一种基于微博文本的人物性格刻画方法与流程
本发明属于数据挖掘领域,涉及用户画像技术,具体是一种基于微博文本的人物性格刻画方法。
背景技术:
随着网民规模的不断增大,社会化媒体也得到迅速发展。以论坛、微博、微信为代表的社会化媒体逐渐渗透到全民生活和工作的每一个层面,对人们的行为模式、心理模式产生了极为深远的影响。社会化媒体每天都会产生大量的短文本,在一定程度上反映人物的特征。通过刻画人物的特征,人们一方面可以了解社会化媒体中人物的个人偏好,根据个人偏好,企业通过社会化媒体给相关群体推荐产品,增加企业的效益。另一方面,人们可以了解社会化媒体中,针对某一事件的意见领袖、舆论煽动者,以及一些潜在的具有巨大影响力的用户的影响,这对政府相关部门的舆情监控有着非常重要的作用。
刻画人物性格是人物画像的一方面,对社会化媒体舆情监控、社会化媒体营销等方面有着重要的作用,已经成为当前研究的重点。
现有技术都是使用传统的实证研究方法来刻画人物性格,如问卷调查、访谈等。传统的实证研究需要投入大量的人力、物力、财力来分析人物性格,具有一定的局限性,主要体现在以下三个方面:1)传统的实证方法需要经过长时间的调查或访谈来采集数据;2)通过调查或访谈采集的数据的可用性较低,存在大量的无效数据;3)传统的调查研究无法保证所采集数据的真实性。
技术实现要素:
本发明针对舆情监控以及社会化营销对人物性格刻画的需求,为了解决传统调查研究带来的成本高、数据可用性低等困难,规避被调查者填写不真实信息的情况,借助当前普及的社会化媒体,提出了一种基于微博文本的人物性格刻画方法。
具体步骤如下:
步骤一、针对某个用户,利用情绪词典对该用户在某段时间内发的每一条微博文本标注情绪标签。
情绪词典包括高兴、生气、悲伤、厌恶和焦虑五种情绪。
首先,计算每一条微博文本属于某种情绪的权重w_sentiment;
计算如下:
w_s表示某条微博文本中的词语word在情绪词典中对应的权重;词语word是指情绪词典中某种情绪包括的具体体现词;count(word)表示该词语word在某条微博文本中出现的频数。
比较每一条微博文本在五类情绪下的权重,取权重最高的情绪作为该微博文本的情绪标签。
步骤二、根据情绪标签,统计该用户每天冲动类和抑郁类情绪的数量;
冲动类包括生气和厌恶两种情绪,抑郁类包括悲伤和焦虑两种情绪;
步骤三、根据该用户冲动类和抑郁类情绪的数量,计算该用户冲动类情绪的主导天数以及抑郁类情绪的主导天数;
步骤301、计算该用户冲动类和抑郁类情绪的微博数量之和,占该用户当天发的所有微博总数的比例;
步骤302、判断步骤301的占比是否大于等于阈值R,如果是,进入步骤303,否则,不做任何处理;
阈值R根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤303、将该用户冲动类情绪占比与抑郁类情绪的占比作差;
步骤304、判断得到的差值绝对值是否大于等于阈值M,如果是,进入步骤305;否则,不做任何处理;
阈值M根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤305、判断冲动类情绪占比是否大于抑郁类情绪占比,如果是,将该用户冲动类情绪的天数累加1天;否则,将该用户抑郁类情绪的天数累加1天。
步骤四、根据该用户冲动类情绪的主导天数以及抑郁类情绪的主导天数,从情绪特征角度对用户进行标记;
具体为:对于冲动类情绪主导天数大于抑郁类情绪主导天数的情况,判断冲动类情绪主导天数是否大于或等于阈值D,如果是,则标记该用户为“易冲动”;否则,标记该用户为“情绪稳定”;
阈值D根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
对于抑郁类情绪主导天数大于冲动类情绪主导天数的情况,判断抑郁类情绪主导天数是否大于或等于阈值D,如果是,则标记该用户为“易抑郁”,否则,则标记该用户为“情绪稳定”。
当冲动类情绪主导天数等于抑郁类情绪主导天数,标记该用户为“情绪稳定”。
步骤五、利用话题词典对该用户的所有微博文本进行关注话题分类,并选择该用户的关注话题;
话题词典有政治类、民生类、军事类、娱乐类和体育类。
首先,计算用户的微博文本所涉及各种类型的话题的权重公式w_topic,如下:
w_t表示某个用户在某段时间内发布的所有微博文本中的词语word在话题词典中对应的权重;
针对某个用户,分别计算该用户在某段时间内发布的所有微博涉及的五种话题的权重,然后,对五种话题的权重进行排序,取权重较高的前N个话题作为该用户微博文本所关注的话题;N大于等于1,小于等于3。
步骤六、判断该用户选取的关注话题中,是否包括政治类和民生类,如果有,利用批判性词典对该用户进行语言特征刻画;否则,不做任何处理。
批判性词典包括的词语为表达讽刺、批评语气的词语。
具体为:统计该用户在某段时间内发布的所有微博文本,计算微博文本中出现的批判性词典中包括的词语,判断出现不同词语的个数是否大于或等于阈值K,如果是,将该用户标记为“批判型”,否则,将用户标记为“其他”。
阈值K根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤七、融合该用户的情绪特征和语言特征刻画该用户的性格,得到该用户的人物性格标签;
具体融合方法如下:
最终得到的人物性格标签有“急躁型”、“悲观型”、“批判型”、“冲动型”、“抑郁型”和“稳定型”。
本发明的优点是:
1)、一种基于微博文本的人物性格刻画方法,适用于对微博中人物性格特征刻画和分析,在舆情监控、人物属性刻画和信息传播扩散等领域有重要的应用价值。
2)、一种基于微博文本的人物性格刻画方法,具有高效性和易用性,能够对千级规模的人物进行性格刻画。
3)、一种基于微博文本的人物性格刻画方法,能降低传统调查研究在人力、物力、财力等方面的成本,而且能较好地规避调查信息不真实的情况。
附图说明
图1为本发明基于微博文本的人物性格刻画方法的流程图;
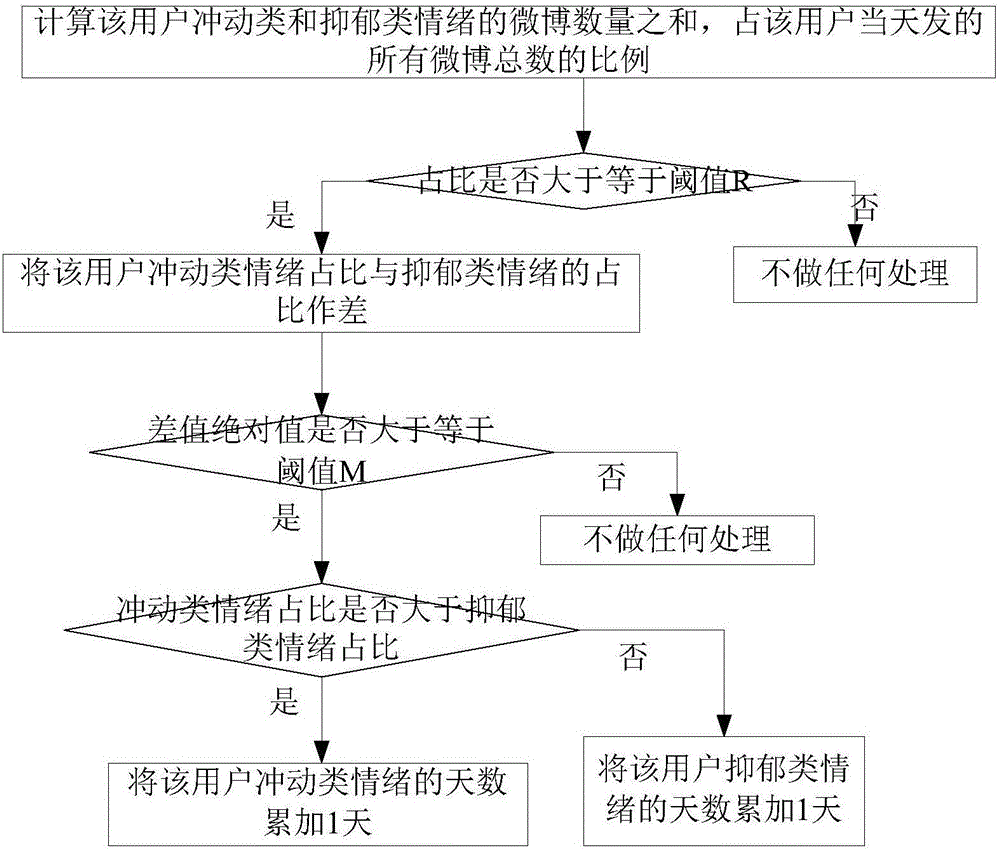
图2是本发明计算用户冲动类情绪以及抑郁类情绪的主导天数的流程图。
具体实施方式
下面将结合附图对本发明作进一步的详细说明。
本发明研究基于微博文本的人物性格刻画的用户画像技术,考虑微博中人们的用语和用词习惯,建立情绪和话题的词典,从情绪和语言两个角度对人物的性格特征进行刻画,再融合这两个角度的特征得到人物的性格特征。首先对微博文本进行情绪分类,以天为单位统计情绪的数量和波动特征,再根据这些特征从情绪角度刻画人物性格。与此同时,根据话题词典对人物的微博文本进行话题分类,选取关注政治类和民生类话题的用户;利用词典对关注政治类和民生类话题的人物进行语言特征的分析,以此刻画人物性格。最后,综合情绪和语言角度得到的性格,对人物的总体性格特征进行刻画。
如图1所示,具体实施步骤如下:
步骤一、针对某个用户,利用情绪词典对该用户在某段时间内发的每一条微博文本标注情绪标签。
情绪词典主要包括高兴、生气、悲伤、厌恶和焦虑五种情绪。根据词典对微博文本进行情绪分类,主要是通过计算每一条微博文本属于上述五类情绪的权重。该权重是某类情绪出现在文本中词语的权重总和,每一条微博文本属于某类情绪的权重w_sentiment,计算公式如下所示:
其中,w_s表示某条微博文本中的词语word在情绪词典中对应的权重,count(word)表示词语word在某条微博文本中出现的频数。
例如:表示高兴情绪的词语有:哈哈,呵呵,嘻嘻,开心等;
针对某条微博,根据“哈哈”在情绪词典中对应的权重w_s,与“哈哈”在该微博文本中出现的频数相乘,同理分别计算“呵呵”“嘻嘻”和“开心”等词,将每个词语权重与频数的乘积再相加,最终得到该微博文本属于高兴情绪的权重;
最后,比较每一条微博文本在这五类情绪下的权重,取权重最高的情绪作为该微博文本的情绪标签。
本步骤的伪代码如下所示:
for weibo_text in所有微博:
for sentiment_type in[高兴,生气,悲伤,厌恶,焦虑]:
total_weight=∑w*count(word)
sentiment_type=max(total_weight);
步骤二、根据情绪标签,统计该用户每天冲动类和抑郁类情绪的数量;
根据上一步骤情绪分类的结果,按人和时间为组织单位,计算每人每天冲动类和抑郁类情绪的数量;冲动类包括生气和厌恶两种情绪,抑郁类包括悲伤和焦虑两种情绪。
步骤三、根据该用户冲动类和抑郁类的数量,计算该用户冲动类情绪的主导天数以及抑郁类情绪的主导天数;
根据上一步骤统计的结果,比较冲动类和抑郁类情绪的数量,按人按天比较情绪的数量和波动性。
首先,比较冲动类和抑郁类情绪的数量之和与其他情绪的数量,用冲动类和抑郁类情绪的微博数量和该用户当天所发的微博总数之比来衡量。本步骤中设置一个阈值R,对于占比大于或等于阈值R的情况,再计算冲动类情绪和抑郁类情绪的数量占比的差值,如果该差值大于或等于阈值M,若冲动类情绪数量大于抑郁类情绪数量,则该用户冲动类情绪的天数累加1天,若抑郁类情绪数量大于冲动类情绪数量,则该用户抑郁类情绪的天数累加1天。如果占比小于阈值R或冲动类和抑郁类情绪数量差值小于阈值M,则不做任何处理。
如图2所示,具体步骤如下:
步骤301、计算该用户冲动类和抑郁类情绪的微博数量之和,占该用户当天发的所有微博总数的比例;
步骤302、判断步骤301的占比是否大于等于阈值R,如果是,进入步骤303,否则,不做任何处理;
阈值R根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤303、将该用户冲动类情绪占比与抑郁类情绪的占比作差;
步骤304、判断得到的差值绝对值是否大于等于阈值M,如果是,进入步骤305;否则,不做任何处理;
阈值M根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤305、判断冲动类情绪占比是否大于抑郁类情绪占比,如果是,将该用户冲动类情绪的天数累加1天;否则,将该用户抑郁类情绪的天数累加1天。
步骤四、根据该用户冲动类情绪的主导天数以及抑郁类情绪的主导天数,从情绪特征角度对用户进行标记;
根据上一步骤计算出的结果,每一个用户都有两个特征值:一个是冲动类情绪主导天数,另一个是抑郁类情绪主导天数;根据情绪特征进行情绪类性格刻画。
本步骤中设置一个天数阈值D,对于冲动类情绪主导天数大于抑郁类情绪主导天数的情况,如果冲动类情绪主导天数大于或等于阈值D,则标记该用户为“易冲动”,否则,冲动类情绪主导天数小于阈值D,标记该用户为“情绪稳定”;
对于抑郁类情绪主导天数大于冲动类情绪主导天数的情况,如果抑郁类情绪主导天数大于或等于阈值D,则标记该用户为“易抑郁”,否则,如果抑郁类情绪主导天数小于阈值D,则标记该用户为“情绪稳定”。
当冲动类情绪主导天数等于抑郁类情绪主导天数,标记该用户为“情绪稳定”。
本步骤从情绪特征角度将每个用户分为“易冲动”、“易抑郁”和“情绪稳定”三种性格特征。
步骤五、利用话题词典对该用户的所有微博文本进行关注话题分类,并选择该用户的关注话题;
根据话题词典对关注话题分类:政治类、民生类、军事类、娱乐类和体育类。
以用户为单位,统计该用户微博文本中出现的各类关注话题的词语;
每个用户关注各种类型的话题的权重w_topic计算公式如下:
w_t表示某个用户在某段时间内发布的所有微博文本中的词语word在话题词典中对应的权重;
例如:表示民生类的词语有:衣、食、住、行、就业、娱乐、家庭、社团、公司、旅游等;
针对某个用户在某段时间内发布的所有微博,根据“衣”在话题词典中对应的权重w_s,与在所有微博文本中出现的频数相乘,同理分别计算其他词语的权重与频数的乘积,最后将所有乘积相加,得到民生类话题的权重;
针对某个用户,对计算出的五类话题权重进行排序,取权重较高的前N个话题类别作为该用户的关注话题;N大于等于1,小于等于3。
步骤六、判断该用户选取的关注话题中,是否包括政治类和民生类,如果有,利用批判性词典对该用户进行语言特征刻画;否则,不做任何处理。
批判性词典包括的词语为:我晕、糊涂、无耻等表达讽刺、批评语气的词语。
根据上一步骤的结果,选出关注政治类、民生类的微博用户,利用批判性词典对该用户进行语言特征的分析。具体为:统计该用户在某段时间内发布的所有微博文本,计算微博文本中出现的批判性词典中包括的不同词语的数量,判断出现不同词语的数量是否大于或等于阈值K,如果是,将该用户标记为“批判型”,否则,将出现不同词语数量小于阈值K的用户标记为“其他”。
例如:某段微博文本出现了2次“我晕”,3次“糊涂”和1次“无耻”,则该段微博文本出现不同的词语数为3个;
阈值K根据专家经验设定,或者根据微博文本数据的统计数量得到的经验值。
步骤七:融合该用户的情绪特征和语言特征刻画该用户的性格,得到该用户的人物性格标签;
本步骤是将根据情绪特征和语言特征刻画的人物性格结果进行融合。采用的组合方法如下表所示。
最终得到的人物性格标签有“急躁型”、“悲观型”、“批判型”、“冲动型”、“抑郁型”、“稳定型”。
本发明鉴于微博文本的口语化、实时性等特征,利用通过微博文本学习得到的词典,对人物所发的微博文本进行情绪分类,并根据情绪数量和波动特征对人物性格进行刻画。同时,对人物关注的话题进行划分,并根据人物关注的话题对人物性格进行刻画。最后,融合情绪特征和语言特征两个维度的结果刻画人物性格。考虑人物在微博文本中的用语习惯,从词典角度出发,考虑人物的情绪和关注的话题,对千级规模的人物进行性格刻画,具有高效性、鲁棒性和易用性等特点。
- 还没有人留言评论。精彩留言会获得点赞!