一种基于图的关键词抽取方法与流程
本发明涉及一种关键词的提取方法,具体涉及一种基于图的关键词抽取方法。
背景技术:
关键词(Key Word)是反映文本内容特征的、起关键作用的词,关键词类型丰富,可以是普通名词,也可以是人名、地名、书籍名等。关键词抽取常见方法有:监督式学习模型和无监督式学习模型两大类。
早期的基于监督式学习的关键词抽取方法的主要任务是训练一个分类器判断候选词是否为关键词,基于这种思想的关键词抽取方法有:朴素贝叶斯(Naive Bayes)、决策树(decision trees)、Boosting算法、最大熵(Maximum Entropy)、支持向量机(support vector machines)等等。使用这些方法仅能得到关键词候选列表,其中的关键词都是同等重要的,但是事实上,不同的关键词具有不同的重要性(即权重),关键词抽取需要对关键词按重要程度进行排序,而不是仅仅给出关键词的列表,因此人们提出了一种基于排序机制的关键词抽取方法,该机制的核心是为候选关键词设计排序器,其基本思想是首先基于词汇识别候选关键词,计算每个候选关键词的特征值,然后根据机器学习方法预测哪些候选词是好的关键词,该方法在后来的基于监督式学习的关键词抽取研究中取得了不错的效果。基于监督式学习的关键词抽取的缺点是需要大量、高质量的标注语料,而标注语料需要大量的时间、人力和资金成本。
基于无监督学习的关键词抽取不需要标注语料,是当前主流的关键词抽取方法。目前基于无监督式学习的关键词抽取方法可以分为四大类:基于图排序、主题聚类、联合学习、语言模型。
基于图排序的关键词抽取:关键词抽取的核心是寻找文档中重要的词或者短语,通常而言,一个候选词重要性不仅与它的出现次数有关,还和它与文档中其他词的关系有关。基于图排序的关键词抽取的基本思想是:基于文本构建图,其中,节点(Node)是候选词,节点之间的边连接两个的候选词,通过节点权重或者边权重可以反映候选词的重要程度。通过图排序可以在没有标注语料的情况下得到候选词的权重排序表,可以选取排名靠前的N个词作为该文本的关键词。
基于主题聚类的关键词抽取:由于关键词通常与主题相关,因此一些研究者基于主题聚类研究关键词抽取方法,Grineva提出了基于CommunityCluter的关键词抽取方法,刘致远基于主题聚类原理提出了基于KeyCluster方法的关键词抽取方法以及基于Topical PagRank(TPR)的关键词抽取方法。
基于联合学习的关键词抽取:由于关键词能够反映文档的概要,所以有些研究者假定关键词抽取和自动文摘能够从对方获取更多信息,Zha提出了第一个基于图的能够同时进行自动文摘和关键词抽取的方法,Wan对Zha的工作进行了扩展,构建了三个图来获取句子(S)和词(W)之间的关系(三个图分别是S-S图、S-W图、W-W图),进而同时获得关键词和文档摘要。
基于语言模型的关键词抽取:之前的方法在关键词抽取/排序之前通过一些基于语言模型的方法抽取了候选关键词,Tomokiyo和Hurst提出了融合这两个步骤的方法,该方法基于短语性(Phraseness)和信息性(Informativeness)对候选关键词打分,通过前景语料库(Foreground corpus)和背景语料库(Background corpus)训练的语言模型估计短语性和信息性这两个特征值,进而得到文本的词的分值,最终选取高分值的词作为关键词。
技术实现要素:
本发明的目的在于提供一种基于图的关键词抽取方法,不需要标注语料,而且可以通过对TextRank算法基于候选词特征增加节点权重、基于词汇语义关系改进边权重可以以较低成本提高关键词抽取的准确率。
为了实现上述目的,发明提供了一种基于图的关键词抽取方法,该方法包括以下步骤:
对文本信息进行预处理,预处理包括分词处理、词性标注处理和命名实体识别处理;
计算节点特征,以及计算词汇的统计关系和词汇的语义关系;节点特征包括:节点的统计特征、位置特性、词性特征和实体特征;
根据节点特征计算节点权重,以及根据词汇的统计关系和词汇的语义关系计算边权重;
根据节点权重和边权重计算候选词的分值;
根据候选词的分值排序结果以及文本大小信息确定该文本的关键词。
优选地,在对文本信息进行预处理步骤之后,以及在计算节点特征步骤之前,还包括去停用词步骤。
本发明提供的一种基于图的关键词抽取方法,不需要标注语料,而且可以通过对TextRank算法基于候选词特征增加节点权重、基于词汇语义关系改进边权重可以以较低成本提高关键词抽取的准确率。
附图说明
图1为本发明实施例提供的基于图的关键词提取方法的Textrank原理图;
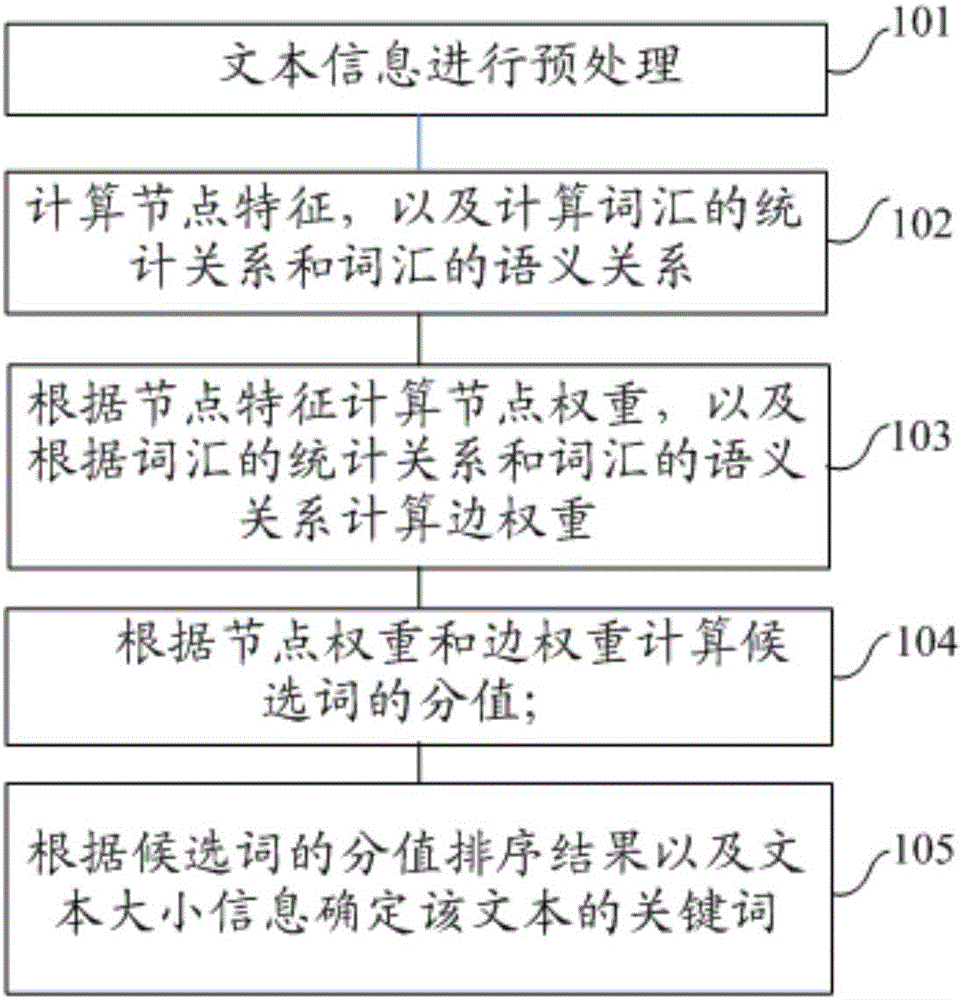
图2为本发明实施例提供的基于图的关键词提取方法流程图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案作进一步的详细描述。
图1为本发明实施例提供的基于图的关键词提取方法的Textrank原理图。
如图1所示,其中:节点表示词,边表示词与词之间的关系。对于基于图的关键词抽取方法而言,一个节点(词)的重要程度取决于连接到它的节点(词)投给它的票数。
将文本表示为一个加权有向图G=(V,E),其中,由点集合V和边集合E组成,E是V*V的子集。给图中的节点指定任意相同的初值,然后由公式1递归计算每个节点的分数到某个词语分数收敛,收敛后每个节点获得一个分数,代表该节点在图中的重要性,公式1是基于TextRank的候选词打分机制。
其中,wij表示两节点Vi和Vj之间边的权重;d为阻尼系数,取值范围为0到1,代表从图中某一特定点指向任意随机节点的概率,通常取值为0.85;Vj是距离Vi在窗口L中出现的词。
对于一个给定的节点Vi,In(Vi)为指向该点的点集合,Out(Vi)为点Vi指向的点集合。可见:是在窗口L内,Vi与Vj两个节点之间的边的权重,因此,公式(1)可以改写为公式(2)的形式,
Score(Vi)=(1-d)+d*EdgeJT(Vi,Vj)*Score(Vj) (2)
其中,EdgeTJ(Vi,Vj)为Vi与Vj两个节点在窗口L内的词汇统计关系。
将Vi称为被打分词、将Vj称为打分词,由公式2可见:对TextRank算法而言,被打分词的分值仅仅来源于与它相邻词的统计关系。
图2为本发明实施例提供的基于图的关键词提取方法流程图。
如图2所示,该方法的实现包括步骤101-105。
步骤101,对文本信息进行预处理,预处理包括分词处理、词性标注处理和命名实体识别处理;
步骤102,计算节点特征,以及计算词汇的统计关系和词汇的语义关系;节点特征包括:节点的统计特征、位置特性、词性特征和实体特征;其中,实体特征包括实体类型特征和命名实体链接特征。
根据节点的统计特征、位置特性、词性特征和实体特征判断一个词是否为关键词;
通过公式(3)计算基于TF*IDF的候选词统计特征:
Feature1(Vi)=TF(Vi)*IDF(Vi) (3)
Feature1(Vi)=TFi,j*IDFi
其中,词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的次数,ni,j是词Vi在文件j中的出现次数,而分母则是在文件j中所有字词的出现次数之和。
IDF(Inverse Document Frequency,IDF)是反文档频率,|D|是语料库中文档的总数,|j:{Vi∈dj}|是包含Vi的文档数;
通过公式(4)计算候选词的位置特征:
通过公式(5)计算候选词的词性特征:
通过公式(6)计算候选词的实体类型特征:
通过公式(7)计算候选词的实体特性:
计算词汇的统计关系和词汇的语义关系:
通过公式(8)计算词汇统计关系STJ(Vi,Vj):
其中,k为词Vi和Vj共现的窗口个数,L为窗口大小。
通过公式(9)计算词汇的语义关系SYY(Vi,Vj):
其中:βi(1≤i≤4)是可调节的参数,且有:β1+β2+β3+β4=1;
Sim1(Vi,Vj)为第一独立义原描述式,即两个义原的相似度,计算公式如下:
其中,Vi和Vj表示两个义原,d是Vi和Vj在义原层次体系中的路径长度,是一个正整数。α是一个可调节的参数;
Sim2(Vi,Vj)为其他独立义原描述式(除第一独立义原以外的所有其他独立义原),计算方法是,先把两个表达式的所有独立义原(第一个除外)任意配对,计算出所有可能的配对的义原相似度;取相似度最大的一对,并将它们归为一组;在剩下的独立义原的配对相似度中,取最大的一对,并归为一组,如此反复,直到所有独立义原都完成分组。
Sim3(Vi,Vj)为关系义原描述式(语义表达式中所有的用关系义原描述式),把关系义原相同的描述式分为一组,并计算其相似度。
Sim4(Vi,Vj)为符号义原描述式(语义表达式中所有的用符号义原描述式),符号义原描述式的配对分组与关系义原描述式类似,我们把关系符号相同的描述式分为一组,并计算其相似度。
步骤103,根据节点特征计算节点权重,以及根据词汇的统计关系和词汇的语义关系计算边权重。
通过公式(13)计算节点权重:
其中,Featurei为被打分词的特征,αki为被打分词Vi的第k个特征的系数,即不同的特征对被打分词的分值计算的贡献是不同的,Featurek(Vi)∈[0,1.1]。
通过公式(12)计算边的权重:
其中,β决定计算边权重时,侧重词汇统计关系STJ(Vi,Vj),或者词汇语义关系SYY(Vi,Vj),β可以设定为1、2或者1/2,β=1时则视二者一样重要。
步骤104,根据节点权重和边的权重计算候选词的分值;
通过公式(13)计算候选词的分值:
Score(Vi)=(1-d)*Node(Vi)+d*Node(Vi)*Edge(STJ(Vi,Vj),
SYY(Vi,Vj))*Score(Vj) (13)
其中,Node(Vi)是被打分词的权重,Edge(STJ(Vi,Vj),SYY(Vi,Vj))是被打分词和被打分词之间的边权重,它由两部分构成:STJ(Vi,Vj)是Vi与相邻词Vj在窗口L中的统计关系,SYY(Vi,Vj)是Vi与Vj的语义关系。
步骤105,根据候选词的分值排序结果以及文本大小信息确定该文本的关键词。
根据候选词的分值排序结果以及文本大小抽取Top N个分值最高的词作为该文本的关键词。
优选地,在对文本信息进行预处理步骤之后,以及在计算节点特征步骤之前,还包括去停用词步骤。
本发明实施例提供的一种基于图的关键词抽取方法,不需要标注语料,而且可以通过对TextRank算法基于候选词特征增加节点权重、基于词汇语义关系改进边权重可以以较低成本提高关键词抽取的准确率。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!