一种重新表示路网轨迹数据的方法与流程
本发明属于轨迹数据计算技术领域,具体涉及一种重新表示路网轨迹数据的方法。
背景技术:
轨迹数据是一种基本的时空数据,通常定义为位置关于时间的函数。经车载定位设备采样得到的轨迹点用(x,y,t)三元组表示,其中x和y分别为经度和纬度,而t为该采样点的时间戳。于是原始路网轨迹可用一个三元组序列表示,即<(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)>,其中,n即为轨迹的长度,而(xi,yi)是车辆在ti时刻的位置。随着车载定位设备的普及,城市中车辆产生了海量的路网轨迹。这些路网轨迹数据承载了大量信息,在分析城市交通状况、挖掘人的行为模式和预测车辆流动方向等问题中常作为重要决策依据和信息来源。城市路网用一个有向图G=(V,E)表示,其中V为道路的交叉点集合,而E为路口之间的路段集合。
数据压缩算法分为无损压缩和有损压缩两类。无损压缩不产生信息损失,即压缩后数据可以完全还原为原始数据;相反有损压缩通过直接舍弃数据中不影响精度要求的部分,来达到更高的压缩率,但是压ω缩后数据存在信息损失。无损压缩算法又分为熵编码和字典式编码两种。常用的熵编码有Huffman编码和算术编码;字典式编码常用Lempel-Ziv编码及衍生出的其他算法。有损压缩算法是针对某些特殊数据设计的专门算法,例如对于图像的JPEG压缩和对于音频的MPEG压缩,和无损压缩不同,这些方法只针对特定的数据(如图像和音频)。针对一般轨迹数据和路网轨迹数据,也有特定的有损压缩算法,这些方法通常直接删除原始轨迹中不影响数据精度的采样点。
原始路网轨迹数据由于是从移动定位设备采样得到,通常表为一个三元组序列T=〈(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)〉,然而这种表示包含了不必要的冗余,不利于数据压缩。根据原始数据表示方法的局限性,我提出一种新的轨迹格式和一种对应的数据分解方法来直接减少数据冗余,使其易于被压缩算法处理。
技术实现要素:
压缩率是衡量数据压缩算法性能的关键指标之一,通常被定义为原始数据和压缩后数据大小的比值。给定原始轨迹T,设其大小为|T|;而压缩后轨迹为Tc,大小为|Tc|,则压缩率为例如,原始数据大小为2KB,而压缩后数据大小为1KB,则数据压缩率为2。
首先考虑在原始轨迹上使用通用的无损压缩算法(sourcecoding)。如果我们直接对原始轨迹数据使用经典的无损压缩算法,由于数据压缩的理论背景是信息论,从信息熵的角度来分析对于轨迹数据压缩问题,可以证明,无论是熵编码还是字典式编码,当实数数据的精度提升时,算法对于轨迹数据的压缩率都将变得很低。
定理:当实数数据的精度提升时,熵编码和字典式编码对于轨迹数据的压缩率都趋向于1。
证明:首先我们证明熵编码对于高精度实数数据是低效的。设X为一连续分布,其概率密度函数为p(x)。为了计算X的熵,我们首先将X的样本空间ω=[a,b)等分为n份,每个小区间的长度为Δ=(b-a)/n。设[a,b)被分为{[a=x0,x1),[x1,x2),…[xn-1,xn=b)},x落在每一区间内的概率构成了离散分布,其概率分布列可用积分计算:
根据积分中值定理,必然存在使得:
换言之,该离散分布的熵为
如果函数p(x)log p(x)黎曼可积,则有
其中,h(X)是连续分布X的微分熵。
上述等式中的n就是数据的精度,因为区间划分越细,用以表示不同数据的符号就越多,即数据的精度越高。如果不对数据作压缩,我们可以直接用比特来存储每一个符号。根据Shannon的信源编码定理以及熵编码算法的最优性,当n趋向于无穷时,对于数据压缩率r有:
综上所述,当数据精度提升时,熵编码的压缩率将趋近于1,即无法压缩数据。
和熵编码不同,为了计算字典式编码的压缩效果,需要分析信源分布的联合熵,但是证明的过程是类似的。给定任意k个字符,设p(x1,x2,…xk)是X1,X2,…Xk的联合概率密度函数。则最优平均编码长度Lk必然满足:
即我们需要至少H(X1,X2,…Xk)比特来表示k个字符。
类似地,我们将采样空间ω=[a1,b1)×[a2,b2)×…[ak,bk)划分为nk部分,每一块的大小为然后计算离散分布的熵为:
所以,如果有k项数据,且它们的精度为n,则至少需要HΔ(X1,X2,…Xk)比特来编码这些数据。如果p(x1,x2,…xk)log p(x1,x2,…xk)黎曼可积,则还有:
其中,h(X1,X2,…Xk)是联合微分熵。最后我们可以计算压缩率r:
证毕。
虽然有损压缩算法可以达到很高的压缩率,但是要以牺牲数据的精度为代价。大部分已有算法直接从原始轨迹中删除采样点,这将导致原始轨迹和压缩后轨迹之间存在巨大的偏差。如果精度要求较高,即严格框定压缩产生的信息损失,那么这些有损压缩算法的压缩率也会很低。最极端地,如果要求信息损失为零,这时有损压缩等价于无损压缩,则这些有损压缩算法也会通用的无损压缩算法一样低效。
基于以上讨论可知,限制数据压缩率的关键因素,是轨迹数据的表示方法,而不是所采用的压缩算法。事实上,熵编码算法和字典式编码算法都已被证明是最优的压缩算法,即它们都达到了信源的熵(或熵率)。在信息论中,信息熵衡量了信源的不确定性,信源不确定性越高,我们从信源输出中得到的信息量就越多,也即需要更多的数据来编码。考虑已有的轨迹三元组表示,它适用于表示二维空间中的任意轨迹。然而路网轨迹的形状被道路严格限制,其不确定性明显小于任意二维轨迹。换言之,原始的轨迹表示方法引入了不必要的不确定性(不必要的信息),这使得用原始三元组表示的轨迹数据难以被压缩。
本发明通过降低数据维度(dimensionalityreduction)来去除数据中不必要的不确定性。假设将三维的轨迹数据(xi,yi,ti)转而用二维形式(di,ti)表示,则其基础压缩率就已经达到了1.5。注意这种转换必须是无损的,即转换前后数据之间必须存在一一对应关系,否则等同于直接对数据用有损压缩。在数据压缩之前预先缓缓数据的表达形式,不仅直接提升了数据压缩率,也使得数据易于被后续的压缩算法处理。
原始轨迹中,采样点(xi,yi,ti)表示在时间ti,目标位于位置(xi,yi)。设(x1,y1)是轨迹的起始采样点,从起始位置(x1,y1)到当前位置(xi,yi)的距离di是确定的。相反,如果知道了从起始点开始的行程,对应的位置(xi,yi)却难以确定。故为了建立原始轨迹到分解后轨迹之间的一一对应关系,还需要额外保存道路序列<e1,e2,…,em>,其中ei是E中的边而m轨迹经过的道路的数量。
至此,已经将轨迹分解为两部分,即空间数据——道路序列,时间数据——距离-时间序列,也即轨迹数据的新格式:轨迹T的道路序列是T在路网G=(V,E)中经过的一系列连续道路,即SPT=<e1,e2,…,em>;(路网G=(V,E)中,V为图顶点(即道路的交叉路口)集合,而E为连接图顶点之间边(即连接路口之间的路段)的集合;V=<v0,v1,v2,…,vm>,E=<e1,e2,…,em>,vi为有向边边ei-1的终点,或边ei的起点。轨迹T的距离-时间序列是一系列(di,ti)二元组,其中di是目标从出发点开始移动到时间ti为止的总距离,即TST=<(d1,t1),(d2,t2),…,(dn,tn)>。
给定任意路网轨迹T,将原始轨迹分解或是将分解轨迹还原都可以在O(|T|)时间内完成。经过数据分解之后,轨迹数据被转化为道路序列和距离-时间序列。接下来,COMPRESS对道路序列用无损压缩,而对距离-时间序列用有损压缩。之所以对道路序列用无损压缩,是因为道路序列是整数序列,其信息熵较低;而距离-时间序列仍然是实数数据,其信息上依旧较高,所以需要用有损压缩。
根据上述分析,本发明提出的重新表示路网轨迹数据的方法,是将路网轨迹数据分解为空间数据和时间数据两部分;其中:
(1)原始GPS采样轨迹格式为T=<(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)>,其中采样点(xi,yi,ti)表示在时间ti,移动目标位于二维坐标位置(xi,yi),坐标值xi,yi和时间戳ti均为实数数据;
(2)将轨迹分解为两部分:空间数据和时间数据;
所述空间数据为道路编号序列,用于表征轨迹的空间形状;
所述时间数据为距离-时间二元组序列,用于表征轨迹速度变化;
所述道路编号序列具体表示行式为:
(1)经过地图匹配后的轨迹数据不再含有GPS采样误差,即轨迹点都被修正,采样点位置距离对应地图道路不存在偏差;
(2)地图匹配后每个采样点都在地图道路上,因此可以得到采样点对应的道路编号。原采样点序列对应的道路编号序列SPT=<e1,e2,…,em>,即为分解后的空间数据;其中ei是E中的边,m为轨迹经过的道路的数量;
(3)也可用地图的顶点序列来表示空间数据,即SPT=<v0,v1,v2,…,vm>,其中vi为有向边边ei-1的终点,或边ei的起点,用顶点表示道路序列和用边表示是等价的。
所述距离-时间二元组序列表示形式为:(di,ti),di是目标从出发点开始移动到时间ti为止的总距离,即二元组序列TST=<(d1,t1),(d2,t2),…,(dn,tn)>作为分解后的时间数据。
将原始轨迹分解为上述格式的轨迹分解方法,具体步骤为:
(1)对输入轨迹经过地图匹配,使每个采样点都对应到道路上;
(2)输出每个采样点(xi,yi,ti)对应的道路编号ei,对于连续的重复项,只保留其中一项;
(3)计算轨迹每相邻两个采样点(xi-1,yi-1)和(xi,yi)在道路网络中经过的距离,记作li,其中,作l1=0;
(4)对于每个采样点(xi,yi,ti),输出作为距离-时间二元组(di,ti)中的di,而时间戳不变。
轨迹计算中,本发明方法可减少数据库中轨迹存储和查询代价。
附图说明
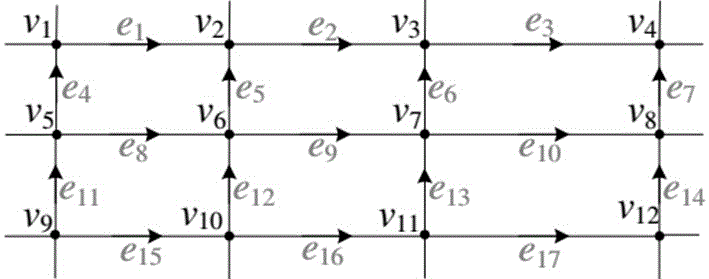
图1为样例道路网路,包含12个路口和17条道路。
图2为路网上的两条样例轨迹。
具体实施方式
下面结合实例道路网络和轨迹来介绍数据格式和轨迹分解方法。
如图1所示,给定道路网络包含12个顶点(路口)和17条边(道路)。考虑轨迹1(蓝色轨迹),由于轨迹都已经过地图匹配,所以所有的采样点均已对应到道路上。在图2中,采样点11对应边15;采样点12对应边16;采样点13对应边13;采样点14对应边16;采样点15对应边3。注意如果采样点恰好落在路口处,则应该统一取后一条边而不是前一条边作为对应的道路序列项,如采样点13对应边13而不是16。所以1的道路序列SP1=<e15,e16,e13,e6,e3>。
为了计算对应的距离-时间序列,需要应用轨迹分解方法。根据计算得到的道路序列和道路形状,可以依次计算两个采样点之间的路网距离,如图1中,11和12之间的距离为(15)+Δ11,其中(15)为道路15的总长度,Δ11为12距离16起始点的距离。为了计算相邻两点之间的距离,需要知道道路的地理形状,一般道路网络中的道路都存储为一条折线,包含若干二维坐标点,将这些二维坐标点依次链接即可模拟实际道路的形状。根据道路形状即可计算落在道路上的采样点之间的距离,仅需根据二维坐标计算欧式距离或者球面距离(用经纬度坐标时)即可。如图1中,11和12之间的距离为1=(15)+Δ11;12和13之间的距离为:2=(16)-Δ11;13和14之间的距离为3=(13)+Δ12;t14和t15之间的距离为l4=w(e6)-Δ12+Δ13。
接下来根据轨迹分解方法中累加得到:
实际上为了方便处理时间数据,可以用第一个采样点所在道路的起始点作为整条轨迹的起始点,如图2中的T2(红色轨迹),我们计算采样点距离v5的距离来替代采样点距离t21的距离。所以得到而时间数据
- 还没有人留言评论。精彩留言会获得点赞!