电商客服自动问答系统语句关键词提取方法与流程
本发明涉及一种关键词提取方法,特别是一种电商客服自动问答系统语句关键词提取方法。
背景技术:
随着网络的发展,网络购物已经悄然兴起,人们通过网络来选购各种物品已经越来越成为一种时尚,然而现在的网络客服机器人只能向消费者提供列表咨询服务,即向消费者提供一个列表,让消费者自己选择需要的服务,消费者不能进行实时咨询,这样会直接降低消费者的购物体验。如果要实现网络机器人对消费者进行实时回话,就要准确理解消费者的意图,如果要使得机器人准确理解消费者的意图,就必须要对消费者的语句进行关键词提取。
技术实现要素:
为解决上述问题,本发明的目的在于提供一种电商客服自动问答系统语句关键词提取方法。
本发明解决其问题所采用的技术方案是电商客服自动问答系统语句关键词提取方法,包括以下步骤:构建分词系统、建立停用词表以及通过神经网络特征选取关键词。
进一步,所述分词系统是NLPIR汉语分词系统,所述分词系统具有中文分词功能、词性标注功能、命名实体识别功能、定义用户词典功能以及新词发现功能。
进一步,所述停用词表包括英文字符、数学字符、标点、频率高的单汉字、拟声字、只能在首位出现的字、方位词以及叹词。
进一步,通过神经网络特征选取关键词是指在用户语句进行分词后得到的关键词集合中提取关键词,提取关键词的时候根据关键词的三方面信息进行提取,所述三方面信息包括语义信息、自身信息和位置信息。
进一步,语义信息包括词语词性、词语关联度、句子命名实体识别以及去停用词;词语词性是指用户语句中各种词性成为关键词的概率存在差异,在关键词提取中对不同词性的关键词赋予不同分值,用于提取分值计算;词语关联度是指用户的句子中词语和其他词语之间存在复杂关系,一句话中各个词语相当于是空间中的一个个语义节点,它们相互之间存在一定关联,因而本方法将此因素考虑其中,利用Word2vec来计算词语关联度值;句子命名实体识别是指命名实体在句子中具有特殊意义,对它们的识别是关键词提取的内容之一;去停用词是指某些关键词在句子中出现频率比较高,但是它的作用很小,所以在进行关键词提取的时候都要去掉这些作用小的词。
进一步,自身信息包括词频和词语长度;词频是指用户多次提到某一词语时,它成为关键词的可能性就很大;词语长度是指越长的词语表示越丰富的信息,其成为关键词的可能性也就越大。
进一步,位置信息包括首次位置和词跨度,如果是单次出现的则用首次出现的位置表示,如果2次或以上出现则用首次出现位置和词语跨度表示;位置其中L为句长,li为词的位置;词跨度Hi,其中li2为最后出现词位置,li1为首次出现词位置。
本发明的有益效果是:本发明是电商客服自动问答系统语句关键词提取方法,本发明通过关键词提取的办法使得网络客服机器人能够对消费者的意图有明确的了解,实现了消费者与网络客服机器人的实时对话,使得网络购物更加方便,大大提高了消费者的购物体验。
附图说明
下面结合附图和实例对本发明作进一步说明。
图1是本发明的自定义词典;
图2是本发明的停用词表;
图3是本发明的词性分值表;
图4是本发明的实例结果。
具体实施方式
要实现对用户商品意图的识别,首先要做的就是对用户输入语句的理解。这种理解的基础工作就是提取句子中的关键词,语句中的关键词语是用户意图表达的外在呈现。问答系统中对用户关键词的提取,首先对用户的语句进行分词,然后去除其中包含的一些网址连接、标点符号等,对剩下的词语进行关键词提取,步骤中的主要内容如下:构建分词系统、建立停用词表以及通过神经网络特征选取关键词。
和英文不同的是中文语句需要进行分词,分词的好坏对关键词的提取存在影响,本发明选取NLPIR汉语分词系统,也就是之前的ICTCLAS2013,本系统具有多项功能如:中文分词、词性标注、命名实体识别,以及定义用户词典、新词发现等;在2003年参加的“国际SIGHAN分词大赛”取得了综合第一的成绩,是最优秀的中文分词系统之一,目前,全球用户突破20万。电商客服机器人使用这一分词系统,同时由于其服务市场是化妆品行业会具有一些专业词汇需要进行添加,这里构建了专属的用户自定义词典,包含词汇660多个,用户自定义词典的前9行如图1所示。
在分词之后得到的集合中,会发现一些无效词,它们可以被排除出关键词的候选集。由于系统使用情景不一样,所以在停用词表建立的时候要考虑到网购的特点。众多学者也进行了停用词的归纳,将“英文字符、数词、量词、数学字符、标点、频率高的单汉字、拟声字、只能在首位出现的字、代词、方位词、叹词”等列入了停用词的选择范围,针对不同的处理文本这些词的选择会存在一些差异。
本系统中一些数词和代词等都不会被列入停用词,因为顾客在购物中会涉及到商品的数量、价格等,这些是句子中的关键信息,显然不能被忽略;此外,代词也是重要的,在问答过程中顾客往往对说过的商品会采用指代的方式提及,因此代词也是重要的语句信息之一;但是在网络购物中常出现的“问候词”例如,“亲、你好、在、在吗”等都对语句的关键信息没什么影响,所以被列入停用词表,但是在问答系统中这些招呼词语会有相应的招呼反馈,即用户打招呼时,机器人也会热情招呼回应。另外,一些单字助词和拟声字、词也不包含重要信息因此将它们也列入,通过统计机器人交互语料以及收集的用户聊天语料进行词频统计,然后进行筛选归纳得到停用词表如图2所示。
问句关键词特征提取,实际对用户的问句进行分词后得到C=[c1,c2…cn];对ci进行特征提取,词语的特征选择从三方面信息展开即语义、自身和位置。
语义信息:(1)词语词性:在用户语句中各种词性成为关键词的概率会存在差异,在关键词提取中对关键词的根据不同词性赋予不同分值,用于提取分值计算,词性分值表如图3所示。(2)词语关联度:将杂网络关系引入到了语言中,并利用了复杂网络中的参数构造了15种语言的复杂网络,用户的句子中词语和其他词语之间存在复杂关系,一句话中各个词语相当于是空间中的一个个语义节点,它们相互之间存在一定关联,因而本发明将此因素考虑其中,利用Word2vec来计算词语关联度值。(3)句子命名实体识别:命名实体在句子中往往具有特殊意义,对它们的识别是很多关键词提取的内容之一。(4)停用词:在句子中出现频率比较高,但是它的作用很小,很多时候在进行关键词提取的时候都要去停用词。
自身信息:(1)词频:用户的话语中当词频逐渐增加时,如用户多次提到某一词语时,它成为关键词的可能性很大。(2)词语长度:有统计发现越长的词语表示越丰富的信息,其成为关键词的可能性很大,本系统中一些专有名词会存在较长的情况,例如:机器人客服关键词树中的“生物纤维”、“覆盆子”等。
位置信息:首次位置和词跨度;词语在句子中出现的位置信息,如果是单次出现的则用首次出现的位置表示,如果2次或以上出现则用首次出现位置和词语跨度表示;位置其中L为句长,li为词的位置;词跨度Hi,其中li2为最后出现词位置,li1为首次出现词位置。
电商客服机器人根据某化妆网店购物语料,结合自身产品和领域收集整理了语料库,这里从其中抽取了不重复的1000条句子进行实验,原因是整理的语料数据存在很多的相似性加上目前语料数量限制,实验步骤如下:
(1)利用中科院NLPIR汉语分词系统进行分词,由于电商客服机器人的应用背景和产品对象的原因,利用分词系统进行分词后不可避免地存在错误分词;因此,本发明对语料库的分词进行审核后,将错误的分词进行提取形成自定义分词词典加入分词系统中提高分词的准确性。
(2)对抽取的1000个句子进行简单处理后分词,得到约6600多个分词结果,在利用中科院分词系统进行分词的过程中就实现了对词语命名实体的识别和词性的标注;本发明赋予不同的词性不同的分值,根据中科院使用的分词标准,制订了词性分值表如表3,另外命名实体是为1,不是为0。
(3)然后对这6600多个词统计上述的其他特征值,词频、词语长度、以及词位置和词跨度统计计算即可;停用词统计利用停用词表标记是为1,不是为0;词语关联度的计算涉及到Word2vec的使用,首先收集了来自店铺购物、新闻、评论、化妆品抓取等4大块的语料,利用Word2vec在服务器上进行训练,训练结束后得到包含词汇向量的bin文件,利用bin文件来计算6600多个词语各自的平均关联度。这里所有的特征值均可得到,数据准备完毕。
利用matlabR2014a对数据进行实验,本发明对得到的6600条数据进行处理,删除了一些判断无效的,如Word2vec值为FAULT的,因为语料资源的限制有些词语未能得到其词向量的表示;同时发现词语“中性”、“混合型”等词性标注为b的区别词等的词性分值为0,实际中这些词表示了肌肤的属性,因此将其词性值设为0.7;最终,得到了6592条有效数据,整理得数据发布地址如下:http://120.237.31.12/E_Bot_backstage/date.html,名为“客服机器人BP神经网络实验数据”。本发明利用matl-ab中的GUI工具nprtool,其中使用数据集默认分配如下:训练样本70%,验证样本15%,测试样本15%,在训练过程中神经网络隐藏层节点的设置首先按照经验设置为5个,经实际训练发现隐藏层节点数为10时训练和结果比较好。鉴于本发明在神经网络中加入了利用Word2vec计算的词语关联度,这里在训练中分别对加此特征和不加此特征的数据进行实验结果比较,即神经网络节点组合分别是(8,10,1)和(7,10,1)经过实验得到两者的混淆矩阵。
另外,本发明利用神经网络进行关键词提取这一方法,在文档关键词提取中进行了应用,本发明的结果将与其进行对比。本发明关键词识别的准确率经过模型实验,测试准确率较为稳定在88%以上,最优达到了90.7%,测试准确率高于利用BP神经网络实现文档提取的83.8%,说明BP神经网络应用于语句关键词提取中的可行性;但是其实验的数据量是新闻和期刊文章,其篇数都为200,词汇量巨大;本发明选取1000条句子,在单位上数量具有可比性,此外,做更大数据量的结果会更具有说服性。
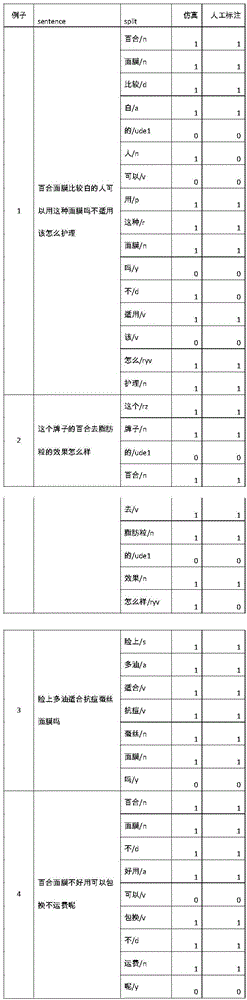
经过之前实验,本发明保存了实验的最优训练仿真模型并对实际的语句进行仿真,呈现的实例的结果如图4所示:
以上四个例子经历了分词和关键词提取,其结果呈现如下:
Ex1:百合面膜比较白的人可以用这种面膜吗不适用该怎么护理?
分词:百合/n面膜/n比较/d白/a的/udel人/n可以/v用/p这种/r面膜/n吗/y不/d适用/v该/v怎么/ryv护理/n
关键词提取结果:百合 面膜 比较 白 人 用 这种 面膜 不 适用 怎么 护理
Ex2:这个牌子的百合去脂肪粒的效果怎么样
分词:这个/rz牌子/n的/ude1百合/n去/v脂肪粒/n的/ude1效果/n怎么样/ryv
关键词提取结果:这个 牌子 百合 去 脂肪粒 效果 怎么样
Ex3:脸上多油适合抗痘蚕丝面膜吗?
分词:脸上/s多油/a适合/v抗痘/v蚕丝/n面膜/n吗/y
关键词提取结果:脸上 多油 适合 抗痘 蚕丝 面膜
Ex4:百合面膜不好用可以包换不运费呢?
分词:百合/n面膜/n不/d好用/a可以/v包换/v不/d运费/n呢/y
关键词提取结果:百合 面膜 不 好用 包换 不 运费
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!