一种基于多源数据的城市公共开放空间的拥挤度预测方法与流程
本发明属于城市计算技术领域。
背景技术:
城镇化率的提高和人口的增加导致城市公共开放空间的需求量增加,并且城市公共开放空间的拥挤度也会提升。而这会带来城市公共安全和交通秩序的隐患。因此,预测城市公共开放空间的人流拥挤度是十分必要的。但由于人流的方向具有随机性和分散性,所以空间中的人流量很难准确的统计,其拥挤度难以合理的划分和预测。日本的BAB HITACHI IND公司公开了一种通过摄像头的视频图像分析的方法来评估人流的拥挤程度(JP2007180709A)。但该方法无法实现预测且严重依赖于昂贵的摄像头硬件,普及性较差。针对这个问题,合肥城市云数据中心有限公司公开了一种基于Wifi定位和云数据处理技术的人流量预测方法(CN104573859)。它通过Wifi热点获取用户的定位数据,并用户定位数据通过坐标匹配的方法匹配到相应的城市道路坐标上并预测出下个时间段的人流量。尽管该发明实现了人流量的评估预测,但是并不能反应出人流的拥挤程度。为此,杭州华为数字技术有限公司公开了一种测量人群拥挤度的方法、装置与系统(CN104540168)。它通过对现场接入点的信号强度的采集,获得统计参数,并将该参数与人群拥挤度对应关系表匹配来评估空间内人群的拥挤度。该发明解决了拥挤度的评估问题,但人流量的计算评估依赖于可发射信号的硬件装置,需要佩戴专门的硬件并且经济性较差。最近,重庆邮电大学公开了一种基于移动网络信令数据的人流拥挤预测技术(CN105512772),它根据一个目标区域的周边区域人流量转移和离开概率来预测目标区域的人流量,并根据划分好的拥挤等级来评估拥挤度。尽管该技术方法实现了不依赖于硬件设备的人流拥挤度评估和预测,但它基于的手机信令数据不是一种实时公开的数据,同时拥挤的等级划分也较为主观,从而造成通用性较差的问题。
综上所述的方法都存在硬件投入较大或只依赖于单一数据源分析预测,从而造成技术方法的经济性和通用性差的问题。
技术实现要素:
本发明的目的是针对现有技术的不足,全新的提出一种基于多源数据的城市公共开放空间的拥挤度预测方法。
本发明的目的是通过以下技术方案来实现的:
本发明全新的提出了一种基于多源数据的城市公共开放空间的拥挤度预测方法,其特征在于,该方法表征为:
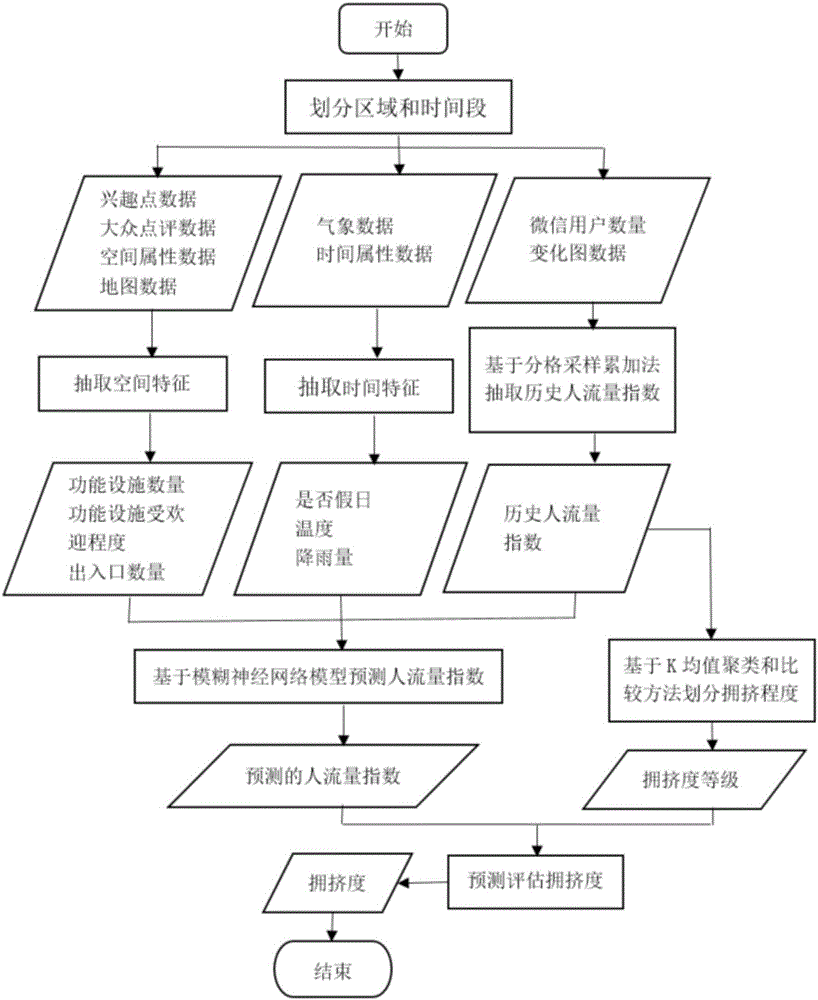
第一大步骤,将空间划分为多个小区域,每个区域是200m×200m。将一天划分为四个时段(0:00-6:00,6:00-12:00,12:00-18:00,18:00-0:00)。
第二大步骤,从兴趣点数据、大众点评数据、空间属性数据、地图数据提取出每个区域的3个空间特征:区域周边功能设施数量、周边功能设置受欢迎程度、区域出入口数量。同时,从气象数据和时间属性数据提取出每个区域在不同时段的3个时间特征:是否假日,当前时段温度,是否降雨。同时,利用分格采样累加法从微信用户数量变化图数据中获得一个区域在不同历史时段内的人流量指数。
在该步骤中,总共提取17个参数。3个空间特征包含的具体参数为13个:一个区域周边500米范围内的6种功能设施的数量即⑴写字楼数量、⑵商店数量、⑶餐馆数量、⑷宾馆数量、⑸地铁站数量、⑹公交车站数量;一个区域周边500米范围内的这6种功能设施在大众点评网上的评论总数即⑺写字楼的评论总数、⑻商店的评论总数、⑼餐馆的评论总数、⑽宾馆的评论总数、⑾地铁站的评论总数、⑿公交车站的评论总数、⒀该区域的出入口数量。3个时间特征包含的具体参数为3个:⒁摄氏温度、⒂降雨量(mm)、⒃假日与否(假日是1,工作日是0)。以及参数⒄不同区域在不同历史时段内的人流量指数。
在该步骤中,基于利用分格采样累加法抽取历史人流量指数:从微信用户数量变化图数据中获取每个小空间区域在不同历史时段的人流量指数。它包括三个小步骤,首先将每天的微信用户数量变化图放置在X轴和Y轴中,X轴表示时间,Y轴表示人流量。并将该数量变化图划分为96×96个小格子,即在X轴平均取96个点。Y轴平均取96个点。其次,X轴上每个点对应的Y轴的值是当前时间的人流量指数,取X轴上96个点对应的人流量指数值。最后,在X轴上按照顺序依次取4个点,对应的Y值累加即表示1小时内的人流量指数。根据此法,从X轴取的96个点对应的Y值按照每隔4个点逐个累加,可以得到一天24小时的人流量指数。
第三大步骤,将第二大步骤中抽取的时空特征和历史人流量指数包含的17个参数的依次输入到经典的模糊神经网络模型中所对应的各个变量,实现模型的训练和人流量指数预测。在经典的模糊神经网络模型中,首先,将已收集到的参数⑴至⒃的历史数据值输入到模糊神经网络模型的输入层X1至X16,以及参数⒄对应的历史数据值输入到解模糊层y,实现模型的训练和建立;其次,输入需要预测时段的参数⑴至⒃的数据值到输入层X1至X16,通过建立好的模型进行计算,最终得出y的预测值即预测的人流量指数。在该模型中的隶属函数层、规则层、解模糊层都是模糊神经网络这个经典模型的固定计算过程部分,只需要将选定好的参数输入并得到最终结果即可,不必关心中间的运算过程。经典的模糊神经网络模型的原理和数学表达如下(已属于现有技术)。
(1)输入层:
xi,i=1,2,…n其中,xi就是第i个输入。N=17,即第二大步骤中提取17个参数。
(2)隶属函数层:
μ2ij(xi)=exp[-(xi-wik)2/σ2ik],i=1,2,…n;k=1,2,…H,H个模糊规则,本方法中H=10。(已属于现有技术)
(3)规则层:
μk=Пniμ2ij(xi)k=1,2,…H。(已属于现有技术)
(4)解模糊层:
y=ΣHk=1μkvk/ΣHk=1μk y即为输出。(已属于现有技术)
同时,将第二大步骤中获得的历史人流量指数,通过经典的K均值聚类算法划分为4类,每一类代表一种拥挤度等级,按照每类的平均人流量指数从小到大分别为稀疏、不拥挤、拥挤和非常拥挤。在经典的K均值聚类算法中的公式步骤等是该模型固定的计算过程,只需要将不同时段的历史人流量指数作为待聚类样本集合X输入到模型中即可,不必关心中间的运算过程。经典的K均值聚类算法的原理和数学表达如下。
设含n个待聚类样本集合X={x1,x2,…x3},其中每个样本xk(k=1,2,…,n)有d个特性指标,xkl(1≤k≤n,1≤l≤d)表示第k个样本第l个特性指标,则样本集X特性指标矩阵:
将样本集X分成k(2≤k≤n)个类别,令mj(j=1,2,…,k)表示第j个聚类的聚类中心,mjl表示第j个聚类中心第l个特性指标,则k个聚类中心向量组成的聚类中心矩阵:
K均值聚类算法的基于内误差平方和的聚类目标函数如下。其中nj表示第j个聚类样本子集样本个数,xk(j)表示第j个子集的样本。
Jk=Σkj=1Σnjk=1||xk(j)-mj||2
求得聚类中心,其函数如下。mj表示聚类中心。
Mj=Σnjk=1xk(j)/nj,j=1,2,…,k
第四大步骤,将第三步中获得的预测的人流量指数和拥挤度等级转化为拥挤度。在该步骤中,将预测出的人流量指数与每一类拥挤度等级的最大人流量指数比较,如果小于稀疏类型的最大人流量指数,拥挤度则划分为稀疏级别;如果大于稀疏类型的最大人流量指数,而小于不拥挤类型的最大人流量指数,拥挤度则划分为不拥挤级别;依次类推,则可以得到预测的拥挤度。
该发明成功的通过开放的城市多源数据实现了拥挤度预测。解决了传统的拥挤度预测方法过度依赖硬件设备而造成预测成本过高,以及单一数据源无法准确预测的技术难题。从而在降低预测经济成本的同时提升了预测精度。
本发明与现有技术相比,具有的有益效果是:
(1)采用了公开的城市多源数据来表达空间区域的时空特征,有效的提高了空间人流拥挤度的预测精度,并成功的解决了过度投入硬件造成经济性差的问题,同时降低了数据的获取难度,而更具有通用性。
(2)通过分格采样累加法从公开的微信用户数量变化图数据中获取人流量指数,从而很容易的获取一个区域的人流量,解决了公开的微信用户数量图没有具体数值的问题。同时也解决了人流量数据难以获得,实时性差的问题。
(3)通过聚类比较的方法,在人流量指数的基础上,从可观的、科学的角度对人流量拥挤度的大小进行分级和分类,避免了人流量无法完全精确统计和主观对拥挤度分级而造成的拥挤度预测不准确问题。
附图说明
图1是一种基于多源数据的城市公共开放空间的拥挤度预测方法的工作原理图。
图2是一种基于多源数据的城市公共开放空间的拥挤度预测方法的流程图。
图3是分格采样累加法的流程图。
图4是预测的人流量转化为拥挤度的流程图。
图5是通过分格采样累加法将微信用户数量图进行分格的示意图。
图6是利用分格采样累加法对整时人流量进行采样的示意图。
图7是实施例中在不同时间段人流量预测结果与真实结果的曲线比较图。
具体实施方式
本发明一种基于多源数据的城市公共开放空间的拥挤度预测方法包括如下步骤:
(1)空间和时段划分:将一个城市公共开放空间划分为多个小的空间区域,每个区域是200m×200m,并且把一天平均划分为4个时间段,分别是0:00-6:00,6:00-12:00,12:00-18:00,18:00-0:00,每个时间段包含6个小时。
(2)区域时空特征的表达方法:从地图数据、兴趣点数据、兴趣点评论数据、区域属性数据抽取内容来表达每个区域的空间特征,抽取的内容包括该区域周边500米范围内的六种功能设施的数量即写字楼数量、超市和商店数量、餐馆数量、宾馆数量、地铁站数量、公交车站数量,该区域周边500米范围内所有的六种功能设施在大众点评网上的评论总数,以及该区域的出入口数量。从气象数据和时间属性数据抽取内容来表达每个区域的时间特征。抽取的内容包括一个区域在某时段的摄氏温度、降雨量、某时段是工作日还是假日。
(3)历史人流量指数的计算方法:利用分格采样累加法,从微信用户数量图数据中获取每个小空间区域在不同历史时段的人流量指数。即将每天的微信用户数量变化图放置在X轴和Y轴中,X轴表示时间,Y轴表示人流量。并将该数量变化图划分为96×96个小格子,即在X轴平均取96个点。Y轴平均取96个点。X轴上每个点对应的Y轴的值是当前时间的人流量指数。在X轴上按照顺序依次取4个点,对应的Y值累加即表示1小时内的人流量指数。根据此法,从X轴取的96个点对应的Y值按照每隔4个点逐个累加,可以得到一天24小时的人流量指数。
(4)人流量指数的预测方法:将每个小区域按照1天中划分的4个时段,在模糊神经网络模型中,逐个输入每个时段内的时空特征和历史人流量指数,随后逐个输出未来一天的4个时段内的人流量指数。实现人流指数的预测。
(5)拥挤度的预测方法:利用聚类评估分级法将预测的人流量指数转化为拥挤度。即将一个区域在不同历史时段内的人流量指数进行层次聚类分析,依据每类的最大人流量指数,按照从大到小的顺序排列,输出4类,分别是非常拥挤类型,拥挤类型,不拥挤类型和稀疏类型。将预测出的人流量指数与每一类的最大人流量指数比较,如果小于稀疏类型的最大人流量指数,拥挤度则划分为稀疏级别;如果大于稀疏类型的最大人流量指数,而小于不拥挤类型的最大人流量指数,拥挤度则划分为不拥挤级别;依次类推,则可以得到预测的拥挤度。
下面根据实施例详细描述本发明,本发明的目的和效果将变得更加明显。以下结合附图和实例对本发明技术方案做进一步介绍。
实施例
(1)将中国上海市的上海滨江步行道中段(从花园石桥路到东园路)作为实施例,收集了从2016年5月1日至2016年8月7日的数据。将2016年5月1日至2016年7月31日的数据作为训练数据,2016年8月1日至2016年8月7日数据作为测试集。上海滨江步行道中段全长约1600m,最宽处为187m。将空间划分为8个长为200米的区域。一天平均划分为4个时间段,分别是第1个时段0:00-6:00,第2个时段6:00-12:00,第3个时段12:00-18:00,第4个时段18:00-0:00,每个时间段包含6个小时。
(2)在划分好的8个区域基础上,首先提取空间特征。即分别抽取每个区域周边500米的六种功能设施的数量、大众点评网上对这六种功能设施的评论总数,区域的出入口数量。区域1的写字楼数量66个、超市和商店数量64个、餐馆数量371个、宾馆数量49个、地铁站数量0个、公交车站数量31个、评论总数1481276条、出入口3个。区域2的写字楼数量69个、超市和商店数量65个、餐馆数量389个、宾馆数量53个、地铁站数量0个、公交车站数量34个、评论总数1491276条、出入口4个。区域3的写字楼数量76个、超市和商店数量69个、餐馆数量413个、宾馆数量62个、地铁站数量1个、公交车站数量34个、评论总数1551276条、出入口12个。区域4的写字楼数量86个、超市和商店数量71个、餐馆数量555个、宾馆数量73个、地铁站数量1个、公交车站数量32个、评论总数1711276条、出入口12个。区域5的写字楼数量76个、超市和商店数量68个、餐馆数量512个、宾馆数量69个、地铁站数量1个、公交车站数量28个、评论总数1552276条、出入口4个。区域6的写字楼数量75个、超市和商店数量30个、餐馆数量413个、宾馆数量61个、地铁站数量1个、公交车站数量28个、评论总数1421376条、出入口3个。区域7的写字楼数量71个、超市和商店数量52个、餐馆数量310个、宾馆数量62个、地铁站数量1个、公交车站数量30个、评论总数1396321条、出入口3个。区域8的写字楼数量56个、超市和商店数量45个、餐馆数量271个、宾馆数量32个、地铁站数量0个、公交车站数量26个、评论总数1421376条、出入口2个。其次提取时间特征,提取8个区域在2016年5月1日至2016年7月31日中每天4个时段的摄氏温度和降雨量,并统计出工作日和假日。
(3)对2016年5月1日至2016年8月7日的每天的微信用户数量图划分为96×96个小格子,在X轴上平均取96个点,并得到对应的Y值即每个时刻对应的人流量指数,按照每天划分的4个时段,累加计算每个时段的人流量指数。其工作示意图见附图2和3。
(4)将(2)和(3)步骤中得到的时空特征与训练集中的人流量指数输入模糊神经网络模型,得到预测出的8个区域在1周内每天四个时段的人流量指数。预测的人流量指数与测试集中实际人流量指数结果比较见附图7。图7是本实施例中在不同时间段人流量预测结果与真实结果的曲线比较图。其中:
7(a)是实施例中,8个区域在7天内第1时段人流量预测结果与真实结果的曲线比较图;
7(b)是实施例中,8个区域在7天内第2时段人流量预测结果与真实结果的曲线比较图;
7(c)是实施例中,8个区域在7天内第3时段人流量预测结果与真实结果的曲线比较图;
7(d)是实施例中,8个区域在7天内第4时段人流量预测结果与真实结果的曲线比较图。
(5)将训练集中的人流量指数进行K均值聚类分析,得到稀疏级别、不拥挤级别、拥挤级别、非常拥挤级别的人流量指数取值范围。稀疏级别的人流量指数是0到94,不拥挤级别的人流量指数是94到289、拥挤级别的人流量指数是289到576、非常拥挤级别的人流量指数是576以上。2016年8月1日至8月7日的4个时段(第1个时段)拥挤度预测结果为:区域1在7天里的4个时段均为稀疏级别。区域2在7天里的第1、2、4时段均为稀疏级别,在第3时段均为不拥挤级别。区域3在7天里的第1、4时段均为稀疏级别。在1至5日的第2时段为稀疏级别,6、7日的第2时段为不拥挤级别,在1至7日的第三时段均为拥挤级别。区域4在7天里的第1时段均为稀疏级别,第2时段均为不拥挤级别。在1日至5日的第3时段为拥挤级别,6,7日为非常拥挤级别。在2日至4日的第四时段为不拥挤级别,在1、5、6、7日第4时段为拥挤级别。区域5在7天里的第1、2个时段均为稀疏级别,在1日至5日第3时段为不拥挤级别,6,7日的第三时段为拥挤级别,在1日至5日的第4时段为稀疏级别,6、7日为不拥挤级别。区域6和区域7天里的4个时段均为稀疏级别。拥挤度的预测误差仅为2.1%。
本发明全新的提出一种基于多源数据的城市公共开放空间中拥挤度预测方法通过使用城市多源数据融合的方法避免了单一数据难以完整获取而导致无法研究的问题,并避免了过度依赖硬件设备而造成预测经济成本过高的问题。同时本发明提出的方法也从一个全新的角度预测和评价了空间的拥挤度,这为城市问题诊断和应急管理提供了重要的参考。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!