一种信息系统运行状态预测方法和装置与流程
本发明涉及IT运维中智能监控技术领域,更具体地,涉及信息系统运行状态预测技术领域。
背景技术:
目前,随着信息系统的日益广泛以及不同领域的业务种类的日益丰富,基于海量数据存储与处理的计算信息系统的应用变得越来越广泛,由此,随着用于大量运算速度及存储量的主机、中间件及数据库的数量的显著增长,其发生故障的概率以及不良影响也越来越大,因此,对信息系统运行状态进行有效的预测变得越来越重要。
在信息运维过程中,支撑应用系统运行的监控指标有很多,通过这些监控指标可以发现应用系统的运行状况。
现有的技术方案存在如下问题需要解决:(1)如何识别关键监控指标(KPI),以减少不重要的监控指标;(2)如何通过这些关键的监控指标综合判断应用系统的运行状况;(3)如何提前预测系统的运行状况。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的方法和装置。
根据本发明的一个方面,如图1所示,提供了一种信息系统运行状态预测方法,包括以下步骤,S1.基于信息系统数据,利用粗糙集算法识别出信息系统的关键监控指标;S2.基于信息系统数据,利用关联规则挖掘算法建立各关键监控指标与信息系统运行状态间的关联规则;S3.基于信息系统实时监控数据,利用所得关联规则,结合预测算法,进行信息系统运行状态的预测。
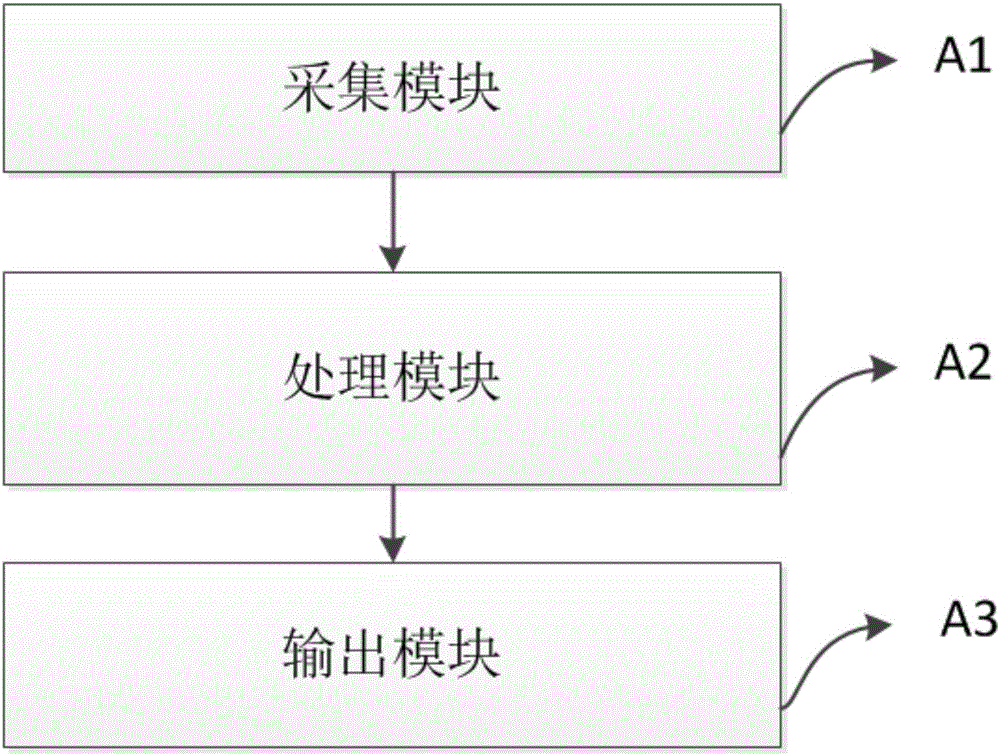
根据本发明的另一个方面,如图2所示,提供了一种信息系统运行状态预测装置,包括以下模块,采集模块,用于采集信息系统数据;处理模块,用于基于信息系统数据,利用粗糙集算法识别出信息系统的关键监控指标;基于信息系统数据,利用关联规则挖掘算法建立各关键监控指标与信息系统运行状态间的关联规则;基于信息系统实时监控数据,利用所得关联规则,结合预测算法,进行信息系统运行状态的预测。
本申请提出一种信息系统运行状态预测方法和装置,利用粗糙集算法识别出信息系统的关键监控指标、利用关联规则挖掘算法建立各关键监控指标与信息系统运行状态间的关联规则、利用预测算法技术以预测信息系统的运行状况。本发明具有效率高、运用关键指标准确预测信息系统运行状态的有益效果。
附图说明
图1为根据本发明实施例的信息系统运行状态预测方法的总体流程示意图;
图2为根据本发明实施例的信息系统运行状态预测装置的总体结构示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
在一个具体实施例中,以某营销基础数据平台信息系统运行状态预测为例,结合附图对本发明进行进一步的说明。
图1给出了根据本发明实施例的一种信息系统运行状态预测方法的总体流程示意图。总的来说,该方法包括:S1.基于信息系统数据,利用粗糙集算法识别出信息系统的关键监控指标;S2.基于信息系统数据,利用关联规则挖掘算法建立各关键监控指标与信息系统运行状态间的关联规则;S3.基于信息系统实时监控数据,利用所得关联规则,结合预测算法,进行信息系统运行状态的预测。利用大数据技术及数据挖掘方法对业务系统进行关联规则挖掘,可以发现支撑业务系统运行的主机、中间件及数据库等资源与业务系统的关联关系,同时也可以挖掘出业务系统之间的关联关系,这对与业务系统故障定位及提前预判有着重要意义,是自动化巡检中的一个关键技术。此外,对于一些重要的系统(比如营销系统)运行状况的提前预判,可以让我们能够及时处理将来可能发生的问题,从而提升客户体验。
在本发明一个具体实施例中,所述步骤S1包括,
1)确定条件属性C和决策属性D,并且用字母编号决策表中数据。
2)对条件属性进行约简,删除多余的属性,本文利用属性的依赖度分析方法来完成约简和求核。
在本发明另一个具体实施例中,步骤S2中所述“关联规则挖掘算法”还包括以下步骤:
利用改进的Apriori算法建立各监控指标与信息系统运行状态的关联规则;所述算法改进点在于:利用频繁项目集Lk-1对所述数据进行筛选,如果Lk-1没有包含集合k,则不对该频繁项目集Lk-1进行后续计算。
在本发明另一个具体实施例中,步骤S2中所述“关联规则挖掘算法”还包括以下步骤:利用Apriori算法建立各监控指标与信息系统运行状态的关联规则。
在本发明另一个具体实施例中,步骤S3还包括以下步骤:利用数据拟合技术进行信息系统运行状态的预测。可以理解为,本发明用于实现信息系统运行状态的预测不仅限于数据拟合算法,还可以利用但不限于以下算法:简易平均算法、移动平均算法、指数平滑算法、线性回归算法
在本发明另一个具体实施例中,所述步骤S1前还包括以下步骤,S001.采集信息系统数据S002.将所述信息系统数据归一化处理,将数据都限定在[0,1]范围内。
在本发明另一个具体实施例中,步骤S12具体方式如下:
①求出条件属性C的等价集;
②求出决策属性D的等价集;
③求出决策属性的各等价集的下近似集;
④以条件属性A为例,计算条件属性C相对于决策属性D的重要性γ(C,D),以及γ(C-{A},D);
⑤求A的重要度Sig(A,C,D)
Sig(A,C,D)=γ(C,D)-γ(C-{A},D)
Sig(A,C,D)>0表示属性是重要的,否则表示属性是不必要冗余的,去掉它们后对分类结果不产生任何影响。通过这种方法就可以识别出关键的监控指标(KPI)。
在本发明的又一个实施例中,所述“关联规则挖掘算法”还包括以下步骤:
S21.若|Lk-1|<k,则输出Ck=φ;若|Lk-1|≥k,则计算出候选k项目集Ck;
S22.若CK≠φ,则计算出候选项目集Ck的各个候选项目支持度,求得k项目集合Lk。
在本发明另一个具体实施例中,所述“关联规则挖掘算法”还包括以下步骤:
S21.若|Lk-1|<k,则输出Ck=φ;若|Lk-1|≥k,则计算出候选k项目集Ck;
S22.若CK≠φ,则计算出候选项目集Ck的各个候选项目支持度,求得k项目集合Lk。
单个信息系统通常由主机、中间件和数据库构成的有机整体,它们之间是相互关联的。因此我们需要挖掘出各监控指标与信息系统运行状态的关联规则,这样就可以通过它们之间的关联关系预判信息系统是否存在问题。我们以营销基础数据平台系统为例,进行关联分析。
营销基础数据平台系统主要包括2台数据库服务器和4台应用服务器(包括主机和中间件)。
这里我们进行关联分析的监控指标包括数据库的“数据库表空间”与“数据库状态”两个指标、中间件的“JVM运行时间”一个指标、主机的“CPU利用率”一个指标,总共4个监控指标。通过对数据库中各监控指标的各个字段的分析和研究,我们发现可以根据各个监控指标的category字段(good\warning\error)来进行关联分析。在本文中,我们利用改进的Apriori算法进行关联规则的挖掘,以发现各个监控指标之间的关联关系。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。为了便于分析,我们分别对各个指标的category字段的值进行标记,标记规则如表I所示。
表I标记规则
我们对2016年3月1日至3月8日的某公司信息中心的监控数据进行了关联分析,分析出不同的最小支持度和可信度时的关联规则,结果如下:
当min_support=60000,min_confidence=0.9时,其关联规则有:
比如关联规则"a11"^"c11"->"b11"^"a21":0.98922274432,表示数据库表空间是good、JVM运行时间good时,CPU利用率是good,那么应用系统的状态是good(正常状态),这个关联规则的可信度为98.9%。
通过预测算法预测出数据库表空间、JVM运行时间和CPU利用率在将来的某个时刻的状态,就可以通过它们之间的关联规则,预测出应用系统在将来的某个时刻的运行状态。
在本发明的又一个实施例中,步骤S002更具体地,主要包括以下的步骤:
其中,为归一化后的数据,xmin和xmax分别为原始数据的最小值和最大值,以为数据个数。
如图2所示,本发明的一种信息系统运行状态预测装置的总体结构示意图,包括:
A1采集模块,用于采集信息系统数据;
A2处理模块,用于基于信息系统数据,利用粗糙集算法识别出信息系统的关键监控指标;基于信息系统数据,利用关联规则挖掘算法建立各关键监控指标与信息系统运行状态间的关联规则;基于信息系统实时监控数据,利用所得关联规则,结合预测算法,进行信息系统运行状态的预测;
A3输出模块,用于输出信息系统运行状态的预测结果。
最后,本申请的方法仅为较佳的实施方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!