基于最小生成树的多模态磁共振影像数据分类方法与流程
本发明涉及图像处理技术,具体是一种基于最小生成树的多模态磁共振影像数据分类方法。
背景技术:
作为多模态磁共振成像技术与复杂网络理论的结合,磁共振影像数据分类方法当前已经成为脑科学领域的热点之一。其广泛应用在各类研究中,特别是脑疾病的研究,并取得许多令人惊喜的成果。
功能磁共振(functional magnetic resonance imaging,fMRI)因其无创、高分辨率及可重复性等优点,在对以功能改变为特征的疾病研究中具有良好的应用前景。功能磁共振是在较短的时间内连续抓取一个时间序列内相同部位的成像,时间分辨率较高。但由于功能磁共振技术的天生弱点,相应的代价就是空间分辨率会下降。
结构磁共振成像(structural magnetic resonance imaging,sMRI)能够客观记录下从疾病潜伏期到发作期整个过程中患者脑结构生物标记的变化,这些数据能够从根本上改变人们对这种疾病的认识,并且能够影响和引导疾病的后续诊断和治疗。结构磁共振成像可以清楚的分辨病人的病灶位置,空间分辨率高,可以弥补功能磁共振成像的缺点。因此,本文采用基于功能磁共振和结构磁共振的多模态磁共振成像技术,来提高测量结果的准确性。
传统影像数据分类方法由于其自身原理所限,普遍存在方法论的限制。比如,图论方法受网络大小(即节点的数目)、网络稀疏度(即存在连接的百分比)和平均度(即每个节点的连接数)的影响。而在脑网络的构建过程中,阈值、冗余链接以及虚假链接会影响脑网络的拓扑结构。由此导致其分类准确率低,从而严重影响其应用价值。虽然一些技术可以在一定程度上控制上述因素所带来的误差,却很难做到完全避免这些因素对结果的影响。
基于此,有必要发明一种全新的磁共振影像数据分类方法,以解决传统磁共振影像数据分类方法存在的上述问题。最小生成树是一个数学定义的、无偏的子网,计算结果不会因为网络大小、平均度或密度的影响而出现误差,可以避免一般的方法论问题。因此,本文采用了一种基于最小生成树的多模态磁共振影像数据分类方法,以提高分类结果的准确性。
技术实现要素:
本发明为了解决传统磁共振影像数据分类方法分类准确率低的问题,提供了一种基于最小生成树的多模态磁共振影像数据分类方法。
本发明是采用如下技术方案实现的:
基于最小生成树的多模态磁共振影像数据分类方法,该方法是采用如下步骤实现的:
步骤S1:对静息态功能磁共振影像进行预处理,并根据选定的标准化脑图谱对预处理后的静息态功能磁共振影像进行区域分割,然后对所分割的各脑区进行平均时间序列的提取;
步骤S2:计算各脑区的平均时间序列两两之间的协方差系数,由此得到协方差矩阵;然后根据协方差矩阵计算各脑区的平均时间序列两两之间的皮尔逊相关系数,由此得到皮尔逊相关矩阵;
步骤S3:对磁共振弥散张量成像影像进行预处理,并根据选定的标准化脑图谱对预处理后的磁共振弥散张量成像影像进行区域分割,然后对所分割的各脑区进行全脑神经纤维追踪,由此得到各脑区的平均局部各向异性及各脑区之间的神经纤维数量;
步骤S4:计算各脑区两两之间的权重,由此得到神经纤维矩阵;
步骤S5:结合皮尔逊相关矩阵和神经纤维矩阵,利用克鲁斯卡尔算法构建多模态最小生成树脑网络;
步骤S6:计算多模态最小生成树脑网络的局部属性;所述局部属性包括:多模态最小生成树脑网络中各节点的度、介数中心度、离心率;
步骤S7:采用支持向量机分类算法,选择多模态最小生成树脑网络的局部属性作为分类特征,由此进行分类器的构建,然后采用交叉验证方法对构建的分类器进行检验;
步骤S8:采用互信息分析方法,对所选特征在分类器中的重要度和冗余度进行量化,然后根据量化结果对所选特征进行二次筛选,由此对多模态最小生成树脑网络进行优化。
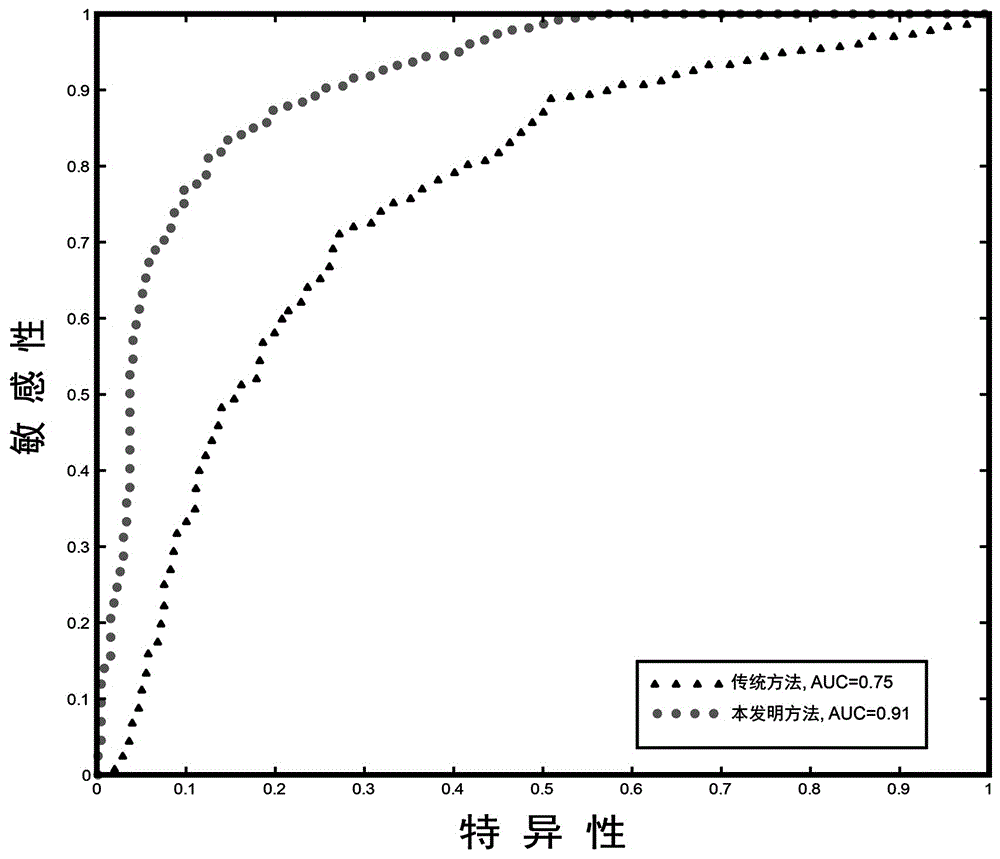
与传统磁共振影像数据分类方法相比,本发明所述的基于最小生成树的多模态磁共振影像数据分类方法通过采用皮尔逊相关方法、克鲁斯卡尔算法、支持向量机分类算法、交叉验证方法、互信息分析方法,实现了多模态最小生成树脑网络的描述,由此大幅提高了分类准确率(如图1所示,本发明的分类准确率明显高于传统磁共振影像数据分类方法的分类准确率),从而使得应用价值更高。
本发明有效解决了传统磁共振影像数据分类方法分类准确率低的问题,适用于磁共振影像数据分类。
附图说明
图1是本发明与传统磁共振影像数据分类方法的对比示意图。
具体实施方式
基于最小生成树的多模态磁共振影像数据分类方法,该方法是采用如下步骤实现的:
步骤S1:对静息态功能磁共振影像进行预处理,并根据选定的标准化脑图谱对预处理后的静息态功能磁共振影像进行区域分割,然后对所分割的各脑区进行平均时间序列的提取;
步骤S2:计算各脑区的平均时间序列两两之间的协方差系数,由此得到协方差矩阵;然后根据协方差矩阵计算各脑区的平均时间序列两两之间的皮尔逊相关系数,由此得到皮尔逊相关矩阵;
步骤S3:对磁共振弥散张量成像影像进行预处理,并根据选定的标准化脑图谱对预处理后的磁共振弥散张量成像影像进行区域分割,然后对所分割的各脑区进行全脑神经纤维追踪,由此得到各脑区的平均局部各向异性及各脑区之间的神经纤维数量;
步骤S4:计算各脑区两两之间的权重,由此得到神经纤维矩阵;
步骤S5:结合皮尔逊相关矩阵和神经纤维矩阵,利用克鲁斯卡尔算法构建多模态最小生成树脑网络;
步骤S6:计算多模态最小生成树脑网络的局部属性;所述局部属性包括:多模态最小生成树脑网络中各节点的度、介数中心度、离心率;
步骤S7:采用支持向量机分类算法,选择多模态最小生成树脑网络的局部属性作为分类特征,由此进行分类器的构建,然后采用交叉验证方法对构建的分类器进行检验;
步骤S8:采用互信息分析方法,对所选特征在分类器中的重要度和冗余度进行量化,然后根据量化结果对所选特征进行二次筛选,由此对多模态最小生成树脑网络进行优化。
所述步骤S1中,预处理步骤具体包括:时间层校正、头动校正、联合配准、空间标准化、低频滤波;标准化脑图谱采用AAL模板;平均时间序列的提取步骤具体包括:提取AAL模板中每个脑区所包含的所有体素在不同时间点上的BOLD强度,并将各体素在不同时间点上的BOLD强度进行算术平均,由此得到各脑区的平均时间序列。
所述步骤S2中,计算公式具体表示如下:
公式(1)中:Sij表示协方差矩阵中第i行第j列的元素,即第i个脑区和第j个脑区之间的协方差系数;M表示时间点个数;xi(t)表示第i个脑区的时间序列;表示第i个脑区的时间序列的平均值;xj(t)表示第j个脑区的时间序列;表示第j个脑区的时间序列的平均值;协方差矩阵的维度为90×90;
公式(2)中:Rij表示皮尔逊相关矩阵中第i行第j列的元素,即第i个脑区和第j个脑区之间的皮尔逊相关系数;xi表示第i个脑区协方差序列;yj表示第j个脑区协方差序列;表示第i个脑区和第j个脑区的协方差;表示第i个脑区的协方差序列的标准差;表示第j个脑区的协方差序列的标准差;皮尔逊相关矩阵的维度为90×90。
所述步骤S3中,预处理采用PANDA软件进行;预处理步骤具体包括:配准、标准化、涡流矫正;标准化脑图谱采用AAL模板;全脑神经纤维追踪采用FACT算法进行。
所述步骤S4中,计算公式具体表示如下:
公式(3)中:Dij表示神经纤维矩阵中第i行第j列的元素,即第i个脑区和第j个脑区之间的权重;FNij表示第i个脑区和第j个脑区之间的神经纤维数量;FAi表示第i个脑区的平均局部各向异性;FAj表示第j个脑区的平均局部各向异性;神经纤维矩阵的维度为90×90。
所述步骤S5中,构建多模态最小生成树脑网络的步骤具体包括:
步骤S51:构造一个只含n个顶点、边集为空的子图,并将子图中的每个顶点均视为一个子集;
步骤S52:结合皮尔逊相关矩阵和神经纤维矩阵,生成权重矩阵;生成公式具体表示如下:
Wij=zscore(Rij)+zscore(Dij) (4);
公式(4)中:Wij表示权重矩阵中第i行第j列的元素;Rij表示皮尔逊相关矩阵中第i行第j列的元素;Dij表示神经纤维矩阵中第i行第j列的元素;
步骤S53:比较权重矩阵中各个元素的值,并将各个元素的值按照升序方式进行排列;每个元素相当于子图的一条链接;
步骤S54:从排列好的各个元素中选取值最小的元素,并判断该元素的两个顶点是否分属不同的子集;若该元素的两个顶点分属不同的子集,则将该元素视为有效链接,并将其加入子图,同时合并两个子集;反之,若该元素的两个顶点落在同一个子集中,则将该元素视为无效链接,并将其剔除,然后从剩余的各个元素中选取值最小的元素,并判断该元素的两个顶点是否分属不同的子集;以此循环,直至子图中的n个子集合并成一个子集时,即子图中存在n-1个元素时,多模态最小生成树脑网络构建完成。
所述步骤S6中,计算公式具体表示如下:
公式(5)中:Ki表示多模态最小生成树脑网络中任意一节点i的度;aij表示多模态最小生成树脑网络中节点i和节点j之间的链接;
公式(6)中:BCi表示多模态最小生成树脑网络中任意一节点i的介数中心度;ρhj表示多模态最小生成树脑网络中从节点h到节点j的最短路径的数量;表示多模态最小生成树脑网络中从节点h到节点j经过节点i的最短路径的数量;
ECCi=max(dij) (7);
公式(7)中:ECCi表示多模态最小生成树脑网络中任意一节点i的离心率;dij表示多模态最小生成树脑网络中节点i与节点j之间的最短路径长度;多模态最小生成树脑网络中节点i的离心率即节点i到其他节点的最短路径的最大值。
所述步骤S7中,分类器的构建步骤具体包括:采用RBF核函数,选择双样本T检验后具有显著组间差异的局部属性的AUC值作为分类特征,由此进行分类器的构建;
检验步骤具体包括:从样本集中随机选择90%的样本作为训练样本,剩余10%的样本作为测试样本,由此进行分类测试并得到分类准确率;将重复进行100次分类测试后得到的分类准确率进行算术平均,然后将算术平均值作为分类器的分类准确率。
所述步骤S8中,量化公式具体表示如下:
公式(8)中:D表示所选特征在分类器中的重要度;S表示所有特征的集合;|S|表示S中特征的个数;xi表示所选特征;c表示样本的类别标签;I(xi,c)表示所选特征与样本的类别标签c的互信息;
公式(9)中:R表示所选特征在分类器中的冗余度;S表示所有特征的集合;|S|表示S中特征的个数;xi表示所选特征;xj表示其它特征;I(xi,xj)表示所选特征与其它特征的互信息;
二次筛选步骤具体包括:分别按照重要度大小和冗余度大小对所选特征进行排名,然后筛选出重要度较大且冗余度较小的特征。
- 还没有人留言评论。精彩留言会获得点赞!