一种基于KVM云平台的分布式数据库系统实现自动伸缩负载均衡的方法与流程
本发明涉及一种基于KVM云平台的分布式数据库系统实现自动伸缩负载均衡的方法,属于云计算技术领域。
背景技术:
KVM,Kernel-based Virtual Machine的简称,是一个开源的系统虚拟化模块,自Linux 2.6.20之后集成在Linux的各个主要发行版本中。它使用Linux自身的调度器进行管理,所以相对于Xen,其核心源码很少。KVM目前已成为学术界的主流VMM之一。
云计算平台因其成本、性能上的优点和其特有的按需分配的特性正在广泛替代传统的IT服务服务器架构,从传统的信息服务平台到分布式计算、大数据挖掘、机器学习等领域,在节省了大量硬件成本和人工成本的同时,由于其灵活的调度特性,为各种弹性分布式系统提供了基础平台。
基于关系型数据的电子商务系统、交易系统等常见系统由于对数据库特殊性能需求,使得关系型数据库短时间内无法被其他类型数据库有效替代,由于数据量的处理要求不断增长,对传统的关系型数据库的承载能力也提出了更高的要求,传统单点关系型数据库性能受制于电子硬件性能发展,无法短时间内在性能上有长足提升,因此,分布式的关系型数据库也成为了人们广泛关注的对象。
技术实现要素:
针对现有技术的不足,本发明提供了一种基于KVM云平台的分布式数据库系统实现自动伸缩负载均衡的方法;
本发明构建一个高性能的分布式关系型数据库,可以在集群能在不间断提供服务而且保持数据一致性的情况下进行自动伸缩以实现负载的自动均衡,直接降低了数据库因负载过高而宕机的可能性。
本发明的技术方案为:
一种基于KVM云平台的分布式数据库系统实现自动伸缩负载均衡的方法,所述分布式数据库系统为一个KVM集群,包括一个MON进程、若干个KVM集群服务器、GUESTAgent用户进程,所述GUESTAgent用户进程分别连接所述MON进程及所述若干个KVM集群服务器,所述MON进程分别连接所述若干个KVM集群服务器;
所述若干个KVM集群服务器具有相同的网络环境并配置libvirt开发接口,KVM集群服务器中运行若干个数据库服务器节点,每个数据库服务器节点具有相同的数据库软件环境和运行TaskAgent进程;所述MON进程根据需要运行在所述KVM集群服务器上;GUESTAgent用户进程根据需要运行在数据库服务器节点或KVM集群服务器上,用于对数据库中的数据进行增删改查操作,所述分布式数据库系统设置Timer时间段的负载阈值,包括Timer时间段的阈值上限及Timer时间段的阈值下限;具体步骤包括:
(1)每个数据库服务器节点自我监控CPU使用量,当在Timer时间段内,CPU使用量的峰值的均值大于或等于设置的Timer时间段的阈值上限时,进入步骤(2),CPU使用量的峰值的均值小于或等于设置的Timer时间段的阈值下限时,进入步骤(3);
(2)向MON进程发送卸载负载请求,MON进程接收到此请求,通过libvirt开发接口向KVM集群的服务器节点发送创建新的数据库服务器节点请求,新数据库服务器节点被创建启动后运行自启动脚本和服务,向MON进程发送加入所述KVM集群请求,MON进程将此数据库服务器节点加入集群并将之前申请卸负载数据库服务器节点所分配的任务取一半给新加入数据库服务器节点,同时向所有GUESTAgent用户进程和新加入数据库服务器节点发送数据同步信号,进入数据同步流程,数据同步完成后,所述KVM集群进入正常工作状态,集群扩张完成;
(3)向MON进程发送增加负载请求,MON进程在接收到两个增加负载请求时,将第二个申请增加负载请求的数据库服务器节点的任务合并至第一个申请增加负载请求的数据库服务器节点中,同时向所有GUESTAgent用户进程和第一个申请增加负载请求的数据库服务器节点发送数据同步信号,进入数据同步流程,数据同步完成后,所述KVM集群进入正常工作状态,集群扩张完成。
根据本发明优选的,所述数据同步流程,具体步骤包括:
a、数据库服务器节点向MON进程中的任务调度器发送注册请求;
b、MON进程获取注册请求后,锁定数据库服务器节点和GUESTAgent用户进程添加数据行为;在迁移期间,不允许新的数据库服务器节点和GUESTAgent用户进程进行注册。
c、按照一致性哈希算法为步骤b所述数据库服务器节点分配哈希索引范围,所述数据库服务器节点进入预备状态,同时向其它所有的GUESTAgent用户进程发出更新所述KVM集群的信号,发送新集群任务分配表;
d、其它所有的GUESTAgent用户进程在收到更新所述KVM集群的信号后,尝试连接所述数据库服务器节点,并检测所述数据库服务器节点的数据库结构,如果成功,其它的GUESTAgent用户进程进入预备状态,并向MON进程返回确认信息;在预备状态中,其它的GUESTAgent用户进程所有的查询、更新、删除和插入动作都按照原哈希索引范围进行;同时在预备状态中,如果某条操作语句的哈希索引在所述数据库服务器节点的哈希索引范围内,则将所述操作语句发送至所述数据库服务器节点中的任务代理进程,任务代理将此条语句添加进自己的任务队列;
e、MON进程接收到其它所有的GUESTAgent用户进程的确认信息后,向所述数据库服务器节点发送同步数据启动指令;
f、所述数据库服务器节点获取同步数据启动指令,根据新集群任务分配表中被分配的任务范围,开始定位数据,读取数据,并写入所述数据库服务器节点中的本地数据库中;
g、执行完步骤f后,执行所述数据库服务器节点中的任务代理中任务队列内的操作语句;
h、执行完步骤g后,向MON进程发送数据同步信号,此时在接收其它所有的GUESTAgent用户进程的语句并执行的同时,向对应的其它所有的GUESTAgent用户进程返回数据同步完毕信号;
i、其它所有的GUESTAgent用户进程接收到同步完毕信号后,将原集群任务分配表抛弃,此后按照新新集群任务分配表执行;
j、MON进程获取同步完毕信号,放开数据库服务器节点和用户进程GUESTAgent添加数据行为,允许新GUESTAgent用户进程加入,整个数据同步流程完毕。
所述分布式数据库系统采用一致性哈希分库分表算法,具体的步骤包括:
数据库建立时,输入数据库所需要的数据表名称,数据库系统对此数据表进行子表建立,子表数量为TableNum,形成表_01至表_TableNum的数据表结构;
数据表建立时,要求规定主键名称,该主键名称存入MON进程中的DB_KEY序列之中。
所述分布式数据库系统在对数据进行操作之前,要对数据操作语句进行语义分析,具体的操作步骤为:
Ⅰ、对数据操作语句进行关键词过滤,获取是否有DB_KEY序列中已经存储的主键名称,如果没有,进入步骤Ⅱ;如果有,进入步骤Ⅲ;
Ⅱ、采用下发任务的机制进行分布式操作,以提高系统效率,具体的步骤为:GUESTAgent用户进程将读取数据操作语句的内部维护的NodeMap数据,所述NodeMap数据为多对数据,每对数据为数据库服务器地址及其对应的哈希索引范围,获取数据库服务器地址,并将此数据操作语句发送至每个数据库服务器节点中,每个数据库服务器节点获取到该指令,则进行则执行该指令并将指令执行结果返回;
Ⅲ、通过语义分析将该数据操作语句分拆为具有层级结构的原子语句,通过对原子语句进行语句过滤,过滤出该数据操作语句中的主键名称对应的值,对主键名称对应的值进行哈希计算,获得哈希值,然后对此哈希值对TableNum取模,获得的结果作为哈希索引HashIndex,将哈希索引HashIndex从NodeMap数据中进行查询,获取对应的数据库服务节点地址,GUESTAgent用户进程对该数据库服务节点直接连接,并执行该数据操作语句,至此,完成了数据的定位和操作。
本发明的有益效果为:
本发明构建一个高性能的分布式关系型数据库,可以在集群能在不间断提供服务而且保持数据一致性的情况下进行自动伸缩以实现负载的自动均衡,直接降低了数据库因负载过高而宕机的可能性。同时,由于其可伸缩的特性,可以灵活根据数据库用户的需求动态调整数据库集群的吞吐性能,可以承受突发性的大量数据吞吐要求;此外,由于灵活的性能调整特性,为云平台提供了一种可以更加灵活的云数据库服务方式,即按照实际数据吞吐性能来提供云数据库服务。
附图说明
图1为本发明所述分布式数据库系统;
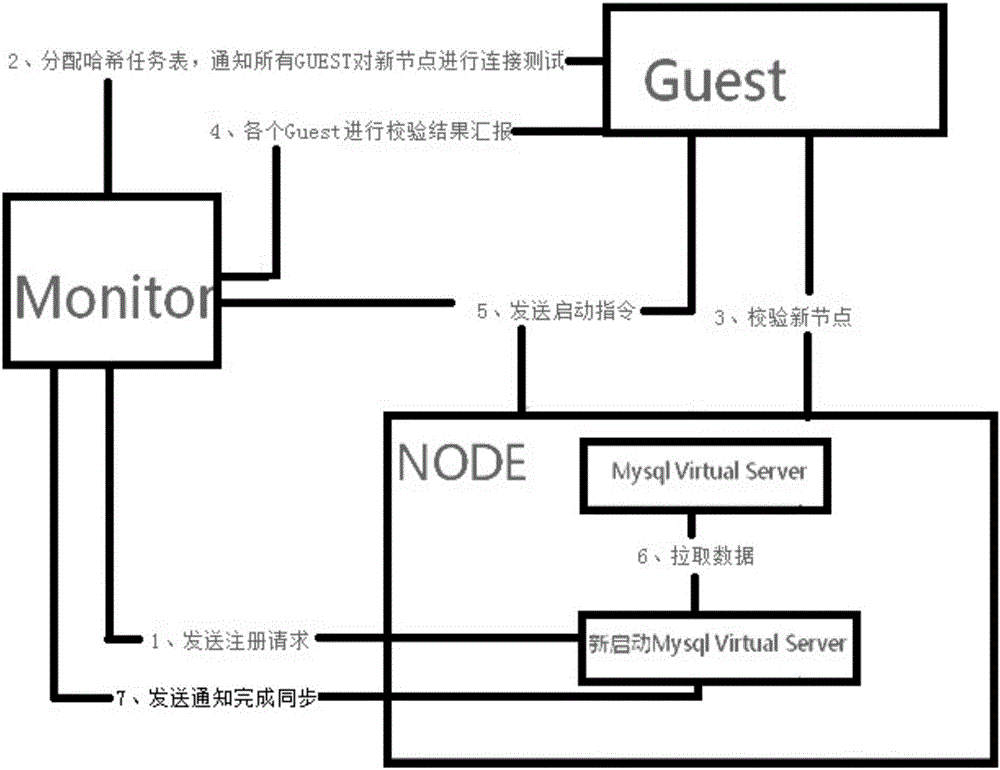
图2为本发明数据同步流程示意图;
图1、图2中,Monitor为MON进程;
Status Monitor为状态监控器进程;
Cluster Controller为服务器管理进程;
Guest为GUESTAgent用户进程;
Query processor为数据操作语句处理进程;
Result processor数据操作结果处理进程;
Task Distributor为数据操作语句分发进程;
NODE为KVM集群服务器;
Mysal Virtual Server为数据库服务器节点;
task Agent为Task Agent进程。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例
一种基于KVM云平台的分布式数据库系统实现自动伸缩负载均衡的方法,所述分布式数据库系统为一个KVM集群,包括一个MON进程、若干个KVM集群服务器、GUESTAgent用户进程,所述GUESTAgent用户进程分别连接所述MON进程及所述若干个KVM集群服务器,所述MON进程分别连接所述若干个KVM集群服务器;如图1所示;
所述若干个KVM集群服务器具有相同的网络环境并配置libvirt开发接口,KVM集群服务器中运行若干个数据库服务器节点,每个数据库服务器节点具有相同的数据库软件环境和运行TaskAgent进程;所述MON进程根据需要运行在所述KVM集群服务器上;GUESTAgent用户进程根据需要运行在数据库服务器节点或KVM集群服务器上,用于对数据库中的数据进行增删改查操作,所述分布式数据库系统设置Timer时间段的负载阈值,包括Timer时间段的阈值上限及Timer时间段的阈值下限;具体步骤包括:
(1)每个数据库服务器节点自我监控CPU使用量,当在Timer时间段内,CPU使用量的峰值的均值大于或等于设置的Timer时间段的阈值上限时,进入步骤(2),CPU使用量的峰值的均值小于或等于设置的Timer时间段的阈值下限时,进入步骤(3);
(2)向MON进程发送卸载负载请求,MON进程接收到此请求,通过libvirt开发接口向KVM集群的服务器节点发送创建新的数据库服务器节点请求,数据库服务器节点被创建启动后运行自启动脚本和服务,向MON进程发送加入所述KVM集群请求,MON进程将此数据库服务器节点加入集群并将之前申请卸负载数据库服务器节点所分配的任务取一半给新加入数据库服务器节点,同时向所有GUESTAgent用户进程和新加入数据库服务器节点发送数据同步信号,进入数据同步流程,数据同步完成后,所述KVM集群进入正常工作状态,集群扩张完成;
(3)向MON进程发送增加负载请求,MON进程在接收到两个增加负载请求时,将第二个申请增加负载请求的数据库服务器节点的任务合并至第一个申请增加负载请求的数据库服务器节点中,同时向所有GUESTAgent用户进程和第一个申请增加负载请求的数据库服务器节点发送数据同步信号,进入数据同步流程,数据同步完成后,所述KVM集群进入正常工作状态,集群扩张完成。
所述数据同步流程,如图2所示,具体步骤包括:
a、数据库服务器节点向MON进程中的任务调度器发送注册请求;
b、MON进程获取注册请求后,锁定数据库服务器节点和GUESTAgent用户进程添加数据行为;在迁移期间,不允许新的数据库服务器节点和GUESTAgent用户进程进行注册。
c、按照一致性哈希算法为步骤b所述数据库服务器节点分配哈希索引范围,所述数据库服务器节点进入预备状态,同时向其它所有的GUESTAgent用户进程发出更新所述KVM集群的信号,发送新集群任务分配表;
d、其它所有的GUESTAgent用户进程在收到更新所述KVM集群的信号后,尝试连接所述数据库服务器节点,并检测所述数据库服务器节点的数据库结构,如果成功,其它的GUESTAgent用户进程进入预备状态,并向MON进程返回确认信息;在预备状态中,其它的GUESTAgent用户进程所有的查询、更新、删除和插入动作都按照原哈希索引范围进行;同时在预备状态中,如果某条操作语句的哈希索引在所述数据库服务器节点的哈希索引范围内,则将所述操作语句发送至所述数据库服务器节点中的任务代理进程,任务代理将此条语句添加进自己的任务队列;
e、MON进程接收到其它所有的GUESTAgent用户进程的确认信息后,向所述数据库服务器节点发送同步数据启动指令;
f、所述数据库服务器节点获取同步数据启动指令,根据新集群任务分配表中被分配的任务范围,开始定位数据,读取数据,并写入所述数据库服务器节点中的本地数据库中;
g、执行完步骤f后,执行所述数据库服务器节点中的任务代理中任务队列内的操作语句;
h、执行完步骤g后,向MON进程发送数据同步信号,此时在接收其它所有的GUESTAgent用户进程的语句并执行的同时,向对应的其它所有的GUESTAgent用户进程返回数据同步完毕信号;
i、其它所有的GUESTAgent用户进程接收到同步完毕信号后,将原集群任务分配表抛弃,此后按照新新集群任务分配表执行;
j、MON进程获取同步完毕信号,放开数据库服务器节点和用户进程GUESTAgent添加数据行为,允许新GUESTAgent用户进程加入,整个数据同步流程完毕。
所述分布式数据库系统采用一致性哈希分库分表算法,具体的步骤包括:
数据库建立时,输入数据库所需要的数据表名称,数据库系统对此数据表进行子表建立,子表数量为TableNum,形成表_01至表_TableNum的数据表结构;
数据表建立时,要求规定主键名称,该主键名称存入MON进程中的DB_KEY序列之中。
所述分布式数据库系统在对数据进行操作之前,要对数据操作语句进行语义分析,具体的操作步骤为:
Ⅰ、对数据操作语句进行关键词过滤,获取是否有DB_KEY序列中已经存储的主键名称,如果没有,进入步骤Ⅱ;如果有,进入步骤Ⅲ;
Ⅱ、采用下发任务的机制进行分布式操作,以提高系统效率,具体的步骤为:GUESTAgent用户进程将读取数据操作语句的内部维护的NodeMap数据,所述NodeMap数据为多对数据,每对数据为数据库服务器地址及其对应的哈希索引范围,获取数据库服务器地址,并将此数据操作语句发送至每个数据库服务器节点中,每个数据库服务器节点获取到该指令,则进行则执行该指令并将指令执行结果返回;
Ⅲ、通过语义分析将该数据操作语句分拆为具有层级结构的原子语句,通过对原子语句进行语句过滤,过滤出该数据操作语句中的主键名称对应的值,对主键名称对应的值进行哈希计算,获得哈希值,然后对此哈希值对TableNum取模,获得的结果作为哈希索引HashIndex,将哈希索引HashIndex从NodeMap数据中进行查询,获取对应的数据库服务节点地址,GUESTAgent用户进程对该数据库服务节点直接连接,并执行该数据操作语句,至此,完成了数据的定位和操作。
- 还没有人留言评论。精彩留言会获得点赞!