一种基于深度神经网络的实体关系抽取方法与流程
本发明涉及机器学习与自然语言处理,具体涉及一种基于深度神经网络的实体关系抽取方法。
背景技术:
类人智能发展迅速,已有相应产品应用于教育、医疗等行业,如针对初等教育考试问题的日本Todai Robot项目和致力于智力问答并拓展到医疗领域的美国IBH的Waston项目。在国内,以“文综”为代表的基础教育资源,蕴含了丰富的知识,完备和高质量的知识库决定类人智能问答系统的智能水平。
深度学习技术在图像领域和语音识别已经取得了重大的突破,在自然语言领域也已经如火如荼的发展。在这些深度学习方法中,包括普通多层神经网络、递归神经网络、长短期记忆神经网络以及卷积神经网络等等。其中卷积神经网络被成功应用于不同的自然语言处理任务中,如词性标注,情感分析,句子分类,语义角色标注,句子填空等,近些年也已经开始有学者将深度学习技术应用到关系分类。
目前,中文知识库构建还主要存在着非结构化文本利用率低、特定领域实体覆盖率较低、等问题,在知识库构建任务前的中文实体关系抽取任务中,关系类型体系不通用、中文语言特点复杂、中文关系抽取公开语料少、中文关系提取需要复杂的预处理等问题,加大了中文实体关系抽取的难度。
技术实现要素:
:
为了克服上述背景技术的缺陷,本发明提供一种基于深度神经网络的实体关系抽取方法,提高了实体关系抽取的准确率和性能。
为了解决上述技术问题本发明的所采用的技术方案为:
一种基于深度神经网络的实体关系抽取方法,包括:
步骤1,将句子的每个字或类别关键词分别映射到字向量或类别向量;
步骤2,根据字向量和类别向量对句子进行特征提取;
步骤3,将步骤2所提取的特征首尾相接输入全连接分类层,即得到抽取结果。
较佳地,步骤1是采用无标注语料训练获取字向量或类别向量。
较佳地,步骤2中进行特征提取包括:进行字特征的提取、进行句子特征的提取和进行类别特征的提取。
较佳地,进行字特征提取的方法包括:
采用滑动窗口机制获取字特征神经网络输入向量,将滑动窗口内的向量首尾相接,既得字特征。
较佳地,字特征神经网络的输入向量包括目标字,以及以目标字为中心的相邻距离小于等于k/2的字的字向量,k为滑动窗口的大小。
较佳地,进行句子特征提取的方法包括:将句子的每个字映射到字向量,对用字向量表示的句子进行卷积运算,对卷积运算的结果进行池化运算得到句子特征。
较佳地,对用字向量表示的句子进行卷积运算,具体是指:用数个卷积核对用字向量表示的句子进行卷积运算,得到数个向量集,向量集的个数与卷积核的个数相同。
较佳地,对卷积运算的结果进行池化运算得到句子特征,具体是指:将卷积运算所得数个向量集分别作为一个池化区域,获取各个池化区域的最大值,将各个最大值首尾相连,即得到句子特征。
较佳地,进行类别特征提取的方法包括:
使用普通神经网络依据类别关键词数据库,从句子中抽取类别关键词或代表类别关键词的字词,类别关键词和代表类别关键词的字词的集合即为类别特征。
较佳地,还包括对抽取结果进行验证评测的步骤,验证评测具体是指:将抽取结果与人工标注结果进行对比,得到正确字数,将正确字数除以测试集的字数得到字标注准确率。
本发明的有益效果在于:本发明利用了机器学习中的普通神经网络与卷积神经网络进行文本的实体关系抽取,提高了实体关系抽取的准确率和性能,简化了实体关系抽取中的人工工作量。利用了预训练的字向量,提高了神经网络的收敛速度和准确率;引入句子特征与类别特征,使用卷积神经网络和普通神经网络进行提取,解决了长短句问题,提高了实体关系抽取的性能。
附图说明
图1为本发明实施例点的流程图,
图2为本发明实施例点的神经网络结构图,
图3为本发明实施字向量映射示意图,
图4为本发明实施字特征提取的神经网络示意图,
图5为本发明实施句子特征提取的神经网络示意图,
图6为本发明实施类别特征提取的神经网络示意图,
图7为本发明实施例点的对比评测结果图。
具体实施方式
下面结合附图和实施例对本发明做进一步的说明。
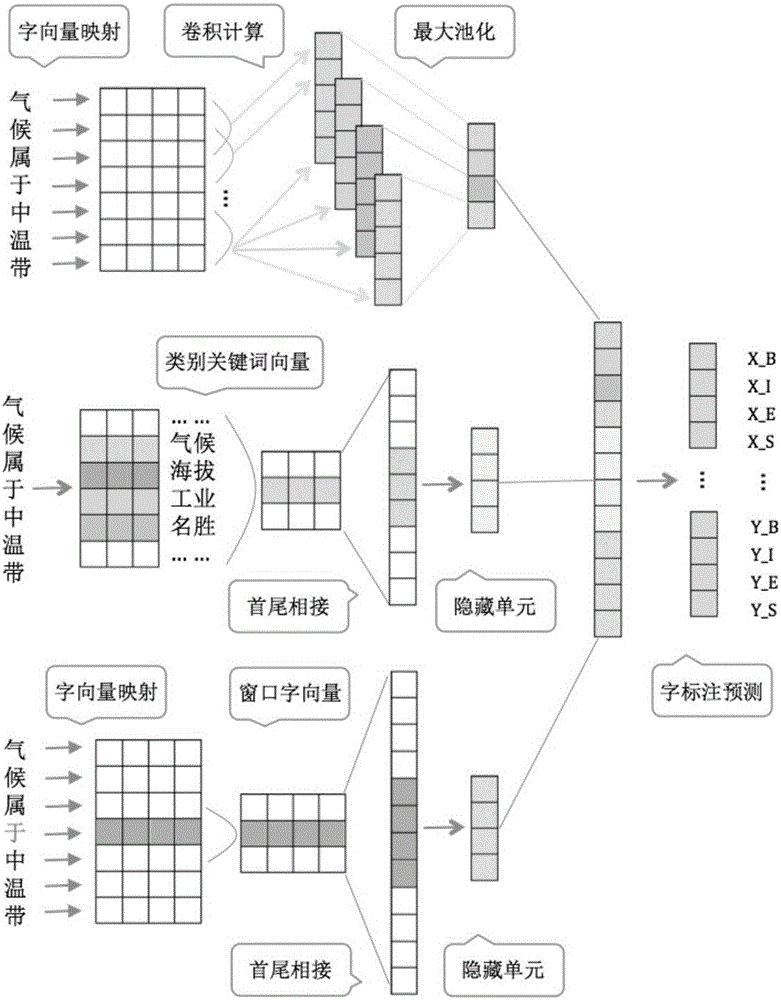
如图1所示,一种基于深度神经网络的实体关系抽取方法,该方法的神经网络结构图如图2所示,该方法包括:
步骤1,将句子的每个字或类别关键词分别映射到字向量或类别向量;
利用无标注语料训练得到具有语义信息的字向量,即利用一个大小为D的词典,句子序列{c1,c2,...cn}经过该层神经网络将被映射为一个实数向量序列{W1,W2,...Wn},其中Wn是字cn的字向量,如图3所示。本实施例使用了基于Hikolov的Word2Vec工具得到的预训练好的字向量。
利用无标注语料训练得到具有语义信息的类别关键词向量,类别关键词序列{kw1,kw2,kw3...kwn}经过该层神经网络将被映射为一个实数向量序列{KW1,KW2,KW3...KWn},其中KWn是字kwn的词向量,本实施例使用了基于Hikolov的Word2Vec工具得到的预训练好的词向量。
步骤2,根据字向量和类别向量对句子进行特征提取,进行特征提取包括进行字特征的提取、进行句子特征的提取和进行类别特征的提取。
步骤21,字特征提取:
字特征提取即局部特征提取,采用滑动窗口机制获取字特征神经网络输入向量,将滑动窗口内的向量首尾相接输入到隐藏层,隐藏层就是许多隐藏单元构成的一个层,如图4所示,提取字特征。字特征神经网络的输入向量包括目标字,以及以目标字为中心的相邻距离小于等于k/2的字的字向量,k为滑动窗口的大小;
步骤22,句子特征提取,即全局征提取,将句子的每个字映射到字向量,对用字向量表示的句子进行卷积运算,即使用卷积神经网络合并所有字向量,对卷积运算的结果进行池化运算得到句子特征,也即使用最大池化运算凸显句子主要的字特征,如图5所示,具体来说包括:
步骤221,将句子的每个字映射到字向量;
步骤222,对用字向量表示的句子进行卷积运算,用数个卷积核对用字向量表示的句子进行卷积运算,得到数个向量集,向量集的个数与卷积核的个数相同,
本实施例用H个卷积核K1,K2...Km(Km∈RD×k,D是字向量的维度,k是窗口的大小)对用字向量表示的句子进行卷积运算,得到H个向量集b1,b2...bm(bi∈R(D-k+1)×1);
步骤223,对卷积运算的结果进行池化运算得到句子特征,将卷积运算所得数个向量集分别作为一个池化区域,获取各个池化区域的最大值,将各个最大值首尾相连,即得到句子特征。
本实施例是将步骤221所得的H个向量集bi分别作为一个池化区域,得到H个池化区域,获取各个池化区域bi的最大值pi,将H个最大值pi首尾相连作为池化层的输出,即得到句子特征。
步骤23,类别特征提取:
使用普通神经网络依据类别关键词数据库,从句子中抽取类别关键词或代表类别关键词的字词,将其用向量表示,头尾相连后输入到隐藏层后提取类别特征,神经网络结构如图6所示。
步骤3,将步骤2所提取的特征首尾相接输入全连接分类层进行预测,得到每个字的标注,如图2中所示的X_B等,其中,X表示类别,B表示词的开始,I表示词的中间字,E表示词的结束,S表示单个字。即得到抽取结果。
步骤4,对抽取结果进行验证评测,验证评测的步骤包括:将抽取结果与人工标注结果进行对比,得到正确字数,将正确字数除以测试集的字数得到字标注准确率。
将三类特征首尾相接作为全连接分类层的输入,最后分类层来预测每个字的标注,并进行评判。因为我们预测的关系有多类,我们先计算每一类的F值、准确率和召回率,最后使用各种指标的加权平均值作为最后的性能评测标准,FAvg是将每一个关系类别的F值加权后求得平均值,Pavg是将每一个关系类别的准确率加权后求得平均值,RAvg是将每一个关系类别的召回率加权后求得平均值。其计算公式分别如下:
其中Ci为第i类的实例的个数,Fi为第i类的F值,Pi是第i类的准确率,Ri是第i类的召回率。
我们认为只有一个关系实例的全部字被模型预测的标注能组成一个完整的标注实例才加入“模型预测某类的实例数”的集合中,因此我们在每次得到最后的结果的时候就要统计被正确预测的字数、测试集中包含的所有的字数、被正确预测的关系字的字数和测试集中包含的关系字的字数。
统计被正确预测的字数和被正确预测的关系字的字数的方法为,将预测所得进行标注也即抽取结果与人工标注结果进行对比,得到被正确预测的字数和被正确预测的关系字的字数;为此针对关系抽取性能的评价增加了字标注准确率(PW)与关系字标注准确率(PR)两个评测标准:
对于本实施例,对不同的特征组合进行了对比实验,实验结果如图7所示,可以明显看出本发明的实体抽取效果较优,在各项性能评测上均取得了较好成绩。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!