一种快速且适用于高维网络的因果骨架构建方法与流程
本发明涉及数据挖掘领域,尤其涉及一种快速且适用于高维网络的因果骨架构建方法。
背景技术:
因果网络是不确定性推断的一种重要工具,因果网络结构学习是机器学习的研究热点之一。对于可观察数据集来说,因果网络可以有效地描述事物之间的因果关系,而不仅仅是事物之间的关联。在因果网络的推断问题上,由数据节点集构建因果网络结构,再通过节点之间的关系推断出因果网络图。不过,传统的方法用在高维数据中,其运算时间复杂度偏高,严重影响了算法的推广。传统的因果网络推断方法一般分两大类,基于估计马尔可夫等价类的贝叶斯网络结构学习算法和基于加性噪声模型(Additive noise model,ANM)或信息几何的因果方向推断算法。其中,贝叶斯网络结构学习算法主要有两种,即基于评分-搜索的结构学习和基于依赖分析的结构学习,都无法识别数据集中存在的马尔可夫等价类,如X->Z->Y与X<-Z<-Y这2种结构。然而,高维网络结构常常存在于马尔可夫等价类中,无法准确推断因果关系。贝叶斯网络结构学习算法采用穷举法搜索达到精准解,但是随着网络结构维度增长,其时间复杂度呈指数增长,很难使用于超过较大的(如超过100维)网络。基于估计马尔可夫等价类的贝叶斯网络结构学习算法只能用于因果结构无向图的环境,而无法准确完成模型的方向推断。基于加性噪声模型或信息几何的因果方向推断算法能够从数据结点集中构建出有效的因果网络。
Shimizu等人提出了一种基于线性加噪声模型的因果推断算法(Linear non-Gaussian acyclic model,LINGAM),此方法对因果网络结构方向推断有一定的效果。在非线性领域,Hoyer等人提出了一种适用于连续数据的基于非线性的ANM。此后Peters等人把ANM推广到离散数据。区别于ANM,Janzing等人提出基于信息熵的因果推断算法(Information-geometric causal inference,IGCI),该方法能够控制阈值,其推断效果高于其余的因果推断算法。此类算法的极限只能处理低维数据,当维度N>7时,ANM的因果推断能力明显变差。由此可知,以上因果推断方法无法适应高维度的情况,然而真实世界的数据常常是高维数据。总结两类因果推断方法的特点,叶斯网络结构学习算法能够解决高维的因果无向图学习模型;ANM算法和IGCI算法可以对马尔可夫等价类进行方向辨别。实际上,在高维网络的数据集中,在集合中任取1点作为目标节点,往往只有少数相邻节点与其相连。直观地,如果存在1个结点集对目标节点呈现强依赖性,则该结点集与目标结点存在因果关系的机率就很高。类似地,在特征选择方法里,最大相关性和最小冗余度(Max-relevance and Min-redundancy,mRMR)规则常被作为目标节点寻找强依赖性节点集的1个重要准则。由于mRMR只能做2维计算,在实验过程中表现出良好的可靠性和鲁棒性。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种快速且适用于高维网络的因果骨架构建方法。可利用最大相关性和最小冗余度的特征选择方法对两个测试节点间的因果特征集进行筛选,从而大大降低算法复杂度。
为了解决上述技术问题,本发明实施例提供了一种快速且适用于高维网络的因果骨架构建方法,包括基于最大相关性和最小冗余度的父亲特征选择方法、基于条件独立性测试的因果关系剔除及方向推断方法;
所述基于最大相关性和最小冗余度的父亲特征选择方法包括以下步骤:
步骤S11,输入关于因果关系无向图G的n维数据集X={x1,x2,…,xn},并初始化y的候选父亲节点集Sy={};
步骤S12,找出X中与y有最大相关性的节点xk,Sy=Sy∪xk;
步骤S13,根据最大依赖性、最小冗余度原则,通过
求出后面的特征父亲节点,并按顺序加入候选父亲节点集Sy′,其中y为目标变量,S′为候选特征集,任意变量xi,xj属于S′,I是互信息;
步骤S14,给定1个值m,直接取S中的前m个作为y的候选父亲节点,设定m=n(1/2)+1;
步骤S15,以x为目标节点,重复步骤S11-S14求出x的候选父亲节点集Sx;
步骤S16,通过S11-S15得到的Sx与Sy,则x,y候选父亲节点的并集Sx,y=Sx∪Sy;
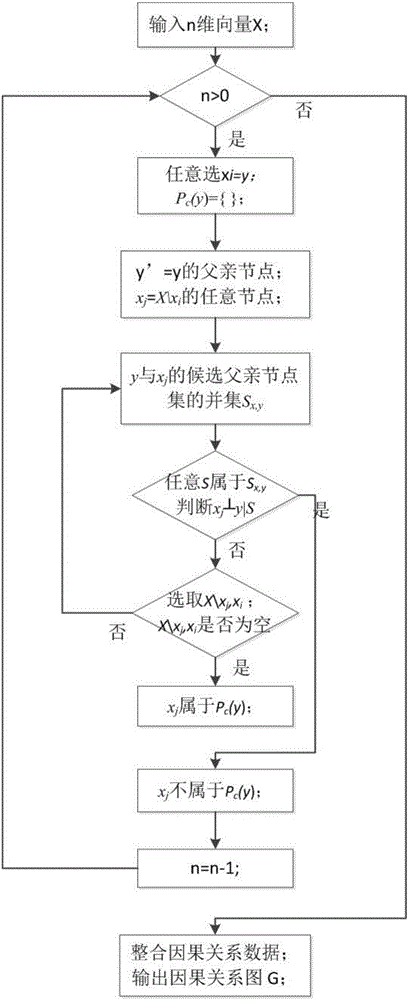
所述基于条件独立性测试的因果关系剔除及方向推断方法包括以下步骤:
步骤S21,对n维数据集X中任意1个节点xi,设xi=y,初始化y的因果节点集PA(y)={};
步骤S22,求出y的父亲节点,在剩下的X\xj的n-1节点中,遍历式选取任意节点xj;
步骤S23,通过条件独立性测试,如果存在任意节点集S,S属于Sx,y使得xi┴y|S,则xi不是y的因果节点,选取X\xj,xi重复步骤S22-S24,如果不存在这样的S,则xi是y的因果节点,将xi加入PC(y);
步骤S24,重复步骤S21-S24直到X中每一个节点都找到其因果节点集,则得到1个完整的因果网络骨架。
其中,还包括全局无向图构建方法,所述全局无向图构建方法包括以下步骤:
步骤S31,初始化全局因果关系图G的元素,把元素的值设为0;
步骤S32,遍历样本集D的第一个样本T,若T为空,则继续执行下一个样本,否则把D中的变量关系存入G中;
步骤S33,重复步骤S12,直到样本集到最后一个样本;
步骤S34,更新因果关系无向图G,并转化成数据集X。
实施本发明实施例,具有如下有益效果:本发明加快了算法整体运行速度,降低了在条件独立性测试中,冗余节点作为条件集进行测试时候产生错误的风险,在一定程度上提高了算法的准确率。
附图说明
图1是基于最大相关性和最小冗余度的父亲特征选择方法的流程图;
图2是基于条件独立性测试的因果关系剔除及方向推断方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明作进一步地详细描述。
本发明实施例的一种快速且适用于高维网络的因果骨架构建方法,包括全局无向图构建方法、基于最大相关性和最小冗余度的父亲特征选择方法、基于条件独立性测试的因果关系剔除及方向推断方法。
1.全局无向图构建方法
输入:样本集D,变量集V。
输出:因果关系无向图G。
(1)步骤1,初始化全局因果关系图G的元素,把元素的值设为0。
(2)步骤2,遍历样本集D的第一个样本T,若T为空,则继续执行下一个样本,否则把D中的变量关系存入G中。
(3)步骤3,重复步骤2,直到样本集到最后一个样本,结束程序。
(4)步骤4,更新因果关系无向图G,并转化成数据集X。
2.基于最大相关性和最小冗余度的父亲特征选择方法,参照图1所示的流程图。
输入:n维数据集,目标变量x和y,阈值m。
输出:父亲节点集合Sx∪Sy。
(1)步骤1,在1个n维数据集中,考虑1个目标节点y与任意x,x属于X。初始化y的候选父亲节点集Sy={}。
(2)步骤2,找出X中与y有最大相关性的节点xk,Sy=Sy∪xk。
(3)步骤3,根据最大依赖性、最小冗余度原则,采用
求出后面的特征父亲节点,并按顺序加入候选父亲节点集Sy,其中y为目标变量,S′为候选特征集,任意变量xi,xj属于S′,I是互信息。
(4)步骤4,与mRMR算法不同,在本发明不对特征集的个数通过交叉检验进行确定,而是给定1个值m,直接取S中的前m个作为y的候选父亲节点,因为通常1个节点的父亲节点不会超过m个,在本实施例中,设定m=n(1/2)+1,一方面提高算法运行速度,另一方面在条件独立性测试过程中,非父亲节点对算法准确率并没有影响。
(5)步骤5,以x为目标节点,重复步骤1~5求出x的候选父亲节点集Sx。
(6)步骤6,通过前5个步骤,可以求得Sx与Sy,则PAx∪PAy=Sx∪Sy,Sx与Sy分别是xi与xj的候选父亲节点,就是x,y候选父亲节点的并集。
3.基于条件独立性测试的因果关系剔除及方向推断方法,如图2所示流程图。
输入:n维数据集X
输出:因果关系图G
(1)步骤1,给定1个n维数据集X={x1,x2,…,xn},对于其中任意1个节点xi,设xi=y,初始化y的因果节点集PA(y)={}。
(2)步骤2,求出y的父亲节点,在剩下的X\xj的n-1节点中,遍历式选取任意节点xj。
(3)步骤3,利用基于最大相关性和最小冗余度的父亲特征选择方法,求出y与xj的候选父亲节点集的并集Sx,y。
(4)步骤4,通过条件独立性测试,如果存在任意节点集S,S属于Sx,y使得xi┴y|S,即在S的条件下,xi和y独立,则xi不是y的因果节点,选取X\xj,xi重复步骤2-4,如果不存在这样的S,则xi是y的因果节点,将xi加入PC(y)。
(5)步骤5,重复步骤1~4,直到X中每一个节点都找到其因果节点集,则得到1个完整的因果网络骨架。
本发明在进行条件独立性测试的时候,约简了条件集的规模,使得算法能够快速地找到相应的条件独立性测试。
传统的算法不同,在本文不对特征集的个数通过交叉检验进行确定,而是给定1个值m,直接取S中的前m个作为y的候选父亲节点,因为通常1个节点的父亲节点不会超过m个。在本实施例中,设定m=n(1/2)+1,一方面提高算法运行速度,另一方面在条件独立性测试过程中,非父亲节点对算法准确率并没有影响。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!