体感互动应用中多数据源人体位置快速配准方法与流程
本发明涉及多媒体互动科技领域,具体涉及体感互动应用中多数据源人体位置快速配准方法。
背景技术:
目前比较流行的体感设备主要有微软的Kinect,英特尔的RealSence和苹果公司的Primesense等,这些设备都可以输出深度数据流和彩色视频流,并且深度数据和视频数据是已经配准好的。但实际应用过程中可能还需要更多的视频流来满足应用需求:比如需要分辨率更高,清晰度更高,焦距更远,或者是需要其它视角的视频图像数据流。此时只采用一个体感设备就没法满足应用要求。
改进的方法是采用一个体感摄像头和多个普通摄像头结合,以实现应用需求,但是由于使用了多个图像采集设备,每个设备的安装位置不尽相同,获取到的图像数据也是不同的,所以玩家或用户的身体呈现在不同图像上的坐标位置也是不同的,比如:通过体感设备获取到的人体头部在体感数据流中的坐标是(a,b),而在另外一个高清设备的视频流中的坐标是(c,d),由于体感设备和高清设备的安装位置不同,所以一般来说(a,b)≠(c,d),我们可以很容易的通过体感设备的SDK获取到(a,b),而从高清视频流中得到(c,d) 却并不容易,如果想在高清视频流中通过AR的方式按照(a,b)的坐标给玩家或用户的头部叠加一顶帽子,这样就会出现“帽子没有戴在头上”的问题。
为了解决这个问题,目前传统的解决方法主要有两种:
一、将体感设备和高清设备的相对位置在出厂时就进行固定,测量出它们位置的相对偏移,将偏移数据写入程序进行校正,该方案的缺点是由于多个设备相对位置被固定,程序的参数也是预先设好,缺少灵活性,给施工安装带来很大不便,也不能根据现场效果进行调整。
二、体感设备和高清设备可以单独安装,安装好后在现场通过人工的方式进行手动校准匹配,这样虽然提高了施工安装的灵活性但是校准调试过程繁琐耗时,而且至少要两个调试人员,费时费力。
技术实现要素:
本发明的目的在于提供一种体感互动应用中多数据源人体位置快速配准方法,以实现应用需求,同时快速完成匹配校准,提高安装的灵活性。
为实现上述目的,本发明采用以下技术方案:
本发明公开了体感互动应用中多数据源人体位置快速配准方法,所述的体感互动应用包括一个体感设备和若干个普通视频采集设备,包括以下步骤,
S1.训练模型:将包含指定姿势人体的图片作为正样本,不包含指定姿势人体的图片作为负样本,将正样本和负样本的HOG特征作为SVM学习的输入数据,得到SVM分类模型;
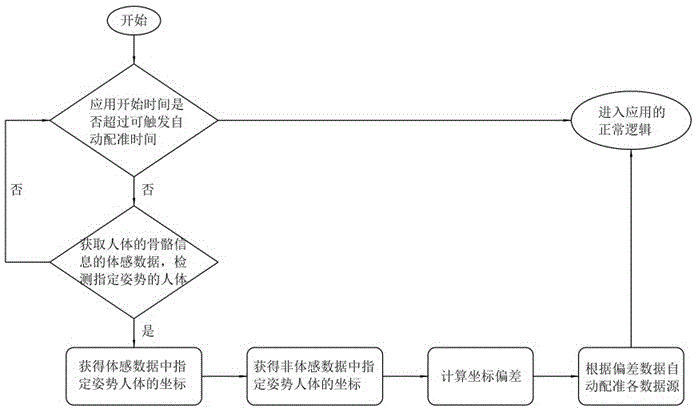
S2.开启应用:开启体感互动应用,等待自动配准;
S3.获取体感数据:使用体感SDK获取人体的骨骼信息的体感数据,在体感数据中检测到步骤S1中的指定姿势的人体,得到人体的三个部位的坐标(x,y),则进入步骤S4;若未在体感数据中检测到指定姿势的人体,则退出等待,进入应用界面;
S4.获取非体感数据:普通视频采集设备拍摄指定姿势的人体,获取视频截图,通过方向梯度直方图和SVM算法得到人体的三个部位的位置坐标(x',y');
S5.计算坐标偏差:分别计算三个部位的位置坐标(x',y')与坐标(x,y)的偏差;
S6.位置配准:将获得的偏差数据配准校正各数据源中人体各部位的位置。
进一步地,步骤S1中正样本或负样本的HOG特征的提取过程为:
(1)获取一张正样本或负样本图片,对于正样本使用窗口标定指定姿势的人体位置,对于负样本使用窗口标定人体图片位置;
(2)提取标定窗口区域的数据,将图像灰度化;
(3)采用Gamma校正方法,对图像进行归一化处理;
(4) 计算梯度图像,将梯度图像平均分成N*M个网格,每个网格为M*M像素;将每个网格的梯度数据按权重投影到方向梯度直方图中;
(5) 相邻4个网格组成一个方块,对每个方块内的网格进行归一化;
(6) 所有方块内的网格中的直方图数据组成一个大的向量即为HOG特征;
(7)将获得的HOG特征作为SVM的训练数据,得到分类模型。
优选地,所述的步骤(1)中,样本图片上人体位置的窗口上方叠加一个蒙版,蒙版中白色部分是需要参与计算的部分,黑色部分是不需要参与计算的部分。
优选地,步骤S2中开启体感互动应用,等待自动配准时,设定有可触发自动配准的时间为1~5min,若未在可触发自动配准的时间内检测到指定姿势的人体,则退出等待,进入应用界面。
一实施例中,所述的指定姿势为双手向上举起,肘与肩平齐的“山”字形姿势,所述的人体的三个部位为头部、肩部和手臂。另一实施例中,所述的指定姿势为双手平直伸出,手掌向内,肘与肩平齐的“十”字形姿势,所述的人体的三个部位为头部,肩部和手掌。本发明使用指定姿势,一是为了触发进入配准流程,二是为了排除数据中其它人体的干扰。
采用上述技术方案后,本发明解决了传统方案存在的问题,不需要在出厂时就固定每个设备的相对位置,不需要预先设定各个设备的相对位置参数,也不需要手动校准,一个调试人员甚至是用户或玩家自己就能快速完成匹配校准,大大提高的施工安装的灵活性,也节省了人力和时间,使得体感互动应用的可用性大大提高。
附图说明
图1为体感互动应用的设备结构示意图。
图2为体感互动应用的操作流程图。
图3为正样本HOG特征的提取流程图。
图4为数据图和蒙版示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。
本发明公开了体感互动应用中多数据源人体位置快速配准方法。如图1所示体感互动应用包括一个体感设备1和若干个普通视频采集设备2。结合图2所示,本发明方法的步骤详述如下。
S1.训练模型:设定人体的指定姿势为:双手向上举起,肘与肩平齐的“山”字形姿势,人体的三个部位为头部、肩部和手臂。将包含“山”字形姿势人体的图片作为正样本,不包含该姿势人体的图片作为负样本,将正样本和负样本的HOG特征作为SVM学习的输入数据,得到SVM分类模型。
正样本或负样本的HOG特征的提取流程如图3所示:
(1) 获取一张正样本或负样本图片,对于正样本使用窗口(128×64)标定“山”字形姿势的人体位置,对于负样本使用窗口(128×64)标定人体图片位置;如图4所示,正样本图片上人体位置的窗口(128×64)上方叠加一个蒙版,蒙版中白色部分是需要参与计算的部分,黑色部分是不需要参与计算的部分。本实施例中“山”字形区域的头部、肩部和两个手臂的特征是需要检测的部分,采用蒙版可以节省很大的计算量,提高计算速度。
(2) 提取标定窗口区域的数据,将图像灰度化。
(3) 采用Gamma校正方法,对图像进行归一化处理。
(4) 计算梯度图像,将梯度图像128×64平均分成16×8个网格,每个网格为8×8像素;将每个网格的梯度数据按权重投影到方向梯度直方图中。
(5) 相邻4个网格组成一个方块,对每个方块内的网格进行归一化。
S2.开启应用:开启体感互动应用,等待自动配准,设定可触发自动配准的时间为开启后1~5分钟。
S3.获取体感数据:使用体感SDK获取人体的骨骼信息的体感数据,在体感数据中检测到“山”字形姿势的人体,得到人体的三个部位坐标:头部坐标(x1,y1)、肩部坐标(x2,y2)和手臂的坐标(x3,y3),则进入步骤S3。若在可触发自动配准的1~5分钟时间内未在体感数据中检测到“山”字形姿势的人体,则退出等待,进入应用的正常逻辑。
S4.获取非体感数据:普通视频采集设备拍摄“山”字形姿势的人体,获取视频截图,通过方向梯度直方图和SVM算法得到指定姿势人体相应的三个部位坐标:头部坐标(x1',y1')、肩部坐标(x2',y2')和手臂的坐标(x3',y3')。
S5.计算坐标偏差:分别计算上述三组坐标的偏差。头部在普通视频图像上的位置相对于体感数据图像上的偏差(△x1,△y1)=(x1'-x1,y1'-y1)。肩部在普通视频图像上的位置相对于体感数据图像上的偏差(△x2,△y2)=(x2'-x2,y2'-y2)。手臂在普通视频图像上的位置相对于体感数据图像上的偏差(△x3,△y3)=(x3'-x3,y3'-y3)。
S6.位置配准:得到偏差数据之后,通过体感设备获取到的头部坐标结合这个偏差就能实时的估计头部在普通视频图像上的位置。
安装好开启应用,系统刚启动的一段时间内,等待配准,调试人员或玩家在摄像头前摆出指定姿势,除了上述实施例中所采用的“山”字形姿势,另一实施例中的指定姿势为双手平直伸出,手掌向内,肘与肩平齐的“十”字形姿势,人体的三个部位为头部,肩部和手掌。其它的操作过程类似。
综上,本发明方法的使用,使得体感互动应用可以根据实际场景分别布置体感设备和其它视频采集设备,调整它们的相对位置到最佳效果,在现场通过本方法配准,给安装施工带来很大的灵活性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!