一种哈夫曼物料采购决策算法的制作方法
本发明涉及企业管理领域,具体地涉及用算法分析制造业材料采购问题。
背景技术:
随着全球市场一体化以及信息时代的来临,专业生产能够发挥其巨大的作用,企业采购的比重也大大增加,采购的重要性日益被人们所认识。在全球范围内,在工业企业的产品构成中,采购的原料以及零部件成本随着行业不同而不同,大体在30%-90%,平均水平在60%以上。从世界范围来说,对于一个典型的企业,采购成本(包括原材料,零部件)要占60%。而在中国的工业企业,各种物资的采购成本要占到企业销售成本的70%。显然采购成本是企业管理中的主体和核心部分,采购是企业管理中“最有价值”的部分。另外,根据国家经贸委1999年发布的有关数据,如果国有大中型企业每年降低采购成本2%-3%,则可增加效益500多亿人民币,相当于1997年国有工业企业实现的利润总和。因此,采购受到了社会各界相当的重视,促使采购研究成为当今社会的热点问题之一。
C4.5算法是决策树类算法的一种,它是以算法选择信息增益的扩充信息增益率为属性选择度量,争取克服算法关于多值属性选择的偏向性,其与关于决策树分类器模型的构造过程算法相同。C4.5算法产生的分类规则易于理解,准确率较高。
哈夫曼算法常用于数据压缩,用得越多的编码长度越短,最终就会得到最优编码。由C4.5算法构建出的决策树信息量多且复杂,要想得到一个确切的解决方案非常困难。
技术实现要素:
针对现有技术的上述不足,本发明要解决的技术问题是提供一种哈夫曼物料采购决策算法。
本发明的目的是为了克服现有算法的问题:由C4.5算法构建出的决策树信息量多且较复杂,不容易得到一个确切的解决方案。
本发明为实现上述目的所采用的技术方案是:一种哈夫曼物料采购决策算法。
该算法的步骤如下:
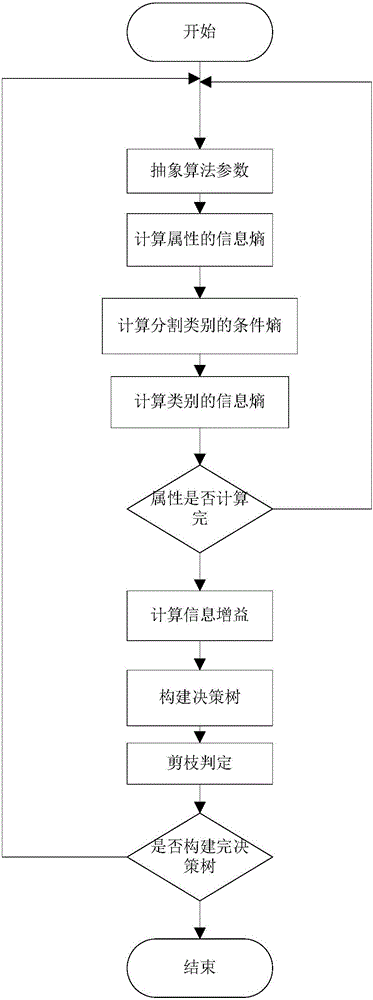
步骤1:构建采购决策树:利用基于C4.5算法构建采购决策树。具体的描述如下:
(1)抽象C4.5算法参数:将物料供应商的类型、等级、所能供给的数量、所供给物料的质量信用度、供应商规模等信息抽象到C4.5算法中,作为算法的数据样本、属性等参数。
(2)计算属性的信息熵。
(3)计算分割后的类别的条件熵。
(4)计算类别的信息熵。
(5)判断所有属性是否计算完,已计算完转到(6),否则转(1)。
(6)信息增益的计算:信息增益率使用分裂信息值将信息增益规范化。
(7)按分裂属性值创建决策树:决策树C4.5的创建是通过将所有属性的信息增益率按大小排序,然后将各个属性作为分支的根节点的顺序。将最大增益率的属性作为树双亲结点,其余的作为该结点的孩子。
(8)剪枝判定:本发明采用前剪枝法结合树深度限定法对决策树进行剪枝。
步骤2:构建采购最优决策树:创建了决策树后,可以清晰的看到各个属性的效果。通过模拟生活中子女继承父母财产的一个简单模式,计算叶子节点的继承财产数来构建最优决策树。继承财产数用信息增益来刻画。
(1)计算每个节点的自有财产:每个节点所拥有的财产用增益函数表示。
(2)计算每层孩子节点可能继承的家族财产数量。
(3)统计接子节点数目N。
(4)构造决策最优二叉树:利用哈夫曼算法构造决策最优二叉树。哈夫曼算法描述为:
a.根据N个叶子节点继承财产序列够建成N棵二叉树的森林F={T1,T2,…,TN},其中,每棵树二叉树Ti中都只有一个权值为Il,i的根节点,其左右子树为空。
b.在森林F中选出两两棵根节点权值最小的数(当这样的数不止两棵时,可以从中任选两棵),将这两棵树中根的取值大的作为右孩子,小的作为左孩子。将这两个孩子的权值之和作为新树根的权值。
c.对新的森林F重复步骤吧b直到森林F中只剩下一棵树为止。那么这棵树就是哈夫曼树,即最优二叉树。
步骤3:输出最优决策结果:步骤2造出的最优二叉树就是最优决策树。决策树叶子节点的继承财产值越大,说从决策树根节点到该叶子节点的这条链路的决策越优。所以,在哈夫曼树中,距离根节点越近的叶子节点对应的到决策树根节点的链路越好。只要将哈夫曼树中的叶子节点按照后续遍历法遍历输出,即可得到决策方案的一个优劣排序。
本发明的有益效果是:
1、利用C4.5算法构建采购决策树,可以得到一个易于理解,准确率较高的采购分析构架。
2、通过模拟生活中子女继承父母财产的一个简单模式,通过信息增益计算决策树叶子节点的财产继承值,继承值越高,则表示该叶子结点到决策树根节点的这一条链路越有价值。
3、通过哈夫曼算法将叶子节点构建最优二叉树(哈夫曼树),用后续遍历法输出哈夫曼树的叶子节点,使得决策分析直观有序。
附图说明
图1为构建采购决策树流程图
图2为一种哈夫曼物料采购决策算法流程图
图3为构造决策最优二叉树算法流程图
图4为哈夫曼算法流程图
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合算法流程图进行详细、具体说明。
一、算法基本思想
首先通过利用C4.5算法建立采购决策树,利用前剪枝法和树深度限定法对决策树的分割进行限制。建立了决策树以后,计算决策树所有叶子节点的继承财产量,称为权值,可以通过这个权值得出某个叶子节点到决策树根节点这条链路的决策价值。利用哈夫曼算法将权值建成一棵哈夫曼树,用后序遍历法将哈夫曼树的叶子节点输出来,即可得到采购决策方案的一个优劣排序。
二、具体实施步骤
步骤1:构建采购决策树:利用基于C4.5算法构建采购决策树。具体的为:
(1)抽象C4.5算法参数:将物料供应商的类型、等级、所能供给的数量、所供给物料的质量信用度、供应商规模等信息抽象到C4.5算法中,作为算法的数据样本、属性等参数。具体问题具体给出对应的参数关系。
(2)计算属性的信息熵:设S为已知类标号的数据样本集,类标号属性为C={Ci|i=1,2,…,z},定义了m个不同类的Ci(i=1,2,…,z)。设Ci,s是S中Ci类数据样本的集合,|S|和|Ci,s|分别表示S和Ci,s的样本个数。则对Ci,s的信息熵Info(S)定义如下:
其中,pi是Ci,s中任意数据样本属于类Ci的概率,Info(S)的实际意义是类别S中数据样本分类的平均信息量。
(3)计算分割后的类别的条件熵:若分类属性Ai={aij|j=1,2,…,ni}将S划分成ni个不同的子集Sij={(Xi,Yi)∈S|xij=aij}表示数据样本集S中在Ai上的取值为aij的所有样本组成的集合。选择S的一个属性A,则类别分割后的类别条件熵计算公式为:
(4)计算类别的信息熵:若选择属性Ai作为分裂属性,则类别信息熵为:
(5)判断所有属性是否计算完,已计算完转到(6),否则转(1)。
(6)信息增益的计算:信息增益率使用分裂信息值将信息增益规范化。属性Ai的信息增益为
从信息增益的计算公式可以看出,Gain(Ai)的实际意义是基于属性Ai分裂后,数据集所含信息量的有效减少量。信息增益越大,表明按属性Ai对数据集分裂所需的期望信息越少,即属性Ai解决的不确定信息量越大,分裂后的输出分区越纯。
(7)按分裂属性值创建决策树:决策树基于数据结构中树的概念。决策树C4.5的创建是通过将所有属性的信息增益率按大小排序,然后将各个属性作为分支的根节点的顺序。
在某一属性集合中将最大增益率的属性作为分列属性,即θ=max{GainRatio(A)},即将最大增益率的属性作为树双亲结点,其余的作为该结点的孩子。
(8)剪枝判定:当决策树划分得太细,数据量很大时,需要设定一个规则,使算法及时收敛,避免算法无限分支无限增长,即剪枝。本发明采用前剪枝法结合树深度限定法对决策树进行剪枝。具体的实施如下:
前剪枝法:前剪枝法是指在构造树的过程中就知道哪些节点可以剪掉,于是干脆不对这些及诶点进行分裂。本发明通过计算增益率方差来确定是否对某一节点剪枝。增益率标准差大于某一设定值,则对该节点剪枝,否则可以分割建立其子树。数学公式描述为:
σi=GainRatio(Ai)-μ
如果σi>ε(标准差限定值),则剪枝,否则继续分割生成决策子树。
树深度限定法:设定一个确限定的树深度L,当决策树的深度到达L以后,停止分割。
步骤2:构建采购最优决策树:创建了决策树后,可以清晰的看到各个属性的效果。通过模拟生活中子女继承父母财产的一个简单模式,通过信息增益计算决策树叶子节点的财产继承值,通过计算叶子节点的继承财产数来构建最优决策树。继承值越高,则表示该叶子结点到决策树根节点的这一条链路越有价值。继承财产数用信息增益来刻画。
(1)计算每个节点的自有财产:每个节点所拥有的财产用增益函数表示,
即
wl,i=Gain(Ai)
wl,i表示数的第l层的第i个节点的财产。
(2)计算每层孩子节点可能继承的家族财产数量:
Il,i=Il-1,i+wl,i,l=2,3,…,(L)
其中,Il-1,i为节点Il,i的双亲结点的继承财产数。
(3)统计接子节点数目N。
(4)构造决策最优二叉树:利用哈夫曼算法构造决策最优二叉树。哈法曼
算法具体实现如下:
a.根据N个叶子节点继承财产序列够建成N棵二叉树的森林F={T1,T2,…,TN},其中,每棵树二叉树Ti中都只有一个权值为Il,i的根节点,其左右子树为空。
b.在森林F中选出两两棵根节点权值最小的数(当这样的数不止两棵时,可以从中任选两棵),将这两棵树中根的取值大的作为右孩子,小的作为左孩子。将这两个孩子的权值之和作为新树根的权值。
c.对新的森林F重复步骤b,直到森林F中只剩下一棵树为止。那么这棵树就是哈夫曼树,即最优二叉树。
步骤3:输出最优决策结果:步骤2构造出的最优二叉树就是最优决策树。因为信息增益越大,表明按属性Ai对数据集分裂所需的期望信息越少,即属性Ai解决的不确定信息量越大,分裂后的输出分区越纯。那么,决策树叶子节点的继承财产值越大,说从决策树根节点到该叶子节点的这条链路的决策越优。所以,在哈夫曼树中,距离根节点越近的叶子节点对应的到决策树根节点的链路越好。只要将哈夫曼树中的叶子节点按照后续遍历法遍历输出,即可得到决策方案的一个优劣排序。
- 还没有人留言评论。精彩留言会获得点赞!