机器翻译方法以及机器翻译装置与流程
本发明涉及进行多种语言之间的翻译的装置、进行多种语言之间的翻译的方法以及进行多种语言之间的翻译的系统。
背景技术:
随着近年来的全球化,正在进行着用于使以不同语言为母语的用户之间的交流成为可能的机器翻译装置、机器翻译系统的开发。另外,对提供机器翻译功能的服务的运用也已经开始,例如在旅行对话等场景中逐渐实际地得到了应用。
现有技术文献
专利文献
专利文献1:日本专利第5653392号公报
专利文献2:日本特开2005-78318号公报
专利文献3:日本专利第5097340号公报
专利文献4:国际公开第2013/014877号
非专利文献
非专利文献1:Papineni,K.,Roukos,S.,Ward,T.,and Zhu,W.J.[BLEU:a method for automatic evaluation of machine translation],Proc.Of the Annual Meeting of the Association of Computational Linguistics(ACL),pp.311-318,2002
非专利文献2:高地なつめ、磯崎秀樹、「スクランブリングを考慮した和訳の自動評価法のNTCIR-9数据による検証」、第219回自然言語処理研究発表会、岡山県立大、2014
非专利文献3:Ilya Sutskever Papineni等、[Sequence to Sequence Learning with Neural Networks],Advances in Neural Information Processing Systems 27,pp.3104-3112,2014
非专利文献4:Dzmitry Bahdanau等、[Neural Machine Translation by Jointly Learning to Align and Translate],arXiv:1409.0473v5,ICLR 2015
技术实现要素:
发明所要解决的问题
然而,上述的机器翻译装置、机器翻译系统需要进一步的改善。
用于解决问题的技术方案
用于解决上述问题的本发明的一个技术方案是机器翻译系统中的机器翻译方法,所述机器翻译系统连接于输出语言信息的信息输出装置,执行第一语言与第二语言之间的翻译处理,所述机器翻译方法包括:接收所述第一语言的翻译对象文;生成将接收到的所述翻译对象文向所述第二语言翻译而得到的多个不同的顺向翻译文;生成针对所述多个不同的所述顺向翻译文的每一个来向所述第一语言逆向翻译而得到的多个逆向翻译文;在所述信息输出装置正输出着所述多个逆向翻译文时受理到从所述多个逆向翻译文中选择一个逆向翻译文的操作的情况下,输出与所述一个逆向翻译文对应的所述顺向翻译文。
发明效果
根据上述技术方案,实现了进一步改善。
附图说明
图1是表示本实施方式中的机器翻译系统的整体结构的一例的图。
图2是表示本实施方式中的信息显示终端结构的框图。
图3是表示本实施方式中的翻译服务器的结构的框图。
图4是表示本实施方式中的机器翻译系统的硬件结构的图。
图5是表示本实施方式中的机器翻译系统的工作的流程图。
图6是表示本实施方式中的译文选择处理的具体工作的流程图。
图7是表示本实施方式中的逆向翻译文选择处理的具体工作的流程图。
图8是表示本实施方式中的短语评价处理的具体工作的流程图。
图9是表示本实施方式中的学习处理的具体工作的流程图。
图10是表示本实施方式中的学习处理的具体工作的流程图。
图11是本实施方式中的一般的短语表的例子。
图12是用于表现本实施方式中的短语分割的概要的说明图。
图13的(A)、(B)、(C)分别是表示本实施方式中的显示画面的一例的图。
图14是表示本实施方式中的显示画面的一例的图。
标号说明
100:信息显示终端
101:通信部
102:输入部
103:输出部
104:控制部
105:选择文检测部
106:存储部
200:网络
210:通信部
220:控制部
230:机器翻译部
231:顺向翻译部
232:顺向翻译文选择部
233:逆向翻译部
234:逆向翻译文选择部
235:选择文判断部
236:短语分割部
237:选择结果评价部
238:学习部
240:存储部
300:翻译服务器
400:麦克风
500:扬声器
1000:计算机
1001:输入装置
1002:输出装置
1003:CPU
1004:ROM
1005:RAM
1006:存储装置
1007:读取装置
1008:收发装置
1009:总线
具体实施方式
以下说明的实施方式均表示本发明的一具体例。在以下的实施方式中表示的数值、形状、构成要素、步骤以及步骤的顺序等仅为一例,并非旨在限定本发明。另外,对于以下的实施方式中的构成要素中的没有记载在表示最上位概念的独立权利要求中的构成要素,将作为任意的构成要素进行说明。另外,在所有的实施方式中,也可组合各自的内容。
(得到本发明的见解)
在翻译设备的开发盛行的状况下,要实现不同语言下的顺利交流,希望机器翻译的精度是完善的。然而,在现状的机器翻译中,对任何句子都 无误地进行翻译是极其困难的,虽然通过将可翻译领域(范围)限定为旅行对话这样的形式提高了翻译精度,但仍处于远远达不到完善的状况。
在此,机器翻译技术大致分为三类。在本文中分别称为:1)基于规则的机器翻译(RBMT:Rule-Based Machine Translation)、2)统计机器翻译(SMT:Statistical Machine Translation)、3)基于深度神经网络获得模型的机器翻译(DNNMT:Deep Neural Network Machine Translation,深度神经网络机器翻译)。
1)基于规则的机器翻译(RBMT)
基于规则的机器翻译(RBMT)是以通过人工构建的转换规则(将译语对作为数据库进行存储而得到的规则)为基础进行翻译的系统,原文与译文的数据库有时也被表达为翻译存储器。
作为优点可举出“由于能够严密地定义规则(进行翻译的模式),因此,当原文(的一部分)存在于该规则内时,所对应的部分的翻译精度高,通过预先整理规则内的翻译表达,也易于对翻译输出的翻译表达保持一贯性”。
缺点可举出“在不存在规则的情况下翻译精度会变得非常低,或者完全翻译不出来,对预想以外的行业、领域的适应性极低”。另外,由于基本上通过人工构建、扩充规则,因此,开发所花费的成本也高。再者,为了提高翻译性能而需要添加规则,但是要在用户侧构建规则而对翻译系统进行定制,则要求对于规则的设计规则要具备相当的知识,因此,一般用户无法轻松地使用。为此,基于规则的翻译(RBMT)的主要开展对象为业务用翻译(专利翻译等),市场出售的业务用翻译软件大多使用了该基于规则的翻译和/或翻译存储器。
2)统计机器翻译(SMT)
统计机器翻译(SMT)是如下的方法:并不创建如RBMT那样的规则(rule),而是大量地准备被称为对译语料库(Translation Corpus)的“源语言与目标语言这两者的译文对”,根据该对译语料库,统计性地计算翻译概率并生成译文。该方法被广泛用于谷歌(Google,注册商标)和 微软(Microsoft,注册商标)等在网页上提供的翻译引擎。
该方法是如下的方法:在计算翻译概率时,根据对译语料库,分别对语言模型(通常是用n-gram模型来表现单一语言中的单词间的出现概率)以及翻译模型(通常是将双语言间的以单词或短语为单位的对应关系作为对齐模型(Alignment Model)来表现,将各单词间的词汇级别的译语对关系作为“词汇模型”来表现)这两个模型统计性地计算概率,并获得各模型的参数(概率值),由此实现统计性翻译。一般被称为“IBM模型”。(在包括日语的情况下,有时会通过句法分析等追加被称为“排序模型”的模型)。
作为该SMT的优点,由于不使用如RBMT那样的规则,所以可举出“能够将‘在不存在规则的情况下翻译精度会变得非常低’这样的问题防患于未然,能够构建具有泛化能力(普适化能力)的翻译引擎”这一优点。
另一方面,作为缺点存在“由于以概率性表达为基础,因此需要大量地准备作为概率计算基础的对译语料库”这一缺点。另外,一方面泛化性能高,而另一方面则翻译结果只不过是“概率性评分高的”输出,因此,对于由RBMT出色地翻译出来的事例,无法保证由SMT也能获得同等的翻译精度,且尽管有“作为整体/平均来说是比较好的”翻译,但也会出现个别翻译事例在准确性上较差的情况。
进一步,在进行概率计算时,需要将各个内部模型(语言模型、翻译模型等)输出的概率值相结合。此时,为了对SMT的翻译引擎整体进行调整(Tuning),要对来自各个模型的概率值加权而进行以权重作为参数的机器学习,但此处所使用的机器评价值成为如字面所述的“机械式的评价值(例如被称为‘BLEU’的评价值)”,因此,存在未必与用户的主观评价一致的报告(例如,参照非专利文献2)。也就是说,具有“机器评价值高、但与用户的实际评价脱节”这样的构造性缺陷。
另外,作为另一构造性缺陷,还可举出如下缺陷:即便想要在用户侧和/或系统侧实现性能的提高而假设追加了多个对译语料库,但由于翻译输出依赖于将对译语料库进行统计处理后的概率性行为,因此也与性能提高 没有直接关系(性能也有可能会下降)。
3)基于深度神经网络获得模型的机器翻译(DNNMT)
基于深度神经网络获得模型的机器翻译(DNNMT)是一种将深度学习(DL:Deep Learning)技术应用于机器翻译的比较新的翻译技术(例如,参照非专利文献3、非专利文献4)。
不同于如RBMT和SMT那样的将输入文或对译语料库适用于“由人设计的规则或模型”中或者进行统计处理的翻译方法,其特征在于系统对适当的模型本身进行学习。目前是处于黎明期的技术,作为机器翻译技术还没有达到实际应用的水平,但作为相似技术,已经在语音识别领域被实际应用在苹果公司的Siri(注册商标)等中。
作为优点,在适当的模型的学习成功的情况下,能期待翻译性能的提高,并能期待特别是超过SMT的泛化性能,对于RBMT和SMT并不擅长的比较长的句子(例如由40个以上的单词构成的句子),能期待在不显著降低翻译性能的情况下输出翻译结果。
作为缺点,可举出难以对DNNMT本身如何学习模型进行外部控制。在没有明确存在与所谓的“使用参数的调整”相当的“参数”的情况下,内部的变量非常多,但并不清楚哪个变量与翻译性能直接相关。也就是说,在决定了神经网络的结构与输入数据、训练数据后,难以对系统如何学习、表现出怎样的性能进行控制,原理上来讲并不清楚怎样才能实现性能的提高。难以运用一般的调整方法,即便想要在用户侧和/或系统侧实现达到或超过SMT的性能改善,也很难应对的。存在如下的构造性缺陷:即便假设追加了多个对译语料库,但翻译输出依赖于神经网络的学习,若不确定神经网络的内部变量,则也并不知道会出来什么结果。
以上是将机器翻译技术大致分为三类时的各自的特征、优点、缺点。
另一方面,当从用户观点来看机器翻译技术时,若用户对想要翻译出的语言、即目标语言具有认识,则即使在机器翻译的精度不那么高的情况下,也有可能能够以翻译输出结果为基础进行对话。也就是说,对于机器翻译的输出,可期待如下的使用方法:用户能够判断“正确/不正确”,对 于有用的翻译部分,对其进行利用。
然而,实际上也很容易想象到用户即使参照了机器翻译的输出结果也无法理解该翻译结果所表示的内容的情况。例如,在假定用户为日本人的情况下,如果有想把日语翻译成主流的语言(英语等)的场合,那么就有想翻译成比较小众的语言(例如,马来语或越南语等)的场合。例如,在目标语言为英语的情况下,具有关于英语的知识的用户参考机器翻译的结果也许就能对自己的英语对话发挥作用。另一方面,在目标语言为小众的语言的情况下,用户大多对目标语言完全没有认识,对于机器翻译结果的内容正确与否,用户无法获得任何信息。也就是说,会发生即便由机器翻译提示出目标语言的译文,也完全无法理解其内容的情况。语言存在数千种,甚至可以说,对于大部分用户来讲,没有认识的语言是大多数的。这样,对于目标语言的翻译结果,在无法理解其意思内容的情况下,也会导致在无法确认传达给对方的意图的状态下提示译文,交流有可能会失败。
为了尽量提高这种现状的机器翻译精度,希望机器翻译系统本身自动进行学习并提高性能。期待机器翻译系统在自动进行学习时,不给用户(源语言说话者)造成负担,除此之外,需要构建机器翻译系统以使得用户能够边通过简便的方法确认传达给对方的意图边生成、利用译文。在机器翻译系统中,要求使用用户的利用结果来进行自动学习。另外,当然地还同时要求尽量减少系统本身所需的计算机资源和/或开发成本。
即,机器翻译系统所要求的是如下的三个需求:“(需求1)不给用户造成负担,且用户能够边通过简便的方式确认传达给对方的意图边生成、利用译文”;“(需求2)能够使用用户的利用结果(不会另外给用户造成负担)来自动进行学习”;“(需求3)在实现需求1、需求2的同时,降低计算机资源和/或开发成本”。实现同时满足这三个需求的机器翻译系统已成为课题。
作为解决该课题的技术方案,例如有如下等的方案:如RBMT那样将使源语言例句与目标语言例句关联的例句作为数据库和/或规则(rule)进行保持,对于说出来的输入文,取得相似的例句,并以源语言、目标语言 这两者进行提示(例如专利文献1);计算输入文与逆向翻译(从目标语言到源语言的翻译)结果的距离来作为翻译可信度,根据需要一并提示可信度与逆向翻译结果,让用户重说和/或进行说法变换(例如专利文献4);使用对统计机器翻译(SMT)系统的性能进行评价的方法、即BLEU(BiLingual Evaluation Understudy)(例如非专利文献1);对于输入文,取得N个逆向翻译文,并进行输入文与逆向翻译文的比较评价(例如专利文献2);在将对译语句登记到对译辞典时,对判别是否对作为对象的翻译装置有效而得出的结果进行机器学习(例如专利文献3)等。
在专利文献1中公开了如下内容:预先使源语言的例句与源语言的例句的译文即目标语言的例句相互对应,并保存在例句保存部。
另外,在专利文献1中公开了如下内容:基于保存在上述的例句保存部中的信息,在显示部分别将所输入的源语言的文字串以及与源语言的文字串对应的目标语言的文字串显示在不同的显示区域。
具体而言,对于所输入的源语言的文字串,将与该源语言的文字串相似的多个相似例句的文字串显示在同一显示区域,与此相对地,将分别与所输入的源语言的文字串以及多个相似例句的文字串对应的目标语言的文字串显示在不同的显示区域。源语言说话者以及目标语言说话者能够在要对输入文确认意思时确认例句。另外,也将目标语言说话者或者源语言说话者选择出的相似文例句以高亮(Highlight)等方式显示给对方的说话者。
在专利文献1中还公开了如下内容:取得作为输入文的源语言的文字串,检索数据库内的对译例中的相似例句,如果是相似度大于等于阈值的例句则判断为是相似例句,并作为与输入文对应的相似例句进行输出。此时,在用户进行了对所输出的相似例句的选择动作的情况下,将选择出的例句高亮显示。
在专利文献2中公开了如下内容:对于原文,接受由正向机器翻译部11输出的正向译文,在逆向翻译部12a、12b、12c,由评价部13对逆向译文A、B、C进行评价。
作为此时的评价方法,一般已知非专利文献1中所公开的内容。在非 专利文献1中,在计算出参考译文(由人工创建的正确翻译)与由机器翻译输出的译文之间的N-gram相一致的数量之后,进行考虑了参考译文长度的影响的修正从而取得BLEU值。虽然BLEU常被用作翻译精度的评价方法,但已知尤其是在如日英、英日这样的语顺大不相同的语言之间的翻译中,与人工评价的相关性较低(例如,参照非专利文献2)。
在专利文献2中进一步公开了如下内容:在执行了逆向翻译文A、B、C与原文的DP匹配之后,输出具有最高评分的逆向译文和原文。评价者通过对它们进行比较能够对正向译文进行主观评价。
综上所述,当在机器翻译精度不完善的状况下进行翻译时,需要系统本身在不会给用户(源语言说话者)造成重复输入等负担的状态下,简单地且边确认传达给对方的意图边生成翻译发声文,并将用户的选择作为评价,进行评价/学习。
若再次提出机器翻译系统所要求的,则是同时满足如下的三个需求:“(需求1)不给用户造成负担,且用户能够边通过简便的方式确认传达给对方的意图边生成、利用译文”;“(需求2)能够使用用户的利用结果(不会另外给用户造成负担)来自动进行学习”;“(需求3)在实现需求1、需求2的同时,降低计算机资源和/或开发成本”。
作为解决该问题的技术方案,在前面列举出的三种技术中采取了如下所述的方法。
1)基于规则的机器翻译(RBMT)
如上所述,在专利文献1中,根据所输入的源语言的文字串,输出相似的源语言的相似文,对于所输出的源语言的相似文,也以能够选择的方式输出所对应的译文。由此,例如在语音输入源语言的文字串的情况下等,能够减小由发声输入时的语音识别错误等引起的输入错误的影响,用户能够简便地选择想要传达的意图。
在专利文献1的第[0012]段中记述有“例句保存部105将源语言的例句(以下,也称为源语言例句)与目标语言的例句(以下,也称为目标语言例句)以相关联的方式保存”,例句保存部105成为执行例句检索的数 据库而保存着源语言和目标语言对。该部分相当于基于规则的翻译的数据库。
此外,在专利文献1的第[0011]段中记述有“机器翻译部103从语音识别部102接收源语言文字串,并将源语言文字串机器翻译成目标语言(也称为第二语言)的文字串,获得翻译结果的文字串即目标语言文字串。机器翻译的具体处理执行一般的处理即可,因此省略此处的说明。”,在此,对于机器翻译部103,专利文献1中并没有公开因使用SMT和/或DNNMT而带来的优势和/或问题,作为专利文献1中的语音翻译系统整体,只不过特征性公开了由例句保存部105发挥的作为RBMT的作用。
如前面所列举的,RBMT存在如下问题:当出现没有记述在规则(rule)中的输入文和/或出现未进行应对的行业、领域的输入的情况下,翻译精度将会显著降低,或者完全翻译不出来。在专利文献1中也既没有公开如下的问题也没有记载解决办法:对于发声输入,在例句保存部105中没有记述相似例的情况下和/或在领域不同的情况下,有可能提示翻译精度极低的译文,很可能会导致在没有关于目标语言的知识的用户无法确认传达给对方的意图的状况下提示译文(或者在误解传达给对方的意图的状况下进行提示)。
再者,在例句保存部105中不存在相似例的情况下,将会变成如下状况:无法进行相似例本身的提示,用户只得使用语音识别结果(有较多错误)的输入文。关于翻译结果,也仅为对于语音识别结果的输入文的机器翻译部103的翻译结果。在这种情况下,用户无法“简便地选择”“依照想要恰当地传达的意图的文章”,且在专利文献1中也没有公开对于该问题的解决办法。
即,对于(需求1),虽然也可以说通过提供对多个相似文检索结果进行提示并选择的单元,而部分公开了“用户简便地选择(文章)”的单元,但是,在相当于RBMT的例句保存部105中不存在相似例的情况下,将会出现丧失选项本身的结果,并没有完全地提供使得“用户简便地选择(文章)”的单元。
再者,对于“传达给对方的意图的确认”,终归只是仅限定于在对例句保存部105所保持的内容中检索到结果的情况下可解决而已,并未涉及到机器翻译部103的翻译结果输出。即,没有提及机器翻译部103的翻译结果是否遵循于原本的源语言文字串的内容,(在专利文献1的第[0011]段中记述有“机器翻译部103从语音识别部102接收源语言文字串,并将源语言文字串机器翻译成目标语言(也称为第二语言)的文字串,获得翻译结果的文字串即目标语言文字串。机器翻译的具体处理执行一般的处理即可,因此省略此处的说明。”,并没有担保机器翻译部103的输出的可信性),即使作为机器翻译部103的输出而出现了与源语言文字串的内容偏离的内容,用户也无从获悉。也就是说,对于前面的“在没有目标语言的知识的用户无法确认传达给对方的意图的状况下提示译文”这一问题,既没有进行公开也没有进行解决。
另外,对于(需求2)、(需求3),既没有进行公开也没有进行解决。尤其是对于需求3,不要说作为系统整体进行轻量化,相反由于除机器翻译部103以外还另外需要相当于RBMT的例句保存部105,因此,不仅增加了计算机资源消耗而且增加了开发工作量。
关于对RBMT中的“(需求2)能够使用用户的利用结果,不会另外给用户造成负担,来自动进行学习”的应对,已公开了如专利文献3那样的方法:分别对输入文和译文进行词素分析(Morphological Analysis),在将对译语句登记到对译辞典时,对判别是否对作为对象的翻译装置有效而得出的结果进行机器学习。
在专利文献3的第[0020]段中,作为“5是机器翻译引擎,例如在规则主导型机器翻译中”,以规则主导型机器翻译这一名称而将RBMT示例为翻译系统,并公开了在将对译语句登记到对译辞典时的有效性的判别方法。在此,在向基于规则的对译辞典登记新的语句的情况下,通过对这之前所登记的对译对进行词素分析之后,再与采用支持向量机(support vector machine)识别出的判定空间进行对照,由此对在系统方面登记该语句是否有效进行判断。即,“向基于规则的对译词典登记新的语句”的执行与 用户的翻译利用无关,关于使用了用户的利用结果的自动学习,既没有公开也没有解决相关问题。
一般来讲,RBMT具有“在不存在规则的情况下翻译精度会变得非常低,或者完全翻译不出来,对预想以外的行业、领域的适应性极低”这一缺点,该缺点本质上并没有被解决(例如专利文献1)。
另外,为了提高翻译性能就需要添加规则,但是这需要开发成本。再者,要在用户侧构建规则而对翻译系统进行定制,要求对于规则的设计规则要具备相当的知识,因此,一般用户无法轻松地使用。即,为了避免“随着RBMT所具有的规则的增加,规则之间产生干涉、副作用的可能性将会飞跃式地增大,从而频繁发生因在某例文中补记有效的规则,而在其他例文中产生不良状况的现象”,“需要掌握系统所具有的所有规则后补充新的规则”,因此,别说是“使用用户的利用结果的自动学习”,连简便的规则添加都是困难的。例如,在上面列举出的专利文献3中,不过是仅对RBMT所具有的翻译规则中的单词译对,自动判断其有效性,而没有涉及对于句法的翻译规则的干涉避免。
由于RBMT存在这种原理性的缺点,因此“由用户进行RBMT的向数据库登记单词、例句”的效率化、简便化被作为RBMT的课题而公开。这些都明确地要求用户对学习用数据进行输入和/或判断,而关于不对用户进行这种请求,即,作为上述的问题的“使用用户的利用结果的自动学习”,则处于既没有公开也没有解决问题的状况。
2)统计机器翻译(SMT)
在SMT中,有如下的方案等:将输入文与逆向翻译(暂先将输入文翻译到目标语言,再进一步从目标语言翻译到源语言)的结果的距离作为翻译可信度进行计算,根据需要一并提示可信度与逆向翻译结果,让用户重说或进行说法变换(例如参照专利文献4。但是在专利文献4中也提及了不以SMT为前提的情况,也将RBMT假定为机器翻译引擎。关于RBMT,在专利文献4的第[0009]段中,记为了“文法规则型翻译”);作为对SMT的翻译精度进行评价的方法,利用以单词n-gram为单位的相 似度(BLEU值)来进行自动学习(参照非专利文献1);对于输入文,生成N个与所获得的译文相对的逆向翻译文,并根据输入文与逆向翻译文的相似度来对译文的好坏进行比较评价(例如专利文献2)。
在此,关于“(需求1)不给用户造成负担,且用户能够边通过简便的方式确认传达给对方的意图边生成、利用译文”,在这些例子中,例如公开了通过对用户提示逆向翻译结果(专利文献4),从而让用户确认“传达给对方的意图”的方法。但是,对于“能够通过简便的方式生成、利用译文”,则要求用户根据逆向翻译结果来重新输入或进行说法变换,并没有解决问题。
具体而言,在专利文献4的第[0013]段中公开了“提供一种可信度计算装置、翻译可信度计算利用方法以及翻译引擎用程序,其能够恰当地获得翻译结果的可信度,并且能够在可信度低的情况下恰当地促使输入侧用户重新输入”。即,在系统判断出翻译结果的可信度低的情况下,不仅要求用户重新输入原文,而且直到输出具有足够高的可信度的译文为止,需要持续地边进行变换原文的表达等反复试验边执行对向翻译系统的输入与译文输出的确认工作。再者,此时必须留意的是,对于使用的用户来说,对于该翻译系统“通过什么样的内部工作生成译文”、“以什么样的基准计算可信度”、“怎样才能得到可信度高的译文”这样的方面,并没有任何知识和见解。在也没有准则的情况下,只是为了获得可信度高的翻译结果,而要求用户不断地以各种各样的说法变换来输入文章,这从实际应用的角度来看,会变成极其不易使用的系统。在专利文献4中,既没有提示与此相关的问题也没有提示解决办法,可以说在“能够通过简便的方式生成、利用译文”这样的方面是不充分的。
另外,关于“(需求2)能够使用用户的利用结果(不会另外给用户造成负担)来自动进行学习”,如此前有关“(需求1)不给用户造成负担,且用户能够边通过简便的方式确认传达给对方的意图边生成、利用译文”所述的那样,RBMT、SMT这两者都没有实现用户在不承受负担的情况下“能够边通过简便的方式确认传达给对方的意图边生成、利用译文”, 为此,由于并未公开获得满足(需求1)的“用户的利用结果”的方法,因此,关于使用了满足(需求1)的“用户的利用结果”的自动的学习,也并未做出问题的公开以及解决办法的提示。
在以该“没有获得满足(需求1)的用户的利用结果的方法”为前提的基础上,从被提供某些其他的学习用数据的情况下的翻译系统的自动评价、学习法这一观点来看,存在如前所述的方案:“执行基于对统计机器翻译系统的性能进行评价的方法、即BLEU的值的自动学习(非专利文献1参照)”、“对于输入文,取得N个逆向翻译文,根据输入文与逆向翻译文的相似度来进行比较评价(例如专利文献2)”、“在将对译语句登记到对译辞典时,对判别是否对作为对象的翻译装置有效而得出的结果进行机器学习(例如参照专利文献3)”等。
非专利文献1为,事先准备输入文的参考译文(正解数据),基于单一语言中的n-gram来对翻译引擎的翻译输出结果与正解数据进行比较,由此,对将比较结果作为值(BLEU评分)来进行机器计算,并对系统进行调整以使该值增大。由于需要事先准备输入文和作为正解数据的参考译文(译文),且本质上翻译引擎的内部模型并不会因该调整产生任何变化而只是权重发生变化,因此,本方法无法适用于想要学习模型本身的情况以及不能获得正解数据、不能唯一确定正解数据的情况。
即使假设获得了“满足需求1的用户的利用结果”,其结果也就是“用户边通过简便的方式边确认向对方传达的意图边生成、利用译文”。关于该“结果”中的“哪个是否为正解数据”、“如何唯一得到正解数据”、“之后如何进行模型的学习”,则既没有公开也没有解决任何的问题。
专利文献2中公开了如下内容:用多个逆向的翻译器将翻译结果恢复成源语言,在输入文与多个逆向翻译文之间对句子的相似度进行机器计算,由此评价原翻译结果的优劣。虽然在专利文献2中公开了通过生成多个逆向翻译文来进行原翻译结果的评价,但是专利文献2中想要解决的问题是对翻译结果进行一定的自动的评价,在这点上,本质并没有与前面的非专利文献1存在差别。即,专利文献2中仅公开了在某些正解文(在非专利 文献1中相当于参考译文,在专利文献2中相当于输入文)与翻译结果文(在非专利文献1中相当于译文,在专利文献2中相当于将翻译结果进行逆向翻译而得到的逆向翻译文)之间,计算表现一致或者相似度的评分(以非专利文献1的BLEU值为代表的评分),并根据该值来评价翻译结果的优劣。
此外,虽然在专利文献2中并没有提及翻译系统自身的学习,但在专利文献2的第[0048]段中记载了“……能够进行三个逆向译文与原文的DP匹配,将最大评分作为正向译文的自动评价结果,因此,不仅能够对例文的译文而且能够对所有的译文进行评价,能够减少评价的工作量并且提高评价的可靠性”,其目的为,构建第[0009]段中的“不仅能够对例文的译文而且能够对所有的译文进行评价、评价的可靠性高并且所需工作量少的机器译文的评价方法以及机器译文的评价装置”。即使在不具有非专利文献1中事先所需要的正解文(参考译文)的情况下,专利文献2中公开了能够基于逆向翻译文与输入原文的机器匹配评分进行评价,虽然在专利文献2中并没有提及学习,但与非专利文献1的结合也给出了将该评分用于学习的启示。
然而,即使在结合了专利文献2和非专利文献1的情况下,在想要对模型本身进行学习时、匹配评分不正确和/或无法唯一确定时,也仍然无法进行调整。
另外,与非专利文献1同样地,即使假设获得了“满足需求1的用户的利用结果”,其结果也就是“用户边通过简便的方式确认向对方传达的意图边生成、利用译文”。关于如何将这种结果作为评价值进行判断,进一步怎样根据该评价值进行模型的学习,则丝毫没有给出对问题的公开和解决。
即,关于“用户边通过简便的方式确认向对方传达的意图边生成、利用译文”,既没有公开问题也没有公开解决办法,关于使用利用结果的学习,也与前面的非专利文献1同样地,丝毫没有给出对问题的公开和解决。
另外,关于“(需求3)在实现需求1、需求2的同时,降低计算机资 源和/或开发成本”,在非专利文献1中另外需要计算BLEU值,在专利文献2中另外需要计算匹配评分,增加了计算机资源、开发成本。
3)基于深度神经网络获得模型的机器翻译(DNNMT)
作为基于神经网络的机器翻译,非专利文献3以及非专利文献4示例出了使用了深度神经网络(DNN:Deep Neural Net)中的RNN(Recurrent Neural Network,递归神经网络)以及作为RNN的一种的LSTM(Long Short Term Memory,长短时记忆网络)的DNNMT。任何一种方法都是通过将对译语料库用作神经网络的输入层以及输出层的正解数据(正例和/或负例),且让神经网络的中间层直接学习,由此直接在神经网络的内部构建翻译模型。DNN以怎样的方式在内部保持翻译模型取决于学习数据的种类和/或给出方法、学习次数、DNN本身的网络结构等。不论在哪一个方案中,都没有公开:在如何变更内部状态后,翻译性能会如何变化(学术上也尚未阐明)。本来,作为神经网络的特性,存在能够对非线性输出进行学习这一点,但现状是,因变为DNN从而使非线性呈飞跃式增长,并未找出内部参数与输出性能之间的一些线性的因果关系。
换言之,从“对于输入文返回什么样的翻译结果”这种意义上来说,DNNMT与前面的RBMT和/或SMT是相同的。然而,在“为什么会得到该翻译结果”这一方面,RBMT只要参照记述了该规则的数据库即可明白得到翻译结果的理由(作为基础的规则),在SMT中知道翻译结果是从翻译模型(各单词、句的发生概率、对齐概率等)和语言模型(n-gram概率)中选出的最大概率的结果,与此相对地,在DNNMT中,由于神经网络自己构建相当于规则和/或模型的内容,因此,除了知道神经网络的输出层所给出的结果是翻译结果的句子之外,关于内部模型、工作则无法获得见解。
因此,DNNMT是学术研究为中心,并未达到实用阶段,还未涉及来自如“(需求1)不给用户造成负担,且用户能够边通过简便的方式确认传达给对方的意图边生成、利用译文”那样的实际利用方面的问题。
另外,关于“(需求2)能够使用用户的利用结果(不会另外给用户 造成负担)来自动进行学习”,关于即使假设获得了“满足(需求1)的用户的利用结果”、但使用该结果“之后如何进行模型的学习”,都需要弄清楚内部工作,当然丝毫没有给出对问题的公开和解决。
综上所述,现有技术在以下方面存在问题。
·当在对译数据库中没有记述相似例、译文的情况下以及领域不同的情况下,有可能会提示翻译精度极低的译文,或者有可能完全翻译不出来。
·由于没有使用户简便地确认并选择译文内容的方法,因此在提示对输入文的逆向翻译文和/或提示翻译品质(可信度)这样的方法中,在提示内容的品质、可信度低的情况下,将会要求用户重新输入,但是通过重新输入并不能保证提高品质,用户除了反复试验进行输入之外别无他法。
·虽然现有例中公开了以BLEU值等、通过某些方法机器计算出的评分为基础的翻译系统的自动调整,但是关于在“用户边通过简便的方式确认向对方传达的意图边生成、利用译文”的情况下,如何进行基于该结果的评价以及学习,均未公开问题,也未公开解决办法。
·需要生成相似例句和/或调整用的数据(计算评价评分等)的计算机资源。另外也需要创建相似例句的开发、人工成本。
由此,为了提高机器翻译系统的功能,研究出了以下的改善方案。
机器翻译系统的机器翻译方法的一个技术方案是是机器翻译系统中的机器翻译方法,所述机器翻译系统连接于输出语言信息的信息输出装置,执行第一语言与第二语言之间的翻译处理,所述机器翻译方法包括:接收所述第一语言的翻译对象文;生成将接收到的所述翻译对象文向所述第二语言翻译而得到的多个不同的顺向翻译文;生成针对所述多个不同的所述顺向翻译文的每一个来向所述第一语言逆向翻译而得到的多个逆向翻译文;在所述信息输出装置正输出着所述多个逆向翻译文时受理到从所述多个逆向翻译文中选择一个逆向翻译文的操作的情况下,输出与所述一个逆向翻译文对应的所述顺向翻译文。
根据上述技术方案,生成将第一语言的翻译对象文向第二语言翻译而得到的多个不同的顺向翻译文;生成针对多个顺向翻译文的每一个来向第 一语言逆向翻译而得到的多个逆向翻译文;在信息输出装置正输出着多个逆向翻译文时受理到从多个逆向翻译文中选择一个逆向翻译文的操作的情况下,输出与所述一个逆向翻译文对应的顺向翻译文。
例如,向用户提示与接收到的翻译对象文对应的多个逆向翻译文,并提示与用户从其中选择出的逆向翻译文对应的顺向翻译文。由此,由于成为用户从多个逆向翻译文之中选择与自己输入的翻译对象文的意图最为接近的逆向翻译文,因此,例如与仅提示出将以第一语言输入的翻译对象文翻译成第二语言所得到的一个译文、以及与该译文对应的一个逆向翻译文的系统相比,因逆向翻译文不同于翻译对象文所意图表达的内容而要求对翻译对象文进行修正或者重新输入等情景变少。
另外,例如,由于能由用户从多个逆向翻译文之中选择一个逆向翻译文,因此,机器翻译系统能够获得如下等反馈:作为所输入的翻译对象文所意图表达的内容,在提示出的多个逆向翻译文之中哪个逆向翻译文是最为妥当的,或者哪个逆向翻译文与用户所喜欢的表达相符。因此,例如在将机器学习应用于上述技术方案中的机器翻译系统的情况下,除了能获得对于所输入的翻译对象文提示出的逆向翻译文是否妥当这一评价之外,还能获得在提示出的多个逆向翻译文之中哪个逆向翻译文的妥当的这一评价。此时,通过机器翻译系统中的一次翻译工作,能获得对多个逆向翻译文的反馈,因此,能够实现机器翻译系统的高学习效率。
进一步,根据上述技术方案,关于机器翻译系统中的机器学习,无需基于BLEU值的计算的翻译精度的评价、或者基于所输入的翻译对象文与逆向翻译文之间的机器匹配评分的翻译精度的评价等,而是通过由用户进行的逆向翻译文的选择来生成学习用数据。因此,生成学习用数据无需新的计算机资源,也能够控制开发成本。
在上述技术方案中,例如也可以为,所述机器翻译系统还与受理用户的语音输入的语音输入装置以及受理用户的文本输入的文本输入装置连接;所述翻译对象文以表示该翻译对象文的语音信息或者表示该翻译对象文的文本信息的方式来接收;根据是以所述语音信息和所述文本信息中的 哪种方式接收到了所述翻译对象文,变更与所述一个逆向翻译文对应的所述顺向翻译文的输出方式。
根据上述技术方案,按照是以语音信息和文本信息中的哪种方式接收到翻译对象文,来变更顺向翻译文的输出方式。由此,例如能根据输入形态(modal)来决定输出的形态,因此,用户能够通过改变输入的形态来自由决定输出的形态。
在上述技术方案中,例如也可以为,所述信息输出装置具有语音输出装置以及显示器;在以语音信息的方式接收到所述翻译对象文的情况下,通过所述语音输出装置输出与所述一个逆向翻译文对应的所述顺向翻译文;在以文本信息的方式接收到所述翻译对象文的情况下,通过所述显示器输出与所述一个逆向翻译文对应的所述顺向翻译文。
由此,输入的形式与输出的形式分别以相同的形态来应对,因此,用户只要以自己希望的输出方式来输入翻译对象文即可,不会产生要以哪种输入方式进行输入才能以希望的输出方式输出译文这样的混乱。
在上述技术方案中,例如也可以为,所述翻译对象文以表示该翻译对象文的文本信息的方式来接收;基于所述文本信息,生成将所述翻译对象文向所述第二语言翻译而得到的多个不同的顺向翻译文。
在上述技术方案中,例如也可以为,所述机器翻译系统还与受理用户的文本输入的文本输入装置连接;所述翻译对象文从所述文本输入装置以表示该翻译对象文的文本信息的方式来接收。
在上述技术方案中,例如也可以为,所述翻译对象文以表现该翻译对象文的语音信息的方式来接收;对接收到的所述语音信息执行语音识别处理来生成表示所述翻译对象文的文本信息;基于所述文本信息,生成将所述翻译对象文向所述第二语言翻译而得到的多个不同的顺向翻译文。
由此,能够使用语音输入翻译对象文,所以例如无需使用键盘、触摸显示器等来输入翻译对象文,因此,用户能够容易地输入翻译对象文。
在上述技术方案中,例如也可以为,所述机器翻译系统还与受理用户的语音输入的语音输入装置连接;所述翻译对象文从所述语音输入装置以 表现该翻译对象文的语音信息的方式来接收。
在上述技术方案中,例如也可以为,所述信息输出装置具有显示器;在所述显示器的第一区域显示所述多个逆向翻译文;在所述显示器的与第一区域不同的第二区域显示所述翻译对象文。
根据上述技术方案,对逆向翻译文和翻译对象文分开要显示的区域。由于逆向翻译文与翻译对象文是相同语言的文章,因此用户能够容易地分清哪个是逆向翻译文哪个是翻译对象文,不会产生混淆。
在上述技术方案中,例如也可以为,在所述显示器的第三区域显示与所述一个逆向翻译文对应的所述顺向翻译文。
由此,逆向翻译文、翻译对象文、顺向翻译文分别显示在不同的区域,因此,对于用户来说容易知道它们分别是哪个文章。
在上述技术方案中,例如也可以为,根据对所述信息输出装置的操作,变更与所述一个逆向翻译文对应的所述顺向翻译文的显示的朝向。
由此,例如,在分别讲不同语言的用户A及用户B面对面进行对话的情况下,与以用户A所讲的语言输入的翻译对象文相对应地,在信息输出装置显示以用户B所讲的语言输出的顺向翻译文时,如果能将顺向翻译文的朝向例如变更为反向,那么用户A既不需要读出顺向翻译文、也不需要变更信息输出装置本身的朝向来向用户B传达顺向翻译文的内容,面对面的两位用户能够以从上方观看信息输出装置的方式实现不同语言间的交流。
在上述技术方案中,例如也可以为,将所述顺向翻译文的显示朝向变更为与显示在所述第一区域中的所述多个逆向翻译文的显示朝向不同的朝向。
在上述技术方案中,例如也可以为,将所述顺向翻译文的显示朝向变更为与显示在所述第一区域中的所述多个逆向翻译文的显示朝向相同的朝向。
在上述技术方案中,例如也可以为,以与显示在所述第一区域中的所述多个逆向翻译文不同的朝向,显示与所述一个逆向翻译文对应的所述顺 向翻译文。
在上述技术方案中,例如也可以为,所述机器翻译系统,生成顺向翻译文组,所述顺向翻译文组是将接收到的所述翻译对象文向所述第二语言翻译而得到的所述顺向翻译文的集合,所述顺向翻译文组包含所述多个不同的顺向翻译文;判断所述顺向翻译文组所包含的各个所述顺向翻译文被分类为疑问句、肯定句、否定句、命令句之中的哪种形式;基于所分类的所述形式,从所述顺向翻译文组中决定出所述多个不同的顺向翻译文。
根据上述技术方案,能基于文章的形态从顺向翻译文组中选择出多个不同的顺向翻译文,因此,例如能够从基于翻译对象文而机器生成的顺向翻译文组中,仅选择形态与翻译对象文的形态相同的顺向翻译文,能够提高最终的翻译精度。另外,例如也可以以包含形态不同于翻译对象文的形态的顺向翻译文的方式来选择多个顺向翻译文,由此,能够增加基于顺向翻译文生成的、提示给用户的多个逆向翻译文的差异性。因此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在即使是未被选择的逆向翻译文也表现了用户所输入的翻译对象文所表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个不同的顺向翻译文包含分别被分类在不同所述形态中的至少两个以上的所述顺向翻译文。
由此,能够增加基于顺向翻译文生成的、提示给用户的多个逆向翻译文的差异性。因此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述机器翻译系统,生成顺向翻译文组,所述顺向翻译文组是将接收到的所述翻译对象文向所述第二语言翻译而得到的所述顺向翻译文的集合,所述顺向翻译文组包含所述多个不 同的顺向翻译文;对所述顺向翻译文组所包含的各个所述顺向翻译文的主语或者谓语进行判断;基于判断出的所述主语或者所述谓语,从所述顺向翻译文组中决定出所述多个不同的顺向翻译文。
根据上述技术方案,能基于主语或者谓语从顺向翻译文组中选择出多个不同的顺向翻译文,因此,例如能够从基于翻译对象文机器生成的顺向翻译文组中,仅选择具有与翻译对象文相同的主语或者谓语的顺向翻译文,能够提高最终的翻译精度。另外,例如也可以以包含具有与翻译对象文不同的主语或者谓语的顺向翻译文的方式来选择多个顺向翻译文,由此,能够增加基于顺向翻译文生成的、提示给用户的多个逆向翻译文的差异性。为此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个不同的顺向翻译文包含被判断为分别包含不同的主语或者谓语的至少两个以上的顺向翻译文。
由此,能够增加基于顺向翻译文生成的、提示给用户的多个逆向翻译文的差异性。为此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个不同的顺向翻译文是被判断为分别包含相同的主语或者谓语的顺向翻译文。
由此,例如能够从基于翻译对象文机器生成的顺向翻译文组中,仅选择具有与翻译对象文相同的主语或者谓语的顺向翻译文,能够提高最终的翻译精度。
在上述技术方案中,例如也可以为,所述机器翻译系统,生成逆向翻 译文组,所述逆向翻译文组是针对所述多个不同的所述顺向翻译文的每一个生成至少一个以上的所述逆向翻译文的集合,所述逆向翻译文组包含所述多个逆向翻译文;对所述逆向翻译文组所包含的各个所述逆向翻译文,算出对与所述翻译对象文的相似度进行评价而得到的评价值;基于所述评价值,从所述逆向翻译文组中选择出所述多个逆向翻译文。
根据上述技术方案,能基于与翻译对象文的相似度从逆向翻译文组中选择出多个不同的逆向翻译文,因此,例如能够仅选择与翻译对象文的相似度高的逆向翻译文,能够提高最终的翻译精度。另外,例如也可以以包含与翻译对象文的相似度低的逆向翻译文的方式来选择多个逆向翻译文,由此,能够增加提示给用户的多个逆向翻译文的差异性。为此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述机器翻译系统,生成逆向翻译文组,所述逆向翻译文组是针对所述多个不同的所述顺向翻译文的每一个生成至少一个以上的所述逆向翻译文的集合,所述逆向翻译文组包含所述多个逆向翻译文;判断所述逆向翻译文组所包含的各个所述逆向翻译文被分类为疑问句、肯定句、否定句、命令句之中的哪种形式;基于所分类的所述形式,从所述逆向翻译文组中选择出所述多个逆向翻译文。
根据上述技术方案,能基于文章的形态从逆向翻译文组中选择出多个不同的逆向翻译文,因此,例如能够从逆向翻译文组中,仅选择形态与翻译对象文的形态相同的逆向翻译文,能够提高最终的翻译精度。另外,例如也可以以包含形态不同于翻译对象文的形态的逆向翻译文的方式来选择多个逆向翻译文,由此,能够增加提示给用户的多个逆向翻译文的差异性。为此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的 情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个逆向翻译文包含分别被分类在不同所述形态中的至少两个以上的所述逆向翻译文。
由此,能够增加提示给用户的多个逆向翻译文的差异性。因此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述机器翻译系统,生成逆向翻译文组,所述逆向翻译文组是针对所述多个不同的所述顺向翻译文的每一个生成至少一个以上的所述逆向翻译文的集合,所述逆向翻译文组包含所述多个逆向翻译文;对所述逆向翻译文组所包含的各个所述逆向翻译文的主语或者谓语进行判断;基于判断出的所述主语或者所述谓语,从所述逆向翻译文组中选择出所述多个逆向翻译文。
根据上述技术方案,能基于主语或者谓语从逆向翻译文组中选择出多个不同的逆向翻译文,因此,例如能够从逆向翻译文组中,仅选择具有与翻译对象文相同的主语或者谓语的逆向翻译文,能够提高最终的翻译精度。另外,例如也可以以包含具有与翻译对象文不同的主语或者谓语的逆向翻译文的方式来选择多个逆向翻译文,由此,能够增加提示给用户的多个逆向翻译文的差异性。为此,例如能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个逆向翻译文包含被判断为分别包含不同的主语或者谓语的至少两个以上的逆向翻译文。
由此,能够增加提示给用户的多个逆向翻译文的差异性。为此,例如 能够防止如下状况的发生:在将机器学习应用于机器翻译系统时,若让用户从多个内容相似的逆向翻译文中选择一个逆向翻译文,则在没有被选择的逆向翻译文也表现了用户所输入的翻译对象文表示的意图的情况下,机器翻译系统会因其没有被选择而作为错误的逆向翻译文进行学习。
在上述技术方案中,例如也可以为,所述多个逆向翻译文是被判断为分别包含相同的主语或者谓语的逆向翻译文。
由此,例如能够从逆向翻译文组中,仅选择具有与翻译对象文相同的主语或者谓语的逆向翻译文,能够提高最终的翻译精度。
在上述技术方案中,例如也可以为,所述机器翻译系统对在所述翻译处理中参照的概率模型进行管理,在所述翻译处理中,适用机器学习,基于表示所述多个逆向翻译文中的哪个所述逆向翻译文被选择为所述一个逆向翻译文的信息,进行所述机器学习,更新所述概率模型的参数。
根据上述技术方案,基于表示将所述多个逆向翻译文中的哪个所述逆向翻译文选择为所述一个逆向翻译文的信息,进行所述机器学习,更新所述概率模型的参数。由此,将表示选择了针对翻译对象文提示出的多个逆向翻译文中的哪个逆向翻译文的信息反映到系统中,因此,能够通过使用机器翻译系统来提高翻译精度。
在上述技术方案中,例如也可以为,所述概率模型包括在所述翻译处理中使用的对每个单词或短语赋予的权重值,所述机器翻译系统,对与所述一个逆向翻译文对应的顺向翻译文即选择顺向翻译文所包含的单词或短语、和与所述一个逆向翻译文以外的逆向翻译文对应的顺向翻译文即非选择顺向翻译文所包含的单词或短语进行比较;对于仅包含在所述选择顺向翻译文中的单词或短语、仅包含在所述非选择顺向翻译文中的单词或短语、以及包含在所述选择顺向翻译文和所述非选择顺向翻译文双方中的单词或短语,各自适用不同的所述权重值的更新方法来更新所述权重值,将更新后的所述权重值以及与更新后的所述权重值对应的所述单词或所述短语用作训练数据来进行所述机器学习。
由此,例如能够以包含在选择顺向翻译文中的单词或短语、和不包含 在选择顺向翻译文中的单词或短语来对评分赋予差别而进行机器学习,因此,即使是包含在非选择顺向翻译文中的单词或短语,也有在权重值的更新中被进行正面(plus)评价的情况。因此,在非选择顺向翻译文中部分地进行了正确翻译的情况下,能够正确地评价该部分,能够反映用户的评价结果。
进一步,通过机器学习,对于概率模型,能够逐次地边以单词或短语为单位反映用户的选择结果,边使概率模型进行学习,能够提高翻译精度。
在上述技术方案中,例如也可以为,所述概率模型包含在所述翻译处理中使用的对每个单词或短语赋予的权重值,所述机器翻译系统,对所述一个逆向翻译文所包含的单词或短语、和所述一个逆向翻译文以外的逆向翻译文即非选择逆向翻译文所包含的单词或短语进行比较;对于仅包含在所述一个逆向翻译文中的单词或短语、仅包含在所述非选择逆向翻译文中的单词或短语、以及包含在所述一个逆向翻译文和所述非选择逆向翻译文双方中的单词或短语,各自适用不同的所述权重值的更新方法来更新所述权重值;将更新后的所述权重值以及与更新后的所述权重值对应的所述单词或所述短语用作训练数据来进行所述机器学习。
由此,例如能够以包含在所选择的一个逆向翻译文中的单词或短语、和不包含在所选择的一个逆向翻译文中的单词或短语来对评分赋予差别而进行机器学习,因此,即使是包含在非选择逆向翻译文中的单词或短语,也有在权重值的更新中被进行正面评价的情况。因此,在非选择逆向翻译文中部分地进行了正确翻译的情况下,能够正确地评价该部分,能够反映用户的评价结果。
进一步,通过机器学习,对于概率模型,能够逐次地边以单词或短语为单位反映用户的选择结果,边使概率模型进行学习,能够提高翻译精度。
在上述技术方案中,例如也可以为,所述机器翻译系统对所述一个逆向翻译文所包含的单词或短语、和所述一个逆向翻译文以外的逆向翻译文即非选择逆向翻译文所包含的单词或短语进行比较,对于仅包含在所述一个逆向翻译文中的单词或短语、仅包含在所述非选择逆向翻译文中的单词 或短语、以及包含在所述一个逆向翻译文和所述非选择逆向翻译文双方的单词或短语,各自根据不同的所述权重值的更新方法来更新所述权重值,将更新后的所述权重值以及与更新后的所述权重值对应的所述单词或所述短语用作训练数据以进行所述机器学习。
在上述技术方案中,例如也可以为,关于仅与所述一个逆向翻译文对应的所述单词,所述权重值是作为正例的值,关于仅与所述一个逆向翻译文以外的句子对应的所述单词,所述权重值是作为负例的值。
由此,能够对所述权重值反映正面评价和负面评价这双方。
在上述技术方案中,例如也可以为,所述机器学习是使用了强化学习、识别学习、神经网络学习中的至少一方的学习。
另外,其他技术方案是一种机器翻译装置,其执行第一语言与第二语言之间的翻译处理,具备:输入部,其受理所述第一语言的翻译对象文的输入;翻译部,其生成将所述翻译对象文向所述第二语言翻译而得到的顺向翻译文、及将所述顺向翻译文向所述第一语言逆向翻译而得到的逆向翻译文,该翻译部对于所述翻译对象文生成多个不同的所述顺向翻译文,并生成与所述多个不同的所述顺向翻译文各自对应的多个逆向翻译文;用户输入部,其受理用户的输入;以及输出部,其在正输出着所述多个逆向翻译文时,当在所述用户输入部受理到从所述多个逆向翻译文中选择一个逆向翻译文的输入的情况下,输出与所述一个逆向翻译文对应的所述顺向翻译文。
另外,第二个其他技术方案是一种对机器翻译装置的工作进行控制的程序,该机器翻译装置连接于信息输出装置,执行第一语言与第二语言之间的翻译处理,所述程序使所述机器翻译装置的计算机执行如下处理:接收所述第一语言的翻译对象文;生成将接收到的所述翻译对象文向所述第二语言翻译而得到的多个不同的顺向翻译文;生成针对所述多个不同的所述顺向翻译文的每一个来向所述第一语言逆向翻译而得到的多个逆向翻译文;在所述信息输出装置正输出着所述多个逆向翻译文时受理到从所述多个逆向翻译文中选择一个逆向翻译文的操作的情况下,输出与所述一个逆 向翻译文对应的所述顺向翻译文。
(实施方式)
下面,参照附图,对本发明的实施方式进行说明。
此外,虽然在以下实施方式中,有将翻译前的语言即源语言作为日语、将翻译后的语言即目标语言作为英语来进行说明的地方,但这些仅为一例,源语言和目标语言对可以是任意组合的语言对。
将通过从源语言到目标语言的翻译而获得的译文表示为“顺向翻译文”,将通过从目标语言到源语言的翻译而获得的译文表示为“逆向翻译文”。
另外,将提示给用户的逆向翻译文表示为“用户提示文”,将用户所选择的逆向翻译文表示为“(用户)选择文”,将未选择的逆向翻译文表示为“(用户)非选择文”。
图1是表示本实施方式中的系统的整体结构的一例的图。系统具备信息显示终端100、网络200、翻译服务器300、麦克风400以及扬声器500。作为信息显示终端100的例子,可列举出智能电话、平板终端、专用显示设备终端、个人计算机(PC)等。除这里所列举的以外,只要是能够与用户交换信息的终端即可。
另外,可将信息显示终端100上的用户的输入操作设想为以文本方式的输入、基于语音的输入等。以文本方式的输入例如可考虑基于触摸面板的输入和/或基于键盘的输入。另外,基于语音的输入的情况例如可考虑基于麦克风的输入。除此之外,例如也可以使用基于手势(gesture)的输入等。
当在信息显示终端100输出机器翻译结果等时,既可以借助显示器输出结果,也可以使用语音来输出结果。
网络200连接有信息显示终端100、翻译服务器300、麦克风400以及扬声器500。作为连接方法的一例,可列举出基于有线、无线的局域网连接等,但是,只要是将各构成要素以可通信的方式进行连接的方法,则并不仅限于此。
翻译服务器300对从信息显示终端100接收到的翻译对象文进行机器翻译处理。例如,接收从信息显示终端100输入的源语言的文字串,并进行机器翻译处理。另外,还具有对于机器翻译结果接受来自用户的反馈从而进行机器学习的功能。将在下文中对翻译服务器300的详细结构进行说明。
此外,例如也可以使信息显示终端100与翻译服务器300成为一体来实现。
麦克风400对机器翻译系统进行基于语音的输入。麦克风400既可以附属于信息显示终端100,也可以单独地具备与网络200连接的功能。另外,在不对机器翻译系统进行基于语音的输入的情况下,麦克风400的结构并不是必须的。
扬声器500在机器翻译系统中进行基于语音的输出。扬声器500既可以附属于信息显示终端100,也可以单独地具备与网络200连接的功能。另外,在机器翻译系统中不进行基于语音的输出的情况下,扬声器500的结构并不是必须的。
机器翻译系统的输入/输出形式(modality)既可以仅具备基于语音的输入输出、和文本方式的输入输出中的任意一方,也可以兼备二者。在由用户对机器翻译系统进行了基于语音的输入的情况下,进行基于语音的输出。另外,在由用户以文本形式进行了输入的情况下,进行基于文本(画面显示)的输出。
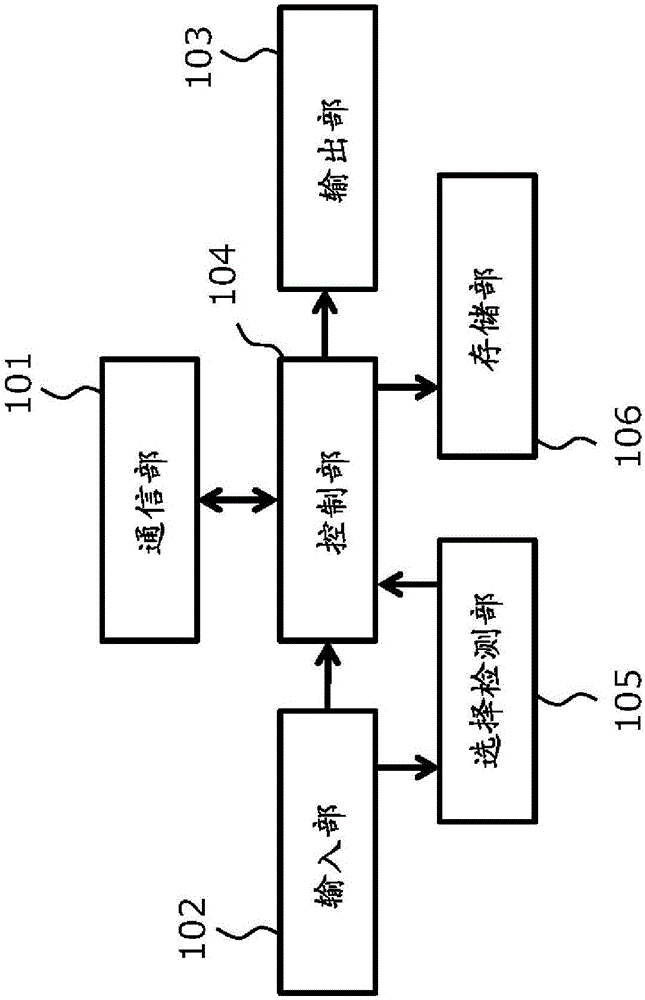
图2是表示本实施方式中的信息显示终端100的结构的框图。
信息显示终端100具备通信部101、输入部102、输出部103、控制部104、选择文检测部105以及存储部106。
通信部101进行与翻译服务器300的通信,进行在信息显示终端100输入的翻译对象文的发送、后述的译文及逆向翻译文的接收等。另外,并不限于这些信息,而是与翻译服务器300进行各种信息的收发。
输入部102受理来自用户的输入。输入部102受理如下输入,即翻译对象文的输入、后述的逆向翻译文的选择输入等。作为输入的方式,可考 虑语音输入、以文本形式的输入。在使用语音输入的情况下,对通过语音输入的翻译对象文进行语音识别处理,将语音识别处理的输出结果的文字串作为输入文而输入到机器翻译系统。在使用以文本形式的输入的情况下,受理通过键盘、鼠标、触摸面板等进行的文字串的输入。
输出部103对在输入部102中所输入的翻译对象文、通过通信部101接收到的多个逆向翻译文、翻译结果等进行输出。此外,输出部103也可以作为显示器等执行画面显示的显示部来实现,例如可设想为用于智能电话、平板终端等的触摸面板式的显示器或者监视器。另外,还可以作为扬声器等输出语音的语音输出部来实现。控制部104对通信部101、输入部102、输出部103、选择文检测部105以及存储部106的工作进行控制。
选择文检测部105用于检测对于由输出部103输出的多个逆向翻译文用户选择了哪个逆向翻译文。例如,当在输入部102进行了从多个逆向翻译文中选择一个逆向翻译文之意的输入的情况下,能在选择文检测部105检测出表示选择了哪个逆向翻译文的用户选择信息。检测出的用户选择信息被通过通信部101发送至翻译服务器300。另外,也可以根据用户选择信息来控制输出部103的输出内容。例如,在输出部103是由显示器实现的情况下,可以执行对用户选择的逆向翻译文进行强调显示、或者将用户没有选择的逆向翻译文从显示画面中删除的控制。
在此,将被用户选择的逆向翻译文以及与该逆向翻译文对应的顺向翻译文作为“用户选择文”。另外,将用户没有选择的逆向翻译文以及与该逆向翻译文对应的顺向翻译文作为“用户非选择文”。
存储部106进行对从翻译服务器300接收到的信息的临时存储、对在信息显示终端100执行的各种应用程序的存储等。
图3是表示本实施方式中的翻译服务器300的结构的框图。翻译服务器300具备通信部210、控制部220、机器翻译部230以及存储部240。进一步,机器翻译部230具有顺向翻译部231、顺向翻译文选择部232、逆向翻译部233、逆向翻译文选择部234、选择文判断部235、短语分割部236、选择结果评价部237以及学习部238。
通信部210进行与信息显示终端100的通信,进行对信息显示终端100输入的翻译对象文的接收、后述的译文以及逆向翻译文的发送等。另外,并不仅限于这些信息,而是与信息显示终端100进行各种信息的收发。
控制部220对通信部210、机器翻译部230以及存储部240的各种工作进行控制。
存储部240对机器翻译部230在各种翻译处理、短语分割处理等中参照的短语表进行保存。将在下文中对短语表进行说明。
机器翻译部230对通过通信部接收到的翻译对象文执行机器翻译处理。在机器翻译部230中,通过基于规则的机器翻译(RBMT)、统计机器翻译(SMT)、基于深度神经网络获得模型的机器翻译(DNNMT)等来进行机器翻译。机器翻译部230对翻译结果进行评价,从而取得自动评价评分(BLEU等)、内部评分(基于人工的评价等)等评分。
另外,为了使由用户做出的选择结果反映到机器学习中,根据翻译方法,根据需要而准备如图11所示的、预先表示了短语对的短语表。
由于基于规则的机器翻译(RBMT)是以通过人工构建的转换规则(将译语对作为数据库进行存储而得到的)为基础进行翻译的,因此有可能没有保持如图11那样的短语表。但是,在存在以句子或者单词为单位的对译数据库的情况下,则既可以将学习结果反映到对译数据库中,也可以另行准备短语表。
在统计机器翻译(SMT)中,预先保持有如图11那样的短语表,因此,只要使用该表即可。
由于在基于深度神经网络获得模型的机器翻译(DNNMT)中是自动构建模型本身的,因此,大多未保持有短语表。由此,也可以另行准备短语表。
进一步,将用户的选择反映至学习结果的对象并不仅限于此,例如,也可以具有表现源语言之间的说法变换对那样的数据库。此外,关于机器翻译处理的详细内容,将在下文中进行说明。
顺向翻译部231执行从通过通信部210接收到的翻译对象文的语言(源 语言)向将翻译对象文进行翻译所得的结果输出的语言(目标语言)的机器翻译处理。在此,将从源语言到目标语言的翻译作为“顺向翻译”,将通过顺翻译获得的译文作为“顺向翻译文”。此时,通过顺翻译处理,对于翻译对象文将会生成多个顺向翻译文。另外,顺向翻译部231参照保存在存储部240中的短语表来进行机器翻译处理。使在顺向翻译部231中生成的多个顺向翻译文为“顺向翻译文组”。顺向翻译部231将所生成的顺向翻译文组输出到顺向翻译文选择部232。
顺向翻译文选择部232进行顺向翻译文选择处理,该顺向翻译文选择处理从由顺向翻译部231生成的顺向翻译文组中选择N个顺向翻译文。关于该顺向翻译文选择处理的详细内容,将在下文中进行说明。顺向翻译文选择部232将选择出的N个顺向翻译文输出到逆向翻译部233。
逆向翻译部233对在顺向翻译文选择部232中选择出的N个顺向翻译文,分别执行从顺向翻译文的语言(目标语言)到翻译对象文的语言(源语言)的机器翻译处理。在此,将从目标语言到源语言的翻译作为“逆向翻译”,将通过逆向翻译获得的译文作为“逆向翻译文”。此时,通过逆向翻译处理,对于各个顺向翻译文将会生成一个以上的逆向翻译文。因此,作为结果,生成多个逆向翻译文。另外,逆向翻译部233参照保存在存储部240中的短语表来进行机器翻译处理。使在逆向翻译部233中生成的多个逆向翻译文为“逆向翻译文组”。逆向翻译部233将所生成的逆向翻译文组输出到逆向翻译文选择部234。
逆向翻译文选择部234进行逆向翻译文选择处理,该逆向翻译文选择处理从由逆向翻译部233生成的逆向翻译文组中选择M个逆向翻译文。将在下文中对该逆向翻译文选择处理进行说明。通过通信部210,逆向翻译文选择部234将选择出的M个逆向翻译文发送到信息显示终端100。在信息显示终端100的输出部103,以可选择的方式输出M个逆向翻译文。
选择文判断部235根据通过通信部210从信息显示终端100接收到的用户选择信息,判断用户从在逆向翻译文选择部234选择出的M个逆向翻译文中选择了哪个逆向翻译文,并将判断出的信息输出到短语分割部236。
短语分割部236基于从逆向翻译文选择部234输入的多个逆向翻译文,对于多个逆向翻译文,分别将逆向翻译文以句子或者单词为单位进行分割。另外,对于与逆向翻译文对应的顺向翻译文,也以句子或者单词为单位进行分割。此时,也可以一并使用从选择文判断部235输入的表示从多个逆向翻译文中选择了哪个逆向翻译文的信息。另外,还可以使用保存在存储部240中的短语表。将以句子或者单词为单位分割逆向翻译文及顺向翻译文所得的信息、以及用户选择信息输出到选择结果评价部237。
在短语分割中,多使用如统计机器翻译(SMT)所示的、表示双语言之间的以句子或者单词为单位的对应关系的短语表,但是,未必需要使用既定的短语表,也可以是与其相似的表。在机器翻译中使用了短语表的情况下,也可以使用该短语表进行分割。或者,既可以使用另行准备的短语表等,如果存在对译辞典等则也可以使用该对译辞典等。
在选择结果评价部237中,基于从短语分割部236输入的信息,对顺向翻译文以及逆向翻译文进行评价。此时,也可以基于用户选择信息,按照用户选择文与用户非选择文来进行不同的评价。将在下文中对详细的评价方法进行说明。选择结果评价部237将对顺向翻译文以及逆向翻译文进行评价而得到的评价信息输出到学习部238。
学习部238基于从选择结果评价部237输入的评价信息,对保存在存储部240中的短语表进行更新,由此,进行机器翻译处理中的机器学习。即,将评价信息反映到短语表中。作为机器学习的对象,既可以是顺向翻译部231所参照的短语表,也可以是逆向翻译部233所参照的短语表。另外,也未必需要将评价信息反映到短语表中,例如,可以将结果反映到说法变换辞典和/或单词辞典等中而进行机器翻译处理中的机器学习。关于对短语表反映评价信息的详细的方法,将在下文中进行说明。
图4是表示通过程序来实现信息显示终端的各部分功能的计算机的硬件结构的图。该计算机1000具备:输入按钮、触摸板等输入装置1001;显示器、扬声器等输出装置1002;CPU(Central Processing Unit,中央处理单元)1003;ROM(Read Only Memory,只读存储器)1004;以及RAM (Random Access Memory,随机存取存储器)1005等。另外,计算机1000也可以具备:硬盘装置、SSD(Solid State Drive,固态盘)等存储装置1006;从DVD-ROM(Digital Versatile Disk Read Only Memory,数字多功能盘只读存储器)、USB(Universal Serial Bus,通用串行总线)存储器等存储介质中读取信息的读取装置1007;以及经由网络进行通信的收发装置1008。上述的各部分通过总线1009来连接。
并且,读取装置1007从存储有用于实现上述各部分功能的程序的存储介质中读取该程序,并存储到存储装置1006中。或者,收发装置1008与连接在网络上的服务器装置进行通信,将从服务器装置处下载的用于实现上述各部分功能的程序存储到存储装置1006中。
并且,CPU1003将存储在存储装置1006中的程序复制到RAM1005中,并从RAM1005依次读取并执行该程序所包含的命令,由此,实现上述各部分的功能。另外,在执行程序时,可将由在各实施方式中说明的各种处理所获得的信息存储在RAM1005或者存储装置1006中,并适当地加以利用。
图5是表示本实施方式中的机器翻译系统的工作的流程图。为了简单起见,在本流程图中,设信息显示终端100的输入部102以及输出部103由触摸屏显示器来实现。设为在信息显示终端100通过触摸屏显示器进行用户的输入以及翻译结果等的输出,但是,例如也可以构成为键盘与显示器等、输入部102与输出部103各自独立的结构。另外,还可以进行基于语音的输入输出。另外为了说明,有使源语言(母语)为日语、使目标语言为英语来进行说明的地方。然而这些仅为一例,源语言以及目标语言可以是任意的组合。
首先,在步骤S401中,取得由用户输入的翻译对象文。在步骤S402中,进行对翻译对象文的机器翻译处理。在此的机器翻译处理是将源语言的翻译对象文翻译成目标语言的文字串(顺向翻译文)的顺翻译处理。此时,例如,统计机器翻译(SMT)根据翻译模型和语言模型来对作为翻译的准确度进行评分。翻译模型是指规定译语的似然性的统计模型,语言模 型是指规定输出语言的单词排列的似然性的统计模型。根据这两个模型,对作为翻译的准确度进行评分,并按其评分顺序输出翻译结果,由此,将会生成多个顺向翻译文,为便于说明,设该多个顺向翻译文为“顺向翻译文组”。
由于本实施方式中的机器翻译的具体处理就是一般的机器翻译的处理,因此省略此处的说明。
在步骤S403中,基于预定的基准,从顺向翻译文组中选择N个顺向翻译文。例如,既可以对顺向翻译文组所包含的多个顺向翻译文分别赋予评价评分,从评价评分高的顺向翻译文中选择N个。另外,也可以与评价评分无关、随机地选择N个,等等。另外,还可以考虑顺向翻译文组所包含的多个顺向翻译文表示的内容,以使选择出的N个顺向翻译文之中不包括相同主旨的顺向翻译文的方式进行选择。另外,当在顺向翻译文组所包含的多个顺向翻译文之中不同主旨的顺向翻译文少的情况下,根据需要也可以执行追加具有不同主旨的顺向翻译文的处理。关于顺向翻译文的详细的选择方法,将在下文中利用图6进行说明。
在进行了步骤S403的处理之后,在判断为需要增加顺向翻译文的情况下(步骤S404的判断结果为“是”),返回到步骤S402,再次执行顺翻译处理。此时,为了获得与已经获得的顺向翻译文不同的顺向翻译文,选择评分较之前低的顺向翻译文。另外,也可以使用其他翻译指标(例如,RIBES:rank-based intuitive bilingual evaluation score,基于排位的直觉双语评价法)。另外,若保持有源语言的说法变换的数据库,则也可以通过对输入文应用该数据库来生成相似文,并再次执行顺翻译处理。由此,可输入表面上不同但意思与输入文相同的句子,因此,能够获得不同的顺翻译文。
再次执行顺翻译处理之后,在步骤S403中执行顺向翻译文选择处理的情况下,既可以按与上次不同的基准选择顺向翻译文,也可以按相同基准选择顺向翻译文。
在进行了步骤S403的处理之后,在判断为无需增加顺向翻译文的情况 下(步骤S404的判断结果为“否”),使流程前进至步骤S405的逆向翻译处理。在步骤S405中执行逆向翻译处理,该逆向翻译处理对在步骤S403中获得的N个顺向翻译文进行逆向翻译。若设从源语言到目标语言的翻译为正向翻译,则逆向翻译是指从目标语言到源语言的逆向翻译。对N个顺向翻译文分别执行任意的生成逆向翻译文的逆向翻译处理。所谓任意的生成逆向翻译文的逆向翻译处理,意味着如下等处理:对于N个顺向翻译文分别生成一一对应的逆向翻译文的逆向翻译处理;在N个顺向翻译文之中存在不执行逆向翻译处理的顺向翻译文的逆向翻译处理;对一个顺向翻译文生成多个逆向翻译文的逆向翻译处理等。通过该逆向翻译处理,将会生成多个逆向翻译文。为便于说明,设该多个逆向翻译文为“逆向翻译文组”。
另外,对于按何种基准输出逆向翻译文,既可以按某种系统的基准来确定,也可以由用户决定。在此的系统的基准是指,使用BLEU等评价、人工评价等计算出顺向翻译文的评分,例如关于评分低的顺向翻译文,则不执行逆向翻译处理(关于某个顺向翻译文,生成零个逆向翻译文),而对评分高的顺向翻译文,则获得任意个数的逆向翻译文(关于某个顺向翻译文,生成多个逆向翻译文)等。在用户决定逆向翻译文个数的情况下,作为一例,可考虑设定对于一个顺向翻译文生成几个逆向翻译文等,但是并不仅限于此。
步骤S406是逆向翻译文选择处理,该逆向翻译文选择处理从通过步骤S405获得的逆向翻译文组之中选择M个逆向翻译文。在逆向翻译文选择处理中,进行与步骤S403的顺向翻译文选择处理大致同样的处理。关于详细的选择方法,将在下文中利用图6、图7进行说明。
在执行了步骤S406的逆向翻译文选择处理之后,在判断为需要增加逆向翻译文的情况下(步骤S407的判断结果为“是”),返回到步骤S402,再次进行顺翻译处理。再次执行了顺翻译处理之后,当在步骤S403中执行顺向翻译文选择处理时,既可以按与上次不同的基准选择顺向翻译文,也可以按相同基准选择顺向翻译文。
在进行了步骤S406的逆向翻译文选择处理之后,在判断为无需增加逆 向翻译文的情况下(步骤S407的判断结果为“否”),在接下来的步骤中,将从逆向翻译文组中选择出的M个逆向翻译文作为用户提示文输出到信息显示终端100。
在步骤S408中,将M个逆向翻译文发送到信息显示终端100,显示在触摸屏显示器上。
在步骤S409中,通过选择文检测部105,检测是否从显示在信息显示终端100的触摸屏显示器上的M个逆向翻译文中选择了一个逆向翻译文。
当判断为在一定期间内没有选择逆向翻译文的情况下,机器翻译系统返回到初始状态,受理用户的输入文(步骤S409的判断结果为“否”)。此时,将触摸屏显示器的显示画面复位。
另外,在用户执行了某种复位操作的情况下,机器翻译系统也同样地返回到初始状态以受理用户的输入文。
在通过选择文检测部105检测出任意的逆向翻译文被选择的情况下(步骤S409的判断结果为“是”),向翻译服务器300发送表示哪个逆向翻译文被选择的用户选择信息。
在步骤S411中,选择文判断部235从逆向翻译文选择部234取得M个逆向翻译文,并基于从信息显示终端100接收到的用户选择信息,对在信息显示终端100上选择了M个逆向翻译文之中的哪个逆向翻译文进行判断。将M个逆向翻译文之中被选择的逆向翻译文作为选择逆向翻译文、没有被选择的逆向翻译文作为非选择逆向翻译文,对后面的步骤进行说明。选择文判断部235将选择逆向翻译文以及非选择逆向翻译文输出到短语分割部236。
在步骤S412中,对选择逆向翻译文和非选择逆向翻译文、以及与各个选择逆向翻译文和非选择逆向翻译文对应的顺向翻译文,进行短语分割处理。
短语分割是指,将作为对象的语句分割成更短的单位、即句子或者单词。将在下文中对短语分割处理的具体例子进行说明。
图11是本实施方式中的一般的短语表的例子。短语表是指,表示了源 语言和目标语言的双语言间的以句子或者单词为单位的对应关系的表。
在图11中,设源语言为日语、目标语言为英语的情况下,从左边起表示有:日语短语、英语短语、短语的英日翻译概率(英语短语被翻译成日语短语的概率)、英译日方向的单词的翻译概率的乘积(英语被翻译成日语时的、短语内的每个单词的翻译概率的乘积)、短语的日英翻译概率(日语短语被翻译成英语短语的概率)、日译英方向的单词的翻译概率的乘积(日语被翻译成英语时的、短语内的每个单词的翻译概率的乘积)。但是,短语表不一定需要包含所有的这些信息,并不仅限于该表示方法。由于该短语表包含翻译概率,因此,在广义上也被称为概率模型。
例如,在图11所示的短语表中,表示了如下内容:短语PH2被翻译成短语PH1的概率为0.38;单词SD3被翻译成单词SD1的概率与单词SD4被翻译成单词SD2的概率的乘积为0.04;短语PH1被翻译成短语PH2的概率为0.05;单词SD1被翻译成单词SD3的概率与单词SD2被翻译成单词SD4的概率的乘积为0.02。
使用这样的短语表,对选择逆向翻译文、非选择逆向翻译文、以及分别与这些逆向翻译文对应的顺向翻译文,进行短语分割处理。
图12是用于表现短语分割的概要的说明图。
图12中示出了通过源语言表现的逆向翻译文RS10、RS20、RS30以及分别与这些逆向翻译文对应的目标语言的顺向翻译文TS10、TS20、TS30。在执行对源语言的逆向翻译文的短语分割处理的情况下,例如,当对逆向翻译文RS10进行短语分割时,将会分割出短语PH11、PH12、PH13这三个短语。另外,在执行对目标语言的顺向翻译文的短语分割处理的情况下,例如,当对顺向翻译文TS10进行短语分割时,将会分割出短语PH14、PH15、PH16这三个短语(单词)。
关于进行短语分割处理的对象文将会被分割成怎样的短语,取决于短语表中所表示的源语言以及目标语言的文字串,因此,有时无法唯一确定。
步骤S413是短语评价处理,该短语评价处理按照预定的基准,对通过短语分割处理输出的各短语评价评分。关于该短语评价处理的详细内容, 将在下文中进行说明。
在步骤S414中,将与通过S411判断出的选择逆向翻译文对应的顺向翻译文发送到信息显示终端100,并作为翻译结果显示在触摸屏显示器上。此时,既可以对显示在触摸屏显示器上的选择逆向翻译文进行强调显示。另外,也可以删除非选择逆向翻译文在触摸屏显示器上的显示,只要能够明示出所显示的翻译结果是与用户选择出的选择逆向翻译文对应的顺向翻译文,则可以进行任意的显示。
此外,步骤S414与步骤S412~S415的一系列处理是能够并行地工作的,因此,只要是在步骤S412的短语分割处理之前到步骤S415的学习处理之后的期间内,可以在任意定时(timing)执行步骤S414。
在步骤S415中,根据通过步骤S413获得的每个短语的评分,进行强化学习、识别学习、神经网络学习等机器学习。有关该处理的详细内容,利用图8、图9进行说明。
图6是表示本实施方式中的译文选择处理的具体工作的流程图。
利用图6,对在步骤S403中通过顺向翻译文选择部232执行的顺向翻译文选择处理、以及在步骤S406中通过逆向翻译文选择部234执行的逆向翻译文选择处理的具体处理进行说明。为便于说明,将顺向翻译文选择处理以及逆向翻译文选择处理这两个处理一并地设为译文选择处理。
在顺向翻译文选择部232中,执行顺向翻译文选择处理,该顺向翻译文选择处理从通过顺向翻译部231生成的顺向翻译文组中选择N个顺向翻译文;在逆向翻译文选择部234中,执行逆向翻译文选择处理,该逆向翻译文选择处理从通过逆向翻译部233生成的逆向翻译文组中选择M个逆向翻译文。根据顺向翻译文组所包含的多个顺向翻译文各自的评价评分,选择出N个顺向翻译文;根据逆向翻译文组所包含的多个逆向翻译文各自的评价评分,选择出M个逆向翻译文。
以下的说明内容既适用于顺向翻译文选择处理也适用于逆向翻译文选择处理,因此,作为译文选择处理进行说明,并将顺向翻译文和逆向翻译文一并地表示为“译文”。另外,将顺向翻译文组和逆向翻译文组表示为 “译文组”。再者,尽管实际上是选择N个顺向翻译文、选择M个逆向翻译文,但是在以下的说明中不加以区分而是表示为“N个”进行说明。
在步骤S501中,从译文组之中选择N-k个(1≤N,0≤k≤N)评价评分高的译文。在此,作为评价评分的例子,可列举出常被用作评价翻译精度的方法的BLEU。除此之外,作为评价翻译精度的方法,还有WER(Word Error Rate,误词率评价法)、METEOR(Metric for Evaluation of Translation with Explicit Ordering:基于显式排序的翻译评价标准)、RIBES(rank-based intuitive bilingual evaluation score,基于排位的直觉双语评价法)等,而评价的方法既可以使用它们中的任意方法,也可以不仅限于这些方法而使用其他的方法。
从译文组之中的在步骤S501中没有被选择的译文中,选择剩余的k个(S502)。
为了选择k个译文,也可以抽取评价评分在预定阈值内的译文,并从抽取出的译文中随机选择k个。另外,还可以抽取评价评分在预定阈值内的译文,并在抽取出的译文中按评分从低到高依次选择k个。虽然在选择N-k个译文时,选择了评价评分高的译文,但是在选择k个译文时,则未必选择评价评分高的译文。若只选择根据特定的评价基准而机械地赋予的评价评分高的译文,则选择出的译文全是内容相似的文章的可能性高。当考虑到在信息显示终端100上将多个逆向翻译文提示给用户、并让用户从中选择一个逆向翻译文时,则优选提示以在某种程度上不同的观点选择出的多个逆向翻译文。
若只提示相似的逆向翻译文而让用户从中进行选择,则有可能导致在后述的对机器翻译系统的机器学习处理中无法获得高的学习效果。在将由用户选择的选择逆向翻译文、以及没有被用户选择的非选择逆向翻译文用作训练数据以执行机器学习处理的情况下,由于对于机器翻译系统作为正例(正解)来学习的选择逆向翻译文、与作为负例(不正解)来学习的非选择逆向翻译文成为相似的文章,因此,无法针对机器翻译系统示出正例和负例的显著差别,无法期待学习的效果。为此,如本实施方式中说明的 那样,优选以在某种程度上不同的观点来选择多个逆向翻译文。
另外,若只提示相似的逆向翻译文,则需要用户考虑这些逆向翻译文的细微差异来选择一个逆向翻译文,因此,无法凭直觉选择一个逆向翻译文,也有可能导致在逆向翻译文的选择上耗费时间。如果如本实施方式这样,提示以在某种程度上不同的观点选择出的多个逆向翻译文,就能够使用户凭直觉从中选择符合自己意图的翻译内容。
另外,由于逆向翻译文是根据顺向翻译文生成的,因此,在选择顺向翻译文的阶段,认为也同样地优选以在某种程度上不同的观念来选择多个顺向翻译文。
另外,作为用于选择k个译文的不同方法,也可以基于过去的用户选择信息来选择k个译文。例如,也可以为每个译文存储过去被用户选择的次数等(对于逆向翻译文存储直接被选择的次数,对于顺向翻译文存储所对应的逆向翻译文被选择的次数),在译文组之中按所存储的次数从多到少依次选择k个译文。另外,还可以不基于这种直接的次数进行选择,而是根据用户过去利用机器翻译系统的历史记录,分析对于翻译对象文的用户容易选择的译文的倾向性,并基于分析出的倾向性来选择k个译文。此外,只要使用与选择N-k个译文的选择基准不同的选择基准,则选择k个译文的选择方法并不仅限于这些。
进一步,在这些k个译文的选择方法中,也可以进行除去与N-k个译文主旨相同的译文的处理。另外,还可以在k个译文之中也进行除去主旨相同的译文的处理。或者,当k个译文不包含与N-k个译文主旨不同的译文或者在k个译文之中包含较少的与N-k个译文主旨不同的译文的情况下,也可以进行添加不同主旨的译文的处理。另外,有关逆向翻译文选择处理,也可以进行与翻译对象文进行比较来选择具有相同主旨的逆向翻译文等处理。
例如,对译文组中包含多少疑问句、肯定句、否定句、命令句这样的各个形式的译文(不同句式的个数)进行计数,如果小于等于阈值,就再度进行顺向翻译处理或者逆向翻译处理。
另外,也有对译文进行句法分析等方法。分别对译文组所包含的多个译文进行句法分析,判断各自的表示主语的单词是什么,如果示出表示主语的单词有几种的不同主语的数量小于等于阈值,就再度进行顺向翻译处理或者逆向翻译处理。此时,也可以不是对主语而是对谓语计算不同数量。另外,还可以是对这两者进行计算。
在此,也可以将不同句式的数量、不同主语的数量、动词或宾语的不同数量等作为评价评分,进行顺向翻译文选择处理以及/或者逆向翻译文选择处理,以使得所包含的不同数量为预定的数量。
在执行顺向翻译文选择处理的情况下,例如可以设置“使不同句式的数量为2以上”这一评价基准,将不同句式的数量作为评价评分以选择顺向翻译文。也可以分别对顺向翻译文组所包含的多个顺向翻译文,依次使用句法分析以及/或者语义分析来进行解析,将出现了疑问句、肯定句、否定句、命令句中的几个种类作为不同句式的数量来进行评分,创建一个包含两种以上的一个小集合。
另外,例如,在执行逆向翻译文选择处理的情况下,也可以设置“使不同主语的数量为预定数以下”这一评价基准,将不同主语的数量作为评价评分以选择逆向翻译文。
此外,顺向翻译文选择处理或者逆向翻译文选择处理也可以并不仅限于这些例子,而是采用任意的顺向翻译文选择或者逆向翻译文选择的方法。
另外,有关逆向翻译文选择处理,也可以设为,进行与翻译对象文的比较评价,将通过比较评价而获得的值作为评价评分。例如,也可以对翻译对象文、以及逆向翻译文组之中的多个逆向翻译文进行句法分析,判断翻译对象文与多个逆向翻译文的各自的相似度,并基于判断出的相似度来选择k个逆向翻译文。
另外,并不限于这些例子,也可以将任意的评价评分进行组合加以使用。再者,也可以将N预先设定为预定的数,进一步以使其中所含的不同数量成为所期望的数量的方式将评分进行组合加以使用。
上述的译文的选择方法仅为一例,并非仅限于此。
此外,在k=0的情况下,N个译文全部从评价评分高的译文中被按序选择。另外,在k=N的情况下,N个译文全部通过从评价评分高的译文中被按序选择以外的选择方法来选择。
在此的系统的基准是指,使用BLEU等评价和/或人工评价等以计算出顺向翻译文的评分,例如关于评分低的顺向翻译文,则不执行逆向翻译处理(关于某个顺向翻译文,生成零个逆向翻译文),而对评分高的顺向翻译文,则获得任意数量的逆向翻译文(关于某个顺向翻译文,生成多个逆向翻译文)等。在用户决定逆向翻译文数量的情况下,作为一例,可考虑设定对于一个顺向翻译文生成几个逆向翻译文等,但是并不仅限于此。
图7是表示本实施方式中的逆向翻译文选择处理的具体工作的流程图。
在利用图5进行的对逆向翻译处理(步骤S405)的说明中,记述了既可以存在不生成逆向翻译文的顺向翻译文,也可以根据一个顺向翻译文生成多个逆向翻译文等。在此,对从根据一个顺向翻译文而得到的多个逆向翻译文之中选择一个逆向翻译文的处理进行说明。
对于通过顺向翻译文选择处理选择出的全部N个顺向翻译文,均执行以下的处理。
在步骤S601中,抽取对于N个顺向翻译文之中的顺向翻译文A所生成的逆向翻译文。
在步骤S602中,对抽取出的逆向翻译文的数量进行判断。在对于顺向翻译文A并没有生成逆向翻译文时,也就是说,在对于顺向翻译文A所生成的逆向翻译文为零个时(步骤S602的“0个”),顺向翻译文A不会被提示给用户,因此进行删除(步骤S603)。
接下来,在对于顺向翻译文A有一个逆向翻译文时(步骤S602的“1个”),将该逆向翻译文确定为与顺向翻译文A对应的逆向翻译文(步骤S604)。
最后,在对于顺向翻译文A生成有两个以上的逆向翻译文时(步骤S602的“2个以上”),从其中确定一个最佳的译文作为与顺向翻译文A 对应的逆向翻译文(步骤S605)。作为确定方法,例如可通过使用对自动评价评分和/或基于人工评价得到的评分进行参照的方法来选择。对于全部N个顺向翻译文反复这些处理。
最后,也可以根据需要进行如下的处理:从通过这些处理获得的逆向翻译文中,除去相同主旨的逆向翻译文,或者,在不同主旨的逆向翻译文少的情况下,追加具有不同主旨的译文等(步骤S606)。此处的处理与在图5的说明中记述的处理相同。
此外,在上述的说明中,设为在图7的步骤S605中,对于一个顺向翻译文选择一个逆向翻译文。然而,也可以是对于一个顺向翻译文选择出多个逆向翻译文的情况。在这种情况下,提示给用户的多个逆向翻译文之中,存在对应同一顺向翻译文的逆向翻译文。
图8是表示本实施方式中的短语评价处理的具体工作的流程图。
设为在流程的初始状态下,取得了事先分割成短语的选择逆向翻译文、非选择逆向翻译文、以及与选择逆向翻译文和非选择逆向翻译文的各自相对应的顺向翻译文。另外,设为也同样地取得了与将这些逆向翻译文以及顺向翻译文进行短语分割而获得的短语对应的短语表。该短语评价处理是分别对逆向翻译文以及顺向翻译文进行的,但是为便于说明,以对逆向翻译文的短语评价处理为例进行说明。
在步骤S701中,对于选择逆向翻译文以及非选择逆向翻译文,按每个逆向翻译文对这些逆向翻译文所包含的短语进行比较,确认有无仅存在于选择逆向翻译文的短语。
在有仅存在于选择逆向翻译文的短语的情况下(步骤S701的判断结果为“是”),对于仅存在于选择逆向翻译文的短语,将用户选择评分进行加分(步骤S702)。该用户选择评分是将仅出现在选择文中的短语设为优良短语的评分,最终将会在图9的处理中与顺向翻译文(在短语评价处理的对象为顺向翻译文的情况下,是翻译对象文)的所对应的短语一并反映到短语表的日英翻译概率或者英日翻译概率中。此时的评分的加分方法可以使用任意的方法。例如,可设想为对符合的短语一律进行加分、取决于 符合的短语的长度来进行加分等方法。当评分的加分结束时,使流程前进至步骤S703。在没有仅存在于选择逆向翻译文的短语的情况下(步骤S701的判断结果为“否”),不进行特别的处理,直接使流程前进至步骤S703。
同样地,在步骤S703中,相对于选择逆向翻译文以及非选择逆向翻译文,按每个逆向翻译文对这些逆向翻译文所包含的短语与进行比较,确认有无仅存在于非选择逆向翻译文的短语。
在有仅存在于非选择逆向翻译文的短语的情况下(步骤S703的判断结果为“是”),对于仅存在于非选择逆向翻译文的短语,将用户选择评分进行减分(步骤S704)。此时的评分的减分方法可以使用任意的方法。例如,可设想为对符合的短语一律进行减分、取决于符合的短语的长度来进行减分等方法。
此外,在步骤S702和S704中,用户选择评分的加分、减分不一定是必须的。也就是说,在图8的流程图中,也可以不对仅存在于选择逆向翻译文的短语进行评分的加分和减分,而对仅存在于非选择逆向翻译文的短语进行用户选择评分的减分。或者,也可以对仅存在于选择逆向翻译文的短语进行用户选择评分的加分,而不对仅存在于非选择逆向翻译文的短语进行用户选择评分的加分和减分。
另外,关于存在于选择逆向翻译文和一部分非选择逆向翻译文的短语,也可以进行评分的加分。在这种情况下,例如可考虑对如下值进行加分:该值是考虑了仅包含于选择逆向翻译文的短语的用户选择评分与仅包含于非选择逆向翻译文的短语的用户选择评分而得到的值(例如,仅包含于选择逆向翻译文的短语的用户选择评分与仅包含于非选择逆向翻译文的短语的用户选择评分的平均值)。这些评分的加分方法仅为一例,并不限于此。
下面,使用图12,列举具体例子进行说明。例如,对在信息显示终端100提示三个逆向翻译文,用户选择了其中一个逆向翻译文的情况进行说明。此时,假设提示在信息显示终端100上的三个逆向翻译文为逆向翻译文RS10、RS20、RS30,假设被用户选择的逆向翻译文是逆向翻译文RS10。另外,为便于说明,将被用户选择的逆向翻译文定义为选择逆向翻译文, 将没有被用户选择的逆向翻译文定义为非选择逆向翻译文。在流程的初始状态下,将作为选择逆向翻译文的逆向翻译文RS10分割成短语PH11、PH12、PH13。另外,对于非选择逆向翻译文也同样地,将逆向翻译文RS20分割成短语PH21、PH22、PH23,将逆向翻译文RS30分割成短语PH31、PH32、PH33。
在S701中,确认在逆向翻译文RS10、RS20、RS30中有无仅存在于作为选择逆向翻译文的逆向翻译文RS10的短语。于是,由于短语PH12仅包含于作为选择逆向翻译文的逆向翻译文RS10,因此将短语PH12的用户选择评分进行加分,设为“+1”。
同样地,在S703中,确认有无仅存在于作为非选择逆向翻译文的逆向翻译文RS20、RS30的短语。于是,由于短语PH22(PH32)和短语PH31仅包含于非选择逆向翻译文,因此分别将短语PH22(PH32)和短语PH31的用户选择评分进行减分,设为“-1”。
在此,关于包含在选择逆向翻译文、非选择逆向翻译文这二者中的短语PH11(PH21)、PH13(PH23、PH33),不进行用户选择评分的加分或者减分。
通过上述的处理,每个短语的最终的用户选择评分的加分量或者减分量如下所示。对于短语PH11(PH21)成为“±0”、对于短语PH31成为“-1”、对于短语PH22(PH32)成为“-1”、对于短语PH12成为“+1”、对于短语PH13(PH23、PH33)成为“±0”这样的加分量或者减分量。在此的评分的加分量以及减分量仅为一例,因此,既可以以大于该例的量级进行加分或者减分,也可以以小于该例的量级进行加分或者减分。
另外,关于对作为目标语言的顺向翻译文的短语评价处理,下面,利用图12,列举具体例子进行说明。对上述的逆向翻译文RS10、RS20、RS30分别对应有顺向翻译文TS10、TS20、TS30。在流程的初始状态下,将顺向翻译文TS10分割成短语PH14、PH15、PH16。另外,将顺向翻译文TS20分割成短语PH24、PH25、PH26,将TS30分割成短语PH34、PH35、PH36。
在S701中,确认有无仅存在于与选择逆向翻译文RS10对应的顺向翻 译文TS10的短语。于是,由于短语PH16仅包含于顺向翻译文TS10,因此将短语PH16的用户选择评分进行加分,设为“+1”。
同样地,在S703中,确认有无仅存在于与作为非选择逆向翻译文的逆向翻译文RS20、RS30对应的顺向翻译文TS20、TS30的任意一方的短语。于是,由于短语PH26(PH36)和短语PH34仅包含于顺向翻译文TS20或者TS30,因此分别将短语PH26(PH36)和短语PH34的用户选择评分进行减分,设为“-1”。
关于包含在与选择逆向翻译文对应的顺向翻译文TS10、包含在与非选择逆向翻译文对应的顺向翻译文TS20和顺向翻译文TS30中的任意一方的短语PH14(PH24)和短语PH15(PH25、PH35),不进行用户选择评分的加分或者减分。
通过上述的处理,每个短语的最终的评分的加分量或者减分量为,对于短语PH14(PH24)成为“±0”、对于短语PH34成为“-1”、对于短语PH26(PH36)成为“-1”、对于短语PH16成为“+1”、对于短语PH15(PH25、PH35)成为“±0”。在此的用户选择评分的加分量以及减分量仅为一例,因此,既可以以大于该例的量级进行加分或者减分,也可以以小于该例的量级进行加分或者减分。
图9是表示本实施方式中的学习处理的具体工作的流程图。
在步骤S801中,取得如下短语对,即与选择逆向翻译文对应的顺向翻译文所包含的短语、和选择逆向翻译文所包含的短语的短语对,或者与选择逆向翻译文对应的翻译对象文所包含的短语、和与选择逆向翻译文对应的顺向翻译文所包含的短语的短语对。短语对是指,进行机器翻译时在源语言、目标语言这两种语言之间分别取得了对应(具有相同的意思)的两个短语。进一步,也同时取得通过图8的处理而得到的用户选择评分。
在该短语对中,若使用图12所示的例子对与从源语言翻译到目标语言时所参照的短语表的值相对的用户选择评分进行定义,例如将会成为如下所示的结果,即短语PH31→短语PH34:-1/短语PH22(PH32)→短语PH26(PH36):-1/短语PH11(PH21)→短语PH14(PH24):0/短 语PH13(PH23、PH33)→短语PH15(PH25、PH35):0/短语PH12→短语PH16:+1。
另外,在短语对中,若对与从目标语言翻译到源语言时所参照的短语表的值相对的用户选择评分进行定义,例如将会成为如下所示的结果,即短语PH34→短语PH31:-1/短语PH26(PH36)→短语PH22(PH32):-1/短语PH14(PH24)→短语PH11(PH21):0/短语PH15(PH25、PH35)→短语PH13(PH23、PH33):0/短语PH16→短语PH12:+1。
在步骤S802中,对保存在存储部240中的短语表的英日翻译概率或者日英翻译概率反映上述的用户选择评分。另外,也可以在对用户选择评分乘以一定的值之后再向短语表反映等、对用户选择评分赋予斜率和/或加权。
利用这些,在机器翻译部230和/或逆向翻译部233中,进行强化学习和/或识别学习、神经网络学习等机器学习。
在迄今为止的机器翻译中,虽然进行了根据对译语料库(收集了在不同的两个语言之间彼此成为译文的句子对的数据)对如图11所示的短语表的概率值进行的调整,但是迄今为止还没有根据用户选择文所包含的和不包含的内容来对评分赋予差别以进行机器学习的方法,本公开的机器翻译系统能够进一步反映用户的评价结果。
再者,通过机器学习,对于由预先准备的对译语料库创建的翻译模型和/或语言模型等,能够逐次地边以短语为单位加入用户的选择结果,边使翻译模型和/或语言模型进行学习,因此,能够提高精度。
再者,通过进行机器学习,从而以数据为基础选择出最佳的参数。由此,人(用户)的选择结果会被反映到翻译系统中,因此,能够构造易于人使用的翻译系统。
此外,不仅进行如上所述的机器学习,而且也能够根据所获得的短语创建新的语料库,以作为用于翻译引擎学习的对译语料库加以利用。
图10是表示本实施方式中的学习部238的具体处理的流程图。利用图12所示的逆向翻译文以及顺向翻译文,对图10所示的流程图的内容进行 说明。
在步骤S901中,取得用户选择文与其顺译文翻译文的短语对。
例如,对在用户提示文显示区1102内显示有逆向翻译文RS10、RS20、RS30的状态下,由用户选择了逆向翻译文RS10的情况(逆向翻译文RS10是用户选择文的情况)进行说明。由于用户选择了逆向翻译文RS10,因此,将会取得短语PH11和短语PH14、短语PH12和短语PH16、短语PH13和短语PH15这样的短语对。
在步骤S902中,取得在机器翻译部230进行机器翻译时所使用的输入文与其顺向翻译文中的短语对。
例如,在逆向翻译文RS30所示的内容是输入文的情况下,将会取得短语PH31和短语PH34、短语PH32和短语PH36、短语PH33和短语PH35这样的短语对。
在步骤S903中,对于根据输入文和用户选择文取得的短语,取得目标语言的文字串相同的短语。例如,设用户选择文中的短语对如下。用户选择文中的短语对为,短语PH11和短语PH14、短语PH12和短语PH16、短语PH13和短语PH15。与此相对地,设输入文的短语对如下。输入文的短语对为,短语PH31和短语PH34、短语PH32和短语PH36、短语PH41和短语PH42。
此时,在用户选择文的短语和输入文的短语中,源语言的短语PH33与短语PH41是具有相同意思而表达不同的短语。另外,短语PH33与短语PH41是在用户选择文的短语和输入文的短语之间分别相对应的短语。
最后,对同一目标语言检查源语言是否不同,将不同的作为释义(说法变换)进行保持(S904的“是”、S905)。也就是说,因为尽管目标语言相同但源语言不同,因此能够将它们视为源语言中的说法变换。
例如,能够将短语PH33与短语PH41视为说法变换,将它们保持为源语言之间的释义。
能够在如下情况参照该释义:在机器翻译部230中进行机器翻译时参照,或者在进行翻译前,作为源语言侧的说法变换来参照。
图13是表示本实施方式中的显示画面的一例的图。
例如,如图13的(A)所示,当从用户受理作为翻译对象的原文的输入时,将所输入的原文OS1内容显示在输入文显示区1101。
接下来,如图13的(B)所示,将与翻译原文OS1而得到的译文相对的逆向翻译结果显示在用户提示文显示区1102。
作为一例,在此,对输出三个逆向翻译文的方式进行说明。作为逆向翻译结果,例如将逆向翻译文RS1、逆向翻译文RS2、逆向翻译文RS3输出并显示在用户提示文显示区1102。此时,图13的(B)的用户提示文显示区1102内所显示的逆向翻译文RS1~RS3在源语言中是分别具有同样意思的相似文。虽然在逆向翻译处理的特性上期待它们为具有同样意思的相似文,但是也可以实现为输出分别具有不同意思的文章。
接下来,如图13的(C)所示,用户对显示在用户提示文显示区1102内的逆向翻译结果进行确认,选择意图最接近于自己的输入内容的逆向翻译文。在此,对于原文OS1,例如选择了逆向翻译文RS1。
当用户选择了逆向翻译文,将与所选择的逆向翻译文对应的译文显示在翻译结果显示区1103。在此,显示了与逆向翻译文RS1对应的译文、即译文TS1。
此外,关于画面显示,并不仅限于如图13的(A)、(B)、(C)所示的布局。根据需要也可以配置各种的按钮,例如也可以设置为,在输入了翻译对象的原文之后,若进行对按钮的操作,则执行翻译处理。另外,还可以设置为,通过进行对按钮的操作,在用户提示文显示区1102内显示出逆向翻译文。另外,输入文显示区1101、用户提示文显示区1102、翻译结果显示区1103的配置和/或所显示的内容、朝向并不仅限于上述的内容。
图14是表示本实施方式中的显示画面的一例的图。
在显示上与图13的(C)有一部分差异。在此,显示在翻译结果显示区1201的文章的朝向与显示在输入文显示区1202及用户提示文显示区1203的文章的朝向不同。这是预想了两位用户(源语言说话者和目标语言说话者)隔着信息显示终端面对面进行交流的场景。即,显示在输入文显示区1202及用户提示文显示区1203的文章是以按照源语言说话者的朝向 来显示的,显示在翻译结果显示区1201的文章是以按照目标语言说话者的朝向来显示的。由此,源语言说话者既不需要将相对于输入文而输出的译文读给目标语言说话者,也不需要变换信息显示终端的朝向以使目标语言说话者容易对译文进行确认,因此,通过信息显示终端等能够与讲不同语言的用户进行顺利的交流。此外,翻译结果显示区1201的朝向能够通过由用户进行的任意操作来变更。另外,与图13同样地,各区域的配置和/或所显示的内容、朝向并不仅限于此。
以上,虽然基于实施方式对本发明的一个技术方案所涉及的翻译方法进行了说明,但是本发明并不限定于这些实施方式。只要不偏离本发明的主旨,则将本领域技术人员能够想到的各种变形实施于本实施方式、或者将不同实施方式中的构成要素组合而构建的方式也包含在本发明的范围内。
例如,虽然在上述的说明中设为从信息显示终端100所提示的多个逆向翻译文之中由用户选择出一个逆向翻译文,但是也可以为选择多个逆向翻译文。例如,虽然是选出一个作为用户的选择来提示顺向翻译文,但是还可以对其他的用户非选择文也进行评价,并将其结果作为学习结果以反映到系统中。作为此处的评价方法,例如以如下方法等进行评价:对于用户非选择文,用户按优劣次序进行排序,由用户选择能够在与用户选择文相同程度地容许的非选择文,由用户选择明显无法容许的非选择文。通过进行这些处理,能够对没有被选择的句子也进行评价,通过将它们反映到系统中,有助于系统的学习。
另外,虽然在上述的说明中,如图13那样对于输入文,通过文本输出了用户提示文和结果的译文,但是与此相对地,也可以以文本和语音方式、或者仅以语音方式进行提示。在这种情况下,对于用户提示文,用户也可以用通过麦克风从用户提示文中选择其一这样的方法来进行选择。
产业上的可利用性
本发明所涉及的机器翻译方法在机器翻译系统中是有用的,该机器翻译系统连接于输出语言信息的信息输出装置,执行第一语言与第二语言之间的翻译处理。
- 还没有人留言评论。精彩留言会获得点赞!