神经网络中的分解卷积操作的制作方法
本申请要求于2014年7月16日提交且题为“DECOMPOSING CONVOLUTION OPERATION IN NEURAL NETWORKS(神经网络中的分解卷积操作)”的美国临时专利申请No.62/025,406的权益,其公开内容通过援引全部明确纳入于此。
技术背景
领域
本公开的某些方面一般涉及神经系统工程,并且尤其涉及用于使用分解卷积操作来训练及操作神经网络的系统和方法。
技术背景
可包括一群互连的人工神经元(即,神经元模型)的人工神经网络是一种计算设备或者表示将由计算设备执行的方法。人工神经网络可具有生物学神经网络中的对应的结构和/或功能。然而,人工神经网络可为其中传统计算技术是麻烦的、不切实际的、或不胜任的某些应用提供创新且有用的计算技术。由于人工神经网络能从观察中推断出功能,因此这样的网络在因任务或数据的复杂度使得通过常规技术来设计该功能较为麻烦的应用中是特别有用的。
概述
在本公开的一方面,给出了一种训练神经网络的方法。该方法包括鼓励该神经网络中的一个或多个滤波器具有低秩。
在本公开的另一方面,给出了一种用于训练神经网络的装置。该装置包括存储器以及耦合至该存储器的一个或多个处理器。(诸)处理器被配置成鼓励该神经网络中的一个或多个滤波器具有低秩。
在本公开的还有另一方面,给出了一种用于训练神经网络的装备。该装备包括用于鼓励该神经网络中的一个或多个滤波器具有低秩的装置。该装备还包括用于向(诸)滤波器应用分解卷积来训练该神经网络的装置。
在本公开的再另一方面,给出了一种用于训练神经网络的计算机程序产品。该计算机程序产品包括其上编码有程序代码的非瞬态计算机可读介质。该程序代码包括用以鼓励该神经网络中的一个或多个滤波器具有低秩的程序代码。
这已较宽泛地勾勒出本公开的特征和技术优势以便下面的详细描述可以被更好地理解。本公开的附加特征和优点将在下文描述。本领域技术人员应该领会,本公开可容易地被用作修改或设计用于实施与本公开相同的目的的其他结构的基础。本领域技术人员还应认识到,这样的等效构造并不脱离所附权利要求中所阐述的本公开的教导。被认为是本公开的特性的新颖特征在其组织和操作方法两方面连同进一步的目的和优点在结合附图来考虑以下描述时将被更好地理解。然而,要清楚理解的是,提供每一幅附图均仅用于解说和描述目的,且无意作为对本公开的限定的定义。
附图简要说明
在结合附图理解下面阐述的详细描述时,本公开的特征、本质和优点将变得更加明显,在附图中,相同附图标记始终作相应标识。
图1解说了根据本公开的某些方面的示例神经元网络。
图2解说了根据本公开的某些方面的计算网络(神经系统或神经网络)的处理单元(神经元)的示例。
图3解说了根据本公开的某些方面的尖峰定时依赖可塑性(STDP)曲线的示例。
图4解说了根据本公开的某些方面的用于定义神经元模型的行为的正态相和负态相的示例。
图5解说了根据本公开的某些方面的使用通用处理器来设计神经网络的示例实现。
图6解说了根据本公开的某些方面的设计其中存储器可以与个体分布式处理单元对接的神经网络的示例实现。
图7解说了根据本公开的某些方面的基于分布式存储器和分布式处理单元来设计神经网络的示例实现。
图8解说了根据本公开的某些方面的神经网络的示例实现。
图9是解说根据本公开的诸方面的用于操作神经网络的方法的流程图。
图10是解说根据本公开的诸方面的用于训练神经网络的方法的流程图。
详细描述
以下结合附图阐述的详细描述旨在作为各种配置的描述,而无意表示可实践本文中所描述的概念的仅有的配置。本详细描述包括具体细节以便提供对各种概念的透彻理解。然而,对于本领域技术人员将显而易见的是,没有这些具体细节也可实践这些概念。在一些实例中,以框图形式示出众所周知的结构和组件以避免湮没此类概念。
基于本教导,本领域技术人员应领会,本公开的范围旨在覆盖本公开的任何方面,不论其是与本公开的任何其他方面相独立地还是组合地实现的。例如,可以使用所阐述的任何数目的方面来实现装置或实践方法。另外,本公开的范围旨在覆盖使用作为所阐述的本公开的各个方面的补充或者与之不同的其他结构、功能性、或者结构及功能性来实践的此类装置或方法。应当理解,所披露的本公开的任何方面可由权利要求的一个或多个元素来实施。
措辞“示例性”在本文中用于意指“用作示例、实例或解说”。本文中描述为“示例性”的任何方面不必被解释为优于或胜过其他方面。
尽管本文描述了特定方面,但这些方面的众多变体和置换落在本公开的范围之内。虽然提到了优选方面的一些益处和优点,但本公开的范围并非旨在被限定于特定益处、用途或目标。相反,本公开的各方面旨在能宽泛地应用于不同的技术、系统配置、网络和协议,其中一些作为示例在附图以及以下对优选方面的描述中解说。详细描述和附图仅仅解说本公开而非限定本公开,本公开的范围由所附权利要求及其等效技术方案来定义。
示例神经系统、训练及操作
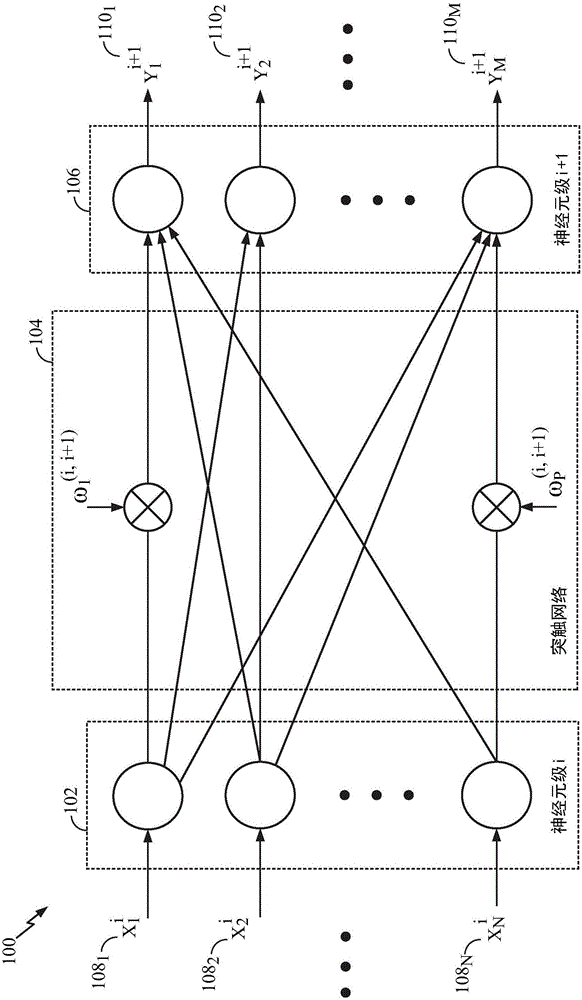
图1解说了根据本公开的某些方面的具有多级神经元的示例人工神经系统100。神经系统100可具有神经元级102,该神经元级102通过突触连接网络104(即,前馈连接)来连接到另一神经元级106。为简单起见,图1中仅解说了两级神经元,尽管神经系统中可存在更少或更多级神经元。应注意,一些神经元可通过侧向连接来连接至同层中的其他神经元。此外,一些神经元可通过反馈连接来后向连接至先前层中的神经元。
如图1所解说的,级102中的每一个神经元可以接收可由前级的神经元(未在图1中示出)生成的输入信号108。信号108可表示级102的神经元的输入电流。该电流可在神经元膜上累积以对膜电位进行充电。当膜电位达到其阈值时,该神经元可激发并生成输出尖峰,该输出尖峰将被传递到下一级神经元(例如,级106)。在一些建模办法中,神经元可以连续地向下一级神经元传递信号。该信号通常是膜电位的函数。此类行为可在硬件和/或软件(包括模拟和数字实现,诸如以下所述那些实现)中进行仿真或模拟。
在生物学神经元中,在神经元激发时生成的输出尖峰被称为动作电位。该电信号是相对迅速、瞬态的神经脉冲,其具有约为100mV的振幅和约为1ms的历时。在具有一系列连通的神经元(例如,尖峰从图1中的一级神经元传递至另一级神经元)的神经系统的特定实施例中,每个动作电位都具有基本上相同的振幅和历时,并且因此该信号中的信息可仅由尖峰的频率和数目、或尖峰的时间来表示,而不由振幅来表示。动作电位所携带的信息可由尖峰、发放了尖峰的神经元、以及该尖峰相对于一个或数个其他尖峰的时间来确定。尖峰的重要性可由向各神经元之间的连接所应用的权重来确定,如以下所解释的。
尖峰从一级神经元向另一级神经元的传递可通过突触连接(或简称“突触”)网络104来达成,如图1中所解说的。相对于突触104,级102的神经元可被视为突触前神经元,而级106的神经元可被视为突触后神经元。突触104可接收来自级102的神经元的输出信号(即,尖峰),并根据可调节突触权重来按比例缩放那些信号,其中P是级102的神经元与级106的神经元之间的突触连接的总数,并且i是神经元级的指示符。在图1的示例中,i表示神经元级102并且i+1表示神经元级106。此外,经按比例缩放的信号可被组合以作为级106中每个神经元的输入信号。级106中的每个神经元可基于对应的组合输入信号来生成输出尖峰110。可使用另一突触连接网络(图1中未示出)将这些输出尖峰110传递到另一级神经元。
生物学突触可以仲裁突触后神经元中的兴奋性或抑制性(超极化)动作,并且还可用于放大神经元信号。兴奋性信号使膜电位去极化(即,相对于静息电位增大膜电位)。如果在某个时间段内接收到足够的兴奋性信号以使膜电位去极化到高于阈值,则在突触后神经元中发生动作电位。相反,抑制性信号一般使膜电位超极化(即,降低膜电位)。抑制性信号如果足够强则可抵消掉兴奋性信号之和并阻止膜电位到达阈值。除了抵消掉突触兴奋以外,突触抑制还可对自发活跃神经元施加强力的控制。自发活跃神经元是指在没有进一步输入的情况下(例如,由于其动态或反馈而)发放尖峰的神经元。通过压制这些神经元中的动作电位的自发生成,突触抑制可对神经元中的激发模式进行定形,这一般被称为雕刻。取决于期望的行为,各种突触104可充当兴奋性或抑制性突触的任何组合。
神经系统100可由通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)或其他可编程逻辑器件(PLD)、分立的门或晶体管逻辑、分立的硬件组件、由处理器执行的软件模块、或其任何组合来仿真。神经系统100可用在大范围的应用中,诸如图像和模式识别、机器学习、电机控制、及类似应用等。神经系统100中的每一神经元可被实现为神经元电路。被充电至发起输出尖峰的阈值的神经元膜可被实现为例如对流经其的电流进行积分的电容器。
在一方面,电容器作为神经元电路的电流积分器件可被除去,并且可使用较小的忆阻器元件来替代它。这种办法可应用于神经元电路中,以及其中大容量电容器被用作电流积分器的各种其他应用中。另外,每个突触104可基于忆阻器元件来实现,其中突触权重变化可与忆阻器电阻的变化有关。使用纳米特征尺寸的忆阻器,可显著地减小神经元电路和突触的面积,这可使得实现大规模神经系统硬件实现更为切实可行。
对神经系统100进行仿真的神经处理器的功能性可取决于突触连接的权重,这些权重可控制神经元之间的连接的强度。突触权重可存储在非易失性存储器中以在掉电之后保留该处理器的功能性。在一方面,突触权重存储器可实现在与主神经处理器芯片分开的外部芯片上。突触权重存储器可与神经处理器芯片分开地封装成可更换的存储卡。这可向神经处理器提供多种多样的功能性,其中特定功能性可基于当前附连至神经处理器的存储卡中所存储的突触权重。
图2解说了根据本公开的某些方面的计算网络(例如,神经系统或神经网络)的处理单元(例如,神经元或神经元电路)202的示例性示图200。例如,神经元202可对应于来自图1的级102和106的任何神经元。神经元202可接收多个输入信号2041-204N,这些输入信号可以是该神经系统外部的信号、或是由同一神经系统的其他神经元所生成的信号、或这两者。输入信号可以是电流、电导、电压、实数值的和/或复数值的。输入信号可包括具有定点或浮点表示的数值。可通过突触连接将这些输入信号递送到神经元202,突触连接根据可调节突触权重2061-206N(W1-WN)对这些信号进行按比例缩放,其中N可以是神经元202的输入连接总数。
神经元202可组合这些经按比例缩放的输入信号,并且使用组合的经按比例缩放的输入来生成输出信号208(即,信号Y)。输出信号208可以是电流、电导、电压、实数值的和/或复数值的。输出信号可以是具有定点或浮点表示的数值。随后该输出信号208可作为输入信号传递至同一神经系统的其他神经元、或作为输入信号传递至同一神经元202、或作为该神经系统的输出来传递。
处理单元(神经元)202可由电路来仿真,并且其输入和输出连接可由具有突触电路的电连接来仿真。处理单元202及其输入和输出连接也可由软件代码来仿真。处理单元202还可由电路来仿真,而其输入和输出连接可由软件代码来仿真。在一方面,计算网络中的处理单元202可以是模拟电路。在另一方面,处理单元202可以是数字电路。在又一方面,处理单元202可以是具有模拟和数字组件两者的混合信号电路。计算网络可包括任何前述形式的处理单元。使用这样的处理单元的计算网络(神经系统或神经网络)可用在大范围的应用中,诸如图像和模式识别、机器学习、电机控制、及类似应用等。
在神经网络的训练过程期间,突触权重(例如,来自图1的权重和/或来自图2的权重2061-206N)可用随机值来初始化并根据学习规则而被增大或减小。本领域技术人员将领会,学习规则的示例包括但不限于尖峰定时依赖可塑性(STDP)学习规则、Hebb规则、Oja规则、Bienenstock-Copper-Munro(BCM)规则等。在一些方面,这些权重可稳定或收敛至两个值(即,权重的双峰分布)之一。该效应可被用于减少每个突触权重的位数、提高从/向存储突触权重的存储器读取和写入的速度、以及降低突触存储器的功率和/或处理器消耗。
突触类型
在神经网络的硬件和软件模型中,突触相关功能的处理可基于突触类型。突触类型可以是非可塑突触(权重和延迟没有改变)、可塑突触(权重可改变)、结构化延迟可塑突触(权重和延迟可改变)、全可塑突触(权重、延迟和连通性可改变)、以及基于此的变型(例如,延迟可改变,但在权重或连通性方面没有改变)。多种类型的优点在于处理可以被细分。例如,非可塑突触不会使用待执行的可塑性功能(或等待此类功能完成)。类似地,延迟和权重可塑性可被细分成可一起或分开地、顺序地或并行地运作的操作。不同类型的突触对于适用的每一种不同的可塑性类型可具有不同的查找表或公式以及参数。因此,这些方法将针对该突触的类型来访问相关的表、公式或参数。
还进一步牵涉到以下事实:尖峰定时依赖型结构化可塑性可独立于突触可塑性地来执行。结构化可塑性即使在权重幅值没有改变的情况下(例如,如果权重已达最小或最大值、或者其由于某种其他原因而不被改变)也可被执行,因为结构化可塑性(即,延迟改变的量)可以是pre-post(前-后)尖峰时间差的直接函数。替换地,结构化可塑性可被设为权重变化量的函数或者可基于与权重或权重变化的界限有关的条件来设置。例如,突触延迟可仅在权重变化发生时或者在权重到达0的情况下才改变,但在这些权重为最大值时则不改变。然而,具有独立函数以使得这些过程能被并行化从而减少存储器访问的次数和交叠可能是有利的。
突触可塑性的确定
神经元可塑性(或简称“可塑性”)是大脑中的神经元和神经网络响应于新的信息、感官刺激、发展、损坏、或机能障碍而改变其突触连接和行为的能力。可塑性对于生物学中的学习和记忆、以及对于计算神经元科学和神经网络是重要的。已经研究了各种形式的可塑性,诸如突触可塑性(例如,根据Hebbian理论)、尖峰定时依赖可塑性(STDP)、非突触可塑性、活跃性依赖可塑性、结构化可塑性和自稳态可塑性。
STDP是调节神经元之间的突触连接的强度的学习过程。连接强度是基于特定神经元的输出与收到输入尖峰(即,动作电位)的相对定时来调节的。在STDP过程下,如果至某个神经元的输入尖峰平均而言倾向于紧挨在该神经元的输出尖峰之前发生,则可发生长期增强(LTP)。于是使得该特定输入在一定程度上更强。另一方面,如果输入尖峰平均而言倾向于紧接在输出尖峰之后发生,则可发生长期抑压(LTD)。于是使得该特定输入在一定程度上更弱,并由此得名“尖峰定时依赖可塑性”。因此,使得可能是突触后神经元兴奋原因的输入甚至在将来作出贡献的可能性更大,而使得不是突触后尖峰的原因的输入在将来作出贡献的可能性更小。该过程继续,直至初始连接集合的子集保留,而所有其他连接的影响减小至无关紧要的水平。
由于神经元一般在其许多输入都在一短时段内发生(即,累积性足以引起输出)时产生输出尖峰,因此通常保留下来的输入子集包括倾向于在时间上相关的那些输入。另外,由于在输出尖峰之前发生的输入被加强,因此提供对相关性的最早充分累积性指示的那些输入将最终变成至该神经元的最后输入。
STDP学习规则可因变于突触前神经元的尖峰时间tpre与突触后神经元的尖峰时间tpost之间的时间差(即,t=tpost-tpre)来有效地适配将该突触前神经元连接到该突触后神经元的突触的突触权重。STDP的典型公式化是若该时间差为正(突触前神经元在突触后神经元之前激发)则增大突触权重(即,增强该突触),以及若该时间差为负(突触后神经元在突触前神经元之前激发)则减小突触权重(即,抑压该突触)。
在STDP过程中,突触权重随时间推移的改变可通常使用指数式衰退来达成,如由下式给出的:
其中k+和k-τsign(Δt)分别是针对正和负时间差的时间常数,a+和a-是对应的比例缩放幅值,并且μ是可应用于正时间差和/或负时间差的偏移。
图3解说了根据STDP,突触权重作为突触前(presynaptic)和突触后(postsynaptic)尖峰的相对定时的函数而改变的示例性示图300。如果突触前神经元在突触后神经元之前激发,则对应的突触权重可被增大,如曲线图300的部分302中所解说的。该权重增大可被称为该突触的LTP。从曲线图部分302可观察到,LTP的量可因变于突触前和突触后尖峰时间之差而大致呈指数式地下降。相反的激发次序可减小突触权重,如曲线图300的部分304中所解说的,从而导致该突触的LTD。
如图3中的曲线图300中所解说的,可向STDP曲线图的LTP(因果性)部分302应用负偏移μ。x轴的交越点306(y=0)可被配置成与最大时间滞后重合以考虑到来自层i-1的各因果性输入的相关性。在基于帧的输入(即,呈特定历时的包括尖峰或脉冲的帧的形式的输入)的情形中,可计算偏移值μ以反映帧边界。该帧中的第一输入尖峰(脉冲)可被视为要么如直接由突触后电位所建模地随时间衰退,要么在对神经状态的影响的意义上随时间衰退。如果该帧中的第二输入尖峰(脉冲)被视为与特定时间帧相关或有关,则该帧之前和之后的有关时间可通过使STDP曲线的一个或多个部分偏移以使得这些有关时间中的值可以不同(例如,对于大于一个帧为负,而对于小于一个帧为正)来在该时间帧边界处被分开并在可塑性意义上被不同地对待。例如,负偏移μ可被设为偏移LTP以使得曲线实际上在大于帧时间的pre-post时间处变得低于零并且它由此为LTD而非LTP的一部分。
神经元模型及操作
存在一些用于设计有用的尖峰发放神经元模型的一般原理。良好的神经元模型在以下两个计算态相(regime)方面可具有丰富的潜在行为:重合性检测和功能性计算。此外,良好的神经元模型应当具有允许时间编码的两个要素:输入的抵达时间影响输出时间,以及重合性检测能具有窄时间窗。最后,为了在计算上是有吸引力的,良好的神经元模型在连续时间上可具有闭合形式解,并且具有稳定的行为,包括在靠近吸引子和鞍点之处。换言之,有用的神经元模型是可实践且可被用于建模丰富的、现实的且生物学一致的行为并且可被用于对神经电路进行工程设计和反向工程两者的神经元模型。
神经元模型可取决于事件,诸如输入抵达、输出尖峰或其他事件,无论这些事件是内部的还是外部的。为了达成丰富的行为库,能展现复杂行为的状态机可能是期望的。如果事件本身的发生在撇开输入贡献(若有)的情况下能影响状态机并约束该事件之后的动态,则该系统的将来状态并非仅是状态和输入的函数,而是状态、事件和输入的函数。
在一方面,神经元n可被建模为尖峰带漏泄积分激发神经元,其膜电压vn(t)由以下动态来支配:
其中α和β是参数,wm,n是将突触前神经元m连接至突触后神经元n的突触的突触权重,以及ym(t)是神经元m的尖峰发放输出,其可根据Δtm,n被延迟达树突或轴突延迟才抵达神经元n的胞体。
应注意,从建立了对突触后神经元的充分输入的时间直至该突触后神经元实际上激发的时间存在延迟。在动态尖峰发放神经元模型(诸如Izhikevich简单模型)中,如果在去极化阈值vt与峰值尖峰电压vpeak之间有差量,则可引发时间延迟。例如,在该简单模型中,神经元胞体动态可由关于电压和恢复的微分方程对来支配,即:
其中v是膜电位,u是膜恢复变量,k是描述膜电位v的时间尺度的参数,a是描述恢复变量u的时间尺度的参数,b是描述恢复变量u对膜电位v的阈下波动的敏感度的参数,vr是膜静息电位,I是突触电流,以及C是膜的电容。根据该模型,神经元被定义为在v>vpeak时发放尖峰。
Hunzinger Cold模型
Hunzinger Cold神经元模型是能再现丰富多样的各种神经行为的最小双态相尖峰发放线性动态模型。该模型的一维或二维线性动态可具有两个态相,其中时间常数(以及耦合)可取决于态相。在阈下态相中,时间常数(按照惯例为负)表示漏泄通道动态,其一般作用于以生物学一致的线性方式使细胞返回到静息。阈上态相中的时间常数(按照惯例为正)反映抗漏泄通道动态,其一般驱动细胞发放尖峰,而同时在尖峰生成中引发等待时间。
如图4中所解说的,该模型400的动态可被划分成两个(或更多个)态相。这些态相可被称为负态相402(也可互换地称为带漏泄积分激发(LIF)态相,勿与LIF神经元模型混淆)以及正态相404(也可互换地称为抗漏泄积分激发(ALIF)态相,勿与ALIF神经元模型混淆)。在负态相402中,状态在将来事件的时间趋向于静息(v-)。在该负态相中,该模型一般展现出时间输入检测性质及其他阈下行为。在正态相404中,状态趋向于尖峰发放事件(vs)。在该正态相中,该模型展现出计算性质,诸如取决于后续输入事件而引发发放尖峰的等待时间。在事件方面对动态进行公式化以及将动态分成这两个态相是该模型的基础特性。
线性双态相二维动态(对于状态v和u)可按照惯例定义为:
其中qρ和r是用于耦合的线性变换变量。
符号ρ在本文中用于标示动态态相,在讨论或表达具体态相的关系时,按照惯例对于负态相和正态相分别用符号“-”或“+”来替换符号ρ。
模型状态由膜电位(电压)v和恢复电流u来定义。在基本形式中,态相在本质上是由模型状态来决定的。该精确和通用的定义存在一些细微却重要的方面,但目前考虑该模型在电压v高于阈值(v+)的情况下处于正态相404中,否则处于负态相402中。
态相相关时间常数包括负态相时间常数τ-和正态相时间常数τ+。恢复电流时间常数τu通常是与态相无关的。出于方便起见,负态相时间常数τ-通常被指定为反映衰退的负量,从而用于电压演变的相同表达式可用于正态相,在正态相中指数和τ+将一般为正,正如τu那样。
这两个状态元素的动态可在发生事件之际通过使状态偏离其零倾线(null-cline)的变换来耦合,其中变换变量为:
qρ=-τρβu-vρ (7)
r=δ(v+ε), (8)
其中δ、ε、β和v-、v+是参数。vρ的两个值是这两个态相的参考电压的基数。参数v-是负态相的基电压,并且膜电位在负态相中一般将朝向v-衰退。参数v+是正态相的基电压,并且膜电位在正态相中一般将趋向于背离v+。
v和u的零倾线分别由变换变量qρ和r的负数给出。参数δ是控制u零倾线的斜率的比例缩放因子。参数ε通常被设为等于-v-。参数β是控制这两个态相中的v零倾线的斜率的电阻值。τρ时间常数参数不仅控制指数式衰退,还单独地控制每个态相中的零倾线斜率。
该模型可被定义为在电压v达到值vS时发放尖峰。随后,状态可在发生复位事件(其可以与尖峰事件完全相同)之际被复位:
u=u+Δu, (10)
其中和Δu是参数。复位电压通常被设为v-。
依照瞬时耦合的原理,闭合形式解不仅对于状态是可能的(且具有单个指数项),而且对于到达特定状态的时间也是可能的。闭合形式状态解为:
因此,模型状态可仅在发生事件之际被更新,诸如在输入(突触前尖峰)或输出(突触后尖峰)之际被更新。还可在任何特定时间(无论是否有输入或输出)执行操作。
而且,依照瞬时耦合原理,突触后尖峰的时间可被预计,因此到达特定状态的时间可提前被确定而无需迭代技术或数值方法(例如,欧拉数值方法)。给定了先前电压状态v0,直至到达电压状态vf之前的时间延迟由下式给出:
如果尖峰被定义为发生在电压状态v到达vS的时间,则从电压处于给定状态v的时间起测量的直至发生尖峰前的时间量或即相对延迟的闭合形式解为:
其中通常被设为参数v+,但其他变型可以是可能的。
模型动态的以上定义取决于该模型是在正态相还是负态相中。如所提及的,耦合和态相ρ可基于事件来计算。出于状态传播的目的,态相和耦合(变换)变量可基于在上一(先前)事件的时间的状态来定义。出于随后预计尖峰输出时间的目的,态相和耦合变量可基于在下一(当前)事件的时间的状态来定义。
存在对该Cold模型、以及在时间上执行模拟、仿真、或建模的若干可能实现。这包括例如事件-更新、步阶-事件更新、以及步阶-更新模式。事件更新是其中基于事件或“事件更新”(在特定时刻)来更新状态的更新。步阶更新是以间隔(例如,1ms)来更新模型的更新。这不一定利用迭代方法或数值方法。通过仅在事件发生于步阶处或步阶间的情况下才更新模型或即通过“步阶-事件更新”,基于事件的实现以有限的时间分辨率在基于步阶的模拟器中实现也是可能的。”
神经网络中的分解卷积操作
深度卷积网络(DCN)被广泛使用于许多计算机视觉应用(包括对象分类、对象定位、面部识别和场景识别)中。卷积操作是DCN中最为计算密集的块之一。本公开的诸方面涉及用以通过在DCN中将二维(2D)卷积操作表达为1D卷积操作的组合来降低卷积操作的计算复杂度的方法。
卷积操作可以在一维(1D)阵列上理解。长度为N的输入向量X可以与长度为M的滤波器W进行卷积以产生长度为N-M+1的输出向量Y=X*W:
其中M和N是整数值。
忽视加法,计算复杂度可以就乘法的次数而言来表达。以上操作中的乘法的次数等于(N-M)*M。假设滤波器大小与输入大小相比较小,那么乘法的次数是使用大O记号的O(NM)乘法的阶数。
在深度卷积网络中,卷积操作可以在2D矩阵而非1D向量上执行。例如,N1×N2维度的输入矩阵X可以与M1×M2维度的滤波器矩阵W卷积来产生(N1-M1+1)×(N2-M2+1)维度的输出矩阵Y,如下:
计算复杂度可以是O(N1N2M1M2)乘法的阶数。若这些矩阵是正方矩阵,即,N1=N2=N以及M1=M2=M,那么计算复杂度是O(N2M2)的阶数。
分解2D卷积操作
2D卷积操作可以取决于滤波器矩阵W的秩表达为1D卷积操作的组合。例如,滤波器矩阵W可以使用奇异值分解(SVD)表达为秩1矩阵的线性组合。
在该示例中,秩(W)表示矩阵W的秩,矩阵W1、W2、…W秩(W)都是单位秩矩阵。进一步,每个单元秩矩阵可以被表达为列向量乘以行向量的乘积。
使用滤波器矩阵W的2D卷积操作可以被分解为使用单元秩矩阵的2D卷积操作的线性组合。使用单元秩矩阵的2D卷积操作的优点在于操作可以被分解为两个1D卷积操作。
在一个示例中,假设Wi=UiVTi,其中Ui是列向量以及VTi是行向量。那么2D卷积操作X*Wi可以通过首先将矩阵X的每一列与列向量Ui卷积,以及随后将所得矩阵的每一行与行向量VTi卷积来分解。
该使用两个1D卷积来计算与单元秩矩阵的2D卷积的方法具有计算复杂度:
N2O(N1M1)+N1O(N2M2)=O(N1N2(M1+M2))
因为列和行卷积操作针对每个单元秩矩阵重复,所以该办法的总体计算复杂度可以被表达为:
O(秩(W)N1N2(M1+M2))。
在正方矩阵的情形中,其等于O(2秩(W)N2M)。这是与O(N2M2)进行比较的,该O(N2M2)为2D卷积操作的计算复杂度。
若滤波器矩阵W具有较小的秩(秩(W))以及具有较大维度(M),那么该分解方法可以是高效的例如,考虑滤波器矩阵的大小是16×16且具有秩2的示例,那么使用该分解方法的O(2*2*16*N2)=O(64N2)次乘法与使用传统方法的O(256N2)次乘法比较。若滤波器矩阵W具有单位秩,那么该比较是O(32N2)次乘法和O(256N2)次乘法之间进行的。
根据本公开的诸方面,将2D卷积操作分解成1D卷积操作的方法可以按以下方式应用到DCN:
在一方面,DCN可以使用任何训练技术来训练。在训练的结束时,可以计算滤波器矩阵的秩。可通过比较O(N1N2M1M2)和O(秩(W)N1N2(M1+M2))来确定是否使用该分解方法来实现2D卷积操作。
在一些方面,DCN可以经历预处理,从而滤波器矩阵可以被低秩近似值来代替。可以仅使用顶部的若干单位秩矩阵来近似滤波器权重矩阵。
这里,R可以小至1,或者可以基于奇异值的能量分布来选择。通常,大多数的能量集中在顶部的若干奇异值中。在一些方面,R可以根据经验选择。例如,R可以通过为R尝试不同值来基于DCN的总体分类性能来选择。即,R的最终值可以根据R的不同值的验证数据集的准确度来确定。可以选择具有可忽略性能降级的R的最低值。
在低秩近似之后,可以使用预训练分类器,或者分类器可以被重新训练。
在另一方面,该训练过程可以被鼓励汇聚至单位秩或低秩滤波器权重矩阵。若秩<K/2,那么滤波器可以被视为具有低秩,其中K是例如滤波器权重矩阵的大小。低秩滤波器的另一示例是Gabor滤波器,其可以如以下表示:
若θ=0,90,180,或270,那么Gabor滤波器矩阵具有秩1并且因此是可分隔的。在另一方面,对于θ的所有其他值,Gabor滤波器的秩为2。在该情形中,Gabor滤波器是两个可分隔滤波器的总和。
在一个示例性方面,可以通过向目标函数增加正则化矩阵项(例如,成本函数)从而惩罚高秩矩阵来鼓励单位或低秩滤波器矩阵。例如,可以使用核范数来减小秩。核范数是奇异值之和并可以表达为:
其中σi是奇异值,以及对于每个滤波器λ||W||*与目标函数相加,其中λ是成本函数。相应地,权重衰减项被增加到梯度更新式中。当然,其他正则化矩阵也可以被用来减小滤波器秩。在已经减小滤波器秩的情形中,可以应用分解卷积。
在另一示例性方面,滤波器权重矩阵的特定秩(例如,单位秩或低秩)可以被强制,以及可以应用后向传播(或者等效的梯度下降)来计算这些强制矩阵上的更新。
例如,假设滤波器矩阵被强制为具有单位秩。那么W是UVT的形式,其中U是列向量以及V是行向量。元素wij可以不是自由变量,但是作为替代可以是基于自由变量ui和vj推导而得的变量:
wij=uivj. (21)
可以应用后向传播过程来针对元素wij计算部分梯度。该关于元素wij的部分梯度可以进而被用来按一下方式关于自由变量ui和vj计算部分梯度。
其中L表示被减小的损耗(或目标)函数。这些部分梯度可以被用来更新变量ui和vj,以及在单位秩权重矩阵的空间中实质上执行梯度派生。由此,结果经训练的DCN将具有单位秩矩阵以及可以采用该分解方法来高效地实现卷积操作。
在另一示例性方面,滤波器矩阵上的仲裁秩(r)可以被强制而非将滤波器矩阵强制为具有单位秩。可以执行用以计算部分梯度的后向传播过程来确定变量ui和vj的更新,如以上所讨论的。
在一些方面,可以为每个贡献单位秩矩阵使用相同权重更新以及使用分集的随机初始情况。在另一方面,r列向量彼此正交以及r行向量彼此正交的附加约束可以被用来鼓励分集。
在一些方面,重用可分隔滤波器可以是合需的。例如,DCN具有多个滤波器在相同输入上操作时,鼓励重用底层滤波器(underlying filter)是有益的。这可以通过配置一组L个可分隔滤波器U1V1T,U2V2T,…ULVL.T来达成。每个滤波器可以被限制为底层滤波器的大小为R的随机子集的线性组合:
其中Sp是滤波器p所使用的可分隔滤波器的子集,且αpr是线性组合参数。可以应用后向传播来学习这L个可分隔滤波器以及线性组合参数。
图5解说了根据本公开的某些方面的使用通用处理器502进行前述分解的示例实现500。与计算网络(神经网络)相关联的变量(神经信号)、突触权重、系统参数、延迟、和频槽信息可被存储在存储器块504中,而在通用处理器502处执行的指令可从程序存储器506中加载。在本公开的一方面,加载到通用处理器502的指令可包括用于确定可分隔滤波器的数目以表达神经网络中的滤波器和/或选择性地向滤波器应用分解卷积的代码。
在本公开的另一方面,加载到通用处理器502的指令可包括用于鼓励神经网络中的一个或多个滤波器具有低秩的代码。
图6解说了根据本公开的某些方面的前述分解技术的示例实现600,其中存储器602可以经由互连网络604与计算网络(神经网络)的个体(分布式)处理单元(神经处理器)606对接。与计算网络(神经网络)相关联的变量(神经信号)、突触权重、系统参数,延迟,频率槽信息,正则化信息和系统度量可被存储在存储器602中,并且可从存储器602经由互连网络604的连接被加载到每个处理单元(神经处理器)606中。在本公开的一方面,处理单元606可以配置成确定可分隔滤波器的数目以表达神经网络中的滤波器和/或选择性地向滤波器应用分解卷积。
在本公开的另一方面,处理单元606可配置成鼓励神经网络中的一个或多个滤波器具有低秩。
图7解说前述分解的示例实现700。如图7中所解说的,一个存储器组702可与计算网络(神经网络)的一个处理单元704直接对接。每一个存储器组702可存储与对应的处理单元(神经处理器)704相关联的变量(神经信号)、突触权重、和/或系统参数,延迟,频率槽信息,正则化信息和/或系统度量。在本公开的一方面,处理单元704可以配置成确定可分隔滤波器的数目以表达神经网络中的滤波器和/或选择性地向滤波器应用分解卷积。
在本公开的另一方面,处理单元704可配置成鼓励神经网路中的一个或多个滤波器具有低秩。
图8解说了根据本公开的某些方面的神经网络800的示例实现。如图8中所解说的,神经网络800可具有多个局部处理单元802,它们可执行本文所描述的方法的各种操作。每个局部处理单元802可包括存储该神经网络的参数的局部状态存储器804和局部参数存储器806。另外,局部处理单元802可具有用于存储局部模型程序的局部(神经元)模型程序(LMP)存储器808、用于存储局部学习程序的局部学习程序(LLP)存储器810、以及局部连接存储器812。此外,如图8中所解说的,每个局部处理单元802可与用于提供针对该局部处理单元的各局部存储器的配置的配置处理器单元814对接,并且与提供各局部处理单元802之间的路由的路由连接处理单元816对接。
在一个配置中,神经元模型被配置成用于确定可分隔滤波器的数目以表达神经网络中的滤波器和/或选择性地向滤波器应用分解卷积。神经元模型包括确定装置和应用装置。在一个方面,该确定装置和/或应用装置可以是被配置成执行所叙述的功能的通用处理器502、程序存储器506、存储器块504、存储器602、互连网络604、处理单元606、处理单元704、局部处理单元802、和/或路由连接处理单元816。在另一配置中,前述装置可以是被配置成执行由前述装置所叙述的功能的任何模块或任何装置。
在另一配置中,神经元模型被配置成用于鼓励神经网络中的一个或多个滤波器具有低秩以及向(诸)滤波器应用分解卷积以训练神经网络。神经元模型包括鼓励装置和应用装置。在一个方面,该鼓励装置和/或应用装置可以是被配置成执行所叙述的功能的通用处理器502、程序存储器506、存储器块504、存储器602、互连网络604、处理单元606、处理单元704、局部处理单元802、和/或路由连接处理单元816。在另一配置中,前述装置可以是被配置成执行由前述装置所叙述的功能的任何模块或任何装置。
根据本公开的某些方面,每个局部处理单元802可被配置成基于神经网络的一个或多个期望功能性特征来确定神经网络的参数,以及随着所确定的参数被进一步适配、调谐和更新来使这一个或多个功能性特征朝着期望的功能性特征发展。
图9解说了用于操作神经网络的方法900。在框902,该过程确定可分隔滤波器的数目以表达神经网络中的滤波器。例如,该过程可以确定足以表达或近似神经网络中的滤波器的可分隔滤波器的数目。在一些方面,确定可分隔滤波器的数目可以基于滤波器的秩。在其他方面,确定可分隔滤波器的数目可以基于滤波器的奇异值分解(SVD)。
在框904,该过程还可以选择性地向滤波器应用分解卷积。
在一些方面,神经元模型可以进一步用低秩近似代替滤波器。该代替可以基于例如性能度量。在一些方面,该代替可以基于通过计算奇异值分解获得的奇异值。
图10解说了训练神经网络的方法1000。在框1002,神经元模型鼓励神经网络中的一个或多个滤波器具有低秩。在一些方面,神经元模型通过向(诸)滤波器的滤波器权重矩阵应用正则化矩阵来鼓励(诸)滤波器具有低秩。该正则化矩阵可包括例如成本度量或核范数。进一步,在框1004,神经元模型向(诸)滤波器应用分解卷积来训练神经网络。
在一些方面,神经元模型通过将滤波器分成行滤波器和列滤波器的线性组合来鼓励(诸)滤波器具有低秩。神经元模型可进一步应用通过后向传播学习到的梯度更新来学习行滤波器和列滤波器。
以上所描述的方法的各种操作可由能够执行相应功能的任何合适的装置来执行。这些装置可包括各种硬件和/或(诸)软件组件和/或(诸)模块,包括但不限于电路、专用集成电路(ASIC)、或处理器。一般而言,在附图中有解说的操作的场合,那些操作可具有带相似编号的相应配对装置加功能组件。
如本文所使用的,术语“确定”涵盖各种各样的动作。例如,“确定”可包括演算、计算、处理、推导、研究、查找(例如,在表、数据库或其他数据结构中查找)、探知及诸如此类。另外,“确定”可包括接收(例如接收信息)、访问(例如访问存储器中的数据)、及类似动作。而且,“确定”可包括解析、选择、选取、确立及类似动作。
如本文所使用的,引述一列项目中的“至少一个”的短语是指这些项目的任何组合,包括单个成员。作为示例,“a、b或c中的至少一个”旨在涵盖:a、b、c、a-b、a-c、b-c、以及a-b-c。
结合本公开所描述的各种解说性逻辑框、模块、以及电路可用设计成执行本文所描述功能的通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列信号(FPGA)或其他可编程逻辑器件(PLD)、分立的门或晶体管逻辑、分立的硬件组件或其任何组合来实现或执行。通用处理器可以是微处理器,但在替换方案中,处理器可以是任何市售的处理器、控制器、微控制器、或状态机。处理器还可被实现为计算设备的组合,例如DSP与微处理器的组合、多个微处理器、与DSP核心协同的一个或多个微处理器、或任何其它此类配置。
结合本公开描述的方法或算法的步骤可直接在硬件中、在由处理器执行的软件模块中、或在这两者的组合中实施。软件模块可驻留在本领域所知的任何形式的存储介质中。可使用的存储介质的一些示例包括随机存取存储器(RAM)、只读存储器(ROM)、闪存、可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)、寄存器、硬盘、可移动盘、CD-ROM,等等。软件模块可包括单条指令、或许多条指令,且可分布在若干不同的代码段上,分布在不同的程序间以及跨多个存储介质分布。存储介质可被耦合到处理器以使得该处理器能从/向该存储介质读写信息。在替换方案中,存储介质可以被整合到处理器。
本文所公开的方法包括用于达成所描述的方法的一个或多个步骤或动作。这些方法步骤和/或动作可以彼此互换而不会脱离权利要求的范围。换言之,除非指定了步骤或动作的特定次序,否则具体步骤和/或动作的次序和/或使用可以改动而不会脱离权利要求的范围。
本文中所描述的功能可以在硬件、软件、固件、或其任何组合中实现。如果以硬件实现,则示例硬件配置可包括设备中的处理系统。处理系统可以用总线架构来实现。取决于处理系统的具体应用和整体设计约束,总线可包括任何数目的互连总线和桥接器。总线可将包括处理器、机器可读介质、以及总线接口的各种电路链接在一起。总线接口可用于尤其将网络适配器等经由总线连接至处理系统。网络适配器可用于实现信号处理功能。对于某些方面,用户接口(例如,按键板、显示器、鼠标、操纵杆,等等)也可以被连接到总线。总线还可以链接各种其他电路,诸如定时源、外围设备、稳压器、功率管理电路以及类似电路,它们在本领域中是众所周知的,因此将不再进一步描述。
处理器可负责管理总线和一般处理,包括执行存储在机器可读介质上的软件。处理器可用一个或多个通用和/或专用处理器来实现。示例包括微处理器、微控制器、DSP处理器、以及其他能执行软件的电路系统。软件应当被宽泛地解释成意指指令、数据、或其任何组合,无论是被称作软件、固件、中间件、微代码、硬件描述语言、或其他。作为示例,机器可读介质可包括随机存取存储器(RAM)、闪存、只读存储器(ROM)、可编程只读存储器(PROM)、可擦式可编程只读存储器(EPROM)、电可擦式可编程只读存储器(EEPROM)、寄存器、磁盘、光盘、硬驱动器、或者任何其他合适的存储介质、或其任何组合。机器可读介质可被实施在计算机程序产品中。该计算机程序产品可以包括包装材料。
在硬件实现中,机器可读介质可以是处理系统中与处理器分开的一部分。然而,如本领域技术人员将容易领会的,机器可读介质或其任何部分可在处理系统外部。作为示例,机器可读介质可包括传输线、由数据调制的载波、和/或与设备分开的计算机产品,所有这些都可由处理器通过总线接口来访问。替换地或补充地,机器可读介质或其任何部分可被集成到处理器中,诸如高速缓存和/或通用寄存器文件可能就是这种情形。虽然所讨论的各种组件可被描述为具有特定位置,诸如局部组件,但它们也可按各种方式来配置,诸如某些组件被配置成分布式计算系统的一部分。
处理系统可以被配置为通用处理系统,该通用处理系统具有一个或多个提供处理器功能性的微处理器、以及提供机器可读介质中的至少一部分的外部存储器,它们都通过外部总线架构与其他支持电路系统链接在一起。替换地,该处理系统可以包括一个或多个神经元形态处理器以用于实现本文所述的神经元模型和神经系统模型。作为另一替换方案,处理系统可以用带有集成在单块芯片中的处理器、总线接口、用户接口、支持电路系统、和至少一部分机器可读介质的专用集成电路(ASIC)来实现,或者用一个或多个现场可编程门阵列(FPGA)、可编程逻辑器件(PLD)、控制器、状态机、门控逻辑、分立硬件组件、或者任何其他合适的电路系统、或者能执行本公开通篇所描述的各种功能性的电路的任何组合来实现。取决于具体应用和加诸于整体系统上的总设计约束,本领域技术人员将认识到如何最佳地实现关于处理系统所描述的功能性。
机器可读介质可包括数个软件模块。这些软件模块包括当由处理器执行时使处理系统执行各种功能的指令。这些软件模块可包括传送模块和接收模块。每个软件模块可以驻留在单个存储设备中或者跨多个存储设备分布。作为示例,当触发事件发生时,可以从硬驱动器中将软件模块加载到RAM中。在软件模块执行期间,处理器可以将一些指令加载到高速缓存中以提高访问速度。随后可将一个或多个高速缓存行加载到通用寄存器文件中以供处理器执行。在以下述及软件模块的功能性时,将理解此类功能性是在处理器执行来自该软件模块的指令时由该处理器来实现的。
如果以软件实现,则各功能可作为一条或多条指令或代码存储在计算机可读介质上或藉其进行传送。计算机可读介质包括计算机存储介质和通信介质两者,这些介质包括促成计算机程序从一地向另一地转移的任何介质。存储介质可以是能被计算机访问的任何可用介质。作为示例而非限定,此类计算机可读介质可包括RAM、ROM、EEPROM、CD-ROM或其他光盘存储、磁盘存储或其他磁存储设备、或能用于携带或存储指令或数据结构形式的期望程序代码且能被计算机访问的任何其他介质。另外,任何连接也被正当地称为计算机可读介质。例如,如果软件是使用同轴电缆、光纤电缆、双绞线、数字订户线(DSL)、或无线技术(诸如红外(IR)、无线电、以及微波)从web网站、服务器、或其他远程源传送而来,则该同轴电缆、光纤电缆、双绞线、DSL或无线技术(诸如红外、无线电、以及微波)就被包括在介质的定义之中。如本文中所使用的盘(disk)和碟(disc)包括压缩碟(CD)、激光碟、光碟、数字多用碟(DVD)、软盘、和碟,其中盘(disk)常常磁性地再现数据,而碟(disc)用激光来光学地再现数据。因此,在一些方面,计算机可读介质可包括非瞬态计算机可读介质(例如,有形介质)。另外,对于其他方面,计算机可读介质可包括瞬态计算机可读介质(例如,信号)。上述的组合应当也被包括在计算机可读介质的范围内。
因此,某些方面可包括用于执行本文中给出的操作的计算机程序产品。例如,此类计算机程序产品可包括其上存储(和/或编码)有指令的计算机可读介质,这些指令能由一个或多个处理器执行以执行本文中所描述的操作。对于某些方面,计算机程序产品可包括包装材料。
此外,应当领会,用于执行本文中所描述的方法和技术的模块和/或其它恰适装置能由用户终端和/或基站在适用的场合下载和/或以其他方式获得。例如,此类设备能被耦合至服务器以促成用于执行本文中所描述的方法的装置的转移。替换地,本文所述的各种方法能经由存储装置(例如,RAM、ROM、诸如压缩碟(CD)或软盘等物理存储介质等)来提供,以使得一旦将该存储装置耦合至或提供给用户终端和/或基站,该设备就能获得各种方法。此外,可利用适于向设备提供本文所描述的方法和技术的任何其他合适的技术。
将理解,权利要求并不被限定于以上所解说的精确配置和组件。可在以上所描述的方法和装置的布局、操作和细节上作出各种改动、更换和变形而不会脱离权利要求的范围。
- 还没有人留言评论。精彩留言会获得点赞!