定文件系统的锁定/打开状态信息最终需要的存储装置的量。
图58是示出根据至少一些实施方案的可在分布式存储服务处执行的客户端会话元数据管理操作的方面的流程图。如元素5801所示,可从支持有状态或面向会话的文件系统协议诸如NFS或SMB的分布式存储服务的访问子系统节点处的客户端接收初始化或创建客户端会话的请求。在一些实现方式中,客户端可使用请求明确会话初始化的API(类似于NFS SetClientID API)。在其他实现方式中,建立会话的请求可以是暗含的,例如如果一个还未存在,那么可响应于从客户端调用的打开()API初始化会话。会话请求可在一些实现方式中包括特定客户端的识别(例如,从IP地址导出的值和/或一个或客户端过程在其处运行的主机的主机名)以及唯一的仅单次使用的验证者值。如果客户端过程存在并且必须重新开始,或者如果客户端过程在其处运行的主机或计算实例重新启动,那么至少在一些实施方案中,新的会话可必须初始化,并且不同验证者可按对应会话初始化请求供应给存储服务。
在所描绘实施方案中,分布式存储服务的元数据子系统可负责将客户端会话信息存储在一个或多个盘区处的持久性存储装置处,而访问子系统可被配置来高速缓存会话状态信息,例如在访问节点处的易失性存储器和/或本地持久性存储装置中。响应于接收会话请求,访问节点可将会话标识符的请求(例如,客户端的会话请求的内部版本)传输到选择的元数据节点(元素5804)。在一些实施方案中可基于客户端的识别信息选择元数据节点,例如,在一个实施方案中,可针对将建立用于客户端C11和C12的各自客户端会话选择两个不同元数据节点MN1和MN2。选择的元数据节点可为将存储的客户端会话元数据的各种元素分配逻辑块(使用前述映射技术中的一种映射到元数据盘区处的一些数量的物理页面),包括例如会话的租用设置、客户端的标识符、客户端会话的负责访问节点的标识符等等(元素5807)。在至少一些实施方案中,可至少部分地基于会话元数据存储在其处的地址为新的会话确定会话标识符(例如,NFS ClientID),例如逻辑块地址或物理页面地址可并入会话标识符内或者用作会话标识符。在所描绘实施方案中,可从元数据节点向访问节点提供会话标识符和初始租用设置(元素5810)。在一些实施方案中,仅会话标识符可提供给访问节点,并且访问节点可能够通过将会话标识符的至少一部分用作读取请求中的参数来从存储子系统检索会话元数据的其他元素。
可由访问节点在会话元数据高速缓存器中高速缓存会话标识符和租用信息,并且可将会话标识符返回到客户端(元素5813)。客户端可包括作为随后文件存储操作请求中的参数的会话标识符,例如,指向文件系统的文件或目录的打开()、读取()、写入()、getattribute()或关闭()呼叫。当访问节点接收这种操作请求时,其可查找其本地高速缓存器中的会话信息例如以便验证客户端的会话仍打开。
对于所描绘实施方案中的一些类型的操作,例如,可根据使用的文件系统协议的并行性管理技术需要指向文件的写入操作、锁。在接收给定文件系统操作请求(包括会话标识符)诸如指向文件存储对象F1的写入或读取时,访问节点可确定是否需要这种锁(元素5816)。如果需要锁并且未在访问节点处高速缓存所述锁,那么可将操作请求的对应内部版本从访问节点传输到元数据节点(元素5819)。元数据节点可确定冲突锁定状态指示符是否已经存在(例如,因为已经代表另一客户端锁定F1)。如果找到这种冲突锁(如元素5820中确定的),那么可例如通过发送指示目标对象已经锁定的错误消息来拒绝客户端的文件系统操作请求(元素5821)。如果未找到冲突,那么元数据节点可确定将用于存储F1的状态信息的逻辑块的持久性存储位置,包括例如对应锁定状态指示符(元素5822)。例如,在一些实施方案中,可使用图57a或57b中示出的技术中的一个来为锁定状态指示符和/或将保存用于F1的其他状态元数据分配空间。可将状态信息存储在持久性存储位置处(元素5825),并且可将包括锁定状态指示符的状态元数据的至少一部分提供给访问节点。
可例如由于指向存储子系统的内部I/O请求由访问节点或元数据节点完成所请求操作(例如,指向F1的读取或写入),并且可将对应响应发送到客户端。访问节点可将锁定状态指示符添加到其会话元数据高速缓冲器并且使用高速缓存的锁定状态指示符、高速缓存租用设置和/或高速缓存的会话标识符来在会话元素5828)期间对来自客户端的随后请求做出响应,例如,而针对随后请求中的至少一些不需要与元数据子系统的交互。在所描绘实施方案中,当并且如果会话期满时,可将会话的元数据从访问节点的高速缓冲器并从在元数据节点的请求下分配的持久性存储装置删除(元素5831)。需注意,根据一些文件系统协议,还可将会话相关元数据中的至少一部分提供给服务的客户端侧部件和/或在所述部件处高速缓存,所述部件例如,在利用文件存储服务的应用在其处运行的主机处实例化的守护进程。
图59是示出根据至少一些实施方案的可在分布式存储服务处执行的客户端会话租用续订操作的方面的流程图。如前所述,租用可表示来自存储服务的对客户端的一组文件、目录或其他客户端可访问存储对象的控制的时限授权。如元素5901所示,可在客户端会话CS1期间在存储服务的访问节点处从客户端C11接收属于导致自动租用续订的操作种类的文件存储操作请求OR1。例如,可接收指向面向会话的文件系统的特定文件诸如NFS的读取、写入、打开或关闭请求。不同文件系统协议可在各种实施方案中限定各自组的租用续订操作。在至少一些实施方案中,还可响应于明确租用续订命令执行图59中示出的剩余操作。请求可包括客户端的会话标识符(例如,NFSClientID),所述会话标识符可用作访问节点的会话元数据高速缓冲器中的元数据记录的索引值。
访问节点可查找客户端会话的租用信息(例如,当租用被设置来期满时)(元素5904),例如在会话元数据高速缓存器中。如果租用是由于某一阈值时间间隔T内的期满(如元素5907中确定的),那么访问节点可向元数据节点传输对CS1的即时租用续订请求(元素5913)。然而,如果租用是由于阈值时间间隔T之后的期满,那么可将对CS1的租用续订请求添加到一组缓存未决的租用续订请求以便按批次发送到元数据节点。如果操作请求OR1需要存储操作被执行(例如,如果在访问节点处已经高速缓存的数据或元数据不能满足请求),那么访问节点可请求存储操作(元素5916),而不管是否发送即时续订请求。在缓存CS1的租用续订请求的情境中,可相对于操作请求OR1异步地将缓存的租用续订请求中的一个或多个传输到元数据节点(元素5919)。
在实现租用续订请求的缓存技术的至少一些实施方案中,与设置用于在元数据节点的请求下存储的会话元数据的持久版本的有效性超时不同的有效性超时可配置或设置用于在访问节点处高速缓存的会话元数据的版本(包括例如会话标识符和会话的LSI)。例如,在一个实现方式中,如果租用超时根据文件系统协议设置被设置为90秒,那么120秒的有效性超时可用于元数据子系统处的持久会话元数据记录,而30秒的有效性超时(例如,至少部分地基于元数据子系统的有效性超时与协议的租用超时之间的差)可设置用于访问节点的高速缓存器处的对应记录。使用此类不同超时组合,可在不致使客户端过早丢失其租用益处的情况下容纳访问节点处的至少一些类型的潜在故障或延迟。例如,通过以上介绍的示例性超时设置,由于访问节点将被要求来在任何情况下从元数据子系统每30秒刷新一次其高速缓存的租用信息,而客户端的实际租用有效持续90秒,将通常不预期几秒的成批延迟(例如,由访问节点到替换节点的故障转移导致的小于30秒的延迟)导致对协议租用语义的任何违反。由于租用续订操作可预期相当频繁地发生,在此类实现方式中,访问节点的较短有效性超时导致访问节点与元数据子系统之间的额外流量的概率可相当低。需注意,至少一些前述技术,诸如有条件写入在读取-修改-写入序列中的使用,分布式事务和/或复制状态机通常也可用于管理客户端会话相关元数据。例如,在一个实现方式中,当客户端会话租用期满时,并且必须删除分布在服务的各个节点之间的多个会话相关联的锁定状态指示符时,可使用分布式事务。
使用尝试计数的连接平衡
在预期包括几千节点并预期处理几万或几十万并行客户端请求的一些分布式存储系统处,对客户端工作负载进行负载平衡可能对实现目标性能和资源利用目标是必不可少的。在至少一些提供商网络环境中,负载平衡节点的集合可被建立为各种服务与希望利用服务的客户端之间的中介。在一些实施方案中,这种中间负载平衡层可建立在客户端装置与分布式存储服务的访问子系统之间。代表客户端针对分布式存储服务建立的网络连接(诸如NFS安装连接)可通常相当长寿,并因此,工作负载平衡的问题可能变得比用户会话通常较短(例如,一些类型的网络服务器环境)的环境中复杂。可使用多种不同技术来管理分布式存储服务访问节点的工作负载水平,包括例如下述考虑先前进行以代表特定客户端建立连接的不成功尝试的数量的连接平衡技术。在一些实施方案中,也如以下所述,连接可在某些工作负载条件下自愿地由访问节点终止。
图60示出根据至少一些实施方案的负载平衡器层被配置用于分布式存储服务的系统。在所描绘实施方案中,负载平衡器层6090包括使用提供商网络6002的资源实现的多个负载平衡器节点(LBN)6070,诸如节点6070A、6070B和6070C。分布式存储子系统的访问子系统6010包括多个访问节点(AN)对等组6060,诸如包括AN6012A、6012B和6012C的AN对等组6060A以及包括AN 6012K、6012L和6012M的AN对等组6060B。在至少一些实施方案中,如以下更详细描述的,AN对等组的成员可彼此协作以用于连接重新平衡操作。在不同实施方案中,AN对等组6060的成员可基于多种准则的任何组合选自存储服务的多个访问子系统节点,例如,基于访问子系统的可用性要求(例如,使得单个局部电源中断或其他基础设施停运不导致AN组的所有成员处的失败)、等待时间要求(例如,使得组的不同成员能够支持类似等待时间水平)、性能容量要求(使得可由AN对等组集体处理的总吞吐量高于某一期望最小值)。在一些实现方式中,AN对等组可包括全部在安装于单个机架处的硬件服务器上实现的多个访问节点。在其他实现方式中,AN对等组边界可能不与机架边界重合;相反,可使用其他因素诸如共享网络地址前缀、对故障的恢复力或处理的文件存储区的类型/数量来限定对等组。
在至少一些实施方案中,协议的TCP/IP(传输控制协议/互联网协议)族可用于客户端180与存储服务之间的通信。客户端180可向其网络地址(例如,虚拟IP地址)已暴露为用于访问存储服务的端点的LBN 6070传输连接建立请求。在不同实施方案中,各种类型的物理或虚拟网络6022可由客户端使用。在一个实施方案中,如前所述,一些或所有客户端(诸如被配置为隔离虚拟网络的部分的计算实例)可在提供商网络内的主机处实例化,并且可因此使用内部网络来连接到负载平衡器节点。在至少一个实施方案中,负载平衡器节点和存储服务的客户端可都在同一主机处执行(例如,作为单独虚拟机),在这种情况下可能不需要脱离主机的脱离主机的网络连接。在另一实施方案中,可使用提供商网络6002外部的网路的一部分诸如互联网的一部分。在一些实施方案中,多个LBN可被配置来对指向与存储服务相关联的单个IP地址的流量做出响应。在一个实现方式中,特定LBN6070可首先暂时地接受客户端的连接建立请求,并且那个LBN 6070可随后尝试通过提供商网络6002的网络结构6024(例如,L3网络)建立到访问节点6012的对应内部连接。在至少一些实施方案中,如下所述,给定访问节点6012可在某些工作负载条件下拒绝由LBN发布的内部连接请求,并且LBN可因此尝试找到愿意建立内部连接的另一访问节点6012。在一些实施方案中,访问节点使用来接受或拒绝LBN的请求的特定准则可取决于LBN已进行的不成功尝试的数量,例如,可在不成功尝试的数量增加时放宽准则,使得连接建立的概率可随尝试的数量增加。
在所描绘实施方案中,每个AN 6012包括两个子部件:局部负载平衡器模块(LLBM)6017(例如,LLBM 6017A、6017B、6017C、6017K、6017L和6017M),以及访问管理器(AM)6015(例如,AM6015A、6015B、6015C、6015K、6015L和6015M)。在连接请求已被接受之后,在一些实施方案中,LLBM可负责接收由LBN代表客户端通过网络结构6024发送的封装TCP数据包。在各种实现方式中,LBN可使用不同协议(例如,用户数据报协议(UDP)或者在提供商网络内部使用的某一专有协议)或者使用TCP自身封装客户端的TCP数据包,例如,客户端的TCP数据包(包括其报头)可包括在LBN TCP数据包内用于LBN与LLBM之间的传输。LLBM可在将数据包传递到与局部AM相关联的TCP处理堆叠之前拆开或者解封数据包。在一些实现方式中,LLBM可在传送到TCP处理堆叠之前改变一个或多个客户端数据包报头的内容诸如TCP序列号。在至少一些实施方案中,LBN和LLBM的组合对客户端数据包进行的操纵(例如,封装/拆开,改变报头等)可使似乎对TCP处理堆叠来说好像数据包在直接与客户端180建立而不是通过LBN和LLBM的TCP连接上接收。AM 6015可实现存储服务前端逻辑,包括例如高速缓存元数据、管理与元数据子系统120和/或存储子系统130的交互,等等。另外,在一些实施方案中,AM 6015可收集AN的各种资源的一组局部工作负载度量,诸如CPU度量、网络度量、存储器度量等,所述度量可用于关于接受另外连接的决定。在一个实施方案中,如以下更详细描述的,对同组6060的不同对等体的AM可关于其工作负载水平查询彼此。
根据至少一些实施方案,可代表客户端180在访问节点6012处从LBN 6070接收包括尝试计数参数的连接请求。尝试技术参数可指示负载平衡器部件代表那个特定客户端180尝试建立连接的次数。在一个实施方案中,客户端可提交安装文件系统的请求(例如,以及NFS安装命令),并且LBN可响应于接收安装命令而生成其连接请求;因此建立的连接可被称为“安装连接”并且可用于来自同一客户端的若干随后请求。在其他实施方案中,其他存储服务命令或请求(即,除了安装请求之外的请求)还可或代替触发连接建立请求。在接收连接请求之后,AN可识别将用于关于连接请求的接受决定的一个或多个工作负载阈值水平(例如,多个资源的各自阈值水平Th1、Th2...)。在一些实施方案中,阈值水平中的至少一个可基于尝试计数参数,例如,对于第一次尝试,CPU工作负载阈值可以是Tc,而对于第二次尝试,CPU工作负载水平可设置为(Tc+delta),使得连接更可能在第二次尝试时接收。在一个示例性情境中,如果针对CPU工作负载识别阈值水平Tc,并且针对网络工作负载识别阈值水平Tn,那么可在AN的CPU工作负载度量低于Tc并且网络工作负载度量低于Tn的情况下接受连接。在另一情境中,可在CPU工作负载度量或网络工作负载度量低于对应阈值的情况下接受连接。在一些实施方案中如以下论述的,可在某一时间间隔内计算用于与阈值比较的工作负载度量,例如,以便减小短期工作负载波动对连接接受决定的影响。
响应于局部工作负载度量或访问子系统节点的度量低于对应工作负载阈值水平的确定,可向请求LBN 6070提供接受连接的指示。连接请求和接受指示都可根据用于LBN与LLBM之间的通信的特定协议(例如,UDP、TCP或某一其他协议)格式化。LBN 6070可在一些实施方案中向客户端确认连接已由AN接受。如果由LBN选择的AN 6012不能接受连接(例如,如果局部工作负载度量高于所识别的阈值),那么连接拒绝消息可发送到LBN。LBN可随后将其请求(以及递增的尝试计数参数)传输到另一AN,并且此过程可如图61中示出的重复并且如下所述,直到成功建立连接或者尝试的数量超过允许的尝试的某一最大数量。
在连接成功建立之后,当LBN 6070接收指示存储服务请求的客户端生成的数据包时,LBN可将数据包传输到访问子系统节点处的LLBM(例如,以封装格式)。LLBM可操纵从LBN接收的消息的内容(例如,以便拆开原始客户端生成的数据包),并且将原始数据包传递到AM 6015以用于处理。取决于必须响应于存储请求执行的操作的本质,AM可在一些情况下必须接触元数据子系统120、存储子系统130或两个后端子系统。存储服务请求的指示可传输到适当子系统。如果客户端的服务请求需要响应,那么响应可遵循相反方向流动,例如,从后端子系统到AN,从AN通过LBN到客户端。在传入数据包由LBN封装并且由LLBM拆开的至少一些实施方案中,LLBM可类似地封装传出数据包并且LBN可在将数据包传递到客户端180之前拆开所述数据包。
图61示出根据至少一些实施方案的负载平衡器节点与分布式存储服务的多个访问子系统节点之间的示例性交互。在所描绘实施方案中,虚拟IP地址6105(例如,可例如在提供商网络的虚拟计算服务的不同计算实例处与不同网络接口动态地相关联并且不绑定到单个网络接口的IP地址)可暴露来使客户端能够向存储服务提交连接请求和其他存储服务请求。一个或多个LBN 6070可负责在任何给定时间接受指向虚拟IP地址的流量。在至少一些实施方案中,LBN(和/或AN)可使用计算实例实现,例如,给定LBN可包括在提供商网络的虚拟计算服务的计算实例处执行、在商用硬件服务器处启动的过程。客户端可向虚拟IP地址6108提交连接建立请求6108。
在所描绘实施方案中,LBN 6070可接收客户端的请求,并且选择特定AN 6012B作为第一AN,所述LBN 6070应向所述第一AN发送对应内部连接请求。可使用多种不同技术来选择AN,例如,可在一些实施方案中使用随机选择,可在其他实施方案中使用循环选择,等等。在一些实施方案中,每个LBN可与一组AN(诸如基于前述可用性、等待时间、容量或其他准则限定的一个或多个AN对等组)联合,并且LBN可针对其连接尝试以指定次序循环通过其联合AN。在一些实施方案中,某一数量的LBN和某一数量的AN可都位于同一机架,并且LBN可先从其自己的机架内选择AN。在所描绘实施方案中,LBN可向选择AN 6012B处的LLBM 6017B提交第一连接尝试6132A,例如,其中尝试计数参数设置为1。(在一些实现方式中,针对第一次尝试,尝试计数参数可设置为零)。在不同实施方案中,关于请求的接受或拒绝的决定可由目标AN处的AM 6015、目标AN处的LLBM或者目标AN处的LLBM和AM的组合做出。
如果接触的第一AN向LBN发送拒绝61234A(例如,至少部分地基于超过对应阈值的一个或多个局部工作负载度量6115B),那么LBN可选择第二AN(所描绘实例中的AN 6012A)。LBN 6070可向第二AN处的LLBM 6017A提交具有递增的尝试计数参数的第二连接请求尝试6132B。如果再次接收拒绝6134B(例如,基于AN 6012A的局部工作负载度量6115A),那么LBN 6070可选择第三AN 6012C并且向其LLBM 6017C提交第三尝试6132C。在所描绘示例性情境中,第三AN 6012C基于对其局部工作负载度量6115C的分析发送回接受6136,并且连接因此建立在AM 6015C与客户端180之间。在所描绘实施方案中,在成功建立连接之后,存储服务与客户端180之间的网络数据包遵循路径6157流动。例如,客户端可向LBN 6070发送数据包,LBN可将所述数据包发送(潜在地使用封装或修改的表示)到LLBM 6017C,LLBM的数据包操纵器6155可拆开或修改所接收的数据包,并且将操纵的输出发送到AM 6015C。AM 6015C可随后发起需要的存储操作,所述操作可涉及与元数据和/或存储子系统的交互。
图62示出根据至少一些实施方案的可随进行的连接尝试的数量变化的连接接受准则的实例。在所描绘实施方案中,对于给定资源,AN相对于那个资源的本机或基线容量6202(诸如CPU或网络带宽)可由故障开销因素6204修改以便达到将用于连接接受决定的已调整容量(AC)6206。例如,如果AN的本机CPU容量是每秒X个操作,那么在一个情景中,可留出所述容量的五分之一(0.2X)来补偿可能在各种种类的故障的情况下发生的临时工作负载增加。因此,在这种情境中,调整的CPU容量将被设置为每秒0.8X(X-0.2X)个操作。
收集针对AN处的给定资源的局部工作负载度量可表现出短期变化以及长期趋势。由于针对存储服务操作建立的连接(诸如针对NFS建立的安装连接)可通常是长期的,可能不建议仅基于最近度量接受/拒绝连接。因此,已调整负载度量(AL)6216可从最近度量6212和某一组历史度量6214(例如,在过去15分钟或一小时内针对那个资源收集的度量)的组合获得。在一些实施方案中,衰减函数6215(例如,指数衰减或线性衰减)可在计算已调整负载时应用到历史度量例如以便表示度量的重要性随时间推移的减少或者对其建模。
为了在AN处接受具有指定尝试计数参数的连接请求,可将给定资源的已调整负载6216与取决于尝试计数的阈值(以那个资源的已调整容量表示)进行比较。因此,如连接接受准则表6255中指示的,如果正考虑的资源的AL小于或等于0.5*AC,那么可接收具有等于一的尝试计数参数的连接请求。如果连接请求已失败一次,并且尝试计数因此设置为2,那么可在AL不大于0.55*AC的情况下接受连接。对于3的尝试计数值,可进一步放宽尝试准则,使得在AL不大于0.6*AC情况下接受连接;对于尝试计数=4,AL可必须不大于0.75*AC,并且对于尝试计数5,AL可必须不大于0.85*AC。因此,在所描绘实施方案中,连接被拒绝的次数越多,最终接受所述连接的AN可允许的负载就越重。在其他实施方案中,可使用相反方法,其中为了接受具有尝试计数K的连接请求,接受节点的工作负载水平可必须低于接受具有较低尝试计数(K-L)的连接请求所需要的工作负载水平。接受连接的相对容易性在尝试计数增加时减小的这种方法可例如用在新连接尝试将在重负载条件下受挫折的情境中。在至少一些实施方案中,用于计算AC和AL的阈值条件以及参数和函数(例如,衰减函数)可全部为可配置设置。针对其限定接受准则的不同尝试计数值的数量可在不同实施方案中变化,并且在至少一个实施方案中可自身为可配置参数。在一些实施方案中,可例如基于对所实现结果的分析随时间推移动态地修改参数、函数和/或阈值。在至少一些实施方案中,接受准则中的一些可对于一定范围的尝试计数值相同,例如,针对尝试计数1和2,可使用同一阈值值。
在一些实施方案中,如上所述,在做出连接接受决定时可考虑与多于一个资源相关联的局部工作负载水平。图63示出根据至少一些实施方案的可取决于与多个资源相关联的工作负载水平以及连接建立尝试计数的连接接受准则的实例。在阵列6312中示出已调整负载水平和对应已调整容量的五个实例。AL[CPU]表示访问节点的已调整CPU工作负载,而AC[CPU]表示已调整CPU容量。AL[Net]表示已调整网络负载,并且AC[Net]表示已调整网络容量。AL[Mem]表示已调整存储器负载,并且AC[Mem]表示已调整存储器容量。AL[Dsk]表示访问节点处的已调整局部存储装置容量负载,并且AC[Dsk]表示已调整存储装置容量。在至少一些实施方案中,还可针对由访问节点处的操作系统结构表示的逻辑资源诸如打开套接字确定已调整负载和容量。在至少一些实施方案中,可在连接接受决定中考虑此类操作系统结构的已调整工作负载(AL[OSS])和已调整容量(AC[OSS])。对于每种资源,已调整负载和已调整容量可以相同单位表示,例如,如果网络负载以数据包/秒表示,那么网络容量也可以数据包/秒表示。
可针对各个尝试计数值中的每一个确定以AC阵列元素表示的阈值,如多资源连接接受准则表6355中指示的。在所描绘实施方案中,可针对不同尝试计数水平考虑不同资源组合,例如,针对尝试计数=2,CPU、网络以及存储器的阈值可与对应已调整负载进行比较,而针对尝试计数=K,仅CPU负载和阈值可进行比较。表6355中的“&&”符号指示布尔型“与”,使得例如,在尝试计数=4时,可能必须满足CPU和网络准则两者以接受连接。在各种实施方案中,可使用不同资源的负载对比阈值比较的不同布尔型组合,例如,可使用或、与或者或和与两者。
图64是示出根据至少一些实施方案的可被执行来基于分布式存储服务处的尝试计数实现连接平衡的操作的方面的流程图。如元素6401所示,一组负载平衡器节点的网络地址(例如,可从图3中示出类型的隔离虚拟网络内访问的虚拟IP地址)可暴露于客户端以便使所述客户端能够向服务提交存储相关请求。可在特定LBN(LBN1)处从客户端接收连接请求(元素6404)。LBN1可进而向选择访问节点AN提交对应连接请求,包括指示已进行建立连接尝试的次数的尝试计数参数(元素6407)。可使用各种方法来选择连接建立尝试指向的下一个AN,例如,AN可随机、使用循环方法选择,或者基于一些其他因素诸如从LBN1在AN处建立连接有多近。
AN可确定一个或多个资源的已调整局部工作负载度量(WM),以及那些工作负载度量将与其进行比较来接受/拒绝连接的阈值值(WT)(元素6410)。阈值中的至少一些可针对不同尝试计数值而不同。在一些实施方案中,阈值可以已调整资源容量表示,并且已调整资源容量可进而从本机或基线资源容量以及故障调整因数导出。在一些实施方案中,可使用资源专用接受条件的各种布尔型组合,如图63中指示的。如果满足接受准则,例如,如果对于针对尝试计数值考虑的资源WM<=WT,如元素6413中确定的,那么可通知LBN1已接受连接(元素6428)。在接受连接之后,可在LBN1处从客户端接收表示存储请求的数据包并且将所述数据包传输到连接建立到的AN处的LLBM(局部负载平衡器模块)(元素6431)。在一些实现方式中,可由LBN1封装客户端的数据包,并且可由LLBM拆开或提取所述数据包(元素6434)。LLBM可将数据包传送到AN处的网络处理堆叠,其中可分析数据包内容以便确定需要哪些存储服务操作来对客户端的请求做出响应。可按需要将那些操作的请求发送到服务的其他子系统(例如,到元数据子系统和/或存储子系统)(元素6437)。
如果在由LBN1选择的AN处未满足接受连接的准则(也如元素6413中检测的),那么可拒绝连接尝试(元素6417)。如果LBN1已进行允许的最大数量的尝试(“最大尝试计数”)建立连接(如元素6419中检测的),那么在一些实施方案中可将指示连接建立失败的错误消息返回到客户端(元素6422)。在许多实施方案中,可以建立连接失败的可能性非常低的方式选择基于尝试计数的接受准则。可跟踪连接建立失败的数量,并且另外AN可按需要被配置来将故障的数量或分数保持低于目标水平。
如果LBN1还未为客户端提交最大可允许数量的连接尝试(也如元素6419中检测的),那么LBN1可选择应向其提交连接请求的另一AN(元素6425)。可将带递增的尝试计数参数的新连接尝试发送到选择的AN,并且可重复对应于从元素6407开始的操作。在一些实施方案中,由LBN1使用来选择第一AN的相同种类的技术可用于选择用于随后尝试的AN。在其他实施方案中,LBN1可基于尝试计数改变其用于选择AN的准则,例如,第一AN可随机选择,而下一个AN可基于LBN1在先前尝试中与各个AN的连接建立的如何成功来选择。在一个这种实施方案中,LBN可维持其与各个AN的连接建立成功率的语义,并且可使用所述语义来选择已能够在过去更频繁地接受连接的AN。
使用对等组工作负载信息的连接重新平衡
建立到文件存储系统的连接诸如NFS安装连接可经常持续长时间。与接收连接请求时的连接接受决定相关的信息,诸如在某一先前时间间隔期间的一个或多个资源的资源工作负载水平,可不必指示访问节点在连接的寿命期间的某一稍后点处的当前条件。在一个实例中,访问节点可在其调整CPU负载是X时接受连接,但连接可在调整CPU负载在某一时段内保持在1.5X处的稍后时间处仍使用。因此,在一些实施方案中,访问节点可尝试在一些情况下重新平衡其工作负载。
图65示出根据至少一些实施方案的可基于访问节点的对等组的成员的工作负载指示符尝试客户端连接重新平衡所在的分布式存储服务的访问子系统的实例。示出包括三个节点AN 6512A、6512B和6512C的访问节点对等组。在不同实施方案中可基于上述多种因素确定对等组中的成员身份,包括例如可用性、等待时间、容量、共位置或共享网络地址前缀。在所描绘实施方案中,每个对等组成员可收集至少两种类型的工作负载度量:局部工作负载度量6155(例如,6115A、6115B或6115C),诸如先前针对CPU、网络、存储器和AN的其他资源论述的观察的负载,以及对等组的其他AN处的工作负载水平的指示符6502。在所描绘示例性配置中,AN 6512A可从AN6512B和AN 6512C收集对等工作负载指示符6502A,AN 6512B可从AN 6512A和AN 6512C收集对等工作负载指示符6502B,并且AN6512C可从AN 6512A和AN 6512B收集对等工作负载指示符。收集工作负载指示符的方式和/或工作负载指示符的本质或内容可在不同实施方案中不同。在一些实施方案中,例如,给定AN可在一些选择时间点处简单地向其对等体中的每一个发送连接建立查询,并且接收指示对等体是否愿意接受连接的响应。在连接接受决定可受如先前论述的尝试计数参数影响的一些实施方案中,连接建立查询还可包括尝试计数参数(例如,可使用为“1”的尝试计数参数值)。发送查询的AN可记录对等体中的每一个在某一时间间隔期间愿意接收多少连接。在每个AN预期在做出连接接受决定时将其局部工作负载度量考虑在内的实施方案中,连接接受率可用作准确且容易获得的工作负载指示符。在其他实施方案中,AN可周期性地或者根据某一时间表简单地交换其局部工作负载度量的摘要或概要,并且此类概要可用于工作负载指示符。在一些实施方案中,工作负载指示符可仅响应于查询而发送,而在其他实施方案中,工作负载指示符可被推到对等组成员,而不管是否接收查询。在所描绘实施方案中,用于共享工作负载信息的特定技术可被选择(或修改),使得与查询/响应6570相关联的总流量和处理开销保持在阈值以下。
对等组的每个AN具有某一组建立或打开连接,诸如AN 6512A处的连接C11、C12...C1n,AN 6512B处的连接C21、C22...C2p,以及AN 6512C处的连接C31、C32...C3n。访问节点可各自维持关于其打开连接的各自连接统计值6504,例如,统计值6504A可维持在AN6512A处,统计值6504B可维持在AN 6512B处,并且统计值6504C可维持在AN 6512C处。针对特定连接Cjk维持的连接统计值6504可包括例如连接寿命的测量(例如,当Cjk建立时)、连接上的流量的量和时间分布、已关于连接请求的存储操作(例如,文件打开、读取、写入等)的数量、数据包的大小、丢弃的数据包的数量,等等。如果并且在AN确定连接将关闭或断开连接用于工作负载重新平衡时,可分析连接统计值6504,并且可根据可基于统计值的关闭目标选择准则关闭一个或多个连接。取决于使用的网络协议,AN可向客户端发送发起断开连接的适当消息;在一些实施方案中,可需要消息的交换来完全关闭连接。
在一些实施方案中,如果满足以下条件中的两者,那么可在访问节点6512处做出关闭连接的决定:(a)那个访问节点处的至少一个局部工作负载度量6115超过重新平衡阈值,以及(b)满足从收集的工作负载指示符导出的对等容量可用性准则。例如,在一个情景中,如果AN 6512的对等体中的至少70%将愿意基于最新可用工作负载指示符接受新的连接,并且AN 6512自己的工作负载水平已达到足够高的水平,那么AN 6512可决定关闭或丢弃所选择的连接。可使用基于局部工作负载的准则,使得仅在高度利用AN的局部资源时尝试连接重新平衡(例如,如此高度利用以至于将不接受新连接)。可考虑对等容量可用性准则,使得例如关闭的连接的另一端的客户端将具有建立连接并继续其存储服务请求流的合理机会。
如果做出关闭某一连接(或多个连接)的决定,那么在至少一些实施方案中,可基于对前述连接统计值6504的分析选择将关闭的特定连接。例如,为了避免在不同AN处重复关闭同一客户端的连接的振荡情境,已存在持续比某一阈值时间长的连接可被优选为关闭目标。在一些实施方案中,流量已导致更大资源使用的连接(例如,已用于资源密集型存储操作的连接)可相对于已导致AN处的更温和资源利用的那些连接被视为优选关闭目标。AN可随后根据使用的特定网络协议(例如,TCP)发起所选择连接的关闭。在至少一些实施方案中,响应于连接的关闭,客户端可试图建立另一连接。负载平衡器节点(可以是与参与现在关闭的连接的建立的LBN相同的LBN,或者不同LBN)可随后代表客户端向所选择AN(例如,属于关闭连接的AN的对等组)发布连接建立请求。可使用类似于前述的连接建立协议,直到找到愿意接受客户端的连接的AN(或者直到负载平衡器达到最大尝试计数)。如果用于做出连接重新平衡决定的对等容量可用性准则是AN对接受连接的意愿的良好指示符,那么客户端可很快能够建立新的连接来替换关闭的连接。在面向会话的文件系统受支持的至少一些实施方案中,客户端可甚至可能继续在连接重新平衡之前使用的同一会话,如以下参考图68描述的。在一个实施方案中,在特定AN已关闭与特定客户端C1的连接之后,如果AN代表同一客户端C1在重新连接阈值时间间隔内接收随后连接请求,那么可拒绝连接请求,例如,以便避免同一客户端已使其连接重复关闭的情境。
在一个实施方案中,负载平衡器节点可能够例如在客户端未得到通知或者不知道关闭其连接是由AN发起的情况下相对于客户端透明地建立替换连接。负载平衡器节点可能够检测(例如,通过检查从AN接收的数据包报头和/或数据包主体内容)已发起重新平衡相关的断开连接。在发现此情况之后,负载平衡器节点可选择不同AN,并且在不通知或告知客户端的情况下发起到不同AN的不同连接的建立。如果负载平衡器节点能够找到接受其请求的AN,那么在至少一些实施方案中,从客户端的角度来看,可能似乎没有什么改变(即,没有重新平衡的效应可由客户端注意到)。为了实现这种透明性,在一些实现方式中,负载平衡器和访问子系统可集体必须管理发起断开连接的AN与替换AN之间的连接状态信息传送。
图66示出根据至少一些实施方案的可在访问子系统节点处使用的连接接受和重新平衡准则的实例。在所描绘实施方案中,可以类似于前述方式的方式使用基于尝试计数的连接接受阈值。然而,需注意在至少一些实施方案中,使用的连接重新平衡技术可正交于连接接受准则,例如,可在实施方案中使用连接重新平衡,即使不使用上述基于尝试计数的连接接受技术亦是如此。
在图66中描绘的实施方案中,如先前论述的一些实例中,用于不同尝试计数水平的阈值可使得连接在尝试计数值升高时更容易被接受。因此,例如,为了拒绝具有等于三的尝试计数的连接请求,AN的已调整CPU负载(AL[CPU])将必须超过已调整CPU容量(AC[CPU])的0.6倍,并且AN的已调整网络负载(AL[net])将必须超过已调整网络容量(AC[net])的0.6倍。然而,为了拒绝具有为四的尝试计数值的连接请求,CPU和网络的已调整负载将各自必须更高(分别为0.8倍的AC[CPU]和0.8倍的AC[net])。
若干因素的组合有助于图66中示出的示例性重新平衡准则。第一,CPU、网络或两者的已调整局部负载水平必须超过0.85倍的对应已调整容量。第二,已调整存储器负载必须超过0.85倍的已调整存储器容量。第三,自先前连接在访问节点处由于重新平衡关闭以来必须消逝至少600秒。以及第四,对等访问节点将愿意接受新的连接(其可从对等组成员收集的工作负载指示符获得)的估计概率可必须超过70%。因此,在所描绘实施方案中,在连接由AN终止之前可必须通过一组相当严格的测试。
图67是示出根据至少一些实施方案的可在分布式存储服务的访问子系统处执行以实现连接重新平衡的操作的方面的流程图。如元素6701所示,可代表服务的一个或多个客户端在多租户分布式存储子系统的访问节点AN1与一个或多个负载平衡器节点(LBN)之间建立多个网络连接C1、C2...Cn。如前所述,在一些实施方案中,一组网络地址(例如,可从提供商网络的隔离虚拟网络内访问的私有虚拟IP地址或者可从互联网访问的公共可访问IP地址)可配置用于负载平衡器并暴露于希望访问服务的客户端。在一些实施方案中,基于尝试计数的连接接受准则可必须用于建立连接C1-Cn,而在其他实施方案中,可建立连接而无需考虑计数。在一些实施方案中,AN1可包括拦截并操纵前述由LBN发送的数据包的局部负载平衡器模块(LLBM),而在其他实施方案中,AN1可不包括此类LLBM。
在某一时间段T期间,AN1可收集两种种类的工作负载信息(元素6704):有关资源诸如AN的CPU、AN的联网模块等的局部工作负载信息,以及从多个对等AN获得的对等组工作负载指示符。在一些实施方案中,AN1可向选择组的对等体(例如,基于前述准则种类选择的对等组的成员)提交工作负载相关查询,并且可响应地接收工作负载指示符;在其他实施方案中,对等组的AN可在各个时间点处将其工作负载指示符主动推到彼此。在一些实现方式中,AN1可不时地向对等AN(例如,AN-k)提交查询以便确定AN-k是否愿意接受连接,并且AN-k的响应可被视为AN-k的工作负载的指示符。在至少一个实现方式中,AN1可向AN-k发送连接建立请求(例如,代替发送关于连接建立的查询)。在一些实施方案中,AN可按需要或者主动地向对等AN周期性地提供其当前局部工作负载估计的摘要或概要。在一个实施方案中,工作负载指示符可捎带在AN之间交换的其他类型的消息上,例如,在管理消息或心跳消息上。
在所描绘实施方案中,在选择连接终止或关闭之前可必须满足若干准则。AN1可确定其局部工作负载度量是否超过第一重新平衡阈值(元素6707)。在一些实施方案中,可使用将原始度量随时间迁移的变化考虑在内的已调整值表示局部工作负载度量,如先前关于针对连接接受性的已调整负载(AL)计算描述的。在一些实施方案中,第一重新平衡阈值可以各种资源的已调整容量单位表示,其留出一些本机资源容量作为处理可能故障的开销,也如先前关于用于限定连接接受准则的已调整容量(AC)描述的。在其他实施方案中,与考虑用于连接接收决定相比,不同组的工作负载度量和/或资源可考虑用于重新平衡决定。
如果满足用于重新平衡的基于局部工作负载的准则,那么AN1可确定是否已满足对等容量可用性准则(元素6710)。在所描绘实施方案中,可基于从其他AN获得的工作负载指示符确定对等容量可用性准则。在至少一些实施方案中,满足对等可用性准则可指示存在如果AN1终止到特定客户端的连接,那么那个客户端将能够建立与另一AN的连接的合理高概率。例如,在一个情景中,如果AN1自己的已调整负载(针对某一组选择资源)超过对应已调整容量的90%,那么可满足对等容量可用性准则,而AN1可使用对等工作负载指示符确定其对等组的成员中至少75%具有小于对应已调整容量的40%的已调整负载并且因此将可能接受新的连接。需注意,至少在一些实施方案中,在AN1处可用于给定对等体AN-k的最近工作负载指示符可将AN-k的状态表示为某一先前时间点,并且不同工作负载指示符可表示不同时间点。在此类实施方案中,对等容量可用性确定可因此基于大约而非精确数据。
如果满足用于重新平衡的局部工作负载准则和对等容量可用性准则,那么在所描绘实施方案中,AN1还可确定在最后时间单位Tmin内其连接中的任一个是否为了重新平衡目的而关闭(元素6713)。例如,在图66中示出的情境中,Tmin被设置为600秒。如果自先前重新平衡相关的连接终止以来大于最小阈值设置Tmin的时间已期满(或者如果这是在AN1处尝试的第一重新平衡),那么可基于关闭目标选择策略选择特定连接Cj用于终止(元素6716)。目标选择策略可考虑各种因素,诸如连接的寿命(在一些实施方案中,不太可能选择最近建立的连接以避免振荡行为)、连接上的流量的量、与连接相关联的各种AN资源(例如,CPU、存储器等)的使用量等等。在一些实施方案中,AN1可利用连接统计值6504来选择关闭目标。
在所描绘实施方案中可从AN1发起所选择目标连接的终止或关闭(元素6719),例如,根据使用的联网协议的适当连接终止句法。在确定连接已丢弃/关闭之后,代表其建立Cj的客户端可向所选择LBN提交另一连接建立请求(元素6722)。LBN可因此代表客户端例如与某一其他AN(例如,AN2)建立连接(元素6725)。需注意,取决于使用的连接接受准则和AN1的工作负载的改变,此新连接可在一些情况下由AN1自身接受。
在图67描绘的实施方案中,如果未满足基于局部工作负载的重新平衡阈值(如元素6707中检测的),那么AN1可继续其常规操作,如元素6704中指示的在随后时间段内收集局部和对等工作负载信息。如果未满足用于重新平衡的其他两个条件中的一个,例如,如果未满足对等容量可用性准则(元素6710)或者自上次连接终止以用于重新平衡以来已消逝不足够的时间,那么AN1可在所描绘实施方案中采取一些另外动作来处理其过量工作负载。例如,如元素6728所示,AN1可例如通过延迟所选择数据包的处理或者通过丢弃数据包来任选地开始节流其打开操作中的一个或多个。当然,取决于使用的联网协议的本质,此类动作可在一些情况下导致来自客户端的重新传输,并且可能起不了多大即时帮助,至少直到连接可选择用于终止的足够时间消逝。在另一实施方案中,如果满足元素6707的基于局部工作负载的重新平衡阈值,那么AN1可关闭所选择连接,即使未满足另外两个条件(对应于元素6710和6713)中的至少一个亦是如此。需注意,可按与一些实施方案中示出的次序不同的次序检查图67中的考虑来确定是否关闭连接的三个条件,例如,在一些实施方案中,情况可能是可先检查自先前终止以来消逝的时间,或者可先检查对等容量可用性。
在一些实施方案中,在分布式存储服务处支持的文件系统协议中的至少一个可以是前述面向会话的,例如,会话标识符可针对客户端生成并且与资源租用和/或锁定相关联。用于重新平衡的客户端连接的终止可在此类实施方案中导致不期望的会话终止,除非采取主动预防措施。图68是示出根据至少一些实施方案的可在分布式存储服务处执行以保存跨连接重新平衡事件的客户端会话的操作的方面的流程图。当例如响应于明确会话建立请求针对客户端C11建立客户端会话CS1时或者当客户端C11发布特定类型的存储请求时,对应会话元数据可由服务的从特定AN接收会话建立请求的元数据子系统节点存储或者存储在所述元数据子系统节点处。如元素6801所示,会话元数据可包括识别用于CS1的特定访问节点的字段(例如,向元数据节点提交会话建立请求并且意图用于来自C11的随后存储请求的AN)。还如图55所示,这种字段可称为“负责访问节点”(RAN)字段。客户端C11可指定在其通过AN1发送的随后存储相关请求中生成为会话元数据的部分的会话标识符(例如,NFS“客户端ID”参数)。
如元素6804所示,AN1可随后例如使用以上论述种类的重新平衡准则来确定C11的连接将终止/关闭以用于重新平衡。因此,可将会话元数据的RAN字段设置为“空”(或者指示没有AN负责的某一其他值)(元素6807)。在一些实施方案中,可由元数据节点在AN1的请求下执行对元数据的改变。连接可在AN1处主动终止。
最终,在C11认识到连接关闭之后,C11可例如向负载平衡器节点发送另一请求来视图重新建立到存储服务的连接(元素6810)。不同访问节点(AN2)可对由LBN代表C11提交的连接建立请求做出响应以接受连接(元素6813)。客户端C11可提交具有其在连接终止之前使用的相同会话标识符的存储服务请求(例如,打开()、读取()或写入())(元素6816)。AN2可接收这种存储服务请求,并且向元数据子系统发送查询来确定对应于客户端指定会话标识符的元数据的状态(元素6819)。如果元数据子系统能够针对指定的会话标识符找到会话元数据,并且如果该元数据的RAN字段设置为“空”(如元素6822中检测的),那么这可向AN2指示AN2可接受继续CL1与现存元数据的会话并承担对C11的会话的责任。因此,可将CS1的元数据的RAN字段设置为AN2的标识符(元素6825),并且可恢复CS1。否则,如果由于某一原因未找到CS1的元数据记录,或者如果CS1的元数据中的RAN字段未设置为“空”,那么在所描绘实施方案中可为客户端创建新的会话(元素6828)。在至少一些实施方案中,建立新的会话可涉及获取一个或多个锁/租用,并且可在此类实施方案中需要比当前会话可用AN2作为负责访问节点恢复的情况下多的资源。
需注意,在各种实施方案中,可使用除了图8a、8b、9、10、15、20、21、22、23、27、28、32、38、41、42、43、44、51、52、53、58、59、64、67和68的流程图中示出的操作之外的操作来实现上述分布式文件存储服务技术。在一些实施方案中,一些示出的操作可不实现,或者可按不同次序实现或者并行而不是顺序地实现。在至少一些实施方案中,上述技术可用于管理除了文件存储区之外的其他类型的存储服务处的工作负载变化,例如,类似技术可用于暴露卷级块存储接口的存储装置、允许使用网络服务接口而不是文件系统接口访问任意存储对象的非结构化存储装置,或者用于访问关系性数据库或非关系性数据库的表或者分区。
使用案例
上述实现支持一个或多个行业标准文件系统接口的高度可缩放、可用且耐久的文件存储系统的技术可用于多种情境中并用于多种客户。提供商网络的许多客户已经将若干其应用迁移到云以便充分利用可利用的大量计算能力。然而,针对此类应用关于在单个文件内存储非常大量的数据(例如,拍字节)并随后从大数量的客户端并行地访问文件而不影响性能的能力可能存在若干约束。关于文件系统目录层级,例如,给定目录可存储的对象数量以及目录层级可包含的级别数量,也可存在可缩放性约束。将节点无缝添加到各种文件存储服务子系统诸如访问子系统、元数据子系统以及存储子系统的能力可帮助减轻此类可缩放性限制。将元数据与数据逻辑地分开可帮助实现元数据和数据两者的期望不同水平的性能、可用性和耐久性,而不将元数据的要求(其可具有更严格的需要)强加在数据上。例如,元数据可优先存储在SSD上,而数据可容纳在比较便宜的基于转盘的装置上。提供商网络环境中的其他存储系统可不支持熟悉文件系统接口以及许多应用被设计来依赖的种类的一致性语义。
所述乐观并行控制机制,包括用于单页面写入的有条件写入机制以及用于多页面写入的分布式事务方案,可帮助避免通常在使用更多基于传统锁定的方案时出现的一些瓶颈类型。盘区过量预订和可变条带定大小可用于管理空间利用效率与元数据大小之间的权衡。基于偏移的拥塞控制技术可帮助改善某些类型的应用的总体I/O性能,例如,其中给定配置文件可必须在应用启动时由大数量的并行客户端线程读取的应用。对象重命名技术可帮助确保元数据节点故障情况下的文件系统一致性,所述元数据节点故障可能不可避免地出现在大型分布式文件存储区中。先前论述的命名空间管理技术可用于实现具有几百万对象(即使在单个目录内)的文件系统同时在对象数量增加时维持相对平坦的响应时间。客户端会话管理高速缓存和租用续订技术可帮助将会话相关开销保持为低。负载平衡和重新平衡方法可帮助减小过载诱发的故障的可能性。
可鉴于以下条款对本公开的实施方案进行描述:
1.一种系统,其包括:
一个或多个计算装置,其被配置来:
在分布式多租户文件存储服务的访问子系统处接收代表特定客户端建立针对文件存储操作的客户端会话的请求;
从所述访问子系统向所述文件存储服务的元数据子系统传输对将与所述客户端会话相关联的会话标识符的请求;
从所述元数据子系统向所述访问子系统提供会话标识符,所述会话标识符至少部分地基于存储所述客户端会话的元数据的一个或多个元素的持久性会话存储位置,其中所述一个或多个元素包括与所述客户端会话相关联的租用的指示;
在所述会话标识符传输到所述特定客户端之前,在所述访问子系统处高速缓存所述会话标识符以及所述租用的指示;
在所述元数据子系统处确定将存储与特定文件存储对象相关联的锁定状态指示符的持久性锁定存储位置,其中所述锁定状态指示符响应于来自所述客户端的不同请求生成,其中所述不同请求包括所述会话标识符并且其中所述锁定状态指示符包括所述会话标识符;
在所述访问子系统处高速缓存所述锁定状态指示符;
在所述访问子系统处利用所高速缓存会话标识符、所述租用的所高速缓存指示以及所高速缓存锁定状态指示符来对来自所述客户端的指向所述特定文件存储对象的服务请求做出响应;以及
响应于确定与所述租用相关联的超时已期满,将(a)所述锁定状态指示符从所述持久性锁定存储位置删除,并且将(b)所述会话标识符从所述持久性会话存储位置删除。
2.如条款1所述的系统,其中所述一个或多个计算装置还被配置来:
在所述访问子系统处确定在所述客户端会话期间从所述特定客户端接收的不同服务请求属于租用续订操作的种类;以及
发起所述租用的续订。
3.如条款2所述的系统,其中为了发起所述租用的所述续订,所述一个或多个计算装置还被配置来:
在所述访问子系统处响应于所述不同服务请求确定所述租用是由于在大于阈值时间段的时间段之后的期满;以及
在对所述元数据子系统的单个成批租用续订请求内,使续订与各自客户端会话相关联的各自租用的多个请求组合。
4.如条款1所述的系统,其中所述访问子系统包括多个访问节点,所述多个访问节点包括接收建立所述客户端会话的所述请求的特定访问节点,其中所述一个或多个计算装置还被配置来:
在存储在所述持久性会话存储位置处的元数据的所述一个或多个元素中的特定元素内,存储所述特定访问节点的标识符。
5.如条款1所述的系统,其中所述会话状态标识符和所述锁定状态指示符根据以下中的一个格式化:(a)NFS(网络文件系统)版本或(b)SMB(服务器消息块)版本。
6.一种方法,其包括:
由一个或多个计算装置执行以下各项:
从分布式文件存储服务的访问子系统向所述文件存储服务的元数据子系统传输对将与特定客户端的客户端会话相关联的会话标识符的请求;
在所述访问子系统处从所述元数据子系统接收会话标识符,所述会话标识符至少部分地基于存储所述客户端会话的元数据的一个或多个元素的持久性会话存储位置;
在所述会话标识符传输到所述特定客户端之前,在所述访问子系统处高速缓存所述会话标识符;
在所述访问子系统处从所述客户端接收特定请求,针对所述请求,将在特定文件存储对象上获得锁,其中所述特定请求包括所述会话标识符;
在所述元数据子系统处确定已代表不同客户端创建与所述特定文件存储对象相关联的冲突锁定状态指示符;以及
拒绝所述特定请求。
7.如条款6所述的方法,其还包括由所述一个或多个计算装置执行以下各项:
在所述访问子系统处从所述客户端接收第二请求,针对所述第二请求,将在不同文件存储对象上获得另一锁,其中所述另一请求包括所述会话标识符;
在所述元数据子系统处确定将存储与所述不同文件存储对象相关联的锁定状态指示符的持久性锁定存储位置,其中所述锁定状态指示符包括所述会话标识符;
在所述访问子系统处高速缓存所述锁定状态指示符;以及
在所述访问子系统处利用所高速缓存会话标识符以及所述锁定状态指示符的所高速缓存指示来对来自所述客户端的另一请求做出响应。
8.如条款7所述的方法,其中元数据的所述一个或多个元素包括与所述客户端会话相关联的租用的指示,其还包括由所述一个或多个计算装置执行以下项:
在所述访问子系统处高速缓存所述租用的所述指示。
9.如条款7所述的方法,其还包括由所述一个或多个计算装置执行以下各项:
在所述访问子系统处确定所述另一请求属于与所述文件存储对象相关联的租用续订操作的种类;以及
发起所述租用的续订。
10.如条款9所述的方法,其中所述发起所述租用的所述续订包括:
在所述访问子系统处响应于所述另一请求确定所述租用是由于在大于阈值时间段的时间段之后的期满;以及
在对所述元数据子系统的单个成批租用续订请求内,使续订与各自客户端会话相关联的各自租用的多个请求组合。
11.如条款9所述的方法,其中所述发起所述租用的所述续订包括:
在所述访问子系统处作为响应于所述另一请求执行的操作的部分确定所述租用是由于在小于阈值时间段的时间段之后的期满;以及
将非成批租用续订请求传输到所述元数据子系统。
12.如条款7所述的方法,其还包括由所述一个或多个计算装置执行以下各项:
在访问子系统高速缓存器处为所述会话标识符配置第一有效性期满超时设置;
在所述元数据子系统处为所述会话标识符配置第二有效性期满超时,其中所述第一有效性期满超时小于所述第二有效性期满超时。
13.如条款12所述的方法,其中根据用于所述客户端会话的文件系统协议,特定租用超时与所述客户端会话相关联,其中所述第二有效性期满超时大于所述特定租用超时,并且其中所述第一有效性期满超时至少部分地基于所述第二有效性期满超时与所述特定租用超时之间的差。
14.如条款7所述的方法,其中所述访问子系统包括具有特定访问节点的多个访问节点,所述方法还包括由所述一个或多个计算装置执行以下各项:
在所述将对会话标识符的所述请求传输到所述元数据子系统之前,在所述特定访问节点处从所述特定客户端接收建立所述客户端会话的请求;以及
在存储在所述持久性会话存储位置处的元数据的所述一个或多个元素中的特定元素内,存储所述特定访问节点的标识符。
15.如条款14所述的方法,其还包括由所述一个或多个计算装置执行以下各项:
在所述特定访问节点处基于工作负载平衡分析确定用于建立所述客户端会话的所述请求的网络连接将关闭;以及
从元数据的所述特定元素移除所述特定访问节点的所述标识符。
16.如条款7所述的方法,其中所述不同文件存储对象属于第一文件存储区,所述方法还包括由所述一个或多个计算装置执行以下项:
针对所述第一文件存储区指定将存储所述文件存储区的多个对象的锁定状态指示符的持久性存储对象,其中在所述元数据子系统处所述确定所述持久性锁定存储位置包括识别所述持久性存储对象的将存储所述锁定状态指示符的特定部分。
17.如条款6所述的方法,其中所述会话状态标识符和所述锁定状态指示符根据以下中的一个格式化:(a)NFS(网络文件系统)版本或(b)SMB(服务器消息块)版本。
18.一种存储程序指令的非暂时计算机可访问存储介质,所述程序指令当在一个或多个处理器上执行时:
从分布式文件存储服务的访问子系统向所述文件存储服务的元数据子系统传输对将与特定客户端的客户端会话相关联的会话标识符的请求;
在所述访问子系统处从所述元数据子系统接收会话标识符,所述会话标识符至少部分地基于存储所述客户端会话的元数据的一个或多个元素的持久性会话存储位置;
在所述会话标识符传输到所述特定客户端之前,在所述访问子系统处高速缓存所述会话标识符;
在所述访问子系统处从所述元数据子系统接收文件存储对象的锁定状态指示符,其中所述锁定状态指示符响应于在所述客户端会话期间来自所述客户端的特定请求在所述元数据子系统处生成;
在所述访问子系统处高速缓存所述锁定状态指示符;以及
在所述访问子系统处至少部分地基于所高速缓存会话标识符和所述锁定状态指示符的所高速缓存指示确定对来自所述客户端的指向所述特定文件存储对象的另一请求的响应。
19.如条款18所述的非暂时计算机可访问存储介质,其中元数据的所述一个或多个元素包括与所述客户端会话相关联的租用的指示,其中所述指令当在所述一个或多个处理器上执行时:
在所述访问子系统处高速缓存所述租用的所述指示。
20.如条款19所述的非暂时计算机可访问存储介质,其中所述指令当在所述一个或多个处理器上执行时:
在所述访问子系统处确定所述另一请求属于与所述文件存储对象相关联的租用续订操作的种类;以及
从所述访问子系统发起所述租用的续订。
21.如条款20所述的非暂时计算机可访问存储介质,其中为了发起所述租用的所述续订,所述指令当在所述一个或多个处理器上执行时:
在所述访问子系统处响应于所述另一请求确定所述租用是由于在大于阈值时间段的时间段之后的期满;以及
在对所述元数据子系统的单个成批租用续订请求内,使续订与各自客户端会话相关联的各自租用的多个请求组合。
22.如条款19所述的非暂时计算机可访问存储介质,其中所述会话状态标识符和所述锁定状态指示符根据以下中的一个格式化:(a)NFS(网络文件系统)版本或(b)SMB(服务器消息块)版本。
说明性计算机系统
在至少一些实施方案中,实现本文所述技术(包括实现分布式文件存储服务的访问、元数据和存储子系统的部件和/或负载平衡器节点的技术)中的一种或多种的一部分或全部的服务器可包括通用计算机系统,所述通用计算机系统包括一个或多个计算机可访问介质或被配置来访问一个或多个计算机可访问介质。图69示出这种通用计算装置9000。在示出的实施方案中,计算装置9000包括通过输入/输出(I/O)接口9030耦接到系统存储器9020(其可包括非易失性存储器模块和易失性存储器模块两者)的一个或多个处理器9010。计算装置9000还包括耦接到I/O接口9030的网络接口9040。
在各种实施方案中,计算装置9000可以是包括一个处理器9010的单处理器系统,或包括若干处理器9010(例如两个、四个、八个或另一合适数量)的多处理器系统。处理器9010可以是能够执行指令的任何合适处理器。例如,在各种实施方案中,处理器9010可以是实现多种指令集架构(ISA)中任何一种架构的通用或嵌入式处理器,所述架构如x86、PowerPC、SPARC或MIPS ISA或者任何其他合适的ISA。在多处理器系统中,每一个处理器9010可通常但并非必须实现同一ISA。在一些实现方式中,可代替或者除了常规处理器之外使用图形处理单元(GPU)。
系统存储器9020可被配置来存储可由处理器9010访问的指令和数据。在至少一些实施方案中,系统存储器9020可包括易失性部分和非易失性部分两者;在其他实施方案中,可仅使用易失性存储器。在各种实施方案中,系统存储器9020的易失性部分可使用任何合适的存储器技术来实现,所述存储器技术诸如静态随机存取存储器(SRAM)、同步动态RAM或任何其他类型的存储器。对于系统存储器的非易失性部分(例如其可包括一个或多个NVDIMM),在一些实施方案中可使用基于闪存的存储器装置,包括NAND闪存装置。在至少一些实施方案中,系统存储器的非易失性部分可包括电源,诸如超级电容器或其他电力存储装置(例如,电池)。在各种实施方案中,基于忆阻器的电阻性随机存取存储器(ReRAM)、三维NAND技术、铁电RAM、磁阻RAM(MRAM)或者各种类型的相变存储器(PCM)中的任一种可至少用于系统存储器的非易失性部分。在示出的实施方案中,实现一个或多个期望功能的程序指令和数据(诸如上文所述的那些方法、技术以及数据)示出为作为代码9025和数据9026存储在系统存储器9020内。
在一个实施方案中,I/O接口9030可被配置成协调处理器9010、系统存储器9020以及装置中的任何外围装置之间的I/O流量,所述外围装置包括网络接口9040或其他外围接口,诸如用于存储数据对象分区的物理复本的各种类型持久性和/或易失性存储装置。在一些实施方案中,I/O接口9030可执行任何必要协议、时序或其他数据转换,以便将来自一个部件(例如,系统存储器9020)的数据信号转换成适合于由另一个部件(例如,处理器9010)使用的格式。在一些实施方案中,I/O接口9030可包括对于通过各种类型外围总线附接的装置的支持,例如像外围部件互连(PCI)总线标准或通用串行总线(USB)标准的变型。在一些实施方案中,I/O接口9030的功能可划分到两个或更多个单独部件中,例如像北桥和南桥。另外,在一些实施方案中,I/O接口9030的功能性中的一些或全部,例如通向系统存储器9020的接口,可直接并入到处理器9010中。
网络接口9040可被配置成允许数据在计算装置9000与附接到一个或多个网络9050的其他装置9060(例如像如图1至图68中所示出的其他计算机系统或装置)之间进行交换。在各种实施方案中,网络接口9040可支持通过任何合适的有线或无线通用数据网络(例如像各类以太网网络)进行通信。另外,网络接口9040可支持通过电信/电话网络(诸如模拟语音网络或数字光纤通信网络)、通过存储区域网络(诸如光纤信道SAN)或者通过任何其他合适类型的网络和/或协议进行通信。
在一些实施方案中,系统存储器9020可以是计算机可访问介质的一个实施方案,所述计算机可访问介质被配置成存储如上文针对图1至图68所描述以便实现对应方法和设备的实施方案的程序指令和数据。然而,在其他实施方案中,可在不同类型的计算机可访问介质上接收、发送或存储程序指令和/或数据。一般来说,计算机可访问介质可包括非暂时存储介质或存储器介质,诸如磁性或光学介质,例如通过I/O接口9030耦接到计算装置9000的磁盘或DVD/CD。非暂时计算机可访问存储介质还可以包括可作为系统存储器9020或另一类型的存储器被包括在计算装置9000的一些实施方案中的任何易失性或非易失性介质,诸如RAM(例如,SDRAM、DDR SDRAM、RDRAM、SRAM等)、ROM等。此外,计算机可访问介质可包括经由通信介质(诸如网络和/或无线链路)传递的传输介质或信号,诸如电信号、电磁信号或数字信号,正如可通过网络接口9040来实现的。多个计算装置中的部分或全部(诸如图69中所示出的那些)可用于实现各种实施方案中的所描述功能;例如,在多种不同的装置和服务器上运行的软件部件可协作来提供功能性。在一些实施方案中,除了或者代替使用通用计算机系统来实现,所描述功能的部分可使用存储装置、网络装置或特殊用途计算机系统来实现。如本文所使用的术语“计算装置”是指至少所有这些类型的装置,并且不限于这些类型的装置。
总结
各个实施方案还可以包括在计算机可访问介质上接收、发送或存储根据前面的描述实现的指令和/或数据。一般来说,计算机可访问介质可包括存储介质或存储器介质,诸如磁性或光学介质(例如磁盘或DVD/CD-ROM)、易失性或非易失性介质(诸如RAM(例如,SDRAM、DDR、RDRAM、SRAM等)、ROM等),以及经由通信介质(诸如网络和/或无线链路)传递的传输介质或信号,诸如电信号、电磁信号或数字信号。
如图中所示出并且在本文中描述的各种方法表示方法的示例性实施方案。所述方法可以在软件、硬件或其组合中实现。方法的次序可以改变,并且各种元素可以添加、重新排序、组合、省略、修改等。
受益于本公开的本领域技术人员将清楚地知晓可做出各种修改和变化。本文旨在包含所有此类修改和变化,且因此,以上描述应视为具有说明性而非限制性意义。
- 还没有人留言评论。精彩留言会获得点赞!