一种基于结构特征的树相似度计算方法与流程
本发明涉及数据结构领域,尤其是大型树形结构数据的相似度计算方法。
背景技术:
随着计算机技术和Internet的迅速普及,人们正在进入一个信息爆炸时代。海量的数据不仅种类繁多,且结构复杂多变,而从中获取有用的信息又是一件及其困难而繁琐的事情。这种现象被称为“数据丰富而知识匮乏”,也就是所谓的数据危机。伴随着海量数据急剧增加,迅速产生和积累了大量的结构化与半结构化数据,而对于这些数据,图挖掘算法的研究逐渐兴起并得到重视。树作为图的特殊表达形式,也有较为重要的研究意义。
树结构在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构;树结构在计算机领域也有广泛的应用,可以用树来表示源程序的语法结构。树形结构的数据相似度计算是当前研究的热点话题,可以用于软件相似度比较,网页聚类等。
在计算树的相似度方面,有学者做了不少的研究。例如2007年乔少杰等提出基于树编辑距离的层次聚类算法,2009年,祁钰等提出网页结构相似度计算,都是不同的计算树的相似度算法。上述算法共同之处在于都是直接计算树的相似度,而如果树的规模较大,计算树的相似度将会是很费时的操作。
技术实现要素:
本发明要解决的技术问题是提供一种计算大型树形结构数据相似度的方法,用于树形结构数据的相似度比较和聚类等操作。
为了解决这个问题,本发明提出基于树T的结构特征计算相似度的方法,构造出K个节点的所有非同构形态的子树,从T中计算这些子树的同构个数,将其作为特征向量来进行树的相似度计算。包括下列3个步骤:
1、选定K值,构造出所有K个节点的非同构形态子树;
2、计算树T相对于上述子树的同构个数,得到关于树T的特征向量
3、利用步骤2得到的选用一种计算相似度的方法进行树T的相似度计算。
关于步骤1,枚举K个节点的所有子树,并对每种子树进行编码,同构子树的编码是相同的,以此来筛选出K个节点的所有非同构子树tK1,tK2,…,tKn°
关于步骤2,设构造的子树为tK1,tK2,…,tKn,共n棵子树。分别计算tK1,tK2,…,tKn在T中同构子树的个数,这些值构成树T的长度为n的特征向量在计算tKi在T中的同构子树个数时,需要将tKi和T中每一个节点进行比较,最后将结果进行累加。
关于步骤3,采用如下方式定义向量间的相似度:
其中A,B为两组特征向量,长度为n,Ai,Bi代表特征向量第i维的值,min(Ai,Bi)为Ai,Bi中较小的一个的值,max(Ai,Bi)则相反。
需要特别说明,在本发明中,关注的重点是树T的结构,而对T中节点属性并没有特别的关注。也就是说T中每一个节点都是等同的。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步的详细描述,其中:
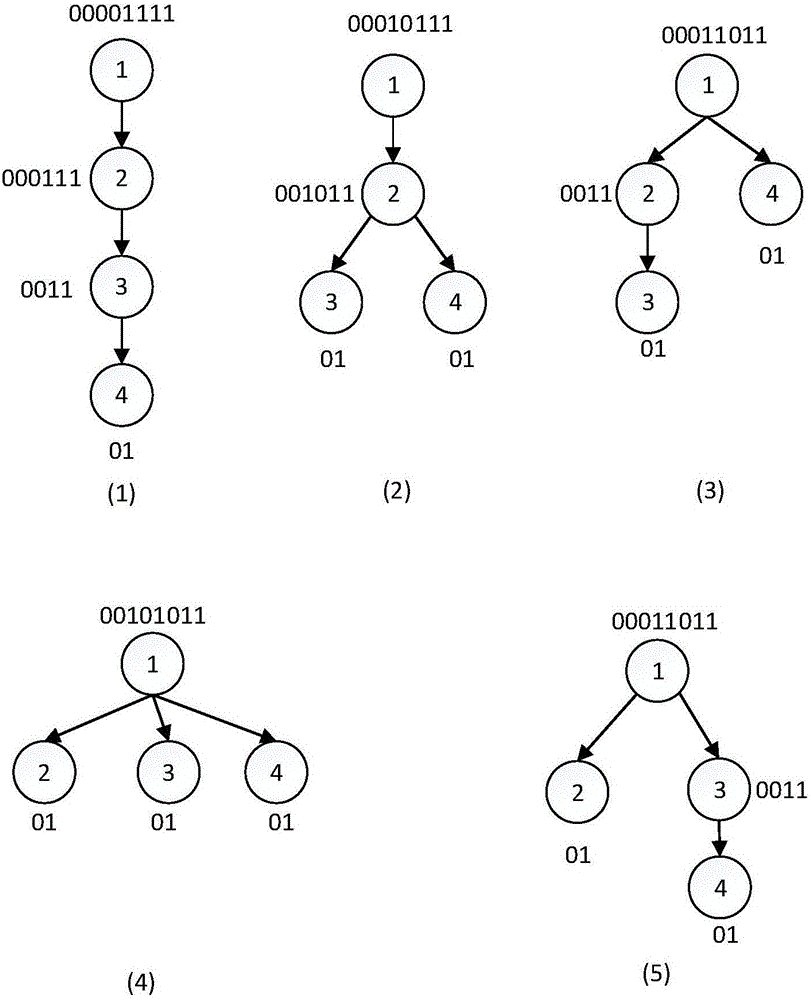
图1是选取K=4时tK的4中非同构形态示意图;
图2是对K=4时非同构子树的编码示意图;
图3是树T的每一个节点存储的信息示意图;
图4是计算同构子树个数的示意图。
具体实施方式
下面将结合附图对本发明的技术方案进行更详细的说明。
本发明主要分为3个步骤:构造K个节点的非同构子树、计算树T中上述子树同构个数并得到特征向量、利用上述特征向量计算T的相似度。
关于步骤1,枚举出K个节点的所有子树,并对每种子树进行编码,编码形式如图2所示,在一棵树中,叶子节点的编码为“01”,对于非叶子节点其编码为将其孩子节点的编码进行排序,将排序好的编码进行拼接,然后在拼接好的编码左边添加数字0,右边添加数字1,以图2中的(3)为例,(3)中的节点3和节点4都是叶子节点所以编码为“01”,节点2只有一个孩子节点3,所以编码为在孩子节点编码的基础上左边添加0,右边添加1构成编码“0011”,对于根节点1,它有两个孩子节点,对孩子节点的编码进行排序(按照ASCII码从小到大的形式)所以节点2的编码排在节点4的编码前面,将两个编码拼接得到编码“001101”,然后在拼接得到的编码的左边添加数字0,有边添加数字1就得到节点1的编码“00011011”。
这样得到的编码,对于同构的子树其编码形式是一样的,如图2中的(3)和(5),这两个子树是同构的,按照上述的编码方式,(3)和(5)根节点的编码是相同的,因此,我们就以根节点的编码来表示一棵树的形态,以此来筛选出K节点的所有非同构子树。
关于步骤2,主要分为两个部分:一是树的构建,二是同构子树个数计算算法。
关于第一部分,树的表示方式很大程度上决定第二部分的计算算法。为了高效计算同构子树个数,我们需要自定义一种表示树的形式。由图3可知,每一个节点需要记录本节点编号,父节点编号,子节点集合;而其孩子节点信息则根据孩子节点的出度进行归类存储。也就是说出度为0的孩子节点存储在一起,然后是出度为1的,以此类推。算法采用插边的方式进行树的构建。
关于第二部分,计算树T中子树tK的同构子树个数,计算方法如下所示:
首先进行节点的合法性检查。对于树T中的节点n1和子树tK中的节点n2,将n1和n2的子节点出度从大到小排列后进行比较,如果n1和n2不存在一个映射关系,保证n1子节点出度≥n2对应子节点出度,则n1中不存在n2的子树同构。利用合法性检查可以缩小T的搜索范围。
设tK的根节点为则我们需要将和T中所有的节点进行比较,将每一次计算出来的同构个数进行累加,最后累加的结果就是tK在T中的同构子树个数。而每一次根节点之间的比较又可分为两部分的乘积:一部分是的叶子节点和RT的孩子节点的对应结果,另一部分是的非叶子孩子结点和RT的非叶子孩子结点的对应结果。下面是T中某一节点RT和tK的根节点的比较过程:
1)记RT的出度为DT,的出度为中为叶子节点的孩子节点个数为
2)如果返回0;
3)如果RT和的合法性检查为非法,返回0;
4)计算第一部分,也就是的叶子节点排列的结果:就是从DT中去掉匹配中出度>0的孩子节点后的个数,从中选出个并进行全排列;
5)计算第二部分,就需要计算两棵树所有非叶子孩子结点的对应关系,并列出下列表格:
表中RTi(i=1,2,…)表示RT中第i个非叶子孩子结点,表示中第j个非叶子孩子结点,而a,b,c,…则表示对应的RTi和这两个孩子节点为根时同构子树的个数。这里就需要递归返回到1)进行计算;
6)列出表格后,我们就需要对表格中的数据进行组合。每一种组合代表两棵子树非叶子孩子结点的一种对应关系。若表3-1为2行3列,则组合结果为a×(e+f)+b×(d+f)+c×(d+e);
7)最后将两部分的结果相乘,就是在RT中同构子树的数目。
由上述比较过程可知,在RT中同构子树的数目由的叶子节点和非叶子孩子结点在RT中的对应关系组合而成。而叶子节点的计算不需要两棵树叶子节点的一一对应,只需计算RT中能够提供给叶子节点匹配的数目,从中选出个并进行全排列即可;非叶子结点孩子的计算则需要两棵树非叶子结点的一一对应,并进行组合。
下面将结合具体例子对本算法中同构子树个数计算进行模拟。
如图4所示,左图为树T,右图为子树tK,需要计算T中tK的同构子树个数。
以节点1和12为根节点进行比较,首先进行节点合法性检查。节点1的子节点出度列表为{1,0,1,3},表示有1个出度为3的节点,0个出度为2的节点,1个出度为1的节点和3个出度为0的节点;节点12的子节点出度列表为{2,1}。可以看出节点1可以提供子节点来满足节点12的子节点需求。
其次计算第一部分,即的叶子节点排列的结果:意思是RT中除去需要匹配的非叶子结点后剩下的节点,用于匹配的叶子节点。
最后计算第二部分,即的非叶子节点排列的结果。需要列出下列表格:
a表示以T中节点2和tK中节点13为根时的同构个数,可递归计算,b、c、d类似。最后第二部分结果可表示为a×d+b×c=6。意思是当节点2和13对应,5和14对应时,同构个数为a×d;当节点2和14对应,5和13对应时,同构个数为b×c,将两种情况相加即得到最后的结果。
关于步骤3,采用如下方式定义向量间的相似度:
其中A,B为两组特征向量,长度为n,Ai,Bi代表特征向量第i维的值,min(Ai,Bi)为Ai,Bi中较小的一个的值,max(Ai,Bi)则相反。在计算两棵树的相似度时,首先分别提取这两棵树的特征向量,之后利用上述式子计算这两个向量的相似度,也就代表了这两棵树的相似度。
- 还没有人留言评论。精彩留言会获得点赞!