一种社交关系驱动的微博主题情感分析方法与流程
本发明涉及网络舆情分析
技术领域:
,特别涉及一种应用于Web2.0环境下的社交关系驱动的微博主题情感分析方法。
背景技术:
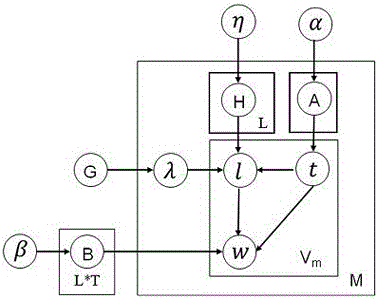
:微博是Web2.0时代兴起的一种集成化、开放化的互联网社交服务,它让用户能够向公众发布简短的文本消息。由于其简便的特点,日益受到互联网用户的青睐。目前新浪微博用户规模已经超过3亿,每天都有大量的微博消息发布。在这些海量的微博消息中,有许多饱含个人情感的资源,如何从这些微博消息中高效自动地提取主题与情感是一个很具有研究价值的热点。作为一个社交平台,微博用户与用户之间有关注、粉丝、互相关注等社交关系,其中互相关注的用户常常是熟识的朋友、拥有相似兴趣爱好或性格相近的用户。若某一用户关注了另一用户或两个用户间互相关注,我们通常可以看到一个用户的粉丝经常转载其所关注用户的微博并且表示赞同,并且用户们也会加入其所关注用户发表的话题中进行讨论,由此可知,微博用户所写微博的主题、情感极性与用户所关注的用户或用户的粉丝存在着联系。若两个用户互相关注,两个用户所写微博的总体情感极性(积极、消极)应该相似,若用户U1关注用户U2,则U1所写微博的总体情感极性应与U2所写微博的总体情感极性相似。现有的LDA主题情感模型如JST、S-LDA、DPLDA等可以对微博进行分析得到微博的情感极性,但这些模型都假设文本间是相互独立、没有联系的,这与微博用户关系不符。例如用户U1与用户U2性格相近、拥有共同兴趣,并且在微博上相互关注,用户U1发了一个微博:微博1:“库里的三分球真是太准了,库里太厉害了,很崇拜他!”可以看出,微博1的情感极性是积极的,而且现有的LDA主题情感模型也可以正确地分析出微博1的情感极性。然后,用户U2也发了一个微博:微博2:“库里太变态了,简直不是人,太厉害了!”我们可以看出,微博2的情感极性也是积极的,但是现有LDA主题情感模型也许会把微博2的情感极性分类为消极情感极性,这是由于没有考虑用户U1与用户U2之间的关系,因为U1与U2互相关注,一定程度上可以表明他们的性格相似、兴趣相投,用户U1的微博总体情感极性为积极,那在判断用户U2所发微博的时候,应该认为用户U2的微博为积极情感极性的概率更大,积极情感极性参数就应该比消极情感极性参数大,但是现有LDA主题情感模型假设文本间互相独立,所以无法达到这个效果。从上述分析可知,现有具有代表性的LDA主题情感模型没有很好地考虑微博用户关系,这可能导致微博情感分析准确率降低。技术实现要素:本发明的目的在于提供一种社交关系驱动的微博主题情感分析方法,该方法能够有效发现隐藏于微博消息中的主题情感模式,提高微博情感分类的正确率。为实现上述目的,本发明的技术方案是:一种社交关系驱动的微博主题情感分析方法,包括以下步骤:步骤1、对微博消息集进行微博文本分词、去停用词预处理,提取微博用户关系分布G,并设置情感词典;步骤2、利用情感词典对微博消息进行情感极性与主题归属先验处理:针对词语w,首先按以下方法为w分配主题:生成一个随机数rt,则w所对应的主题t即是第(rt+1)个主题,其中rt∈[0,T],T为微博消息集的主题数;然后按以下方法为w分配情感标签:从情感词典中查找词语w,若情感词典中有w,则将情感词典中w所对应的情感标签l分配给w,否则产生一个随机数rl,则w的情感标签l即是第(rl+1)个情感标签,其中rl∈[0,L],L为情感极性类别数;步骤3、初始化社交关系主题情感模型SRTSM的分布参数并将循环控制计数器C1与C2置0;步骤4:利用社交关系主题情感模型SRTSM不断对变量VarSet=(nm,t,l,nm,t,nm,nt,l,w,nt,l)、和进行如下迭代更新直到循环控制计数器C1达到最大迭代次数:步骤41:判断C1是否大于设定值X,是则转步骤5,否则转下一步骤;步骤42:对每条微博d中的每个词语w,首先从VarSet中除去当前词语w所属的情感标签与主题,再通过用户关系分布G查找与当前微博作者相互关注的用户并利用这些用户微博的情感极性确定用户关系参数λ的值,然后利用吉布斯采样的联合概率p(ti=t,li=l|t-i,l-i,w)重新给w赋一个基于用户关系参数λ的情感标签和主题,同时更新变量VarSet;步骤43:令C2=C2+1,以更新C2;步骤44:判断C2是否大于设定值Y,是则转下一步骤,否则返回步骤42;步骤45:更新和并置C2=0,然后转步骤41;其中nm,t,l表示微博dm中情感极性为l的词语属于主题t的频数,nm,t表示微博dm中属于主题t的词语总频数,nm表示微博dm总词语数,nt,l,w表示词语w同时属于主题t、情感极性l的频数,nt,l表示所有同时属于主题t、情感极性l的词语总频数,表示微博dm中主题t出现的概率,表示所有微博中词语w同时属于主题t和情感标签l的概率,表示微博dm中情感标签l属于主题t的概率;步骤5、判断微博m的情感极性并输出:若其中l1为积极情感,l2为消极情感,则判定微博dm的情感极性为积极情感,反之为消极情感。进一步的,所述社交关系主题情感模型SRTSM的建立方法为:(1)初始化社交关系主题情感模型SRTSM的分布参数Π={A,B,H},其中,A为微博-主题分布,表示微博dm的主题为t的概率,B为(主题,情感)-词语分布,表示词语w同时属于情感极性l与主题t的概率,H为(微博,主题)-情感分布,表示微博dm中情感极性l属于主题t的概率,A、B与H分别服从狄利克雷分布Dir(α)、Dir(β)与Dir(η),其中α是指主题t在微博dm中出现的先验次数,β是指词语在微博集C中出现的先验次数,η是指情感极性l在微博dm中出现的先验次数;(2)重复如下操作直到生成一条微博消息中的所有词语:首先从微博-主题分布A中选出一个主题t,t服从Mul(A)分布,其中Mul(*)表示多项分布;接着根据产生的主题t,从(微博,主题)-情感分布H中选出一个情感标签l,l服从Mul(H)分布并且受λ的影响,λ受用户关系分布G影响,G为已知的微博用户关系矩阵,假设当前微博作者为用户k,若用户k与j互相关注,则G(k,j)=1,否则G(k,j)=0;当G(k,j)为1时,计算用户j的情感极性值,通过所有与用户k互相关注的用户的情感极性值确定用户关系参数λ;最后根据选出的主题t和情感并且l,从(主题,情感)-词语分布B中选择一个词语w,w服从Mul(B)分布;(3)重复步骤(2)直到微博集C中的所有微博消息生成完毕。本发明的有益效果是提供了一种社交关系驱动的微博主题情感分析方法,相较于传统的微博主题情感分析方法,本发明方法将相互关联的微博用户所发微博的情感视为相互关联的,能更好地反映微博社交行为习惯,避免了现有LDA主题情感模型的不同用户的微博间上相互独立的假设,能有效提高微博情感分类正确率,可广泛应用于新浪、腾讯等各种微博平台,提升信息主动服务质量,增强网络文化安全。附图说明图1是本发明实施例的实现流程图。图2是本发明实施例中用户关系主题情感模型SRTSM的图模型。图3是本发明实施例中微博用户关系比例对SRTSM情感分类准确率的影响示意图。具体实施方式下面结合附图及具体实施例对本发明作进一步的详细说明。为了更好地描述本发明的技术方案,现将本发明技术方案的相关符号进行列表说明,参见表1。表1符号说明符号说明α微博-主题分布的Dir参数β(主题,情感)-词语分布的Dir参数λ用户关系参数η(微博,主题)-情感分布的Dir参数Α微博-主题分布Β(主题,情感)-词语分布H(微博,主题)-情感分布G用户关系分布t主题l情感w词语M微博数W微博中词语数T主题数L情感数V微博词库的词语数为了方便详细阐述本发明,首先对LDA主题模型进行简介。LDA是一种非监督机器学习技术,可以用来识别大规模文档集中潜藏的主题信息。它采用了词袋(bagofwords)表示方法,将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数学对象,每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。LDA通过概率推导方法来寻找文档集的语义结构,具体可描述为文档单词生成过程:对每一篇文档都从主题分布中抽取一个主题,然后从与该主题所对应的单词分布中抽取一个单词,重复上述过程直至遍历文档中的每一个单词。本发明社交关系驱动的微博主题情感分析方法,综合主题模型LDA与微博用户相关关注行为对微博主题情感进行分析,如图1所示,包括以下步骤:步骤1、对微博消息集进行微博文本分词、去停用词等预处理,提取微博用户关系分布G,并设置情感词典。步骤2、利用情感词典对微博消息进行情感极性与主题归属先验处理:针对词语w,首先按以下方法为w分配主题:生成一个随机数rt,则w所对应的主题t即是第(rt+1)个主题,其中rt∈[0,T],T为微博消息集的主题数;然后按以下方法为w分配情感标签:从情感词典中查找词语w,若情感词典中有w,则将情感词典中w所对应的情感标签l分配给w,否则产生一个随机数rl,则w的情感标签l即是第(rl+1)个情感标签,其中rl∈[0,L],L为情感极性类别数。在本领域公知技术中,情感极性和情感标签具有相同含义,但在不同环境中一般相应使用上述不同名称,因此,在本发明中,保留本领域的惯用表达而未做名称上之统一。步骤3、初始化社交关系主题情感模型SRTSM的分布参数并将循环控制计数器C1与C2置0。步骤4:利用社交关系主题情感模型SRTSM不断对变量VarSet=(nm,t,l,nm,t,nm,nt,l,w,nt,l)、和进行如下迭代更新直到循环控制计数器C1达到最大迭代次数:步骤41:判断C1是否大于设定值X,是则转步骤5,否则转下一步骤;步骤42:对每条微博d中的每个词语w,首先从VarSet中除去当前词语w所属的情感标签与主题,再通过用户关系分布G查找与当前微博作者相互关注的用户并利用这些用户微博的情感极性确定用户关系参数λ的值,然后利用吉布斯采样的联合概率p(ti=t,li=l|t-i,l-i,w)重新给w赋一个基于用户关系参数λ的情感标签和主题,同时更新变量VarSet;步骤43:令C2=C2+1,以更新C2;步骤44:判断C2是否大于设定值Y,是则转下一步骤,否则返回步骤42;步骤45:更新和并置C2=0,然后转步骤41。其中nm,t,l表示微博dm中情感极性为l的词语属于主题t的频数,nm,t表示微博dm中属于主题t的词语总频数,nm表示微博dm总词语数,nt,l,w表示词语w同时属于主题t、情感极性l的频数,nt,l表示所有同时属于主题t、情感极性l的词语总频数,表示微博dm中主题t出现的概率,表示所有微博中词语w同时属于主题t和情感标签l的概率,表示微博dm中情感标签l属于主题t的概率。步骤5、判断微博m的情感极性并输出:若其中l1为积极情感,l2为消极情感,则判定微博dm的情感极性为积极情感,反之为消极情感。上述社交关系主题情感模型SRTSM的建立方法为:(1)初始化社交关系主题情感模型SRTSM的分布参数Π={A,B,H},Π表示分布参数A、B、H的集合,其中,A为微博-主题分布,表示微博dm的主题为t的概率,B为(主题,情感)-词语分布,表示词语w同时属于情感极性l与主题t的概率,H为(微博,主题)-情感分布,表示微博dm中情感极性l属于主题t的概率,A、B与H分别服从狄利克雷分布Dir(α)、Dir(β)与Dir(η),其中α是指主题t在微博dm中出现的先验次数,β是指词语在微博集C中出现的先验次数,η是指情感极性l在微博dm中出现的先验次数;(2)重复如下操作直到生成一条微博消息中的所有词语:首先从微博-主题分布A中选出一个主题t,t服从Mul(A)分布,其中Mul(*)表示多项分布;接着根据产生的主题t,从(微博,主题)-情感分布H中选出一个情感标签l,l服从Mul(H)分布并且受λ的影响,λ受用户关系分布G影响,G为已知的微博用户关系矩阵,假设当前微博作者为用户k,若用户k与j互相关注,则G(k,j)=1,否则G(k,j)=0;当G(k,j)为1时,计算用户j的情感极性值,通过所有与用户k互相关注的用户的情感极性值确定用户关系参数λ;最后根据选出的主题t和情感并且l,从(主题,情感)-词语分布B中选择一个词语w,w服从Mul(B)分布;(3)重复步骤(2)直到微博集C中的所有微博消息生成完毕。下面参考图2来说明本发明方法中的社交关系主题情感模型SRTSM。尽管主题模型LDA有着牢固的数学基础与良好的扩展性,但情感层的缺失使其无法完成文档情感的分析。基于此,我们对LDA主题情感模型进行改造,在情感层中加入了用户关系分布G和用户关系参数λ,构造一个用以分析微博主题情感模式的概率图模型SRTSM(图2)。在SRTSM中,在判断一个微博的情感极性时,根据用户关系分布G找出与微博作者相互关注的微博用户,根据这些微博用户的平均情感极性值来确定用户关系参数λ,用户的情感极性为用户积极情感极性微博与消极情感极性微博的比值,用户平均情感极性值是用户情感极性值的和与用户数的比值。对于微博集C={d1,d2,…,dM},其中M为微博集的微博数,与微博集C对应的词典的大小为V,微博dm由Wm个单词组成,即dm={w1,w2,…,wWm}。SRTSM产生微博集C的过程可简单归结为如下两个步骤:1)初始化SRTSM模型的分布Θ={A,B,H},具体地,A、B与H分别服从狄利克雷分布Dir(α)、Dir(β)与Dir(η),其中β是指单词在微博集C中出现的先验次数,η是指情感标签l在微博dm中出现的先验次数,α是指主题t在微博dm中出现的先验次数。2)生成微博集C中的单词,此生成过程可简单描述如下:首先从微博-主题分布A中选出一个主题t,t服从Mul(A)分布(Mul(*)表示多项分布);接着根据产生的主题t,从(微博,主题)-情感分布H中选出一个情感标签l,l服从Mul(H)分布并且受λ的影响,λ受用户关系分布G影响,G为已知的微博用户关系矩阵,假设当前微博作者为用户X,若用户X与Y互相关注,则GX,Y=1,否则GX,Y=0。当GX,Y为1时,计算用户Y的情感极性值,通过所有与用户X互相关注的用户的情感极性值确定用户关系参数λ;最后根据选出的主题t和情感并且l,从(主题,情感)-词语分布B中选择一个单词w,w服从Mul(B)分布。SRTSM模型重复以上过程M*Wm次。SRTSM模型推导SRTSM采用吉布斯采样进行推导,为了得到本发明所需要的分布A、B与H,需要计算联合分布:P(ti=t,li=l|t-i,l-i,w)(1)其中t-i与l-i分别是指除微博dm中第i个词以外的其他词的主题与情感标签。联合分布可以拆分为如下项:P(w,t,l)=P(w|t,l)P(l|t)P(t)(2)通过对式子(4.2)进行展开可得:P(w|t,l)=∫P(w,|t,l,B)P(B|β)dB=(Γ(Vβ)[Γ(β)]V)T*L*Πl=1LΠt=1TΠw=1VΓ(nt,l,w+β)Γ(nt,l+Wβ)---(3)]]>其中nt,l,w表示单词w同时属于主题t、情感标签l的频数,nt,l,表示所有同时属于主题t、情感标签l的单词总频数,Γ(*)表示伽马函数。P(l|t)=∫P(l|t,λ,H)P(H|η)dH=(Γ(Lα)[Γ(α)]L)M*T*Πm=1MΠt=1TΠl=1LΓ(nm,t,l+η+λ)Γ(nm,t+Lη)---(4)]]>其中nm,t,l表示微博dm的中情感标签为l的词语属于主题t的频数,nm,t表示微博dm中属于的主题t的词语总频数。λ为用户关系参数,λ由与当前微博作者相互关注用户的情感极性决定,每个微博用户的λ取值不同。P(t)=∫P(t|A)P(A|α)dA=(Γ(Tη)[Γ(η)]T)M*Πm=1MΠt=1TΓ(nm,t+α)Γ(nm+Tα)---(5)]]>其中nm,t表示微博dm中主题t出现的频数,nm表示微博dm总单词数。有了公式(3)、(4)、(5)后,就可以计算吉布斯采样的联合概率:p(ti=t,li=l|t-i,l-i,w)=P(w|t,l)P(l|t)P(t)P(w)P(w-i|t-i,l-i)P(l-i|t-i)P(t-i)∝{nt,lw}-i+β{nt,l}-i+Wβ*{nm,tl}-i+η+λ{nm,t}-i+Lη*{nmt}-i+α{nm}-i+Tα---(6)]]>其中,表示除了当前单词,所有微博中单词w同时属于主题t和情感标签l的频数,{nt,l}-i表示除了当前单词,所有微博中属于主题t和情感标签l的单词总频数。表示微博dm中,除了当前单词,情感标签l属于主题t的频数,{nm,t}-i表示微博dm中,除了当前单词,属于主题t的情感标签总频数。表示除了当前单词,微博dm中主题t的频数,{nm}-i表示除了当前单词,微博dm的单词总数。进一步利用最大似然估计方法对参数Π={A,B,H}进行估计,其可形式化为公式(7)、(8)与(9)。Bt,lw=nt,lw+βnt,l+Wβ---(7)]]>Amt=nmt+αnm+Tα---(8)]]>Hm,tl=nm,tl+η+λlnm,t+Lη---(9)]]>其中,表示所有微博中词语w同时属于主题t和情感标签l的概率。表示微博dm中,主题t出现的概率。表示微博dm中情感标签l属于主题t的概率。对于一个需要进行情感分析的微博,可以根据计算微博的情感极性,若微博属于积极情感的概率大于微博属于消极情感的概率(即其中0为积极情感,1为消极情感),则判定该微博的情感极性为积极,反之,则判定该微博的情感极性为消极。性能评测为了定量地分析SRTSM模型的性能,我们选择短文本主题情感分析的代表性算法JST、S-LDA、DPLDA模型与我们的SRTSM模型在新浪微博数据集上进行情感分析准确率、用户关系对准确率的影响和主题提取三个方面的定量分析。实验环境为:CPU为IntelCorei5-2450MCPU,内存4G,OS为Windows7。本实验采用从新浪微博采集的三个数据集进行实验,数据集的情感极性已经由人工分类,数据集的结构如表2与表3所示。表2实验数据集数据集用户数文档数正向情感负向情感Data11211000050005000Data2981000050005000Data31281000050005000表3数据集预处理前后对比情感分析准确率我们从Data1、Data2、Data3中分别抽取8个微博数据集,每个微博数据集分别包含1000篇微博,其中积极情感微博与消极情感微博分别为500篇,然后用SRTSM模型分别对每个微博集进行情感分析,结果如表4、5与6所示。表4Data1情感分析准确率JSTSLDADPLDASRTSM162.6259.9260.7166.26263.3460.9961.8367.73361.4158.2855.2464.95462.2759.8357.7869.33560.6758.7055.4564.76663.4162.1158.7365.49764.4361.3956.5366.30865.3460.3559.7368.90Avg62.9460.2058.2566.72表5Data2情感分析准确率JSTSLDADPLDASRTSM163.1561.4961.5566.09262.0361.8359.7465.13365.0762.3161.0366.41469.6164.6261.9171.73566.6765.4259.1369.54668.0863.461.7870.73764.168.2363.4469.5867.1864.9659.5868.12Avg65.7464.0361.0268.41表6Data3情感分析准确率JSTSLDADPLDASRTSM160.5263.757.7267.51258.2962.8659.2963.67362.0858.8461.4765.64461.7253.4555.7164.6556.7863.9458.6566.32663.456.6861.7465.19758.7555.9960.7563.39858.3557.561.8164.91Avg59.9959.1259.6465.15从表4、表5、表6可以看出,总的平均准确率SRTSM要高于JST、SLDA、DPLDA,这说明我们提出的SRTSM模型对于微博情感分析具有更好的性能。对于Data1和Data2,JST的准确率要高于SLDA与DPLDA,SLDA略高于DPLDA,对于Data3,JST的准确率高于SLDA和DPLDA,与Data1和Data2不同,对于Data3,DPLDA的情感分析准确率略高于SLDA。从表中还可以看出,SRTSM对Data2的情感分析性能最强,其次是Data1,最后是Data3。从各个微博集来看,SRTSM的准确率也都要高于其他三种模型。从上述分析可知,对于现有的LDA主题情感模型,SRTSM模型可以较好地提高微博情感分析的准确率。用户关系对准确率的影响我们分别将三个数据集中互相关注的用户比例数定为10%-90%,以此进行用户关系对准确率的影响实验,互相关注的用户比例数的计算方法如公式(10)所示,其中Ratio表示互相关注的用户比例数,UR为互相关注的用户数,U为总用户数。实验结果如图3所示。Ratio=UR/(U*(U-1)/2(10)从图3可以看出,虽然随着互相关注用户比例的上升,微博情感分析准确率有提升也有降低,但是总体趋势是提升的。从Data1的曲线可以看出,相对于用户比例为50%与70%时,准确率在用户比例为60%与80%时有所降低。除此之外,随着比例的提高,微博情感分析准确率呈上升趋势,在50%处达到准确率最大值。对于Data2来说,用户比例为20%时的准确率比用户比例为10%时低,其余都是呈上升趋势,在90%处达到最大值。从Data3的曲线可以看出,当用户比例为30%、60%与90%时,准确率分别比20%、50%与80%时要低,其余准确率都呈上升趋势,在80%处达到最大值。SRTSM对Data2的情感分析性能最好,其次是Data1,SRTSM对Data3的情感分析性能相对较差。从上述分析可以得出,微博用户关系对准确率的影响较大,当互相关注的用户比例较大时,微博情感分析准确率也较高,所以微博用户关系有助于提高微博情感分析的准确率。从上述分析可以得出,微博用户关系对准确率的影响较大,当互相关注的用户比例较大时,微博情感分析准确率也较高,所以微博用户关系有助于提高微博情感分析的准确率。主题提取本实验用SRTSM分别对Data1、Data2与Data3进行主题提取并且列出积极情感与消极情感出现概率最高的15个主题词,结果如表7所示。表7数据集主题词Data1的积极情感主题词中包含“喜欢”、“好看”、“可爱”、“好玩”等积极情感极性较强的词语,从“泡面”、“抽奖”、“手机”等可以看出,这可能是一个讨论抽奖的主题,用户应该是抽中了手机、泡面等奖品,因此表示自己喜悦的心情。Data1的消极情感主题词中出现的“苦恼”、“烦躁”等词较明显地展示了用户消极的情感,“天气”,“孩子”等词表达了用户对天气不好而造成孩子生病的抱怨。从Data2的积极情感主题词可以看出,“谢谢”、“有趣”、“支持”等词具有较强的积极情感色彩,“湖南卫视”、“节目”、“游戏”等词可能说明用户们正在谈论湖南卫视的一档节目,对该节目某个环节的游戏或其他表示了支持,“电视剧”、“搞笑”等词表示用户可能正在讨论一部搞笑的电视剧。而Data2消极情感主题词中的“难过”、“麻烦”、“不爽”具有较强的消极情感色彩,其中“付费”、“音乐”、“流行”等词也许是在谈论某些流行歌曲需要付费,用户对此表达了自己的不满。Data3积极情感主题词中出现了“恭喜”、“谢谢”、“快乐”、“喜欢”、“漂亮”,这些词具有较强的积极情感极性,“生日”、“礼物”、“聚会”、“唱歌”等向我们展示了一幅庆祝生日的场景,表示用户们可能在谈论一场生日会或者是帮某人过生日。Data3消极情感主题词中“害怕”、“难受”具有较强消极情感极性,从“好像”、“燃烧”、“肚子”中可以看出,该主题应该是对于肚子疼或其他类似主题的探讨,而这样的主题通常是消极情感的。从上述分析可以得出,SRTSM模型可以较好地提取出微博的主题词,能为微博主题分析提供很好的帮助。以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1