一种基于窗口打分和超像素分割的候选区域提取方法与流程
本发明属于图像中的目标检测技术领域,具体的涉及一种基于窗口打分和超像素分割的候选区域提取方法。
背景技术:
目标检测又称物体检测,是计算机视觉的基本任务之一,在监控系统、图片搜索、医学导航手术、自动驾驶、军事目标检测等领域有着广泛的应用。传统方法多采用滑动窗方式从图像中提取出大量的图像区域,然后对区域中的图像提取特征进行分类,完成目标检测的流程。滑动窗方式产生的图像区域数量过于庞大,许多鲁棒性较好但是比较复杂的特征在实际应用中会由于计算量大而产生目标检测效率很低的问题,但是使用简单的特征又难以达到较好的目标检测精度。随着当前图像的分辨率的不断提升,这种矛盾更加凸显。
近些年来,为了使用强分类器提高目标检测的性能,同时为了提高检测效率,许多候选框生成算法被提出来以减少要分类的图像区域数量。当前的候选框生成算法主要有两类,基于融合的算法和基于窗口打分的算法。基于融合的方法大都是基于分割结果做一些融合处理得到候选区域,如2012年提出的selective search方法,此类方法虽然平均召回率一般很高,但是计算比较耗时。基于窗口打分的方法多是先从图像中采用滑动窗的方式采样得到大量的区域,然后对区域中的图像采用一定的方法进行打分排序进行筛选得到候选区域,如BING方法,此类方法需要保留大量的候选框才能保持较高的平均召回率,而过多的候选区域数量又限制着目标检测的整体效率。因此,在提高候选区域提取环节的计算效率的同时,如何在较少的候选区域数量下得到较高的平均召回率来保证最终的目标检测效率和准确率,成为当前目标检测中的一个问题。
技术实现要素:
本发明针对现有技术存在此类方法需要保留大量的候选框才能保持较高的平均召回率,而过多的候选区域数量又限制着目标检测的整体效率等问题,提出一种基于窗口打分和超像素分割的候选区域提取方法。
本发明的技术方案是:一种基于窗口打分和超像素分割的候选区域提取方法,包括窗口打分算法和超像素分割算法,该候选区域提取方法包含以下步骤:
步骤1:采用超像素算法对图像进行分割获得初始区域集合;
步骤2:依据真值区域和初始区域设定正负样本,提取特征训练SVM;
步骤3:对图像根据步骤1提取初始区域,提取初始区域特征,采用步骤2中训练得到的SVM进行分类,得到最终的候选区域。
所述的基于窗口打分和超像素分割的候选区域提取方法,所述步骤1的具体方法为:
步骤101:使用真值框和随机生成的框组成正负样本训练得到线性模板w;
步骤102:使用GS在32种尺度图像上进行超像素分割,并将每个超像素缩放到8×8,计算梯度范数特征;
步骤103:使用w对分割得到的每个超像素进行打分排序;
步骤104:使用对应尺度下的打分结果和对应的候选框作为训练样本进行训练得到vi,ti,利用公式ol=visl+ti到每个超像素包含目标的确定度,其中,vi,ti为第i种尺度下的分值系数和偏置,通过学习得到。
所述的基于窗口打分和超像素分割的候选区域提取方法,考虑到超像素分割效率和对边缘的保持能力,采用基于图的超像素分割方法进行超像素分割;对每种尺度图像进行超像素分割时,设置为尺度图像长度与宽度乘积的平方根为r,在分割时k值取r的多个倍数进行分割,倍数集合为{1/4,1/2,1,2,4,8,16,32},最小区域大小则根据尺度图像的大小从集合{64,256,1024,4096}中动态选取1到3个逐步将较小的区域进行融合,并将每次融合后得到的所有超像素都加入到初始区域集合中。
所述的基于窗口打分和超像素分割的候选区域提取方法,所述步骤2中提取特征训练SVM的具体过程为:真值区域图像和初始区域集合中与真值区域交并比在0.7以上的区域图像作为正样本,初始区域中集合中与真值区域交并比在0.4以下的区域图像作为负样本,然后对每个区域图像缩放到8×8大小,并提取梯度范数特征,然后放入SVM进行训练,训练完成后得到一个分类器。
所述的基于窗口打分和超像素分割的候选区域提取方法,所述窗口打分算法又称为二值化梯度范数,窗口打分算法具体为:目标都有一个封闭的边界,缩小到一个合适的尺度大小后,梯度范数特征能够将目标与周围的背景区分开来,窗口打分算法选择32种尺度进行缩放,然后对缩小后的图像计算梯度范数,计算公式为min(|gx|+|gy|,255),其中gx和gy分别为水平方向和垂直方向上的梯度;窗口打分算法将目标缩小后的固定大小定为8×8,将8×8窗口内的64个梯度范数值作为特征,称为梯度范数(Normed Gradients,NG)特征;然后通过一个64维的线性模型对缩放后的图像中的每一个窗口进行打分,公式为:sl=<w,gl>,l=(i,x,y)
其中,sl,w,gl,i,x,y分别为分值、学习得到的线性分类模板、梯度范数特征、缩放后的尺度和位置。
本发明的有益效果是:1、本发明提出将超像素分割方法加入到基于窗口打分类候选区域提取方法的框架中替代滑动窗方式的采样方法来提取候选区域,并在PASCAL VOC 2007上进行了实验,实验硬件为Think Station D30内存64G,处理器为XeonE5-2650V2,主频2.6GHz,32核心,实验结果如表1。从实验结果中可以看出,本发明方法最终提取的候选区域数量较少,平均召回率较高,计算效率较高,有利于提高整体目标检测的效率和正确率。
表1本发明方法在PASCAL VOC 2007数据集上的实验结果
2、GS算法对于目标边缘良好的捕捉能力,在结合进BING算法的32种尺度图像中以后,能够尽可能的帮助捕捉任意尺度大小的目标。另外,将BING算法和GS算法进行结合实现了自顶向下的学习分类算法和自底向上的分割算法的结合,这样学习到的结果更利于对目标与背景进行区分,借助GS对目标实际边缘的捕捉,最终生成的候选框尽管数量少,但是平均召回率高,对提高最终的目标分类结果有一定的帮助。
说明书附图
图1交并比阈值为0.5时的召回率曲线示意图;
图2交并比阈值为0.6时的召回率曲线示意图;
图3交并比阈值为0.7时的召回率曲线示意图;
图4交并比阈值为0.8时的召回率曲线示意图;
图5交并比阈值为0.9时的召回率曲线示意图;
图6平均召回率曲线示意图;
图7为生成候选框结果示意图,
具体实施方式
实施例1:一种基于窗口打分和超像素分割的候选区域提取方法,包括窗口打分算法和超像素分割算法,该候选区域提取方法包含以下步骤:
步骤1:采用超像素算法对图像进行分割获得初始区域集合;
所述步骤1的具体方法为:步骤101:使用真值框和随机生成的框组成正负样本训练得到线性模板w;
步骤102:使用GS在32种尺度图像上进行超像素分割,并将每个超像素缩放到8×8,计算梯度范数特征;
步骤103:使用w对分割得到的每个超像素进行打分排序;
步骤104:使用对应尺度下的打分结果和对应的候选框作为训练样本进行训练得到vi,ti,利用公式ol=visl+ti到每个超像素包含目标的确定度,其中,vi,ti为第i种尺度下的分值系数和偏置,通过学习得到。
考虑到超像素分割效率和对边缘的保持能力,采用基于图的超像素分割方法进行超像素分割;对每种尺度图像进行超像素分割时,设置为尺度图像长度与宽度乘积的平方根为r,在分割时k值取r的多个倍数进行分割,倍数集合为{1/4,1/2,1,2,4,8,16,32},最小区域大小则根据尺度图像的大小从集合{64,256,1024,4096}中动态选取1到3个逐步将较小的区域进行融合,并将每次融合后得到的所有超像素都加入到初始区域集合中。
步骤2:依据真值区域和初始区域设定正负样本,提取特征训练SVM;SVM的具体过程为:真值区域图像和初始区域集合中与真值区域交并比在0.7以上的区域图像作为正样本,初始区域中集合中与真值区域交并比在0.4以下的区域图像作为负样本,然后对每个区域图像缩放到8×8大小,并提取梯度范数特征,然后放入SVM进行训练,训练完成后得到一个分类器。
步骤3:对图像根据步骤1提取初始区域,提取初始区域特征,采用步骤2中训练得到的SVM进行分类,得到最终的候选区域。
窗口打分算法又称为二值化梯度范数,窗口打分算法具体为:目标都有一个封闭的边界,缩小到一个合适的尺度大小后,梯度范数特征能够将目标与周围的背景区分开来,窗口打分算法选择32种尺度进行缩放,然后对缩小后的图像计算梯度范数,计算公式为min(|gx|+|gy|,255),其中gx和gy分别为水平方向和垂直方向上的梯度;窗口打分算法将目标缩小后的固定大小定为8×8,将8×8窗口内的64个梯度范数值作为特征,称为梯度范数(Normed Gradients,NG)特征;然后通过一个64维的线性模型对缩放后的图像中的每一个窗口进行打分,公式为:sl=<w,gl>,l=(i,x,y)
其中,sl,w,gl,i,x,y分别为分值、学习得到的线性分类模板、梯度范数特征、缩放后的尺度和位置。
GS算法:超像素分割算法有Graph-based Segmentation,简称GS算法,对于一张图像,GS算法首先构建无向图G=(V,E),vi∈V为图的顶点,每个顶点对应图像中的一个像素,(vi,vj)∈E为相邻顶点间的边,每条边有一个权重w((vi,vj)),为相邻顶点(即像素)间的一种非负的相似性度量。
首先定义区域的区域内差异Int(C)为区域的最小生成树MST(C,E)的最大权重,即公式(3),表示区域内最小生成树所能容忍的最大差异。然后定义两个区域的区域间差异Dif(C1,C2)为连接两个区域的最小权重,即公式(5),如果C1和C2没有边进行连接,则令Dif(C1,C2)=∞。
通过检查两个区域间的差异是否至少大于两个区域的区域内差异中的一个来判断两个区域之间是否存在边界,这种检查通过一个阈值函数来控制。为此,定义推断函数:
其中,最小区域间差异的计算公式为:
MInt(C1,C2)=min(Int(C1)+τ(C1),Int(C2)+τ(C2)) (4)
阈值函数τ控制着两个区域间的差异大于区域内差异的程度。区域比较小的时候,并不能很好的估计局部特征,因此,为了约束生成的区域不至于过小,使用的阈值函数为:
τ(C)=k/|C| (5)
|C|为区域大小,k为常量参数,控制区域大小的趋势。
算法输入为n个顶点m个边的图,输出为一系列区域。
实验及结果分析
实验环境为:Think Station D30,内存64G,处理器为XeonE5-2650V2,主频2.6GHz,32核心。实验选用PASCAL VOC 2007数据集,共有5011张训练图像和4952张测试图像;评价方法采用了文献所应用的不同交并比阈值下的召回率和最终的平均召回率。召回率(Recall)是候选框生成算法最常用的评价指标,具体计算公式为
Recall=N/G (6)
其中,N表示在一定交并比阈值下检测到的目标数量,G为实际的目标数量,当交并比阈值为0.5时,PASCAL VOC将其定义为检测率(Detection Rate,DR),即只要交并比阈值大于0.5,就认为找到了目标。平均召回率(Average Recall,AR)为文献[1]提出的用于评价候选框生成算法综合性能的指标,与最终的目标检测结果成正线性相关,其定义为:
其中,o,IoU(gti)都代表与真值框最接近的候选框与真值框的交并比,n为真值框个数。
GS算法中,常数参数k控制着生成的超像素的大小的趋势,即控制着得到的候选框的在某种尺度图像上的大小。在本文的实验中,GS中的常数参数k根据每种尺度图像大小进行动态设置,最小区域大小也一样。设置基础k值其中分别为第i种尺度下的图像的宽和高,在对第i种尺度下的图像进行超像素分割时选用,k值的取值为base_k(为行文方便起见,省略下标i,后文于此相同)的整数倍,倍数的取值集合为m={1,2,4,8,16,32,64},最小区域大小的取值集合为{64,256,1024,4096},实际中根据缩小后的图像的大小以一定规则从集合中取1到4个最小区域大小值,强制小区域按照最小区域大小进行逐级融合,设置每种尺度下得到的候选框数量上限为400.为了充分评价算法的性能,本文还比较了本文算法在k值取base_k的多个倍数共同作用下的结果和每种尺度图像最大容许的候选框数量为1000时的BING算法的结果。
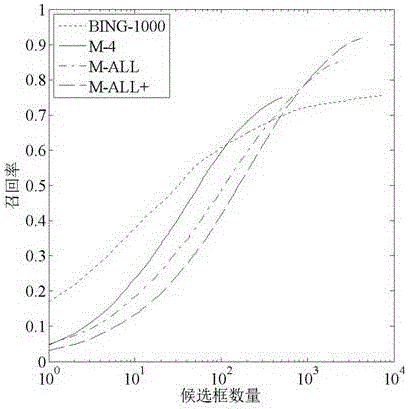
图1到图5分别为各算法及不同参数条件下的结果在交并比阈值为0.5到0.9时的召回率曲线,图6为平均召回率曲线,其中,BING-1000为每种尺度下的候选框数量限制为1000条件下的结果,M4为k取base_k的4倍条件下的结果,M-ALL为k值取上述base_k所有倍数条件下的结果,为了得到更多的候选框,M-ALL+在M-ALL的基础上,在倍数集合中添加了96,在最小区域大小集合中添加了25。从图1中可以看出,在交并比阈值取0.5时,BING算法在不同候选框数量下的召回率总是高于本文算法中所有条件下的召回率,然而,从图2到图5中可以看出,交并比阈值取到0.6时,本文算法在k取base_k单一倍数值时,结果大都与BING算法相当,综合多k值的结果要远优于BING算法,从图3到图5中可以看出,随着交并比阈值取0.6以上时,本文算法在候选框数量大于100时,不同条件下的召回率都要大于BING算法,候选框的精度相比于BING算法得到了很大的提升。从图6中可以看出,在候选框数量大于100时,本文算法在所有条件下的平均召回率也都大于BING算法。另外,从图1-6以及表2中可以看出,BING算法随着候选框数量的增多,并没有多少性能提升;本文算法k取在base_k单一倍数的情况下生成的候选框数量少,精度高,而且将多个base_k倍数件下的结果叠加时,召回率和平均召回率都得到了很大的提升,最高平均召回率能够达到60.4%,而BING算法的平均召回率最高为35.8%.本文算法在多k值多最小区域下的部分结果与BING的部分结果如图7。从图中可以看出本文算法大部分时候都能够有效的提升候选框与真值框的吻合程度,但是从最后一张图的结果中可以看出,由于GS算法在超像素的融合过程中只采用最简单的大小和位置信息,也会产生一些质量不高的候选框,但是候选框仍能够包含目标的整体,一般不会像BING一样容易对目标进行截断。
本文算法和BING算法在各种条件下的计算时间以及平均每张图片生成的候选框数量和最高平均召回率如表2。从表2中可以看出,在k值取base_k单一倍数的情况下,本文算法处理每张图片的平均时间大约为BING算法的4到5倍,多个倍数叠加的情况下,计算用约为单一倍数条件下的叠加。虽然本文算法相比于BING算法计算效率上有所下降,但是从具体时间上可以看出本文算法的计算效率也很高。由于叠加时没有相互之间的数据交换,因此多个倍数叠加的情况也可以在后续工作中进行并行加速处理,这样算法的计算效率可以进一步得到提升。另外,本文算法在k值取base_k单一倍数的情况下,平均每张图片得到的候选框数量不到1000,有效减少了后续分类器的分类负担。
从以上结果中可以看出,GS算法对于目标边缘良好的捕捉能力,在结合进BING算法的32种尺度图像中以后,能够尽可能的帮助捕捉任意尺度大小的目标。另外,将BING算法和GS算法进行结合实现了自顶向下的学习分类算法和自底向上的分割算法的结合,这样学习到的结果更利于对目标与背景进行区分,借助GS对目标实际边缘的捕捉,最终生成的候选框尽管数量少,但是平均召回率高,对提高最终的目标分类结果有一定的帮助。
- 还没有人留言评论。精彩留言会获得点赞!