基于粗糙集理论与WAODE算法的入侵检测方法与流程
本发明涉及网络安全防御技术领域,具体地说是一种基于粗糙集理论与WAODE算法的入侵检测方法。
背景技术:
随着互联网与计算机技术的日益发展,网络上的信息越来越多,这使得作为互联网信息安全手段之一的入侵检测技术得到越来越多的重视。入侵检测,即是对计算机网络或计算机系统的入侵行为的察觉。它通过对计算机已有的或实时收集的安全日志、审计日志、网络行为等数据进行分析处理,判断网络中是否存在异常,从而对入侵进行识别。入侵检测通常分为异常检测与误用检测两种。
粗糙集理论是1982年由波兰的Pawlak教授提出的一种理论,是一种用来研究不完整数据、不确定的知识表达、学习和归纳的理论方法。粗糙集理论广泛应用于数据挖掘、机器学习、知识发现等多个领域,主要是作为一种不确定数据分析研究和推理的工具。其中基于粗糙集的属性约简技术可以对属性进行约简同时仍保持较好的分类能力。然而传统的基于粗糙集的属性约简方法使用的是基于差别矩阵的属性约简,然而对于入侵检测的网络数据,属性的数量较大,用于建立模型的数据对象通常也比较多,在计算差别矩阵过程中会占用较多的内存和CPU资源,导致入侵检测模型更新代价较大。
贝叶斯分类是在贝叶斯定理的基础上发展而来的分类方法,原本是作为统计学方法使用,但随着近些年数据挖掘与机器学习技术的兴起,贝叶斯由于原理简单、计算结果误差小、应用范围广而得到了广泛的应用。基于贝叶斯的分类算法主要有朴素贝叶斯与贝叶斯网络这两种方法。朴素贝叶斯方法由于推理能力强、效果稳定、相对误差较小的优点,常常被应用到入侵。但朴素贝叶斯方法存在着一些缺陷,如特征属性之间要求具有独立性的约束等,因此许多研究者都在其基础上提出改进方法来提高分类的效果。在众多基于朴素贝叶斯的改进算法中较为有名的有LBR(Lazy Bayesian Rules)以及SP-TAN(Super Parent TAN)。其中LBR是通过一种较为复杂的分类测试机制来提高分类精度的,而SP-TAN则是通过更准确地模型来取得更好的精度,但效率也相对较低。
技术实现要素:
本发明的目的在于提出一种使用粗糙集进行属性约简,使用WAODE进行分类的的入侵检测的方法。在入侵检测前,使用已有的连接数据作为建立模型的训练集。随后利用粗糙集理论,对网络连接数据实行基于粗糙集理论的属性约简。然后利用WAODE算法建立入侵检测模型。在实时入侵检测过程中,对实时数据,进行属性约简,最后根据建立好的入侵检测模型,对实时的连接数据进行分类,从而判断连接是正常连接还是入侵数据。算法资源消耗较低、易于实现,且具有较好实时性与准确度。
实现本发明目的的技术方案是:
一种基于粗糙集理论与WAODE算法的入侵检测方法,它包括以下步骤:
第一步,对于过去收集的、已标示是正常连接还是某种入侵方式的网络连接数据进行随机抽样,作为建立模型的训练集;
第二步,对抽样后的数据进行数据离散化、数据均一化等数据预处理工作;
第三步,对于完成预处理的数据,利用基于粗糙集理论的属性重要度对数据进行属性约简;
第四步,对于属性约简后的训练集数据,利用WAODE算法和约简后的训练集数据建立分类模型,得到入侵检测模型;
第五步,对于待检测的网络连接数据,将其输入入侵检测模型,利用检测模型判断该数据是属于正常数据还是入侵数据。
本发明与现有技术相比,其显著优点为:本发明基于粗糙集理论、使用属性依赖度进行属性约简的方法,相较于使用差别矩阵的属性方法,既能提高属性约简的运行的速度,也减少了资源消耗。而用于分类的WAODE算法结合了LBR以及SP-TAN算法的优点并考虑了属性值的重要程度,进一步提高了分类器的准确度与效率。而通过将基于粗糙集理论的属性约简与基于WAODE算法的分类结合在一起,既能提高入侵检测的效率,减少入侵检测系统的资源消耗,同时能够保证较高的入侵检测准确度。
附图说明:
图1是基于粗糙集理论与WAODE算法的入侵检测方法的流程图。
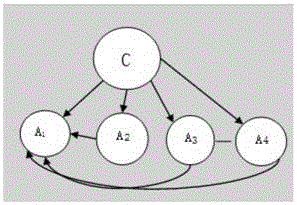
图2是具体WAODE算法,某属性计算的模型图。
具体实施方式:
下面结合附图对本发明做进一步的说明:
如图1所示,一种基于粗糙集理论与WAODE算法的入侵检测方法,具体步骤如下:
第一步,对于过去收集的、已标示是正常连接还是某种入侵方式的网络连接数据进行随机抽样,作为建模的训练集;
第二步,对抽样后的数据进行数据预处理;
其中,对于建模的训练集数据预处理方法如下:
步骤1,对于训练集中某一属性,若训练集中该属性数据值区间相比较其他属性差异过大,对该属性进行均一化处理;
步骤2,对于对于训练集中某一属性,若其为连续型数据,对其进行数据离散化处理。
第三步,对于完成预处理的数据,利用粗糙集理论对其进行属性约简;
其中,利用粗糙集理论进行属性约简的步骤如下:
步骤1,初始化集合R为空集即令
步骤2,设定一个临时的集合T,令T=R;
步骤3,对于条件属性集C与属性集R的差集(C-R)中的每一个元素x,判断R与x的并集对于决策属性D的属性依赖度γRU{x}(D)是否大于T对于决策属性D的属性依赖度γT(D),如果是,令T=R∪{x},否则,继续判断下一个元素,直到(C-R)中元素都判断一次。
步骤4,令R=T;
步骤5,判断集合R对于决策属性D的属性依赖度γR(D)是否等于条件属性集C对于决策属性D的属性依赖度γc(D),如果不是,转到步骤2,否则返回属性约简集R;
其中计算属性依赖度的计算过程如下(以γR(D)为例,计算γRU{x}(D),γRU{x}(D),γR(D)方法与此相同):
步骤5.1:对于R中的每个属性Ri,将数据对象集U中Ri属性值相同的数据对象分别构成集合,求出U根据Ri属性得到的一个划分U/Ri;
步骤5.2:对U关于属性集R中的属性R1,R2,...,Ri的划分集合U/R1,U/R2,...,U/Ri,进行操作,得到数据集U关于属性集R的划分U/R。,其中
步骤5.3:对于属性集U关于属性集R的划分U/R以及决策属性D,求出属性集R和数据集U的子集X的下近似集RX,其中
步骤5.4:对于下近似集RX,求出属性集R对于决策属性D的正域POSR(D),其中POSR(D)=Ux∈DRP
步骤5.5:分别求出正域POSR(D)和数据对象集U的基数||POSR(D)||和||U||,则
第四步,对于属性约简后的训练集数据,利用WAODE算法和约简后的训练集数据建立分类模型,得到入侵检测模型;
其中,用WAODE算法和约简后的训练集数据建立分类模型的步骤如下:
步骤1,对于属性约简后的训练集的完成属性约简的训练集数据,对于标示是正常连接还是某种入侵方式的类属性中每个不同的值ck,扫描所有类属性(c1,c2,c3…ck),分别记录不同类属性的样本数s1,s2,...,sn,以公式计算先验概率P(ck);
其中,计算P(ck)的方法如下:
步骤1.1:扫描所有类属性(c1,c2,c3…ck),分别记录不同类属性的样本数s1,s2…,sk,
步骤1.2:以如下公式计算概率P(ck);
步骤2,对于所有的非类属性的不同取值ai,计算ai与类属性ck的联合概率P(ai,c);
其中,计算联合概率P(ai,c)的方法如下
步骤2.1:对于某一个属性A,对于所有训练集中的每种样本值x=<A1=a1.A2=a2...An=αn>,首先选取其中一个属性值Ai=ai作为根属性,构建一个分类模型,如图2所示;
步骤2.2:扫描所有训练数据集,然后选择其中第Ai个属性值满足Ai=ai但个数不满足m=30的属性,则将其从分类模型中去除掉
步骤2.3:扫描所有训练数据集,记录其中第Ai个属性的属性值为ai且类为c的样本在训练集中的数量F(ai,c);
步骤2.4:扫描数据集,记录训练集样本的数量N;
步骤2.5:扫描数据集,记录vi是与根属性Ai对应的属性值相同的样本的数量;
步骤2.6:扫描数据集,记录类不同取值的数量k;
步骤2.7:根据如下公式计算P(ai,c),
步骤3,对于属性约简后的训练集的所有分属性的不同取值aj,计算类属性ck与两个属性ai,aj之间的条件概率P(aj|ai,c);
其中,计算P(aj|ai,c)的方法如下:
步骤3.1:对于某一个属性A,对于所有训练集中的每种样本值x=<A1=a1.A2=a2....An=an>,首先选取其中一个属性值Ai=ai作为根属性,构建一个分类模型,如图2所示;
步骤3.2:扫描所有训练数据集,然后选择第Ai个属性值满足Ai=ai但个数不满足m>=30的属性,则将其从分类模型中去除掉
步骤3.3:扫描所有训练数据集,记录其中第Ai个属性值为ai且第Aj个属性值为aj且类为c的样本在训练集中的数量F(aj,ai,c);
步骤3.4:扫描数据集,记录训练集样本的数量N;
步骤3.5:扫描数据集,记录vj是与根属性Aj对应的属性值相同的样本的数量;
步骤3.6:扫描数据集,记录类不同取值的数量k;
步骤3.7:扫描所有训练数据集,记录其中第Ai个属性的属性值为ai且类为c的样本在训练集中的数量F(ai,c);
步骤3.8:根据以下公式计算条件概率P(aj|ai,c):
步骤4,根据公式计算两个属性之间的互信息IP(Ai;c),以IP(Ai;c)作为属性Ai权重Wi
步骤5,根据如下公式,生成入侵检测模型。
第五步,对于待检测的网络连接数据,将其输入入侵检测模型,判断该数据是属于正常数据还是入侵数据。
- 还没有人留言评论。精彩留言会获得点赞!