基于分布式离线技术的电量数据批量高速处理方法及系统与流程
本发明涉及一种数据批处理方法及系统,尤其指基于分布式离线技术的电量数据批量高速处理方法及系统。
背景技术:
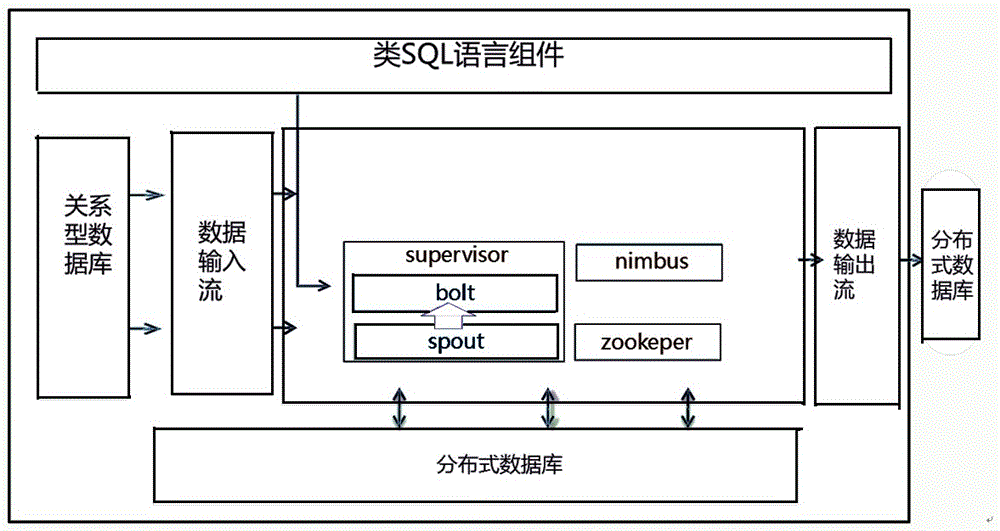
:用电信息采集系统由系统主站、传输信道、采集终端以及智能电表组成。系统主站负责整个系统的用电信息采集、存储、分析、处理和应用,由通信子系统、数据库、业务应用、接口应用等组成。大部分网省公司采用省级集中部署方式建设。传输信道分为系统主站与终端之间的远程通信信道、终端与智能电表之间的本地通信信道。当前公司范围内采集系统远程通信信道主要采用GPRS/CDMA无线公网系统、230MHz无线专网信道、电话PSTN、光纤通信信道等。本地通信信道主要采用RS485、低压电力线载波(窄带、宽带)、微功率无线等。目前,系统采集范围主要为专变用户、公变计量点、低压用户及非统调电厂。各网省公司平均接入用户规模已达千万户级别,平均接入采集终端规模从几万台到几百万台不等,平均数据存储规模开始从TB级别向PB级别迈进。系统每日采集数据包括现场电能表示数、三相电压曲线、三相电流曲线、有功功率曲线、无功功率曲线、功率因数、电压合格率统计数据、各类终端及电能表事件记录等。不同数据采集频率不同,曲线数据采集频率为最高,达15分钟一次。但目前,高速海量数据存储计算模型欠缺,现用电信息采集业务数据模型,随着高频数据采集、存储、计算的需要,浙江省全省2000多万低压用户,未能满足不同种类、不同形式的海量数据存储、计算。技术实现要素:本发明要解决的技术问题和提出的技术任务是对现有技术方案进行完善与改进,提供基于分布式离线技术的电量数据批量高速处理方法,以达到加快处理速度的目的。为此,本发明采取以下技术方案。基于分布式离线技术的电量数据批量高速处理方法,其包括以下步骤:1)电量采集前置机将采集电量实时发送到Kafka队列缓存;2)Storm集群读取Kafka队列电量信息,并实时存储到Hbase;3)Spark在Hbase中抽取需要处理的电量信息,并将其导入到Hive数据表;4)通过Spark离线计算操作相关Hive数据表得到当期电量,并对相关异常处理。Storm可以实现正真流式实时的处理数据,例如每次处理一条消息,这样,延迟就可以控制在秒级以下,实时性很高;在数据容错能力方面,spark的容错是通过状态记录去实现的,spark会将所有的处理过程状态都以log的形式记录下来;spark的批处理特点,能够保证每个批处理的所有数据只处理一次,保证数据不会在恢复的时候错乱(批处理重新执行)。本技术方案集Storm和Spark的优点,提升整体计算处理容量。从事务保障任务节点动态迁移技术,提出完整的任务节点迁移的事务保障协议,在确保迁移过程中流系统消息不丢包、不重复的同时,提高迁移本身的执行效率,提升系统稳定性。作为对上述技术方案的进一步完善和补充,本发明还包括以下附加技术特征。在步骤2)中,Storm集群包括一个主节点Nimbus和一群工作节点Supervisor,并通过Zookeeper进行协调;Nimbus负责在集群里面分发代码,分配计算任务给机器,并且监控状态;Supervisor监听分配给它那台机器的工作,根据需要启动/关闭工作进程。Supervisor的每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在多台机器上的多个工作进程组成。计算任务Topology是由不同的Spouts和Bolts,通过数据流连接起来的图;Spout作为Storm中的消息源,用于为Topology生产消息,从外部数据源不间断地读取数据并发送给Topology消息;Bolt为Storm中的消息处理者,用于为Topology进行消息的处理,Bolt处理包括消息过滤、聚合、查询数据库,其对消息作逐级处理。最后,Topology被提交到Storm集群中运行;或通过命令停止Topology的运行,将Topology占用的计算资源归还给Storm集群。基于分布式离线技术的电量数据批量高速处理系统包括:HDFS集群:用于存储原始数据文件,包括电量、负荷数据;分布式消息队列存储模块:用于对电量采集前置机采集到的电量进行队列缓存;分布式数据库:用于存储分布式电量数据;数据处理工具模块:在系统部署初始化时,使用Sqoop工具直接从关系数据库读取档案数据,并将数据存储到分布式文件存储中,提供给各个分布式计算服务调用档案数据;在系统运行过程中,从关系数据库读取增量档案更新数据,并可将数据实时更新到云平台的分布式文件存储中,为分布式流计算和离线计算提供准确的基础信息;分布式流计算模块:采用ApacheStorm进行分布式实时计算;读取分布式消息队列存储模块数据,并实时存储到分布式数据库;分布式离线计算模块:用于在分布式数据库中抽取需要处理的电量信息,并将其导入到Hive数据表;通过Spark离线计算处理相关Hive数据表得到当期电量,并对相关异常处理;运维监控模块:根据各个应用框架的交互和状态数据,进行可视化的界面展现,同时通过读取各个计算服务存储在分布式数据库中的日志信息以及收集的文本日志信息,监控计算服务的运行状态,实现计算节点的热部署;对计算服务进行实时任务调度。运维监控模块通过直接读取ZooKeeper中存储的整个Hadoop生态圈的各个应用框架的交互和状态数据,进行可视化的界面展现,同时通过读取各个计算服务存储在分布式数据库中的日志信息以及由Flume收集的文本日志信息,监控计算服务的运行状态,通过调用脚本的方式,实现计算节点的热部署;当需要更改任务调度时,通过直接修改ZooKeeper中的任务数据对计算服务进行实时任务调度;其中ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务。分布式流计算模块针对每个存储和计算服务功能部署独立的Topolopy,根据每个Topolopy的不同数据特性和性能特点,配置对应的节点数和进程数,通过与分布式MySql和HBase的接口进行数据的实时读取和写入。Storm为一个免费、开源的分布式实时计算系统,其在用电信息采集系统中,针对每个存储和计算服务功能部署独立的Topolopy,可针对每个Topolopy的不同数据特性和性能特点,配置不同的节点数和进程数,充分利用服务器资源,实现将终端上报的大量数据流的高速存储。分布式离线计算模块在Spark的MLlib内置用于机器学习和应用的实现库,实现库存储内容包括分类、回归、聚类、协同过滤、降维,以为用电信息采集系统中复杂的分析计算提供了原生算法支持。Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,充分利用了内存加速,很好的解决了交互式查询和迭代式机器学习的效率问题。有益效果:本技术方案集Storm和Spark的优点,提升整体计算处理容量。从事务保障任务节点动态迁移技术,提出完整的任务节点迁移的事务保障协议,在确保迁移过程中流系统消息不丢包、不重复的同时,提高迁移本身的执行效率,提升系统稳定性。附图说明图1是本发明流程图。图2是本发明系统框图。图3是本发明实时流计算框图。具体实施方式以下结合说明书附图对本发明的技术方案做进一步的详细说明。目前,采集系统可广泛应用于公司营销及其他多个专业。通过远程自动抄表应用实现电费抄核收模式的转变,支撑阶梯电价和峰谷电价的全面实施,自动抄表核算比率达92%以上;通过费控功能应用有效提高了电费回收效率,减小电费风险;通过计量装置在线监测实现对现场计量装置的运行状态评估,对保障电网安全稳定运行、反窃电和降低计量偏差造成的舆情发挥重要作用;通过线损监测应用,降低台区线损,并为同期线损计算提供重要技术支撑;通过分布式电源监测,一方面可实现对分布式电源的有序利用,另一方面可实现配电网的安全、可靠运行;通过市场分析与需求侧管理应用更好的掌握用户的负荷情况和用电规律,有效支撑有序用电工作快速响应,为电力需求侧分析提供数据支撑;通过电能质量监测应用支撑配电网电压质量、供电可靠性的自动统计,提高供电的安全性、可靠性和经济性。同时,采集系统还向营销业务系统、供电电压监测系统、电能质量在线监测系统、省级计量中心生产调度平台、营销稽查监控系统、配网抢修指挥平台、运营监测(控)中心等多个业务应用系统提供接口数据。采集系统正推动着电力营销管理模式的重大变革,并已成为包括营销在内的各专业不可或缺的重要基础支撑系统。故提高采集系统的计算处理速度,显得尤为重要。为了提高采集系统的处理速度,如图1所示,电量数据批量处理方法包括以下步骤:1)电量采集前置机将采集电量实时发送到Kafka队列缓存;2)Storm集群读取Kafka队列电量信息,并实时存储到Hbase;3)Spark在Hbase中抽取需要处理的电量信息,并将其导入到Hive数据表;4)通过Spark离线计算操作相关Hive数据表得到当期电量,并对相关异常处理。Storm可以实现正真流式实时的处理数据,例如每次处理一条消息,这样,延迟就可以控制在秒级以下,实时性很高;在数据容错能力方面,spark的容错是通过状态记录去实现的,spark会将所有的处理过程状态都以log的形式记录下来;spark的批处理特点,能够保证每个批处理的所有数据只处理一次,保证数据不会在恢复的时候错乱(批处理重新执行)。Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大。得益于弹性分布式数据集(RDD)的数据对象操作模式,Spark在计算效率方面远高于HadoopMapReduce。本技术方案集Storm和Spark的优点,提升整体计算处理容量。从事务保障任务节点动态迁移技术,提出完整的任务节点迁移的事务保障协议,在确保迁移过程中流系统消息不丢包、不重复的同时,提高迁移本身的执行效率,提升系统稳定性。在步骤2)中,Storm集群包括一个主节点Nimbus和一群工作节点Supervisor,并通过Zookeeper进行协调;Nimbus负责在集群里面分发代码,分配计算任务给机器,并且监控状态;Supervisor监听分配给它那台机器的工作,根据需要启动/关闭工作进程。Supervisor的每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在多台机器上的多个工作进程组成。计算任务Topology是由不同的Spouts和Bolts,通过数据流连接起来的图;Spout作为Storm中的消息源,用于为Topology生产消息,从外部数据源不间断地读取数据并发送给Topology消息;Bolt为Storm中的消息处理者,用于为Topology进行消息的处理,Bolt处理包括消息过滤、聚合、查询数据库,其对消息作逐级处理。最后,Topology被提交到Storm集群中运行;或通过命令停止Topology的运行,将Topology占用的计算资源归还给Storm集群。如图2所示,基于分布式离线技术的电量数据批量高速处理系统包括:HDFS集群:用于存储原始数据文件,包括电量、负荷数据;分布式消息队列存储模块:用于对电量采集前置机采集到的电量进行队列缓存;分布式数据库:用于存储分布式电量数据;数据处理工具模块:在系统部署初始化时,使用Sqoop工具直接从关系数据库读取档案数据,并将数据存储到分布式文件存储中,提供给各个分布式计算服务调用档案数据;在系统运行过程中,从关系数据库读取增量档案更新数据,并可将数据实时更新到云平台的分布式文件存储中,为分布式流计算和离线计算提供准确的基础信息;分布式流计算模块:采用ApacheStorm进行分布式实时计算;读取分布式消息队列存储模块数据,并实时存储到分布式数据库;分布式离线计算模块:用于在分布式数据库中抽取需要处理的电量信息,并将其导入到Hive数据表;通过Spark离线计算处理相关Hive数据表得到当期电量,并对相关异常处理;运维监控模块:根据各个应用框架的交互和状态数据,进行可视化的界面展现,同时通过读取各个计算服务存储在分布式数据库中的日志信息以及收集的文本日志信息,监控计算服务的运行状态,实现计算节点的热部署;对计算服务进行实时任务调度。分布式离线计算模块采用ApacheSpark技术,ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,与Hadoop的区别在于它充分利用了内存加速,很好的解决了交互式查询和迭代式机器学习的效率问题。同时可使用Spark框架中MLlib提供的大量开源算法工具,通过SparkSQL的方式直接读取HDFS文件系统中存储的电量、负荷等原始数据文件,实现各种复杂的分析计算,并将计算结果通过内置接口返回关系数据库或者HBase。分布式流计算模块采用ApacheStorm技术,ApacheStorm是一个免费、开源的分布式实时计算系统,现已升级为Apache顶级项目。在用电信息采集系统中,针对每个存储和计算服务功能部署独立的Topolopy,可针对每个Topolopy的不同数据特性和性能特点,配置不同的节点数和进程数,充分利用服务器资源,实现将终端上报的大量数据流的高速存储。通过与分布式MySql和HBase的接口进行数据的实时读取和写入。在系统部署初始化时,可使用Sqoop工具直接从关系数据库读取档案数据,并将数据通过MR计算的方式直接存储到分布式文件存储中,提供给各个分布式计算服务调用档案数据。在系统运行过程中,通过使用OracleGoldenGate工具从关系数据库读取增量档案更新数据,并可将数据实时更新到云平台的分布式文件存储(如HBase和Hive)中,为分布式流计算和离线计算提供准确的基础信息。运维监控模块可以通过直接读取ZooKeeper中存储的整个Hadoop生态圈的各个应用框架的交互和状态数据,进行可视化的界面展现。同时可通过读取各个计算服务存储在分布式数据库中的日志信息以及由Flume收集的文本日志信息,监控计算服务的运行状态,通过调用Shell脚本等方式,实现计算节点的热部署。必要时通过直接修改ZooKeeper中的任务数据对计算服务进行实时任务调度。ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。对于主数据库中的计算任务,使用关系数据库的作业调度定时执行存储过程来实现用电信息采集系统中安装覆盖、抄表统计等统计分析功能。DBMS_JOB包是Oracle提供的内部函数包,提供了管理和调度作业队列中的作业定时执行的控制机制。可以通过DBMS_JOB可视化的管理和配置计算任务的定时执行情况,以及通过存储过程输出日志了解计算任务的内部计算详情。分布式离线计算,目前主流的分布式离线计算框架有ApacheHive和ApacheSpark,现在都属于Apache基金会下的顶级项目。Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大。得益于弹性分布式数据集(RDD)的数据对象操作模式,Spark在计算效率方面远高于HadoopMapReduce。当Spark的MLlib内置了一些机器学习算法和应用的实现库,包括分类、回归、聚类、协同过滤、降维等,为用电信息采集系统中复杂的分析计算提供了原生算法支持。如图3所示,分布式流计算模块基于Storm进行实时流计算,它提供了一系列的基本元素用于进行计算:Topology、Stream、Spout、Bolt等等。将整个集群主要由一个主节点(Nimbus后台程序)和一群工作节点(workernode)Supervisor的节点组成,通过Zookeeper进行协调,Nimbus类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器,并且监控状态。从事务保障任务节点动态迁移技术,提出完整的任务节点迁移的事务保障协议,在确保迁移过程中流系统消息不丢包、不重复的同时,提高迁移本身的执行效率,提升系统稳定性。每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。计算任务Topology是由不同的Spouts和Bolts,通过数据流(Stream)连接起来的图。Spout作为Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源不间断地读取数据并发送给Topology消息(tuple元组)。Bolt作为Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤,聚合,查询数据库等操作,而且可以一级一级的进行处理。最终,Topology会被提交到Storm集群中运行;也可以通过命令停止Topology的运行,将Topology占用的计算资源归还给Storm集群。为进一步说明本技术方案能有效实现电量数据批量高速处理,以下就选择Storm、Spark进行计算处理的理由作进一步说明。一、Storm功能性对比测试方法Storm和SparkStreaming是一个流处理技术,以tuple为基本单位,每个tuple可以包含多个字段(field)。我们给tuple定义两个字段:lData:存放原始的数据,这里是1000字节的数据,此测试中我们仅仅是直接的转发数据,所以唯一的处理开销就是1000字节的内存拷贝lltsInfo:时间戳信息,每经过一个处理模块,在此字段中追加上当时的时间戳,最后统计模块就可以根据这些时间信息计算出总延迟等。由于不同的机器时间戳并不同步,这给计算延迟带来了固有误差,解决的办法就是把数据发送模块和最后的统计模块放到一台物理机上。关于在分布式集群上测试storm的一个说明:在storm上,很难给某个模块(component)指定其运行的物理机,storm总是自动的把任务平均分配给集群中的各个机器,因此在测试中我们将使用storm的工作方式来扩展,sender与processer不在同一台机器,并与以上测试结果对比。由于不同主机上时间戳不同步,为了消除由此带来的误差,我们必须将数据产生模块sender和最后的计算模块stats放到同一台计算机上,将数据处理模块放到另一台计算机上。二、Spark与Hive技术性能测试功能特性对比对比项SparkHive数据处理模型、数据延迟性Spark得益于其在迭代计算和内存计算上的优势,可以自动调度复杂的计算任务,避免中间结果的磁盘读写和资源申请过程,非常适合数据挖掘算法。MapReduce为大数据挖掘提供了有力的支持,但是复杂的挖掘算法往往需要多个MapReduce作业才能完成,多个作业之间存在着冗余的磁盘读写开销和多次资源申请过程,使得基于MapReduce的算法实现存在严重的性能问题。数据保护、容错能力Spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集(RDD:ResilientDistributedDataset)中。这些数据对象既可以放在内存,也可以放在磁盘。Hive将每次处理后的数据都写入到磁盘上框架实现以及编程APISpark支持Scala、Java、Python等几种语言(译者blogchong.com注:spark最合适的编程语言是scala,虽然也支持java,但实现起来很麻烦)通过使用类SQL的HiveQL语言实现数据查询。Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。测试方法借助Spark与Hive的SQL客户端工具,测试日常关键读写操作SQL的性能和执行效率,测试数据规模取其中一张大表数据,以浙江2300万用户为例,日电量2300万行记录,一月按31日计算,则测试数据为7.13亿行数据集。以上图1-3所示的基于分布式离线技术的电量数据批量高速处理方法是本发明的具体实施例,已经体现出本发明实质性特点和进步,可根据实际的使用需要,在本发明的启示下,对其进行形状、结构等方面的等同修改,均在本方案的保护范围之列。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1