基于改进PCA的云计算网络中高维数据可视化方法与流程
本发明涉及一种基于改进PCA的云计算网络中高维数据可视化方法,属于高维数据标准化处理技术领域。
背景技术:
目前,随着计算科技技术的飞速发展,高维数据呈现出海量增长的模式。在云计算网络中,大数据是云计算的基础和核心技术,在这些大数据中存在大量的高维数据,但当前人类认知能力具有一定的局限性,无法掌握复杂多变的高维数据中蕴含的深层信息,因此在这种情况下,如何有效地开发处理这些高维数据成为了相关领域亟待解决的主要问题,对高维数据进行可视化是进行高维数据进行标准化处理的前提,决定了标准化处理的效果。而云计算网络中高维数据可视化方法可以对原始高维数据矩阵中的变量进行标准化处理,对转换后的高维数据按行重新组建,完成了云计算网络中高维数据可视化呈现,是解决上述问题的根本途径,引起了很多专家与学者的重视。
文献[1]提出了一种基于径向坐标可视化的云计算网络中高维数据可视化方法。该方法先利用最大似然原理估计出云计算网络中高维数据的本征维数,利用较少的变量结合与径向坐标原理相融合,在此基础上对云计算网络中高维数据进行降维可视化处理。该方法较为简单,但是存在方法局限性大的问题。文献[2]提出了一种基于随机森林的云计算网络中高维数据可视化方法。该方法先利用RF进行有监督学习,对高维数据样本间的相似度进行度量,并在低维空间中采用散点图对数据进行可视化,从而完成了对云计算网络中高维数据可视化呈现。该方法鲁棒性较强,但是采用当前算法对数据进行可视化处理时,无法消除高维数据集中包含大量无关信息和冗余信息,存在数据呈现误差大的问题。文献[3]采用了基于SOM的云计算网络中高维数据可视化方法。该方法先将云计算网络中的高维数据映射到三维空间中,利用TDSOM将三维坐标下点集的横坐标、纵坐标和竖坐标三个变量映射在数据集的属性类别中,在此基础上完成了云计算网络中高维数据可视化呈现。该方法可扩展性较强,但是存在难以清晰准确地展现高维数据的缺陷的问题。
参考文献:
[1]谢永华,王畅,袁复兴.基于线性八叉树光线投射算法在云可视化方面的应用[J].科学技术与工程,2014,14(30):191-195.
[2]时钢.基于Mipmap的大规模地形绘制算法与仿真[J].计算机仿真,2015,32(2):270-274.
[3]王晶,许志杰.基于时空纹理的实时群体行为检测[J].西安邮电大学学报,2015,20(2):64-76.
技术实现要素:
发明目的:针对现有技术中存在的问题与不足,本发明提出一种基于改进PCA的云计算网络中高维数据可视化方法,对云计算网络中高维数据进行标准化处理,仿真结果表明,改进方法具有较好的可视化和分类效果,可以很好的实现云计算网络中高维数据标准化处理。主成分分析(PCA)是一种数学降维的方法,其方法是找出几个综合变量来代替原来众多的变量,使这些综合变量尽可能多地反映原来变量的信息量,而且彼此之间相互独立。
技术方案:一种基于改进PCA的云计算网络中高维数据可视化方法,对云计算网络中高维数据进行标准化处理优化;包括高维数据特征矩阵的组建和基于高维数据可视化的数据标准化处理优化两部分。
高维数据特征矩阵的组建
在对高维数据可视化过程中,将原始高维数据矩阵中的变量进行标准化处理,给出新的高维数据特征矩阵,将矩阵中的特征值按顺序进行排列,选取方差最大的主成分数据。具体的步骤如下详述:
假设,由代表云计算网络下原始数据矩阵,将X代表的各变量进行标准化预处理,利用式(5)获取标准化数据矩阵Z
式中,xi,j代表第i个高维数据的第j个类别属性,代表第i个高维数据的协方差矩阵,代表第i个高维数据的低维嵌入空间。
则利用式(6)和式(7)计算出
假设,由C代表协方差矩阵,则利用式(8)计算出C
利用雅可比法得到C的特征值矩阵Λ=diag(λ1,λ2,…λm)和特征向量W。
将各个数据的特征值依据从大到小顺序排列λ1>λ2>…>λm,并对特征向量列的顺序进行相应的调整,促使第一个主成分具有最大的方差,促使第二个主成分具有次大的方差,而将最小的方差对应第d个主成分。选取方差最大的k个主成分,并促使k个主成分能够保留大部分的原始信息,一般情况下使选取的k个主成分的累积方差贡献大于总方差的85%,即假设,由wi代表选择的k个主成分的特征向量,则利用式(11)得到k个独立的线性组合新变量;
综上所述可以说明,在对高维数据可视化过程中,将原始高维数据矩阵中的变量进行标准化处理,给出新的高维数据特征矩阵,将矩阵中的特征值按顺序进行排列,选取方差最大的主成分数据,为实现对高维数据可视化奠定了基础。
基于高维数据可视化的数据标准化处理优化
综合考虑主成分贡献率因素和列间的相似度,提出了新的数据列排序方法,主要过程如下:
假设,由Y代表主成分转换后的数据矩阵,以获取的ξk为依据,利用式(12)计算出Y
式中,FC代表不同类别数据的类间分离度,G代表高维空间聚类数据,ω*代表类内聚集度。
1.贡献度因子计算
首先计算得到的列间的相似度矩阵为
其中Sij表示第i列与第j列的相似度。则对于第i列,和其他所有列的平均相似度为
Ti可以反映第i列和其他列的相似程度,因此可以定义新的贡献度因子为
ai代表贡献度因子权值,该贡献度因子由主成分贡献率因素和列间的相似度的乘积得到,可以更好地反映各列的重要性程度。
2.数据排序
对gi代表的贡献度因子依据从大到小的顺序排列,而且要相应的调整其对应在Y中列的顺序,假设,由Y′代表调整顺序后的矩阵,则利用式(14)进行表述
从式(14)中可以表述出,贡献率越大,Y中的数据列在Y′中所对应的数据列排序越靠前,则在可视化呈现中显示顺序越靠前。
3.数据列权重
将Y′的每一列的权重大小定义为贡献率,并将Y′每一列与对应的贡献率相乘,则利用式(15)表述
假设,由λnew代表新的数据贡献率,利用式(16)计算λnew中任意两行i,j间的距离
式中,D(i,j)代表未加入贡献率因素前i,j的距离。
附图说明
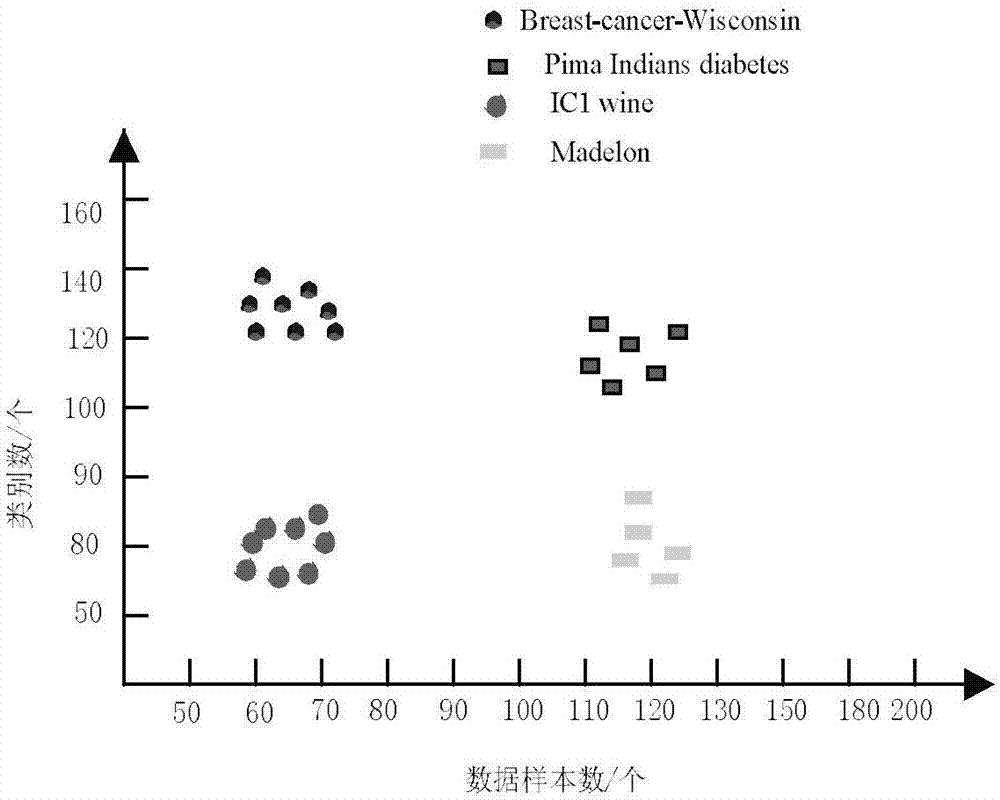
图1本发明方法的数据可视化效果;
图2为文献[2]算法的数据可视化效果。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
在进行高维数据标准化处理优化过程中,需要在对云计算网络中高维数据可视化的基础上才能完成,先对云计算网络中全部的高维数据进行降维,将高维数据投影至二维数据空间上,提取高维数据集中类别和其特征间的关系,搜索不同数据特征排列顺序和最优映射,在此基础上对数据集进行分类,利用其结果完成对高维数据的可视化处理,实现高数据标准化处理,具体的步骤如下详述:
假设,由xi输入云计算环境下的高维数据,xi=(xi1,xi2,xid)T代表xi的d维特征向量,则利用式(1)对云计算网络中全部的高维数据进行降维,将高维数据投影至二维数据空间上;
式中,wj代表全部高维数据相同维度的向量,ε(t)代表样本数据集。λ(k)代表特征间相似度的平均值,公式1中的j=1,…,d,x为高维数据矩阵,wc为所要降维的数据矩阵。
假设,由cv(i,j)代表高维数据样本间的相似度,vk(i)代表随机的高维数据特征向量,则利用式(2)提取高维数据集中类别和其特征间的关系
式中,cvn×n代表高维数据的变换矩阵。
假设,由cvn×n代表高维数据的变换矩阵,代表不同类型高维数据的特征值,满足于(k=1,2,3...)的条件,则搜索不同数据特征排列顺序和最优映射,利用式(3)建立高维数据的可视化模型
式中,prox(i,j)代表样本(i,j)之间的相似度,λ(k)代表特征间相似度的平均值。
以式(3)为依据,利用式(4)对全部的高维数据集进行标准化处理
但是传统方法不能有效消除冗余数据和信息,可视化效果差,降低了数据标准化处理的效果。提出一种基于改进PCA的云计算网络中高维数据可视化方法,对云计算网络中高维数据进行标准化处理优化;包括高维数据特征矩阵的组建和基于高维数据可视化的数据标准化处理优化两部分。
高维数据特征矩阵的组建
在对高维数据可视化过程中,将原始高维数据矩阵中的变量进行标准化处理,给出新的高维数据特征矩阵,将矩阵中的特征值按顺序进行排列,选取方差最大的主成分数据。具体的步骤如下详述:
假设,由代表云计算网络下原始数据矩阵,将X代表的各变量进行标准化预处理,利用式(5)获取标准化数据矩阵
式中,xi,j代表第i个高维数据的第j个类别属性,代表第i个高维数据的协方差矩阵,代表第i个高维数据的低维嵌入空间。
则利用式(6)和式(7)计算出
假设,由C代表协方差矩阵,则利用式(8)计算出C
利用雅可比法得到C的特征值矩阵Λ=diag(λ1,λ2,...λm)和特征向量W。
通过以上阐述,将各个数据的特征值依据顺序排列λ1>λ2>…>λm,并对特征向量列的顺序进行相应的调整,促使第一个主成分具有最大的方差,促使第二个主成分具有次大的方差,而将最小的方差对应第d个主成分。选取方差最大的k个主成分,并促使k个主成分能够保留大部分的原始信息,一般情况下使选取的k个主成分的累积方差贡献大于总方差的85%,即假设,由wi代表选择的k个主成分的特征向量,则利用式(11)得到k个独立的线性组合新变量;
综上所述可以说明,在对高维数据可视化过程中,将原始高维数据矩阵中的变量进行标准化处理,给出新的高维数据特征矩阵,将矩阵中的特征值按顺序进行排列,选取方差最大的主成分数据,为实现对高维数据可视化奠定了基础。
基于高维数据可视化的数据标准化处理优化
综合考虑主成分贡献率因素和列间的相似度,提出了新的数据列排序方法,主要过程如下:假设,由Y代表主成分转换后的数据矩阵,以获取的ξk为依据,利用式(12)计算出Y
式中,FC代表不同类别数据的类间分离度,G代表高维空间聚类数据,ω*代表类内聚集度。
1.贡献度因子计算
首先计算得到的列间的相似度矩阵为
其中Sij表示第i列与第j列的相似度。则对于第i列,和其他所有列的平均相似度为
Ti可以反映第i列和其他列的相似程度,因此可以定义新的贡献度因子为
式中,ai代表贡献度因子权值,该贡献度因子由主成分贡献率因素和列间的相似度的乘积得到,可以更好地反映各列的重要性程度。
2.数据排序
对gi代表的贡献度因子依据从大到小的顺序排列,而且要相应的调整其对应在Y中列的顺序,假设,由Y′代表调整顺序后的矩阵,则利用式(14)进行表述
从式(14)中可以表述出,贡献率越大,Y中的数据列在Y′中所对应的数据列排序越靠前,则在可视化呈现中显示顺序越靠前。
3.数据列权重
1)将Y′的每一列的权重大小定义为贡献率,并将Y′每一列与对应的贡献率相乘,则利用式(15)表述
假设,由λnew代表新的数据贡献率,利用式(16)计算λnew中任意两行i,j间的距离
式中,D(i,j)代表未加入贡献率因素前i,j的距离。
仿真证明
为了证明提出的基于改进PCA的云计算网络中高维数据可视化方法进行高维数据标准化处理的有效性,需要进行一次实验。实验选取的硬件系统为2.8GHz CPU,1G内存的计算机,实验中的数据集来源于http://dbgroup.cs.tsinghua.edu下载。所选数据集经常用于文献中各种模式识别任务的性能比较,表1给出实验数据集的样本数、特征数和类别数。
表1实验数据集信息
其中,Nd代表数据名称,Ns代表样本数,Cs代表特征数,Nc代表类别数,
为了保障高维数据可视化实验的公平性,分类器错误率的估计采用6V,取6次独立实验的平均结果,11V是指将数据集样本共分成6份。因为可视化效果的优劣直接影数据标准化处理优化效果,因此本发明对高维数据可视化的效果进行验证。
不同算法分类错误率
分别采用本文算法和文献[2]、文献[1]算法进行云计算网络中高维数据可视化实验。比较3种不同算法的高维数据分类错误率,对比结果见表2。
表2不同算法分类错误率对比
其中,Nd代表数据名称,Pa代表本发明方法的错误率,La[9]代表文献[2]算法的错误率,La[8]代表文献[1]算法的错误率。
从表2中可以分析得出,利用本发明方法进行云计算网络中高维数据可视化分类的错误率远远低于文献[2]、文献[1]算法进行云计算网络中高维数据可视化分类的错误率,这主要是因为在利用本文算法进行高维数据可视化时,用主成分贡献率得到转换后的高维数据列间距离,利用分级聚类算法对转换后的高维数据按行重新组建,从而保障了本发明方法进行云计算网络中高维数据可视化数据分类的精确性。
不同算法进行高维数据可视化的效果对比
分别采用本发明方法和文献[2]进行云计算网络中高维数据可视化实验。比较2种不同算法的高维数据可视化效果。对比结果见图1和图2。
从图1和图2中分析可以得出,利用本发明方法进行云计算网络中高维数据可视化的效果要优于文献[2]进行高维数据可视化的效果,这主要是因为在利用文献[2]进行高维数据可视化时,先将原始高维数据矩阵中的变量进行标准化处理,给出新的高维数据特征矩阵,将矩阵中的特征值按顺序进行排列,选取方差最大主成分数据,从而保障了本发明方法进行高维数据可视化的优越性。
仿真结果表明,所提方法具有较好的可视化和分类效果。
- 还没有人留言评论。精彩留言会获得点赞!