打包数据操作掩码串接处理器、方法、系统及指令与流程
技术领域
实施例涉及处理器。具体地,实施例涉及响应于打包数据操作掩码串接指令而串接打包数据操作掩码的处理器。
背景技术:
许多处理器具有单指令多数据(SIMD)架构。该SIMD架构通常有助于显着提高处理速度。在SIMD架构中,与仅在一个数据元素或一对数据元素上操作标量指令不同,打包数据指令、向量指令、或SIMD指令可在多个数据元素、或多对数据元素上同时或并行地操作。处理器可具有并行执行硬件,该并行执行硬件响应于打包数据(packed data)指令来同时或并行地执行多个操作。
在SIMD架构中,可将多个数据元素打包在一个寄存器或存储器位置内作为打包数据或向量数据。在向量数据中,寄存器或其他存储位置的位(比特)可被逻辑地划分成多个固定尺寸的数据元素的序列。数据元素中的每一个可表示个体数据片,该个体数据片连同通常具有相同尺寸的其他数据元素一起被存储在寄存器或存储位置中。例如,256位宽寄存器可具有四个64位宽打包数据元素,八个32位宽打包数据元素,十六个16位宽打包数据元素,或三十二个8位宽打包数据元素。每一打包数据元素可表示独立的个体数据片(例如,像素的颜色等),该数据片可单独地操作或与其他数据片独立地操作。
代表性地,打包数据指令、向量指令或SIMD指令(例如,打包加法指令)中的一种类型可指定在来自两个源打包数据操作数的所有相应数据元素对上以垂直方式执行单个打包数据操作(例如,加法)以生成目的或结果打包数据。这些源打包数据操作数是相同尺寸,可包含相同宽度的数据元素,并因此可各自包含相同数量的数据元素。两个源打包数据操作数中的相同的比特位置中的源数据元素可表示相应的数据元素对。可分开地或独立地对这些相应的源数据元素对中的每一个上执行打包数据操作,以便生成匹配数量的结果数据元素,且因而每一对相应的源数据元素可以具有相应的结果数据元素。通常,这样的指令的结果数据元素是相同次序的,且它们常常具有相同的尺寸。
除这种示例性类型的打包数据指令之外,还有各种其它类型的打包数据指令。例如,存在仅具有一个源打包数据操作数或具有两个以上的源打包数据操作数的打包数据指令、以水平方式而不是垂直方式操作的打包数据指令、生成不同尺寸的结果打包数据操作数的打包数据指令、具有不同尺寸的数据元素的打包数据指令和/或具有不同的数据元素次序的打包数据指令。
附图说明
通过参考用来说明本发明的实施例的以下描述和附图,可最好地理解本发明。在附图中:
图1是具有含一个或多个打包数据操作掩码串接指令的指令集的处理器的示例实施例的框图。
图2A是示出采取合并的被掩码(masked)打包数据操作的第一代表性示例实施例的框图。
图2B是例示采取归零操作的被掩码打包数据操作的第二代表性示例实施例的框图。
图3是包括存储有打包数据操作掩码串接指令的机器可读的存储介质的制品(例如,计算机程序产品)的框图。
图4是具有执行单元的指令处理装置的示例实施例的框图,该执行单元可操作用于执行包含打包数据操作掩码串接指令的示例实施例的指令。
图5是可由处理器和/或执行单元响应于打包数据操作掩码串接指令和/或作为其结果而执行的打包数据操作掩码串接操作的示例实施例的框图。
图6是对打包数据操作掩码串接指令的示例实施例进行处理的方法的示例实施例的流程框图。
图7是一组合适的打包数据寄存器的示例实施例的框图。
图8是示出合适打包数据格式的若干示例实施例的框图。
图9是示出打包数据操作掩码位的数目依赖于打包数据宽度和打包数据元素宽度的表格。
图10是一组合适的打包数据操作掩码寄存器的示例实施例的框图。
图11的图例示:在被用作打包数据操作掩码或用于掩码遮蔽的打包数据操作掩码寄存器的示例实施例中,位的数目取决于打包数据宽度和数据元素宽度的图。
图12A-12C例示打包数据操作掩码串接指令和其操作的多种特定示例实施例。
图13是可由处理器和/或执行单元响应于和/或作为打包指令的结果而执行的打包操作的示例实施例的框图。
图14A示出示例性AVX指令格式,包括VEX前缀、实操作码字段、MoD R/M字节、SIB字节、位移字段以及IMM8。
图14B示出来自图14A的哪些字段构成完整操作码字段和基础操作字段。
图14C示出来自图14A的哪些字段构成寄存器索引字段。
图15是根据本发明的一个实施例的寄存器架构的框图。
图16A是示出根据本发明的实施例的示例性有序流水线和示例性寄存器重命名的无序发布/执行流水线二者的框图。
图16B示出处理器核,该处理器核包括耦合到执行引擎单元的前端单元,并且两者耦合到存储器单元。
图17A是根据本发明的各实施例的单个处理器核连同它与管芯上互连网络的连接以及其二级(L2)高速缓存的本地子集的框图。
图17B是根据本发明的各实施例的图17A中的处理器核的一部分的展开图。
图18是根据本发明的实施例的可具有一个以上的核、可具有集成存储器控制器、并且可具有集成图形器件的处理器的方框图。
图19所示为根据本发明的一个实施例的系统的框图。
图20所示为根据本发明的实施例的第一更具体示例性系统的框图。
图21所示为根据本发明的实施例的第二更具体的示例性系统的框图。
图22所示为根据本发明的实施例的SoC的框图。
图23所示为根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。
具体实施方式
本文中公开的是打包数据操作掩码串接(concatenation)指令、用于执行打包数据操作掩码串接指令的处理器、该处理器在处理或执行打包数据操作掩码串接指令时执行的方法、以及包含一个或多个用于处理或执行打包数据操作掩码串接指令的处理器的系统。在下面的描述中,阐述了很多具体细节。然而,应当理解,本发明的各实施例可以在不具有这些具体细节的情况下得到实施。在其他实例中,未详细示出公知的电路、结构和技术以免混淆对本描述的理解。
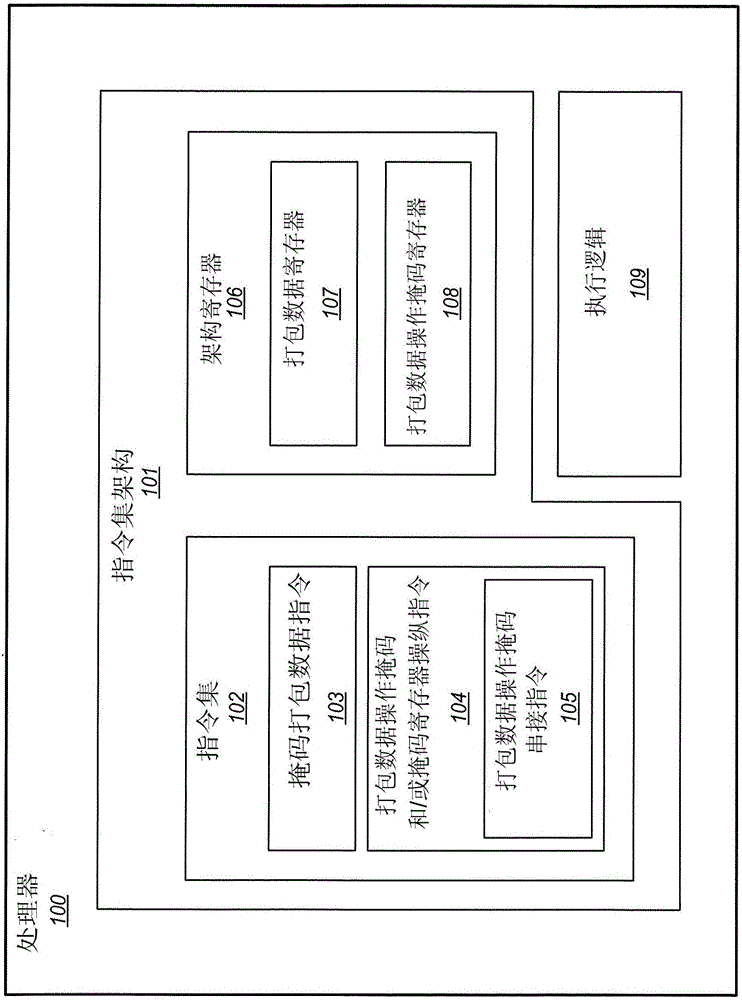
图1是具有含一个或多个打包数据操作掩码串接指令105的指令集的处理器100的示例实施例的框图。该处理器可以是各种复杂指令集计算(CISC)处理器、各种精简指令集计算(RISC)处理器、各种超长指令字(VLIW)处理器、其各种混合、或完全其他类型的处理器中的任何处理器。在一些实施例中,处理器可以是通用处理器(例如,用于台式、膝上型等计算机中的一类通用微处理器),但这不是必须的。替换地,指令处理处理装置可以是专用处理器。合适的专用处理器的示例包括但不限于,网络处理器、通信处理器、加密处理器、图形处理器、协处理器、嵌入式处理器、数字信号处理器(DSP)以及控制器(例如,微控制器),仅列举数例。
处理器具有指令集架构(ISA)101。ISA表示处理器的架构中涉及编程的那部分。ISA通常包括原生指令、架构寄存器、数据类型、寻址模式、存储器架构、中断和异常处理以及处理器的外部输入和输出(I/O)。ISA与微架构不同,微架构通常表示选择用于实现指令集架构的特定处理器设计技术。带有不同的微架构的处理器可以共享共同的指令集架构。
ISA包括架构寄存器(例如,架构寄存器组)106。所示出的体系结构寄存器包括打包数据寄存器107。每个打包数据寄存器可操作用于存储打包数据、向量数据或者SIMD数据。所示出的体系结构寄存器还包括打包数据操作掩码寄存器108。打包数据操作掩码寄存器中的每一个都可操作以存储打包数据操作掩码。
架构寄存器表示板上处理器存储位置。架构寄存器此处也可以被简称为寄存器。短语架构寄存器、寄存器组、以及寄存器在本文中用于表示对软件和/或编程器可见的寄存器(例如,软件可见的),和/或由宏指令指定用以标识操作数的寄存器,除非另外予以指定或清楚明显可知。这些寄存器与给定微架构中的其他非架构寄存器(例如,暂时(temporary)寄存器、重排序缓冲器、引退(retirement)寄存器等)形成对比。
所示的ISA包括处理器所支持的指令集102。指令集包括若干不同类型的指令。指令集的这些指令表示宏指令(例如,提供给处理器以供执行的指令),与微指令或微操作(例如,从处理器的解码器解码宏指令得到的)不同。
指令集包括一个或多个被掩码(masked)打包(packed)数据指令103。被掩码打包数据指令可类似于在背景部分中提及的打包数据指令,且具有一些显着差别。类似于前述打包数据指令,被掩码打包数据指令中的每一个可操作用于导致或致使处理器在该打包数据指令指示的一个或多个打包操作数的数据元素上执行打包数据操作。打包数据操作数可被存储在打包数据寄存器107中。然而,被掩码打包数据指令中的每个指令可使用一个或多个打包数据操作掩码寄存器108和/或打包数据操作掩码以对打包数据处理进行掩码遮蔽(mask)、断言(predicate)或条件控制。打包数据操作掩码和/或掩码寄存器可表示掩码操作数、断言操作数或条件操作控制操作数。
打包数据操作掩码和/或掩码寄存器可操作用于在诸数据元素的粒度下对打包数据处理进行掩码或条件控制。例如,打包数据操作掩码可操作用于掩码设定:在来自单个源打包数据操作数的各个数据元素上、或在来自两个源打包数据操作数的相应数据元素的各个对上所执行的被掩码打包数据指令的打包数据操作的结果是否要存储在打包数据结果中。被掩码打包数据指令可允许与数据元素分开地且独立地断言或条件地控制对每个数据元素或每对相对应数据元素的打包数据处理。被掩码打包数据指令、操作和掩码可提供某些优点,诸如增加的代码密度和/或较高的指令吞吐量。
再次参考图1,指令集还包括一个或多个打包数据操作掩码和/或掩码寄存器操纵指令104。打包数据操作掩码和/或掩码寄存器操纵指令中的每一个可操纵用于导致或致使处理器对一个或多个打包数据操作掩码寄存器108和/或掩码进行操纵或操作。如所示,打包数据操作掩码或掩码寄存器操纵指令可包括一个或多个打包数据操作掩码串接指令105。打包数据操作掩码串接指令105中的每一个可操作用于致使或导致处理器将两个或更多个打包数据操作掩码(例如,存储在打包数据操作掩码寄存器108中)串接。以下进一步公开打包数据操作掩码串接指令的各不同实施例。
处理器还包括执行逻辑109。执行逻辑可操作用于执行或处理指令集的指令(例如,被掩码打包数据指令和打包数据操作掩码串接指令)。执行逻辑可包括执行单元、功能单元、算术逻辑单元、逻辑单元、算术单元等。
为了进一步说明打包数据操作掩码,考虑它们的使用的代表示例是有帮助的。图2A是示出采取合并操作的被掩码打包数据操作203A的第一代表性示例实施例的框图。可响应于被掩码打包数据指令(例如,图1的被掩码打包数据指令103中的一个)或者作为该指令的结果来执行被掩码打包数据操作。
用于所示的被掩码打包数据操作的指令指示第一源打包数据210-1和第二源打包数据210-2。其他被掩码打包数据指令可指示仅单个源打包数据,或多于两个源打包数据。在该例示中,第一和第二源打包数据具有相同尺寸,包含相同宽度的数据元素,并且因此各自包含相同数目的数据元素。在例示中,第一和第二源打包数据中的每一个具有十六个数据元素。作为示例,第一和第二源打包数据可各自为512位宽,并且可各自包括十六个32位双字数据元素。两个源打包数据中相同比特位置中(例如,相同垂直位置中)的源数据元素表示相对应数据元素对。数据元素中的每一个具有在表示数据元素的块内所示出的数值。例如,第一源打包数据的最低位数据元素(右侧)具有值3,第一源打包数据的次最低位数据元素具有值7,第一源打包数据的最高位数据元素(左侧)具有值12,等等。
被掩码打包数据操作的指令还指示打包数据操作掩码211。打包数据操作掩码包括多个掩码元素、断言元素、条件控制元素、或标记。可以按与一个或多个相对应源数据元素一一对应的形式来包含所述元素或标记。例如,如例示中所示,在操作涉及两个源打包数据操作数的情况下,对于每对相应源数据元素,可以有一个这样的元素或标志。打包数据操作掩码的每个元素或标志可操作用于对一个或多个相应的源打包数据元素上的单独打包数据操作进行掩码。例如,在该示例中,每个元素或标记可对相应源打包数据元素对上的单独打包数据操作进行掩码。
如图中所示的,通常每个元素或标志可以是单个位。单个位可允许指定两个不同可能性(例如,执行操作对不执行操作,存储操作的结果对不存储操作的结果等)中的任一个。替代地,如果需要在多于两个的不同选项中进行选择,则可对每个标志或元素使用两个或更多个位。在图示中,打包数据操作掩码包括十六个位(即,0011100001101011)。十六个位中的每一个具有与第一和第二打包数据的相应数据元素的十六个对中的一对的有序对应关系。例如,掩码的最低位比特对应于第一和第二打包数据的对应最低位数据元素的对,掩码的最高位比特对应于相应的最高位数据元素的对,等等。在替换实施例中,其中源打包数据具有更少或更多的数据元素,打包数据操作掩码可类似地具有更少或更多的数据元素。
具体的经例示出的被掩码打包数据操作是被掩码打包数据加法操作,该加法操作可操作用于根据打包数据操作掩码211的相应位提供的条件操作控制或断言,将来自第一和第二源打包数据210-1、210-2的相应数据元素对的和条件性地存储打包数据结果212中。该具体的被掩码打包数据加法操作规定:在每个相应数据元素的对上、与其它对分离或独立于其它对、以垂直方式条件性地执行单个操作(在这种情况下是加法)。目的地操作数或打包数据结果与源打包数据的尺寸相同且具有与源打包数据相同数量的数据元素。因此,每个相应源数据元素的对,在打包数据结果中的与它们相应的源数据元素对在源打包数据中的位置相同的比特位置中,具有相应结果数据元素。
再次参考打包数据操作掩码211。打包数据操作掩码的十六个位中的每一个被置位(即,具有二进制值1)或者被清除(即,具有二进制值0)。根据所例示的协定,每个位被分别置位(即,1)或清除(即,0),以允许或不允许将在第一和第二源打包数据的相应数据元素对上执行的打包数据操作的结果存储在打包数据结果的相应数据元素中。例如,打包数据操作掩码中的次最低位位被置位(即,1),且表示在相应的次最低位数据元素对上执行的打包数据加法操作(即,7+1)的结果的和(即,8)被存储在打包数据结果的相应次最低数据元素中。在例示中,求和通过下划线标出。
相反,当给定的位被清除(即,0)时,不允许相应的源数据元素对的打包数据操作结果被存储在打包数据结果的对应数据元素中。相反,可将另一个值存储在结果数据元素中。例如,如图例所示,来自第二源打包数据的相应数据元素的值可被存储在打包数据结果的相应数据元素中。例如,打包数据操作掩码中最高位比特被清除(即,0),且来自第二源打包数据的最高位数据元素的数值(即,15)被存储在打包数据结果的最高位结果数据元素中。这称为合并-掩码(merging-masking)。与所例示相反的协定也是可能的,其中位被清零(即,0)以允许存储结果,或被置位(即,1)以不允许存储结果。
在一些实施例中,打包数据操作可任选地在第一和第二源打包数据的所有相应数据元素对上执行,而不管打包数据操作掩码的相应位被置位还是清除,但是打包数据操作的结果可被存储或可不被存储在打包数据结果中,这取决于打包数据操作掩码的相应位是被置位还是被清零。替代地,在另一实施例中,如果打包数据操作掩码的相应位指定操作的结果不被存储在打包数据结果操作中,则打包数据操作可被任选地省去(即,不被执行)。在一些实施例中,可任选地,异常(例如,异常标志)或冲突可被抑制,或不被在掩码关闭(masked-off)的元素上的打包数据操作所引起。在一些实施例中,对于具有存储器操作数的被掩码打包数据指令,可任选地针对掩码关闭数据元素抑制存储器错误。该特征可有助于实现控制流断言,因为掩码事实上可提供合并行为打包数据寄存器,但不是必须的。
图2B是例示采取归零操作的被掩码打包数据操作203B的第二代表性示例实施例的框图。采取归零的被掩码打包数据操作类似于前述采取合并的被掩码打包数据操作。为了避免使描述变得模糊,不再重复相似之处,相反,将主要提及不同之处。一个明显的不同之处在于,与在打包数据结果的相应位被掩码关闭(例如,清除为0)时将源打包数据(例如,图2A中的第二源打包数据210-2)的数据元素的值合并或存储到打包数据结果的相应数据元素中不同,打包数据结果的相应数据元素被归零。例如,双字结果打包数据元素的所有32位可具有零值。这称为归零-掩码(zeroing-masking)。替换地,也可任选地使用除零之外的其他预定值。
这些仅仅是被掩码打包数据操作的几个示例性示例。应当理解,处理器可支持宽泛的各种不同类型的被掩码打包数据操作。例如,这些可包括仅具有一个源打包数据或具有两个以上的源打包数据的操作、生成不同尺寸的结果打包数据的操作、具有不同尺寸的数据元素的操作和/或具有不同的结果数据元素顺序的操作、及其组合。
图3是包括存储有打包数据操作掩码串接指令的机器可读的存储介质314的制品(例如,计算机程序产品)的框图。在一些实施例中,机器可读存储介质可包括有形的和/或非瞬态的机器可读存储介质。在各示例实施例中,机器可读存储介质314可包括软盘、光存储介质、光盘、CD-ROM、磁盘、磁光盘、只读存储器(ROM)、可编程ROM(PROM)、可擦除可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)、随机存取存储器(RAM)、静态RAM(SRAM)、动态RAM(DRAM)、闪存、相变存储器、半导体存储器、其它类型的存储器或它们的组合。在一些实施例中,介质可包括一个或多个固态材料,例如半导体材料、相变材料、磁性材料、光学透明固体材料等等。
打包数据操作掩码串接指令305可操作用于指定或以其它方式指示具有第一打包数据操作掩码的第一源,用于指定或以其它方式指示具有第二打包数据操作掩码的第二源,并用于指定或以其它方式指示目的地。在一些实施例中,打包数据操作掩码串接指令可操作用于明确指定第一源、第二源、和目的地。在某些实施例中,第一源、第二源、和目的地可各自为打包数据操作掩码寄存器,尽管这不是必需的(例如,目的地可以在存储器中或另一存储位置中)。指令可具有由指令格式或指令的编码所定义的一个或多个字段,以明确指定寄存器和存储位置。在一些实施例中,指令可遵循VEX编码方案,但这不是必须的。VEX编码方案的进一步的细节(如果需要的话,但对于理解本发明而言不是必须的)可在以下文件中获得:加利福尼亚州圣克拉拉市的英特尔公司,64和IA-32架构软件开发者手册,序号:253666-039US,2011年5月。可另选的,指令可隐含地指示源和/或目的地。在一些实施例中,目的地可不同于第一和第二源。在其他实施例中,第一和第二源中的一个可被用作目的地(例如,结果可至少部分地盖写源中的一个的初始数据)。
打包数据操作掩码串接指令,如果被机器执行,可操作用于致使机器响应于打包数据操作掩码串接指令而将结果存储在目的地中。结果包括:和第二打包数据操作掩码串接的第一打包数据操作掩码。应理解的是,可以在存储介质上存储其他的指令或指令的序列以执行本文所公开的一个或多个操作或方法(例如,将打包数据操作掩码串接指令的结果指示为预测操作数的被掩码打包数据指令、紧密附属的打包数据指令、或使用打包数据操作掩码串接指令的例程或算法)。
不同类型的机器的示例包括但不限于指令处理装置、指令执行装置、处理器(例如,通用处理器和专用处理器)以及具有一个或多个指令处理装置、指令执行装置和/或处理器的各种电子设备。这种电子设备的几个代表示例包括但不限于计算机系统、台式机、膝上型计算机、笔记本、服务器、网络路由器、网络交换机、上网计算机、机顶盒、蜂窝电话、视频游戏控制器等。
图4是具有执行单元417的指令处理装置415的示例实施例的框图,该执行单元417可操作用于执行包含打包数据操作掩码串接指令405的示例实施例的指令。在一些实施例中,指令处理装置可以是处理器和/或可被包括在处理器中。例如,在一些实施例中,指令处理装置可以是图1的处理器或类似设备,或者可被包括在图1的处理器或类似设备中。替换地,指令处理装置可被包括在不同的处理器或电子系统中。
指令处理装置415可接收打包数据操作掩码串接指令405。可从存储器、指令队列、指令获取单元或其它源接收指令。打包数据操作掩码串接指令可表示由指令处理装置识别的机器指令、宏指令或控制信号。指令处理装置可具有专用的或特定的电路或其它逻辑(例如,与硬件和/或固件结合的软件),该专用的或特定的电路或其它逻辑可操作用于处理指令和/或响应于指令的结果或按指令所指示地存储结果。
指令处理装置的所示实施例包括指令解码器416。解码器可接收并解码较高级的机器指令或宏指令,诸如所接收的打包数据操作掩码串接指令。解码器可以生成并输出一个或多个较低级的微操作、微代码入口点、微指令、或其他较低级的指令或控制信号,它们反映和/或来源于原始较高级的指令。一个或多个较低级指令或控制信号可通过一个或多个较低级(例如,电路级或硬件级)操作来实现较高级指令的操作。解码器可以使用各种不同的机制来实现。合适机制的示例包括但不限于微代码只读存储器(ROM)、查找表、硬件实现、可编程逻辑阵列(PLA)、用于实现本领域已知的解码器的其他机制等。
或者,在一个或多个其它实施例中,装置不是具有解码器416,而是可具有指令仿真器、转换器、变形器(morpher)、解释器或者其他指令变换逻辑。各种不同类型的指令变换逻辑在本领域中是已知的,并且可在软件、硬件、固件、或者其组合中实现。指令转换逻辑可接收打包数据操作掩码串接指令,并且仿真、翻译、变形、解释、或者以其他方式将该指令转换成一个或多个对应的导出指令或控制信号。在又一个其它实施例中,指令处理装置可具有解码器和附加的指令变换逻辑二者。例如,指令处理装置可具有:指令变换逻辑,以将打包数据操作掩码串接指令变换成第二指令;以及解码器,以将该第二指令解码成可由指令处理装置的原生硬件执行的一个或多个较低级的指令或控制信号。指令变换逻辑中的一些或全部可位于指令处理装置的其余部分的管芯外,诸如在单独的管芯上或在管芯外的存储器中。
再次参照图4,指令处理装置还包括:可操作用于存储第一打包数据操作掩码的第一打包数据操作掩码寄存器408-1;和可操作用于存储第二打包数据操作掩码的第二打包数据操作掩码寄存器408-2。如前所述,该指令可明确地指定(例如,通过位,或通过一个或多个字段)或以其它方式指示第一打包数据操作掩码寄存器、第二打包数据操作掩码寄存器、和目的地419。在一些实施例中,目的地可以是第三打包数据操作掩码寄存器408-3。或者,目的地存储位置可以是另一个寄存器或存储器位置。在一些实施例中,第一、第二和第三打包数据操作掩码寄存器可在一组打包数据操作掩码寄存器(例如,寄存器组)408中。
打包数据操作掩码寄存器可各自表示板上处理器存储位置。打包数据操作掩码寄存器可表示架构寄存器。打包数据操作掩码寄存器可对于软件和/或编程器可见(例如,软件可见),和/或可以是宏指令(例如,打包数据操作掩码串接指令)所指示或指定的用以标识操作数的寄存器。打包数据操作掩码寄存器可通过使用公知技术以不同方式实现于不同的微架构中,并且不限于任何已知的特定类型的电路。多种不同类型的寄存器是可适用的,只要它们能够存储并提供在本申请中描述的数据。合适类型的寄存器的示例包括但不限于专用物理寄存器、使用寄存器重命名的动态分配的物理寄存器、及其组合。
指令处理装置还包括执行单元417。执行单元与第一、第二、和第三打包数据操作掩码寄存器相耦合。执行单元还与解码器耦合。执行单元可从解码器接收一个或多个微操作、微代码进入点、微指令、其他指令或其他控制信号,它们反映了打包数据操作串接指令或者是从打包数据操作串接指令导出的。
执行单元可操作用于,响应于打包数据操作掩码串接指令和/或作为其结果,在目的地存储结果。所述结果包括:和第二打包数据操作掩码相串接的第一打包数据操作掩码。作为示例,执行单元可包括算术逻辑单元、逻辑单元、算术单元、功能单元等。执行单元可包括可操作用于串接第一和第二打包数据操作掩码的串接逻辑418。执行单元和/或串接逻辑可包括可操作用于实现指令的操作(例如,执行一个或多个微指令)的电路或其它执行逻辑(例如,软件、固件、硬件或组合)。
在某些实施例中,第一和第二打包数据操作掩码具有相同的尺寸,但这不是必需的。在各种实施例中,每一个打包数据操作掩码的尺寸是8位、16位、或32位。在某些实施例中,打包数据操作掩码的尺寸可以对打包数据操作串接指令是隐含的(例如,对于指令的操作码是隐含的)。在某些实施例中,指令集可包括用于打包数据操作掩码的多个不同尺寸中的每一个的不同打包数据操作掩码串接指令(例如,一个指令用于8位掩码,另一个指令用于16位掩码,再一个指令用于32位掩码,等等)。打包数据操作掩码寄存器和/或源可至少与最大尺寸的打包数据操作掩码一样大或任选地比该最大尺寸更大。在一个示例中,打包数据操作掩码寄存器可以为64位宽,但这不是必需的。打包数据操作掩码可包含打包数据操作掩码寄存器的有效位、被利用的位、或有意义的位,而打包数据操作掩码寄存器的未被用于打包数据操作掩码的剩余位可表示非有效位、未利用的位、非有意义的位或无关的位。
在某些实施例中,第一打包数据操作掩码的位在结果中出现的顺序和第一打包数据操作掩码的位在第一源中出现的顺序相同,且第二打包数据操作掩码的位在结果中出现的顺序和第二打包数据操作掩码在第二源中出现的顺序相同。在某些实施例中,第一和第二打包数据操作掩码可位于第一和第二源的对应部分(例如,相应的最低位部分,相应的最高位部分,等等),且执行单元可操作用于在目的地的对应部分的位数的两倍的位中存储被串接的打包数据操作掩码。在一些实施例中,执行单元可进一步操作用于使目的地中未被用于存储串接掩码的位归零,或者给予这些位另一个预定值。
为了进一步说明,在实施例中,第一和第二打包数据操作掩码可各自为8位,且源和目的地(例如,打包数据操作掩码寄存器)可各自有(N+1)位,其中(N+1)位大于32位(例如,为64位)。在这样的实施例中,第一打包数据操作掩码可被存储在第一源的位[7:0],且第二打包数据操作掩码可被存储在第二源的位[7:0]。响应于打包数据操作掩码串接指令和/或作为其结果,执行单元可操作用于存储结果,其包括在目的地的[7:0]位的第一打包数据操作掩码,和在目的地的[15:8]位的第二打包数据操作掩码。在某些实施例中,第一源的[N:8]位是全零,且第二源的[N:8]位是全零,且执行单元可操作用于将零存储在目的地的[N:16]位中。
在其他实施例中,第一和第二打包数据操作掩码可各自为16位,且源和目的地(例如,打包数据操作掩码寄存器)可各自有(N+1)位,其中(N+1)位大于32位(例如,为64位)。在这样的实施例中,第一打包数据操作掩码可被存储在第一源的位[15:0],且第二打包数据操作掩码可被存储在第二源的位[15:0]。响应于打包数据操作掩码串接指令和/或作为其结果,执行单元可操作用于存储结果,其包括在目的地的[15:0]位的第一打包数据操作掩码,和在目的地的[31:16]位的第二打包数据操作掩码。在某些实施例中,第一源的[N:16]位是全零,且第二源的[N:16]位是全零,且执行单元可操作用于将零存储在目的地的[N:32]位中。
在其他实施例中,第一和第二打包数据操作掩码可各自为32位,且源和目的地(例如,打包数据操作掩码寄存器)可各自有(N+1)位,其中(N+1)位至少是64位。在这样的实施例中,第一打包数据操作掩码可被存储在第一源的位[31:0],且第二打包数据操作掩码可被存储在第二源的位[31:0]。响应于打包数据操作掩码串接指令和/或作为其结果,执行单元可操作用于存储结果,其包括在目的地的[31:0]位的第一打包数据操作掩码,和在目的地的[63:32]位的第二打包数据操作掩码。在某些实施例中,第一源的[N:32]位是全零,第二源的[N:32]位是全零。如果目的地有超过64位,则执行单元可操作用于将零存储在目的地的[N:64]位中。
为了避免混淆描述,已示出和描述了相对简单的指令处理装置。在其他实施例中,指令处理装置或处理器可任选地包括其他公知组件,诸如举例而言,指令获取单元、指令调度单元、分支预测单元、指令和数据的高速缓存、指令和数据的转换后备缓冲器、预获取缓冲器、微指令队列、微指令定序器、总线接口单元、第二或更高级高速缓存、引退单元、寄存器重命名单元以及上述的各种组合。此外其它实施例可具有多种不同类型的执行单元,这些执行单元中的至少一个响应于本文公开的指令的实施例。其它实施例可具有多个核、逻辑处理器或执行引擎。可操作用于执行本文中公开的指令的实施例的执行单元可被包含在核、逻辑处理器或执行引擎中的至少一个、至少两个、大多数或全部中。实际上在处理器和其它指令处理装置中存在这些组件的多种不同的组合和配置。本发明的范围不仅限于任何已知的这样的组合或配置。
图5是可由处理器和/或执行单元响应于打包数据操作掩码串接指令(例如,指令405)和/或作为其结果而执行的打包数据操作掩码串接操作的示例实施例的框图。该指令指示第一源打包数据操作掩码寄存器508-1,第二源打包数据操作掩码寄存器508-2,和目的地打包数据操作掩码寄存器508-3。
在该示例实施例中,第一8位打包数据操作掩码511-1被存储在第一源打包数据操作掩码寄存器508-1的[7:0]位中,而第二8位打包数据操作掩码511-2被存储在第一源打包数据操作掩码寄存器508-2的[7:0]位中。在其它实施例中,打包数据操作掩码可可更宽(例如32位、64位等)或更窄(例如,4位、8位等)。此外,在其他实施例中,掩码可存储在寄存器的其他部分中(例如,在最高有效位中)。源和目的地打包数据操作掩码寄存器各自是(N+1)位宽,其中N是整数的位数。在某些实施例中,这些寄存器可各自为64位。或者,这些寄存器可更宽(例如,80位、128位等)或更窄(例如,8位、16位、32位、48位等)。在某些实施例中,第一源打包数据操作掩码寄存器的[N:8]位是全零597-1,而第二源打包数据操作掩码寄存器的[N:8]位是全零597-2,尽管这不是必需的。
响应于或由于打包数据操作掩码串接指令,结果被存储在目的地打包数据操作掩码寄存器508-3中。如所示,在某些实施例中,结果可包括第一和第二8位打包数据操作掩码598的16位串接项。第一打包数据操作掩码511-1可被存储在目的地的位[7:0],且第二打包数据操作掩码511-2可被存储在目的地的位[15:8]。在另选实施例中,这些掩码的位置可在目的地中交换。在某些实施例中,可在目的地的[N:16]位中存储零。另选地,可在目的地的[N:16]位中存储另一预定值,或者目的地的[N:16]位中的初始位可不变。对于其他尺寸的打包数据操作掩码(例如,16位掩码、32位掩码等),可执行和本例中所示操作类似的操作。
图6是处理打包数据操作掩码串接指令的示例实施例的方法620的示例实施例的流程框图。在各实施例中,该方法可由通用处理器、专用处理器(例如,图形处理器或数字信号处理器)、或另一种类型的数字逻辑设备或指令处理装置执行。在一些实施例中,方法620可由图1的处理器100、图4的指令处理装置415或类似的处理器或指令处理装置执行。可另选地,方法620可由处理器或指令处理装置的不同实施例执行。此外,图1的处理器100和图4的指令处理装置415可执行与图6的方法620的操作和方法相同、类似或不同的操作和方法的实施例。
方法包括在框621处接收打包数据操作掩码串接指令。打包数据操作掩码串接指令指定或以其它方式指示具有第一打包数据操作掩码的第一源,指定或以其它方式指示具有第二打包数据操作掩码的第二源,并指定或以其它方式指示目的地。在各个方面,该指令可在处理器、指令处理装置或者其一部分(例如,解码器、指令变换器等)处接收。在各个方面,指令可从处理器外的源(例如,从主存储器、盘、或总线或互连)或者从处理器上的源(例如,从指令高速缓存)接收。
然后,在框622,响应于、由于、和/或依照打包数据操作掩码串接操作指令所指定的,结果被存储在目的地中。所述结果包括:和第二打包数据操作掩码相串接的第一打包数据操作掩码。作为示例,执行单元、指令处理装置或处理器可串接掩码并存储结果。
在某些实施例中,第一和第二打包数据操作掩码可具有相同的尺寸,但这不是必需的。在各种实施例中,每一个打包数据操作掩码的尺寸是8位、16位、或32位,不过其他尺寸也是可能的。在某些实施例中,打包数据操作掩码的尺寸可以对打包数据操作串接指令是隐含的(例如,对于指令的操作码是隐含的)。打包数据操作掩码寄存器和/或源可至少与最大尺寸的打包数据操作掩码一样大或任选地比该最大尺寸更大。在一个示例中,打包数据操作掩码寄存器可以为64位宽,但这不是必需的。
在某些实施例中,第一和第二打包数据操作掩码可位于第一和第二源的对应部分(例如,相应的最低位部分,相应的最高位部分,等等),且串接的打包数据操作掩码可被存储在目的地的对应部分的位数的两倍的位中(例如,如果掩码被存储在最低位部分,则在最低位部分中)。在某些实施例中,未被用于存储经串接掩码的目的地的位可任选地被归零,或可另选地,被给予另一预定值,或者就让最初在寄存器中的位被保留和/或未被改变。
所示的方法包括从处理器或指令处理装置外部可见的操作(例如,从软件的视点来看)。在其它实施例中,该方法可任选地包括一个或多个其它操作(例如,在处理器或指令处理器装置内部发生的一个或多个操作)。作为示例,在接收到指令之后,可将指令解码、转换、仿真或以其它方式变换成一个或多个其它指令或控制信号。可访问和/或接收第一和第二打包数据操作掩码。执行单元可被启用用于根据指令生成或执行串接,并且可生成或执行该串接。
该方法还可与其它操作和/或方法一起使用。例如,附加的操作可包括:接收被掩码打包数据指令,该被掩码打包数据指令将在方框621被存储的结果或目的地指示为掩码或预测操作数,用于掩码遮蔽或预测在打包数据上的打包数据操作。作为另一个示例,如下文将进一步解释的,在某些实施例中,可结合紧密相关或关联的打包数据指令(例如,用于将来自两个源打包数据的数据元素打包为打包数据结果的打包指令)来执行该方法。附加的操作可包括:接收指定第一和第二打包数据并且指定该第一和第二打包数据的数据元素的重新安排和/或串接的打包指令。用于打包数据操作掩码串接指令的方法可被用于重新安排和/或串接第一和第二打包数据操作掩码的位,所述的位可各自对应于第一和第二打包数据的诸数据元素中的一个不同数据元素,以帮助维持打包数据操作掩码的位和打包数据结果的对应数据元素之间的位置对应关系,该位置对应关系可有助于进一步的掩码(masking)操作。本发明的范围不限于和这样的指令结合使用,而是本文所公开的指令有更为宽泛的用途。
图7是一组合适的打包数据寄存器707的示例实施例的方框图。所示打包数据寄存器包括三十二个512位宽打包数据或向量寄存器。这些三十二个512位宽寄存器被标记为ZMM0至ZMM31。在所示实施例中,这些寄存器中的较低十六个的较低位256位(即,ZMM0-ZMM15)重叠或者覆盖在各个256位宽打包数据或向量寄存器(标记为YMM0-YMM15)上,但是这不是必需的。同样,在所示实施例中,YMM0-YMM15的较低位128位被混叠或者覆盖在相应128位打包数据或向量寄存器(标记为XMM0-XMM1)上,但是这也不是必需的。512位宽寄存器ZMM0至ZMM31可操作用于保持512位打包数据、256位打包数据、或者128位打包数据。256位宽寄存器YMM0-YMM15可操作用于保持256位打包数据或者128位打包数据。128位宽寄存器XMM0-XMM1可操作用于保持128位打包数据。每一寄存器可用于存储打包浮点数据或打包整数数据。支持不同数据元素尺寸,包括至少8位字节数据、16位字数据、32位双字或单精度浮点数据、以及64位四字或双精度浮点数据。打包数据寄存器的替换实施例可包括不同数量的寄存器、不同尺寸的寄存器,并且可以或者可以不将较大寄存器混叠在较小寄存器上。
图8是示出具有合适打包数据格式的若干示例实施例的框图。256位打包字格式810-1是256位宽,并且包括十六个16位字数据元素。在图示中十六个16位字数据元素从最低有效位位置至最高有效位位置标记为WORD0至WORD15。256位打包双字格式810-2是256位宽,并且包括八个32位双字(dword)数据元素。在图示中八个32位双字数据元素从最低有效位位置至最高有效位位置标记为DWORD0至DWORD7。256位打包四字格式810-3是256位宽,并且包括四个64位四字数据元素。在图示中四个64位四字数据元素从最低有效位位置至最高有效位位置标记为QWORD0至QWORD3。
其他打包数据结果也是合适的。例如,其他合适的256位打包数据格式包括256位打包8位字节格式,256位打包32位单精度浮点格式,以及256位打包64位双精度浮点格式。单精度浮点格式和双精度浮点格式可分别类似于所示的双字格式810-2和四字格式810-3,然而数据元素内的位的含义/解释可不同。此外,大于和/或小于256位的打包数据格式也是合适的。例如,前述数据类型的512位(或更大)打包数据格式和/或128位(或更小)打包数据格式也是合适的。通常,对于相同数据类型而言,512位打包数据格式可具有为256位打包数据格式的两倍之多的数据元素,而对于相同数据类型而言,128位数据格式可具有为256位打包数据格式的一半那么多的数据元素。通常,打包数据元素的数量等于以位计的打包数据的尺寸除以以位计的打包数据元素的尺寸。
图9是例示打包数据操作掩码位923的数目取决于打包数据宽度和打包数据元素宽度的表格。示出128位、256位和512位的打包数据宽度,但是其它宽度也是可能的。8位字节、16位字、32位双字(dword)或单精度浮点、以及64位四倍字(Qword)或双精度浮点的打包数据元素宽度被考虑,然而其它宽度也是可能的。
如图所示,当打包数据宽度是128位时,当打包数据元素宽度是8位时可将16位用于掩码,当打包数据元素宽度是16位时可将8位用于掩码,当打包数据元素宽度是32位时可将4位用于掩码,当打包数据元素宽度是64位时可将2位用于掩码。当打包数据宽度是256位时,当打包数据元素宽度是8位时可将32位用于掩码,当打包数据元素宽度是16位时可将16位用于掩码,当打包数据元素宽度是32位时可将8位用于掩码,当打包数据元素宽度是64位时可将4位用于掩码。当打包数据宽度是512位时,当打包数据元素宽度是8位时可将32位用于掩码,当打包数据元素宽度是16位时可将16位用于掩码,当打包数据元素宽度是32位时可将8位用于掩码,当打包数据元素宽度是64位时可将4位用于掩码。
图10是一组合适的打包数据操作掩码寄存器1008的示例实施例的框图。打包数据操作掩码寄存器中的每一个可用于存储打包数据操作掩码。在所例示的实施例中,该组包括标示为K0至k7的八个打包数据操作掩码寄存器。替代的实施例可包括比八个更少(例如,两个、四个、六个等)或比八个更多(例如,十六个、二十个、三十二个等)打包数据操作掩码寄存器。在所例示的实施例中,打包数据操作掩码寄存器中的每一个为64位宽。在替代实施例中,打包数据操作掩码寄存器的宽度可以比64位更宽(例如,80位,128位等)或比64位更窄(例如,8位、16位、32位等)。打包数据操作掩码寄存器可通过使用公知技术以不同方式实现,并且不限于任何已知的特定类型的电路。多种不同类型的寄存器可适用,只要它们能够存储并提供在本申请中描述的数据。合适寄存器的示例包括但不限于,专用物理寄存器、使用寄存器重命名的动态分配的物理寄存器、以及其组合。
在一些实施例中,打包数据操作掩码寄存器908可以是分开的专用架构寄存器集合。在一些实施例中,与用于编码或指定其它类型的寄存器(例如,图1的打包数据寄存器108)相比,指令可在指令格式的不同位或一个或多个不同字段组合中编码或指定打包数据操作掩码寄存器。作为示例,被掩码打包数据指令可使用三个位(例如,3位字段)来编码或指定八个打包数据操作掩码寄存器k0至k7中的任一个。在替代实施例中,在分别有更少或更多打包数据操作掩码寄存器时,可使用更少或更多位。在一个特定实现中,仅打包数据操作掩码寄存器k1至k7(而非k0)可被寻址作为断言操作数以用于断言被掩码打包数据操作。寄存器k0可被用作常规源或目的地,但是可能不被编码为断言操作数(例如,如果k0被指定,则其具有全一或“无掩码”的编码)。在其他实施例中,寄存器中的全部或仅一些可被编码为断言操作数。
图11是例示打包数据操作掩码寄存器1108的示例实施例并且示出可被用作打包数据操作掩码和/或用于掩码遮蔽(masking)的位的数目取决于打包数据宽度和数据元素宽度的示图。所例示的打包数据操作掩码寄存器的示例实施例为64位宽,但是并不必需如此。取决于打包数据宽度和数据元素宽度的组合,可将全部64位或仅64位的子集用作用于掩码遮蔽的打包数据操作掩码。一般而言,当单个每元素的掩码控制位被使用时,打包数据操作掩码寄存器中可用于进行掩码遮蔽的位的数目等于以位计的打包数据宽度除以以位计的打包数据元素宽度。
示出若干示例性示例。即,当打包数据宽度为512位而打包数据元素宽度为64位时,则仅寄存器的最低位8位被用作打包数据操作掩码。当打包数据宽度为512位而打包数据元素宽度为32位时,则仅寄存器的最低位16位被用作打包数据操作掩码。当打包数据宽度为512位而打包数据元素宽度为16位时,则仅寄存器的最低位32位被用作打包数据操作掩码。当打包数据宽度为512位而打包数据元素宽度为8位时,则寄存器的全部64位被用作打包数据操作掩码。根据所示例的实施例,被掩码打包数据指令可基于该指令相关联打包数据宽度和数据元素宽度而仅访问和/或利用寄存器中用于打包数据操作掩码的最低位或最低有效位的数目。
在所例示的实施例中,寄存器的最低位子集或部分被用于掩码遮蔽,但是并不要求如此。在替代实施例中,可任选地使用最高位子集或某一其他子集。此外,在所例示的实施例中,仅512位打包数据宽度被考虑,然而,相同的原理适用于其他打包数据宽度,诸如例如256位和128位宽度。如先前提及的,并不必需使用64位打包数据操作掩码寄存器。
图12A-12C例示打包数据操作掩码串接指令和其操作的多种特定示例实施例。在这些图中,SRC1是第一源,SRC2是第二源,DEST是目的地,MAX_KL表示DEST的位数,符号←表示存储。在一些实施例中,SRC1、SRC2和DEST各自是打包数据操作掩码寄存器,且在一些实施例中MAX_KL是64位,但这不是必须的。在其他实施例中,不是将DEST的最高位部分归零,而是可给予另一预定值(例如,全为1,或保持、或合并来自SRC1或SRC2中一个的值)。再其他实施例中,来自SRC2的打包数据操作掩码相比来自SRC1的打包数据操作掩码位可以位于DEST的较低位比特位置。
本文中公开的打包数据操作掩码串接指令是具有一般用途的通用指令。例如,这些指令可被单独使用或结合其他指令使用,以串接打包数据操作掩码和/或掩码寄存器,以便以特定应用、算法或代码有用且期望的各种不同方式操纵掩码或掩码寄存器。在一些实施例中,本文公开的打包数据操纵掩码串接指令可与紧密附属的或相关联的指令结合使用。在某些实施例中,紧密相关或关联的打包数据指令是打包指令,其可操作用于将来自两个源打包数据的数据元素打包为结果打包数据。适当的打包指令的示例是在美国专利US5802336中描述的指令和在256位和/或512位打包数据上操作的打包指令。
图13是可由处理器和/或执行单元响应于和/或作为打包指令的结果而执行的打包操作1396的示例实施例的框图。打包指令可操作用于指示第一源打包数据1310-1,第二源打包数据1310-2,和用于打包数据结果的目的地1312。第一和第二源打包数据和目的地可均为打包数据寄存器(例如,图1中的打包数据寄存器107)。在该示例中,第一和第二源打包数据和目的地都是相同长度的(例如,都是256位,或都是512位,等等)。在这个具体的示例实施例中,第一源打包数据具有标为A0-A7的八个数据元素。第二源打包数据具有标为B0-B7的八个数据元素。作为示例,第一和第二源打包数据可各自为256位宽度,且数据元素可各自为32位双字(dword)。
打包数据结果可响应于打包数据指令而被存储在目的地中。打包数据结果包括被标为A0’-A7’和B0’-B7’的十六个数据元素。结果数据元素A0’-A7’在相应位置对应于源数据元素A0-A7(例如,B2’对应B2,B5’对应B5,等等)。结果数据元素是源数据元素的位宽度的一半,且结果包括来来自两个源的所有数据元素。类似地,结果数据元素B0’-B7’在相应位置对应于源数据元素B0-B7。在某些实施例中,数据元素A0’-A7’的每一个包括:A0’-A7’的每个对应数据元素的一部分,和与A0-A7的每个对应数据元素的相对应的饱和值,二者中的一项(例如,A0’包括A0的一部分,A6’包括对应于A6的饱和值)。
类似的,B0’-B7’的每一个包括:B0-B7的每个对应数据元素的一部分,和与B0-B7的每个对应数据元素的相对应的饱和值,二者中的一项。
在一些实施例中,本文公开的打包数据操作掩码串接指令的串接操作可用于,作为包括指令的结果,使在源打包数据的数据元素上执行的打包操作并行或镜像。可按照源打包数据被重新安排或打包的方式,将打包数据操作掩码的位串接或重新安排。在源打包数据上的打包指令和/或操作可在代码序列中与打包数据操作掩码串接指令和/或操作并行执行或一起执行。有利的是,这可帮助以模拟方式重新安排打包数据操作掩码的位以及相应的打包数据元素,从而使得打包数据操作掩码的位和对应的打包数据元素之间的位置对应关系可被保持。保持这种位置对应关系可有助于允许打包数据操作掩码的位跟踪对应的打包数据元素,使得这些位可用于掩码后续的打包数据操作(例如,由在打包指令的打包数据结果上操作的后续被掩码打包数据指令所使用)。然而,本发明的范围不限于和这些打包指令一起使用本文公开的打包数据操作掩码串接指令。
除了这些打包指令,打包数据操作掩码串接指令还可以用于其他指令,例如将两个打包数据的数据元素中的每一个转化为具有一半尺寸的对应数据元素(例如,从双字到字或字节)的一个或多个其他指令。打包数据操作掩码串接指令还可以被用于暂时地在打包数据操作掩码寄存器的上部分的非活动位中存储第一打包数据操作掩码(不是立即需要的),该打包数据操作掩码寄存器还在其活动位的最低有效部分中存储第二打包数据操作掩码。在第一掩码不会即将被使用的时刻,将第一掩码临时地存储在还在其活动位中存储第二掩码的相同寄存器的非活动位中,可有助于避免需要消耗附加的打包数据操作掩码寄存器来存储第一掩码。这可帮助避免用尽打包数据操作掩码寄存器和/或避免在没有可用的打包数据操作掩码寄存器时需要将打包数据操作掩码存储到存储器中。还基于本公开构想到其它使用。
指令集包括一个或多个指令格式。给定指令格式定义各个字段(位的数量、位的位置)以指定要执行的操作(操作码)以及要对其执行该操作的操作码等。通过指令模板(或子格式)的定义来进一步分解一些指令格式。例如,给定指令格式的指令模板可被定义为具有指令格式的字段(所包括的字段通常按照相同顺序,但是至少一些字段具有不同的比特位置,因为包括的字段更少)的不同子集,和/或被定义为具有不同解释的给定字段。由此,ISA的每一指令使用给定指令格式(并且如果定义,则以该指令格式的指令模板中的给定一个)来表达,并且包括用于指定操作和操作数的字段。例如,示例性ADD指令具有专用操作码以及包括用于指定该操作码的操作码字段和用于选择操作数的操作数字段(源1/目的地以及源2)的指令格式;并且该ADD指令在指令流中的出现将具有选择专用操作数的操作数字段中的专用内容。已经发布和/或公布了涉及高级向量扩展(AVX)(AVX1和AVX2)且使用向量扩展(VEX)编码方案的SIMD扩展集(例如,参见2011年10月的64和IA-32架构软件开发手册,并且参见2011年6月的高级向量扩展编程参考)。
示例性指令格式
本文中所描述的指令的实施例可以不同的格式体现。另外,在下文中详述示例性系统、架构、以及流水线。指令的实施例可在这些系统、架构、以及流水线上执行,但是不限于详述的系统、架构、以及流水线。
VEX指令格式
VEX编码允许指令具有两个以上操作数,并且允许SIMD向量寄存器比128位长。VEX前缀的使用提供了三操作数(或者更多)句法。例如,先前的两操作数指令执行盖写源操作数的操作(诸如A=A+B)。VEX前缀的使用使操作数执行非破坏性操作,诸如A=B+C。
图14A示出示例性AVX指令格式,包括VEX前缀1402、实操作码字段1430、Mod R/M字节1440、SIB字节1450、位移字段1462以及IMM8 1472。图14B示出来自图14A的哪些字段构成完整操作码字段1474和基础操作字段1442。图14C示出来自图14A的哪些字段构成寄存器索引字段1444。
VEX前缀(字节0-2)1402以三字节形式进行编码。第一字节是格式字段1440(VEX字节0,位[7:0]),该格式字段1440包含显性的C4字节值(用于区分C4指令格式的唯一值)。第二-第三字节(VEX字节1-2)包括提供专用能力的多个位字段。具体地,REX字段1405(VEX字节1,位[7-5])由VEX.R位字段(VEX字节1,位[7]–R)、VEX.X位字段(VEX字节1,位[6]–X)以及VEX.B位字段(VEX字节1,位[5]–B)组成。这些指令的其他字段对如在本领域中已知的寄存器索引的较低三个位(rrr、xxx以及bbb)进行编码,由此可通过增加VEX.R、VEX.X以及VEX.B来形成Rrrr、Xxxx以及Bbbb。操作码映射字段1415(VEX字节1,位[4:0]–mmmmm)包括对隐含的领先操作码字节进行编码的内容。W字段1464(VEX字节2,位[7]–W)由记号VEX.W表示,并且提供依赖于该指令而不同的功能。VEX.vvvv 1420(VEX字节2,位[6:3]-vvvv)的作用可包括如下:1)VEX.vvvv对以反转(1补码)的形式指定第一源寄存器操作数进行编码,且对采取两个或两个以上源操作数的指令有效;2)VEX.vvvv针对特定向量位移对以1补码的形式指定的目的地寄存器操作数进行编码;或者3)VEX.vvvv不对任何操作数进行编码,保留该字段,并且应当包含1111b。如果VEX.L 1468尺寸的字段(VEX字节2,位[2]-L)=0,则它指示128位向量;如果VEX.L=1,则它指示256位向量。前缀编码字段1425(VEX字节2,位[1:0]-pp)提供了用于基础操作字段的附加位。
实操作码字段1430(字节3)还被称为操作码字节。操作码的一部分在该字段中被指定。
MOD R/M字段1440(字节4)包括MOD字段1442(位[7-6])、Reg字段1444(位[5-3])、以及R/M字段1446(位[2-0])。Reg字段1444的作用可包括如下:对目的地寄存器操作数或源寄存器操作数(Rrrr中的rrr)进行编码;或者被视为操作码扩展且不用于对任何指令操作数进行编码。R/M字段1446的作用可包括如下:对引用存储器地址的指令操作数进行编码;或者对目的地寄存器操作数或源寄存器操作数进行编码。
缩放、索引、基址(SIB)-缩放字段1450(字节5)的内容包括用于存储器地址生成的SS1452(位[7-6])。先前已经针对寄存器索引Xxxx和Bbbb参考了SIB.xxx 1454(位[5-3])和SIB.bbb 1456(位[2-0])的内容。
位移字段1462和立即数字段(IMM8)1472包含地址数据。
示例性寄存器架构
图15是根据本发明的一个实施例的寄存器体系结构1500的框图。在所示出的实施例中,有32个512位宽的向量寄存器1510;这些寄存器被引用为zmm0到zmm31。较低的16zmm寄存器的较低位256个位覆盖在寄存器ymm0-16上。较低的16zmm寄存器的较低位128个位(ymm寄存器的较低位128位)覆盖在寄存器xmm0-15上。
写掩码寄存器1515-在所示的实施例中,存在8个写掩码寄存器(k0至k7),每一写掩码寄存器的尺寸是64位。在替换实施例中,写掩码寄存器1515的尺寸是16位。如先前所述的,在本发明的一个实施例中,向量掩码寄存器k0无法用作写掩码;当正常指示k0的编码用作写掩码时,它选择硬连线的写掩码0xFFFF,从而有效地停用该指令的写掩码(masking)。
通用寄存器1525——在所示出的实施例中,有十六个64位通用寄存器,这些寄存器与现有的x86寻址模式一起使用来寻址存储器操作数。这些寄存器通过名称RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP以及R8到R15来引用。
标量浮点堆栈寄存器组(x87堆栈)1545,在其上面混叠有MMX打包整数平坦寄存器组1550——在所示出的实施例中,x87堆栈是用于使用x87指令集扩展来对32/64/80位浮点数据执行标量浮点运算的八元素堆栈;而使用MMX寄存器来对64位打包整数数据执行操作,以及为在MMX和XMM寄存器之间执行的某些操作保存操作数。
本发明的替换实施例可以使用较宽的或较窄的寄存器。另外,本发明的替换实施例可以使用更多、更少或不同的寄存器组和寄存器。
示例性核架构、处理器和计算机架构
处理器核可以用出于不同目的的不同方式在不同的处理器中实现。例如,这样的核的实现可以包括:1)旨在用于通用计算的通用有序核;2)旨在用于通用计算的高性能通用无序核;3)主要旨在用于图形和/或科学(吞吐量)计算的专用核。不同处理器的实现可包括:包括预期用于通用计算的一个或多个通用有序核和/或预期用于通用计算的一个或多个通用无序核的CPU;以及2)包括主要预期用于图形和/或科学(吞吐量)的一个或多个专用核的协处理器。这样的不同处理器导致不同的计算机系统架构,其可包括:1)在与CPU分开的芯片上的协处理器;2)在与CPU相同的封装中但分开的管芯上的协处理器;3)与CPU在相同管芯上的协处理器(在该情况下,这样的协处理器有时被称为诸如集成图形和/或科学(吞吐量)逻辑等的专用逻辑,或被称为专用核);以及4)可以将所描述的CPU(有时被称为应用核或应用处理器)、以上描述的协处理器和附加功能包括在同一管芯上的片上系统。接着描述示例性核架构,随后描述示例性处理器和计算机架构。
示例性核架构
有序和无序核框图
图16A是示出根据本发明的实施例的示例性有序流水线和示例性寄存器重命名的无序发布/执行流水线二者的框图。图16B是示出根据本发明的实施例的要包括在处理器中的有序架构核的示例性实施例和示例性的寄存器重命名、无序发布/执行架构核的框图。图16A-B中的实线框示出了有序流水线和有序核,而虚线框中的可选附加项示出了寄存器重命名的、无序发布/执行流水线和核。考虑到有序方面是无序方面的子集,将描述无序方面。
在图16A中,处理器流水线1600包括提取级1602、长度解码级1604、解码级1606、分配级1608、重命名级1610、调度(也称为分派或发布)级1612、寄存器读取/存储器读取级1614、执行级1616、写回/存储器写入级1618、异常处理级1622和提交级1624。
图16B示出处理器核1690,该核1690包括耦合到执行引擎单元1650的前端单元1630,并且两者耦合到存储器单元1670。核1690可以是精简指令集合计算(RISC)核、复杂指令集合计算(CISC)核、超长指令字(VLIW)核、或混合或替代核类型。作为又一选项,核1690可以是专用核,诸如例如网络或通信核、压缩引擎、协处理器核、通用计算图形处理器单元(GPGPU)核、图形核等等。
前端单元1630包括耦合到指令高速缓存单元1634的分支预测单元1632,该指令高速缓存单元1634被耦合到指令转换后备缓冲器(TLB)1636,该指令转换后备缓冲器1636被耦合到指令获取单元1638,指令获取单元1638被耦合到解码单元1640。解码单元1640(或解码器)可解码指令,并生成从原始指令解码出的、或以其他方式反映原始指令的、或从原始指令导出的一个或多个微操作、微代码进入点、微指令、其他指令、或其他控制信号作为输出。解码单元1640可使用各种不同的机制来实现。合适的机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(PLA)、微代码只读存储器(ROM)等。在一个实施例中,核1690包括存储(例如,在解码单元1640中或否则在前端单元1630内的)特定宏指令的微代码的微代码ROM或其他介质。解码单元1640耦合至执行引擎单元1650中的重命名/分配器单元1652。
执行引擎单元1650包括重命名/分配器单元1652,该重命名/分配器单元1652耦合至引退单元1654和一个或多个调度器单元(多个)1656的集合。调度器单元1656表示任何数目的不同调度器,包括预留站(reservations stations)、中央指令窗等。调度器单元1656被耦合到物理寄存器组单元1658。每个物理寄存器组单元1658表示一个或多个物理寄存器组,其中不同的物理寄存器组存储一种或多种不同的数据类型,诸如标量整数、标量浮点、打包整数、打包浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针)等。在一个实施例中,物理寄存器组单元1658包括向量寄存器单元、写掩码寄存器单元和标量寄存器单元。这些寄存器单元可以提供架构向量寄存器、向量掩码寄存器、和通用寄存器。物理寄存器组(多个)单元(多个)1658被引退单元1654重叠以示出可以用来实现寄存器重命名和无序执行的各种方式(例如,使用记录器缓冲器(多个)和引退寄存器组(多个);使用将来的文件(多个)、历史缓冲器(多个)和引退寄存器组(多个);使用寄存器映射和寄存器池等等)。引退单元1654和物理寄存器组单元1658被耦合到执行群集1660。执行群集1660包括一个或多个执行单元1662的集合和一个或多个存储器访问单元1664的集合。执行单元1662可以执行各种操作(例如,移位、加法、减法、乘法),以及对各种类型的数据(例如,标量浮点、打包整数、打包浮点、向量整数、向量浮点)执行。尽管某些实施例可以包括专用于特定功能或功能集合的多个执行单元,但其他实施例可包括全部执行所有函数的仅一个执行单元或多个执行单元。调度器单元(多个)1656、物理寄存器组(多个)单元(多个)1658和执行群集(多个)1660被示为可能有多个,因为某些实施例为某些类型的数据/操作(例如,标量整型流水线、标量浮点/打包整型/打包浮点/向量整型/向量浮点流水线,和/或各自具有其自己的调度器单元、物理寄存器组(多个)单元和/或执行群集的存储器访问流水线——以及在分开的存储器访问流水线的情况下,实现其中仅该流水线的执行群集具有存储器访问单元(多个)1664的某些实施例)创建分开的流水线。还应当理解,在分开的流水线被使用的情况下,这些流水线中的一个或多个可以为无序发布/执行,并且其余流水线可以为有序发布/执行。
存储器访问单元1664的集合被耦合到存储器单元1670,该存储器单元1670包括耦合到数据高速缓存单元1674的数据TLB单元1672,其中该数据高速缓存单元1674耦合到二级(L2)高速缓存单元1676。在一个示例性实施例中,存储器访问单元1664可包括加载单元、存储地址单元和存储数据单元,其中的每一个均耦合至存储器单元1670中的数据TLB单元1672。指令高速缓存单元1634还耦合到存储器单元1670中的二级(L2)高速缓存单元1676。L2高速缓存单元1676被耦合到一个或多个其他级的高速缓存,并最终耦合到主存储器。
作为示例,示例性寄存器重命名的、无序发布/执行核架构可以如下实现流水线1600:1)指令提取1638执行取指和长度解码级1602和1604;2)解码单元1640执行解码级1606;3)重命名/分配器单元1652执行分配级1608和重命名级1610;4)调度器单元(多个)1656执行调度级1612;5)物理寄存器组(多个)单元(多个)1658和存储器单元1670执行寄存器读取/存储器读取级1614;执行群集1660执行执行级1616;6)存储器单元1670和物理寄存器组(多个)单元(多个)1658执行写回/存储器写入级1618;7)各单元可牵涉到异常处理级1622;以及8)引退单元1654和物理寄存器组(多个)单元(多个)1658执行提交级1624。
核1690可支持一个或多个指令集合(例如,x86指令集合(具有与较新版本一起添加的某些扩展);加利福尼亚州桑尼维尔市的MIPS技术公司的MIPS指令集合;加利福尼州桑尼维尔市的ARM控股的ARM指令集合(具有诸如NEON等可选附加扩展)),其中包括本文中描述的各指令。在一个实施例中,核1690包括支持打包数据指令集合扩展(例如,AVX1、AVX2)的逻辑,由此允许被许多多媒体应用使用的操作将使用打包数据来执行。
应当理解,核可支持多线程化(执行两个或更多个并行的操作或线程的集合),并且可以按各种方式来完成该多线程化,此各种方式包括时分多线程化、同步多线程化(其中单个物理核为物理核正同步多线程化的各线程中的每一个线程提供逻辑核)、或其组合(例如,时分取指和解码以及此后诸如用超线程化技术来同步多线程化)。
尽管在无序执行的上下文中描述了寄存器重命名,但应当理解,可以在有序架构中使用寄存器重命名。尽管所例示的处理器的实施例还包括分开的指令和数据高速缓存单元1634/1674以及共享L2高速缓存单元1676,但替换实施例可以具有用于指令和数据两者的单个内部高速缓存,诸如例如一级(L1)内部高速缓存或多个级别的内部缓存。在某些实施例中,该系统可包括内部高速缓存和在核和/或处理器外部的外部高速缓存的组合。或者,所有高速缓存都可以在核和/或处理器的外部。
具体的示例性有序核架构
图17A-B示出了更具体的示例性有序核架构的框图,该核将是芯片中的若干逻辑块之一(包括相同类型和/或不同类型的其他核)。这些逻辑块通过高带宽的互连网络(例如,环形网络)与某些固定的功能逻辑、存储器I/O接口和其它必要的I/O逻辑通信,这依赖于应用。
图17A是根据本发明的各实施例的单个处理器核连同它与管芯上互连网络1702的连接以及其二级(L2)高速缓存1704的本地子集的框图。在一个实施例中,指令解码器1700支持具有打包数据指令集合扩展的x86指令集。L1高速缓存1706允许对高速缓存存储器的低等待时间访问进入标量和向量单元。尽管在一个实施例中(为了简化设计),标量单元1708和向量单元1710使用分开的寄存器集合(分别为标量寄存器1712和向量寄存器1714),并且在这些寄存器之间转移的数据被写入到存储器并随后从一级(L1)高速缓存1706读回,但是本发明的替换实施例可以使用不同的方法(例如使用单个寄存器集合,或包括允许数据在这两个寄存器组之间传输而无需被写入和读回的通信路径)。
L2高速缓存的本地子集1704是全局L2高速缓存的一部分,该全局L2高速缓存被划分成多个分开的本地子集,即每个处理器核一个本地子集。每个处理器核具有到其自己的L2高速缓存1704的本地子集的直接访问路径。被处理器核读出的数据被存储在其L2高速缓存子集1704中,并且可以被快速访问,该访问与其他处理器核访问它们自己的本地L2高速缓存子集并行。被处理器核写入的数据被存储在其自己的L2高速缓存子集1704中,并在必要的情况下从其它子集清除。环形网络确保共享数据的一致性。环形网络是双向的,以允许诸如处理器核、L2高速缓存和其它逻辑块之类的代理在芯片内彼此通信。每个环形数据路径为每个方向1012位宽。
图17B是根据本发明的各实施例的图17A中的处理器核的一部分的展开图。图17B包括L1高速缓存1704的L1数据高速缓存1706A部分、以及关于向量单元1710和向量寄存器1714的更多细节。具体地说,向量单元1710是16宽向量处理单元(VPU)(见16宽ALU 1728),该单元执行整型、单精度浮点以及双精度浮点指令中的一个或多个。该VPU支持通过混合单元1720混合寄存器输入、通过数值转换单元1722A-B进行数值转换,以及通过复制单元1724进行对存储器输入的复制。写掩码寄存器1726允许断言所得的向量写入。
具有集成存储器控制器和图形器件的处理器
图18是根据本发明的实施例的处理器1800的方框图,该处理器可具有一个以上的核、可具有集成存储器控制器、并且可具有集成图形器件。图18的实线框示出了处理器1800,处理器1800具有单个核心1802A、系统代理1810、一组一个或多个总线控制器单元1816,而可选附加的虚线框示出了替代的处理器500,其具有多个核心1802A-N、系统代理单元1810中的一组一个或多个集成存储器控制器单元1814以及专用逻辑1808。
因此,处理器1800的不同实现可包括:1)CPU,其中专用逻辑1808是集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核),并且核1802A-N是一个或多个通用核(例如,通用的有序核、通用的无序核、这两者的组合);2)协处理器,其中核1802A-N是主要旨在用于图形和/或科学(吞吐量)的大量专用核;以及3)协处理器,其中核1802A-N是大量通用有序核。因此,处理器1800可以是通用处理器、协处理器或专用处理器,诸如例如网络或通信处理器、压缩引擎、图形处理器、GPGPU(通用图形处理单元)、高吞吐量的集成众核(MIC)协处理器(包括30个或更多核)、或嵌入式处理器等。该处理器可以被实现在一个或多个芯片上。处理器1800可以是一个或多个衬底的一部分,和/或可以使用诸如例如BiCMOS、CMOS或NMOS等的多个加工技术中的任何一个技术将其实现在一个或多个衬底上。
存储器层次结构包括在各核内的一个或多个级别的高速缓存、一组或一个或多个共享高速缓存单元1806、以及耦合至集成存储器控制器单元1814的集合的外部存储器(未示出)。该共享高速缓存单元1806的集合可以包括一个或多个中间级高速缓存,诸如二级(L2)、三级(L3)、四级(L4)或其他级别的高速缓存、末级高速缓存(LLC)、和/或其组合。尽管在一个实施例中,基于环的互连单元1812将集成图形逻辑1808、共享高速缓存单元1806的集合以及系统代理单元1810/集成存储器控制器单元(多个)1814互连,但替代实施例可使用任何数量的公知技术来将这些单元互连。在一个实施例中,在一个或多个高速缓存单元1806与核1802-A-N之间维持相干性。
在某些实施例中,核1,802A-N中的一个或多个核能够多线程化。系统代理1810包括协调和操作核1,802A-N的那些组件。系统代理单元1810可包括例如功率控制单元(PCU)和显示单元。PCU可以是或包括调整核1802A-N和集成图形逻辑1808的功率状态所需的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核1802A-N在架构指令集合方面可以是同构的或异构的;即,这些核1802A-N中的两个或更多个核可以能够执行相同的指令集合,而其他核可以能够执行该指令集合的仅仅子集或不同的指令集合。
示例性计算机架构
图19-22是示例性计算机架构的框图。本领域已知的对膝上型设备、台式机、手持PC、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(DSP)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备以及各种其他电子设备的其他系统设计和配置也是合适的。一般来说,能够含有本文中所公开的处理器和/或其它执行逻辑的大量系统和电子设备一般都是合适的。
现在参考图19,所示出的是根据本发明一个实施例的系统1900的框图。系统1900可以包括一个或多个处理器1910、1915,这些处理器耦合到控制器中枢1920。在一个实施例中,控制器中枢1920包括图形存储器控制器中枢(GMCH)1990和输入/输出中枢(IOH)1950(其可以在分开的芯片上);GMCH1990包括存储器和图形控制器,存储器1940和协处理器1945耦合到该图形控制器;IOH 1950将输入/输出(I/O)设备1960耦合到GMCH 1990。替换地,存储器和图形控制器中的一个或两个在处理器(如本文所述)内集成,存储器1940和协处理器1945直接耦合到处理器1910、以及在单一芯片中具有IOH 1950的控制器中枢1820。
附加处理器1915的可选性质用虚线表示在图19中。每一处理器1910、1915可包括本文中描述的处理核中的一个或多个,并且可以是处理器1800的某一版本。
存储器1940可以是例如动态随机存取存储器(DRAM)、相变存储器(PCM)或这两者的组合。对于至少一个实施例,控制器中枢1920经由诸如前侧总线(FSB)之类的多分支总线(multi-drop bus)、诸如快速通道互连(QPI)之类的点对点接口、或者类似的连接1995与处理器1910、1915进行通信。
在一个实施例中,协处理器1945是专用处理器,诸如例如高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、或嵌入式处理器等等。在一个实施例中,控制器中枢1920可以包括集成图形加速器。
按照包括体系结构、微体系结构、热、功耗特征等等优点的度量谱,物理资源1910、1915之间存在各种差别。
在一个实施例中,处理器1910执行控制一般类型的数据处理操作的指令。嵌入在这些指令中的可以是协处理器指令。处理器1910将这些协处理器指令识别为应当由附连的协处理器1945执行的类型。因此,处理器1910在协处理器总线或者其他互连上将这些协处理器指令(或者表示协处理器指令的控制信号)发布到协处理器1945。协处理器1945接受并执行所接收的协处理器指令。
现在参照图20,所示出的是根据本发明实施例的更具体的第一示例性系统2000的框图。如图20所示,多处理器系统2000是点对点互连系统,且包括经由点对点互连2050耦合的第一处理器2070和第二处理器2080。处理器2070和2080中的每一个都可以是处理器1800的某一版本。在本发明的一个实施例中,处理器2070和2080分别是处理器1910和1915,而协处理器2038是协处理器1945。在另一实施例中,处理器2070和2080分别是处理器1910和协处理器1945。
处理器2070和2080被示为分别包括集成存储器控制器(IMC)单元2072和2082。处理器2070还包括作为其总线控制器单元的一部分的点对点(P-P)接口2076和2078;类似地,第二处理器2080包括点对点接口2086和2088。处理器2070、2080可以使用点对点(P-P)接口电路2078、2088经由P-P接口2050来交换信息。如图20所示,IMC 2072和2082将处理器耦合到相应的存储器,即存储器2032和存储器2034,这些存储器可以是本地附连到相应处理器的主存储器的部分。
处理器2070、2080可各自经由使用点对点接口电路2076、2094、2086、2098的各个P-P接口2052、2054与芯片组2090交换信息。芯片组2090可以可选地经由高性能接口2038与协处理器2039交换信息。在一个实施例中,协处理器2038是专用处理器,诸如例如高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、或嵌入式处理器等等。
共享高速缓存(未示出)可以被包括在两个处理的任一个之内或被包括两个处理器外部但仍经由P-P互连与这些处理器连接,从而如果将某处理器置于低功率模式时,可将任一处理器或两个处理器的本地高速缓存信息存储在该共享高速缓存中。
芯片组2090可经由接口2096耦合至第一总线2016。在一个实施例中,第一总线2016可以是外围部件互连(PCI)总线,或诸如PCI Express总线或其它第三代I/O互连总线之类的总线,但本发明的范围并不受此限制。
如图20所示,各种I/O设备2014可连同总线桥2018一起耦合到第一总线2016,总线桥2016将第一总线2016耦合到第二总线2020。在一个实施例中,诸如协处理器、高吞吐量MIC处理器、GPGPU的处理器、加速器(诸如例如图形加速器或数字信号处理器(DSP)单元)、现场可编程门阵列或任何其他处理器的一个或多个附加处理器2015被耦合到第一总线2016。在一个实施例中,第二总线2020可以是低引脚计数(LPC)总线。各种设备可以被耦合至第二总线2020,在一个实施例中这些设备包括例如键盘/鼠标2022、通信设备2027以及诸如可包括指令/代码和数据2028的盘驱动器或其它海量存储设备的存储单元2030。此外,音频I/O 2024可以被耦合至第二总线2020。注意,其它架构是可能的。例如,取代图20的点对点架构,系统可以实现多分支总线或其它此类架构。
现在参考图21,示出了根据本发明的一个实施例的更具体的第二示例性系统2100的方框图。图20和图21中的相同部件用相同附图标记表示,并从图21中省去了图20中的某些方面,以避免使图21的其它方面变得难以理解。
图21例示了处理器2070、2080可分别包括集成存储器和I/O控制逻辑(“CL”)2072和2082。因此,CL 2072、2082包括集成存储器控制器单元并包括I/O控制逻辑。图21示出:不仅存储器2032、2034耦合至CL 2072、2082,I/O设备2114也耦合至控制逻辑2072、2082。传统I/O设备2115被耦合至芯片组2090。
现在参照图22,所示出的是根据本发明一个实施例的SoC 2200的框图。在图18中,相似的部件具有同样的附图标记。另外,虚线框是更先进的SoC的可选特征。在图22中,互连单元(多个)2202被耦合至:应用处理器2210,该应用处理器包括一个或多个核202A-N的集合以及共享高速缓存单元(多个)1806;系统代理单元1810;总线控制器单元(多个)1816;集成存储器控制器单元(多个)1814;一组或一个或多个协处理器2220,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(SRAM)单元2230;直接存储器存取(DMA)单元2232;以及用于耦合至一个或多个外部显示器的显示单元2240。在一个实施例中,协处理器(多个)2220包括专用处理器,诸如例如网络或通信处理器、压缩引擎、GPGPU、高吞吐量MIC处理器、或嵌入式处理器等等。
本文公开的机制的各实施例可以被实现在硬件、软件、固件或这些实现方法的组合中。本发明的实施例可实现为在可编程系统上执行的计算机程序或程序代码,该可编程系统包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。
诸如图20中示出的代码2030之类的程序代码可应用于输入指令,以执行本文描述的各功能并生成输出信息。输出信息可以按已知方式被应用于一个或多个输出设备。为了本申请的目的,处理系统包括具有诸如例如数字信号处理器(DSP)、微控制器、专用集成电路(ASIC)或微处理器之类的处理器的任何系统。
程序代码可以用高级程序化语言或面向对象的编程语言来实现,以便与处理系统通信。程序代码也可以在需要的情况下用汇编语言或机器语言来实现。事实上,本文中描述的机制不仅限于任何特定编程语言的范围。在任一情形下,语言可以是编译语言或解译语言。
至少一个实施例的一个或多个方面可以由存储在机器可读介质上的代表性指令来实现,该指令表示处理器中的各种逻辑,该指令在被机器读取时使得该机器制作用于执行本文所述的技术的逻辑。被称为“IP核”的这些表示可以被存储在有形的机器可读介质上,并被提供给各种客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
这样的机器可读存储介质可以包括但不限于通过机器或设备制造或形成的制品的非瞬态、有形配置,其包括存储介质,诸如硬盘;任何其它类型的盘,包括软盘、光盘、紧致盘只读存储器(CD-ROM)、紧致盘可重写(CD-RW)的以及磁光盘;半导体器件,例如只读存储器(ROM)、诸如动态随机存取存储器(DRAM)和静态随机存取存储器(SRAM)的随机存取存储器(RAM)、可擦除可编程只读存储器(EPROM)、闪存、电可擦除可编程只读存储器(EEPROM);相变存储器(PCM);磁卡或光卡;或适于存储电子指令的任何其它类型的介质。
因此,本发明的各实施例还包括非瞬态、有形机器可读介质,该介质包含指令或包含设计数据,诸如硬件描述语言(HDL),它定义本文中描述的结构、电路、装置、处理器和/或系统特性。这些实施例也被称为程序产品。
仿真(包括二进制变换、代码变形等)
在某些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以变换(例如使用静态二进制变换、包括动态编译的动态二进制变换)、变形(morph)、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上部分在处理器外。
图23是根据本发明的实施例的对照使用软件指令转换器将源指令集中的二进制指令转换成目标指令集中的二进制指令的框图。在所示的实施例中,指令转换器是软件指令转换器,但作为替代该指令转换器可以用软件、固件、硬件或其各种组合来实现。图23示出:采用高级语言2302的程序可使用x86编译器2304来编译以生成x86二进制代码2306,该二进制代码可原生地由具有至少一个x86指令集核心的处理器2316来执行。具有至少一个x86指令集核的处理器2316表示任何处理器,这些处理器能通过兼容地执行或以其他方式处理以下内容来执行与具有至少一个x86指令集核的英特尔处理器基本相同的功能:1)英特尔x86指令集核的指令集的本质部分,或2)被定向为在具有至少一个x86指令集核的英特尔处理器上运行的应用或其它程序的目标代码版本,以便取得与具有至少一个x86指令集核的英特尔处理器基本相同的结果。x86编译器2304表示用于生成x86二进制代码2306(例如,对象代码)的编译器,该二进制代码2306可通过或不通过附加的可链接处理在具有至少一个x86指令集核的处理器2316上执行。类似地,图23示出:采用高级语言2302的程序可使用替换指令集编译器2308来编译以生成替换指令集二级制代码2310,该替换指令集二级制代码2314可由不具有至少一个x86指令集核心的处理器2314(诸如,具有可执行加利福尼亚州桑尼威尔的MIPS技术公司的MIPS指令集的处理器和/或执行加利福尼亚州桑尼威尔的ARM控股公司的ARM指令集的处理器)来原生地执行。指令转换器2312被用来将x86二进制代码2306转换成可以由不具有x86指令集核的处理器2314原生执行的代码。该经转换的代码不大可能与替换性指令集二进制代码2310相同,因为能够这样做的指令转换器难以制造;然而,转换后的代码将完成一般操作并由来自替换性指令集的指令构成。因此,指令转换器2312表示:通过仿真、模拟或任何其它过程来允许不具有x86指令集处理器或核的处理器或其它电子设备得以执行x86二进制代码2306的软件、固件、硬件或其组合。
在说明书和权利要求书中,可使用术语“耦合”和“连接”及其衍生词。应当理解,这些术语并不旨在作为彼此的同义词。相反,在具体实施例中,“连接的”用于指示两个或更多个要素彼此直接物理或电接触。“耦合”可表示两个或多个元件直接物理或电气接触。然而,“耦合”也可表示两个或更多个要素可能并未彼此直接接触,但是仍然彼此协作、彼此作用。例如,执行单元可通过一个或多个中间组件与寄存器耦合。
在以上描述中,出于解释的目的,阐明了众多具体细节以提供对本发明的实施例的透彻理解。然而,对本领域技术人员而言将是明显的是,不用这些具体细节中的一些也可实践一个或多个其他实施例。所描述的具体实施例不是为了限制本发明而是为了说明。本发明的范围不是由所提供的具体示例确定,而是仅由所附权利要求确定。在其它实例中,以方框图形式而非以细节地示出了公知的电路、结构、设备和操作以避免混淆对说明书的理解。
本领域的技术人员将意识到可对本文公开的实施例做出修改,诸如对实施例的各组件的配置、形式、功能和操作方式和使用进行修改。在附图中显示且在说明书中描述的关系的所有等效关系都被涵盖在本发明的实施例内。为说明的简单和清楚起见,在附图中示出的元素不一定按比例绘制。例如,为清楚起见,一些元件的尺寸相对其它元件被夸大。在附图中,箭头用于示出耦合。
已描述了各种操作和方法。已经以流程图方式以基础方式对一些方法进行了描述,但操作可选择地被添加至这些方法和/或从这些方法中移去。另外,根据示例性实施例,描述操作的特定顺序,但要理解该特定顺序是示例性的。替代实施例可选择地以不同顺序执行操作、合并某些操作、重叠某些操作,等等。可对所描述的方法作出和构想出许多修正和调整。
某些操作可由硬件组件执行,或者可体现在机器可执行或电路可执行的指令中,它们可用于使得或至少导致用执行这些操作的指令编程的电路或硬件。电路可包括通用或专用处理器、或逻辑电路,这里仅给出几个示例。这些操作还可任选地由硬件和软件的组合执行。执行单元和/或处理器可包括专门或特定电路,或者其它逻辑,它们对指令或微指令或者衍生自机器指令的一个或多个控制信号作出响应,以执行某些操作。
还应当理解,说明书全文对“一个实施例”、“一实施例”或“一个或多个实施例”的引用例如表示特定特征可包含在本发明实施例的实践中。类似地应当理解,在本说明书中,各个特征有时被一起编组在单个实施例、附图或其描述中以使本公开变得流畅并帮助理解各个创新性方面。然而,该公开方法不应被解释成反映本发明需要比每项权利要求中所明确记载的更多特征的意图。相反,如下面权利要求反映的,各创新性方面可具有比单个公开的实施例的全部特征更少的特征。因此,所附权利要求因此被明确纳入该说明书中,每一项权利要求独自作为本发明单独的实施例。
- 还没有人留言评论。精彩留言会获得点赞!